ETL 如何处理企业数据?ETL 实操要点有哪些?
ETL是企业数据处理的核心环节,做好ETL才能让分散的数据形成有效资产,而多数人对ETL的实际处理流程却一知半解。开始之前给大家分享一份数字化全流程资料包https://s.fanruan.com/pxb9h,里面有名企CIO的ETL相关数据化建设心得,还有从0-1做数据建设、搭建数据指标体系的干货内容,能帮我们从底层理解ETL在数据建设中的逻辑。接触数据工作这些年,我发现凡是数据应用做得好的企业,必然把ETL的每一个环节做透了,ETL的处理能力直接决定了数据的质量,也决定了后续数据分析和业务决策的有效性,你懂我意思吗?
用过来人的经验告诉你,做数据工作最忌讳的就是只知道ETL的概念,却摸不清实际的处理步骤,很多企业数据孤岛难以打破,核心问题就是ETL处理流程出了问题。这篇文章我会把自己多年做ETL数据处理的实操经验讲透,从核心流程到具体操作,再到工具选择和问题解决,全是实打实的干货,看完就能落地操作。
一、ETL 处理数据的核心逻辑与整体流程
简单来说,ETL 就是抽取(Extract)、转换(Transform)、加载(Load)的简称,这三个步骤是 ETL 处理数据的核心,缺一不可,且必须按照固定的逻辑推进,跳过任何一步或者打乱顺序,都会导致数据处理失败。我一直强调,做 ETL 不是简单的数据搬运,而是让数据从 “分散、杂乱、无价值” 变成 “统一、规范、有价值” 的过程,而这个过程的核心,就是把抽取、转换、加载的每一个细节做到位。
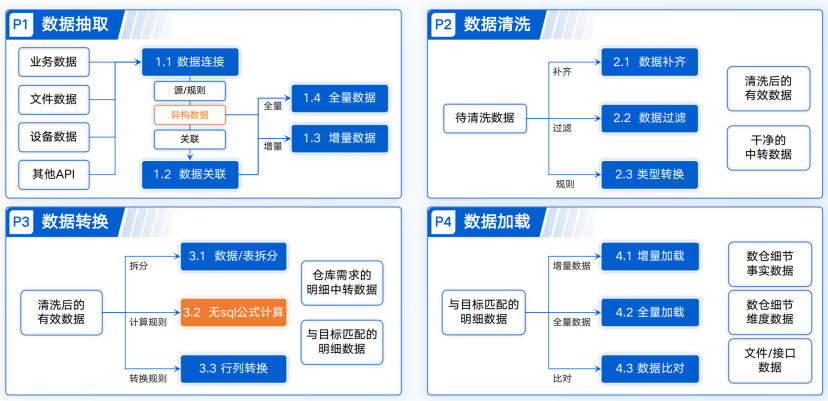
1. ETL 处理数据的核心原则
- 数据真实性:抽取的原始数据必须保留源数据的真实状态,不做任何主观修改,这是后续所有处理的基础,一旦原始数据失真,后续转换和加载再精细也毫无意义。
- 处理标准化:转换环节的所有操作必须制定统一的标准,比如日期格式、数值单位、字段命名,避免因标准不统一导致数据无法整合。
- 加载适配性:加载到目标系统的数据,必须适配目标系统的存储结构和使用需求,比如数据仓库的分层架构、BI 分析的字段要求。
2. ETL 处理数据的整体流转思路
企业的原始数据分散在 MySQL、Oracle、Excel 文件、API 接口等不同的数据源中,这些数据各自独立,形成数据孤岛。ETL 的整体思路就是先从这些分散的数据源中提取数据,再按照业务需求和统一标准进行清洗、转换,最后将处理后的标准数据加载到数据仓库、数据湖等目标系统,为后续的 BI 分析、业务决策提供数据支撑。说白了,ETL 就是企业数据的 “加工流水线”,从源头取料,到车间加工,再到成品入库,每一个环节都有明确的操作要求。
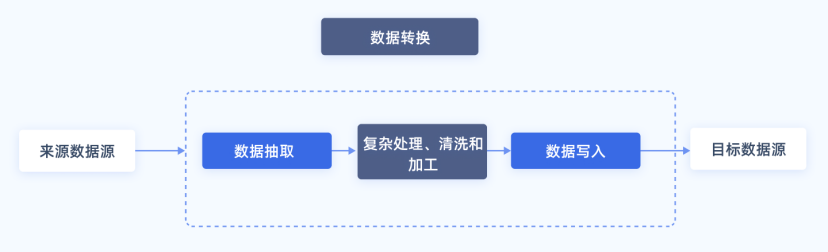
二、ETL 处理数据的三步实操详解
1. 抽取:从源系统高效获取原始数据
抽取是 ETL 处理数据的第一步,核心目标是高效、低侵入地从源系统获取数据,既不能影响源系统的正常业务运行,又要保证数据的完整性。抽取的方式主要分为全量抽取和增量抽取两种,具体选择哪种方式,要根据数据量和业务需求来定。
- 全量抽取:简单来说,就是一次性提取源系统中的所有数据,适用场景主要是首次做数据加载,或者源系统的数据量较小的情况。优点是简单直接,缺点是会传输冗余数据,对源系统资源有一定消耗,因此不适合日常的高频数据同步。
