图神经网络分享系列-GraphSage(Inductive Representation Learning on Large Graphs) (三)
目录
1.1 在动态演进图上的归纳学习:引文与Reddit数据实验
图神经网络概览:图神经网络分享系列-概览
上一篇文章:图神经网络分享系列-GraphSage(Inductive Representation Learning on Large Graphs) (二)
一、实验
实验设计
我们测试了GraphSAGE在三个基准任务上的性能:(i)使用Web of Science引文数据集对学术论文进行学科分类,(ii)将Reddit帖子归类到不同社区,(iii)跨不同生物蛋白质-蛋白质相互作用(PPI)图谱对蛋白质功能进行分类。4.1和4.2节总结了数据集信息,补充材料包含更多细节。所有实验中,预测均针对训练时未见的节点进行;对于PPI数据集,测试则基于完全未见过的图谱。
实验设置
为对比归纳式基准的实证结果,我们比较了四种基线方法:随机分类器、基于逻辑回归的特征分类器(忽略图谱结构)、代表因子分解方法的DeepWalk算法,以及原始特征与DeepWalk嵌入的拼接。同时评估了四种GraphSAGE变体(采用不同聚合函数,见3.3节)。由于GraphSAGE的“卷积”变体是Kipf等人半监督GCN的归纳扩展版本,故将其命名为GraphSAGE-GCN。测试包括基于方程(1)损失的无监督GraphSAGE变体,以及直接使用分类交叉熵损失训练的有监督变体。所有GraphSAGE变体均采用ReLU作为非线性激活函数,设K=2,邻域采样规模S1=25、S2=10(敏感性分析见4.4节)。
对于Reddit和引文数据集,DeepWalk采用Perozzi等人描述的“在线”训练方式,预测前通过SGD优化新测试节点的嵌入(详见附录)。多图谱场景下,DeepWalk无法应用,因不同独立图谱生成的嵌入空间可能存在任意旋转(附录??)。
实现细节
所有模型(除DeepWalk外)均基于TensorFlow实现,使用Adam优化器(DeepWalk采用普通梯度下降优化器效果更佳)。实验目标为:(i)验证GraphSAGE相对基线方法(原始特征和DeepWalk)的改进,(ii)系统比较不同GraphSAGE聚合架构。为公平对比,所有模型共享相同的迷你批次迭代器、损失函数及邻域采样器(如适用)。为防止不同聚合器变体间的超参数偶然性优化,所有GraphSAGE变体采用相同的超参数搜索空间(根据验证集性能选择最佳配置)。超参数范围通过早期引文和Reddit子集的验证测试确定,后续分析中排除这些子集。附录提供更多实现细节。
1.1 在动态演进图上的归纳学习:引文与Reddit数据实验
