牛津&Meta开源!CoWTracker:跟踪一切!新SOTA引领多个稠密点跟踪基准
我们推测,这一优势源于我们的头部直接对图像特征进行操作,而不是在构建代价体时将外观压缩为相关分数:点积相似性可能会丢弃边界处对可见性具有预测性的通道线索,而基于扭曲索引的特征则保留了这些信息,供遮挡头部使用。太长不看版:基于简单变形算法的架构,实现密集点跟踪和光流计算,无需使用成本高昂的体积数据,却能在TAP-Vid和RoboTAP测试中取得领先成果,同时具备出色的零样本光流性能。与我们的研究更相
点击下方卡片,关注「3D视觉工坊」公众号
选择星标,干货第一时间送达
来源:3D视觉工坊
「3D视觉从入门到精通」知识星球(点开有惊喜) !星球内有20多门3D视觉系统课程、200+场顶会直播、顶会论文最新解读、3D视觉算法源码、项目承接、求职招聘等。想要入门3D视觉、做项目、搞科研,欢迎加入!

太长不看版:基于简单变形算法的架构,实现密集点跟踪和光流计算,无需使用成本高昂的体积数据,却能在TAP-Vid和RoboTAP测试中取得领先成果,同时具备出色的零样本光流性能。

论文信息
标题:CoWTracker: Tracking by Warping instead of Correlation
作者:Zihang Lai, Eldar Insafutdinov, Edgar Sucar, Andrea Vedaldi
机构:Visual Geometry Group, University of Oxford、Meta AI
原文链接:https://arxiv.org/abs/2602.04877
代码链接:http://cowtracker.github.io/
导读
密集点跟踪是计算机视觉领域的基本问题,其应用范围涵盖视频分析到机器人操控等众多领域。目前的先进跟踪算法通常依赖成本体积来匹配不同帧间的特征,但这种方法在空间分辨率上存在二次方复杂度问题,从而限制了算法的可扩展性和效率。在本文中,我们提出了一种新型的密集点跟踪算法,该算法摒弃了成本体积模型,转而采用变形技术来实现特征匹配。受光流算法最新进展的启发,我们的算法通过根据当前估计结果将目标帧的特征变形到查询帧上来迭代优化跟踪结果。结合能够对所有跟踪对象进行时空联合推理的Transformer架构,我们的设计能够在无需计算特征相关性的情况下建立长距离对应关系。该模型结构简洁,在包括TAP-Vid-DAVIS、TAP-Vid-Kinetics和Robo-TAP在内的标准密集点跟踪基准测试中均取得了领先性能。值得注意的是,该模型在光流估计方面也表现出色,有时甚至在Sintel、KITTI和Spring等基准测试中超越了专用光流算法。这些结果表明,基于变形技术的架构有望实现密集点跟踪与光流估计的统一处理。
效果展示
CoWTracker结果。我们的追踪器能够在各种现实场景中生成密集且覆盖范围广泛的点轨迹。它能够可靠地跟踪处于快速运动状态中的人(a、b、c、e)、多次被遮挡且背景杂乱的动物(d),以及在具有挑战性的户外环境中行驶的车辆(b、f)。角点图像显示了来自第0帧的查询点。结果通过8倍的抽样方式进行缩减(仅显示预测点的1/64)。

