小白程序员必备!轻松掌握LightRAG,构建高效知识库与智能问答系统(收藏版)
将文档转换为知识图谱(实体+关系)支持多层次检索(局部/全局/混合)使用向量数据库加速语义搜索通过LLM生成高质量答案LightRAG的核心优势知识图谱:理解实体关系,支持复杂推理多模式查询:local/global/hybrid适应不同问题高效检索:向量+图谱双重索引可扩展:支持多种存储后端(JSON/PostgreSQL/Neo4j)生产就绪:完善的并发控制、错误处理、状态管理学习路径建议运行
小白程序员必备!轻松掌握LightRAG,构建高效知识库与智能问答系统(收藏版)
LightRAG是一个基于知识图谱的检索增强生成(RAG)系统,通过将文档转换为知识图谱并支持多层次检索,能够理解实体关系、进行多跳推理和全局理解。本文详细介绍了LightRAG的整体架构设计、核心算法(文档索引流程、实体关系抽取、知识融合算法和查询检索流程),并提供小白理解指南和关键概念速查。通过学习LightRAG,程序员可以轻松构建高效的知识库,提升信息检索和生成能力。
1、什么是 LightRAG?

LightRAG 是一个基于知识图谱的检索增强生成(RAG)系统,它的核心创新在于:
- 将文档转换为知识图谱(实体+关系)
- 支持多层次检索(局部/全局/混合)
- 使用向量数据库加速语义搜索
- 通过LLM生成高质量答案
2、核心价值
相比传统RAG(只做文本块检索),LightRAG通过构建知识图谱,能够:
- 理解实体关系:不仅知道"张三"和"李四",还知道他们是"同事关系"
- 多跳推理:能回答"张三的同事的老板是谁"这类复杂问题
- 全局理解:既能回答细节问题,也能回答宏观问题
3、整体架构设计
- 三层架构

- 核心组件关系
LightRAG (主控制器)
├── 文档插入流程
│ ├── 文本分块 (chunking_by_token_size)
│ ├── 实体抽取 (extract_entities)
│ └── 知识融合 (merge_nodes_and_edges)
│
├── 查询流程
│ ├── 关键词提取
│ ├── 图谱检索 (kg_query)
│ ├── 向量检索 (naive_query)
│ └── LLM生成答案
│
└── 存储管理
├── full_docs (完整文档)
├── text_chunks (文本块)
├── entities_vdb (实体向量)
├── relationships_vdb (关系向量)
└── chunk_entity_relation_graph (知识图谱)
4、核心算法设计
算法1: 文档索引流程
1.1 文本分块算法 (chunking_by_token_size)
目的:将长文档切分为适合LLM处理的小块
核心逻辑:
def chunking_by_token_size(
tokenizer, # 分词器
content, # 原始文本
chunk_token_size, # 每块最大token数 (默认1200)
chunk_overlap_token_size # 重叠token数 (默认100)
):
# 步骤1: 将文本编码为token序列
tokens = tokenizer.encode(content)
# 步骤2: 滑动窗口切分
chunks = []
for start in range(0, len(tokens), chunk_token_size - chunk_overlap_token_size):
chunk_tokens = tokens[start : start + chunk_token_size]
chunk_text = tokenizer.decode(chunk_tokens)
chunks.append(chunk_text)
return chunks
关键设计:
- 重叠窗口:相邻块有100个token重叠,避免切断语义
- Token计数:基于token而非字符,确保LLM输入不超限
- 可选分隔符:支持按段落/句子分割后再按token切分
1.2 实体关系抽取 (extract_entities)
目的:从文本块中提取结构化的实体和关系
核心流程:
async def extract_entities(chunks, global_config):
results = []
for chunk_id, chunk_data in chunks.items():
# 步骤1: 构造提示词
prompt = PROMPTS["entity_extraction"].format(
entity_types=config["entity_types"], # 实体类型列表
tuple_delimiter="<|#|>", # 字段分隔符
record_delimiter="\n", # 记录分隔符
input_text=chunk_data["content"] # 文本块内容
)
# 步骤2: 调用LLM提取
extraction_result = await llm_func(prompt)
# 步骤3: 解析LLM输出
entities, relationships = parse_extraction_result(extraction_result)
# 步骤4: 存储到缓存
results.append({
"chunk_id": chunk_id,
"entities": entities,
"relationships": relationships
})
return results
LLM输出格式示例:
entity<|#|>张三<|#|>人物<|#|>公司CEO,负责战略决策
entity<|#|>ABC公司<|#|>组织<|#|>一家科技公司
relation<|#|>张三<|#|>ABC公司<|#|>任职于<|#|>张三是ABC公司的CEO
<|COMPLETE|>
关键技术:
- Few-shot提示:提供示例引导LLM输出标准格式
- 多轮Gleaning:如果首次提取不完整,追加提示再次提取
- 缓存机制:提取结果存入llm_response_cache,避免重复调用
1.3 知识融合算法 (merge_nodes_and_edges)
目的:将多个文本块的提取结果合并为统一的知识图谱
核心挑战:
- 同一实体在不同块中可能有不同描述
- 同一关系可能被多次提取
- 需要保持数据一致性
算法流程:
async def merge_nodes_and_edges(chunk_results, knowledge_graph_inst):
# 步骤1: 按实体名分组
entity_groups = defaultdict(list)
for result in chunk_results:
for entity in result["entities"]:
entity_groups[entity["name"]].append(entity)
# 步骤2: 合并实体描述
for entity_name, entity_list in entity_groups.items():
# 收集所有描述
descriptions = [e["description"] for e in entity_list]
# 使用LLM总结(如果描述过多)
if len(descriptions) > 3:
merged_description = await summarize_descriptions(descriptions)
else:
merged_description = "\n".join(descriptions)
# 更新图谱
await knowledge_graph_inst.upsert_node(
entity_name,
{
"description": merged_description,
"entity_type": entity_list[0]["type"],
"source_id": GRAPH_FIELD_SEP.join([e["chunk_id"] for e in entity_list])
}
)
# 步骤3: 合并关系(类似逻辑)
# ...
关键设计:
- Map-Reduce总结:描述过多时分批总结再合并
- Source ID追踪:记录每个实体/关系来自哪些文本块
- 并发控制:使用keyed_lock确保同一实体的更新串行化
算法2: 查询检索流程
2.1 查询模式对比

