李飞飞团队新作Dream2Flow:把视频生成变成可执行的机器人动作
点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
【具身智能】微信群成立!大家快扫码加入具身智能群,将获得:最新具身智能技术和项目、❤️ 从入门到精通的学习路线、🤖 具身智能招聘(实习/校招/社招/升学)、具身智能公司名单和高校实验室/教师名单和 👀 行业动态和行业报告等。

▲【具身智能】学习群
来源:AI东经开篇
开源/商用的 Video Generation 模型已经能“想象”合理的人类交互,但机器人需要的是低层动作与约束可行性;Dream2Flow 把两者之间最难的 embodiment gap 拆开,用 3D Object Flow 做中间接口,让“视频里发生了什么状态变化”可被规划/RL 直接追踪执行。
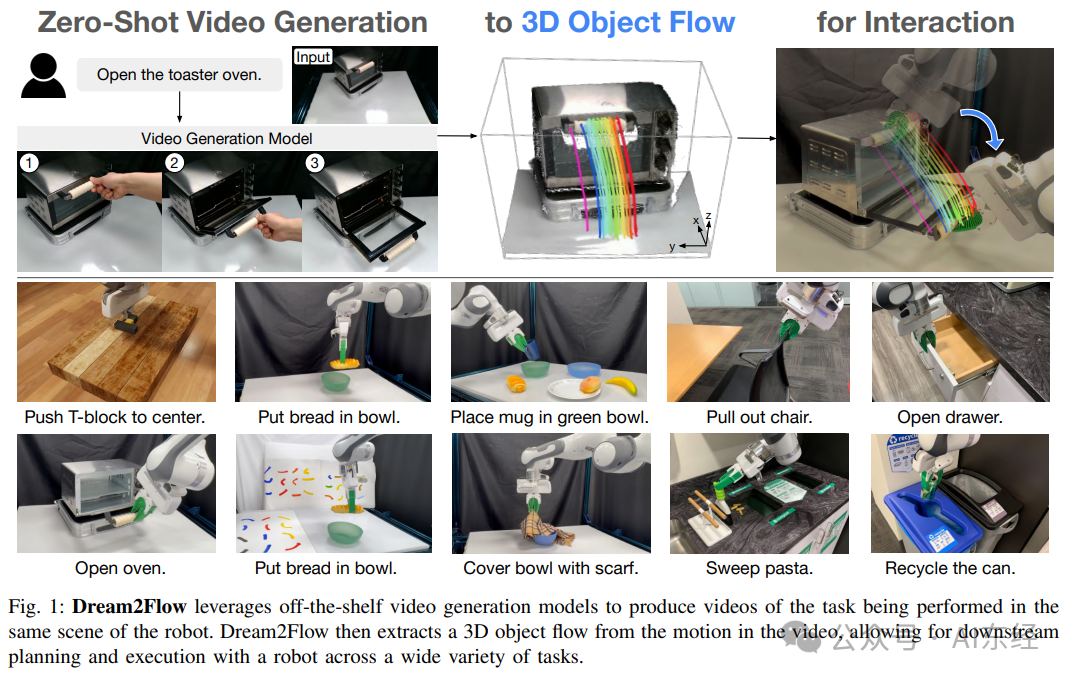
1. 核心观点速览
-
• 把 open-ended 语言任务“编译”为可执行目标的关键,不是模仿人手轨迹,而是追踪“物体该怎么动”:Dream2Flow 不尝试 imitation human motion,而是从 Video Generation 的预测中重建 3D object motions,把 manipulation 化为 object trajectory tracking(Method III-A 的问题重写 + 代价函数形式)。
-
• 3D Object Flow 是一种“与 embodiment 解耦”的接口:同一条 3D Object Flow,可以用 trajectory optimization(真实机器人、Push-T)或 Reinforcement Learning(SAC)(Door Opening)去实现;论文强调“what needs to happen”与“how to realize”分离,从而跨越不同 action space / morphology。
-
• 工程管线完全靠 off-the-shelf 组件拼起来,但关键细节在“深度标定 + 点跟踪 + mask”这三步的鲁棒性:视频深度有 monocular 的 scale-shift ambiguity,需要用机器人真实深度对齐;3D Flow 来自 SAM 2 + CoTracker3 + 相机投影,任何一步失败都会导致 downstream 执行偏离(Method III-B + Failure 分析)。
-
• 实证上,3D Object Flow 比“rigid transform”接口更稳,尤其在 occlusion / 可见点少时:Table I 显示 Dream2Flow 在 Bread in Bowl / Open Oven / Cover Bowl 三个真实任务上优于 AVDC、RIGVID;论文解释原因是 Flow 目标对遮挡更“软”,不必每帧稳定估计刚体位姿。
-
• 瓶颈也很明确:上游 Video Generation 的 morphing/hallucination + 单视角遮挡 + 处理时延(3–11 min):论文给出失败类型统计(Fig.7)与典型例子(Fig.12),并在 Limitations 明确指出处理时间与 rigid-grasp 假设限制了可用任务范围。
2. 痛点与背景
2.1 现有方法具体卡在哪?
