分布式数据库学习
HDFS
一.HDFS概述
1.1 HDFS产生背景
随着数据量越来越大,在一个操作系统存不下所有的数据,那么就分配到更多的操作系统的管理的磁盘中,但是不方便管理和维护,迫切需要一个系统来管理多台机器上的文件,这就是分布式文件管理系统。HDFS只是分布式文件系统管理中的一种。
1.2 HDFS定义
HDFS(Hadoop Distributed File System),它是一个文件系统,用于存储文件,通过目录树来定位文件;其次,它是分布式的,有很多服务器联合起来实现其功能,集群中的服务器有各自的角色。
HDFS的使用场景:适合一次写入,多次读出的场景,且不支持文件的修改,适合用来做数据分析,并不适合来做网盘应用。
1.3 HDFS的优缺点
优点:
(1)高容错性
- 数据自动保存多个副本。它通过增加副本的形式,提高容错性。
- 某一个副本丢失以后,它可以自动恢复。
(2)适合处理大数据
- 数据模型:能够处理数据规模达到GB,TB,甚至PB级别的数据;
- 文件规模:能够处理百万规模以上的文件数据,数量相当之大
(3) 可构建在廉价的机器上,通过多副本机构,提高可靠性。
缺点:
(1)不适合低延时数据访问,比如毫秒级的存储数据,是做不到的。
(2)无法高效地对大量小文件进行存储。
- 存储大量小文件的话,它会占用NameNode大量的内存来存储文件目录和块信息。这样是不可取的,因为NameNode的内存总是有限的;
- 小文件存储的寻址时间会超过读取时间,它违反了HDFS的设计目标。
(3)不支持并发写入,文件随机修改。
一个文件只能有一个写,不允许多个线程同时写;
仅支持数据append(追加),不支持文件的随机修改
1.4HDFS组成架构
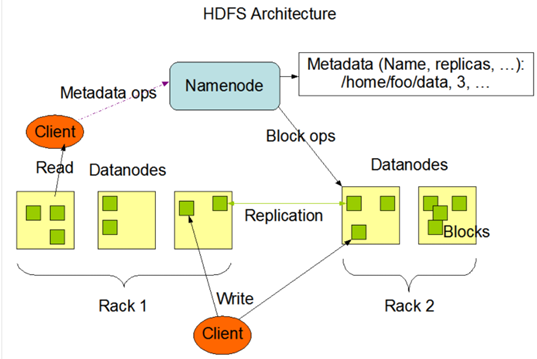
NameNode(nn):就是Master(管理者),它是一个主管,管理者。
- 管理HDFS的名称空间;
- 配置副本策略;
- 管理数据块的映射信息;
- 处理客户端的读写请求。
DataNode:就是Slave.NameNode下达命令。DataNode执行实际的操作。
- 存储实际的数据块。
- 执行数据块的读/写操作。
Client:就是客户端
- 文件切分。文件上传HDFS的时候,Client将文件切分成一个一个的Block,然后进行上传。
- 与NameNode交互,获取文件的位置信息;
- 与DataNode交互,读取或者写入数据;
- Client提供一些命令来管理HDFS,比如NameNode格式化;