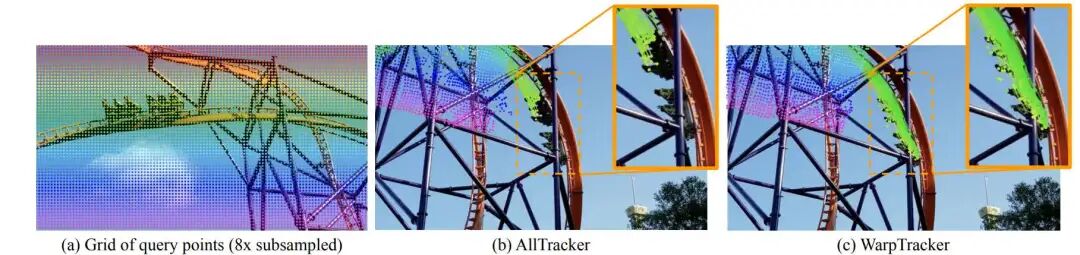
引言
点跟踪与计算机视觉的发展历史一样悠久,且至今仍是视频分析领域的重要工具。尽管早期的跟踪器基于基本原理和手工设计,但随着相关滤波器的引入,深度学习改变了这一领域。点跟踪领域的最新进展主要集中任意点跟踪(TAP)方法上,该方法利用神经网络跟踪视频中的任意点。PIPs模型对后续研究产生了深远影响。该模型设计的关键在于使用Transformer网络随时间推移对轨迹进行推理,将每个点轨迹视为一个标记序列。另一个关键方面借鉴了光流文献中的方法,即使用代价体(cost volumes)来衡量跨帧图像特征之间的相似性,从而促进点匹配。
特征关联和代价体计算是光流和跟踪中的基本方法。然而,它们可能成为瓶颈:将一幅图像中的每个特征与另一幅图像中的每个特征进行匹配,其计算量与图像分辨率的平方成正比。然而,最近一些光流研究对这一设计选择提出了质疑。例如,光流预测器在训练过程中可以逐渐减少对代价体的依赖,并在测试时弃用代价体。
与我们的研究更相关的是,WAFT 表明,代价体可以被一种基于扭曲(warping)的机制所替代,这种机制更简单且高效。
在本文中,我们探讨这些优势能否从光流领域转移到密集点跟踪领域。为了回答这一问题,我们提出了CoWTracker,这是一种新型密集点跟踪模型,它摒弃了代价体,转而采用与WAFT类似的扭曲机制。
WAFT借鉴了早期光流方法,同时也与空间变换器有关。简而言之,WAFT通过迭代方式优化两幅图像之间的对应关系。在每次迭代中,第二幅(目标)图像的密集特征会根据当前估计的正向光流扭曲回第一幅(源)图像。扭曲后的目标特征与相应的源特征在通道上进行拼接,然后由网络处理以更新光流估计。与代价体明确比较源图像中每个位置与目标图像中候选位置邻域的方法不同,这种方法仅评估由当前光流估计指定的单一配对。
乍一看,这种设计似乎无法有效建立匹配,因为每次迭代中每个源位置仅与一个目标位置配对。然而,WAFT的另一个见解是,如果通过自注意力机制,利用Transformer处理配对的特征,模型仍然可以对对应关系进行全局推理。
除了光流领域,在跟踪领域也提出了通过自注意力机制全局处理匹配的想法,例如CoTracker。基于这一观察,我们进一步探讨了联合跟踪与基于扭曲的匹配之间的联系。事实上,CoTracker中的联合跟踪是通过引入跨轨迹的自注意力层实现的,这与WAFT中用于全局对应关系推理的自注意力层在概念上是等价的。
基于这一联系,我们提出了一种基于扭曲的跟踪技术。我们为参考图像中的每个像素密集估计轨迹。根据当前轨迹估计,我们将所有其他帧的特征扭曲到参考帧。然后,我们使用一个在空间和时间维度上分别进行自注意力的Transformer来优化轨迹。这一设计灵感来源于PIPs和CoTracker的设计,同时也涵盖了WAFT中的空间注意力。
最终的设计极其简单却有效。当与强大的特征编码器(尤其是VGGT)结合时,CoWTracker在多个密集点跟踪基准测试中取得了最优性能,包括TAP-Vid-DAVIS [7]、TAP-Vid-Kinetics和Robo-TAP。此外,同一模型在光流任务中也表现出色,有时在Sintel、KITTI 和Spring等基准测试中超越了最优性能。
主要贡献
