DolphinScheduler项目架构和逻辑复盘
在 Worker 内部,虽然执行流程是统一的,但具体的“变身内容”是由这些插件决定的。我们可以从以下三个维度来理解这最后一层的运作:1、 核心接口:抽象执行器 🧩所有的任务类型在代码层面都实现了一个共同的基类(通常是 AbstractTask)。统一规范:它规定了每个插件必须实现 handle() 方法。无论底层是发个 HTTP 请求,还是跑个 Flink 任务,对于 Worker 来说,都只是
| 模块名称 | 职责定位 🛠️ | 对应架构图组件 📍 |
|---|---|---|
| dolphinscheduler-api | 提供 RESTful 接口,负责与前端交互、权限校验及元数据存储。 | API |
| dolphinscheduler-master | 核心大脑,负责工作流的调度、DAG 切分和任务分发。 | MasterServer |
| dolphinscheduler-worker | 执行者,负责接收 Master 的指令并真正启动任务进程。 | WorkerServer |
| dolphinscheduler-task-plugin | 任务插件集合,包含你刚才用的 Shell、SQL 等各类算子的具体实现。 | 底部的蓝色任务框 |
| dolphinscheduler-dao | 数据访问对象层,封装了对数据库(DB)的所有操作。 | DB |
| dolphinscheduler-registry | 注册中心模块,负责服务的发现和分布式锁。 | ZK Cluster |
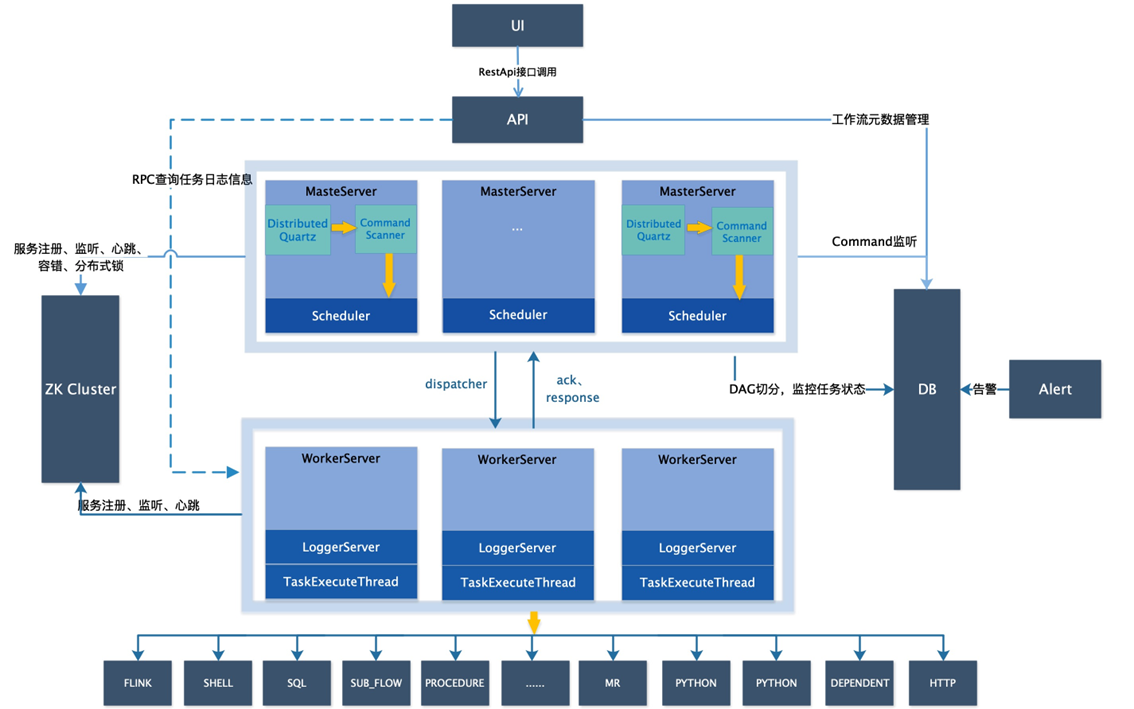
一、RestApi接口调用
1、UI 与 API 的“握手”过程
(1)数据封装:在 UI 画布上画的任务节点和连线(DAG)会被前端序列化为一个复杂的 JSON 对象。
(2)网络请求:前端使用 axios 或类似的工具,通过 HTTP 请求发送给后端 dolphinscheduler-api 模块。
(3)业务处理:API 模块接收到请求后,会进行身份认证、权限校验,最后通过 DAO 层将工作流定义存入数据库(DB)。
2、 源码:寻找 API 的入口
既然你已经打开了项目目录,我们可以直接去代码里“堵截”这个请求。
模块名称:dolphinscheduler-api
源代码路径:src/main/java/org/apache/dolphinscheduler/api/controller
在这个目录下,我们看到很多以 Controller 结尾的类。这些类就是处理前端请求的第一站。
在 DolphinScheduler 中,所有的核心操作都遵循 RESTful 风格。当你在 UI 上操作工作流时,通常会涉及到以下两个核心控制器:
(1)ProcessDefinitionController 📝:负责工作流定义的“静态”操作,比如创建、修改、删除和查询工作流的节点与连线。
(2)ExecutorController 🚀:负责工作流的“动态”操作,即当你点击那个三角形的“运行”按钮时,请求会发送到这里。
ProcessDefinitionController ——工作流“剧本”管理的核心入口
主要负责 CRUD(增删改查)以及工作流的上线与下线。
让我们根据你提供的架构图,梳理一下从 UI 点击到这个 Controller 的具体路径:
1、第一阶段:UI 到 Controller 的“剧本录制”
当你点击“保存工作流”或“创建”时,前端会通过 POST 请求访问这个 Controller。
