阿里ASR模型本地化部署:Speech Seaco免配置镜像快速上手指南
本文介绍了如何在星图GPU平台上自动化部署Speech Seaco Paraformer ASR阿里中文语音识别模型镜像。该镜像由科哥构建,开箱即用,用户可快速搭建本地语音识别服务,轻松将会议录音、访谈音频等文件转换为文字稿,有效提升内容整理效率并保障数据安全。
阿里ASR模型本地化部署:Speech Seaco免配置镜像快速上手指南
你是不是也遇到过这样的场景:手头有一段重要的会议录音,急需转换成文字稿,但手动听写耗时耗力,用在线工具又担心数据安全和隐私问题?或者,作为一个开发者,你想在自己的项目中集成一个强大的中文语音识别能力,却对复杂的模型部署和配置望而却步?
今天,我要给你介绍一个“开箱即用”的解决方案——Speech Seaco Paraformer ASR。这是一个基于阿里达摩院FunASR框架构建的中文语音识别模型,由科哥封装成了免配置的Docker镜像。这意味着,你不需要懂复杂的Python环境配置,也不需要处理繁琐的依赖包,只需要一条简单的命令,就能在本地拥有一个媲美商业服务的中文语音识别系统。
这篇文章,我将带你从零开始,手把手完成这个镜像的部署和上手使用。整个过程就像安装一个普通软件一样简单,但背后却是阿里顶尖的语音识别技术。准备好了吗?我们开始吧。
1. 为什么选择Speech Seaco Paraformer?
在深入部署之前,我们先花一分钟了解一下,这个“黑盒子”里到底装了什么,以及它能为你带来什么。
Speech Seaco Paraformer 的核心是阿里达摩院开源的 Paraformer 模型。这个名字你可能有点陌生,但它的几个特点,足以让你眼前一亮:
- 高精度识别:针对中文场景进行了深度优化,在多个公开测试集上表现优异,对日常对话、会议、访谈等场景的语音识别准确率非常高。
- 流式与非流式一体:这意味着它既能处理完整的录音文件(非流式,精度更高),也具备处理实时音频流(流式)的潜力,架构很先进。
- 热词定制:这是它的一个“杀手锏”功能。你可以在识别前,输入一些专业术语、人名、产品名等作为“热词”,系统会显著提升这些词汇的识别优先级和准确率。对于垂直领域(如医疗、法律、科技)的应用来说,这个功能价值巨大。
- 即装即用:科哥将这个模型连同完整的Web界面(WebUI)打包成了一个Docker镜像。你不需要关心模型下载、环境配置、服务启动这些琐事,所有东西都已经预置好了。
简单来说,你得到的是一个带有漂亮操作界面的、功能强大的、完全本地运行的中文语音转文字服务。数据不出本地,安全可控;功能强大,足以应对大多数场景;使用简单,几乎没有学习成本。
2. 准备工作:三分钟搞定基础环境
部署这个镜像,你只需要准备两样东西:一台电脑(或服务器)和Docker。如果你的系统已经安装了Docker,可以直接跳到下一节。如果没有,请按照下面的步骤快速安装。
2.1 安装Docker
Docker是一个容器化平台,可以理解为一种轻量级的虚拟机。它能让我们的应用在任何系统上都以相同的方式运行,避免了“在我电脑上是好的”这种问题。
对于Windows/macOS用户: 访问 Docker 官网(docker.com),下载对应的 Docker Desktop 安装包,像安装普通软件一样完成安装。安装后,在开始菜单或应用程序中找到并启动“Docker Desktop”。