前两项实验聚焦于动态信息图中节点的分类任务,该任务对高吞吐量生产系统具有特殊意义,这类系统会持续遇到未见过的数据。
实验一:引文数据
任务目标是通过大型引文数据集预测论文的主题类别。采用的数据集来自Thomson Reuters Web of Science核心合集,包含2000-2005年间六个生物学领域的论文,构建为无向引文图。节点标签对应六个不同领域,共302,424个节点,平均度为9.15。训练数据为2000-2004年的论文,2005年数据用于测试(其中30%用于验证)。特征工程包括节点度数和论文摘要处理:摘要通过Arora等人提出的句子嵌入方法转化为300维向量,词向量使用GenSim的word2vec实现训练。
实验二:Reddit数据
任务目标是预测Reddit帖子所属的社区(即“子版块”)。数据来自2014年9月的Reddit帖子,选取了50个大型社区构建帖子关系图:若同一用户对两个帖子均发表评论,则连接这两个帖子节点。数据集包含232,965个帖子,平均度为492。前20天的数据用于训练,剩余天数用于测试(30%验证集)。特征包括:
- 帖子标题的词向量均值(300维GloVe CommonCrawl预训练向量)
- 帖子所有评论的词向量均值
- 帖子得分(score)
- 帖子的评论数量
上述特征被拼接为最终输入。
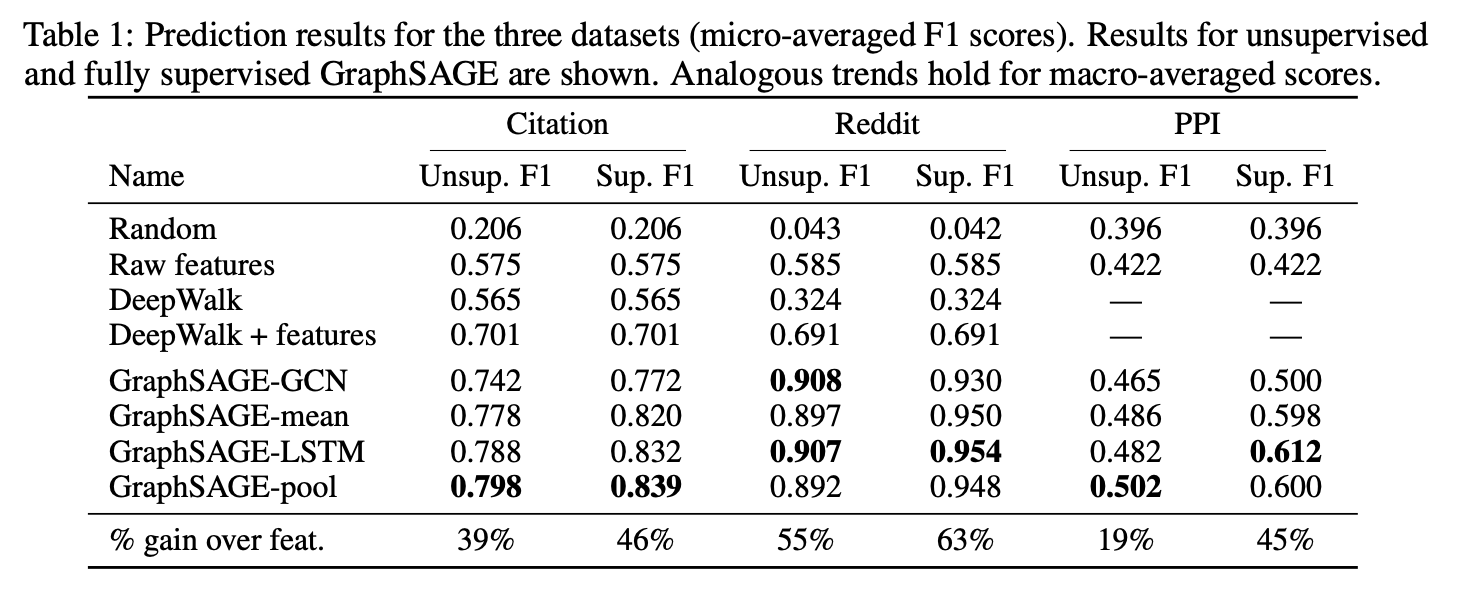
表1前四列性能对比分析
GraphSAGE及基线方法在两个数据集上的表现总结如下:GraphSAGE显著优于所有基线方法,且可训练的神经网络聚合器相比GCN方法带来明显提升。
无监督版本GraphSAGE-pool在引文数据上比DeepWalk嵌入与原始特征拼接的结果高13.8%,在Reddit数据上高29.1%;监督版本则分别提升19.7%与37.2%。值得注意的是,基于LSTM的聚合器虽专为序列数据设计,但在此无序集合任务中仍表现优异。
无监督GraphSAGE与全监督版本的性能差距较小,表明该框架无需任务特定微调即可实现强劲表现。
1.2 跨图泛化:蛋白质-蛋白质相互作用
本节探讨跨图泛化任务,其核心在于学习节点角色而非社区结构。通过人类不同组织对应的蛋白质-相互作用(PPI)图,对蛋白质角色(基于基因本体的细胞功能)进行分类。特征采用位置基因集、 motif 基因集和免疫特征,标签来自基因本体集(共121类),数据源自分子特征数据库[34]。平均每张图包含2373个节点,平均度为28.8。所有算法在20张图上训练,随后在两张测试图(另两张用于验证)上计算平均预测F1分数。
表1最后两列总结了各方法在此数据上的准确率。结果显示,GraphSAGE显著优于基线方法,其中基于LSTM和池化的聚合器比基于均值与GCN的聚合器有显著提升。
