从零实现 Agent Skills:给 AI 智能体装上可插拔的“技能包“
Agent Skills 说白了就是"带加载机制的结构化提示词",听起来朴素,但真正用起来,解决的都是做智能体时最烦的那些问题——上下文膨胀、主提示词越改越乱、不同场景相互打架、调试全靠盲猜。完整实现不到两百行 Python,一个下午就能跑起来。建议先写一个技能试试水,感觉顺手了再逐步扩展。有些看起来很花哨的架构,其实核心就是把常识性的工程思路——按需加载、关注点分离、模块化——老老实实落到 Pr
从零实现 Agent Skills:给 AI 智能体装上可插拔的"技能包"
大家构建智能体应用的时候或多或少会有个烦恼:系统提示词越写越长,什么代码审查、Git 操作、文件整理、API 测试……全往里塞,最后一个 Prompt 两千多行,跑一次烧一堆 token 不说,模型还经常抓不住重点,东一榔头西一棒子。
最近在调研智能体Skill实现方式,才算找到一个比较优雅的解法。网上讲概念的文章一大把,但真正动手实现的不多,所以这篇就来把底层原理和代码实现一次性讲清楚,文末会附上完整的一套最小可用实现,130 行 Python 左右就能跑起来。

完整代码可以参考:https://github.com/onlyoneaman/agent-skills/tree/main
Agent Skills 到底解决了啥问题
举个例子,假设现在要做一个全能型的开发助手,传统写法大概是这样:
你是一个全能开发助手,擅长代码审查、Git 操作、文件整理、API 测试……
[后面跟着两千行的详细指令]
这种写法的问题非常明显。一是上下文被塞得满满当当,真正的用户输入反而挤不进去;二是每次调用都要把所有指令传一遍,哪怕这次对话只是想让模型帮忙写个 commit message,你也得把代码审查的规则一起喂给它,token 花得心疼;三是调试起来极其痛苦,模型到底是按哪段指令在回答,基本靠猜。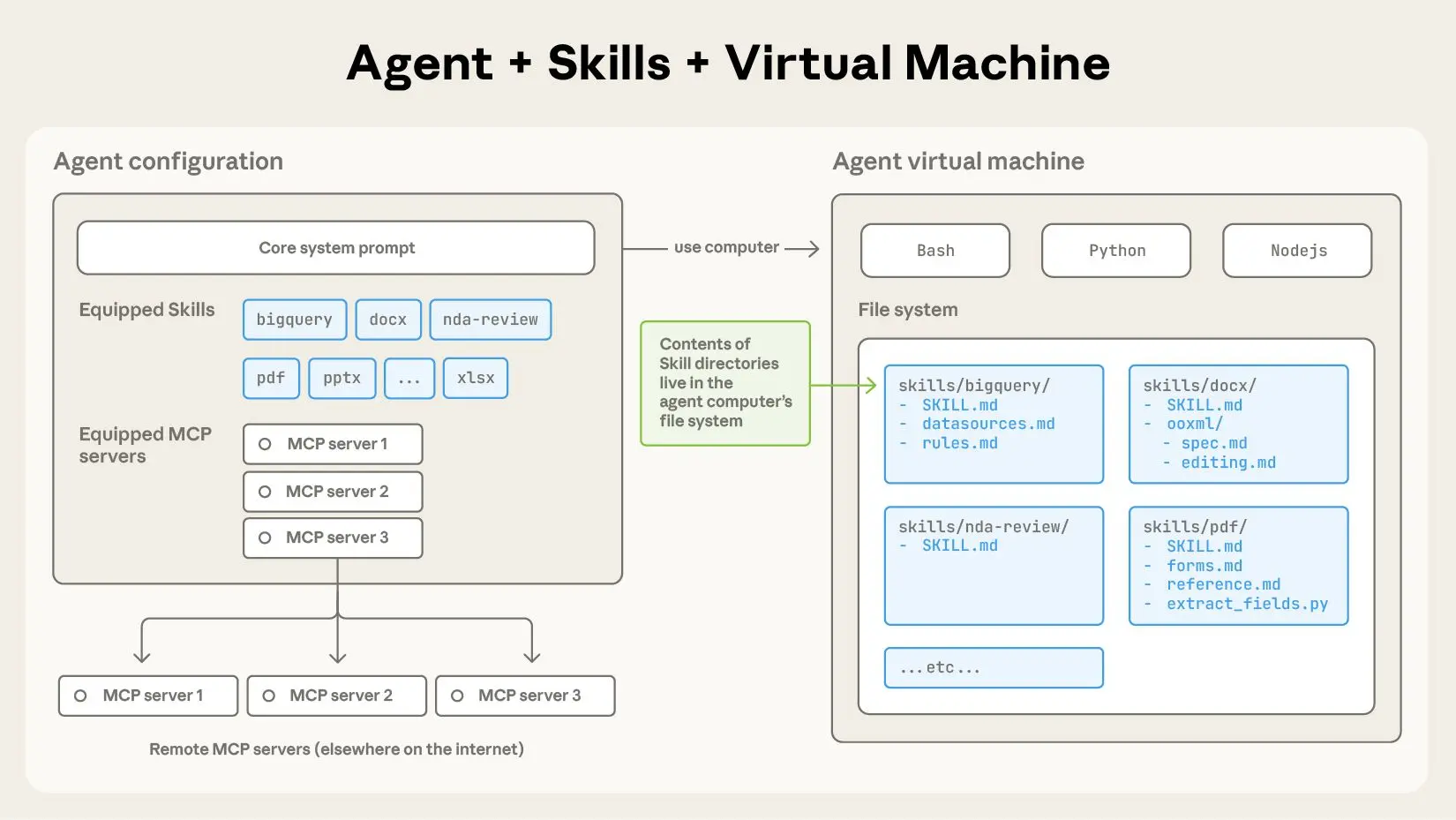
Skills 的思路换了个角度:别一次性把所有能力都告诉模型,而是给它一份"菜单",需要哪个技能再现场加载哪个。
你可以调用以下技能:
- code-review: 代码审查,检查 bug 和安全问题
- git-helper: Git 工作流和故障排查
- file-organizer: 智能文件整理
- api-tester: REST API 测试
需要时再加载对应技能。
这样一来,启动时只加载几百字节的元数据,真正用到某个技能的时候才把完整指令拉进来。核心思想其实一句话就能说清——技能就是结构化的、按需加载的提示词模板。
一个 Skill 长什么样
每个 skill 本质上就是一个放在独立目录里的 SKILL.md 文件,由两部分组成:YAML frontmatter 写元数据,下面的 Markdown 正文写详细指令。
以代码审查技能为例:
---
name: code-review
description: 审查代码,检查 bug、安全问题和最佳实践
version: 1.0.0
---
# 代码审查技能
你是一名资深代码审查员。
## 重点关注
1. **安全性**
- SQL 注入
- XSS 攻击
- 鉴权绕过
2. **代码质量**
- 可读性
- 可维护性
- DRY 原则
3. **性能**
- N+1 查询
- 内存泄漏
- 低效算法