论文的动机很直接:Video Generation 模型能生成“看起来合理”的交互视频,但机器人需要低层可执行动作。核心卡点在 embodiment gap:视频里通常是 human embodiment(手、臂、姿态),而机器人 action space 可能是 joint torques、end-effector pose、skill primitives 等(Introduction + Method III-A 明确“不假设特定动作参数化 U”)。
2.2 prior work 为什么不可靠 / 不可扩展 / 成本高?
论文在 Related Works 把路径分成几类:
-
• language-conditioned visuomotor policy / VLA(Vision-Language-Action):需要大量机器人数据或特定对齐方式,扩展到 open-world 的成本高。
-
• outcome-based(如 image goal):目标表达不足以覆盖复杂状态变化(例如 articulated / deformable)。
-
• rigid transform / pose tracking from generated videos(AVDC、RIGVID 等):对 rigid object 假设敏感,一旦可见点少或发生遮挡,位姿/刚体变换估计噪声会放大到执行失败(论文在对比实验讨论“transform estimation noisy”)。
2.3 作者从哪个关键瓶颈切入?
他们认为真正的瓶颈不是“视频模型不会想象”,而是如何把视频预测转成机器人可用的控制目标。切入点是:
既然视频模型在给定初始图像 + 语言指令时,往往能合成“合理的物体运动”,那就只抽取 object motion,并在 3D 中追踪它。
这直接导向 3D Object Flow 中间表示(Introduction + Method)。
2.4 论文试图否定或修正的主流假设是什么?
-
• 修正假设 1:“从人类视频/生成视频到机器人控制,应该模仿人类动作”。Dream2Flow 明确避免直接 mimic human motion,而是追踪物体状态变化(object trajectory tracking)。
-
• 修正假设 2:“把生成视频转成刚体位姿序列就够了”。论文通过 Table I 表明仅用 rigid transforms 会在 deformable / occlusion 下崩溃,而 3D Object Flow 更通用。
2.5 目标定义:想优化什么?想避免什么?