2.2 Local模式详解
核心思路:从实体出发,找到相关文本块
async def kg_query_local(query, entities_vdb, text_chunks, param):
# 步骤1: 提取低层关键词
ll_keywords = await extract_keywords(query, level="low")
# 示例: ["张三", "职位", "工作内容"]
# 步骤2: 向量检索相关实体
entities = await entities_vdb.query(
query=" ".join(ll_keywords),
top_k=param.top_k # 默认60
)
# 返回: [{"entity_name": "张三", "description": "...", "source_id": "chunk1,chunk2"}]
# 步骤3: 收集实体关联的文本块
chunk_ids = set()
for entity in entities:
chunk_ids.update(entity["source_id"].split(GRAPH_FIELD_SEP))
# 步骤4: 获取文本块内容
chunks = await text_chunks.get_by_ids(list(chunk_ids))
# 步骤5: 构造上下文
context = format_context(entities, chunks)
# 步骤6: LLM生成答案
answer = await llm_func(
prompt=PROMPTS["rag_response"].format(
context=context,
query=query
)
return answer
关键技术:
- 关键词提取:使用LLM从问题中提取实体名
- 向量相似度:通过embedding找到语义相关的实体
- Source ID追踪:快速定位实体出现的文本块
2.3 Global模式详解
核心思路:从关系出发,理解全局结构
async def kg_query_global(query, relationships_vdb, entities_vdb, param):
# 步骤1: 提取高层关键词
hl_keywords = await extract_keywords(query, level="high")
# 示例: ["组织架构", "管理层级", "部门关系"]
# 步骤2: 向量检索相关关系
relationships = await relationships_vdb.query(
query=" ".join(hl_keywords),
top_k=param.top_k
)
# 返回: [{"src": "张三", "tgt": "ABC公司", "description": "任职于", ...}]
# 步骤3: 获取关系涉及的实体
entity_names = set()
for rel in relationships:
entity_names.add(rel["src"])
entity_names.add(rel["tgt"])
entities = await entities_vdb.get_by_names(list(entity_names))
# 步骤4: 构造图谱上下文
context = format_graph_context(entities, relationships)
# 步骤5: LLM生成答案
answer = await llm_func(
prompt=PROMPTS["rag_response"].format(
context=context,
query=query
)
)
return answer
关键设计:
- 关系优先:通过关系理解实体间的连接
- 社区发现:可选地使用图算法找到实体社区
- 层次聚合:支持多跳关系的递归查询
2.4 Rerank优化
目的:对检索到的文本块重新排序,提升相关性
async def rerank_chunks(query, chunks, rerank_func):
# 步骤1: 准备重排序输入
rerank_input = [
{"query": query, "document": chunk["content"]}
for chunk in chunks
]
# 步骤2: 调用Rerank模型
scores = await rerank_func(rerank_input)
# 返回: [0.95, 0.82, 0.67, ...]
# 步骤3: 按分数排序
ranked_chunks = sorted(
zip(chunks, scores),
key=lambda x: x[1],
reverse=True
)
# 步骤4: 过滤低分块
filtered_chunks = [
chunk for chunk, score in ranked_chunks
if score > MIN_RERANK_SCORE # 默认0.0
]
return filtered_chunks
5、代码结构分析
核心代码 vs 辅助代码
核心代码(必须理解)
1.lightrag.py (2500行)
- LightRAG.__init__: 初始化存储和配置
- ainsert: 文档插入主流程
- aquery: 查询主流程
- adelete_by_doc_id: 文档删除逻辑
2.operate.py (5000行)
- extract_entities: 实体抽取
- merge_nodes_and_edges: 知识融合
- kg_query: 图谱查询
- naive_query: 向量查询
3.base.py (1000行)
- BaseVectorStorage: 向量存储接口
- BaseGraphStorage: 图存储接口
- QueryParam: 查询参数定义
辅助代码(可选理解)
kg/* (存储实现)
- json_kv_impl.py: JSON文件存储
- postgres_impl.py: PostgreSQL存储
- neo4j_impl.py: Neo4j图数据库
llm/* (LLM适配器)
- openai.py: OpenAI API
- ollama.py: Ollama本地模型
- gemini.py: Google Gemini
api/* (Web服务)
- lightrag_server.py: FastAPI服务器
- routers/: API路由定义
6、关键流程详解
流程1: 文档插入完整流程
用户上传文档
↓
[1] 文档入队 (apipeline_enqueue_documents)
- 生成doc_id (MD5哈希)
- 检查重复
- 存储到full_docs
- 状态设为PENDING
↓
[2] 文本分块 (chunking_by_token_size)
- 按1200 token切分
- 100 token重叠
- 生成chunk_id
↓
[3] 并行处理块 (extract_entities)
- 每块调用LLM提取实体/关系
- 结果存入llm_response_cache
- 更新chunk的llm_cache_list
↓
[4] 知识融合 (merge_nodes_and_edges)
- 按实体名分组
- 合并描述(可能调用LLM总结)
- 更新图谱和向量库
- 使用keyed_lock保证一致性
↓
[5] 持久化 (_insert_done)
- 调用所有存储的index_done_callback
- JSON存储写入磁盘
- 状态设为PROCESSED
↓
完成
并发控制:
- max_parallel_insert: 控制同时处理的文档数(默认2)
- llm_model_max_async: 控制并发LLM调用数(默认4)
- keyed_lock: 确保同一实体的更新串行化
流程2: 查询完整流程
用户提问
↓
[1] 关键词提取
- 调用LLM提取高层/低层关键词
- 高层: 抽象概念 (如"组织架构")
- 低层: 具体实体 (如"张三")
↓
[2] 根据模式检索
├─ local模式
│ - 向量检索实体
│ - 获取关联文本块
│
├─ global模式
│ - 向量检索关系
│ - 获取关联实体
│
└─ hybrid模式
- 合并local+global结果
↓
[3] Rerank (可选)
- 使用Rerank模型重排序文本块
- 过滤低分块
↓
[4] Token控制
- 统计实体/关系/块的token数
- 按优先级截断(保证不超max_total_tokens)
↓
[5] 构造上下文
- 格式化实体、关系、文本块
- 添加引用信息
↓
[6] LLM生成答案
- 使用rag_response提示词
- 支持流式输出
↓
返回结果
Token控制策略:
# 默认配置
MAX_ENTITY_TOKENS = 6000 # 实体上下文
MAX_RELATION_TOKENS = 8000 # 关系上下文
MAX_TOTAL_TOKENS = 30000 # 总预算
# 动态分配
chunk_tokens = MAX_TOTAL_TOKENS - actual_entity_tokens - actual_relation_tokens
7、存储层设计
存储类型与职责