对于Linux用户(以Ubuntu为例): 打开终端,依次执行以下命令:
# 更新软件包列表
sudo apt-get update
# 安装必要的依赖
sudo apt-get install ca-certificates curl gnupg
# 添加Docker官方GPG密钥
sudo install -m 0755 -d /etc/apt/keyrings
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo gpg --dearmor -o /etc/apt/keyrings/docker.gpg
sudo chmod a+r /etc/apt/keyrings/docker.gpg
# 设置Docker仓库
echo \
"deb [arch="$(dpkg --print-architecture)" signed-by=/etc/apt/keyrings/docker.gpg] https://download.docker.com/linux/ubuntu \
"$(. /etc/os-release && echo "$VERSION_CODENAME")" stable" | \
sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
# 安装Docker引擎
sudo apt-get update
sudo apt-get install docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin
# 验证安装(可选)
sudo docker run hello-world
安装完成后,在终端输入 docker --version,如果能看到版本号,说明安装成功。
2.2 获取镜像
环境准备好了,我们现在来获取Speech Seaco的镜像。科哥已经将镜像托管在了公共仓库,我们只需要一行命令来拉取。
打开你的终端(Windows用户可以使用PowerShell或CMD,确保Docker Desktop正在运行),输入以下命令:
docker pull registry.cn-hangzhou.aliyuncs.com/csdn_mirrors/speech_seaco_paraformer:latest
这行命令会从阿里云镜像仓库下载最新的Speech Seaco镜像。下载时间取决于你的网速,镜像大小约几个GB,请耐心等待。看到“Status: Downloaded newer image for...”的提示,就表示下载完成了。
3. 一键部署:启动你的语音识别服务
镜像下载完毕,部署步骤简单到令人发指。只需要一条命令,服务就会在后台运行起来。
在终端中,运行以下命令:
docker run -d --name speech_seaco -p 7860:7860 registry.cn-hangzhou.aliyuncs.com/csdn_mirrors/speech_seaco_paraformer:latest
我们来拆解一下这条命令:
