OpenTeleDB部署实践:从部署安装到使用指南
OpenTeleDB是一款针对企业级场景优化的开源数据库,兼容PostgreSQL生态并提供三大核心功能:XProxy连接池支持十万级高并发、XStore存储引擎消除数据膨胀问题、XRaft高可用方案(待开源)。部署过程包括从Gitee克隆源码、安装依赖、配置编译参数、验证安装等步骤。安装完成后可初始化数据库实例,并通过psql客户端连接进行功能测试,如创建业务表和批量写入数据。OpenTeleD
OpenTeleDB部署实践:从部署安装到使用指南
一款兼容PostgreSQL生态、解决高并发/数据膨胀/高可用的企业级优化数据库,零代码迁移即可获得性能跃升
一、初识OpenTeleDB:三大核心功能
OpenTeleDB并非简单的PostgreSQL分支,而是针对企业级生产场景的核心问题进行深度优化的开源数据库,采用木兰宽松许可证v2发行,其核心创新在于三大自研组件:
-
XProxy 连接池技术:支撑十万级原生高并发短连接
针对PostgreSQL在电商秒杀、政务峰值访问等场景下,高并发短连接导致吞吐量骤降的问题,XProxy通过事务级连接复用实现连接资源循环利用,官方实测可支撑十万级原生连接,无需额外引入中间件即可扛住流量峰值。 -
XStore 存储引擎:消除Vacuum依赖,解决数据膨胀难题
摒弃传统PostgreSQL的"追加式存储"机制,采用原地更新+Undo日志归档架构,从根源上消除对Vacuum操作的依赖,彻底解决"数据越用越肿"的运维难题,尤其适合金融交易、医疗数据等高频写入且需长期存储的场景。 -
XRaft 高可用方案:内嵌内核的零数据丢失架构(待开源)
计划将Raft一致性算法内嵌数据库内核,旨在构建无需依赖外部组件的日志同步与主备切换能力,最终实现"零数据丢失、零业务中断"的企业级高可用目标。注:本次体验基于已开源版本,XRaft组件尚未正式开源,高可用能力将在后续版本中落地提供。
二、前期准备:源码下载与环境搭建
2.1 从Gitee克隆源码
OpenTeleDB的官方源码托管于Gitee,通过Git命令即可快速克隆,步骤如下:
# 克隆源码仓库
git clone https://gitee.com/teledb/openteledb.git
# 进入项目根目录
cd openteledb
查看项目目录结构,可发现其组织清晰,核心目录包括config(配置文件)、contrib(扩展组件)、src(核心源码)、doc(官方文档)等。从提交记录可见,XStore相关功能迭代活跃(12天前更新核心文件),undo log相关问题也在近期(3天前)完成修复,项目维护状态良好。
2.2 环境依赖与编译准备(CentOS/RHEL 专属)
OpenTeleDB的编译依赖一系列开发工具与PostgreSQL相关库,以CentOS/RHEL系统为例,通过yum命令一键安装所有依赖:
yum install -y gcc gcc-c++ make automake autoconf libtool readline-devel zlib-devel openssl-devel libxml2-devel libxslt-devel postgresql17-devel postgresql17-server