- Client可以通过一些命令来访问HDFS,比如对HDFS增删改查操作。
Secondary NameNode:并非NameNode的热备,当NameNode挂掉的时候,它不能马上替换NameNode并提供服务。(查一下Fsimage和Edits是干什么的,原理是什么)
- 辅助NameNode,分担其工作量,比如定期合并Fsimage和Edits,并推送给NameNode;
- 在紧急情况下,可辅助恢复NameNode。
作业Fsimage和Edits:
内存(快,断电容易丢失)edits:编辑文件
硬盘 Fsimage:为了防止断电数据丢失,会落盘为fsimage
edits1:2026.4.14日10:30-10:40 新的东西
edits2:2026.4.14日10:40-10:50 新的东西
Secondary NameNode:fsimage2=fsimage1+edits1+edits2
同步传给namenode,会存fsimage2
name
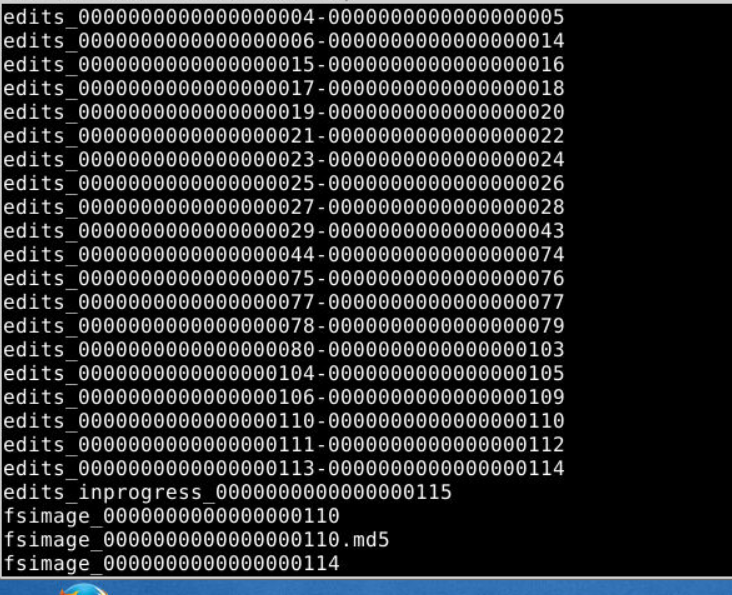
secondary namenode
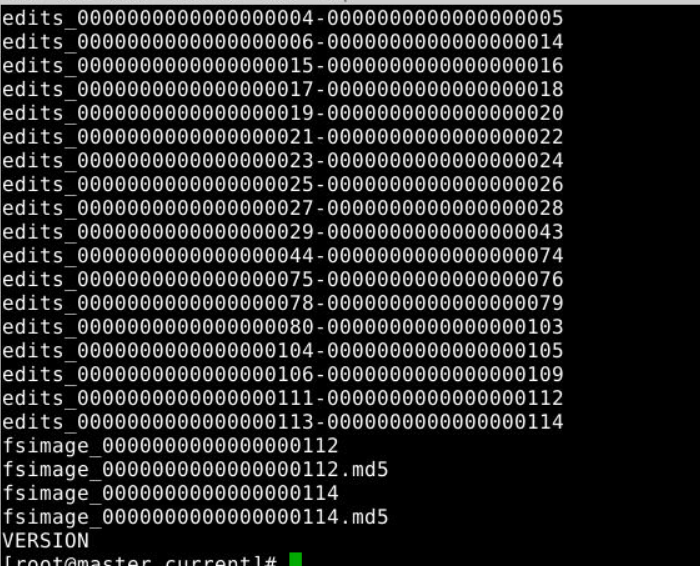
只不过namenode会多一个edits inprogeress
1.namenode fsimage edits 会跟secondarynamenode同步
2.secondarynamenode会把fsimage edits 加起来得到一个新的fsimage,传回给namenode
namenode(物理地址):/usr/local/hadoop/tmp/dfs
1.5 HDFS文件块大小(面试重点)
HDFS中的文件在物理上是分块存储(Block),块的大小可以通过参数配置(dfs.blocksize)来规定,默认大小在Hadoop2.X版本是128M,老版本是64M
block1 block2 ......block65 block66
1.如果寻址时间约为10ms,即找到目标block的时间为10ms
2.寻址时间为传输时间的1%时,则为最佳状态。传输时间=10ms/0.01=1s
3.目标磁盘的传输速率普遍为100MB/S 块大小:100MB/s*1s=100M 128M
普通机械硬盘 80M/s-90M/s 块大小:80-90M 128M,64M
固定硬盘 200M/s-300M/s 块大小:200-300M 256M
思考:为什么块的大小不能设置太小,也不能设置太大?