docker run:运行一个容器。-d:让容器在“后台”运行,这样你不会被日志刷屏,可以关掉终端。--name speech_seaco:给这个容器起个名字,方便后续管理,比如停止或重启。-p 7860:7860:这是最关键的部分。它将容器内部的7860端口映射到你电脑的7860端口。这样,你才能通过浏览器访问服务。- 最后一段就是刚才下载的镜像地址。
执行命令后,你会看到一串长长的容器ID。此时,服务已经在后台启动了。首次启动需要加载模型,可能需要1-2分钟。你可以通过以下命令查看容器日志,确认是否启动成功:
docker logs -f speech_seaco
当你看到日志中出现类似 Running on local URL: http://0.0.0.0:7860 的信息时,就说明服务已经就绪。
访问服务:打开你的浏览器,在地址栏输入 http://localhost:7860。如果一切顺利,你将看到Speech Seaco Paraformer的Web操作界面。
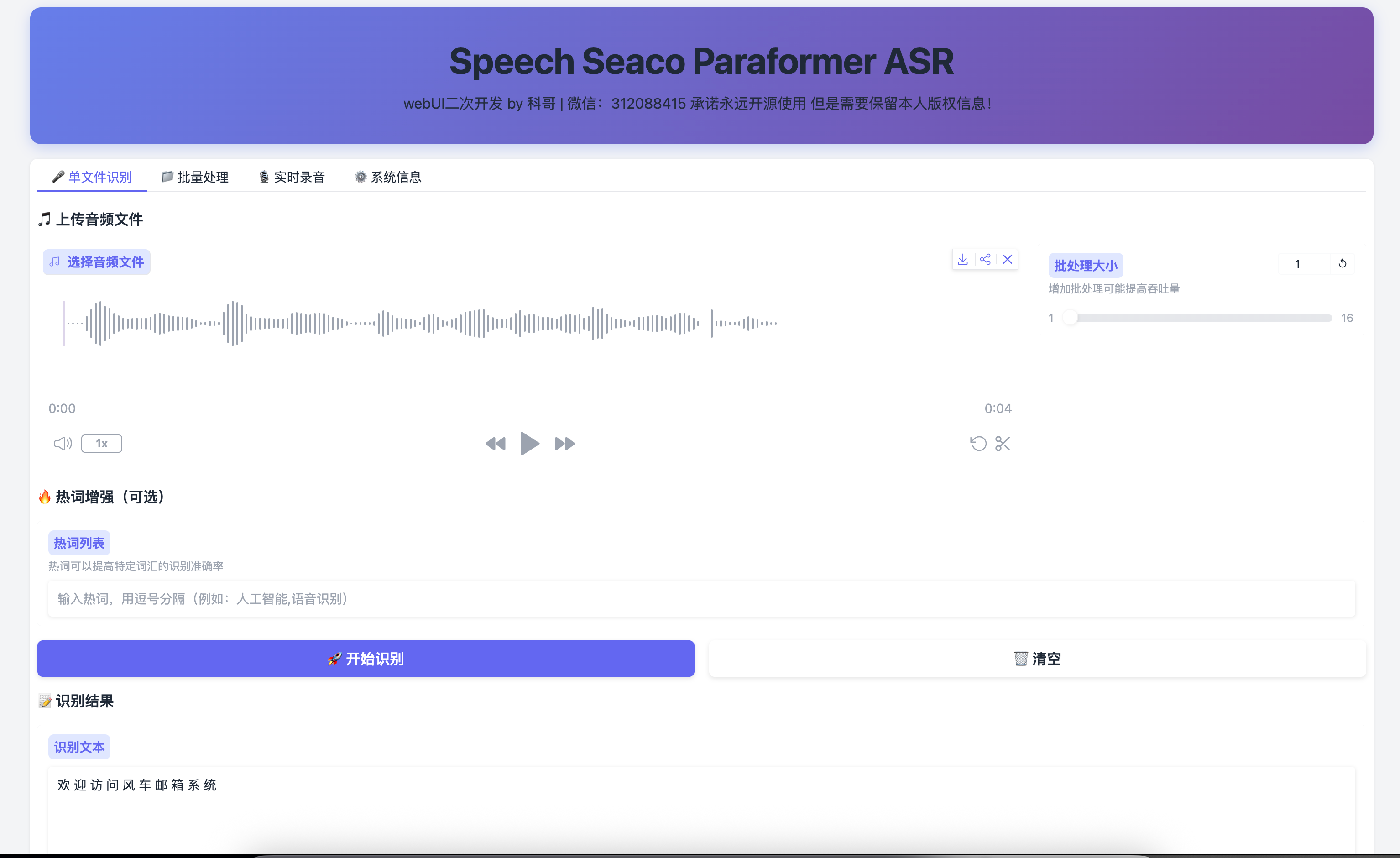
4. 功能详解:像使用App一样操作
这个Web界面设计得非常直观,主要分为四个功能标签页,我们一个一个来看怎么用。
4.1 单文件识别:处理单个录音
这是最常用的功能。你有一段会议录音、采访音频,或者自己录的一段语音备忘录,想把它变成文字。
- 上传文件:点击“选择音频文件”按钮,支持 MP3, WAV, M4A, FLAC 等多种常见格式。
- 设置热词(可选但推荐):在“热词列表”输入框中,填入你这段音频里可能出现的、比较生僻或重要的词汇。比如,音频内容是关于“量子计算”的,你可以输入
量子比特, 叠加态, 薛定谔的猫。多个热词用英文逗号隔开。这个功能能极大提升专业词汇的识别准确率。 - 开始识别:点击那个醒目的 「🚀 开始识别」 按钮。
- 查看结果:稍等片刻(处理速度通常是音频长度的1/5到1/10),识别出的文字就会显示在下方。点击“📊 详细信息”还可以看到识别置信度、处理耗时等详细信息。
小技巧:对于重要的音频,识别完成后,务必仔细核对一下。虽然模型准确率很高,但对于口音、背景噪音或多人快速交谈的场景,可能仍有少量错误,人工校对一遍是值得的。
4.2 批量处理:解放双手的利器
如果你有多个音频文件需要处理,比如一周的会议记录、一系列采访录音,那么这个功能就是为你准备的。
- 切换到 「📁 批量处理」 标签页。
- 点击“选择多个音频文件”,可以按住Ctrl键(或Cmd键)多选。
- 点击 「🚀 批量识别」。
- 系统会按顺序处理所有文件,并以一个清晰的表格展示结果,包括每个文件的文件名、识别文本和置信度。你可以一目了然地查看所有结果,并复制需要的文本。
4.3 实时录音:边说边转文字
这个功能适合需要即时记录的场景,比如临时会议纪要、灵感速记,或者单纯想体验一下实时识别的感觉。
- 切换到 「🎙️ 实时录音」 标签页。
- 首次使用,浏览器会请求麦克风权限,点击“允许”。
- 点击麦克风按钮开始录音,对着麦克风清晰说话。
- 说完后,再次点击按钮停止录音。
- 点击 「🚀 识别录音」,你刚才说的话就会变成文字。
4.4 系统信息:看看“家底”
在 「⚙️ 系统信息」 标签页,你可以看到当前服务运行的基础信息,比如使用的模型名称、运行设备(是CPU还是GPU)、Python版本等。点击“🔄 刷新信息”可以更新状态。这个页面主要用于确认服务运行是否正常。
5. 进阶技巧与常见问题
5.1 如何重启或停止服务?