- 增量抽取:仅提取源系统中发生变化的数据,适用场景是日常的数更新,或者源系统的数据量较大的情况。这是企业日常 ETL 工作中最常用的方式,能有效降低资源消耗,提升抽取效率。增量抽取的技术主要有三种:时间戳抽取,操作简单但可能出现数据遗漏;日志解析(CDC 技术),通过 MySQL Binlog、Oracle Redo Log 捕获数据变更,准确性高,是目前主流的增量抽取方式;触发器抽取,在源表增删改时触发数据同步,侵入性高,不推荐在生产环境使用。
我在实际工作中总结了一个抽取小技巧:首次加载用全量抽取,后续日常同步用 CDC 技术做增量抽取,既能保证数据的完整性,又能最大程度降低对源系统的影响。
2. 转换:对原始数据做清洗与标准化
转换是 ETL 处理数据中最核心、最耗时的步骤,也是决定数据质量的关键步骤,据 Gartner 统计,转换环节的工作占据了 ETL 整体工作量的 60%-80%。核心目标是将杂乱的原始数据转化为满足业务需求的标准数据,典型的操作包括数据清洗、格式转换、业务计算、多表关联等,每一个操作都有明确的实操要点。
- 数据清洗:这是转换的基础操作,主要解决原始数据中的缺失值、重复值、异常值问题。缺失值处理要分类解决,非关键字段且缺失比例低的可以直接删除,关键字段可以填充 “未知” 或用均值、中位数填充;重复值处理要先确定唯一键;异常值处理常用 3σ 原则,过滤掉偏离正常范围的数据。
- 格式标准化:将不同格式的字段统一为标准格式。
- 业务计算与关联:根据业务需求对数据进行计算。
3. 加载:将标准数据写入目标系统
加载是 ETL 处理数据的最后一步,核心目标是高效、可靠地将转换后的标准数据写入目标系统,常见的目标系统包括数据仓库、数据湖、业务数据库等。加载的策略主要分为全量加载、增量加载、批量加载三种,具体选择要根据目标系统的类型和数据使用需求来定。
- 全量加载:先清空目标表的原有数据,再将转换后的数据全部插入。
- 增量加载:仅将新增或变更的数据插入或更新到目标表。
- 批量加载:利用数据库原生接口将数据批量写入目标系统,亿级数据加载必须采用这种方式。
加载环节有一个关键注意点:加载前必须对数据进行最后一次校验,确认数据格式、字段类型与目标系统完全匹配,避免因格式不匹配导致加载失败,同时要根据目标系统的存储结构做好分区和索引,提升后续数据查询和分析的效率。
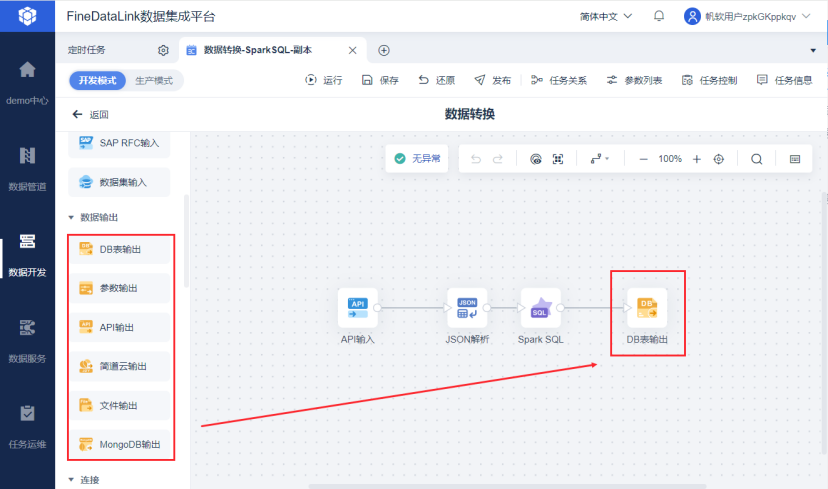
三、ETL数据处理的工具选择与实操优化
用过来人的经验告诉你,做好ETL数据处理,光懂流程还不够,选对工具并做好流程优化,才能让ETL工作事半功倍。很多企业投入了大量的人力和时间做ETL,却效果不佳,要么是工具选得不合适,要么是没有做好流程优化,导致数据处理效率低、质量差。
1. ETL数据处理的工具选型要点
选择ETL工具,核心要关注三个指标:一是数据源兼容性,能否连接企业内的所有数据源,包括数据库、ERP、Excel、API接口等;二是操作门槛,是否适合企业的技术团队和业务团队使用;三是性能与稳定性,能否支撑大数据量的处理,且保证任务运行的稳定性。
传统的开源ETL工具如Spark、Flink,功能强大但需要专业的技术人员进行开发和维护,学习成本高,适合技术团队完善的大型企业。而对于大多数中小企业,或者需要业务团队参与数据处理的企业,低代码ETL平台是更优选择,其中FineDataLink 是目前国内性价比很高的一站式数据集成平台,它支持四十多家数据源的对接,覆盖了企业常见的数据库、文件、接口等,操作上采用拖拽式的DAG可视化设计,非技术人员也能快速上手,同时支持Kafka实时流处理、Python算法扩展,既能满足日常的批量数据处理,也能支撑实时ETL的需求,大大降低了企业的ETL建设成本。感兴趣的可以免费体验:https://s.fanruan.com/ysq87