存储实例映射
# LightRAG中的存储实例
self.full_docs # KV: 完整文档内容
self.text_chunks # KV: 文本块内容
self.full_entities # KV: 文档的实体列表
self.full_relations # KV: 文档的关系列表
self.entity_chunks # KV: 实体->块ID映射
self.relation_chunks # KV: 关系->块ID映射
self.entities_vdb # Vector: 实体向量
self.relationships_vdb # Vector: 关系向量
self.chunks_vdb # Vector: 文本块向量
self.chunk_entity_relation_graph # Graph: 知识图谱
self.doc_status # Status: 文档状态
self.llm_response_cache # KV: LLM缓存
数据流转示例
插入时:
文档 → full_docs (KV)
↓
文本块 → text_chunks (KV) + chunks_vdb (Vector)
↓
实体提取 → chunk_entity_relation_graph (Graph) + entities_vdb (Vector)
↓
关系提取 → chunk_entity_relation_graph (Graph) + relationships_vdb (Vector)
↓
元数据 → full_entities (KV) + full_relations (KV)
查询时:
问题 → 关键词提取
↓
entities_vdb.query() → 相关实体
↓
chunk_entity_relation_graph.get_node() → 实体详情
↓
text_chunks.get_by_ids() → 文本块内容
↓
LLM生成答案
8、小白理解指南
类比1: LightRAG就像一个智能图书馆
传统RAG(普通图书馆):
- 只有书架和书
- 找书靠关键词搜索
- 不知道书之间的关系
LightRAG(智能图书馆):
- 有书架(文本块)
- 有索引卡(实体)
- 有关系网(知识图谱)
- 馆员(LLM)能理解你的问题,找到最相关的书和索引卡
类比2: 文档处理像做笔记
- 分块:把一本厚书分成章节(每章1200字)
- 提取:从每章提取关键人物和事件
- 整理:把所有章节的笔记合并,去重
- 建索引:制作人物关系图和事件时间线
类比3: 查询像问图书馆员
Local模式(问具体问题):
- 你:“张三是谁?”
- 馆员:查索引卡→找到"张三"→翻出相关书页→总结答案
Global模式(问宏观问题):
- 你:“公司的组织架构?”
- 馆员:查关系图→找到所有"任职"关系→画出组织图→解释
Hybrid模式(问复杂问题):
- 你:“张三在公司的影响力?”
- 馆员:查索引卡(张三的详情)+ 查关系图(张三的关系网)→综合分析
关键概念速查