## 输出格式
**总结**:整体评估
**关键问题**:安全相关(如有)
**改进建议**:优化建议
**亮点**:做得好的地方
另外最近写了很多数据分析的算子,把它转换为Skill了,大致内容如下: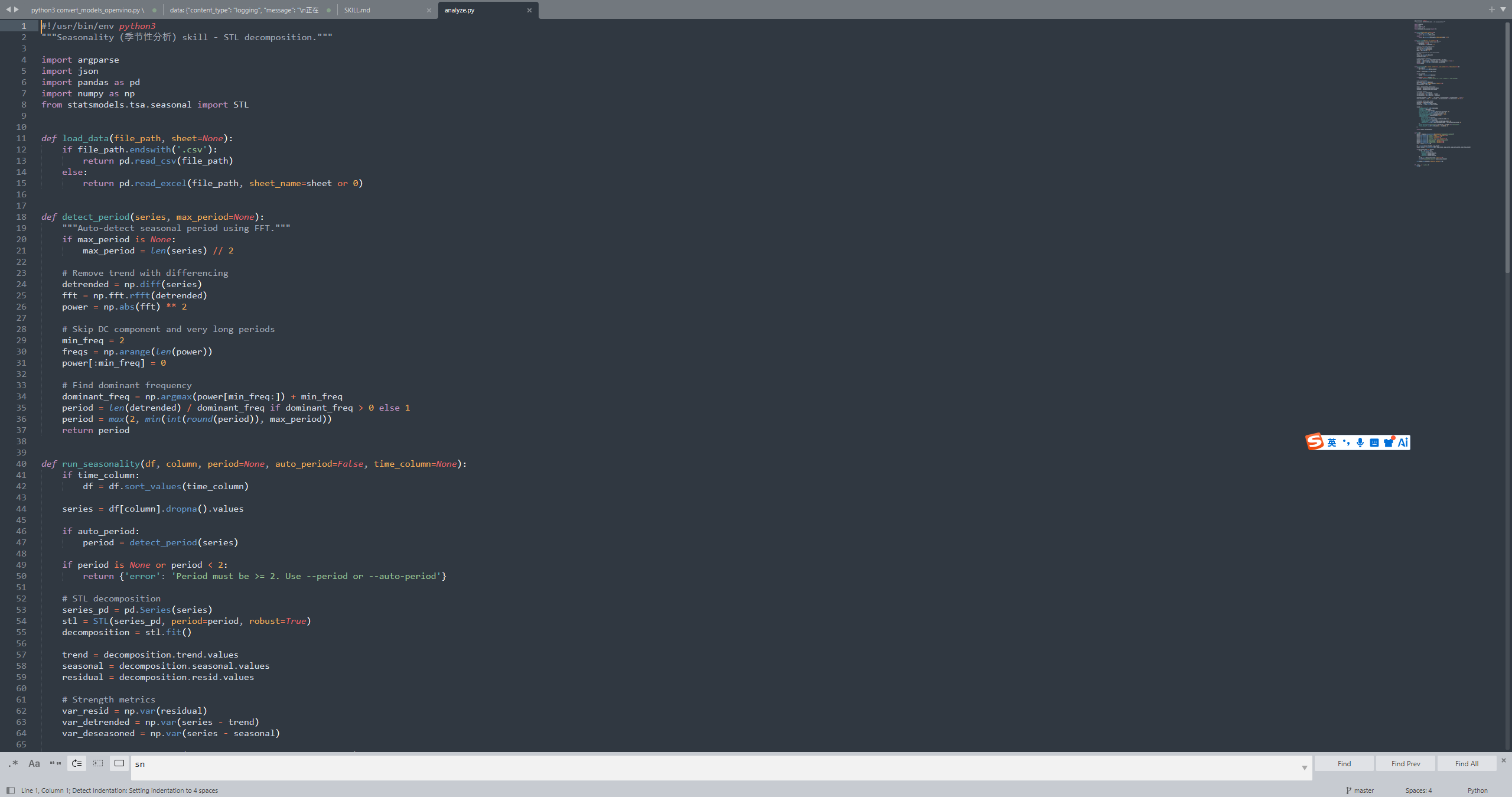
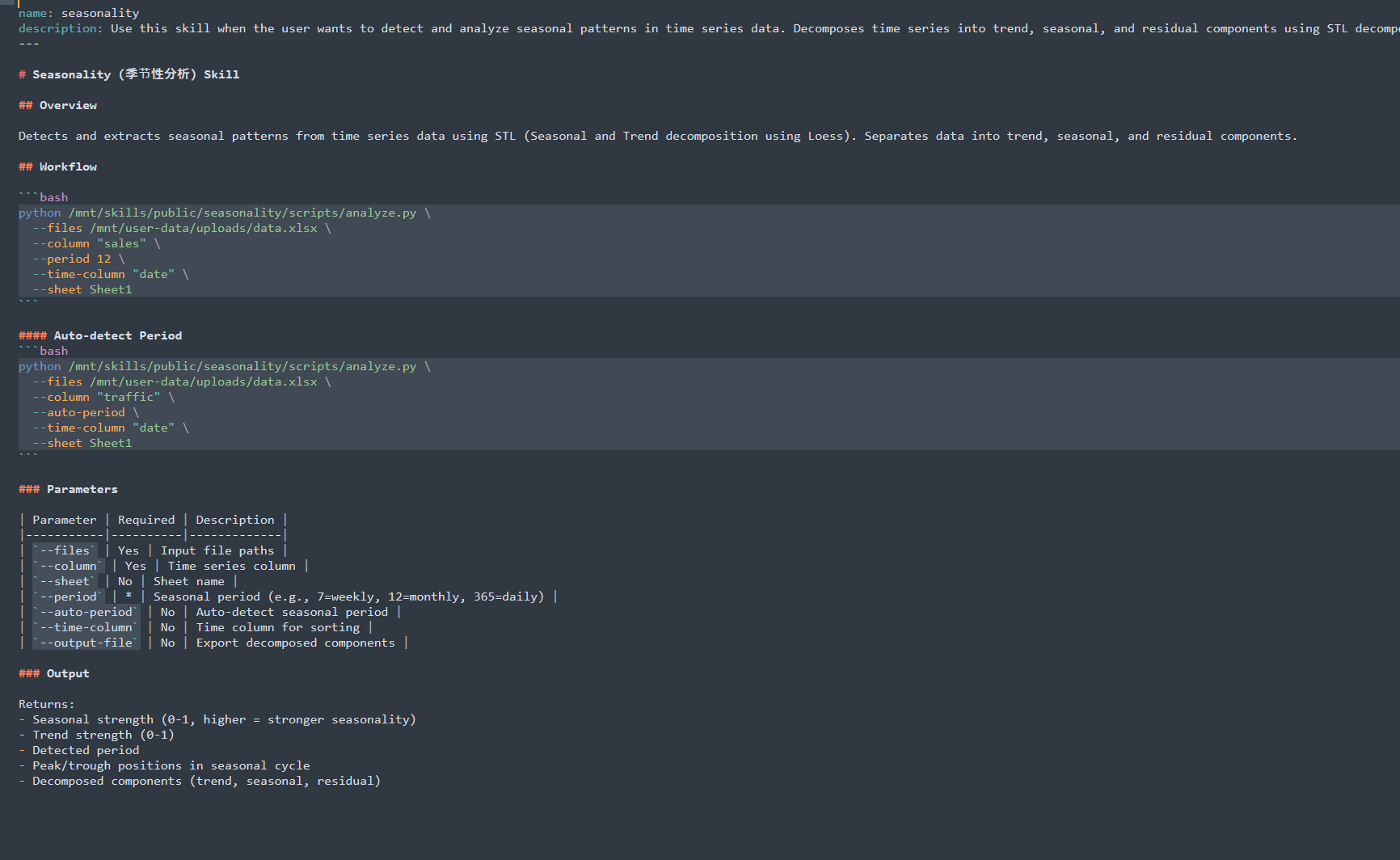
这里有个小经验:结构化的指令比大段散文管用得多。清晰的小标题、列表、预期输出格式,模型跟着走的依从度会高一个档次。要是写成一整段话糊脸上,模型大概率会选择性失忆。
目录结构也很简单,每个技能一个子目录:
skills/
├── code-review/
│ └── SKILL.md
├── git-helper/
│ └── SKILL.md
├── file-organizer/
│ └── SKILL.md
└── api-tester/
└── SKILL.md
底层到底是怎么跑起来的
整个流程可以拆成四步,理解了这四步,自己撸一个也就是一下午的事。
第一步:发现(Discovery)
启动时扫描 skills 目录,找所有 SKILL.md,但只解析 frontmatter,正文不读。这一步的关键在于"只拿元数据"——拿到 name 和 description 就行,完整内容先留在磁盘上躺着。
def _discover_skills(self):
if not self.skills_directory.exists():
return
for item in self.skills_directory.iterdir():
if item.is_dir():
skill_file = item / "SKILL.md"
if skill_file.exists():
skill = self._parse_skill(skill_file, item)
self.skills[skill.name] = skill
这里有个容易踩的坑:不少人图省事,直接在启动时把所有 SKILL.md 全读进内存。这就完全背离了 Skills 的初衷——等于又回到一次性加载所有指令的老路,白忙活一场。元数据是元数据,正文是正文,必须分开处理。
第二步:工具注册(Tool Registration)
把每个 skill 转成一个 OpenAI function call 工具暴露给模型。模型看到的是一组可调用的函数:
def get_skill_tools(self) -> List[Dict]:
tools = []
for skill in self.skills.values():
tool = {
"type": "function",
"function": {
"name": f"activate_skill_{skill.name.replace('-', '_')}",
"description": f"激活 {skill.name} 技能。{skill.description}",
"parameters": {
"type": "object",
"properties": {
"context": {
"type": "string",
"description": "任务上下文"
}
},
"required": ["context"]
}
}
}
tools.append(tool)
return tools
这里 description 字段极其关键,因为模型就是靠这行字判断"这个任务该激活哪个技能"。写得糊弄,模型就选得糊弄。
