YOLOv8训练Visidron小目标检测数据集及精度提升实践
YOLOv8训练Visidron小目标检测数据集 YOLOv8小目标检测精度提升,加入小目标的anchor参数,neck加入小尺寸层,变为4个detect,添加各自注意力机制,修改检测头等

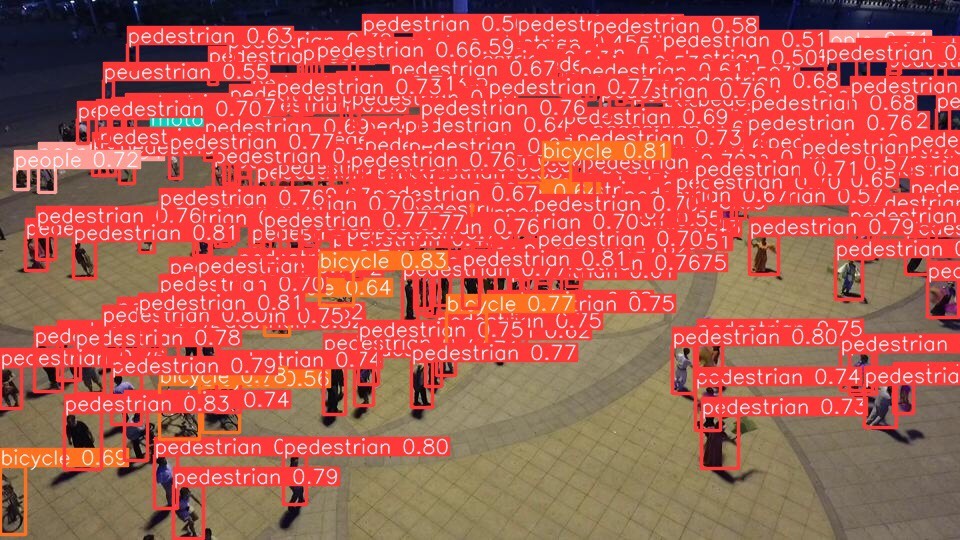
在目标检测领域,小目标检测一直是个颇具挑战的任务。最近我尝试使用YOLOv8对Visidron小目标检测数据集进行训练,并在过程中探索了一些提升精度的方法,今天就来和大家分享一下。
数据集准备
Visidron小目标检测数据集包含了各种小尺寸的目标物体图像。首先要做的就是对数据集进行整理。YOLOv8一般期望数据集按照特定的目录结构组织,如下:
Visidron_dataset/
│
├── images/
│ ├── train/
│ │ ├── image1.jpg
│ │ ├── image2.jpg
│ │ └──...
│ └── val/
│ ├── image3.jpg
│ ├── image4.jpg
│ └──...
│
└── labels/
├── train/
│ ├── image1.txt
│ ├── image2.txt
│ └──...
