AI从南天门一直砍到蓬莱东路。
本文通过生动比喻讲述了AI技术对医疗行业的深刻变革。作者以"花果山十三太保"的段子开篇,形象描述了AI如同"砍刀"般快速取代人工岗位的过程。文中详细记录了2015年一个120人医疗编辑部门被AI系统取代的案例,以及当前正在推进的医疗编码AI项目。同时回溯了医疗转录行业20年发展历程,从早期Nuance语音识别到最新GPT应用,展现了AI技术如何通过提升效率、
引子
一个林志玲喜欢过的男人说过:
“知道我是谁不?花果山十三太保知道不?我就是老大!想当年,我手拿着两把西瓜刀,从南天门一直砍到蓬莱东路。来回砍了三天三夜,是血流成河。可我就是手起刀落手起刀落手起刀落篇愁墨,一眼都没眨过。”
故事的开始
在群里一个网友说:“程序员革命完自己,就要开始革命其它行业了”。俺就想起了一个林志玲喜欢过的男人说的那段话。于是俺和网友开始聊了起来。俺说:“俺觉得 很多年前,AI 在其他行业就是:从南天门一直砍到蓬莱东路。来回砍了三天三夜,是血流成河。”。
那个故事
俺在一个二线落后城市,2015年时候 ,单位就用一个“不复杂的程序 + 一些AI调用” 替代了一个 120人的部门 ,只留下了4个部门领导。
俺还记得 当时那个部门解散时,好几个人在 走廊里哭。她们的工作是可以在家远程上班的。她们是 医疗编辑 (就是电子病历的录入人员)。她们的日常工作就是 听 国外的医生的电话录音,然后整理成文档 ,大部分是电子病历,也有一些是法庭的文案。平时工作很忙,会排夜班,夜班12个小时 ,从晚上8点到第二天早上的8点。她们的英语水平一般是专业8级,还懂医疗。 收入也比 我们软件研发岗的收入高。她们是按照 工作量 计算工资的。有些手快的,收入是俺们的2倍。所以她们很在意这份工作。
单位里 ,工号用 '7' 开头的 都是AI或者程序,不是真人。从最开始的 '7777' 到现在的 '7789' 都是 AI 或者一段代码。每个新的 '7' 开头的工号的出现,就是一个部门 或者 一个分公司的 消失。这些 部门和分公司都不是 研发岗,一般是医疗编辑、文档、 翻译、 质检、 文员......。俺们单位在的这个小行业(医疗服务),不同公司之间就是拼价格,拼价格的核心就是降成本,降成本的关键就 AI 。这个行业从30年前就是这样。 在俺写的《基于语音识别的智能电子病历》一系列的博客里有介绍。
现在
这两年俺一直在做 AI Coding ,这个Coding 不是写软件代码 ,而是医疗编码。
背景:医疗编码员(Medical Coder) ,一般人3-6个月就可以拿下证书。工作内容就是查看病人的资料和病历等,给出疾病编码、诊疗编码等(例如 ICD10 i11.9 CPT 99214)。俺们单位目前有2000多位医疗编码员。 这个项目2025年 6月已经上线了。
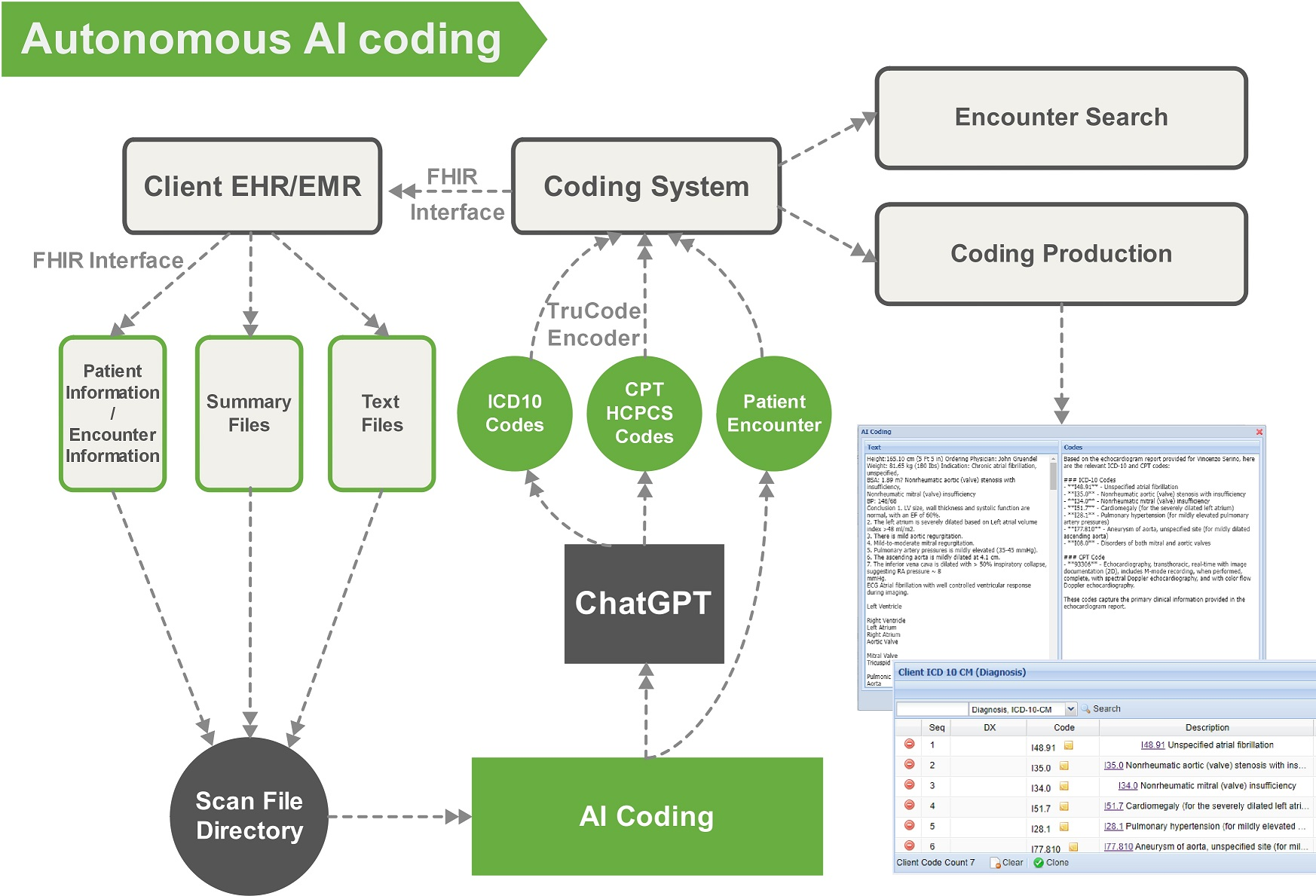
AI给出的结果,不同的颜色表示准确度不同。K44.9 是绿色的,表示这个编码AI的准确性>90%,如何让AI给出准确性,在俺的文章《AI人工智能的接入和使用》中有详细说明。如果结果全部是绿色的当做是最终结果,无须人工干预。如果有黄色的结果,就转到人工处理。
