基于 MediaPipe 的人体姿态估计与面部网格检测实战:从原理到代码全解析
本文介绍了基于MediaPipe框架的人体姿态估计和面部网格检测技术。主要内容包括:1.环境配置与核心依赖库安装;2.静态图像人体姿态估计实现,解析33个三维关键点检测与可视化;3.实时视频面部网格检测,讲解478个面部关键点的精细化建模;4.两种技术的对比分析与优化建议。通过完整可运行的Python代码示例,详细演示了从图像处理、模型推理到结果可视化的全过程,适用于运动分析、表情识别、虚拟交互等
在计算机视觉与人工智能交互领域,人体姿态感知和面部精细化分析是两大核心技术方向,广泛应用于运动健身、虚拟主播、表情交互、行为识别、影视特效等场景。谷歌开源的MediaPipe框架,凭借轻量化、高精度、跨平台的优势,成为实时感知任务的首选工具,无需深度学习基础即可快速实现工业级效果。
本文将基于两段完整可运行的 Python 代码,深度讲解MediaPipe 人体姿态估计和MediaPipe 面部网格(Face Mesh)检测两大核心功能。文章将从环境配置、核心原理、代码逐行解析、参数调优、应用场景等维度展开,全程 3000 字干货,帮助零基础开发者快速掌握实时视觉感知技术,完成从理论到实战的跨越。
本文所有代码适配 Windows、Mac、Linux 系统,依赖库仅需 OpenCV 和 MediaPipe,代码可直接复制运行,适合计算机视觉初学者、毕业设计开发者、交互技术爱好者学习使用。
一、环境搭建:零基础配置开发环境
在开始实战前,我们需要配置 Python 开发环境,并安装核心依赖库。MediaPipe 对环境要求极低,无需配置 CUDA 等深度学习环境,普通电脑即可流畅运行。
1.1 安装 Python
推荐安装 Python 3.8 及以上版本,官网下载地址:https://www.python.org/,安装时勾选Add Python to PATH,配置环境变量。
1.2 安装核心依赖库
打开电脑的命令提示符(CMD)或终端,执行以下两条命令,一键安装 OpenCV(图像处理)和 MediaPipe(感知模型):
# 安装OpenCV计算机视觉库
pip install opencv-python
# 安装MediaPipe谷歌感知框架
pip install mediapipe
安装完成后,无报错即代表环境配置成功,接下来即可进入实战环节。
1.3 素材准备
- 人体姿态检测:准备一张名为
dongzuo.png的人体图片,放置在代码同级目录; - 面部网格检测:准备一段名为
smile.mp4的视频文件,也可直接调用电脑摄像头。
二、实战一:MediaPipe 静态图像人体姿态估计
2.1 功能概述
MediaPipe Pose 是谷歌推出的高精度人体姿态估计模型,能够在单张图片或视频中,检测出人体33 个三维关键点,覆盖头部、躯干、手臂、腿部等全身部位,同时输出关键点的三维坐标(x,y,z),并支持 3D 姿态可视化。该模型支持三种精度模式,兼顾速度与识别效果,广泛应用于运动分析、姿态矫正、体感交互等领域。
2.2 核心原理
- 关键点定义:MediaPipe Pose 共检测 33 个关键点,包含鼻子、肩膀、手肘、手腕、髋部、膝盖、脚踝等核心部位,每个关键点都有唯一的索引和空间坐标;
- 模型工作流程:读取图像 → 颜色空间转换(BGR 转 RGB) → 模型推理检测关键点 → 绘制骨骼连线 → 输出结果;
