【PG数据库SQL优化学习之--执行优化器】
查询优化分为逻辑优化和物理优化,逻辑优化主要包括:表达式预处理、子查询优化、子连接提升、等价谓词重写、条件化简、外连接消除等,对查询树进行等价逻辑优化,生成逻辑查询执行计划。虽然数据库开发人员在编写SQL语句时会基于自身知识和经验尽可能优化查询性能,但由于应用程序通常需要编写大量复杂的查询语句,且这些语句的逻辑结构可能非常复杂,因此很难保证每个SQL语句都能达到理想的执行效率,PostgreSQL
优化器原理
查询优化是SQL性能调优的核心内容。在数据库系统中,SQL语句仅明确查询目标而未指定具体执行方法,其实现细节完全由数据库系统内部处理机制完成。当查询处理过程存在效率瓶颈时,将导致系统性能下降问题。
虽然数据库开发人员在编写SQL语句时会基于自身知识和经验尽可能优化查询性能,但由于应用程序通常需要编写大量复杂的查询语句,且这些语句的逻辑结构可能非常复杂,因此很难保证每个SQL语句都能达到理想的执行效率,PostgreSQL 优化器把一条 SQL 从文本变成结果,要依次走过解析 → 分析 → 重写 → 规划/优化 → 执行五大阶段。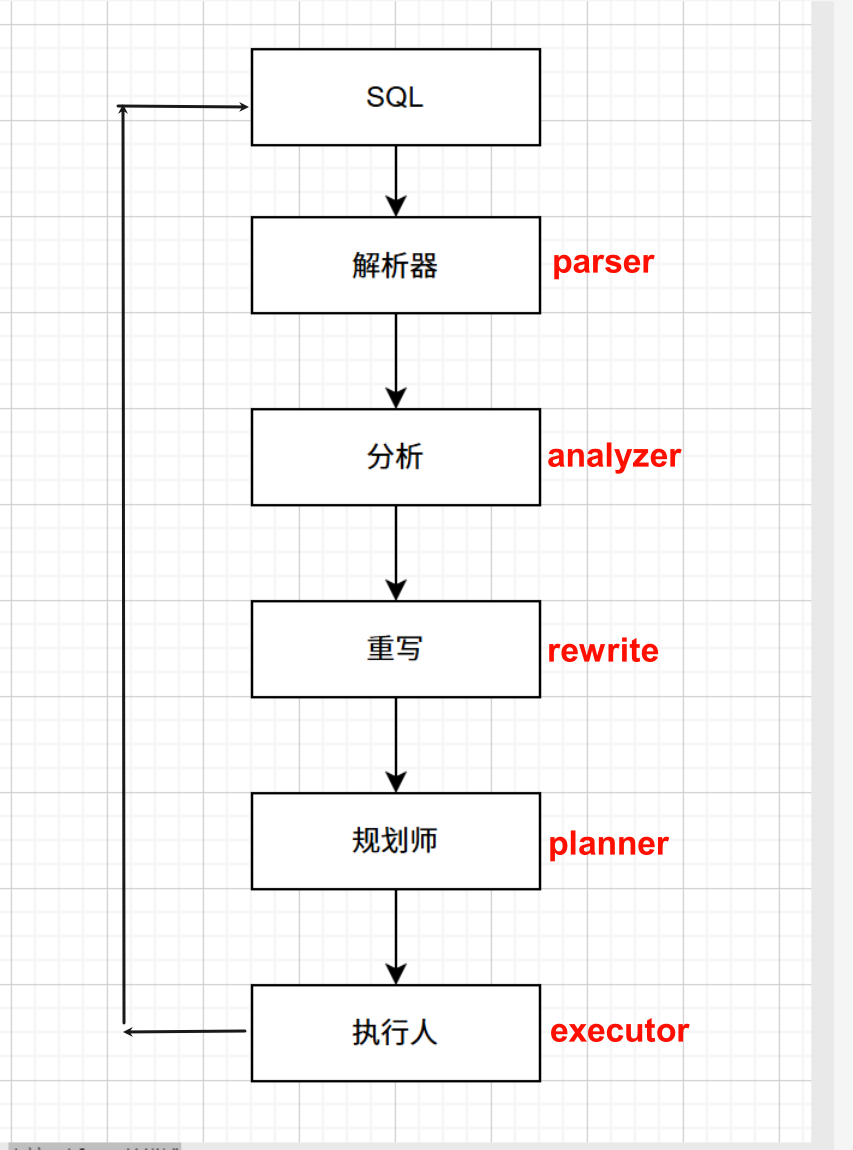
1、解析器(Parser)
总结:
检查语法错误
生成解析树(parse tree)
目标:把文本 SQL 变成“机器能懂的结构化对象”——语法树(AST)。
关键技术
• 词法/语法分析:Flex+Bison(PG)、Lemon(SQLite)、手写的递归下降(MySQL 8.0)。
• 语义检查:表/列是否存在、权限、数据类型解析、同义词展开。
• 生成 Query_block(MySQL)或 Query_tree(PG)对象,带上元数据句柄。
分析器(Analyzer)
分析器负责验证解析器生成的 raw_parsetree 结构。例如:检查表名有效性、插入数据类型匹配和字段存在性,最终将对象名称转换为内部 OID(对象标识符),并生成查询树(query tree)。
总结:
执行语义分析
验证数据库对象(表、列等)
将名称转换为内部 OID
生成查询树
Rewrite(重写 / 规则阶段)
目标:基于规则把语义树改写成“对优化器更友好”的等价形式。
关键技术
• 视图展开:把视图定义直接贴进主查询,避免物化。
• 谓词下推(Predicate Push-Down):把 WHERE 条件尽可能压到扫描层。
• 外连接消除:WHERE 里对可空侧加“IS NOT NULL”可转内连接。
