大数据运维
核心逻辑:围绕 Hadoop 核心,衍生出数据存储(HBase、Hive)、数据采集(Flume、Sqoop)、计算引擎(Spark、Flink)、资源管理(YARN)、协调服务(ZooKeeper)等组件,形成完整的大数据技术栈。核心逻辑:Hadoop 是谷歌三篇论文的开源实现,核心由 HDFS(分布式存储)和 MapReduce(分布式计算)组成,特点是高容错、易扩展、低成本。核心逻辑:Had
一,大数据技术回顾
01 谷歌三驾马车
核心逻辑:谷歌提出三大技术奠定大数据基础——GFS 解决海量数据存储,MapReduce 解决大规模计算,Bigtable 解决结构化数据存储。

02 什么是Hadoop
Hadoop 源自 Google 的三篇论文(GFS、MapReduce、Bigtable),由 Doug Cutting 在 Apache 项目中实现并开源。它成为大数据领域的基石,开启了企业级数据处理的平民化时代。

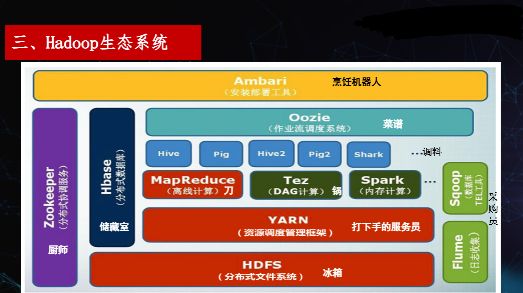
03 Hadoop生态
核心逻辑:围绕 Hadoop 核心,衍生出数据存储(HBase、Hive)、数据采集(Flume、Sqoop)、计算引擎(Spark、Flink)、资源管理(YARN)、协调服务(ZooKeeper)等组件,形成完整的大数据技术栈。
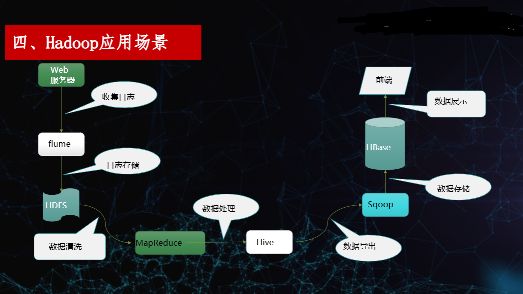
04 Hadoop应用场景
核心逻辑:Hadoop 主要用于海量数据离线分析、日志处理、数据仓库 ETL,以及作为机器学习平台的基础存储与计算层。
二,分布式大数据集群框架
对于刚接触 Hadoop 的初学者来说,搭建分布式集群环境往往是最让人头疼的一步。许多人花费大量时间在安装与配置上,却因为各种细节问题导致环境无法成功运行。更令人沮丧的是,搭建失败的概率在初学者中相当高。因此,在正式开始搭建集群之前,做好充分的集群规划,是确保后续操作顺利进行的关键一步。