控制器入口:对应代码中的 @PostMapping() 方法 createProcessDefinition。
关键参数:
taskRelationJson: 对应你在 UI 上拉的那些连线(DAG 结构) 🔗。
taskDefinitionJson: 对应你每个算子里的具体配置(比如那个 Shell 脚本) 🐚。
转交业务层:你会发现这一行代码:
Map<String, Object> result = processDefinitionService.createProcessDefinition(...);
这说明 Controller 只负责接电话,真正的逻辑交给了 ProcessDefinitionService。
2、第二阶段:从“写剧本”到“下达指令”
在架构图中,API 还需要负责将指令写入 DB 以便 Master 监听。你可以注意代码中关于 Release(上线/下线) 的逻辑:
上线操作:releaseProcessDefinition 方法。
背后的逻辑:只有状态为 ONLINE 的工作流,才会被 Master 扫描到并执行。
这就是架构图中从 API 指向 DB 的“工作流数据管理”线。
ExecutorController 中的 startProcessInstance 方法就是架构图中 UI 与 API 模块之间那个关键箭头的“终点”。 (通常对应 UI 上的那个三角形运行按钮)
1、API 模块的核心动作:下达开演令
正如你所料,这个 Controller 接收来自 UI 的请求,并将剧本(工作流定义)转化为实际的演出任务。
方法解析:
startProcessInstance 方法包含了你刚才在 UI 画图后运行时的所有配置,比如:
processDefinitionCode: 也就是那个剧本的“唯一代码”。
scheduleTime: 定时或者补数据的时间。
execType: 命令类型(比如是启动、补数据还是从断点恢复)。
2、转交执行:
注意这段代码:
#调用了 execService(即 ExecutorServiceImpl)
Map<String, Object> result = execService.execProcessInstance(loginUser, projectCode, processDefinitionCode, ...);
3、 下一步:进入“指令生成”的现场
在架构图中,API 的职责之一是工作流数据管理。当 execService.execProcessInstance 被调用时,它实际上在执行一个非常关键的操作:向数据库的 t_ds_command 表插入一条记录。
这就是架构图中 Command监听箭头的上游数据来源。
🔍 引导问题:寻找“入库”的那一行代码\
核心发现:createCommand 方法
在 execProcessInstance 方法的末尾,你会看到这几行关键代码:
create command
int create = this.createCommand(triggerCode, commandType, processDefinition.getCode(), ...);
(1)数据校验 🛡️:在执行之前,它会检查租户是否有效 (checkValidTenant)、Master 是否存在 (checkMasterExists) 以及工作流是否已经上线。
(2)对象构造 🏗️:在 createCommand 方法内部,它创建了一个 Command 对象,并把你在 UI 上设置的所有参数(如 failureStrategy、workerGroup、warningType 等)塞了进去。
