读《亿级流量》有感:如果用Redis做主库,该怎么设计点赞计数
本文介绍了高并发计数系统的设计与实现。针对社交应用中点赞、评论等计数场景的特点(读写量大、非核心功能、精度要求递减),提出使用Redis作为主库的方案,替代传统关系型数据库。系统采用三层架构:事实层用Bitmap记录用户行为,事件层通过Kafka异步更新,汇总层定期聚合数据到定制化的SDS结构。这种设计通过数据结构优化(位图分片、紧凑数组)和异步处理机制,实现了高性能、低延迟的计数服务,同时保证了
0.前言
这篇文章我们来介绍一下计数系统,其理论基础的支撑来源于书籍《亿级流量系统架构设计与实战》的第八章——通用计数系统。我也只是学习了本章的内容后以本文作为自己的读书笔记,记录一下问题分析和解决的流程。
1. 计数系统概述
1.1 计数的使用场景
具有累计性质的计数数据在当前C端可以说是非常广泛的存在,无论是刷抖音还是小红书,几乎都离不开计数系统:
- 用户发布的每条帖子,都可以看到点赞数、评论数、收藏数、分享数等;
- 用户主页还有关注数、粉丝数、作品数等;
- 评论区中的每条评论还有点赞数和评论数。
以上只是计数功能的冰山一角,可以说我们使用的每个社交APP,几乎都和计数分不开。
1.2 计数数据的特点
- 读写请求量巨大:用户每次刷新页面,就要重新进行一次读取,因此计数结果的展示需要支持高并发;其次对于写,由于点赞、转发这些行为对于用户来说触发成本很低,因此计数的写入也必须要支持高并发。
- 非核心功能:点赞这种具有累加性质的计数数据和钱包余额不同,它是否能正常展示并不影响用户使用APP。在极端情况下,比如网络波动、服务器遭受攻击等,计数系统作为非核心业务,在无法展示时并不会对用户造成非常大的影响。
- 对数据的精确度要求与数值增加成反比:这个点非常有意思,非常贴近生活。对于我们这些普通人而言,发了一条抖音或者朋友圈,可能会非常看重点赞数:哪些人给我点赞了,哪些人给我评论了。但如果一不小心突然火了,这条抖音的点赞数飙升到了1w,那你就不会纠结那一个两个点赞,而是开始关心级别的跃迁,比如万级别的跃迁。事实上抖音也确实是这么做的,每当作品的点赞数超过1w时,他就会开始以万作为计数单位,此时对数据并没有很强的准确性要求,一个两个点赞根本没什么影响。
在初学的时候,我们通常认为,计数数据应该来源于这条记录本身。比如我们想要看一条帖子的点赞数,那我们就要去罗列这个作品的所有点赞记录,并统计其个数,但事实上这样的做法有很高的并发风险,最可靠的做法是将计数数据与数据记录解耦,独立成一个模块。
2.关系型数据库的困境
我们以作品点赞数为例,哪个作品被哪个用户点赞过,这条点赞记录会被存储到关系型数据库MySQL里。我们要获取这个作品的点赞记录,就用执行SQL的count语句,这个语句在不同的引擎中实现方式是不同的。
在MyISAM引擎中,它把一张表的总行数存储在磁盘上,因此在执行count时会直接返回这个数,效率很高。而InnoDB在执行count时,需要把数据一行一行的从引擎中读出来,然后进行累加计数。
但由于InnoDB提供了良好的事务保证,在绝大多数场景中,我们都会选择使用InnoDB作为MySQL的存储引擎。如果是点赞数比较少的应用场景,那我们使用count来获取总数问题不大;但是如果遇到那些点赞量较大的作品,如果我们去使用count,对MySQL的性能造成极大的影响。而且我们只是想获取一个数据的总数而已,为了这个总数,我们还必须将每条数据读出来,这个逻辑本身也很笨重。因此,依赖统计来展示计数数据显然是不可行的。
3.Redis力挽狂澜
在我们过去的认知里,如果MySQL无法应对写压力,可以通过异步方式对数据进行更新:先更新缓存数据, 再使用消息队列异步通知关系型数据库进行数据更新; 而如果关系型数据库无法应对读压力, 则可以使用缓存对外提供服务。
而对于计数模块而言,其读写请求量是巨大的,几乎每时每刻都在与缓存系统直接交互,在Redis之后再使用MySQL似乎有点多此一举。另外,计数数据也不是那种绝对不可丢失的数据,它可以由数据记录总数反向推出。因此针对高并发的计数模块,我们干脆直接使用Redis作为主库。
这样一来,不仅满足了计数模块高并发的服务能力要求,而且减少了非必要的数据存储,包括省去了一系列的问题,例如数据一致性、缓存三剑客等,整体架构异常简洁。
4.海量数据计数服务设计
通过前面的讨论,我们已经确定采用Redis作为主库来存储计数数据,本节就正式开始设计。我们以一个论坛项目为例,在一个类似于小红书的论坛中,我们每点开一篇帖子,都会显示这篇帖子的点赞、收藏、转发数。
4.1 选择数据结构
点赞系统的数据结构比较简单,没什么好纠结的,直接选择bitmap就可以了,bitmap最适合用在这种二值场景下,毕竟点赞和收藏功能也符合这种二值场景,也就是只存在“点赞/未点赞”两种状态。
