基于FunASR开发的智能录音转写系统可区分说话人并且可以明确是谁讲的哪句话
摘要: 开发了一套支持离线的语音转写与声纹识别系统,适用于对数据安全要求严格的场景。系统基于开源ASR和声纹模型(seaco-paraformer、cam++等),支持Windows、MacOS及国产操作系统(如欧拉),提供声纹注册、识别、转写等功能。采用前后端分离架构(FastAPI+前端三剑客),数据存储于MySQL,适用于会议记录、通话质检等场景。目前项目未开源,可通过指定渠道获取演示视频及
1. 开发背景
国内有很多公司或者事业单位等对数据安全要求十分严格,我们通话录音,会议录音这类十分私密的音频,如果我们想要转写为文字做进一步分析,我们需要用ASR技术,并且不能调用云端的API接口,因为任何连接互联网的设备都是不够安全的。如今有很多开源的ASR和声纹识别模型,我们利用这些开源的模型和开源的框架开发了这套系统。这系统不单支持Ubuntu, CentOS这些外国Linux系统,也支持国内的系统,比如华为的欧拉系统是支持的,并且还支持普通的PC系统,比如Windows也是支持的,当然MacOS也一样支持。
2. 系统功能
系统支持“声纹注册”,“声纹信息管理”,“声纹识别”,“用户管理”,“历史转写记录管理”,“语音转写”。