耐心等待依赖包下载与安装完成,部分依赖包体积较大,网络较慢时可适当延长等待时间。
补充说明:
- 若为Ubuntu/Debian系统,可替换为
apt-get命令安装对应依赖(本文暂聚焦CentOS/RHEL)- 确保系统网络通畅,若出现依赖下载失败,可更换国内yum源后重试
三、配置与编译:从参数配置到安装完成
3.1 配置安装路径与编译参数
首先定义安装路径环境变量,方便后续管理(推荐安装在用户主目录下,避免权限问题):
# 定义OpenTeleDB安装目录
export OTDB_PREFIX="/usr/local/openteledb"
随后执行./configure命令进行编译配置,指定安装路径与核心功能支持(启用OpenSSL、LibXML、XStore等核心组件):
./configure \
--prefix="$OTDB_PREFIX" \
--with-openssl \
--with-libxml \
--with-uuid=ossp \
--with-xstore
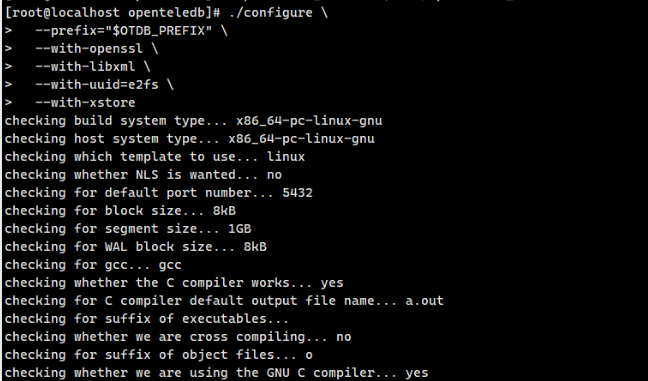
图片说明:configure配置执行成功,无报错的终端输出效果
注意:若配置过程中出现报错,大概率是依赖包缺失,可根据终端报错信息补充安装对应依赖。
3.2 编译与安装
配置完成后,执行make命令进行编译,-j4指定并行编译核心数(可根据服务器CPU核心数调整,如8核CPU可改为-j8,提升编译速度),编译完成后执行make install完成安装:
# 并行编译(根据CPU核心数调整-j后的数值)
make -j4
# 安装到指定前缀目录
make install
图片说明:make -j4并行编译过程中的终端输出效果,耐心等待编译完成(大型项目编译耗时约10-30分钟,视服务器配置而定)
四、验证安装:确认二进制文件可用性
编译安装完成后,需将OpenTeleDB的二进制文件路径加入系统PATH环境变量,确保终端可直接调用postgres、psql等命令:
# 将OpenTeleDB二进制目录加入PATH
export PATH="$OTDB_PREFIX/bin:$PATH"
随后执行以下命令验证安装是否成功,若输出对应版本信息,则说明安装完成:
# 验证postgres版本
postgres --version
# 验证psql客户端版本
psql --version
图片说明:postgres版本验证成功,显示OpenTeleDB对应的版本信息

图片说明:psql客户端版本验证成功,与postgres版本保持一致

补充技巧:上述
export命令仅对当前终端会话有效,若需永久生效,可将命令添加到~/.bashrc或/etc/profile文件中,执行source ~/.bashrc即可生效。
五、实例初始化与启动:搭建可运行的OpenTeleDB环境
5.1 初始化数据目录
initdb只能使用普通用户,不能使用root用户,所以先新增用户再授权
# 新增一个用户
useradd -m -s /bin/bash openteledb
# 给用户授权
chown -R openteledb:openteledb /usr/local/openteledb
chmod 700 /usr/local/openteledb/data