而至于点赞数的读取,我们确实需要斟酌一下,由于一篇帖子需要同时统计点赞收藏评论三个指标,那么很容易想到我们要基于Hash来存储,一篇帖子对应一个key,包含点赞收藏评论三个字段,每个字段取值即可,这样的设计确实非常直观,但仍然存在一些问题。
一篇帖子除了这三个指标,还有浏览量、转发,只是这两个指标不显示,但我们也要存在redis中,那么我们就有五个hash字段,这样我们就要执行三次MGET来获取三个需要显示的指标,其实网络IO的消耗还是蛮大的。另外就是,Hash的内存占用也不小。
这样我们如果需要追求极致的性能,那就必须要设计定制化的数据结构。
有什么数据结构既占用更小内存,又能以尽量少的IO次数读到尽量多的数据呢?很容易想到数组具有这样的特点,数组的内存空间是非常紧凑的,同时把数组地址读出来后,我们可以通过偏移来遍历数组。
运用到我们的系统中,我们可以设计类似数组的定制化SDS,首先它需要依次存放五个指标:浏览量、点赞、收藏、评论、转发,我们给每个指标分配4个字节,攻击20个字节,单个指标最大可以存储40亿,可以说是绰绰有余;另外只要一次IO将SDS读出,就可以通过位偏移来获取参数。
4.2 BitMap初始配置
/**
* 位图分片配置与帮助函数。
* 采用固定分片大小,避免单键因用户ID偏移过大而膨胀。
*/
public final class BitmapShard {
// 每个分片的位数(32K 位 => 4KB/分片)
public static final int CHUNK_SIZE = 32_768;
public static long chunkOf(long userId) {
return userId / CHUNK_SIZE;
}
public static long bitOf(long userId) {
return userId % CHUNK_SIZE;
}
private BitmapShard() {}
}
我们以32768位为一片,这样我们根据user_id除32768得到的整数来作为分片,余数作为在这一片的偏移。
我们就以user_id=1为例,其分片是0,偏移是1,那么对应100号知文的点赞redis key就为:bm:{like}:{knowpost}:{100}:{0},用户在这片bitmap的1位,该位为1代表点赞,为0代表没有点赞。
4.3 定制化SDS
/**
* 计数 Schema 映射及常量定义。
* 阶段一采用 8 字节 Int64 固定偏移(SDS),后续可平滑替换为 5 字节实现。
*/
public final class CounterSchema {
// 使用 v1 Schema:下标约定(可扩展)
// 0: read(预留)
// 1: like
// 2: fav
// 3: comment(预留)
// 4: repost(预留)
public static final String SCHEMA_ID = "v1";
public static final int FIELD_SIZE = 4; // 改为 4 字节 Int32 存储
public static final int SCHEMA_LEN = 5; // 预留 5 个指标位
public static final int IDX_LIKE = 1;
public static final int IDX_FAV = 2;
public static final Map<String, Integer> NAME_TO_IDX = Map.of(
"like", IDX_LIKE,
"fav", IDX_FAV
);
public static final Set<String> SUPPORTED_METRICS = NAME_TO_IDX.keySet(); // 对外可请求的指标集合
private CounterSchema() {}
}
这是定制化的SDS结构,所有的参数如下图所示
5.核心功能实现:从用户点赞到显示全流程
上一节我们讲完了数据结构的设计,这一节我们着重于业务逻辑的设计。
我们要想实现高并发、幂等性、异常可恢复的计数模块,显然是不能让用户直接操作数据库的,因此这里设计了三层架构: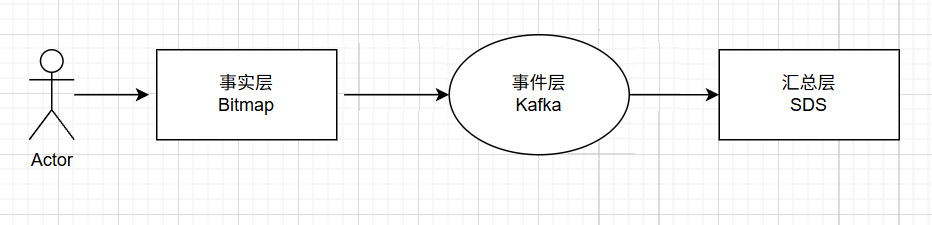
- 事实层:用户的点赞会直接操作事实层,基于Bitmap记录“谁给哪片帖子点赞了”,这是计数的原始数据;
- 事件层:状态产生变化后,发送 Kafka 事件异步通知计数更新,避免同步操作阻塞接口;
- 汇总层:汇总层先写入Redis聚合桶,每隔1s就将聚合桶内数据汇总写入SDS。
5.1 事实层
local bmKey = KEYS[1]
local offset = tonumber(ARGV[1])
local op = ARGV[2] -- 'add' or 'remove'
local prev = redis.call('GETBIT', bmKey, offset)