系统采用前后端分离架构开发,后端使用fastapi开发成API接口,前端使用前端三剑客开发。数据持久化到MySQL数据库中。下面是系统核心功能页面截图。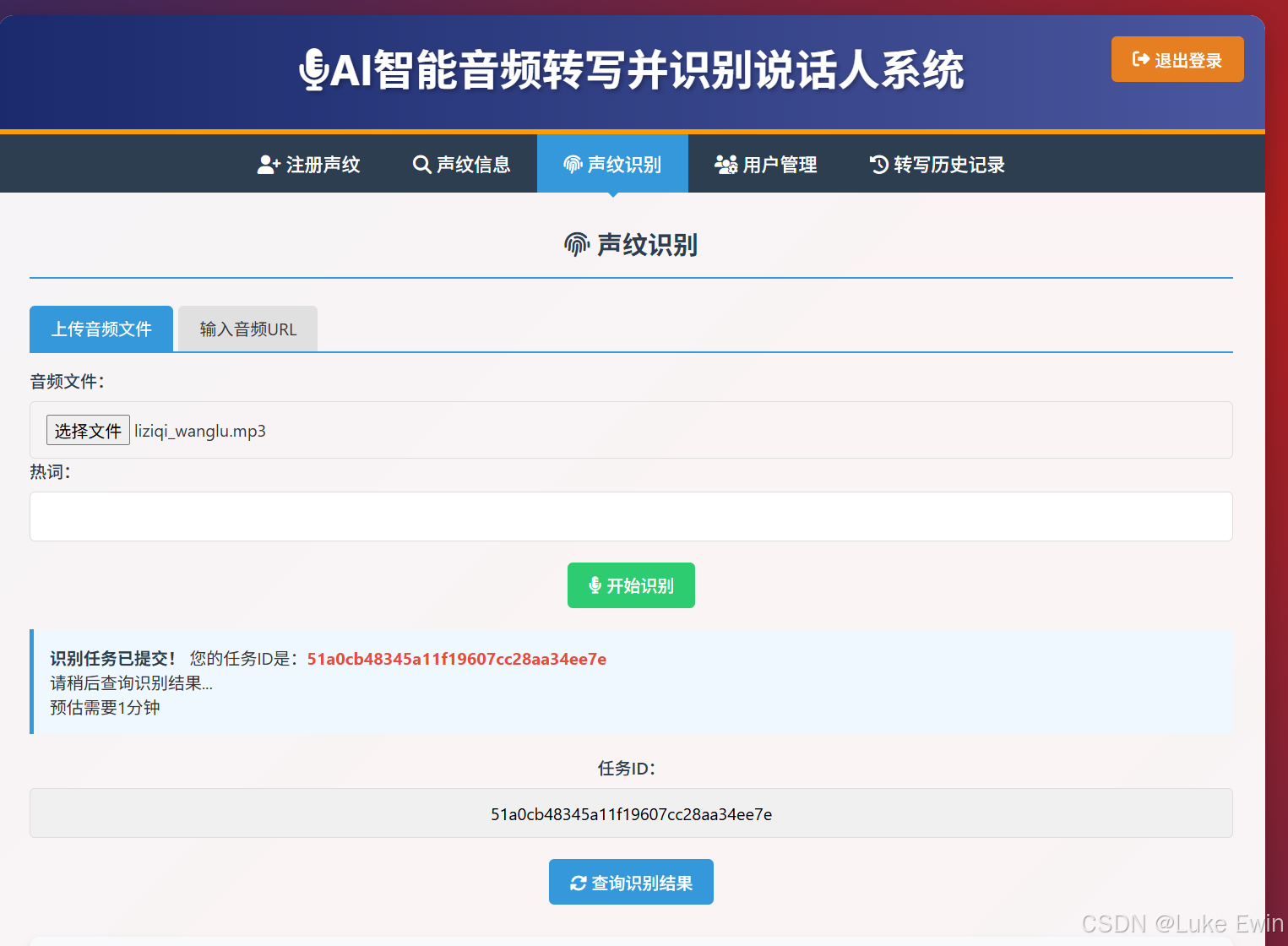
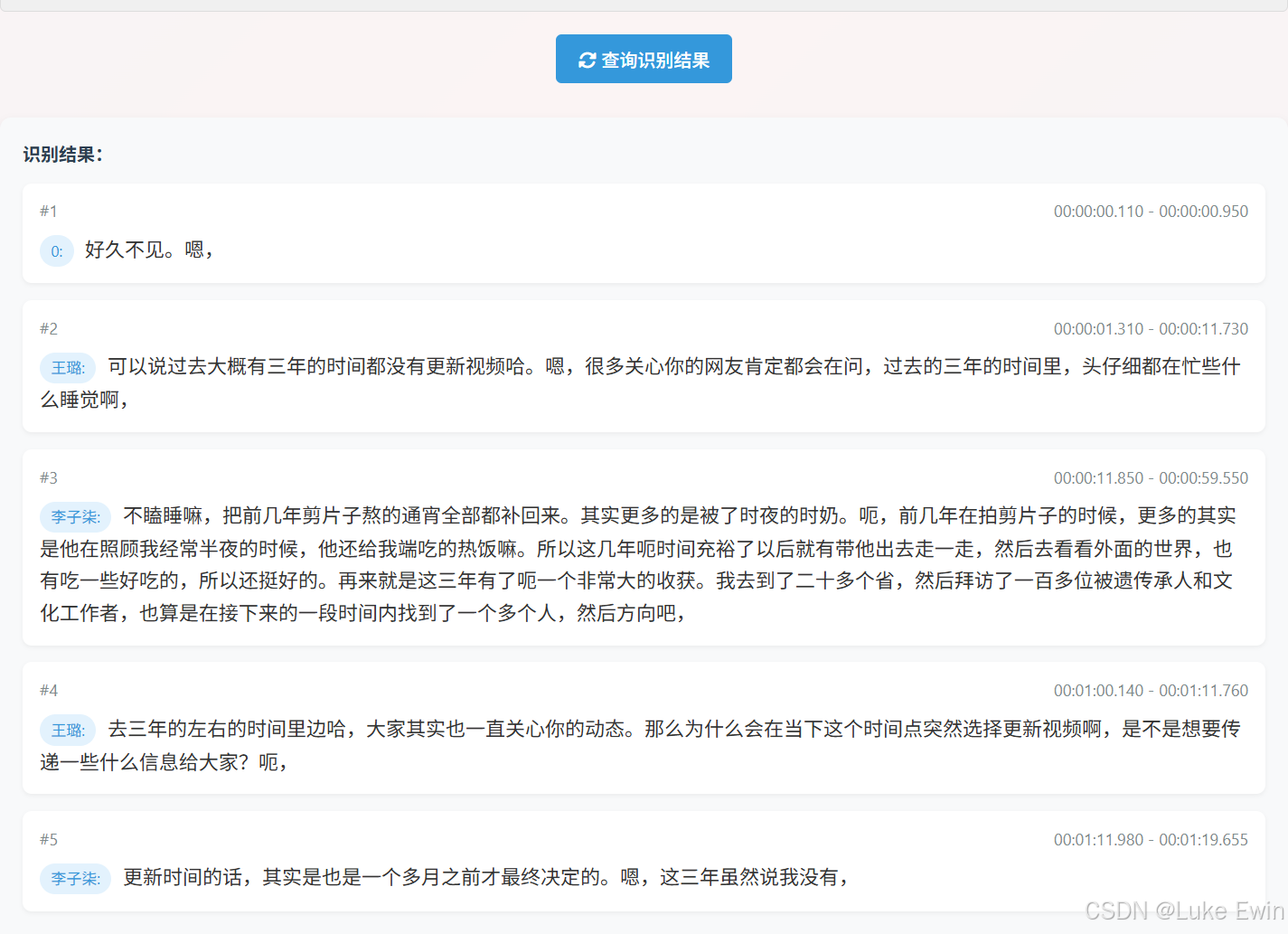
这个系统效果演示可以看我发布到B站的视频,点击这里观看演示视频。
3. 使用到的模型
一共使用四个模型,分别是语音识别模型 seaco-paraformer模型,添加标点符号模型 punc,端点预测模型 vad 以及声纹识别模型 cam++
4. 应用场景
可以应用到会议录音转写并且识别说话人,可以应用到通话语音质检,甚至可以做到区分客户和客服。
还有哪些应用场景呢?欢迎大家留言讨论。
5. 其它
这个项目开源吗?这个项目目前不打算开源,可以在*宝中搜索“AI语音工坊”或者在某🐟中搜索“美丽自信的西西”。或者到我的个人博客的首页中联系我。点击这里跳转到我的博客。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 8
8 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)