2. ETL数据处理的全流程优化技巧
我在实际工作中总结了一套ETL流程优化技巧,覆盖抽取、转换、加载三个环节,落地后能有效提升处理效率,降低问题发生率:
- 抽取阶段优化:优先使用CDC工具做增量抽取,替代定时全表扫描,能让源库的CPU占用降低70%;同时采用并行抽取,按主键分片,抽取速度与分片数正相关。
四、ETL 数据处理的常见问题与解决方法
在多年的 ETL 实操工作中,我遇到过各种各样的问题,比如数据重复、格式错误、加载失败、任务延迟等,这些问题看似复杂,其实都有固定的解决方法。下面我把最常见的三类问题和对应的解决方法讲清楚,帮大家避开坑。
|
问题类型 |
核心成因 |
标准化解决方法 |
|
数据质量问题(缺失、重复、异常) |
原始数据本身存在缺陷,ETL处理过程中未做全流程校验,导致无效数据流入目标库 |
构建“数据质量防火墙”,让数据质量处理贯穿ETL全流程;缺失值按字段重要性分类处理,不一刀切;重复值通过唯一键+group by语句去重,保留最新数据;异常值通过3σ原则或业务规则过滤,同时对核心字段设置数据校验规则 |
|
任务运行问题(失败、延迟、资源占用过高) |
配置参数有误、数据处理逻辑低效、抽取方式不合理,导致任务异常或占用过多系统资源 |
任务失败:做好数据源配置校验,确保IP、端口、账号密码正确、网络可达,统一源数据和目标数据格式;任务延迟:优化抽取和转换策略,采用并行处理和批量加载;资源占用过高:改用增量抽取,替代全量抽取和全表扫描,减少对源系统的资源消耗 |
|
数据一致性问题(源数据与目标数据不一致) |
增量同步、实时ETL场景下,数据变更捕获不精准,加载环节无校验机制 |
采用CDC技术捕获数据变更,保证数据同步的实时性和准确性;在加载环节设置数据校验机制,对比源数据和目标数据的条数、核心字段值,一旦出现不一致,及时触发告警并重新同步 |
五、常见问答(Q&A)
Q1:中小企业做 ETL 数据处理,是否需要投入大量的技术人员?
A:不需要。中小企业的数据源和数据量相对有限,无需使用复杂的开源 ETL 工具,选择像 FineDataLink 这样的低代码 ETL 平台,拖拽式操作无需编写大量代码,技术人员只需做好基础配置,业务人员也能参与到数据处理中,大大降低了技术人员的投入。
Q2:ETL 处理数据时,如何平衡数据实时性和系统稳定性?
A:核心是根据业务需求选择合适的 ETL 模式,对于需要实时数据的业务,比如电商的实时交易监控,采用 CDC 技术做实时 ETL,同时控制实时同步的频率,避免对源系统造成过大压力;对于非实时需求的业务,比如日结、月结分析,采用批量 ETL,在凌晨系统负载低的时候执行任务,既保证数据的完整性,又不影响系统稳定性。
Q3:ETL处理跨数据源数据时,该怎么统一数据口径?
A:跨数据源ETL最容易出现口径混乱问题,解决核心是先定标准、再做映射、最后校验。第一步梳理全业务域统一的数据字典,明确字段名称、计算逻辑、单位、枚举值等标准,杜绝各数据源自定义口径;第二步建立数据源字段映射规则,将不同源系统的同含义字段对应到统一标准字段,第三步在转换环节加入口径校验节点,对核心指标做逻辑校验,确保跨数据源整合后的数据口径一致、数值可比对,从根源避免数据口径偏差导致的分析失误。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 10
10 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)