9、常见问题
Q1: 为什么要分块? A: LLM有输入长度限制(如4K token),必须把长文档切小块处理。
Q2: 为什么要建知识图谱? A: 纯文本检索只能找到"包含关键词"的段落,图谱能理解"张三和李四是同事"这种关系。
Q3: 向量数据库有什么用? A: 快速找到语义相似的内容。比如搜"CEO"能找到"首席执行官"。
Q4: Rerank是什么? A: 第一次检索可能不准,Rerank用更强的模型重新打分,把最相关的排前面。
Q5: 为什么需要缓存? A: LLM调用很慢很贵,缓存能避免重复计算。比如同一个文本块的实体提取结果可以复用。
总结
LightRAG的核心优势
知识图谱:理解实体关系,支持复杂推理
多模式查询:local/global/hybrid适应不同问题
高效检索:向量+图谱双重索引
可扩展:支持多种存储后端(JSON/PostgreSQL/Neo4j)
生产就绪:完善的并发控制、错误处理、状态管理
学习路径建议
入门(1-2天):
- 运行lightrag_openai_demo.py,理解基本流程
- 阅读base.py,理解核心接口
- 查看prompt.py,理解提示词设计
进阶(3-5天):
- 阅读lightrag.py的ainsert和aquery方法
- 理解operate.py的extract_entities和kg_query
- 尝试修改提示词或查询参数
高级(1-2周):
- 实现自定义存储后端
- 优化实体抽取算法
- 添加新的查询模式
- 集成到生产系统
最后
近期科技圈传来重磅消息:行业巨头英特尔宣布大规模裁员2万人,传统技术岗位持续萎缩的同时,另一番景象却在AI领域上演——AI相关技术岗正开启“疯狂扩招”模式!据行业招聘数据显示,具备3-5年大模型相关经验的开发者,在大厂就能拿到50K×20薪的高薪待遇,薪资差距肉眼可见!
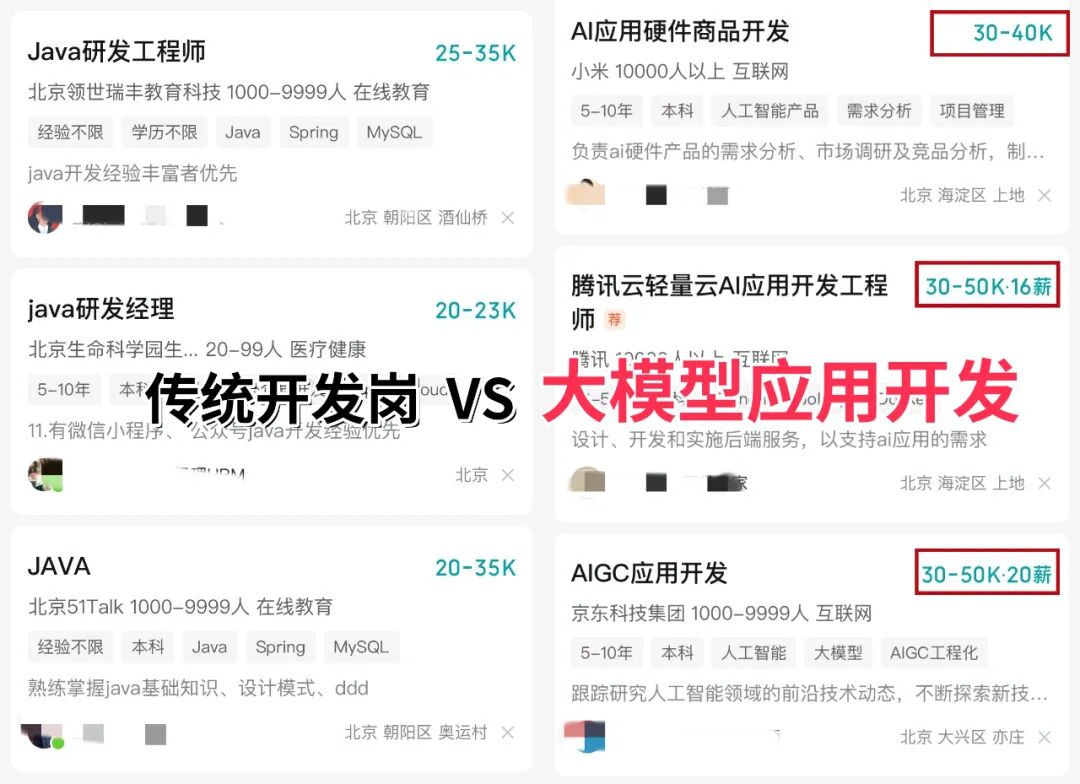
业内资深HR预判:不出1年,“具备AI项目实战经验”将正式成为技术岗投递的硬性门槛。在行业迭代加速的当下,“温水煮青蛙”式的等待只会让自己逐渐被淘汰,与其被动应对,不如主动出击,抢先掌握AI大模型核心原理+落地应用技术+项目实操经验,借行业风口实现职业翻盘!
深知技术人入门大模型时容易走弯路,我特意整理了一套全网最全最细的大模型零基础学习礼包,涵盖入门思维导图、经典书籍手册、从入门到进阶的实战视频、可直接运行的项目源码等核心内容。这份资料无需付费,免费分享给所有想入局AI大模型的朋友!

