Oceanus+TCHouse-C 构建轻量云原生实时数仓实战
前言
在高并发实时数据分析场景下,传统自建 Flink + ClickHouse 架构存在开发重、运维复杂、扩展成本高、集群维护难度大等问题。为解决这些痛点,本文基于腾讯云 Oceanus 与 TCHouse-C 构建一套轻量、稳定、可水平扩展的云原生实时数仓方案。
简单说明核心组件:
- Oceanus:腾讯云基于 Apache Flink 构建的全托管流式计算服务,提供开箱即用、高稳定、易扩展的流计算能力。
- TCHouse-C:腾讯云自研的分布式 ClickHouse 云原生服务,兼容开源 ClickHouse 协议,具备高性能、高并发、低成本、免运维等特点,非常适合实时数仓、大屏分析、多维聚合等场景。
本次实践采用 配置化多链路分发 + 计算下沉到存储层 的设计思路,通过自研 Flink DataSync 通用 Jar 包实现数据源与 Sink 动态扩展,无需修改代码、无需重启作业,即可快速新增链路,大幅降低实时数仓的建设与维护成本。
一、业务场景与核心需求
1.1 典型业务场景
本次实践面向高并发实时数据分析通用场景,需处理千万级业务数据,支撑多渠道、多角色的全链路数据处理,核心特征:
- 多渠道数据接入:同时支撑多类业务渠道数据,需按渠道隔离分析核心指标;
- 强实时需求:业务侧需实时查看核心数据指标,摒弃传统 T+1 离线计算模式;
- 多角色数据需求:覆盖运营、业务、财务等多角色,需提供个性化数据服务;
- 多链路数据落地:除实时数仓分析外,还需支撑离线批量处理、核心数据持久化、检索分析等多场景;
- 高可靠要求:核心业务链路数据准确率≥99.99%,支持故障快速定位与恢复。
1.2 核心技术指标与设计要求
1.2.1 核心技术指标
- 实时性:数据处理端到端延迟≤200ms,支撑实时数据分析决策;
- 高并发:稳定支撑 5000+QPS 高并发查询,复杂多维度查询耗时降至毫秒级;
- 数据规模:日均处理千万级业务数据,支持多业务线扩展;
- 可靠性:数据传输 / 计算准确率≥99.99%,核心链路零故障;
- 扩展性:新增数据链路 / 业务场景,仅需配置,无需修改代码、无需重启服务。
1.2.2 核心工程化设计要求
- 轻量开发:减少自定义代码开发,优先云原生可视化配置;
- 易维护:全链路可监控、可追溯,统一管控降低协作成本;
- 无定制化依赖:基于公有云原生组件实现,提升架构复用性;
- 聚焦业务:底层数据流转标准化,开发人员仅关注业务指标设计。
二、轻量云原生实时数仓架构设计
2.1 架构核心设计思路
架构设计遵循六大核心原则,兼顾轻量开发与灵活扩展:
- 统一采集:所有数据源接入统一消息队列采集层,屏蔽数据源差异;
- 无状态分发:引入 Flink DataSync 作为多链路分发底座,仅做数据转发,规避流计算运维复杂度;
- 链路解耦:各数据链路(实时分析、离线处理、持久化、检索)完全独立,新增 / 修改链路不影响其他链路;
- 计算下沉:将数据计算重心下沉至 TCHouse-C,充分发挥其列式存储、分布式计算优势;
- 云原生落地:核心链路采用 Oceanus ETL 标准化写入,实现可视化配置、高可靠落地;