目标是:给定语言指令 ℓ 与初始 RGB-D 观测 (I0, D0),输出动作序列 去完成任务;优化本质上是让真实物体点云轨迹贴近视频里重建的 3D Object Flow,同时满足控制可行性与平滑性等约束(Method III-A 的目标函数 + Real-world planning 细化)。
典型“之前路线失败症状”:model bias / hallucination 造成目标错位。论文在 Failure(Fig.12)中展示 Video Generation 会发生 object morphing 与 hallucination,导致点跟踪与 3D lifting 失败,机器人把物体送到错误位置或根本跟不上。
3. 核心方法拆解
3.1 整体方法总览
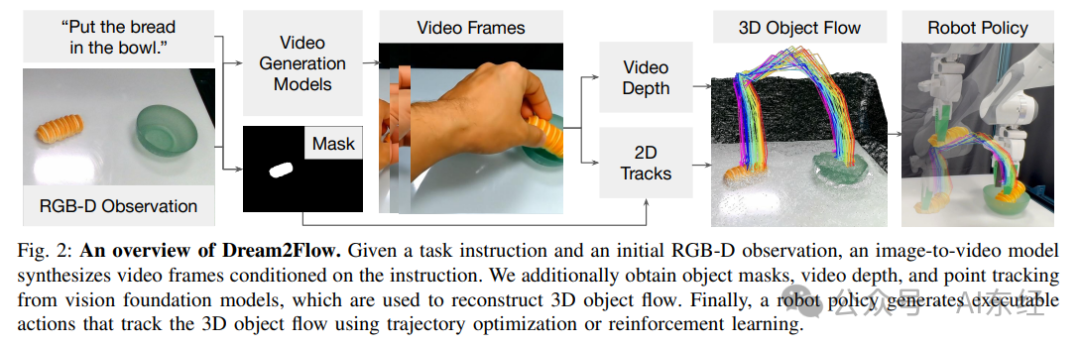
【Figure 2:An overview of Dream2Flow(视频生成→深度→2D tracks→3D Object Flow→Robot Policy)】
-
• 一句话解释:Dream2Flow 用 Video Generation “想象”任务中物体如何移动,再把这种移动重建成 3D Object Flow,最终让机器人通过规划或 RL 去追踪这条 3D 轨迹完成任务。
-
• 系统输入:任务语言指令 ℓ、初始 RGB-D 观测 (I0, D0)、相机投影 Π(含 intrinsics/extrinsics 到 robot frame)。
-
• 系统输出:动作序列 (论文明确不固定动作参数化,U 可是 motion primitive、end-effector pose 或 low-level controls)。
-
• Pipeline 阶段(按论文 Method III):
-
1. Video Generation:由 (I0, ℓ) 生成视频帧 {Vt};
-
2. Video Depth Estimation + calibration:生成每帧深度并用 D0 做 scale/shift 对齐;
-
3. Object mask + point tracking:定位任务相关物体,采样像素点并跨帧追踪得到 2D trajectories;
-
4. Lift to 3D:用深度与相机投影把可见点提升到 3D,得到 (3D Object Flow);
-
5. Action inference:将 manipulation 写成“追踪目标点集”的优化或 RL。
-
• 作者认为“最关键的建模发生在哪一步?”
-
-
• 关键决策点 1:把目标从‘动作’改写为‘物体 3D 轨迹’(III-A 的 formulation)。
-
• 关键决策点 2:如何在不同 domain/embodiment 下实现追踪(III-C 给了 Push-T 的 random shooting + learned dynamics、真实机器人 rigid-grasp + 轨迹优化、Door Opening 的 SAC)。
3.2 关键模块一:Extracting 3D Object Flows from Videos(Sec. III-B)
设计动机
-
• 视频模型擅长合成“合理的物体运动”,但人类手的动作对机器人不可直接执行;因此抽取 object motion 并转为 3D,是跨 embodiment 的最小信息子集(Introduction + III-B)。
输入/输出
-
• 输入:初始 RGB 图像 、语言指令 ℓ、机器人提供的初始深度 、相机投影 Π。
-
• 中间产物:生成视频帧 ,视频深度 ,物体 mask ,2D 轨迹 与可见性 。
-
• 输出:3D Object Flow 及可见性矩阵(论文记为 )。
内部核心机制
-
1. Video Generation(image-to-video)
-
• 论文有一个非常工程化的经验:不要把机器人出现在初始帧,也不要在 prompt 里提 robot,否则当前 image-to-video 模型在 fine-grained interaction 上更容易产生物理不合理轨迹(III-B 并指向 Appendix A 细节)。
-
-
2. Video Depth Estimation + Scale/Shift calibration
-
-
• 使用 SpatialTrackerV2 做单目视频深度(得到 ),但单目存在 scale-shift ambiguity;因此在第 1 帧用机器人真实深度 对齐,解出全局 ,得到
。 -
• 这一步非常关键:后续 lift 到 3D 全靠 Z 的尺度正确,否则 3D Flow 就是“看起来像”但坐标不对。
-
-
3. Object localization & mask:Grounding DINO → SAM 2
-
-
• 用 Grounding DINO 从 (I0, ℓ) 预测 bounding box,再用该 box prompt SAM 2 得到 binary mask 。
-
-
4. Point sampling & tracking:CoTracker3
-
-
• 在 t=1 的 mask 区域采样 n 个像素点,跨帧跟踪得到 与可见性 。
-
-
5. Lift to 3D:depth + camera projection
-
-
• 将可见点用 calibrated depth 与 Π 提升到 robot frame,得到 。
【Figure 2:管线示意(mask / depth / 2D tracks → 3D Object Flow)】
相对 prior work 的差异
-
• 与“dense optical flow → rigid transform”的路线相比(论文在 Table I 的对比对象 AVDC、RIGVID),Dream2Flow 直接保留 per-point 的 3D 轨迹,不强行压到刚体变换,因此对 deformable / articulated 的覆盖更自然。
3.3 关键模块二:Action Inference with 3D Object Flow(Sec. III-C)
模块之间的关系:串联还是循环?