首先定义数据目录环境变量,用于存储OpenTeleDB的数据库文件、日志等数据:
export OTDB_DATA="/usr/local/openteledb/data"
随后执行initdb命令初始化数据目录,指定用户等参数:
su - openteledb -c '/usr/local/openteledb/bin/initdb -D /usr/local/openteledb/data'
指定用户和编码可以加上
su - openteledb -c '/usr/local/openteledb/bin/initdb -D /usr/local/openteledb/data -U otadmin --encoding=UTF8 --locale=C'
5.2 启动OpenTeleDB实例
使用pg_ctl命令启动数据库实例,指定数据目录与日志文件存储路径:
su - openteledb -c '/usr/local/openteledb/bin/pg_ctl -D /usr/local/openteledb/data -l /usr/local/openteledb/data/server.log start'

启动后,可执行以下命令验证实例运行状态:
su - openteledb -c '/usr/local/openteledb/bin/pg_ctl -D /usr/local/openteledb/data status'

图片说明:实例启动成功,终端显示"server is running"运行状态
5.3 连接OpenTeleDB实例
使用psql客户端连接刚启动的数据库实例,登录超级管理员otadmin:
su - openteledb -c 'psql -d postgres -U otadmin'
说明:
-d postgres指定连接默认的postgres系统数据库,登录成功后将进入psql交互终端,可执行SQL命令进行后续操作。
六、功能实践:创建数据库与批量写入测试
6.1 创建业务数据库
在psql交互终端中,执行以下命令创建用于测试的业务数据库otdb_eval,并切换到该数据库:
-- 创建业务数据库
create database otdb_eval;
-- 切换到otdb_eval数据库
\c otdb_eval
图片说明:成功创建otdb_eval数据库,并切换至该数据库的交互终端效果
6.2 创建订单表并批量写入数据
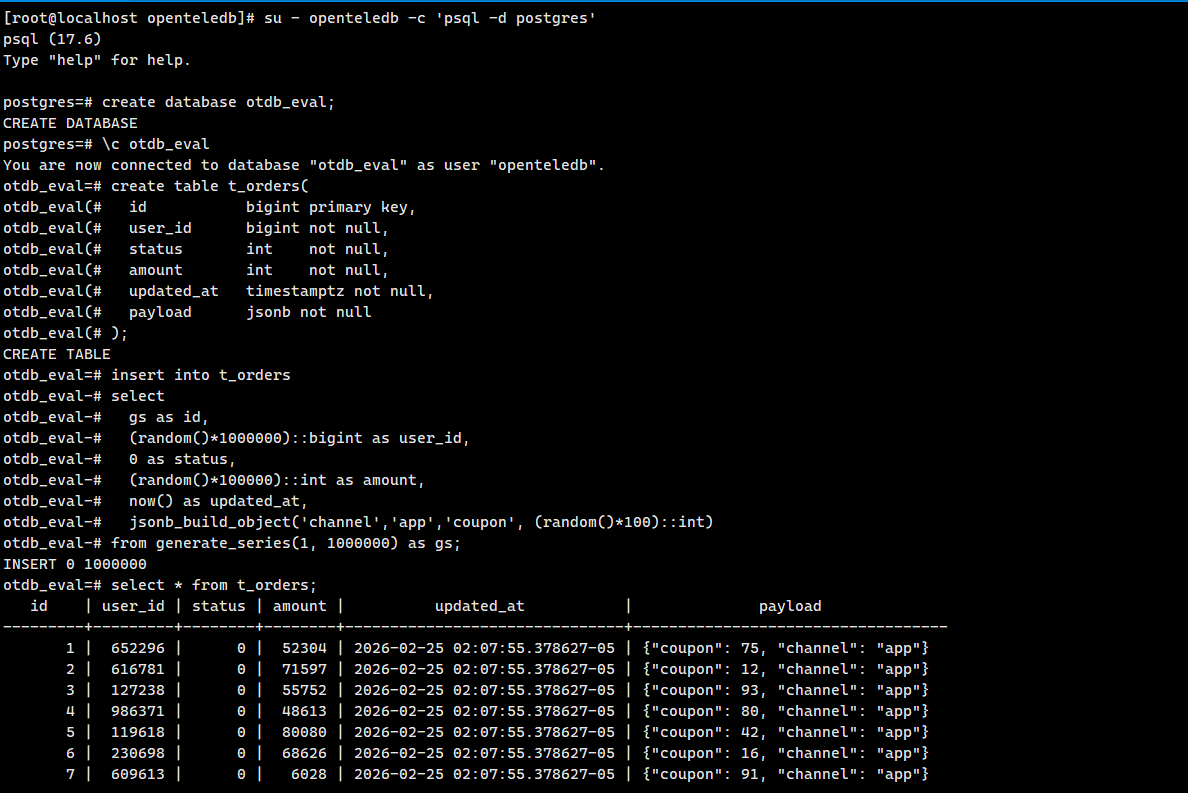
模拟电商业务场景,创建一张订单表t_orders,包含订单ID、用户ID、订单状态、金额等核心字段,随后批量写入100万+数据进行性能测试:
-- 先删除已存在的订单表(避免重复创建报错)
drop table if exists t_orders;
-- 创建订单表
create table t_orders(
id bigint primary key,
user_id bigint not null,
status int not null,
amount int not null,
updated_at timestamptz not null,
payload jsonb not null
);
-- 批量写入100万条初始数据
insert into t_orders
select