if op == 'add' then
if prev == 1 then return 0 end
redis.call('SETBIT', bmKey, offset, 1)
return 1
elseif op == 'remove' then
if prev == 0 then return 0 end
redis.call('SETBIT', bmKey, offset, 0)
return 1
end
return -1
""";
用户点赞或是取消赞时,我们用 Lua 脚本来保证 “查状态 + 改状态” 是一个原子操作。上面是Lua脚本的代码,它保证了幂等性,因为只有用户这一位产生了变化,才会去计数,这就确保了用户只能点赞一次,不会出现重复点赞的情况。
5.2 事件层
用户点赞完成后,我们并没有直接操作SDS,而是加了一层Kafka来优化,这是在高并发场景下的核心优化。
只有状态发生变化时,才会通过CounterEventProducer往 Kafka 发送一个 “计数增量事件”
Producer
/**
* 计数事件生产者。
*
* <p>职责:将业务产生的计数增量事件异步发送到 Kafka 主题,供聚合消费者处理。</p>
*/
@Service
public class CounterEventProducer {
private final KafkaTemplate<String, String> kafka;
private final ObjectMapper objectMapper;
public CounterEventProducer(KafkaTemplate<String, String> kafka, ObjectMapper objectMapper) {
this.kafka = kafka;
this.objectMapper = objectMapper;
}
/**
* 发布计数事件到 Kafka。
* @param event 计数事件(实体类型、ID、指标、delta 等)
*/
public void publish(CounterEvent event) {
try {
String payload = objectMapper.writeValueAsString(event);
kafka.send(CounterTopics.EVENTS, payload); // 异步写入计数事件主题(幂等生产已在配置启用)
} catch (JsonProcessingException e) {
// 生产异常不抛出影响主流程;可接入告警
}
}
}
比如用户给 id为100的knowpost点赞,发送的事件就是:entityType=knowpost, entityId=100, metric=like, idx=0, delta=1。
Consumer
CounterAggregationConsumer消费 Kafka 事件后,不会直接改汇总计数,而是先把增量写到Redis Hash 聚合桶(agg:schema:knowpost:123),等后续再写入
/**
* 消费计数事件并写入聚合桶。
* @param message 事件 JSON
* @param ack 位点确认对象(手动提交)
*/
@KafkaListener(topics = CounterTopics.EVENTS, groupId = "counter-agg")
public void onMessage(String message, Acknowledgment ack) throws Exception {
CounterEvent evt = objectMapper.readValue(message, CounterEvent.class);
String aggKey = CounterKeys.aggKey(evt.getEntityType(), evt.getEntityId());
String field = String.valueOf(evt.getIdx());
try {
// 将增量持久化到 Redis Hash
redis.opsForHash().increment(aggKey, field, evt.getDelta());
// 成功后提交位点,绑定“已持久化”语义
ack.acknowledge();
} catch (Exception ex) {
// 不提交位点以便重试
}
}
5.3 汇总层
Hash桶每隔一秒就会将记录的数据写入SDS,这样做的好处是:在高并发的场景下,也只需要 1 秒刷一次 SDS,而非每次操作都写,大幅降低 Redis 的写压力。
/**
* 将聚合增量刷写到 SDS 固定结构计数。
* 固定延迟 1s,保证秒级最终一致性。
*/
@Scheduled(fixedDelay = 1000L)