-
• 在总体 pipeline 上是串联(生成→重建→控制)。
-
• 在 Push-T 的 planning 中存在循环重规划(replan):每次 push 后根据在线 tracking 更新粒子,再 random shooting 选下一步(Appendix C)。
是否存在显式 latent variable / world state / policy / value?
-
• 论文没有引入显式 latent world state(不像典型 World Model 会学 latent dynamics)。Dream2Flow 的“状态”更 object-centric: ,其中 是 object points, 是 robot state(III-A)。
-
• Policy/value:在 Door Opening 域使用 SAC 学 sensimotor policy(policy/value 属于 SAC 标配),但论文没有展开 network 结构细节(原文未说明)。
统一的优化视角(III-A)
论文把 action inference 写成:用动力学模型 roll out 预测 ,并最小化 object point 与目标 flow 的距离 + control 代价:
$$
\min_{{u_t\in U}}\sum_{t=0}^{H-1}\lambda_{task}(\hat x_t^{obj}, \tilde P_t)+\lambda_{control}(\hat x_t,u_t)
\quad \text{s.t.}\ \hat x_{t+1}=f(\hat x_t,u_t),\ \hat x_0=x_0
$$
其中
$$
\lambda_{task}(\hat x_t^{obj}, \tilde P_t)=\sum_{i=1}^{n}|\hat x_t^{obj}[i]-\tilde P_t[i]|_2^2
$$
(III-A 直接给出)。这里的“时间对齐”也很工程: 来自视频流 ,可通过 uniform time-warping 或 nearest-shape matching;具体实现细节在不同 domain 里进一步落地(III-A/III-C/Appendix C/H)。
三个 domain 的实例化(III-C)
-
1. Simulated Push-T(non-prehensile)
-
• Action space:push skill primitive,参数为起点 、方向 、距离 d。
-
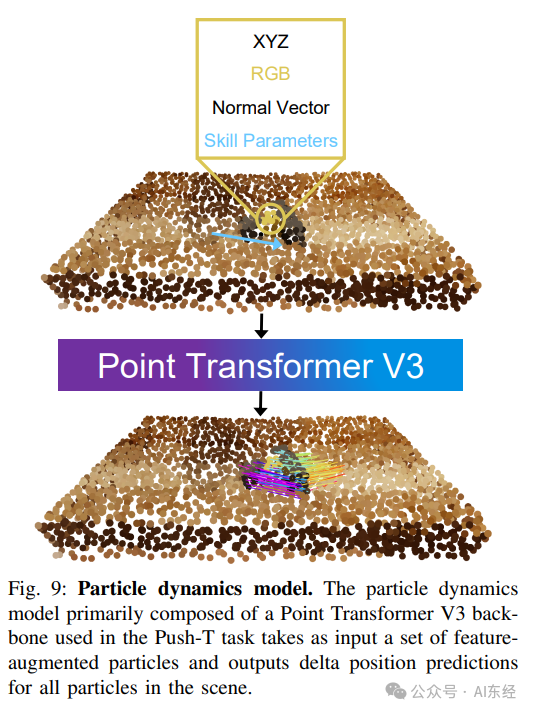
• Dynamics:学习一个 particle-based forward dynamics,输入是 feature-augmented particles ,输出每点位置增量 (III-C + Appendix B 的 Point Transformer V3 结构示意 Fig.9)。
-
• Planning:random shooting 随机采样 r 个 push 参数,roll out 预测并选 cost 最小者;并用“最近时刻 ”做子目标对齐(III-C + Appendix C)。
-
-
2. Real-World(rigid grasp + trajectory optimization)
-
-
• Action space:absolute end-effector poses。
-
• 先 grasp 再 move:用 AnyGrasp 生成 grasps,再用 HaMer 检测视频里 thumb 位置,选与 thumb 最近的 grasp(III-C + Appendix D + Fig.10)。
-
• Dynamics:rigid-grasp assumption——被抓取的点集做刚体变换,非抓取点不动;然后用 PyRoki 做轨迹优化,并加入 smoothness / reachability 等控制项(III-C + Appendix F)。
-
-
3. Simulated Door Opening(RL / SAC)
-
-
• 把 “追踪 3D Object Flow 的优化过程” 编译成 parametric policy:用 simulator 作为 dynamics model,reward 用 3D Object Flow(III-C)。
-
• 论文观察到不同 embodiment 会学出不同策略(Fig.6):Spot 会移动 base 改善 reachability,GR1 会用手掌与手指间区域增强稳定性。
作者如何避免常见问题:model bias / distribution shift / error accumulation?