- 多存储协同:适配多类存储引擎,各引擎发挥自身优势满足不同业务需求。
2.2 整体架构图
架构分为 6 大核心层级,以 Flink DataSync 为多链路分发核心,Oceanus ETL 为实时链路标准化写入工具,各层级无耦合、可独立扩展:
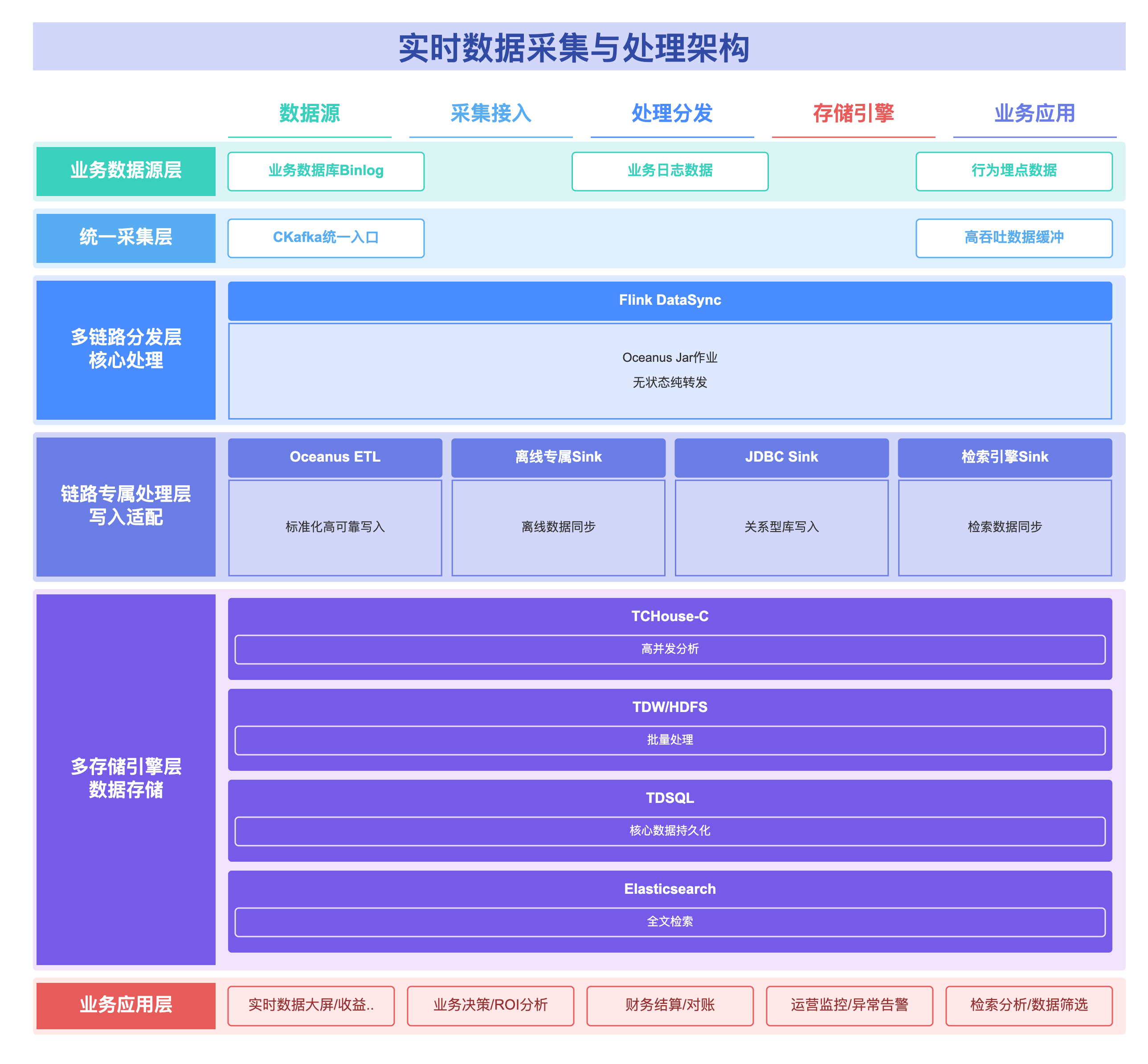
2.3 核心组件选型与职责分工
所有组件选用腾讯云原生产品 + 开源主流组件,无定制化依赖,各层级职责明确:
|
架构分层 |
核心组件 |
组件类型 |
核心职责 |
选型依据 |
|
业务数据源层 |
业务数据库 / 日志 / 埋点系统 |
业务源 |
产生各类业务原始数据 |
贴合通用实时分析场景数据源类型 |
|
统一采集层 |
腾讯云 CKafka |
云原生消息队列 |
统一采集入口,高吞吐、低延迟数据缓冲,屏蔽数据源差异 |
与 Oceanus 无缝对接,高可用、易维护 |
|
多链路分发层 |
Flink DataSync(Oceanus 作业) |
云原生流计算 |
架构核心,无状态纯转发,将数据分发至各业务链路,支持无限扩展 |
Oceanus 托管 Flink,Jar 包封装通用逻辑,配置化扩展适配业务快速迭代 |
|
链路处理 / 写入层 |
Oceanus ETL / 轻量自定义 Sink |
云原生 + 轻量自定义 |
各链路标准化处理 / 写入,核心链路用 Oceanus ETL,其他链路用轻量 Sink |
兼顾开发效率与扩展性 |
|
多存储引擎层 |
TCHouse-C/TDW/TDSQL/Elasticsearch |
云原生数仓 / 数据库 / 检索 |
多引擎协同,满足不同业务的存储 / 查询需求 |
各引擎发挥自身优势,TCHouse-C 做实时分析,TDSQL 做持久化,ES 做检索 |
|
业务应用层 |
自定义 API / 报表平台 / 监控大屏 |
业务应用 |
对接各角色业务需求,提供个性化数据服务 |
基于标准化数据开发,无需关注底层流转 |
2.4 核心组件核心能力说明
2.4.1 Flink DataSync(多链路分发核心)
- 部署形式:基于 Oceanus 独享集群,以Flink Jar 作业形式部署,Jar 包封装通用的数据分发逻辑,无硬编码的数据源 / Sink 信息;
- 核心能力:无状态纯转发,基于配置文件 / 控制台配置加载多数据源、多 Sink 规则,支持一份数据同时分发至 4 类及以上目标链路;
- 扩展特性:
- 新增数据源:仅需在配置中新增 CKafka / 消息队列等数据源信息,配置保存后实时加载,无需修改 Jar 代码、无需重启作业;
- 新增 Sink 链路:仅需在配置中新增目标 Sink 的连接信息、字段映射规则,配置生效后立即参与数据分发,全程无代码修改、无服务重启;
- 关键特性:支持 Checkpoint 故障恢复(保障数据不丢)、自动扩缩容(适配峰值压力)、死信队列(处理异常数据);
- 开发优势:通用逻辑一次性封装,后续扩展仅需配置,新手可在 10 分钟内完成新链路的新增配置。
2.4.2 Oceanus ETL(实时链路标准化写入)