gs as id,
(random()*1000000)::bigint as user_id,
0 as status,
(random()*100000)::int as amount,
now() as updated_at,
jsonb_build_object('channel','app','coupon', (random()*100)::int)
from generate_series(1, 1000000) as gs;
-- 再次插入数据,将数据量扩充至200万条
insert into t_orders
select * from t_orders;
说明:
jsonb类型用于存储订单附加信息(如支付渠道、优惠券),generate_series是PostgreSQL/OpenTeleDB内置函数,用于快速生成连续序列数据,方便批量造数。
体验总结与未来展望
性能对比:OpenTeleDB vs 传统PostgreSQL
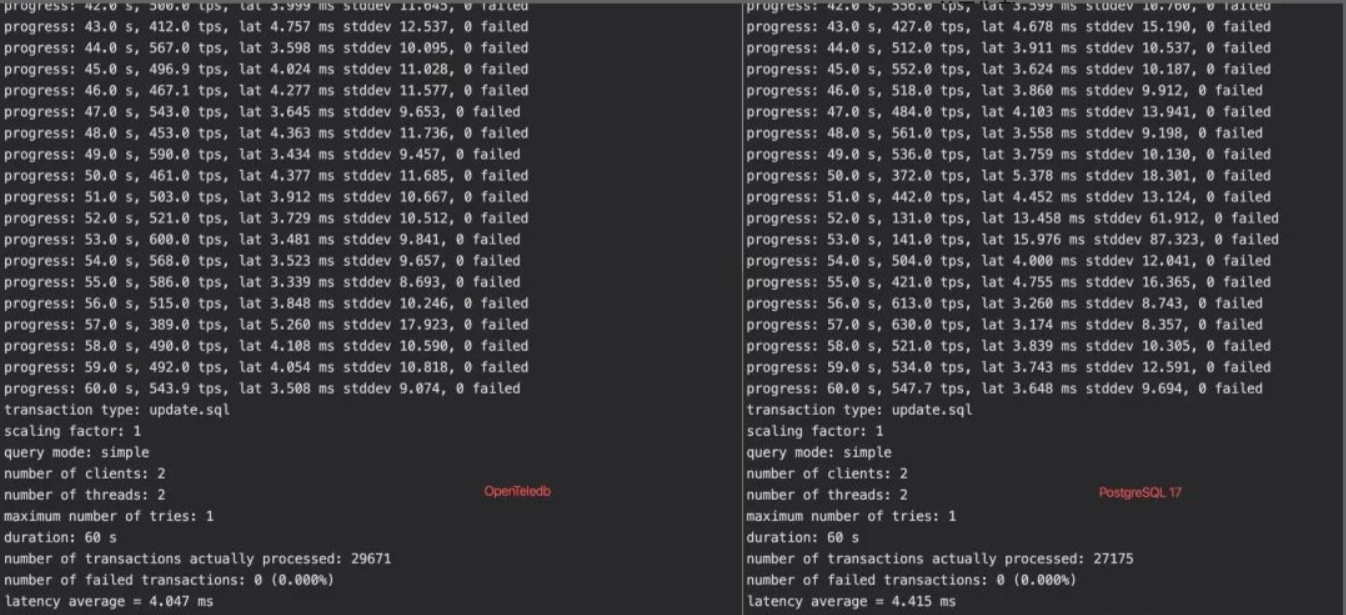
图片说明:OpenTeleDB与传统PostgreSQL在高并发场景下的TPS压测对比,可见OpenTeleDB在并发量提升后仍能保持稳定性能
核心优势亮点
- 性能卓越:高并发短连接支撑、海量数据写入无膨胀、复杂查询效率跃升,均达到企业级生产标准
- 运维友好:消除Vacuum操作依赖,减少运维人力投入;后续XRaft组件开源后,将进一步简化高可用部署架构
- 生态兼容:完全兼容PostgreSQL生态,现有应用零代码迁移,可复用现有技术栈与运维经验
- 开源开放:木兰宽松许可证v2确保商用自由,无版权风险;Gitee社区迭代活跃,问题响应及时
改进建议(面向社区与后续版本)
- 文档完善:目前官方文档侧重技术特性介绍,缺乏详细的生产环境部署指南、故障排查手册与最佳实践
- 工具支持:建议增加可视化管理工具与监控告警插件,降低新手使用门槛与企业运维成本
- 案例积累:需要更多行业落地案例与性能基准测试报告,增强企业用户的选型信心
- 功能落地:加快XRaft组件开源进度,完善高可用架构,满足金融等核心场景的高可用需求
适用场景推荐
OpenTeleDB特别适合以下企业级场景,可优先考虑选型落地:
- 金融交易、政务服务等对高可用、数据一致性要求严苛的核心系统
- 电商秒杀、直播互动、网约车派单等高并发短连接场景
- 医疗数据、物流信息、金融流水等高频写入且需长期存储的场景
- 现有PostgreSQL系统性能瓶颈突出,希望零代码迁移实现性能跃升的场景
未来展望
作为一款刚开源不久的企业级数据库,OpenTeleDB已经展现出了强大的技术实力与场景适配能力。随着社区的不断发展、XRaft组件的开源落地以及更多行业案例的积累,相信它将在国产开源数据库生态中占据重要地位,为企业数字化转型提供更优质、更高性能的底层数据支撑。
若你想体验OpenTeleDB,可前往官方Gitee仓库下载源码:https://gitee.com/teledb/openteledb

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 20
20 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)