-
• model bias(上游视频偏差):论文并没有给出可证明的“消除机制”,更多是通过 failure analysis 明确指出问题来源(morphing / hallucination / camera motion)并通过 prompt 工程(still camera、by one hand 等)降低发生概率(Appendix A + Fig.12 + Table III 讨论)。也就是说,“避免”主要是工程约束与筛选,而非理论保证(论文未给出明确机制)。
-
• compounding errors(轨迹误差累积):Push-T 通过 replan + intermediate subgoal(lookahead L=20)缓解;Door Opening 用 RL 让策略在环境闭环中自适应(Appendix C/H)。
-
• distribution shift:论文没有系统讨论“训练分布 vs 测试分布”的理论边界,但在真实任务中做了 instance/background/viewpoint 的 robustness 评估(Fig.4),属于经验性证据。
3.4 训练目标与优化逻辑
训练 vs 推理是否不同?
Dream2Flow 本身更像一个 pipeline,不是端到端训练一个大模型;训练/优化主要发生在两处:
-
1. Push-T 的 particle dynamics model(需要收集 transitions 训练)
-
2. Door Opening 的 SAC policy(需要训练 iterations)
真实机器人部分主要是 trajectory optimization,不涉及 learning policy(至少在论文中如此)。
Push-T:Particle dynamics model 的训练(Appendix B)
-
• 数据:收集 500 transitions 的随机 pushing。
-
• 标注方式:在仿真里为效率用 simulator 的 object pose 得到粒子前后位置;论文备注“实践中也可用 CoTrackerV3 + depth 追踪”(Appendix B)。
-
• 网络:Point Transformer V3 backbone + MLP 投影(Fig.9)。
Real-world:trajectory optimization 的目标展开(Appendix F)
论文把 control cost 展开成三项,并给出权重:
$$
\sum_{t=0}^{H-1}\lambda_{task}(\hat x_t^{obj},\tilde P_t)+\lambda_{control}(\hat x_t,u_t)
$$-
• :reachability(越界惩罚)
-
• :pose smoothness(相邻末端位姿差)
-
• :manipulability(鼓励可操作性)
权重: ,task cost 权重 。之后用 B-spline 拟合并用 PyBullet IK + impedance controller 执行(Appendix F)。
Door Opening:SAC 的 reward 形式(Appendix H)
论文把对比的 handcrafted reward 与 3D Object Flow reward 都明确写成公式:
-
• Object state reward:含 reach 与 rotation (Eq.(3)(4)),并在 hinge angle 超阈值时给 completion reward。
-
• 3D Object Flow reward:
-
-
• particle tracking term (Eq.(5)),其中 通过
(Eq.(6))确定;
-
• end-effector alignment term (Eq.(7)),鼓励末端靠近 object particles 的均值位置。
-
-
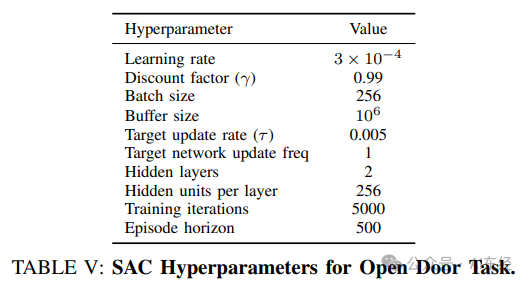
• SAC 超参 Table V:learning rate 、 、batch size 256、buffer size 、 、hidden layers 2、units 256、training iterations 5000(GR1 用 10000)、episode horizon 500(Appendix H)。
训练流程小结
-
• Step 1:用 Video Generation 生成任务视频(并通过 prompt 约束手与相机)。
-
• Step 2:深度估计并用初始真实深度对齐尺度;SAM 2 分割 + CoTracker3 跟踪;lift 得到 3D Object Flow。
-
• Step 3A(Push-T):训练 particle dynamics(500 transitions)→ random shooting + replan 执行。
-