(3)持久化入库 💾:它调用了 commandService.createCommand(command)。一旦这行代码执行成功,数据库里的 t_ds_command 表就会多出一条记录。
二、从“大脑”出发 ——master
在 dolphinscheduler-master 模块中,所有的“调度魔法”都是由一个核心循环驱动的。
你会发现它启动了几个非常核心的组件:
1、MasterSchedulerBootstrap 🚀:这是最核心的“扫描器”,它负责从数据库里把那些该跑的工作流(Command)给“捞”出来。
那么,Master 节点是如何感知到这条记录并启动整个工作流的呢?
这背后离不开 Master 节点的“扫描雷达”—— Command Scanner。
(1)扫描器的启动:MasterSchedulerBootstrap 启动器 🔎
在 MasterServer 启动时,它会初始化并启动一个核心组件:MasterSchedulerBootstrap。
这个类的职责非常单纯:不停地轮询数据库,寻找待执行的任务指令。
源码位置: dolphinscheduler-master 模块中的 MasterSchedulerBootstrap.java
它内部维护了一个独立的工作线程,这个线程的核心是一个不间断的 while 循环。
(2)获取指令:fetchCommands 🎣
在循环体内部,最重要的第一步就是从数据库捞取数据。Master 不会一次性捞取所有指令,而是根据配置的槽位(Slot)和步长进行过滤,确保分布式环境下多个 Master 之间不会产生任务抢夺。
// 简化后的核心逻辑
List<Command> commands = commandFetcher.fetchCommands();
数据库查询:它会查询 t_ds_command 表中状态正常的指令。
多 Master 负载均衡:通过 id % masterCount == currentMasterSlot 的逻辑,确保指令只会被分配给特定的 Master 节点处理。
(3)指令转化:从 Command 到可执行对象 ⚡
一旦捞到了 Command,Master 就需要把这个静态的数据库记录转化为一个动态的“生命体”—— WorkflowExecuteRunnable。
workflowExecuteRunnableFactory.createWorkflowExecuteRunnable(command);
Command: 只是一个“我要运行工作流 A”的信号。
WorkflowExecuteRunnable: 这是一个完整的“执行上下文”。它包含了你的 DAG 结构、Task A 和 Task B 的关系、以及你设置的那些参数。
WorkflowExecuteRunnableFactory:Master 使用工厂模式来创建执行器。
DAG 构建:在创建过程中,Master 会读取 ProcessDefinition(工作流定义),解析其中的 taskRelationJson,在内存中重新构建出 DAG(有向无环图)。
(4) 激活大脑:WorkflowEvent 发送 📬
Master 不会直接在扫描线程里跑逻辑(那会阻塞扫描),而是将生成的 WorkflowExecuteRunnable 放入缓存,并向 Workflow Event Queue 发送一个“启动”事件。
// 将启动事件加入队列
workflowEventQueue.addEvent(new WorkflowEvent(WorkflowEventType.START_WORKFLOW, processInstance.getId()));
MasterServer拓展
🕸️ 什么是 DAG 拆解?