- 核心能力:云原生 ETL 工具,可视化配置实现数据向 TCHouse-C 的高可靠写入,替代自定义 Connector;
- 关键特性:支持 Exactly-Once 语义、批量写入、自动重试,保障数据不重不漏;
- 运维优势:与 Oceanus 控制台一体化,可实时监控写入吞吐量、延迟、成功率。
2.4.3 TCHouse-C(实时数仓核心)
- 核心能力:腾讯云原生 ClickHouse 分布式集群,支持列式存储、预计算、分布式并行计算;
- 关键特性:支持多维度分区 / 分片、读写分离、资源隔离、TTL 自动清理,适配高并发、大数据量场景;
- 业务适配:完美支撑多维度指标聚合、复杂报表查询、标准化数据输出。
三、核心技术落地实现
3.1 Flink DataSync 多链路分发实现
Flink DataSync 是架构扩展核心,基于 Jar 包封装通用逻辑,通过配置化实现多链路分发,核心落地要点:
3.1.1 核心设计逻辑
- 通用 Jar 包封装:将数据消费、格式解析、无状态转发等通用逻辑封装至 Flink Jar 包,Jar 包不包含任何具体的数据源 / Sink 配置,仅暴露配置加载接口;
- 配置化数据源接入:通过外部配置文件 / Oceanus 控制台配置 CKafka 源信息(如 Topic、消费组、数据格式、异常处理规则),Jar 包启动时加载配置,新增数据源仅需新增配置项,无需修改 Jar 包;
- 配置化多 Sink 适配:为每个目标链路配置独立的 Sink 规则(连接信息、字段映射、攒批策略、重试规则),所有 Sink 规则热加载,新增 Sink 仅需添加配置,无需重启作业;
- 无状态透传分发:Jar 包接收 CKafka 标准化数据后,根据配置的 Sink 规则完成数据透传,无任何过滤、转换等业务逻辑,保障分发效率与通用性;
- 高可靠保障配置:在配置中开启 Checkpoint(间隔 5 秒),配置死信队列地址,解析失败或写入失败的数据自动路由至死信队列,不影响主链路数据分发。
3.1.2 扩展操作示例
- 新增 Redis Sink 链路:
- 在配置中心新增 Redis Sink 配置(包含地址、端口、密码、字段映射规则);
- 保存配置后,Flink DataSync 自动加载新配置;
- 验证 Redis 数据写入正常,全程无需修改 Jar 代码、无需重启作业,扩展周期≤10 分钟。
3.2 Oceanus ETL 实现 TCHouse-C 高可靠写入
实时链路采用 Oceanus ETL 可视化配置实现数据写入,核心要点:
3.2.1 TCHouse-C 表设计
- 引擎选择:根据业务特征选择合适的表引擎(如 CollapsingMergeTree 处理数据更新、ReplacingMergeTree 处理明细数据);
- 分区策略:按业务维度 + 时间双层分区,减少数据扫描范围,提升查询效率;
- TTL 配置:按数仓分层设置不同 TTL,自动清理过期数据,降低存储压力。
3.2.2 ETL 作业配置
- 数据源配置:选择对应消息队列数据源,配置连接信息、消费 Topic,验证连通性;