值得注意的是,在近期后续研究中,Chen和Zhu[6]通过针对PPI任务专门优化GraphSAGE的超参数,并采用新的训练技术(如Dropout、层归一化和新的采样方案),实现了更优的性能。建议读者参考他们的工作,了解基于GraphSAGE方法变体在PPI数据集上当前最先进的性能指标。
1.3 运行时间与参数敏感性分析
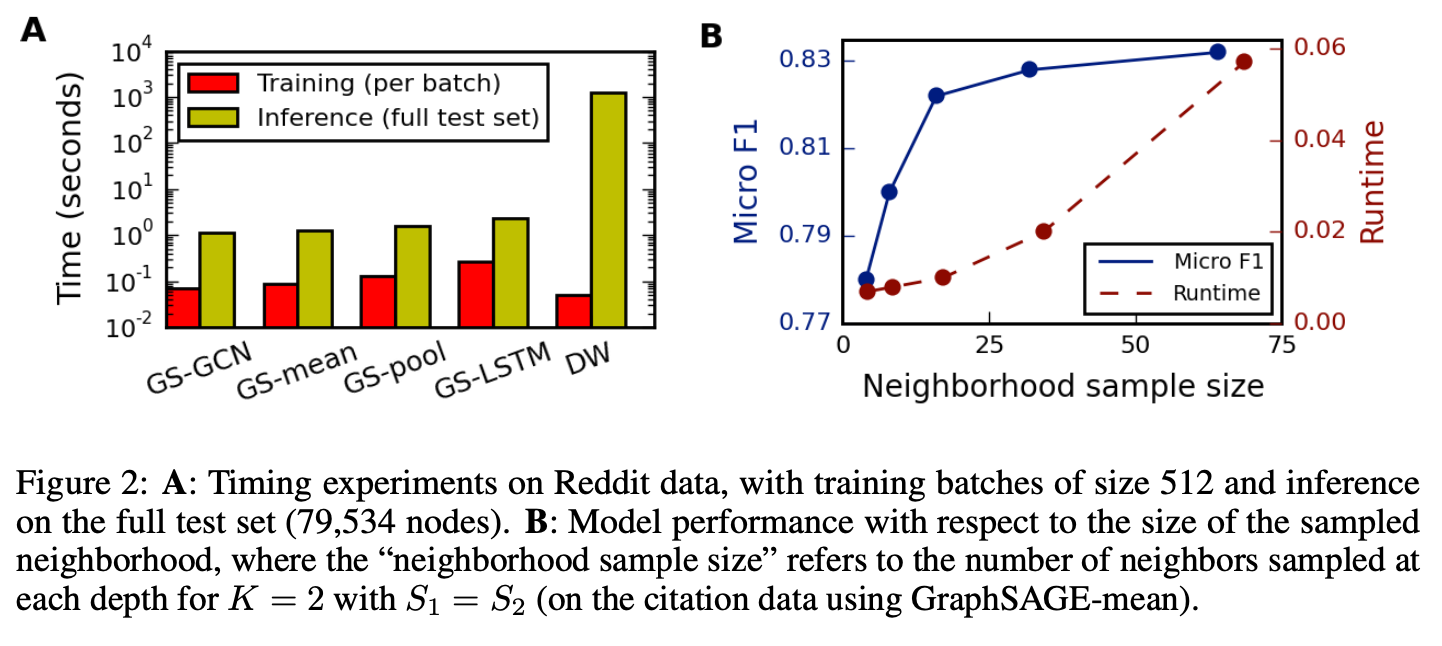
图2.A汇总了不同方法的训练和测试运行时间。各方法的训练时间较为接近(其中GraphSAGE-LSTM最慢)。然而,由于需要在测试时对未见的节点重新采样随机游走并运行新一轮SGD嵌入,DeepWalk的测试速度比GraphSAGE慢100-500倍。
对于GraphSAGE的变体,实验发现设置跳数K=2相比K=1能稳定提升约10-15%的准确率;但将K增加到超过2时,性能提升有限(0-5%),而运行时间会急剧增加10-100倍(具体倍数取决于邻域采样规模)。研究还表明,扩大邻域采样规模带来的收益逐渐递减(图2.B)。因此,尽管子采样邻域会引入更高方差,GraphSAGE仍能保持较强的预测准确性,同时显著提升运行效率。
1.4 不同聚合器架构的综合比较
总体而言,LSTM和基于池化的聚合器表现最佳,无论是平均性能还是在多数实验设置中作为最优方法的次数(表1)。为了量化这些趋势,将六种实验设置(即3个数据集×无监督与有监督)视为独立试验,分析可能泛化的性能规律。
采用非参数Wilcoxon符号秩检验量化不同聚合器在试验中的差异,并报告T统计量和p值(若适用)。该方法基于排名,核心是检验新实验设置中某方法是否可能优于另一方法。由于样本量较小(仅6种设置),显著性检验的统计效力有限,但T统计量和p值仍可作为评估聚合器相对性能的定量指标。
LSTM、池化和均值聚合器均显著优于基于GCN的方法(三者T=1.0,p=0.02)。但LSTM和池化方法相对于均值聚合器的优势较微弱(LSTM对比均值:T=1.5,p=0.03;池化对比均值:T=4.5,p=0.10)。LSTM与池化方法间无显著差异(T=10.0,p=0.46)。然而,GraphSAGE-LSTM的运行速度显著慢于GraphSAGE-pool(约2倍),这可能使池化聚合器在整体上略占优势。
二、理论分析
本节探讨GraphSAGE的表达能力,旨在揭示其如何通过特征学习图结构信息。以预测节点聚类系数为例展开研究,该系数表示节点一阶邻域内闭合三角形所占比例[38]。聚类系数是衡量节点局部邻域聚类程度的重要指标,也是构建更复杂结构模式的基础[3]。
研究表明,算法1能够以任意精度逼近聚类系数:
定理1的翻译
设(∀v ∈ V)表示图G = (V,E)上算法1的特征输入,其中U是
的任意紧致子集。假设存在一个固定的正常数C ∈ R+,使得对于所有节点对,满足