public void flush() {
// 简化实现:扫描所有聚合桶键(生产建议使用索引集合替代 KEYS)
Set<String> keys = redis.keys("agg:" + CounterSchema.SCHEMA_ID + ":*");
if (keys.isEmpty()) {
return;
}
for (String aggKey : keys) {
Map<Object, Object> entries = redis.opsForHash().entries(aggKey);
if (entries.isEmpty()) {
continue;
}
// 解析 etype/eid 以定位 SDS key
String[] parts = aggKey.split(":", 4); // agg:schema:etype:eid
if (parts.length < 4) {
continue;
}
String cntKey = CounterKeys.sdsKey(parts[2], parts[3]);
for (Map.Entry<Object, Object> e : entries.entrySet()) {
String field = String.valueOf(e.getKey());
// 增量
long delta;
try {
delta = Long.parseLong(String.valueOf(e.getValue()));
} catch (NumberFormatException nfe) {
continue;
}
if (delta == 0) continue;
int idx;
try {
idx = Integer.parseInt(field);
} catch (NumberFormatException nfe) {
continue;
}
try {
redis.execute(incrScript, List.of(cntKey),
String.valueOf(CounterSchema.SCHEMA_LEN),
String.valueOf(CounterSchema.FIELD_SIZE),
String.valueOf(idx),
String.valueOf(delta));
// 成功后删除该字段,避免重复加算
redis.opsForHash().delete(aggKey, field);
} catch (Exception ex) {
// 留存字段,下一轮重试
}
}
// 如 Hash 已为空,删除聚合桶Key
// 目的:降低键空间噪音,避免后续无效扫描
Long size = redis.opsForHash().size(aggKey);
if (size == 0L) {
redis.delete(aggKey);
}
}
}
6.高可用保证
设计完了这个计数模块还不够,我们还要考虑出了故障怎么办,这里我们设计了几个重要的兜底策略:
6.1 计数重建:基于位图恢复真实值
如果 SDS 里的汇总计数丢了,那么读取SDS的时候会发现为null,又或者是哪一位出故障了,这时候会触发 计数重建:
但是重建也不可能让所有线程去,因此这里还需要加分布式锁,用 Redisson 的 RLock 加锁。
此外还设置了限流 + 退避的策略,10 秒内最多重建 3 次,防止频繁重建;重建失败时,指数级增加下次重建的等待时间(从 500ms 到 30s 封顶),避免热点内容拖垮 Redis;
重建的过程就是重新进行位图统计,遍历该内容的所有位图分片,用 BITCOUNT 统计真实的点赞数,把统计结果写回 SDS,重置退避状态。
6.2 故障兜底:Kafka 事件回放
那你可能会问,Redis坏了咋办,那我们的Bitmap也丢了咋办?
虽然这种情况比较极端,但我们也应该做好预案,这里还有CounterRebuildConsumer:
消费者从 Kafka 的earliest位点回放所有历史事件,把历史事件的增量刷写到 SDS,重建所有计数,这是最后的数据恢复手段。
7.总结与展望
这个计数模块,看起来非常复杂,其实一共就三层:
- 用Bitmap存用户行为,作为事实层;
- 用 Kafka 异步解耦,避免主流程阻塞;
- 用 SDS 计数,保证查询快;
当然项目也存在一些可以优化的点,比如一篇帖子很多用户点赞,他们的id是不规律的,这就会产生很多的bitmap,但每一片bitmap其实并没有物尽其用,会造成一些资源的浪费。
这里我想到比较好的方法是用Roaring Bitmap来做优化,但没有具体实现,后续可能会做一下这方面的优化。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 7
7 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)