反例:“帮助写代码” ——这描述等于没写。
正例:“审查 Python/JavaScript 代码,检查安全漏洞、PEP 8 规范和性能问题” ——该覆盖的场景一目了然。
另外函数命名建议统一加前缀 activate_skill_,调试的时候看日志一眼就知道发生了啥。
第三步:激活(Activation)
当模型决定要用某个技能,它会调用对应的 function。这时候才去把完整的 SKILL.md 读进来,作为 tool 的返回结果塞回对话里:
def activate_skill(self, skill_name: str) -> Optional[str]:
skill = self.skills.get(skill_name)
if skill:
return skill.load_full_content()
return None
这就是懒加载。有 20 个技能,但这次对话只用到了 2 个,就只读了 2 个文件的内容进上下文。token 账单能肉眼可见地变薄。
第四步:执行(Execution)
模型拿到技能指令后,就按着走。这个技能在当次任务里相当于一个临时的 system prompt,任务做完,如果不是多轮对话,这段内容就自然淡出上下文了。
对话流程里最容易翻车的地方
这里单独拎出来说,因为很多人卡在这一步。完整的一轮对话顺序是这样的:
- 用户发消息
- 模型返回带
tool_calls的响应(说要用某个技能) - 把带 tool_calls 的 assistant 消息加进对话历史(关键步骤)
- 把技能内容作为 tool 角色的消息加进去
- 模型基于技能指令继续生成
- 返回最终答复
第 3 步特别容易漏。漏了之后 OpenAI 会直接甩你一个报错,类似这样:
Error: Missing required parameter: messages[1].tool_calls[0].type
报错的根本原因是 tool_calls 的结构必须严格按嵌套格式来,不能平铺:
# 正确格式
{
"id": "call_xxx",
"type": "function", # 这个 type 字段不能少
"function": { # function 字段要嵌套
"name": "activate_skill_code_review",
"arguments": "{...}"
}
}
另一个常见翻车点是:技能激活后继续调用模型时,忘了再把 tools 参数传进去。一旦忘了,模型在执行技能指令的过程中就没法再调用其他工具(比如代码执行),技能的能力就瘸了半边。所以每次调模型,tools 参数都得带上。
多轮工具调用:要写成循环
技能是可以链式触发的。比如 api-tester 这个技能被激活后,它自己还要调 execute_python 去实际发 HTTP 请求。所以整个处理逻辑必须是个循环,直到某一轮模型不再返回 tool_calls 为止:
max_iterations = 10 # 防止死循环兜底
iteration = 0
while iteration < max_iterations:
iteration += 1
response = self.llm_client.chat(
messages=self.messages,
tools=tools if tools else None # 每次都要传
)