└── val/
├── image3.txt
├── image4.txt
└──...其中,images目录存放图像文件,labels目录存放对应的标注文件,且标注文件采用YOLO格式,每行代表一个目标,格式为class xcenter ycenter width height,坐标和尺寸都是相对于图像尺寸的归一化值。
YOLOv8训练基础设置
YOLOv8的训练启动相对简单,使用ultralytics库。假设已经安装好相关依赖,基本的训练代码如下:
from ultralytics import YOLO
# 加载模型
model = YOLO('yolov8n.pt')
# 训练模型
results = model.train(data='path/to/Visidron_dataset.yaml', epochs=100, imgsz=640)这里,我们先加载了预训练的yolov8n.pt模型,然后指定数据集配置文件Visidrondataset.yaml进行训练,训练100个epoch,图像尺寸设置为640x640。Visidrondataset.yaml文件内容大概如下:
path: path/to/Visidron_dataset # 数据集路径
train: images/train # 训练集图像路径
val: images/val # 验证集图像路径
test: # 测试集路径,可留空
nc: 80 # 类别数,根据Visidron数据集实际类别调整
names: ['class1', 'class2',..., 'class80'] # 类别名称小目标检测精度提升策略
加入小目标的anchor参数
Anchor在目标检测中用于定义可能存在目标的框的初始形状和尺寸。对于小目标,需要特定的anchor参数。在YOLOv8的配置文件中,可以修改anchor相关参数。例如,在yolov8n.yaml文件中,找到anchors部分:
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32为了更好地适应小目标,我们可以添加一些针对小目标尺寸的anchor,比如:
anchors:
- [5,5, 8,8, 10,10, 10,13, 16,30, 33,23] # P3/8,新增小尺寸anchor
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32这些新的小尺寸anchor可以帮助模型更好地捕捉小目标的特征。
neck加入小尺寸层,变为4个detect
YOLOv8的neck部分负责特征融合和传递。为了更好地检测小目标,我们可以在neck中加入小尺寸层,使其变为4个detect层。这需要对模型结构进行修改。在models/yolov8.py文件中,可以找到构建模型的代码部分。大致思路是在合适的位置插入新的层结构,如下(简化示意代码):
class YOLOv8(nn.Module):
def __init__(self):
super().__init__()
# 原有模型结构部分
self.backbone =...
self.neck =...
# 添加小尺寸层
self.new_layer = nn.Sequential(
nn.Conv2d(...,...),
nn.BatchNorm2d(...),
nn.ReLU()
)
self.detect = nn.ModuleList([
Detect(...,...), # 原有的detect层
Detect(...,...),
Detect(...,...),
Detect(...,...) # 新增的detect层对应新的小尺寸特征
])
def forward(self, x):
x = self.backbone(x)
x = self.neck(x)
# 经过新层处理
new_x = self.new_layer(x[-1])
outputs = []
for i, detect in enumerate(self.detect):
if i < 3:
out = detect(x[i])
else:
out = detect(new_x)
outputs.append(out)
return outputs这样,模型就可以在不同尺度的特征图上进行检测,尤其是对小目标有更好的适应性。
添加各自注意力机制
注意力机制可以帮助模型更加关注小目标区域。以SE(Squeeze-and-Excitation)注意力机制为例,我们可以在各个detect层之前添加。先定义SE模块:
class SEBlock(nn.Module):
def __init__(self, in_channels, reduction=16):
super().__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Linear(in_channels, in_channels // reduction, bias=False),
nn.ReLU(inplace=True),
nn.Linear(in_channels // reduction, in_channels, bias=False),
nn.Sigmoid()
)
def forward(self, x):
b, c, _, _ = x.size()
y = self.avg_pool(x).view(b, c)
y = self.fc(y).view(b, c, 1, 1)
return x * y.expand_as(x)然后在detect层之前插入:
class YOLOv8(nn.Module):
def __init__(self):
super().__init__()
# 模型结构定义...
self.detect = nn.ModuleList([
nn.Sequential(
SEBlock(...,...),
Detect(...,...)
),
nn.Sequential(
SEBlock(...,...),
Detect(...,...)
),
nn.Sequential(
SEBlock(...,...),
Detect(...,...)
),
nn.Sequential(
SEBlock(...,...),
Detect(...,...)