。那么对于任意ε > 0,存在算法1的一组参数Θ∗,使得在K = 4次迭代后满足以下结论。
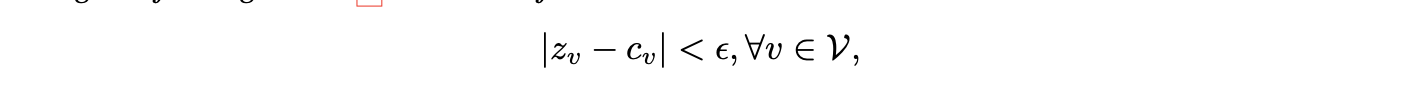
表示由算法1生成的最终输出值,
表示节点聚类系数。
关键术语解析
:z_v 属于实数集,代表算法输出的数值结果。
:节点聚类系数(clustering coefficient),衡量网络中节点邻居间的连接紧密程度。
关键术语说明
- 紧致子集:指在欧几里得空间中闭且有界的集合。
- ∥xv − xv′∥2 > C:表示任意两节点特征向量的欧几里得距离严格大于常数C。
- 参数设置Θ∗:指算法1中可调整的权重或超参数集合。
定理1指出,对于任意图结构,若每个节点的特征均唯一(且模型维度足够高),则存在一种参数设置使得算法1能以任意精度逼近该图中的聚类系数。完整证明见附录。
作为定理1的推论,即使节点特征输入采样自绝对连续的随机分布,GraphSAGE仍能学习局部图结构(详见附录)。证明的核心思想是:若每个节点具有唯一的特征表示,则可通过将节点映射至指示向量来识别邻域关系。
该定理的证明依赖于池化聚合器的某些特性,这亦解释了为何GraphSAGE-pool的性能优于GCN和均值聚合器。
关键术语说明
- 聚类系数:衡量节点邻域连接紧密程度的指标
- 绝对连续分布:概率密度函数处处连续的随机分布
- 指示向量:仅一个元素为1、其余为0的稀疏向量
- 池化聚合器:通过非线性变换聚合邻域信息的机制
补充说明
该定理表明,在节点特征差异足够大(距离下界为C)的条件下,算法1仅需有限次迭代(K=4)即可逼近目标精度ε。
三、结论
我们提出了一种新颖的方法,能够高效地为未见过的节点生成嵌入表示。GraphSAGE 在性能上始终优于最先进的基线模型,通过采样节点邻域实现了性能与运行时间的有效平衡,理论分析进一步揭示了该方法如何学习局部图结构。未来存在多种扩展和改进的可能性,例如将 GraphSAGE 扩展到处理有向图或多模态图。一个特别值得探索的方向是研究非均匀邻域采样函数,甚至可能将其作为 GraphSAGE 优化过程的一部分进行学习。
关于GraphSage的实验部分就分享到这里,后续会针对附录进行分享:
图神经网络分享系列-GraphSage(Inductive Representation Learning on Large Graphs) (四)
GraphSage 的代码和相关数据集可通过以下链接获取:
http://snap.stanford.edu/graphsage/

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 16
16 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)