1. 集群拓扑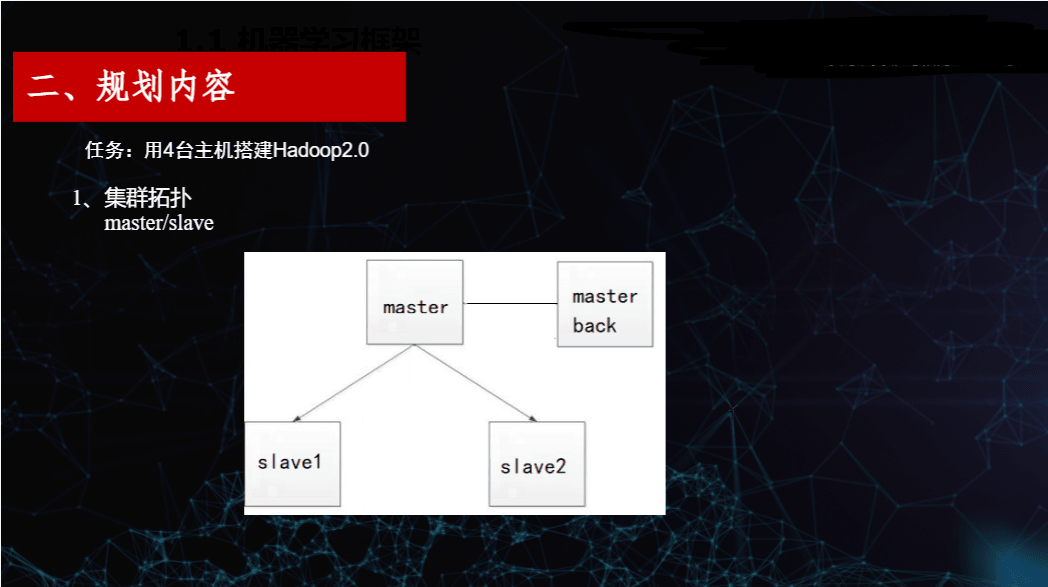
本次规划的任务是使用 4 台主机 搭建 Hadoop 2.0 集群。集群中节点角色包括 Master 和 Slave,具体拓扑如下:
-
master
-
masterback
-
slave1
-
slave2
其中,master 和 masterback 承担主控节点角色,slave1 和 slave2 作为工作节点。
2. 主机规划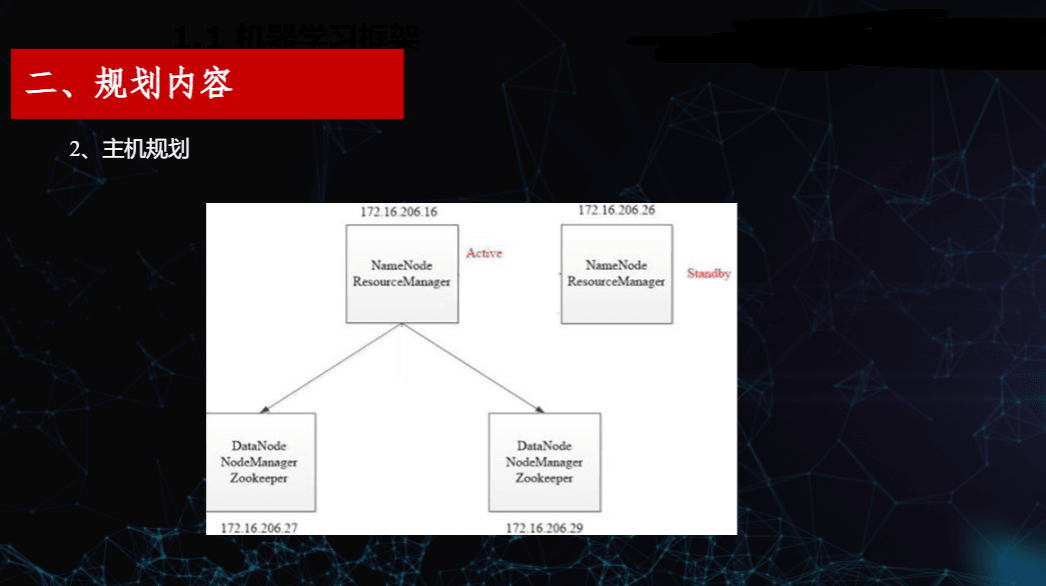
在主机规划中,我们为四台主机分配了各自的 IP 地址和角色,确保高可用与职责分离:
| IP 地址 | 主机名 | 角色分配 |
|---|---|---|
| 172.16.206.16 | master | Active NameNode、ResourceManager、ZooKeeper |
| 172.16.206.26 | masterback | Standby NameNode、ResourceManager、ZooKeeper |
| 172.16.206.27 | slave1 | DataNode、NodeManager、ZooKeeper |
| 172.16.206.29 | slave2 | DataNode、NodeManager、ZooKeeper |
通过这种角色划分,实现了 NameNode 的高可用(Active/Standby),同时也保证了资源管理与数据存储的分布式部署。
3. 软件规划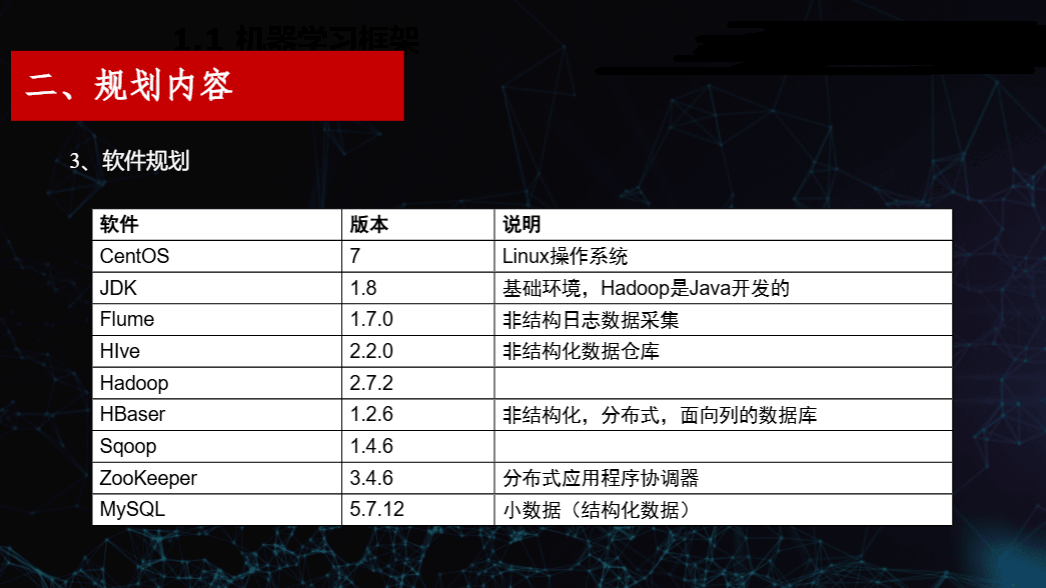
集群的运行依赖于多个软件组件,各组件及其版本说明如下:
| 软件 | 版本 | 说明 |
|---|---|---|
| CentOS | 7 | Linux 操作系统 |
| JDK | 1.8 | Hadoop 基于 Java 开发,基础运行环境 |
| Flume | 1.7.0 | 用于非结构日志数据采集 |
| Hive | 2.2.0 | 非结构化数据仓库工具 |