• Step 3B(Real-world):AnyGrasp + HaMer 选 grasp → PyRoki 优化轨迹 → IK + controller 执行。
-
• Step 3C(Door):用 SAC 以 3D Object Flow reward 训练 policy。
3.5 符号表(必须有)
Symbol
Meaning
Where it appears
task instruction (language)
Method III-A
initial RGB observation
Method III-A / III-B
initial depth from robot
Method III-A / III-B
camera projection (intrinsics/extrinsics to robot frame)
Method III-A
generated video frame at time t
Method III-B
uncalibrated / calibrated video depth
Method III-B
binary mask of task-relevant object
Method III-A / III-B
2D track and visibility for sampled point i at time t
Method III-B
3D object flow (trajectory of n object points over T frames)
Method III-A / III-B
action sequence
Method III-A
state (object points + robot state)
Method III-A
dynamics model
Method III-A / III-C
predicted next state under dynamics
Method III-A
time-aligned target points from video flow
Method III-A
tracking cost / control cost
Method III-A / Appendix F
closest timestep index in reference flow
III-C / Appendix C / Appendix H
3.6 方法小结
Dream2Flow 本质上在建模的是:“任务相关物体的状态变化轨迹”,并将其作为可迁移的控制目标。它改变了主流路线里“必须把语言直接映射到动作/技能”的假设,把语言→视频→物体 3D 运动当作中间层。其设计哲学是:用生成模型提供高层意图与物理先验,用 flow 抽取可执行的状态变化,再由规划/RL 负责满足 embodiment 约束。优势成立的条件在论文里也很清楚:上游视频必须给出足够正确的物体运动、视角遮挡不能太重、以及(真实世界)rigid-grasp 假设要基本成立;否则就会落入论文总结的失败模式(Fig.7/Fig.12/Limitations)。
4. 实验数据说话
论文的实验问题(IV 开头)围绕 5 个点:3D Object Flow 作为接口的属性、与替代接口对比、作为 RL reward 的效果、视频模型选择影响、动力学模型选择影响。
4.1 核心结果概览
【Table I:Real robot 上 Dream2Flow vs AVDC vs RIGVID(Bread in Bowl / Open Oven / Cover Bowl)】
【Table III:不同 Video Generation Model 的影响(Wan2.1 / Kling 2.1 / Veo 3)】
【Table IV:Dynamics model ablation(Pose / Heuristic / Particle)】-
1. Dream2Flow 相对 rigid transform 接口的优势(Table I)
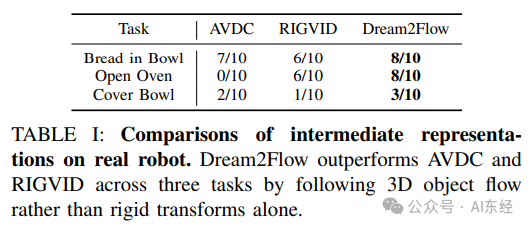
-
• Bread in Bowl:Dream2Flow 8/10(高于 AVDC 7/10、RIGVID 6/10)
-
• Open Oven:Dream2Flow 8/10(AVDC 0/10、RIGVID 6/10)
-
• Cover Bowl:Dream2Flow 3/10(虽然整体都难,但仍高于 AVDC 2/10、RIGVID 1/10)
这组结果的重要性不在“8/10 很高”,而在于:当目标物体不是严格刚体、或可见点不足以稳定估计变换时,强行估计 rigid transform 会把噪声放大到执行层;3D Object Flow 追踪则允许在可见区域强约束、遮挡时弱约束,轨迹更平滑(论文对比段落解释)。
-
1. Video Generation 模型选择直接决定上限(Table III + 文字分析)
-