在 DolphinScheduler 中,你画的每一根线都代表了任务之间的依赖关系。
Master 的核心工作就是把这个静态的图形拆解成动态的执行流。
简单来说,Master 会计算每个任务的入度(In-degree)。
入度 = 0:代表没有任何前置依赖,可以立刻跑(比如你的 Task A)。
入度 > 0:代表前面还有“大哥”在挡路,必须等“大哥”跑完才能轮到它(比如你的 Task B)。
🧠 Master 的计算逻辑
当 Master 启动一个工作流时,它会调用 DagHelper 这个工具类来分析任务链。以下是它的基本步骤:
初始扫描:Master 会扫描整个图,找出所有入度为 0 的任务,并将它们放入一个待执行队列。
触发执行:Master 从队列中取出任务,发送给 Worker 执行。
状态监听:Master 会时刻盯着任务的状态。一旦某个任务跑完(比如 Task A 变绿 ✅),它会立刻检查这个任务的所有后置节点。
动态递减:每当一个前置任务成功,Master 就会给后续任务的“入度”减 1。
解锁下一关:当某个任务的入度减到 0 时,它就被“激活”了,进入待执行队列。
📂 源码追踪:DagHelper
在你的源码目录里,有一个非常核心的文件负责这套逻辑:
模块:dolphinscheduler-service
路径:org.apache.dolphinscheduler.service.process.DagHelper
在DagHelper有这样的一个方法,parsePostNodes ,将它想象成一个交通指挥官。当一个任务(preNodeCode)跑完时,它负责看地图(dag),决定接下来哪些任务可以上路。
它主要分成了两步:
1、寻找“潜在”的后续节点 🗺️
代码首先根据当前任务的类型,决定从哪里开始找下一个任务:
如果当前没任务 (preNodeCode == null):说明工作流刚启动,直接找 dag.getBeginNode()(入度为 0 的任务)。
如果是条件/分支任务 (isConditionTask / isSwitchTask):它会走特殊的逻辑,根据判断结果选择走哪条路。
如果是普通任务:直接通过 dag.getSubsequentNodes(preNodeCode) 拿到所有连在它后面的任务。
2、检查这些节点是否具备“起跑条件” 🚦
拿到后续节点后,代码并不是立刻让它们运行,而是通过一个关键的循环进行筛选。请特别关注这一段:
if (!DagHelper.allDependsForbiddenOrEnd(taskNode, dag, skipTaskNodeList, completeTaskList)) {
continue;
}
这就是我们之前讨论的“入度”检查。
submitPostNode 是 Master 决策链中的“发令官”。
当一个任务(TaskInstance)执行完成后,Master 需要决定下一步该做什么。submitPostNode 的核心逻辑就是调用我们刚才看到的 DagHelper.parsePostNodes,根据 DAG 图的连线关系,计算出所有能够被激活的后置任务。
(1) 寻找接棒者:解析后置节点 🗺️
首先,它调用了我们之前讨论过的“核心工具”:
Set<Long> submitTaskNodeList = DagHelper.parsePostNodes(parentNodeCode, skipTaskNodeMap, dag, getCompleteTaskInstanceMap());
这一步是根据 DAG 连线关系,计算出在 parentNodeCode(当前跑完的任务)之后,有哪些任务已经满足了运行条件(比如所有前置依赖都已完成)。
(2)状态检查与接管:处理存量任务 🔄
接下来是一个复杂的循环,它在处理 submitTaskNodeList。如果一个任务已经存在(比如因为容错或重跑产生过实例),Master 会判断它的状态:
正在运行或已提交:尝试执行 tryToTakeOverTaskInstance(接管任务)。
无法接管:如果任务状态异常,会将其标记为 NEED_FAULT_TOLERANCE(需要容错),并克隆一个新的实例。
全新任务:如果任务还没跑过,则调用 createTaskInstance 创建一个新的“身份牌”。
(3)参数传递:变量池合并 🧪
这段逻辑非常有意思:
if (parentNodeCode != null && dag.getEndNode().contains(parentNodeCode)) {
// 合并 VarPool
}
当一个分支执行到终点时,它会将该任务产生的变量(VarPool)合并到整个工作流实例中。这就是为什么你在任务 A 里设置的值,后面的任务 B 能拿到的原因。