if response["tool_calls"]:
self._handle_tool_calls(response)
continue # 继续下一轮,处理 tool 结果
break # 没 tool call 了,拿到最终回复
那个 max_iterations 的兜底很有必要。偶尔模型会抽风循环调用,没有这个保险丝,你的 API 账单可能会变得很精彩。
一个可以直接跑的完整实现
把上面的逻辑拼起来,核心的 SkillsManager 类大概长这样:
import yaml
from pathlib import Path
from typing import Dict, List, Optional
from dataclasses import dataclass
@dataclass
class Skill:
name: str
description: str
path: Path
content: Optional[str] = None
metadata: Optional[Dict] = None
def load_full_content(self) -> str:
if self.content is None:
skill_file = self.path / "SKILL.md"
with open(skill_file, 'r', encoding='utf-8') as f:
self.content = f.read()
return self.content
class SkillsManager:
def __init__(self, skills_directory: str = "skills"):
self.skills_directory = Path(skills_directory)
self.skills: Dict[str, Skill] = {}
self._discover_skills()
def _discover_skills(self):
if not self.skills_directory.exists():
return
for item in self.skills_directory.iterdir():
if item.is_dir():
skill_file = item / "SKILL.md"
if skill_file.exists():
try:
skill = self._parse_skill(skill_file, item)
self.skills[skill.name] = skill
except Exception as e:
print(f"加载技能失败 {item}: {e}")
def _parse_skill(self, skill_file: Path, skill_dir: Path) -> Skill:
with open(skill_file, 'r', encoding='utf-8') as f:
content = f.read()
metadata = {}
if content.startswith('---'):
parts = content.split('---', 2)
if len(parts) >= 3:
try:
metadata = yaml.safe_load(parts[1])
except yaml.YAMLError as e:
print(f"frontmatter 解析失败: {e}")