我们的贡献包括:(i)证明了基于扭曲的匹配在光流和跟踪任务中均表现良好,并利用这一观察构建了CoWTracker,这是一个统一的模型,无需计算代价体即可同时解决这两个问题;(ii)证明了CoWTracker在多个密集点跟踪基准测试中取得了最优性能;(iii)展示了同一模型在光流任务中也极具竞争力,有时在标准基准测试中超越了最优性能。我们认为,这一设计可作为未来光流、点跟踪及其他匹配任务研究的基石。
方法
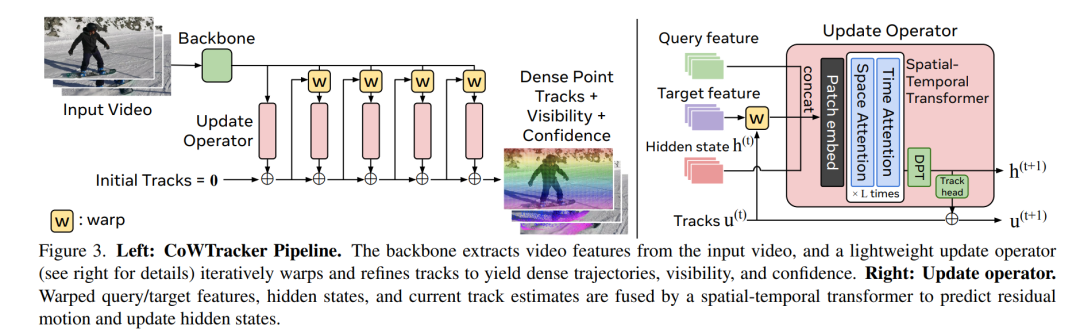
主干网络从输入视频中提取视频特征,轻量级更新算子(详见右侧)通过迭代扭曲和优化轨迹,生成密集轨迹、可见性和置信度。右侧:更新算子。扭曲的查询/目标特征、隐藏状态和当前轨迹估计通过时空Transformer融合,以预测残差运动并更新隐藏状态。
实验结果
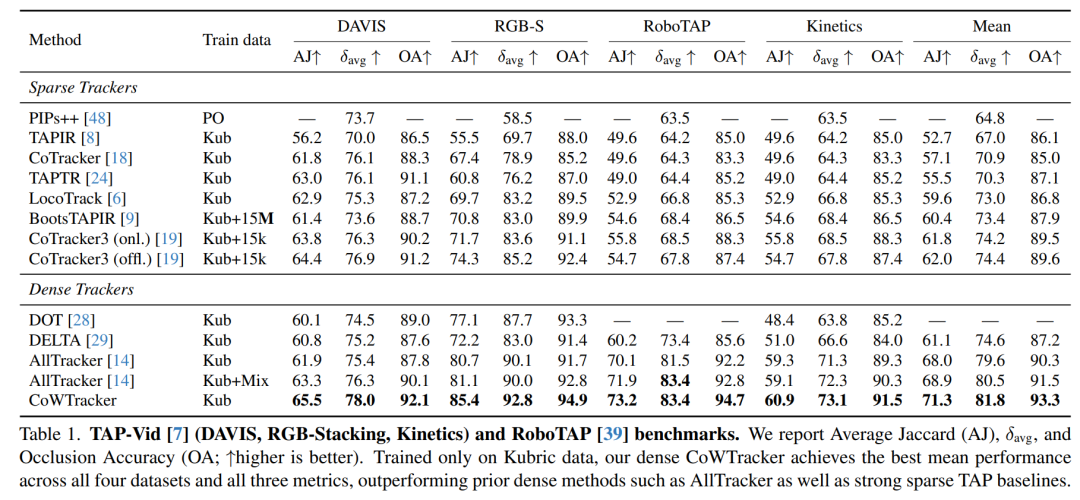
表1报告了TAP-Vid基准测试和RoboTAP的结果。我们的模型在所有四个数据集和所有三个指标上均超越了最优的密集先验模型AllTracker。在所有数据集上平均而言,CoWTracker将AJ提高了2.4,将δavg提高了1.3,将OA提高了1.8。就每个数据集而言,改进也是一致的。这些改进是在未使用代价体或多分辨率金字塔(AllTracker中使用)的情况下实现的,表明仅使用基于扭曲的头部和轻量级基于视频的Transformer即可实现精确的点跟踪。
当控制训练数据时,这一差距进一步扩大:与AllTracker(Kub)相比,CoWTracker在AJ/δavg/OA上的平均改进分别提高至3.3 / 2.2 / 3.0。我们将从野外Kinetics数据集到以机器人为中心的RGB-Stacking数据集等异构领域的鲁棒性归因于我们的基于扭曲的架构所实现的高分辨率像素对齐。
除了点跟踪精度外,CoWTracker在遮挡分类方面也表现出色。平均而言,与AllTracker(Kub)相比,我们将OA提高了3.0,与AllTracker(Kub+Mix)相比,我们将OA提高了1.8,在DAVIS数据集上的差距最大(+4.3)。
我们推测,这一优势源于我们的头部直接对图像特征进行操作,而不是在构建代价体时将外观压缩为相关分数:点积相似性可能会丢弃边界处对可见性具有预测性的通道线索,而基于扭曲索引的特征则保留了这些信息,供遮挡头部使用。

总结 & 未来工作
我们提出了CoWTracker,这是一种密集点跟踪器,它用基于迭代扭曲的优化替代了代价体。这种简单、基于扭曲的头部与空间分辨率呈线性关系,并在TAP-Vid和RoboTAP基准测试上取得了最优跟踪性能,同时在无需光流特定训练的情况下,在光流估计方面也表现出色。我们希望这些结果将鼓励人们重新审视密集对应关系架构,采用简单、以扭曲为中心的设计,以连接跟踪和光流领域。
对更多实验结果和文章细节感兴趣的读者,可以阅读一下论文原文~
本文仅做学术分享,如有侵权,请联系删文。
3D视觉方向论文辅导来啦!可辅导SCI期刊、CCF会议、本硕博毕设、核心期刊等。



添加微信:cv3d001,备注:姓名+方向+单位,邀请入群。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 1
1 0
0- 0



 已为社区贡献94条内容
已为社区贡献94条内容

所有评论(0)