- 目的表配置:选择 TCHouse-C,配置集群地址、数据库、目标表信息,测试连通性;
- 字段映射:可视化完成字段映射,Oceanus 自动适配数据类型转换;
- 同步策略:配置批量写入(攒批大小 + 超时时间)、自动重试、死信队列、Exactly-Once 语义,保障写入高可靠。
3.2.3 监控运维
- 实时监控:在 Oceanus 控制台查看写入吞吐量、延迟、成功率、异常数;
- 告警配置:设置延迟阈值、成功率阈值、死信数据告警规则,及时发现并处理异常;
- 数据对账:按日核对写入数据量与源端数据量,确保数据准确率≥99.99%。
3.3 TCHouse-C 标准化数仓分层落地
基于 TCHouse-C 搭建 DIM(维度层)、ODS(原始层)、DWD(明细层)、DWS(指标层)、ADS(应用层)五层实时数仓,核心要点:
3.3.1 数仓分层设计
- DIM 层(维度层):存储静态 / 动态维度数据(如渠道信息、商品分类、角色信息),实时同步业务侧变更,为明细层提供维度补充;
- ODS 层(原始层):存储标准化原始数据,过滤无效数据,保留原始面貌,作为数仓数据底座,由 ETL 直接写入;
- DWD 层(明细层):关联维度表补全字段(如渠道名称、商品名称)、统一数据格式,生成多维度明细宽表,支撑精细化分析;
- DWS 层(指标层):分场景、分粒度聚合核心指标,预计算高频指标(如订单数、交易额、转化率),提升查询效率;
- ADS 层(应用层):按业务角色 / 场景创建专用视图,标准化指标输出,直接对接业务应用。
3.3.2 高性能优化策略
- 存储优化:双层分区 + 分布式分片,减少数据扫描范围,提升存储与读取效率;
- 计算优化:分场景拆分预计算任务,避免单视图承载过多计算逻辑,峰值时各视图并行刷新,提升计算效率;
- 查询优化:搭建读写分离集群、配置资源隔离、建立二级索引,保障高并发查询性能,支撑 5000+QPS 查询需求。
3.4 多存储引擎协同落地
多存储引擎各司其职、互补共赢,核心要点:
3.4.1 各引擎分工
- TCHouse-C:承担实时分析、多维度聚合、高并发查询场景;
- TDW/HDFS:承担离线批量处理、跨周期分析、财务对账场景;
- TDSQL:承担核心数据持久化、高频小查询、跨系统数据互通场景;
- Elasticsearch:承担全文检索、模糊查询、日志检索场景。
3.4.2 数据一致性保障
- 统一数据源:所有引擎数据均来自 CKafka 统一采集层,确保源头一致;
- 偏移量对账:各链路记录消费偏移量,按日核对数据条数,确保一致性;
- 异常校验:所有写入数据均通过字段格式、范围校验,避免脏数据进入存储层。
四、架构核心技术亮点与落地效果
4.1 核心技术亮点
- 配置化免重启扩展:Flink DataSync 基于 Jar 包封装通用逻辑,新增数据源 / Sink 仅需配置,无需改代码、无需重启,扩展周期≤10 分钟,彻底解决传统架构耦合高、扩展难的痛点;
- 轻量开发模式:核心链路采用可视化配置,自定义代码量减少 90%,Jar 包通用逻辑一次性开发,后续扩展仅需配置,开发门槛降低;