• Push-T:Wan2.1 52/100,Kling 2.1 31/100(Veo 3 当时不支持 goal image prompting,所以无结果)
-
• Open Oven:Wan2.1 2/10,Kling 2.1 4/10,Veo 3 8/10
论文给出的解释很工程:Wan2.1 在 Open Oven 里更容易产生 camera motion,破坏“still camera”假设;Kling/Wan 也会出现 articulation axis 错误(绕错轴开门),导致失败;而 Veo 3 在真实域更稳。
-
1. 下游 dynamics model 的粒度影响巨大(Table IV)
Push-T 上:Pose 12/100、Heuristic 17/100、Particle 52/100。
这条证据说明:就算上游 3D Object Flow 指导一致,如果下游 dynamics 只建模 pose 或粗糙平移,无法解释旋转等关键变化,仍然完成不了任务;而 per-point particle dynamics 能更好覆盖复杂运动(论文结论段也再次强调)。
4.2 消融实验(Ablation)
严格来说,论文最清晰的“消融”是 dynamics model ablation(Table IV):
-
• 去掉 particle 级预测、换成 pose/heuristic 后成功率断崖式下降,说明 Dream2Flow 的优势不是“只要有个目标就能推”,而是下游必须有足够表达力的 dynamics/控制来匹配 flow 目标。
-
• 这也解释了为什么真实世界部分采用 rigid-grasp + 轨迹优化:它把 dynamics 简化成“被抓取点做刚体变换”,可行但能力边界明显(见 4.3 / 5.1)。
【Table IV:Dynamics model ablation(Pose / Heuristic / Particle)】
4.3 失败案例/局限性
论文不仅给了 failure case,而且给得很“可复现”:
-
• 失败统计(Fig.7):真实机器人共 60 次 trial,失败来源包括 video generation failures(12)、flow extraction failures(4)、robot execution failures(4)等;其中 video failures 主要是 morphing / hallucination。
-
• 具体例子(Fig.12):
-
-
• morphing:bread 变成 crackers,导致跟踪断裂;
-
• hallucination:凭空出现第二个 bowl,导致机器人把 bread 放错位置。
-
-
• 局限性(Appendix J):
-
1. 真实世界依赖 rigid-grasp assumption,限制任务类型;要扩展到真实世界的 particle dynamics“non-trivial”;
-
2. 获取 3D Object Flow 总耗时 3–11 分钟,主要瓶颈是 video generation;
-
3. 单视角生成视频难以处理 heavy occlusions,未来可考虑 3D point trackers 或 full 4D representations。
5. 总结与展望
5.1 真实贡献边界
基于论文原文,Dream2Flow 的真实贡献可以严格表述为三点:
-
1. 提出并验证 3D Object Flow 作为 video→robot 的通用接口:把 manipulation 形式化为 object trajectory tracking,并能接入 trajectory optimization 或 RL(III-A/III-C + 多任务实验)。
-
2. 证明该接口在多类对象与任务上可用:覆盖 rigid、articulated、deformable、granular(Abstract/Intro + Fig.1/任务集),并在真实机器人任务上优于 rigid transform 基线(Table I)。
-
3. 给出清晰的 failure taxonomy 与工程约束:still camera prompt、by one hand、morphing/hallucination、遮挡导致 tracking dropout、grasp selection mismatch(Appendix A/D + Fig.7/Fig.12)。
边界同样清晰:
-
• 已解决(有证据):在一组 open-world manipulation 任务上,能零样本利用 video model 的“物体运动先验”,并通过 flow interface 转成可执行动作/策略。
-
• 未解决(从实验与假设分析得到):
-
-
• 上游视频如果发生严重 camera motion、错误 articulation axis、或 morphing/hallucination,系统会系统性失败(Table III + Fig.12)。
