智能语音技术(八)
双门限法通过。
端点检测
好的,我们来详细解释一下语音端点检测的原理。
语音端点检测原理详解
语音端点检测是语音信号处理中的一项基础技术,其核心目标是准确地定位一段录音信号中语音段的起始点和终止点,即区分出语音段和非语音段(如静音、背景噪声)。它在语音识别、语音增强、说话人识别等系统中扮演着至关重要的前置角色,能有效提高后续处理的效率和准确性。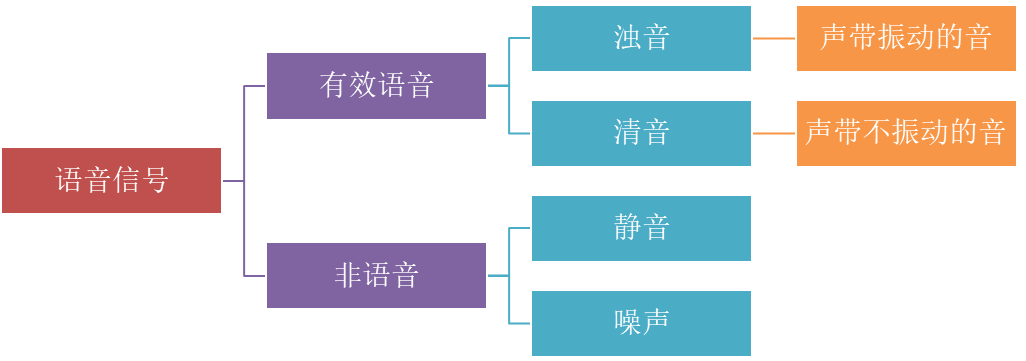
核心原理
其基本原理在于利用语音信号和非语音信号在时域和频域上的显著统计特性差异: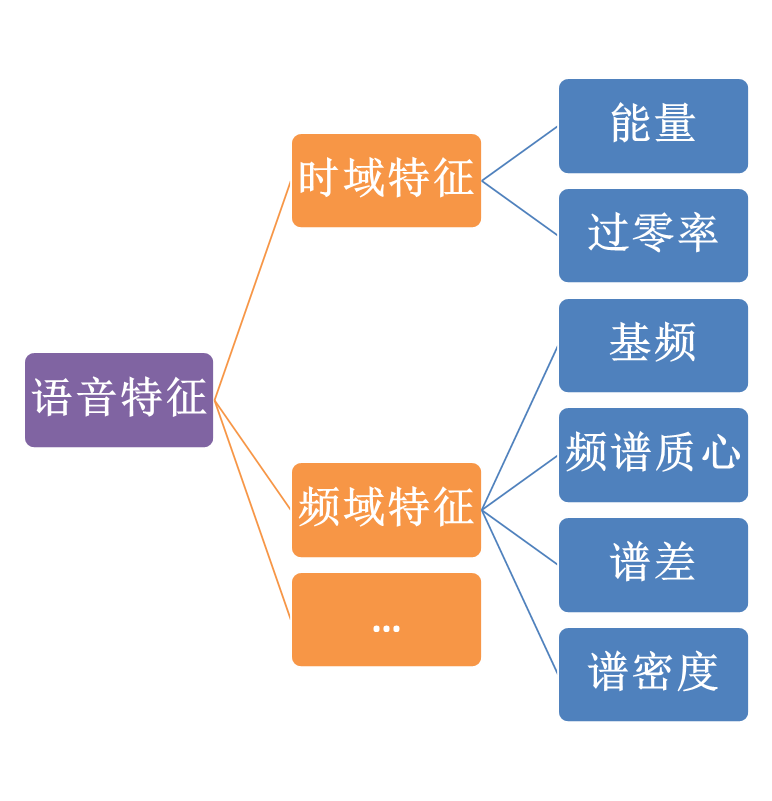
-
能量特征差异:
- 语音段(特别是元音和浊辅音)通常具有较高的能量(振幅)。
- 静音段或背景噪声段的能量通常较低且相对平稳。
- 因此,计算信号的短时能量是端点检测最常用、最基础的判据之一。定义短时能量 EnE_nEn 为:
En=1N∑m=−∞∞[x(m)w(n−m)]2E_n = \frac{1}{N} \sum_{m=-\infty}^{\infty} [x(m)w(n-m)]^2En=N1m=−∞∑∞[x(m)w(n−m)]2
其中 x(m)x(m)x(m) 是语音信号, w(n−m)w(n-m)w(n−m) 是窗函数(如汉明窗), NNN 是窗长。当 EnE_nEn 超过某个预设的能量阈值时,可能表示语音开始。
-
过零率特征差异:
- 过零率指信号波形穿过零电平轴的次数。单位时间内过零的次数。
- 清音(如 /s/, /f/)和背景噪声通常具有较高的过零率。
- 浊音(如元音)和静音段的过零率较低。
- 因此,结合短时过零率 ZnZ_nZn 可以辅助区分清音和静音/背景噪声。定义 ZnZ_nZn 为:
Zn=12N∑m=−∞∞∣sgn[x(m)]−sgn[x(m−1)]∣w(n−m)Z_n = \frac{1}{2N} \sum_{m=-\infty}^{\infty} |\text{sgn}[x(m)] - \text{sgn}[x(m-1)]| w(n-m)Zn=2N1m=−∞∑∞∣sgn[x(m)]−sgn[x(m−1)]∣w(n−m)
其中 sgn[⋅]\text{sgn}[\cdot]sgn[⋅] 是符号函数。高过零率可能表示清音或噪声。
-
频谱特征差异:
- 语音信号(特别是浊音)在频谱上具有明显的谐波结构或共振峰结构。
- 背景噪声的频谱通常较平坦或具有不同的分布。
- 可以使用更复杂的特征如频谱熵、梅尔频率倒谱系数的统计量(如第一维系数的均值和方差)等来表征这种差异,提高检测鲁棒性。
更先进的方法
为了在复杂噪声环境下提高端点检测的鲁棒性,研究者提出了许多更先进的方法:
- 基于统计模型的方法:如使用隐马尔可夫模型对语音和噪声状态进行建模。
- 基于机器学习的方法:使用分类器(如支持向量机, 深度神经网络)将每一帧信号分类为“语音”或“非语音”。
- 结合多特征融合:综合利用能量、过零率、频谱特征、倒谱特征等多种信息。
- 自适应阈值调整:根据背景噪声水平动态调整检测阈值。

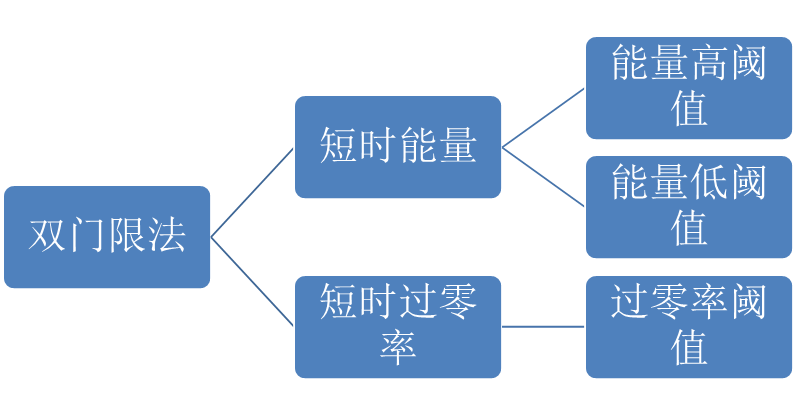
一、双门限法基本原理