return Skill(
name=metadata.get('name', skill_dir.name),
description=metadata.get('description', '无描述'),
path=skill_dir,
metadata=metadata
)
def activate_skill(self, skill_name: str) -> Optional[str]:
skill = self.skills.get(skill_name)
if skill:
return skill.load_full_content()
return None
工具处理那一坨,重点在于把每种 tool_call 分别处理,技能调用走 activate_skill_ 分支,代码执行走 execute_python 分支:
def _handle_tool_calls(self, response: Dict):
# 第 3 步:先把 assistant 的 tool_calls 消息加进去
self.messages.append({
"role": "assistant",
"tool_calls": response["tool_calls"],
"content": response.get("content")
})
for tc in response["tool_calls"]:
tool_name = tc["function"]["name"]
if tool_name == "execute_python":
args = json.loads(tc["function"]["arguments"])
result = self.code_executor.execute(args.get("code", ""))
tool_result = f"执行成功\n输出:\n{result['output']}" if result["success"] \
else f"执行失败\n错误:\n{result['error']}"
elif tool_name.startswith("activate_skill_"):
skill_name = tool_name.replace("activate_skill_", "").replace("_", "-")
skill_content = self.skills_manager.activate_skill(skill_name)
tool_result = f"技能 '{skill_name}' 已激活,请按以下指令执行:\n\n{skill_content}" \
if skill_content else f"错误:找不到技能 '{skill_name}'"
else:
tool_result = f"错误:未知工具 '{tool_name}'"
self.messages.append({
"role": "tool",
"tool_call_id": tc["id"],
"content": tool_result
})
这套模式为什么值得用
用下来之后,感受最明显的是几个点。
上下文清爽了。以前一股脑塞两千行指令,现在启动只加载几百字节的元数据,用到啥加载啥。token 账单直接腰斩不夸张。
模块化做得很干净。加个新技能不用改任何代码,丢一个 SKILL.md 进去就完事。不想要了就删目录。以前那种动不动就要改主提示词的痛苦一下就没了。