• 分区裁剪(Partition Pruning):根据常量分区键直接剪掉无关分区。
查询规划器(Planner)
负责执行语句成本估算和生成优化的查询计划。根据语句类型、表结构、是否有索引及其大小等,计算不同的执行方法(也叫路径)。
目标:生成“物理执行路径”并选出代价最小者。
关键技术
• 扫描方式选择:SeqScan vs IndexScan vs BitmapOr vs IndexOnlyScan。
• 连接顺序:基于遗传(GEQO)、动态规划(DPsize)、深度优先分支限界(Cascades)。
• 连接算法:Nested-Loop、Hash Join、Sort-Merge;选择依据是表大小、索引、内存 work_mem。
• 并行度:parallel_tuple_cost、parallel_setup_cost、max_parallel_workers。
• 代价模型:CPU 周期 + 随机/顺序 IO 页 + 网络 + 启动代价;系数可调(seq_page_cost、random_page_cost)。
总结:
负责生成执行计划
确定所有可能的获取结果的方法(或路径)
选择能以最短时间完成查询的最佳方法
执行器(Executor)
根据最优优化路径实际执行
PG收到来自客户端的SQL语句后进入Parser模块,Parser模块负责词法分析、语法分析,生成各种Stmt结构体传入Analyzer进行语义检查,语义检查完后生成Query结构体进入查询重写阶段。查询重写主要是对视图的重写,然后进入优化器阶段进行查询优化。
查询优化分为逻辑优化和物理优化,逻辑优化主要包括:表达式预处理、子查询优化、子连接提升、等价谓词重写、条件化简、外连接消除等,对查询树进行等价逻辑优化,生成逻辑查询执行计划。物理优化则是基于代价的查询优化(Cost-based Optimizer,简称CBO),其主要流程是枚举各种待选的物理查询路径,并且根据路径上各节点的信息计算这些待选路径的代价,进而选择出代价最小的路径。以上是SPJ的优化,对于非SPJ优化主要是对分组、排序、聚集、去重等操作的优化。
经过查询优化生成最优(cost最少)的执行计划,执行器执行计划获得查询结果返回给客户端。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 22
22 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)