- 坐标说明:x、y 为归一化坐标(0~1),乘以图像宽高可得到像素坐标;z 为深度坐标,代表关键点距离摄像头的距离,数值越小距离越近;
- 3D 可视化:模型支持输出世界坐标系关键点,可直接生成 3D 姿态骨骼图,直观展示人体空间姿态。
2.3 代码逐行深度解析
# 导入OpenCV和MediaPipe库
import cv2
import mediapipe as mp
# 程序主入口
if __name__ == '__main__':
# 初始化MediaPipe姿态估计模块
mp_pose = mp.solutions.pose
# 配置姿态估计模型参数
pose = mp_pose.Pose(
static_image_mode=True, # True:静态图片模式;False:视频动态模式
model_complexity=1, # 模型复杂度:0(快/低精)、1(中速/中精)、2(慢/高精)
smooth_landmarks=True, # 开启关键点平滑,消除抖动
min_detection_confidence=0.5, # 最小检测置信度,高于0.5才判定为有效关键点
min_tracking_confidence=0.5 # 最小跟踪置信度
)
# 初始化MediaPipe绘图工具,用于绘制关键点和骨骼线
drawing = mp.solutions.drawing_utils
# 1. 读取本地图片(OpenCV默认读取格式为BGR)
img = cv2.imread("dongzuo.png")
# 显示原始图片
cv2.imshow("原始图像", img)
# 2. 颜色空间转换:BGR转RGB(MediaPipe模型仅支持RGB格式输入)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# 3. 调用模型进行姿态推理
results = pose.process(img)
# 4. 转换回BGR格式,用于OpenCV显示
img = cv2.cvtColor(img, cv2.COLOR_RGB2BGR)
# 打印关键点总数(固定为33个)
print("人体关键点总数:", len(results.pose_landmarks.landmark))
# 遍历33个关键点,打印三维坐标
for i in range(len(results.pose_landmarks.landmark)):
x = results.pose_landmarks.landmark[i].x # 水平坐标
y = results.pose_landmarks.landmark[i].y # 垂直坐标
z = results.pose_landmarks.landmark[i].z # 深度坐标
print(f"关键点{i} 坐标:x={x:.3f}, y={y:.3f}, z={z:.3f}")
# 绘制关键点和骨骼连接线
drawing.draw_landmarks(
img, # 绘制图像
results.pose_landmarks, # 姿态关键点数据
mp_pose.POSE_CONNECTIONS # 骨骼连接规则
)
# 显示绘制关键点后的图像
cv2.imshow("姿态关键点检测结果", img)
# 3D姿态可视化:生成世界坐标系的3D骨骼图
drawing.plot_landmarks(results.pose_world_landmarks, mp_pose.POSE_CONNECTIONS)