(4) 放入待发车区:提交到就绪队列 🚀
最后,代码将确定要执行的任务实例依次经过一系列过滤(检查是否已在队列、是否已成功、是否被杀掉),然后:
addTaskToStandByList(task);
submitStandByTask();
submitStandByTask()
#将任务推向我们接下来要看的 Dispatch(分发) 环节的最后临门一脚。
ExecutorDispatcher
Master 在 submitPostNode 确定了待运行任务后,会将其交给 ExecutorDispatcher。
ExecutorDispatcher 扮演的是“派遣员”的角色。
它不直接执行任务,而是负责解决两个核心问题:“发给谁?” 和 “怎么发?”。
1、在分发之前,任务会先进入一个 TaskPriorityQueue 🚦(任务优先级队列)。
这就像是一个候车大厅,优先级高的任务可以优先“检票上车”。
2、负载均衡的智慧——HostManager 🎯
这是博文中最硬核的部分。为了不让某台 Worker “累死”,Master 会通过 HostManager 进行筛选。这里有几种策略:
随机(Random):简单粗暴。
轮询(RoundRobin):排队领取。
低负载优先(LowerWeight):这是最常用的,Master 会实时根据 Worker 的 CPU 和内存使用率来打分。
3、 跨网络传输:NettyExecutor 📨
一旦选定了目标 Worker,Master 就会动用 Netty 进行远程通信,把任务包(TaskDispatchCommand)发送过去。
Alert 告警模块
我们正好来到了架构图中右侧相对独立的 Alert 告警模块。它就像是整个系统的“警报器”,负责在任务出现异常时,第一时间通知到相关人员。
1\ 触发源头:DB 中的“异常信号” 📈
在图中你可以看到,Alert 模块通过箭头指向了 DB。这是因为所有的任务状态(成功、失败、重试等)都会实时写入数据库。
扫描机制:Alert 模块内部有一个独立的线程,它会定时扫描数据库中的告警记录表。
判定逻辑:当它发现某个任务实例的状态符合告警策略(比如“失败告警”或“超时告警”),就会生成一条“待发送”的告警指令。
2、 核心架构:插件化设计 🔌
这是 Alert 模块最精妙的地方。正如 Worker 支持多种任务插件一样,Alert 也支持多种告警媒介。
告警类型:它支持钉钉 (DingTalk)、企业微信 (WeChat)、邮件 (Email)、飞书 (Feishu)、甚至短信和电话。
隔离逻辑:这种设计使得增加一种新的通知方式非常简单,只需要实现对应的插件接口,而不需要修改核心代码。
3、执行流程:从“信号”到“消息” 📨
当 Alert 模块捕获到异常后,它会经历以下步骤:
获取告警组:根据任务配置,找到该任务关联的“告警组”(即要通知哪些人)。
渲染模板:将枯燥的任务 ID、状态、执行时间等数据,填入预设好的文字模板中,变成可读的消息。
调用插件发送:调用对应的插件接口(如调用邮件服务器的 SMTP 或钉钉的 Webhook),将消息推送出去。
💡 总结闭环
现在我们将它放回全局架构中看:
Master 监控到任务失败,更新 DB。
——>
Alert 扫描到 DB 中的异常,触发告警逻辑。
——>
用户 在手机或电脑上收到通知,及时介入处理。
Dispatch分发和ZK cluster
ZooKeeper:分布式系统的“神经中枢” 🧠
在 DolphinScheduler 架构图中,ZooKeeper 不仅仅是一个存储 IP 地址的通讯录,它还承担了服务发现、状态监控和分布式协调等多重任务。
我们可以从以下几个维度来理清它是如何工作的:
(1)服务注册(临时节点) 📝
当每一个 WorkerServer 启动时,它会主动向 ZooKeeper 的特定路径(例如/dolphinscheduler/nodes/worker)创建一个临时节点(Ephemeral Node)。
这个节点包含了该 Worker 的关键信息,如 IP 地址、端口号以及初始的心跳数据。
(2)健康状态与心跳机制 💓
Worker 会与 ZooKeeper 维持一个长连接(Session)。只要长连接不断,临时节点就一直存在。
一旦 Worker 机器宕机或网络中断,连接超时后,ZooKeeper 会自动删除对应的临时节点。这就相当于“情报中心”实时剔除了不健康的成员。
(3)监听机制(Watcher) 🛰️
MasterServer 并不需要像轮询一样不停地去问 ZK:“Worker 还在吗?”