(1)HDFS的块设置大小,会增加寻址时间,程序一直找,块的开始位置。(找目标快)
(2)如果快设置的太大,从磁盘传输数据的时间会明显大于定位合格块开始位置的时间(寻址时间)。导致程序在处理这块数据时,会非常慢。
总结:HDFS块的大小设置主要取决于磁盘的传输速率。
1.6 HDFS的Shell操作
1.基本的语法
bin/ 下hadoop fs 具体命令
bin/ 下hdfs dfs 具体命令
两个完全相同
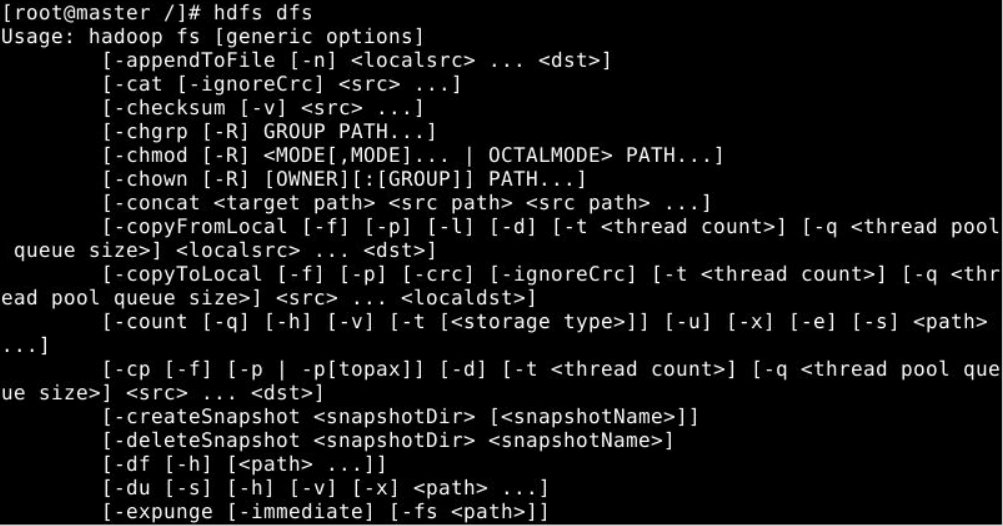
2.常用命令
(0)启动Hadoop集群
sbin/下start-dfs.sh 启动hdfs系统
sbin/下start-yarn.sh 启动yarn
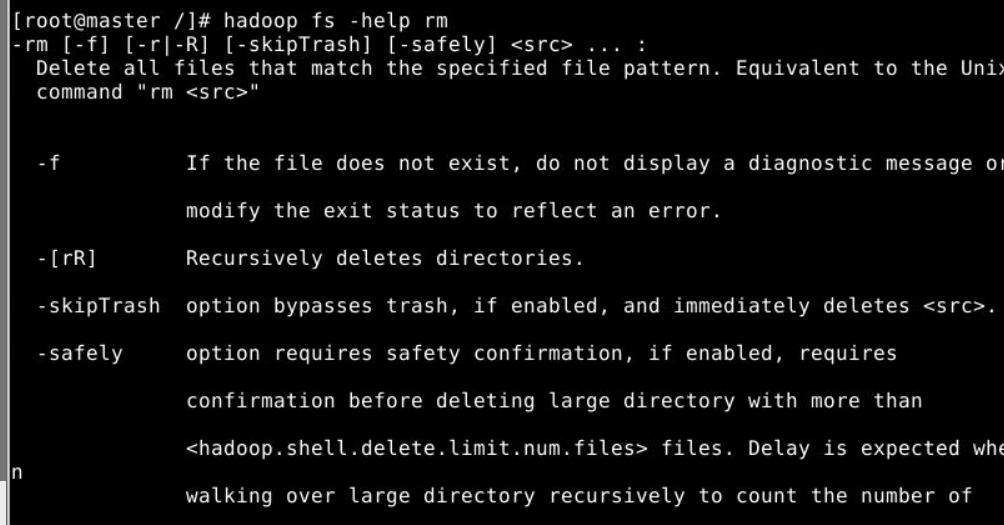
(1)-help:输出这个命令参数
hadoop fs -help rm :输出rm这个命令的相关解释以及参数说明
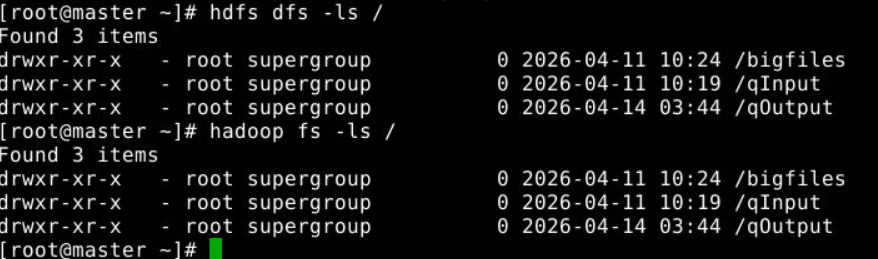
(2)-ls:显示目录信息
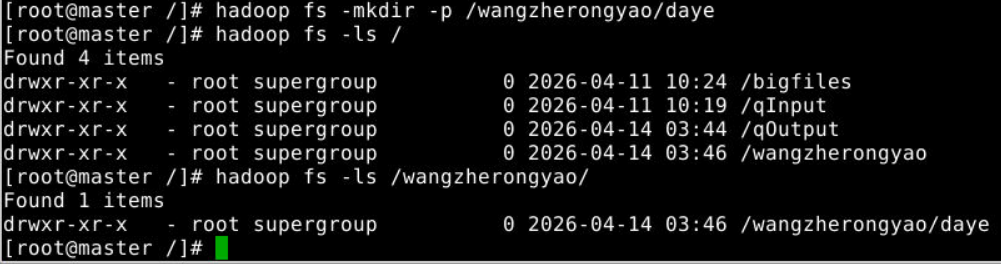