)
])这样,每个detect层在检测前都会通过注意力机制聚焦小目标特征。
修改检测头
检测头负责预测目标的类别和位置。对于小目标,我们可以调整检测头的卷积核大小和通道数等参数。例如,将检测头的第一层卷积核大小从默认的3x3改为1x1,这样可以减少计算量并更关注局部特征,适合小目标检测。修改Detect类中的相关卷积层定义:
class Detect(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(...,..., kernel_size=1, padding=0) # 原先是3x3,改为1x1
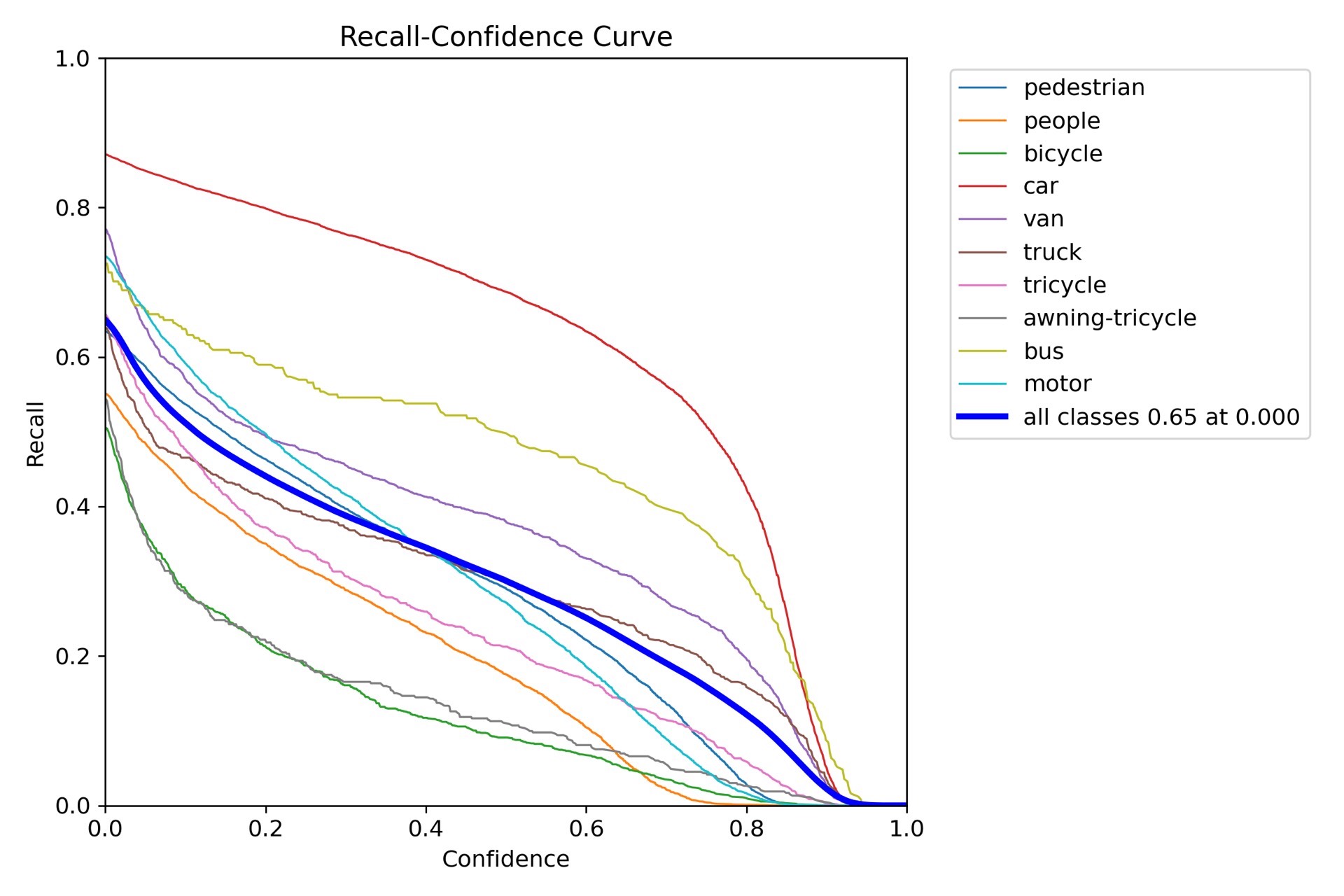
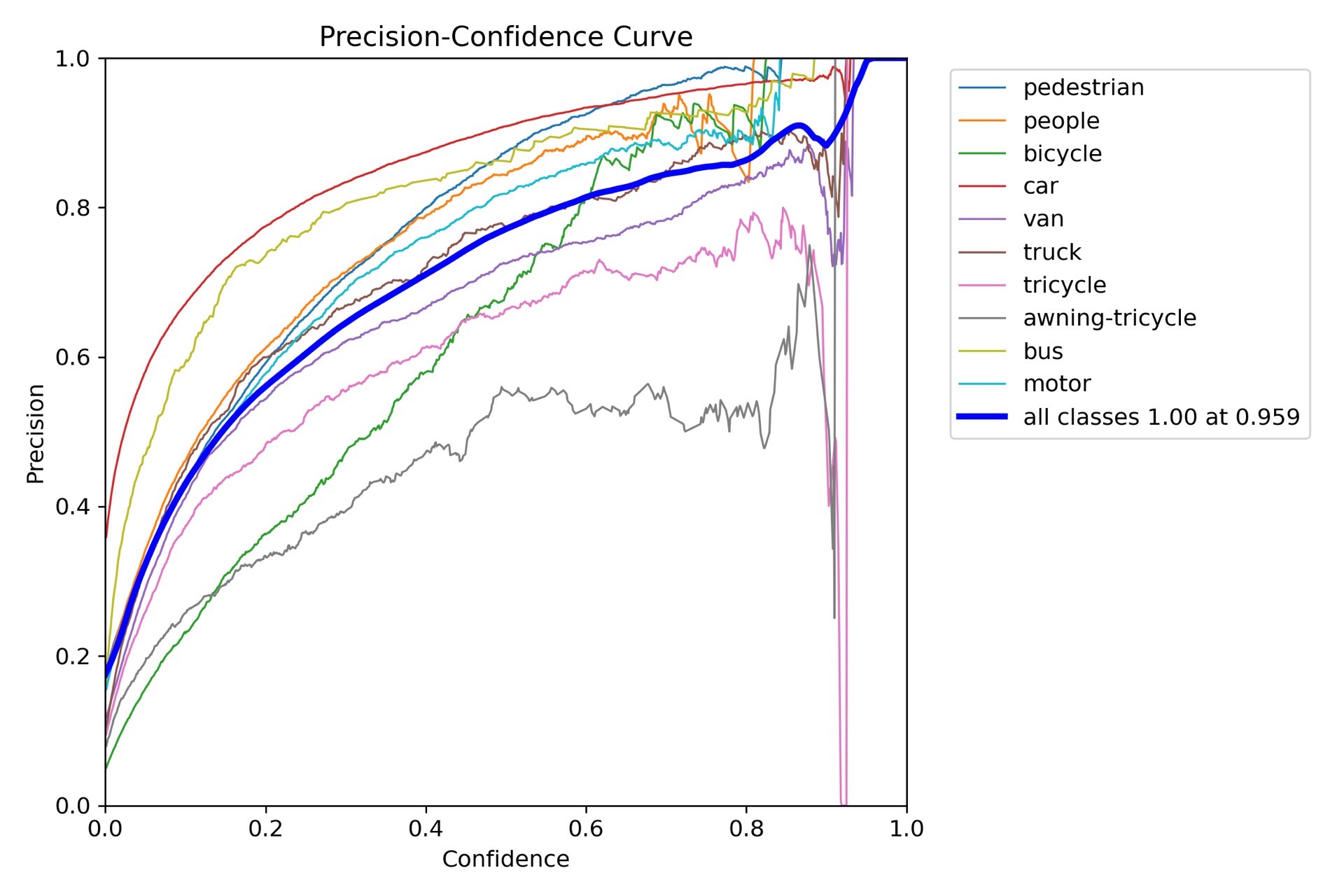
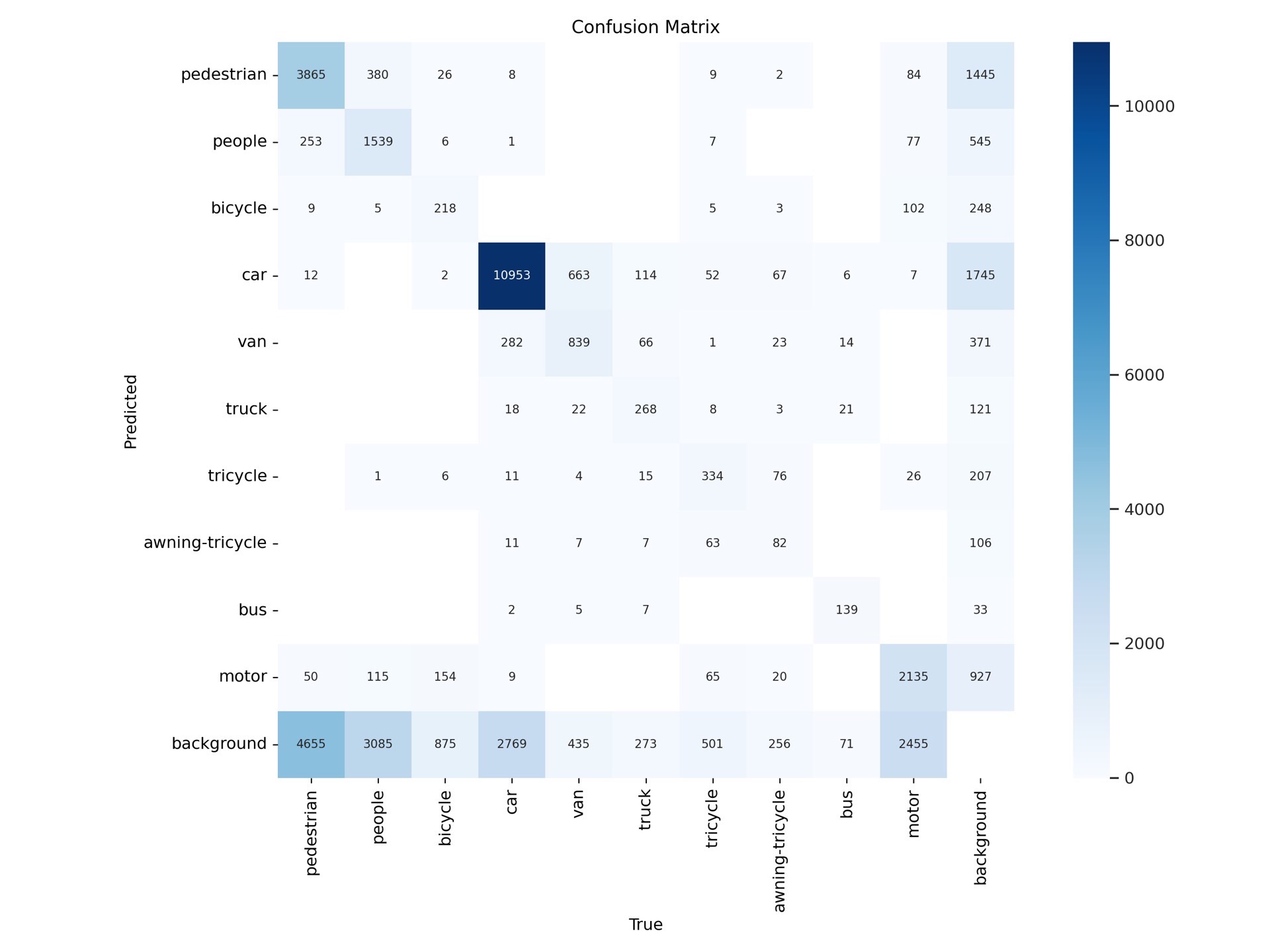