Master 会在 Worker 节点路径上注册一个 Watcher(监听器)。一旦 Worker 列表发生变化(新增或减少),ZooKeeper 会主动向 Master 发送一个事件通知。
Master 接收到通知后,会立即刷新本地的 Worker 列表缓存。
(4)动态负载均衡数据同步 ⚖️
Worker 在运行过程中,还会定期更新节点中的数据,上报自己当前的 CPU 使用率、内存占用率以及正在执行的任务数量。
Master 在分发任务(Dispatch)时,会读取这些数据,从而计算出哪台机器“最闲”,实现真正的动态平衡。
WorkerServer
根据架构图,WorkerServer 内部有三个关键层级:WorkerServer 本体、LoggerServer 以及最核心的 TaskExecuteThread。
我们可以通过以下流程来拆解它的内部运作:
1、任务的“领用”与初始化 📥
当 Dispatch 指令到达时,WorkerServer 会先进行前置准备:
任务解包:从网络报文中提取任务配置(如任务类型、脚本内容、环境变量等)。
资源申请:Worker 会检查自身的负载(如 CPU、内存)。如果当前执行的任务数已达到上限,它会通过 ack 反馈给 Master,或者将任务放入本地队列排队。
2、 核心执行引擎:TaskExecuteThread 🧵
这是架构图中 Worker 最底层的模块,也是真正的“打工人”。
线程创建:Worker 会为每一个到来的任务分配(或从线程池中取出)一个 TaskExecuteThread。
插件化加载:Worker 采用了插件化设计。它会根据任务类型(架构图最下方那一排:SHELL、SQL、PYTHON、FLINK 等)加载对应的执行插件。
执行环境准备:
创建工作目录:在本地磁盘创建一个临时目录。
拉取资源文件:如果任务依赖 HDFS 或 S3 上的文件,会在这一步下载到本地。
生成脚本:将用户在 UI 上写的代码持久化为本地脚本文件(如 .sh 或 .py)。
3、实时监控与日志桥梁:LoggerServer 📝
在任务运行的同时,架构图中的 LoggerServer 就开始忙碌了:
重定向输出:它会接管任务运行过程中的标准输出(stdout)和错误输出(stderr)。
日志本地化:将这些实时产生的日志写入本地磁盘。
RPC 准备:正如你之前提到的,LoggerServer 会开启一个 RPC 接口。当你在 UI 上点开“查看日志”时,API 就会通过这个接口实时从 LoggerServer 抓取数据。
4、 状态反馈:ack 与 response 📡
这是架构图中间那条向上指回 Master 的箭头:
ack (确认):Worker 收到任务并准备开始执行时,立即发回一个 ack,告诉 Master:“收到,我准备开工了”。
response (结果):当脚本运行结束(退出码为 0 或非 0),TaskExecuteThread 会捕获这个状态,通过 response 告知 Master 任务是 SUCCESS 还是 FAILURE。
拓展
多任务并行的秘密:Worker 是如何管理大量并发任务而互不干扰的?