# 等待按键按下后关闭窗口
cv2.waitKey(0)
cv2.destroyAllWindows()
2.4 核心参数详解
static_image_mode:静态图片设为True,模型会对每张图片独立检测;视频处理设为False,模型会跟踪关键点,提升速度;model_complexity:核心参数,0 适合低配设备实时处理,1 适合常规场景,2 适合高精度离线分析;smooth_landmarks:开启后平滑关键点坐标,避免检测结果抖动,提升视觉效果;min_detection_confidence:置信度阈值,建议 0.5~0.8,数值越高,检测结果越精准,但可能漏检。
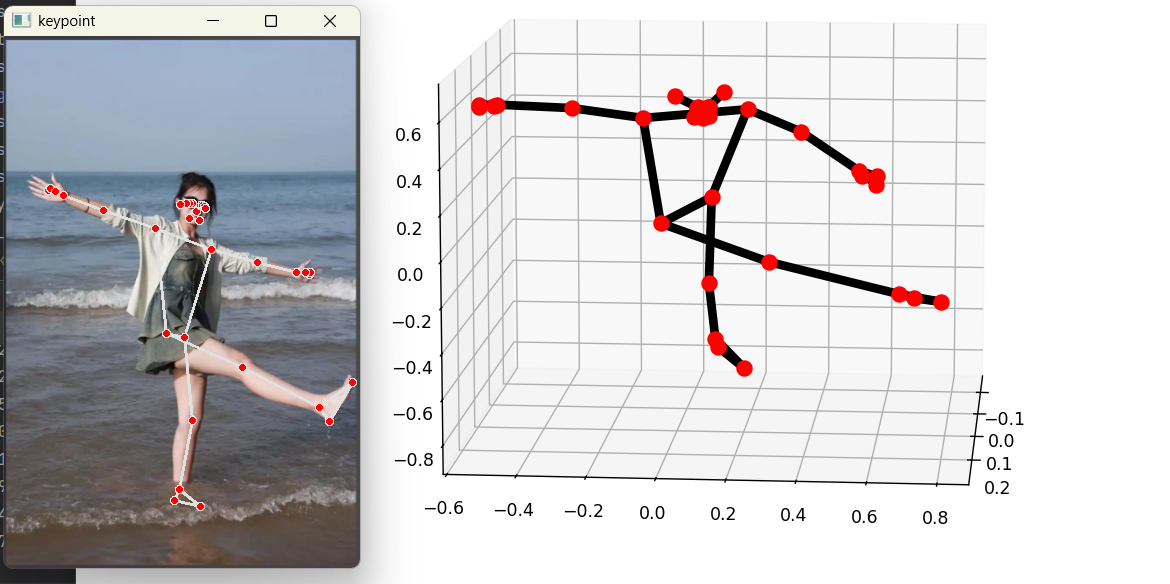
2.5 运行效果
运行代码后,会依次弹出三个窗口:
- 原始人体图片;
- 标注了 33 个关键点和骨骼连线的检测结果图;
- 3D 立体姿态可视化窗口,可旋转查看人体空间姿态。同时控制台会打印 33 个关键点的精确三维坐标,可用于后续姿态分析、动作识别等开发。
2.6 拓展应用场景
- 运动健身:深蹲、俯卧撑、瑜伽等动作标准度检测;
- 体感交互:无接触手势控制、体感游戏开发;
- 安防监控:人体行为识别、跌倒检测;
- 影视特效:虚拟数字人动作捕捉。
三、实战二:MediaPipe 实时视频面部网格检测
3.1 功能概述
MediaPipe Face Mesh 是一款面部精细化关键点检测模型,能够实时检测面部478 个高精度三维关键点,构建面部三维网格模型,实现对面部轮廓、眼睛、鼻子、嘴巴、眉毛等部位的精细化建模。模型支持同时检测多张人脸,支持视频流实时处理,是表情识别、美颜滤镜、虚拟试妆、面部动画的核心技术。
相比于传统的 68 点人脸检测,478 点面部网格检测精度提升数倍,能够捕捉微表情和面部细微结构,且运行速度极快,普通电脑摄像头可实现 30 帧 / 秒的实时处理。
3.2 核心原理
- 478 关键点:覆盖面部全区域,包括眼球、嘴唇内侧、面部轮廓等细微部位,实现三维面部重建;
- 实时处理流程:读取视频 / 摄像头 → 逐帧预处理 → 模型检测面部网格 → 绘制关键点编号与纹理网格 → 实时显示;
- 网格绘制:通过
FACEMESH_TESSELATION参数,绘制面部三角网格纹理,还原面部三维结构; - 坐标应用:关键点坐标可用于表情判断、头部姿态估计、视线追踪等高级功能。
3.3 代码逐行深度解析
# 导入OpenCV和MediaPipe库
import cv2
import mediapipe as mp
# 初始化MediaPipe面部网格模块
mp_face_mesh = mp.solutions.face_mesh
# 初始化绘图工具和绘图样式
mp_drawing = mp.solutions.drawing_utils
mp_drawing_styles = mp.solutions.drawing_styles
# 配置面部网格模型参数
face_mesh = mp_face_mesh.FaceMesh(
static_image_mode=False, # False:视频动态模式;True:静态图片模式
max_num_faces=2, # 最大检测人脸数量
refine_landmarks=True, # 开启关键点精细化,提升眼睛、嘴唇检测精度