结束语
知道我是谁不?“人工智能 AI ” 知道不?我就是老大!想当年,我手拿着两把西瓜刀,从南天门一直砍到蓬莱东路。来回砍了三天三夜,是血流成河。可我就是手起刀落手起刀落手起刀落篇愁墨,一眼都没眨过。
另
人工智能在很多年前就医疗行业广泛使用
2000年,俺刚参加工作时,公司就在做这方面的应用。是一个医疗“转录”系统。先介绍一下具体背景:医生有着录不完那些电子病历(在美国一个外科医生,上完高中之后,最快要还要再读11年书才能拿下执照。学费接近80万美元。然后每天花费大量时间录入电子病历,就是坐在键盘前敲啊敲,医生会觉得是一种浪费)。这时候就形成了一个新的行业,就是“转录”行业。医生把要录入的内容录音到磁带中,交给“转录”公司,后来医生开始使用座机电话进行录音(拨打公司的服务电话即可)。公司安排人听录音进行录入。然后以每录入一行文字8美分到1毛的价格进行收费。
到了2003年左右,Nuance公司的Dragon语音识别引擎已经开始实用了。虽然这个时期的语音识别 引擎还是基于隐含马尔可夫链的。但是对于特定人群和特定行业,要比后来的非待定人群的深度神经网络的识别引擎的识别质量要好很多很多。实际上特定人群就是为每个医生创建特征库,那怕这个医生是墨西哥或者印度那种口音特别严重(叽里咕噜)的,因为针对每个医生都创建了特征库(Nuance的一个医生的特征库大约是 50-200M),所以识别质量还是不错的。这个时候我们公司就用了Nuance的引擎(离线版),然后用了大量服务器 搭建了自己的平台。这样我们公司的工作模式就改成了 对于医生的录音先识别语音,再人工检查修改(医疗报告要求内容准确,我们有多级质检)。这样大幅度提高了工作效率,降低了价格,然后更多的医生开始接受这种服务(主要是便宜了)。公司的也壮大了。就这段时间来看,是人工智能增加了工作机会。
2010年之后,又有很多语音识别引擎出现,例如Google 、微软、 Siri等等。但是这些大部分都是非待定人群的服务。俺一直在关注这方面的技术。过段时间就用真实的语音进行 质量比对。例如使用200份3-5分钟的录音,使用各种识别引擎进行识别。在对识别的结果进行比较。这些识别引擎的识别结果非常差。经常大段的缺失(一般是医生的声音忽大忽小,或者医生开始叽里咕噜,语速贼快),识别出的内容大部分不到Nuance特定人群识别的三分之一,对于一些医疗专业术语更是无法识别。不过这个时候出现了一个新人M*Modal,这小伙也是特定人群识别的识别。但是有两个的优点:
1、通过在不断的再训练提高识别质量
在完成了医生的报告之后,把完成好的报告和语音回传给M*Modal,M*Modal就会为这个医生再次训练模型。这样经过一段时间后,这个医生的语言识别的质量就非常好了。哪怕这个医生有很多单词的发音有问题,识别的结果也是正确的。另外M*Modal 也通过语义分析语法规则等等,对识别的结果再处理,特别是数字 日期 等的处理有很好的结果。
2、生成结构化的电子病历
M*Modal 基于语义分析,对识别的内容进行整理,对不同的段落进行归类标注 形成结构化的文档
通过这些优点,M*Modal 快速发展,成为医疗语音识别的第2大公司。第1还是Nuance。