双门限法是一种基于短时能量和过零率的语音端点检测方法。通过设置两个门限值(能量门限 TET_ETE 和过零率门限 TZT_ZTZ),结合噪声特性,实现语音段的起止点定位。其核心优势在于抗噪声干扰能力强,尤其适用于低信噪比环境。
二、完整步骤详解
步骤1:预处理
-
分帧
将语音信号 s(n)s(n)s(n) 分割为长度为 NNN 的帧,帧移 MMM(通常 M=N/2M = N/2M=N/2)。
si(m)=s(i⋅M+m),0≤m<N s_i(m) = s(i \cdot M + m), \quad 0 \leq m < N si(m)=s(i⋅M+m),0≤m<N -
加窗
每帧加汉明窗以减少频谱泄漏:
w(m)=0.54−0.46cos(2πmN−1) w(m) = 0.54 - 0.46 \cos\left(\frac{2\pi m}{N-1}\right) w(m)=0.54−0.46cos(N−12πm)
步骤2:计算短时能量
每帧能量 EiE_iEi 定义为:
Ei=∑m=0N−1[si(m)⋅w(m)]2 E_i = \sum_{m=0}^{N-1} [s_i(m) \cdot w(m)]^2 Ei=m=0∑N−1[si(m)⋅w(m)]2
步骤3:计算短时过零率
过零率 ZiZ_iZi 表示信号穿过零轴的次数:
Zi=∑m=1N−1∣sgn[si(m)]−sgn[si(m−1)]∣ Z_i = \sum_{m=1}^{N-1} \left| \operatorname{sgn}[s_i(m)] - \operatorname{sgn}[s_i(m-1)] \right| Zi=m=1∑N−1∣sgn[si(m)]−sgn[si(m−1)]∣
步骤4:噪声估计与门限设定
噪声难点:背景噪声会导致能量和过零率波动,需动态调整门限。
- 初始噪声估计
取前 KKK 帧(纯噪声段)计算平均能量 Eˉnoise\bar{E}_\text{noise}Eˉnoise 和平均过零率 Zˉnoise\bar{Z}_\text{noise}Zˉnoise。 - 动态门限
- 能量门限:
- 过零率门限:
其中 α\alphaα、β\betaβ 为经验系数(通常 α∈[1.5,2.5]\alpha \in [1.5, 2.5]α∈[1.5,2.5], β∈[1.2,1.8]\beta \in [1.2, 1.8]β∈[1.2,1.8])。
步骤5:双门限判决
- 初步检测
- 若 Ei>TEE_i > T_EEi>TE 且 Zi>TZZ_i > T_ZZi>TZ,标记为 语音段。
- 否则标记为 噪声段。
- 连续段合并
合并相邻的语音段,并忽略过短的孤立段(如长度 <0.1s< 0.1\text{s}<0.1s)。
步骤6:后处理优化
- 端点修正
语音起始点前扩展 T1T_1T1 帧,结束点后扩展 T2T_2T2 帧(捕获弱辅音)。 - 过零率补偿
对清音(如/s/)进行过零率加权:$ Z_i’ = Z_i \cdot \gamma (((\gamma > 1$)。
三、噪声难点处理策略
- 非平稳噪声
- 动态更新 Eˉnoise\bar{E}_\text{noise}Eˉnoise 和 Zˉnoise\bar{Z}_\text{noise}Zˉnoise(如每 101010 帧更新一次)。
