HuggingFace项目实战之填空任务实战
大模型在填空任务中的应用主要涉及自动补全、内容生成和知识推理等场景,其核心能力在于基于上下文预测缺失信息。
·
一、使用场景
大模型在填空任务中的应用主要涉及自动补全、内容生成和知识推理等场景,其核心能力在于基于上下文预测缺失信息。
二、代码分析
import torch
from transformers import AutoTokenizer
#加载tokenizer
tokenizer = AutoTokenizer.from_pretrained('google-bert/bert-base-chinese')
tokenizer

from datasets import load_dataset
#加载数据集
dataset = load_dataset(path='lansinuote/ChnSentiCorp')
#编码
f = lambda x: tokenizer(
x['text'], truncation=True, max_length=30, return_token_type_ids=False)
dataset = dataset.map(f, remove_columns=['text', 'label'])
#过滤句子长度
f = lambda x: len(x['input_ids']) >= 30
dataset = dataset.filter(f)
#重置label字段
def f(data):
#定义第15个字为label
data['label'] = data['input_ids'][15]
#替换句子中的第15个字为mask
data['input_ids'][15] = tokenizer.mask_token_id
return data
dataset = dataset.map(f)
#设置数据类型
dataset.set_format('pt')
dataset, dataset['train'][0]
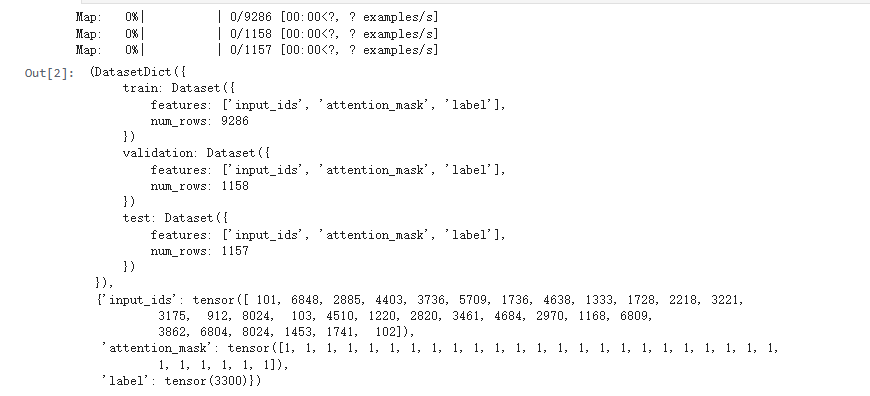
loader = torch.utils.data.DataLoader(dataset['train'],
batch_size=8,
shuffle=True,
drop_last=True)
data = next(iter(loader))
for k, v in data.items():
print(k, v.shape)
len(loader)

#查看数据样例
for q, a in zip(data['input_ids'], data['label']):
print(tokenizer.decode(q))
print(tokenizer.decode(a))
print('==============')

#定义模型
class Model(torch.nn.Module):
def __init__(self):
super().__init__()
#加载预训练模型
from transformers import AutoModel
self.pretrained = AutoModel.from_pretrained(
'google-bert/bert-base-chinese')
self.fc = torch.nn.Linear(in_features=768,
out_features=tokenizer.vocab_size)
def forward(self, input_ids, attention_mask, label=None):
#使用预训练模型抽取数据特征
with torch.no_grad():
last_hidden_state = self.pretrained(
input_ids=input_ids,
attention_mask=attention_mask).last_hidden_state
#取第15个词的特征向量
last_hidden_state = last_hidden_state[:, 15]
#对抽取的特征只取第一个字的结果做分类即可
out = self.fc(last_hidden_state).softmax(dim=1)
#计算loss
loss = None
if label is not None:
loss = torch.nn.functional.cross_entropy(out, label)
return loss, out
model = Model()
model(**data)

#执行训练
def train():
optimizer = torch.optim.Adam(model.parameters(), lr=1e-4)
#知识扩展:
#iteration:1个iteration等于使用batchsize个样本训练一次;
#epoch:1个epoch等于使用训练集中的全部样本训练一次,通俗的讲epoch的值就是整个数据集被轮几次。
for epoch in range(5):
#内层循环遍历数据加载器(loader)中的所有批次(batch)
#i: 当前批次的索引
#data: 包含输入数据和标签的字典
for i, data in enumerate(loader):
#将数据输入模型进行前向传播
#**data: 解包数据字典作为模型参数
#out: 模型输出(预测结果)
#loss: 计算得到的损失值
loss, out = model(**data)
#loss.backward(): 计算梯度(反向传播)
#optimizer.step(): 根据梯度更新模型参数
#optimizer.zero_grad(): 清空梯度,防止梯度累积
loss.backward()
optimizer.step()
optimizer.zero_grad()
if i % 200 == 0:
#知识扩展:
#核心功能: torch.argmax(dim=1) 函数返回输入张量在指定维度 dim=1 上最大值的索引。
#参考示例1
out = out.argmax(dim=1)
acc = (out == data['label']).sum().item() / len(data['label'])
#打印的内容详情:
#当前epoch
#当前batch索引
#总batch数量
#当前loss值
#当前准确率
print(epoch, i, len(loader), loss.item(), acc)
train()

1、参考示例1

#执行测试
def test():
loader_test = torch.utils.data.DataLoader(dataset['test'],
batch_size=8,
shuffle=True,
drop_last=True)
correct = 0
total = 0
for i, data in enumerate(loader_test):
with torch.no_grad():
_, out = model(**data)
out = out.argmax(dim=1)
correct += (out == data['label']).sum().item()
total += len(data['label'])
print(i, len(loader_test), correct / total)
if i == 5:
break
return correct / total
test()


腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 9
9 0
0- 0



 已为社区贡献21条内容
已为社区贡献21条内容

所有评论(0)