这样“转录”服务的价格进一步下降,有些合同 每一行的价格只有5美分。更多的医院和医生开始使用这种服务。当时在印度有超过10万人从事这种工作(就是对识别后的内容进行检查和纠正)。
接下来这个行业基本就是 Nuance 和 M*Modal 两家公司的舞台。俺们公司使用了这2家公司的识别服务,但是太贵了。所以我们自己开发了一套自己的流水线,把一些没啥口音的医生放在我们自己的识别引擎上。这样一个月能够节省很多美元。为啥不用便宜的或者免费的。Google 、微软的是便宜,几乎没有成本,但是识别质量实在是不行,非待定人群的没法和特定人群识别的比质量。
后来 M*Modal 被3M收购了。Nuance被微软收购了。
在十几年中,语音识别在医疗中的使用确实是很多,也带来了几十万个新的工岗位。
百家争鸣
2018年之后,随着人工智能的发展,很多视觉领域的应用也在医疗行业上出现。例如医疗影像的辅助阅片。还有一些疾病的辅助诊断。之前遇接触一个从事皮肤疾病的人工智能公司。他们通过对皮肤拍照进行分析,从而得出可能的皮肤病,这对于一些基层医疗机构(乡镇医院)的医生有很多帮助。还有就是OCR,其实医疗行业上也有很多纸张资料需要处理。我写过的一个项目就是对病人的各种资料进行归类,经常有些扫描件需要处理。前一段时间,俺看到的统计数字是这个项目最近12个月处理了2.07亿页的资料。在语音识别方面, 2020年出现了一家新的公司Soniox,这家公司的医疗语音识别的质量很不错。当然还出现了很多很多其他的公司。但是质量比不过Soniox。原来的老大Nuance 被微软收购后,还是第一。
GPT的横空出世
GPT 来了 ,GPT真不错,GPT是个好同志。俺们也开始在一个项目上开始使用GPT了。还在对接中。这个项目其实是个Teams机器人,我们公司有个业务叫做医疗助手服务,其实就是给医生打下手。医生和我们公司的人在Microsoft Teams里进行网络会议,同时把我们的机器人也加入会议。会议结束后,俺们的Teams机器人就把会议的录音识别成文档,同时使用GPT做出会议摘要 。这里插一句,现在的复杂场景的语音识别很不错了,能够识别出 每句话是哪个人说的。需要上传每个人的特征语音,就是随便说几句话,然后识别引擎就记住这个人的声音。俺们另外的一个法庭录音处理的项目也是用了新的语音识别(就是上面说的Soniox)。
人工智能改变了或正在改变着很多行业的工作模式。分工也更加精细化,也带来了海量的工作岗位。在没有人工智能的时候,很多事情没法做或者太耗费人工。有了人工智能后,这些事情就变成了可行的方案,然后落地 、发展。
————————————————
版权声明:本文为CSDN博主「月巴月巴白勺合鸟月半」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/withcsharp2/article/details/134535737

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 21
21 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)