1、任务的“隔离墙”:独立的执行进程 🏗️
这是最基础也是最重要的手段。Worker 每接收到一个任务(Task),并不会在自己的主进程里直接跑代码,而是会启动一个全新的、独立的 TaskExecuteThread(任务执行线程)。
进程隔离:实际上,对于 Shell、Python 等脚本类任务,Worker 会通过 Java 调用操作系统的命令,启动一个子进程。
互不干涉:由于每个任务都在自己的进程/线程里运行,它们拥有独立的内存空间和执行栈。即使 Task A 崩溃了,也不会导致 Task B 跟着挂掉。
2、 线程池与并发控制 🚦
Worker 不会无限制地接单。它内部维护着一个线程池来管理并发量。
槽位(Slots)限制:你可以把 Worker 想象成一个有固定工位的车间。如果线程池设置了 100 个线程,那么该 Worker 同一时间最多只能处理 100 个任务。
过载保护:当 Master 尝试 Dispatch 任务时,Worker 会检查自己还有没有空闲的“工位”。如果没有,它会拒绝任务,Master 就会把任务重新发给其他有空位的 Worker。
3、 环境隔离与变量保护 🧪
为了防止两个任务因为环境变量或文件路径起冲突,Worker 做了精细的规划:
独立工作目录:每个任务在 Worker 的磁盘上都有一个专属于自己的临时文件夹。
上下文隔离:每个任务执行时,Worker 会为其注入独立的变量池和环境变量,确保 Task A 的参数不会“串门”到 Task B。
任务插件的“变身”:以 Shell 任务为例,看它是如何从一段文字变成 Linux 进程执行的。
1、落笔成文:脚本的生成与落地 📝
当你点击保存时,Shell 内容只是存储在数据库里的一个字符串。当 Worker 领到任务后,第一件事就是把它变成 Linux 认得的物理文件。
独立目录:Worker 会在本地磁盘为每个任务创建一个唯一的临时工作目录。
生成脚本:Worker 的 BashShellInterceptorBuilder 会读取任务中的 command 内容,并在该目录下生成一个名为 t_ds_…_node.sh 的临时脚本文件。
注入变量:如果你的 Shell 里用了 ${a} 这种变量,Worker 会在生成脚本时,通过环境变量或前置命令把这些值注入进去。
2、披挂上阵:封装执行命令 ⚔️
脚本写好了,直接运行是不够的。Worker 需要给这个脚本包上一层“保护壳”。
Interceptor 拦截器:Worker 使用 IShellInterceptor 机制。默认情况下,它会使用 BashShellInterceptorBuilder 来构建最终的执行指令。
权限管理 (sudo):如果你配置了特定租户(Tenant),Worker 会在执行命令前加上 sudo -u [tenant_user],确保任务是以特定 Linux 用户身份运行的,实现权限隔离。
3、开机点火:ProcessBuilder 触发进程 🚀
这是“变身”的灵魂步骤,Worker 利用 Java 的 ProcessBuilder 来调用操作系统的内核功能。
创建子进程:Worker 会启动一个独立的子进程来执行刚才生成的 .sh 文件。
PID 跟踪:一旦进程启动,Worker 会立即记录该任务的 PID (进程 ID)。这样如果用户在 UI 上点击“停止”,Master 就会通知 Worker 根据这个 PID 把对应的 Linux 进程“杀掉”。
4、实时播报:日志重定向 📡
任务跑起来了,日志怎么回到 UI 上?