- 计算下沉提效:将所有计算逻辑下沉至 TCHouse-C,充分利用 ClickHouse列式存储、物化视图预计算、分布式并行计算的性能优势,避免跨组件数据传输开销,复杂多维度查询性能提升 85%,支撑 5000+QPS 高并发;
- 多引擎协同互补:适配四类存储引擎,覆盖实时、离线、持久化、检索全场景数据需求,替代单一存储引擎的功能短板;
- 全链路云原生管控:基于腾讯云控制台实现一站式监控运维,故障定位时间从小时级降至 10 分钟内,运维成本降低 80%;
- 企业级高可靠:通过多链路容错、配置化对账、死信队列等机制,核心业务链路零故障,数据准确率≥99.99%,满足生产级要求。
4.2 核心落地效果
- 实时性:端到端数据处理延迟稳定在 200ms 内,完全满足实时分析决策需求;
- 高并发:系统稳定支撑 5000+QPS 高并发查询,复杂多维度报表查询耗时≤50ms;
- 数据规模:日均处理亿级业务数据,稳定支撑 20 + 业务线扩展,无性能瓶颈;
- 可靠性:核心业务链路连续 3 个月零故障,数据传输 / 计算准确率达 99.996%;
- 扩展性:新增检索链路仅需 40 分钟完成配置与上线(含验证),新增业务分析链路仅需 1 天;
- 成本优化:相比传统自建架构,开发成本降低 75%,运维成本降低 82%,跨团队协作效率提升 60%。
五、架构复用与云原生迁移实践
本架构采用 “通用开源 + 云原生组件” 设计,无企业内部定制化依赖,兼具跨场景复用能力与公有云迁移可行性,核心实践方案如下:
5.1 跨行业 / 跨场景复用方案
架构的核心方法论(配置化免重启分发、计算下沉、多引擎协同、云原生可视化开发)具备高度通用性,可快速复用于多行业实时分析场景,仅需调整配置与数仓指标,无需修改核心逻辑:
5.1.1 适配场景与复用要点
|
目标行业 / 场景 |
核心复用内容 |
需调整配置 / 指标 |
|
电商行业(销量统计 / 商户分析) |
架构分层、Flink DataSync 配置化分发、TCHouse-C 数仓分层逻辑、多引擎协同模式 |
新增商品 SKU 维度配置、调整订单 / 销量核心指标、配置电商专属 Sink(如店铺管理系统) |
|
金融行业(交易对账 / 风控监控) |
高可靠分发机制、Exactly-Once 语义配置、数据校验规则、TDSQL 持久化链路 |
新增交易流水维度配置、调整风控核心指标(如交易频次 / 金额阈值)、配置合规审计 Sink |
|
物流行业(轨迹追踪 / 分拣效率) |
实时数据流转链路、TCHouse-C 预计算策略、Elasticsearch 检索链路 |
新增物流单号 / 网点维度配置、调整轨迹 / 效率指标、配置物流系统专属 Sink |
|
零售行业(客流分析 / 库存监控) |
多数据源接入配置、ODS-DWD-DWS 分层逻辑、实时大屏对接模式 |
新增门店 / 商品分类维度配置、调整客流 / 库存指标、配置零售 POS 系统 Sink |
5.1.2 复用核心步骤
- 复用架构分层与组件选型,仅替换业务数据源配置(如从订单数据改为交易流水数据);
- 调整 TCHouse-C 数仓分层的维度表与指标聚合规则,通过配置文件新增 / 修改预计算逻辑;