min_detection_confidence=0.5, # 最小检测置信度
min_tracking_confidence=0.5 # 最小跟踪置信度
)
# 打开视频文件/摄像头(0为默认摄像头,替换为视频路径即可处理视频)
cap = cv2.VideoCapture('smile.mp4')
# 循环读取视频帧
while cap.isOpened():
# 读取单帧画面
success, frame = cap.read()
# 获取画面的高度和宽度
h, w = frame.shape[:2]
# 判断是否读取成功,读取失败则退出循环
if not success:
print("无法读取视频画面")
break
# 颜色空间转换:BGR转RGB,适配MediaPipe模型
frame_rgb = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
# 模型推理:检测面部网格关键点
results = face_mesh.process(frame_rgb)
# 判断是否检测到人脸
if results.multi_face_landmarks:
# 遍历检测到的每一张人脸
for face_landmarks in results.multi_face_landmarks:
# 遍历478个面部关键点,绘制编号
for i in range(len(face_landmarks.landmark)):
# 获取归一化坐标
x = face_landmarks.landmark[i].x
y = face_landmarks.landmark[i].y
# 将归一化坐标转换为像素坐标,绘制关键点编号
cv2.putText(
frame, str(i),
(int(x * w), int(y * h)),
cv2.FONT_HERSHEY_SIMPLEX,
0.3, (0, 255, 0), 1
)
# 绘制面部三角网格纹理
mp_drawing.draw_landmarks(
image=frame,
landmark_list=face_landmarks,
connections=mp_face_mesh.FACEMESH_TESSELATION,
landmark_drawing_spec=None,
connection_drawing_spec=mp_drawing_styles.get_default_face_mesh_tesselation_style()
)
# 实时显示检测结果
cv2.imshow('Face Mesh', frame)
# 按下ESC键退出程序
if cv2.waitKey(1) == 27:
break
# 释放视频资源
cap.release()
# 关闭所有OpenCV窗口
cv2.destroyAllWindows()
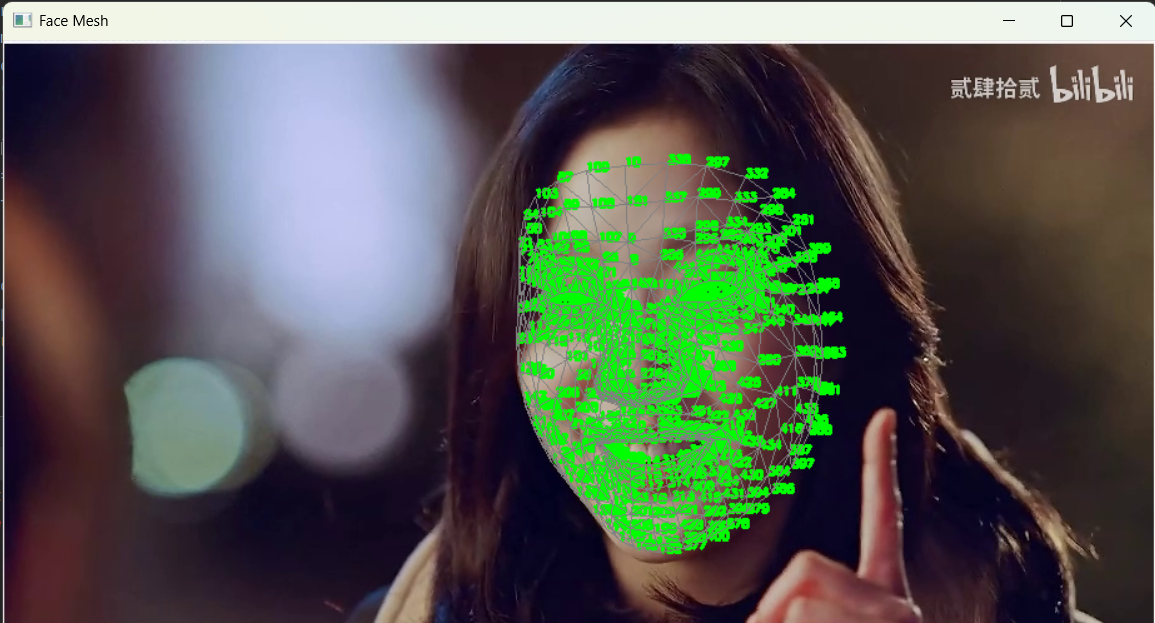
3.4 核心参数与函数详解
max_num_faces:根据需求设置最大检测人脸数,默认 1,本文设置为 2,支持双人同时检测;refine_landmarks:必须开启,开启后模型会精细化眼睛、嘴唇区域的关键点,精度大幅提升;FACEMESH_TESSELATION:面部三角网格连接规则,绘制后可呈现三维面部结构;- 摄像头调用:将