(3)-mkdir:在HDFS上创建文件夹()
hadoop fs -mkdir -p /wangzherongyao/daye
(4)-moveFromLocal:从本地剪切粘贴到HDFS
1.本地有一个文件
touch buzhihuowu.txt 创建buzhihuowu.txt这个空文件
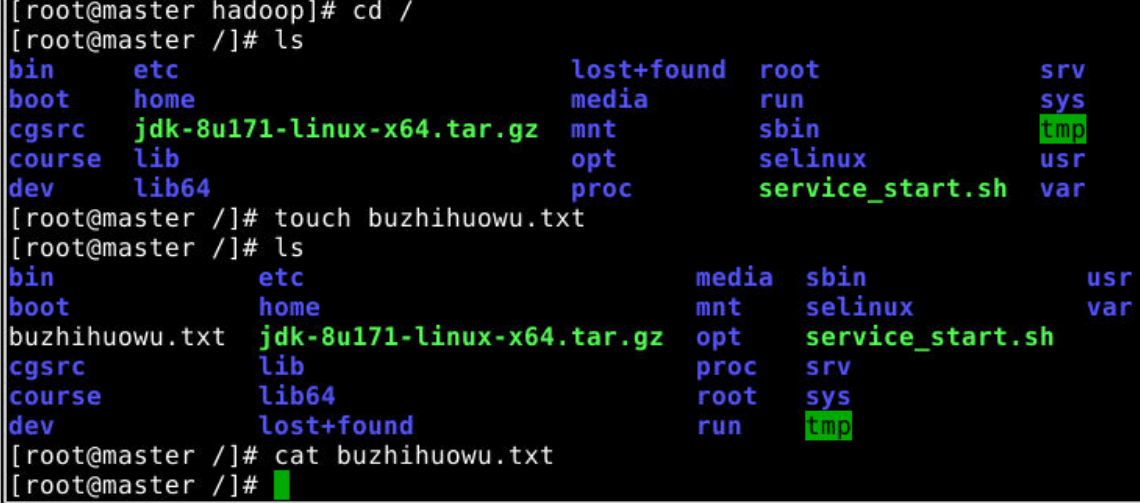
2.将本地的文件剪切,粘贴到HDFS系统里面
hadoop fs -moveFromLocal 本地文件 HDFS里面的文件:从本地文件复制到HDFS文件里面
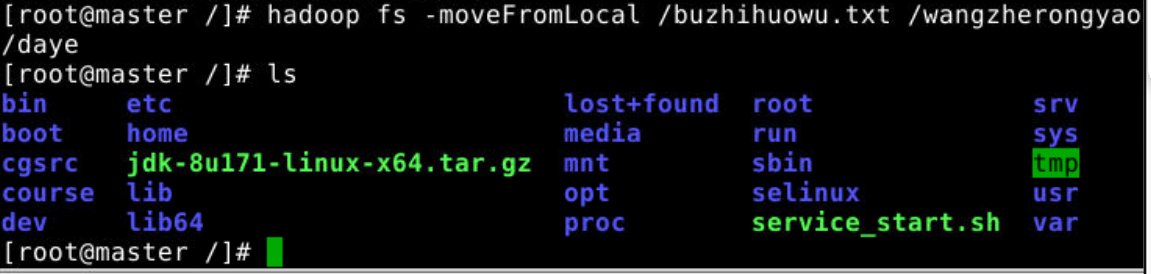
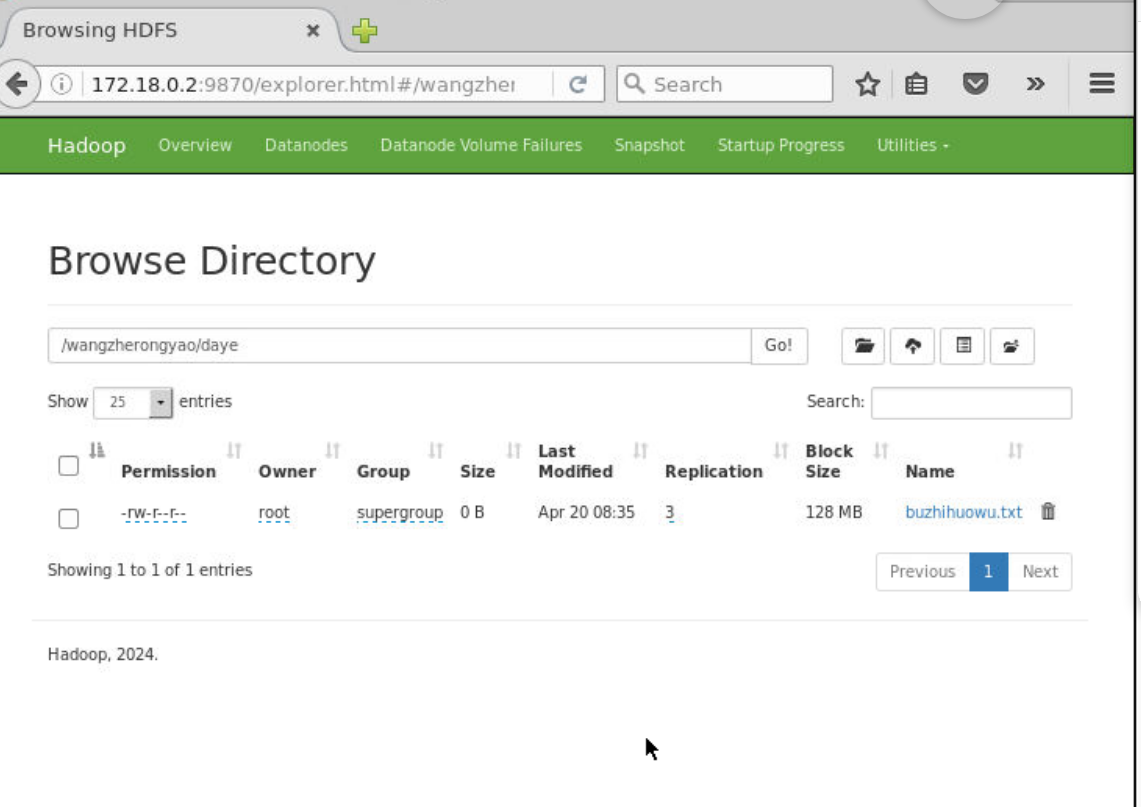
(5)-appendToFile:追加一个文件到已经存在的文件末尾。
1.本地文件(一般是有内容的)
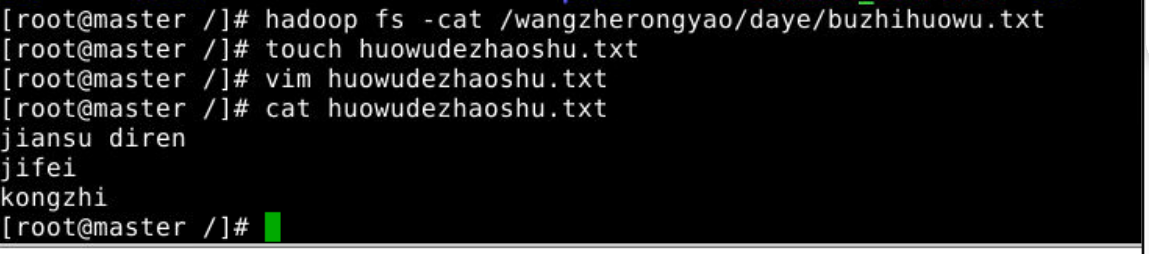
2.把本地文件的内容放到 (HDFS系统里面已经存在的) 文件的末尾