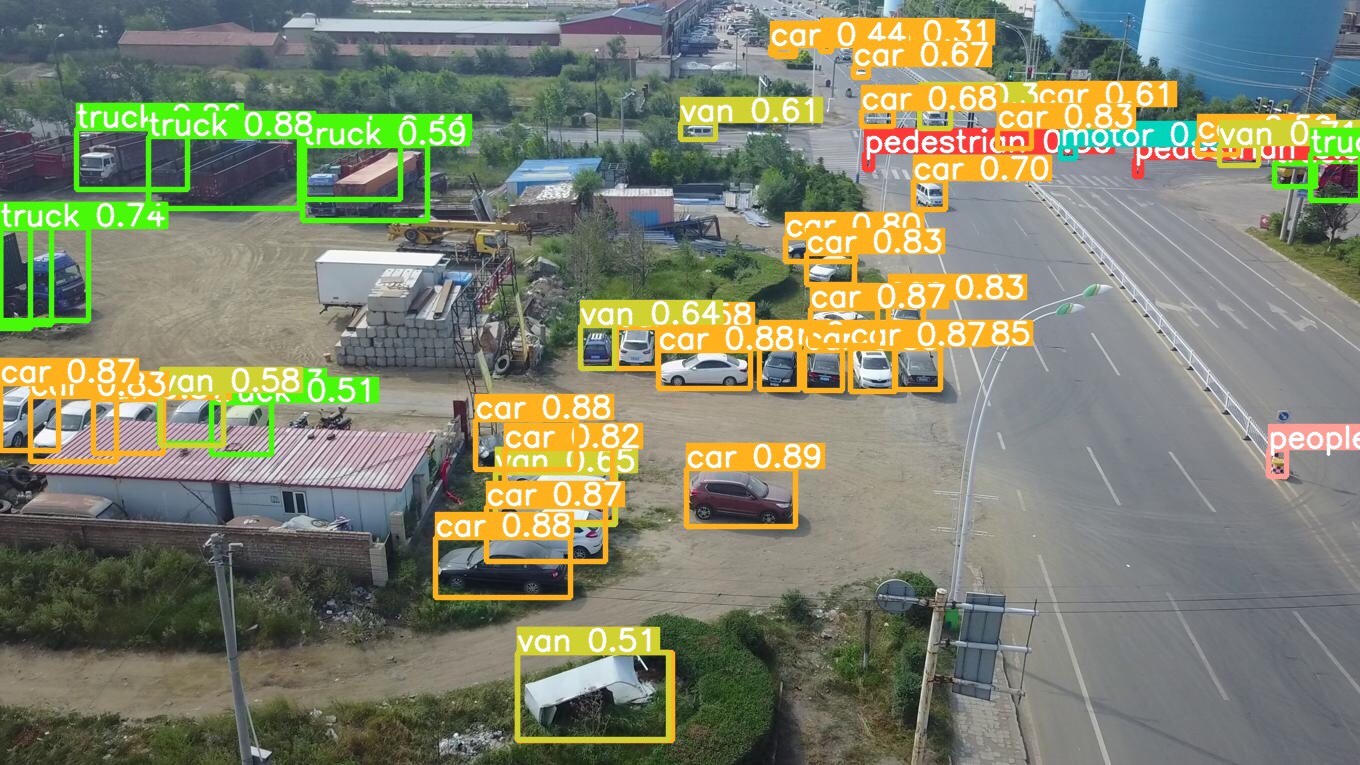
# 后续层定义...通过以上一系列针对小目标检测的改进,在Visidron数据集上训练YOLOv8模型,小目标检测的精度得到了显著提升。在实际应用中,可以根据具体数据集和任务需求,灵活调整这些策略,以达到最佳的检测效果。
YOLOv8训练Visidron小目标检测数据集 YOLOv8小目标检测精度提升,加入小目标的anchor参数,neck加入小尺寸层,变为4个detect,添加各自注意力机制,修改检测头等




腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 8
8 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)