输出流重定向:ProcessBuilder 会开启该子进程的 stdout(标准输出)和 stderr(错误输出)流。
LoggerServer 采样:Worker 内部的日志处理器会不断读取这些流,并实时写入到本地工作目录下的 .log 文件中。
结束反馈:当进程退出时,Worker 会捕获它的 Exit Code。如果是 0,则代表成功;如果是 137(通常是被 kill),则代表停止;其他则视为失败。
📦 最后一层:万物皆插件 (Task Plugins)
在 Worker 内部,虽然执行流程是统一的,但具体的“变身内容”是由这些插件决定的。
我们可以从以下三个维度来理解这最后一层的运作:
1、 核心接口:抽象执行器 🧩
所有的任务类型在代码层面都实现了一个共同的基类(通常是 AbstractTask)。
统一规范:它规定了每个插件必须实现 handle() 方法。无论底层是发个 HTTP 请求,还是跑个 Flink 任务,对于 Worker 来说,都只是调用一次 handle() 而已。
参数解析:插件负责将 UI 传来的 JSON 配置解析为自己需要的特定参数(如 SQL 插件解析出数据源 ID,HTTP 插件解析出 URL)。
2、 插件的“执行路径”差异化 🛤️
虽然接口统一,但根据架构图底部的模块,它们的执行逻辑分为两大派系:
外部系统调用派 (SQL, HTTP, FLINK, MR):
它们通常不消耗 Worker 太多的 CPU,Worker 只是扮演一个“中转站”。
比如 SQL 插件:Worker 连接数据库执行 SQL,然后等待数据库返回结果。
本地算力消耗派 (SHELL, PYTHON, DATAX):
它们会在 Worker 本地启动子进程。
比如 Python 插件:Worker 会检查本地是否有 Python 环境,然后拉起 Python 解释器跑脚本。
3、 结果的“标准化归放” 🏁
无论插件内部经历了多么复杂的计算,最终它们必须给 Worker 一个“交代”:
Exit Code 翻译:插件负责把各种执行结果翻译成统一的数字状态。
数据回传(可选):某些插件支持将执行结果(如 SQL 的查询结果或 Python 的输出)存入变量池,供下一个节点使用。
📝 总结:这幅架构图的精髓
通过这一路从 API -> Master -> Worker -> Task Plugin 的探索,我们可以总结出 DolphinScheduler 架构的精髓:
“上层搞协调(Master),中层搞管理(Worker),底层搞实现(Plugin)。”
深度解析 DolphinScheduler:一个分布式任务的“入世”与“圆满”
第一阶段:出世 —— 从 UI 到 API 坐落 🏛️
一切的起点源于用户在 UI 上的轻轻一试。
RestApi 接口调用:API 模块接收来自前端的请求,负责“写剧本”。
Command 持久化:ExecutorServiceImpl 将运行指令转化为 t_ds_command 表中的一条记录,并在 DB 中打下“烙印”。这一步完成了从用户意图到系统指令的转化。
第二阶段:点将 —— Master 的扫描与指挥 🧠
MasterServer 是集群的大脑,它不直接干活,但负责运筹帷幄。
Command 监听:Master 的 CommandScanner 像雷达一样不停扫描 DB。
DAG 切分:一旦发现任务,Master 会解析其拓扑结构(DAG),通过 submitPostNode 计算出谁该先跑,谁该等待。
Dispatcher(分发):Master 通过 ZooKeeper 实时感知 Worker 的健康状态。它利用负载均衡算法(如低负载优先),通过 Netty 将任务“派遣”给最合适的 Worker。
第三阶段:领命 —— Worker 的执行与隔离 ⚙️
Worker 是最踏实的“打工人”,它负责把抽象的逻辑落地。
TaskExecuteThread:Worker 为每个任务开启独立的执行线程,确保任务之间互不干扰。
标准化反馈:无论任务多复杂,Worker 都会通过 ack 回复 Master 确认收到,并在结束时通过 response 告知结果。
日志桥梁:LoggerServer 在任务运行的同时,通过 RPC 接口对外提供实时日志查询服务。
第四阶段:变身 —— 任务插件的百花齐放 📦
这是架构图的最底层,也是最精彩的部分。DolphinScheduler 采用了“万物皆插件”的设计理念:
统一接口:所有任务(Shell, SQL, Python 等)都继承自 AbstractTask。
差异化执行:
Shell/Python:Worker 会生成临时脚本并启动独立的 Linux 子进程执行。
SQL/HTTP:Worker 则充当代理,与远程数据库或接口进行交互。
环境隔离:通过独立的临时工作目录和租户权限(sudo),确保了生产环境的安全与洁净。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 12
12 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)