cv2.VideoCapture('smile.mp4')改为cv2.VideoCapture(0),即可直接调用电脑摄像头进行实时检测。
3.5 运行效果
运行代码后,程序会自动读取视频文件,实时检测画面中的人脸,标注 478 个关键点的编号,并绘制绿色的面部三角网格。面部移动时,网格和关键点会实时跟踪,无明显延迟,检测效果流畅精准。无论是微笑、睁眼、转头等动作,模型都能精准捕捉关键点位置。
3.6 拓展应用场景
- 美颜美妆:虚拟口红、美瞳、腮红、瘦脸等滤镜开发;
- 表情交互:微笑、眨眼、皱眉等微表情识别;
- 虚拟主播:面部动画驱动、数字人表情生成;
- 医疗健康:面部肌肉分析、疲劳检测、干眼症筛查;
- 人机交互:视线追踪、头部姿态控制。
四、两大核心技术对比与进阶优化建议
4.1 技术对比总结
| 功能 | MediaPipe Pose | MediaPipe Face Mesh |
|---|---|---|
| 检测目标 | 全身人体 | 面部精细化区域 |
| 关键点数量 | 33 个 | 478 个 |
| 应用场景 | 姿态分析、体感交互 | 表情识别、美颜特效 |
| 运行速度 | 极快 | 快速 |
| 坐标类型 | 三维空间坐标 | 三维精细化坐标 |
4.2 进阶优化建议
- 速度优化:将
model_complexity设为 0,关闭不必要的可视化绘制,降低图像分辨率; - 精度优化:提高
min_detection_confidence至 0.7,开启refine_landmarks,使用复杂度更高的模型; - 功能拓展:结合关键点坐标,编写逻辑判断动作(如抬手、微笑),实现交互控制;
- 保存结果:使用
cv2.imwrite()保存检测后的图片,使用视频写入器保存检测后的视频。
五、学习总结与未来展望
通过本文的两段实战代码,我们完成了从人体全身姿态感知到面部精细化网格分析的全流程学习。MediaPipe 框架的核心优势在于开箱即用、高精度、实时性强,彻底降低了计算机视觉感知技术的开发门槛,让零基础开发者也能快速实现专业级效果。
人体姿态估计解决了人体行为感知的问题,面部网格检测解决了面部表情感知的问题,二者结合可以构建完整的人机交互系统,应用于智能家居、虚拟现实、智能汽车、教育培训等多个领域。
对于开发者而言,掌握本文的技术后,可进一步拓展学习:
- 结合 PyQt 开发可视化交互软件;
- 结合深度学习实现动作分类、表情分类;
- 移植到移动端(Android/iOS)实现移动端感知应用;
- 结合 OpenCV 实现视频录制、图像保存等功能。
六、结语
计算机视觉的核心价值是让机器拥有 “视觉感知能力”,而 MediaPipe 正是实现这一目标的最佳工具之一。本文从环境配置到代码解析,从原理讲解到应用拓展,全方位覆盖了人体姿态估计和面部网格检测的核心知识点,旨在帮助每一位初学者快速入门。
技术的魅力在于实践与创新,希望大家能够基于本文的代码,发挥自己的创意,开发出属于自己的交互项目。无论是毕业设计、趣味工具还是商业应用,MediaPipe 都能为你提供强大的技术支撑。
最后,提醒各位开发者,技术是一把双刃剑,在使用面部检测、姿态识别等技术时,务必遵守法律法规,尊重他人隐私,让技术服务于社会,创造更多价值。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 24
24 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)