hadoop fs -appendToFile 本地文件 HDFS的文件:把本地文件的内容放到HDFS里面

(6)-cat:显示文件内容

(7)-chgrp,chmod,chown:Linux文件系统中的用法一样,修改文件所属的权限
(ch:change,grp:group分组,mod:mode权限,own:owner拥有者)
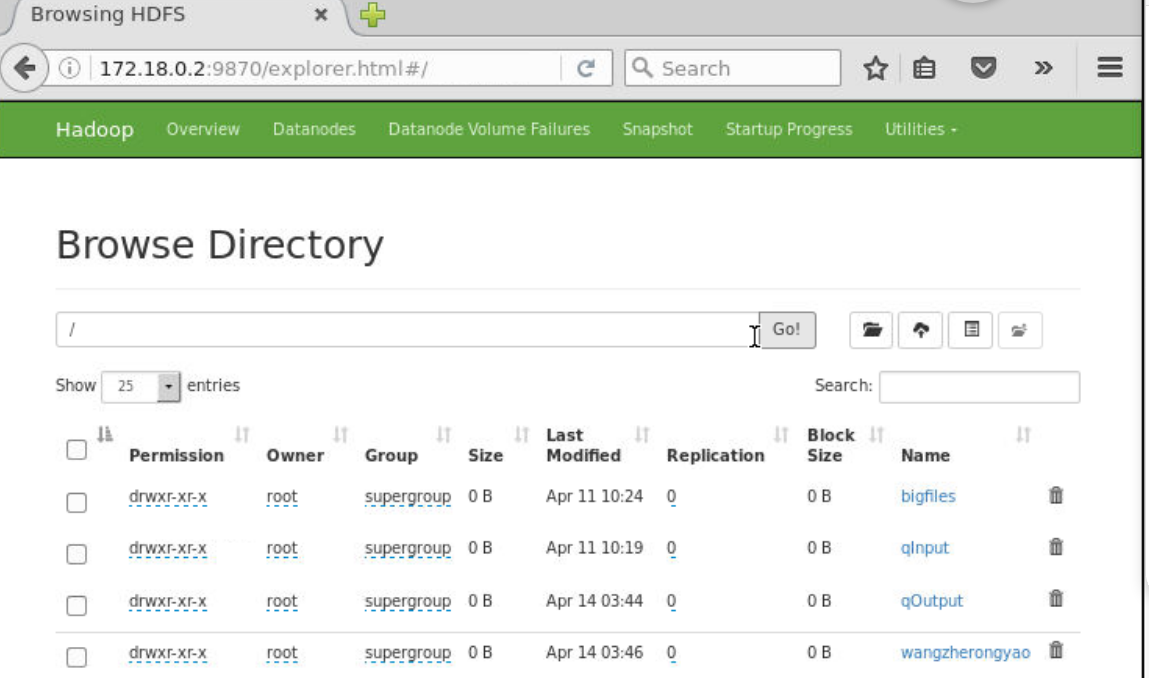
chgrp [R] 组名 文件或者目录名:更改文件/目录所属的用户组
hadoop fs -chgrp 新改的组名 文件或者文件夹
![]()
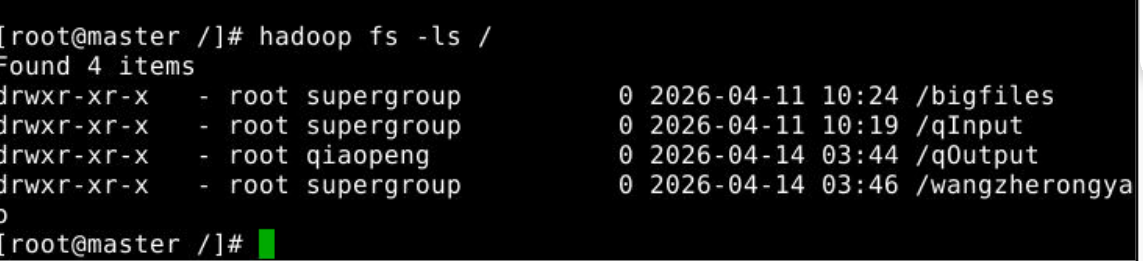
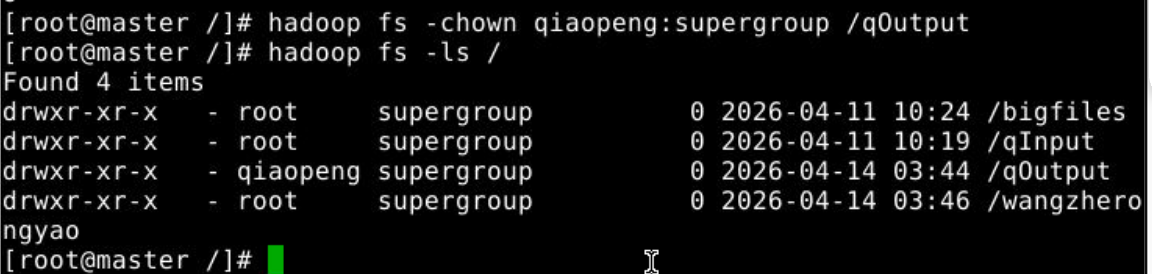
chown:修改文件/目录所有者
hadoop fs -chown 更改为所有者:组名 文件或者文件夹
1.7HDFS客户端操作
master,slave1,slave2,slave3
hdfs客户端代码 ,可以控制整个集群
1.pom.xml
<!--dependencies代表这个项目所有的依赖 -->
<dependencies>
<!--junit单元测试类 -->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
<!-- log4j 打印日志,日志等级-->
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-slf4j-impl</artifactId>
<version>2.12.0</version>
</dependency>
<!-- hadoop的客户端-->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.1.3</version>
</dependency>
</dependencies>2.log4j2.xml
<?xml version="1.0" encoding="UTF-8"?>
<Configuration status="error" strict="true" name="XMLConfig">
<Appenders>
<!-- 类型名为Console,名称为必须属性 -->
<Appender type="Console" name="STDOUT">
<!-- 布局为PatternLayout的方式,
输出样式为[INFO] [2018-01-22 17:34:01][org.test.Console]I'm here -->
<Layout type="PatternLayout"
pattern="[%p] [%d{yyyy-MM-dd HH:mm:ss}][%c{10}]%m%n" />
</Appender>
</Appenders>
<Loggers>
<!-- 可加性为false -->
<Logger name="test" level="info" additivity="false">
<AppenderRef ref="STDOUT" />
</Logger>
<!-- root loggerConfig设置 -->
<Root level="info">
<AppenderRef ref="STDOUT" />
</Root>
</Loggers>
</Configuration>3.HdfsClient

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)