- 按需配置新增 / 裁剪 Sink 链路(如金融场景新增审计 Sink),无需修改 Flink DataSync 核心 Jar 包;
- 验证各链路数据一致性与业务指标准确性,复用周期≤1 周。
5.2 公有云原生迁移方案
架构可轻松从自建环境迁移至腾讯云公有云,核心架构逻辑完全复用,仅需替换底层组件,迁移成本可控:
5.2.1 核心迁移原则
- 架构逻辑不变:数仓分层逻辑、配置化分发策略、物化视图设计、多链路协同模式等核心内容完全复用,无需修改;
- 组件平滑替换:用腾讯云原生组件替代自建组件,屏蔽底层集群运维复杂度;
- 成本可控:迁移周期 2-3 周,无需重构业务代码,仅需调整组件配置与数据对接方式。
5.2.2 组件迁移映射与配置调整
|
自建组件 |
腾讯云原生替代组件 |
迁移配置要点 |
|
自建 Flink 集群 |
腾讯云 Oceanus 独享集群 |
迁移 Flink DataSync Jar 包至 Oceanus,调整作业配置(如资源规格、Checkpoint 间隔) |
|
自建 ClickHouse 集群 |
腾讯云 TCHouse-C |
迁移表结构与物化视图,调整分区 / 分片策略,适配 TCHouse-C 分布式集群架构 |
|
自建 Kafka 集群 |
腾讯云 CKafka |
迁移 Topic 配置与消费组信息,调整接入地址与权限配置 |
|
自建关系型数据库 |
腾讯云 TDSQL |
迁移表结构与数据,调整 JDBC Sink 连接配置,保障事务一致性 |
5.2.3 迁移效果保障
- 稳定性提升:云原生组件支持自动扩缩容、故障自愈,迁移后核心链路可用性≥99.99%;
- 性能优化:TCHouse-C/Oceanus 针对高并发场景优化,迁移后查询性能提升 30% 以上;
- 运维减负:无需关注集群部署、备份、升级,运维成本降低 80%;
- 扩展性增强:依托腾讯云生态,可快速配置新增云产品 Sink(如腾讯云 ES、数据湖)。
六、总结
本次实践基于腾讯云 Oceanus+TCHouse-C,以 Flink DataSync 配置化分发为核心,打造了一套轻量、可扩展、高可靠的云原生实时数仓架构。其核心价值在于通过 “配置化免重启分发 + 云原生可视化开发 + 计算下沉 + 多引擎协同”,解决了传统实时数仓开发复杂、扩展难、运维成本高的痛点,实现了技术指标与业务价值的双重提升。
架构的核心优势可概括为三点:
- 扩展极致灵活:Flink DataSync 基于 Jar 包 + 配置化设计,新增数据源 / Sink 无需改代码、无需重启,扩展周期≤10 分钟;
- 开发极致轻量:云原生工具 + 通用 Jar 包封装,自定义代码量减少 90%,大幅降低开发门槛与成本;
- 性能极致优异:计算下沉至 TCHouse-C + 多引擎协同,支撑 5000+QPS 高并发、200ms 内低延迟,满足企业级实时分析需求。
📚 我的技术博客导航:[点击进入一站式查看所有干货]

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 7
7 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)