基于YOLOv5和PyTorch的口罩检测系统搭建之旅
基于YOLOv5的口罩检测系统,pytorch开发
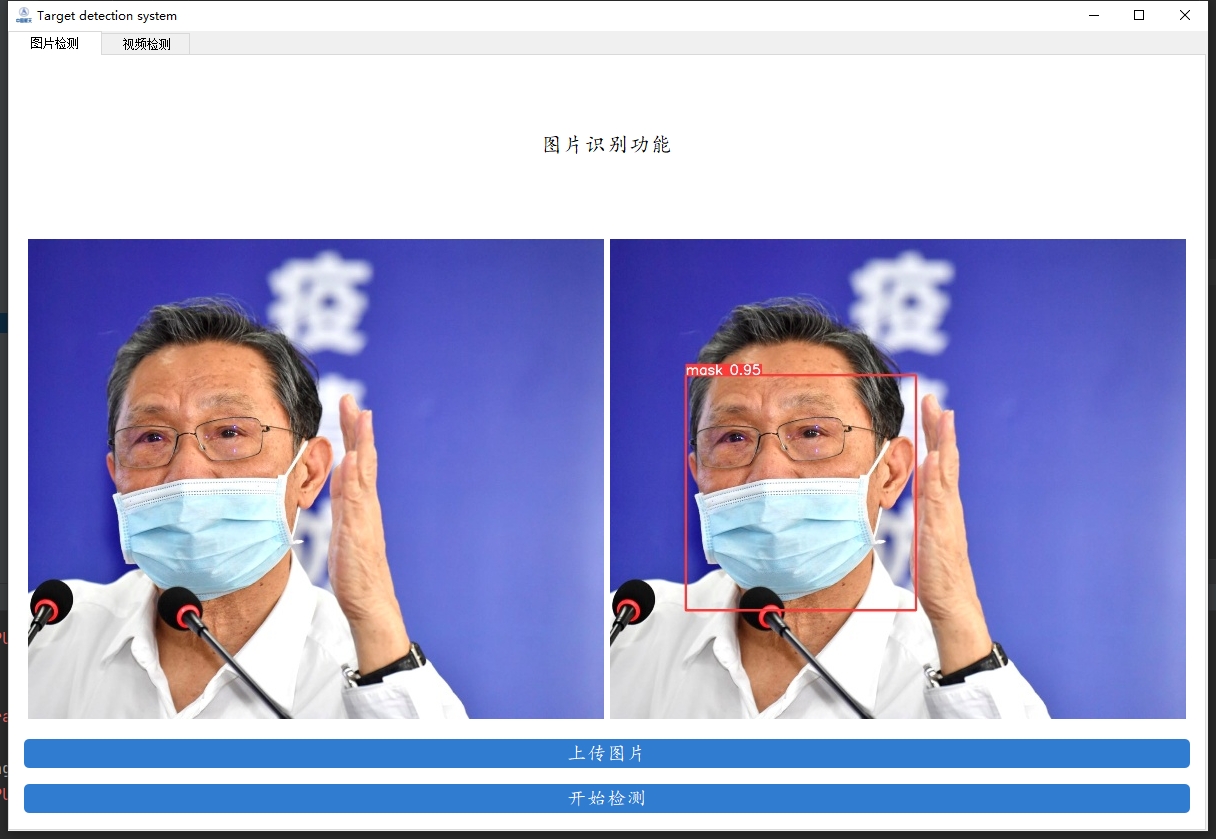
在如今这个特殊时期,口罩成为了我们生活中不可或缺的一部分。而利用计算机视觉技术实现口罩的自动检测,无论是在公共场所的安防监控,还是在生产线上对口罩质量的把控,都有着重要的意义。今天就来和大家分享一下基于YOLOv5和PyTorch开发口罩检测系统的过程。
YOLOv5与PyTorch简介
YOLOv5 是一种目标检测算法,它速度快且精度较高,在各种实际场景中都有广泛应用。PyTorch 则是一个基于Python的科学计算包,专为深度学习而设计,其动态计算图的特性使得模型的开发和调试更加灵活和直观。
环境搭建
首先,确保你安装了Python环境,这里建议使用Anaconda来管理虚拟环境。创建一个新的虚拟环境:
conda create -n yolo_mask python=3.8
conda activate yolo_mask接着安装PyTorch,根据你的CUDA版本选择合适的安装命令,比如我这里使用CUDA 11.1,就可以运行:
pip install torch==1.9.0+cu111 torchvision==0.10.0+cu111 torchaudio==0.9.0 -f https://download.pytorch.org/whl/torch_stable.html然后安装YOLOv5相关依赖,从GitHub上克隆YOLOv5仓库:
git clone https://github.com/ultralytics/yolov5
cd yolov5
pip install -r requirements.txt数据准备
要训练一个口罩检测模型,我们需要有带标注的口罩数据。可以从公开数据集下载,或者自己收集图片并标注。标注一般使用VOC格式,即每个图片对应一个XML文件,描述图片中目标的类别、位置等信息。
假设我们已经准备好了数据集,结构大概如下:
dataset/
├── images/
│ ├── train/
│ │ ├── img1.jpg
│ │ ├── img2.jpg
│ │ └──...