| Hadoop | 2.7.2 | 核心分布式计算与存储框架 |
| HBase | 1.2.6 | 分布式、面向列的非结构化数据库 |
| Sqoop | 1.4.6 | 结构化数据与 Hadoop 之间的数据同步工具 |
| ZooKeeper | 3.4.6 | 分布式应用程序协调服务 |
| MySQL | 5.7.12 | 存储小规模结构化数据 |
这些软件共同构成了一个完整的大数据处理平台,涵盖数据采集、存储、计算与协调等多个环节。
4. 数据目录规划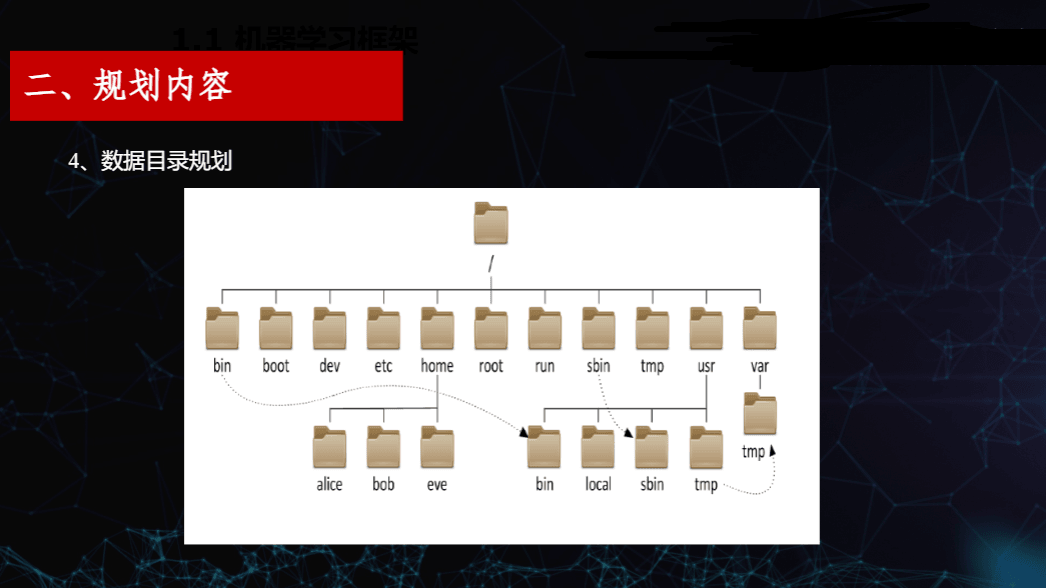
合理的目录结构有助于管理和维护集群中的各类数据与应用程序。规划中涵盖了 Linux 系统标准目录与自定义数据目录,例如:
-
/bin、/boot、/dev、/etc等系统目录 -
/home下的用户目录如alice、bob、eve -
/usr/local、/sbin、/tmp等应用与临时目录
通过清晰划分,避免了文件混乱与权限冲突,便于后续服务的部署与日志管理。
5. Windows 主机映射
为了在 Windows 环境下通过主机名访问各台虚拟机,需要修改本机的 hosts 文件。操作步骤如下:
-
打开 hosts 文件(路径通常为
C:\Windows\System32\drivers\etc\hosts) -
添加以下映射关系:
text
172.16.206.16 master 172.16.206.26 masterback 172.16.206.27 slave1 172.16.206.29 slave2
完成配置后,即可通过主机名(如 master)访问对应节点,简化后续配置与操作。
通过以上五个方面的详细规划,我们为 Hadoop 集群的搭建奠定了清晰、可靠的基础。每一步规划都旨在降低搭建过程中的不确定性,帮助新手更顺利地完成环境部署,集中精力在后续的大数据应用与开发上。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)