-
• 真实世界对 deformable / non-rigid 的能力仍弱(Cover Bowl 3/10),与 rigid-grasp 假设直接相关(Table I + Limitations)。
-
5.2 可落地性判断
-
1. 最可能直接落地的组件:
-
• “3D Object Flow 作为目标接口”的思想本身 + “mask + point tracking + depth lifting”这套 perception 组合(SAM 2 / CoTracker / depth estimation)——因为它不要求大规模机器人数据训练,且可替换其中任意模块。
-
-
2. 落地最大工程难点:
-
-
• 时延:3–11 分钟主要卡在 video generation(Limitations),对 real-time manipulation 不友好;
-
• 可靠性:morphing/hallucination 与遮挡问题会让系统“目标错误但还在执行”,这在安全上是硬伤;论文没有给出安全监测/回退策略(原文未说明)。
-
-
3. 对自动驾驶/机器人等领域的意义:
-
-
• 对机器人:提供一种“可替换、可组合”的接口,把 Video Generation 的强先验用于任务规格化;
-
• 对更广义的 Embodied AI:强调“世界模型输出不一定要是 action”,也可以是 object-centric 的中间表示,让下游控制去适配 embodiment。
5.3 前瞻观点
以下展望若超出论文内容,我会明确标注为推断。
-
1. 把 Video Generation 的不确定性显式化,变成“分布式 3D Object Flow”而不是单一路径(基于论文信息的合理推断,非原文结论)
论文失败大量来自上游生成错误(Fig.7/Fig.12)。一个可检验方向是:对同一 (I0, ℓ) 采样多条视频→多条 flow,形成候选集合,并在下游用可行性/代价筛选最一致的一条(或做 risk-aware planning)。验证方式:在相同任务上比较单样本 vs 多样本的成功率与安全性。 -
2. 真实世界扩展的关键在“超越 rigid-grasp assumption 的可学习 dynamics”,但需要新的数据闭环(论文部分指出 + 推断)
论文明确说真实世界的 particle dynamics 训练与扩展 non-trivial(Limitations)。可检验方向:用机器人在线跟踪(CoTracker + depth)收集真实世界粒子转移,做自监督/弱监督的 dynamics 学习,然后把 Dream2Flow 的 flow tracking 目标接上去。验证方式:在 articulated + deformable 任务上对比 rigid-grasp 版本与 learned particle dynamics 版本。 -
3. 遮挡鲁棒性需要从“单视角 2D tracks”升级到“3D point tracking / 4D 表示”(论文给出的未来方向)
论文已经点名 heavy occlusions 是硬限制,并建议 3D point trackers 或 full 4D representations(Limitations)。这是一个非常清晰可检验路线:替换 tracking 模块后,在小物体/手部遮挡严重任务上测成功率与轨迹误差。
工程复现提示(仅基于论文/附录)
-
• Prompt 工程不是装饰:真实任务 prompt 必须包含 “by one hand” 与 “the camera holds a still pose” 来降低 camera motion,并辅助 grasp selection(Appendix A)。
-
• Push-T 规划的“lookahead 子目标”很关键:L=20(Appendix C),否则只追最终状态会出现“平移误差小但旋转误差大”导致 timeout。
-
• Real-world 轨迹优化的权重给得很具体: ,并用 B-spline + IK + impedance controller 执行(Appendix F)。
【具身智能】学习路线发布!
扫描下方二维码加群后,即可领取学习!

【具身智能】知识星球优惠券链接:
https://t.zsxq.com/CdGte
【具身智能】vip 微信交流群成立!
还有 vip 微信交流群!已加入【具身智能】知识星球的同学,一定要扫描下方二维码,添加具身智能小助手的微信(微信号:EAI0011),她会拉你进【具身智能】 vip 微信交流群!还可以第一时间从她的朋友圈获取本星球的所有内容推送,更方便大家学习。

 点击阅读原文,加入具身学习群!
点击阅读原文,加入具身学习群! -

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 0
0 0
0- 0



 已为社区贡献58条内容
已为社区贡献58条内容

所有评论(0)