👇👇扫码免费领取全部内容👇👇

部分资料展示
1、 AI大模型学习路线图

2、 全套AI大模型应用开发视频教程
从入门到进阶这里都有,跟着老师学习事半功倍。

3、 大模型学习书籍&文档

4、 AI大模型最新行业报告
2025最新行业报告,针对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。

5、大模型大厂面试真题
整理了百度、阿里、字节等企业近三年的AI大模型岗位面试题,涵盖基础理论、技术实操、项目经验等维度,每道题都配有详细解析和答题思路,帮你针对性提升面试竞争力。


6、大模型项目实战&配套源码
学以致用,在项目实战中检验和巩固你所学到的知识,同时为你找工作就业和职业发展打下坚实的基础。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
- 👇👇扫码免费领取全部内容👇👇

这些资料真的有用吗?
这份资料由我和鲁为民博士(北京清华大学学士和美国加州理工学院博士)共同整理,现任上海殷泊信息科技CEO,其创立的MoPaaS云平台获Forrester全球’强劲表现者’认证,服务航天科工、国家电网等1000+企业,以第一作者在IEEE Transactions发表论文50+篇,获NASA JPL火星探测系统强化学习专利等35项中美专利。本套AI大模型课程由清华大学-加州理工双料博士、吴文俊人工智能奖得主鲁为民教授领衔研发。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的技术人员,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。 

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 6
6 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)