如果你需要重启容器(比如修改了某些配置,或者服务出现异常),不需要重新运行 docker run 命令。
- 重启容器:在终端运行
/bin/bash /root/run.sh。这个命令是容器内部预设的启动脚本。 - 停止容器:在终端运行
docker stop speech_seaco。 - 启动已停止的容器:运行
docker start speech_seaco。 - 彻底删除容器:如果你想从头开始,可以先停止容器
docker stop speech_seaco,然后删除docker rm speech_seaco,最后再重新执行第3节的docker run命令。
5.2 提升识别准确率的秘诀
- 用好热词:这是最重要的技巧。把你领域内的专有名词、产品名、人名、地名提前输入,效果立竿见影。
- 保证音质:尽量使用清晰的音源。如果原始录音噪音大,可以先用音频编辑软件(如Audacity)进行简单的降噪处理。
- 控制时长:单次识别的音频建议不要超过5分钟。过长的音频可能会导致处理时间变长,或增加内存占用。对于很长的录音,可以先用音频切割工具分成小段。
- 选择合适格式:WAV或FLAC等无损格式的识别效果通常比高压缩率的MP3要好。
5.3 常见问题解答
- Q:访问
localhost:7860打不开页面怎么办? A:首先确认容器是否在运行(docker ps命令查看)。如果运行中,可能是端口冲突。尝试将命令中的-p 7860:7860改为-p 7861:7860,然后通过http://localhost:7861访问。 - Q:识别速度很慢怎么办? A:默认情况下,镜像使用CPU进行推理。如果你的电脑有NVIDIA GPU并安装了CUDA驱动,可以尝试在
docker run命令中加入--gpus all参数来启用GPU加速,速度会有显著提升。 - Q:识别结果中有一些错误怎么办? A:这是正常现象,即使是顶级的ASR模型也无法保证100%准确。结合“热词”功能,并对关键内容进行人工校对,是目前最可靠的方案。
- Q:支持英文或其他语言吗? A:Speech Seaco Paraformer这个模型主要针对中文普通话优化。对于中英混杂的场景,它有一定的识别能力,但纯英文或其他语言的识别效果可能不佳。
6. 总结
通过以上步骤,你已经成功在本地部署了一个功能完整、易于使用的阿里级中文语音识别服务。我们来回顾一下关键点:
- 价值:你获得了一个本地化、高精度、支持热词定制的语音转文字工具,数据隐私和安全得到保障。
- 部署:过程极其简单,只需安装Docker和运行两条命令(
docker pull和docker run),无需任何复杂的深度学习环境配置。 - 使用:通过直观的Web界面,你可以轻松完成单文件识别、批量处理和实时录音转写,热词功能能有效提升专业场景的准确率。
- 管理:服务以Docker容器形式运行,启动、停止、重启都非常方便,不污染你的主机环境。
无论你是需要处理日常录音的普通用户,还是想在项目中集成ASR能力的开发者,Speech Seaco Paraformer这个免配置镜像都是一个绝佳的选择。它降低了顶尖AI技术的使用门槛,让每个人都能轻松享受语音识别带来的效率提升。
现在,就去找一段录音试试吧,感受一下从声音到文字的魔法。
获取更多AI镜像
想探索更多AI镜像和应用场景?访问 CSDN星图镜像广场,提供丰富的预置镜像,覆盖大模型推理、图像生成、视频生成、模型微调等多个领域,支持一键部署。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 1
1 0
0- 0



 已为社区贡献166条内容
已为社区贡献166条内容

所有评论(0)