- 突发噪声
- 增加 过零率变化率检测:若 ΔZi=∣Zi−Zi−1∣>δ\Delta Z_i = |Z_i - Z_{i-1}| > \deltaΔZi=∣Zi−Zi−1∣>δ,暂不标记为语音。
- 低能量语音
- 使用 多通道门限:
TE′=max(TE,η⋅max(Ei))(η≈0.1) T_E' = \max(T_E, \eta \cdot \max(E_i)) \quad (\eta \approx 0.1) TE′=max(TE,η⋅max(Ei))(η≈0.1)
- 使用 多通道门限:
四、示意图说明
下图展示了双门限法在含噪语音中的检测过程: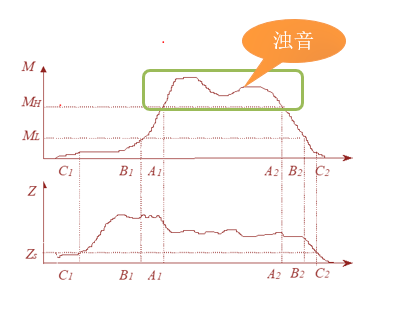
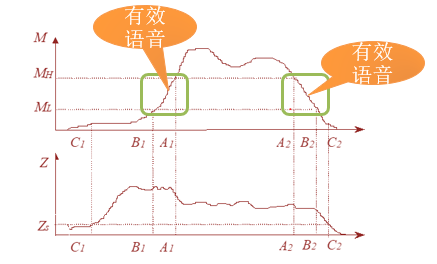
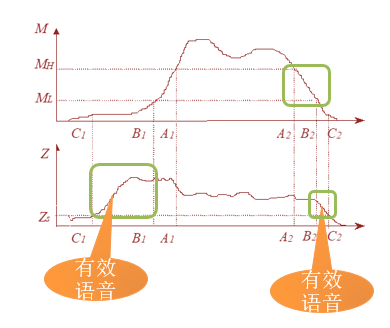

---
### **五、示例代码(Python)**
```python
import numpy as np
def dual_threshold_detection(signal, fs, frame_len=0.025, frame_shift=0.01):
# 分帧与加窗
n_frame_len = int(frame_len * fs)
n_frame_shift = int(frame_shift * fs)
frames = [signal[i:i+n_frame_len] for i in range(0, len(signal)-n_frame_len, n_frame_shift)]
# 计算能量与过零率
energy = [np.sum(np.abs(frame)**2) for frame in frames]
zcr = [np.sum(np.abs(np.diff(np.sign(frame)))) / 2 for frame in frames]
# 噪声估计(前10%帧)
noise_frames = int(0.1 * len(frames))
E_noise = np.mean(energy[:noise_frames])
Z_noise = np.mean(zcr[:noise_frames])
# 设置门限
alpha, beta = 2.0, 1.5
T_E = alpha * E_noise
T_Z = beta * Z_noise
# 双门限判决
speech_flags = [(e > T_E and z > T_Z) for e, z in zip(energy, zcr)]
# 合并连续段并扩展端点
# ...(具体实现略)
return speech_segments
六、总结
双门限法通过能量与过零率的协同判决,结合动态噪声估计和后处理优化,显著提升了在噪声环境下的端点检测鲁棒性。实际应用中需根据场景调整 α\alphaα、β\betaβ 等参数,并针对非平稳噪声设计自适应更新策略。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 12
12 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)