调试简单了一大截。日志里明晃晃写着"激活了 git-helper 技能",一眼就能看出模型当前是按哪套规则在动作。以前那种大块头提示词,出了问题基本靠瞪眼猜。
复用价值很高。别人写的 api-tester 技能,直接拷过来就能用,零修改。相当于给智能体建了一个共享的能力库,慢慢就能攒出一套自己的"工具箱"。
啥时候别用这套
这东西挺好,但不是银弹。如果就做个单一用途的小工具,系统提示词只有几十行,上 Skills 反而是杀鸡用牛刀,增加了没必要的复杂度。
适合用 Skills 的场景,大致是这几类:多领域的通用型智能体,需要覆盖代码、Git、运维、测试等多个场景;有一堆专门化工作流需要分门别类管理;团队里要沉淀共享能力;或者系统提示词已经撑爆上下文窗口,再不拆就要出事。
没必要用的场景也很明确:目的单纯的智能体;提示词规模还很小、维护得过来;或者就是个临时的原型和实验。
常见坑位清单
过一遍容易翻车的几个点:
坑一:启动就把所有技能加载到内存。直接把 Skills 的价值清零,记得只读 frontmatter。
坑二:描述写得太虚。"帮助处理代码"这种描述,模型根本不知道该啥时候调。得写具体:做啥、适用哪类任务、核心能力有哪些。
坑三:tool_calls 格式不对。那个 type: "function" 和嵌套的 function 对象,该怎么嵌套怎么嵌套,别自作主张扁平化。
坑四:技能激活后调模型忘了传 tools。技能可能还要调其他工具,每一次 LLM 调用都得把 tools 带上。
坑五:技能里全是大段散文。模型对结构化指令的依从度比散文高得多,多用小标题、列表、示例、明确的输出格式。
坑六:技能粒度没把握好。一个技能对应一个领域,code-review、git-helper、api-tester 都是好例子。像 developer-tools 这种,范围太大了,模型根本选不准。
上手做个自己的
实际操作非常简单,三步就能搞定:
mkdir -p skills/my-skill
目录结构可以如下:
Folder Structure
your-skill-name/
├── SKILL.md # Required: instructions + metadata
├── scripts/ # Optional: executable code
├── references/ # Optional: documentation
└── assets/ # Optional: templates, resources
创建 skills/my-skill/SKILL.md:
---
name: my-skill
description: 这个技能具体做什么
version: 1.0.0
---
# 我的技能
你是 [某领域] 的专家。
## 指引
1. 第一步
2. 第二步
3. 第三步
## 示例
展示这个技能如何发挥作用的具体例子。
比如pdf解析的技能可以写成:
---
name: pdf-processing
description: Extracts text from PDF files using PyPDF2.
---
# PDF Processing Skill
## When to use this skill
Use this skill when a user needs to extract text from a PDF file.