│ └── val/
│ ├── img3.jpg
│ ├── img4.jpg
│ └──...
└── labels/
├── train/
│ ├── img1.xml
│ ├── img2.xml
│ └──...
└── val/
├── img3.xml
├── img4.xml
└──...模型训练
在YOLOv5的根目录下,创建一个data.yaml文件来描述数据集的信息:
train: path/to/dataset/images/train
val: path/to/dataset/images/val
nc: 2 # 类别数,这里是戴口罩和未戴口罩两类
names: ['with_mask', 'without_mask']接下来就可以开始训练模型了,运行以下命令:
python train.py --img 640 --batch 16 --epochs 50 --data data.yaml --weights yolov5s.pt这里--img指定输入图片的大小,--batch是批次大小,--epochs为训练轮数,--data指定数据集配置文件,--weights使用预训练权重yolov5s.pt来加速训练。
基于YOLOv5的口罩检测系统,pytorch开发
在train.py代码中,核心部分是模型的初始化和训练循环。以模型初始化为例:
from models.experimental import attempt_load
# 加载模型
weights = 'yolov5s.pt'
model = attempt_load(weights, map_location=device) attempt_load函数会尝试加载预训练权重,如果权重文件存在且设备匹配,就会成功加载。在训练循环中,会不断计算损失并更新模型参数。
模型推理
训练完成后,就可以用训练好的模型进行口罩检测了。编写一个简单的推理脚本detect_mask.py:
import cv2
from models.experimental import attempt_load
from utils.general import non_max_suppression, scale_coords
from utils.torch_utils import select_device
weights = 'runs/train/exp/weights/best.pt' # 训练好的权重路径
device = select_device('') # 选择设备,空字符串表示自动选择CPU或GPU
model = attempt_load(weights, map_location=device)
cap = cv2.VideoCapture(0) # 打开摄像头
while True:
ret, img = cap.read()
if not ret:
break
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
img = cv2.resize(img, (640, 640))
img = np.transpose(img, (2, 0, 1))
img = np.expand_dims(img, axis=0)
img = torch.from_numpy(img).to(device).float() / 255.0
pred = model(img)[0]
pred = non_max_suppression(pred, 0.4, 0.5)
for i, det in enumerate(pred):
if det is not None and len(det):
det[:, :4] = scale_coords(img.shape[2:], det[:, :4], img0.shape).round()
for *xyxy, conf, cls in reversed(det):
label = f'{model.names[int(cls)]} {conf:.2f}'
cv2.rectangle(img0, (int(xyxy[0]), int(xyxy[1])), (int(xyxy[2]), int(xyxy[3])), (0, 255, 0), 2)
cv2.putText(img0, label, (int(xyxy[0]), int(xyxy[1]) - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 255, 0), 2)
img0 = cv2.cvtColor(img0, cv2.COLOR_RGB2BGR)
cv2.imshow('Mask Detection', img0)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()这段代码首先加载训练好的权重,然后打开摄像头获取视频流。对每一帧图像进行预处理后输入模型得到预测结果,再通过nonmaxsuppression函数进行非极大值抑制去除多余的检测框,最后将检测结果绘制在图像上并显示。
通过以上步骤,我们就基于YOLOv5和PyTorch完成了一个口罩检测系统的搭建。当然,实际应用中还可以根据需求进一步优化和部署,希望这篇文章能给大家在计算机视觉项目开发上一些启发。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 0
0 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)