## How to Use this Skill
This skill provides the `extract_text()` function from the `parse_pdf.py` script. Import it into your agent script:
python
from skills.pdf_parsing.parse_pdf import extract_text
result = extract_text(
file_path="/path/to/document.pdf",
pages="all" # or "1-3" or "1,2,3"
)
### Parameters
- `file_path` (str): Path to the PDF file
- `pages` (str): Pages to extract - "all", "1-3" (range), or "1,2,3" (specific pages)
### Returns
JSON object with:
- `success` (bool): Whether extraction succeeded
- `file_path` (str): Path to the processed file
- `total_pages` (int): Total pages in PDF
- `extracted_pages` (int): Number of pages extracted
- `pages` (list): Array of {page: number, text: string} objects
Alternatively, you can call the script directly from the command line:
command
python skills/pdf-parsing/parse_pdf.py extract_text --file_path /path/to/file.pdf --pages all
丢进去就行,SkillsManager 自动发现。啥代码都不用改。
写在最后
Agent Skills 说白了就是"带加载机制的结构化提示词",听起来朴素,但真正用起来,解决的都是做智能体时最烦的那些问题——上下文膨胀、主提示词越改越乱、不同场景相互打架、调试全靠盲猜。
完整实现不到两百行 Python,一个下午就能跑起来。建议先写一个技能试试水,感觉顺手了再逐步扩展。有些看起来很花哨的架构,其实核心就是把常识性的工程思路——按需加载、关注点分离、模块化——老老实实落到 Prompt 工程里而已。
顺便一提,AgentSkills.io 是这个格式的开放标准,SKILL.md 命名、frontmatter schema、目录结构、最佳实践都定好了。按标准来,写出来的技能可以跨项目复用,甚至用到别人家的智能体里也能直接跑,这点属实香。
参考资源:
- AgentSkills.io — 官方标准
- Claude Skills — Anthropic 的官方技能示例
- Open Agent Skills — 社区技能库
- 完整实现代码 — 本文所有代码都在这

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 6
6 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)