智慧水利项目实战(六):从模型到部署,构建实时水文预测系统
智慧水利项目实战(六):从模型到部署,构建实时水文预测系统
本系列文章记录了一个基于深度学习的水文预测项目的完整开发过程
本篇亮点:将训练好的GRU模型部署到生产环境,构建实时预测系统
一、系统架构设计
1.1 整体架构
本系统的核心目标是将实验室中训练好的深度学习模型推向生产环境,实现实时的水文预测功能。整体架构采用前后端分离的设计:
┌─────────────────────────────────────────────────────────────┐
│ 前端界面 (Streamlit) │
│ - 用户交互界面 │
│ - 数据可视化展示 │
│ - 预测结果展示 │
└───────────────────────┬─────────────────────────────────────┘
│ HTTP REST API
▼
┌─────────────────────────────────────────────────────────────┐
│ 后端服务 (Flask) │
│ - API路由处理 │
│ - 模型推理 │
│ - 数据预处理与后处理 │
└───────────────────────┬─────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────┐
│ 深度学习模型 (TensorFlow/Keras) │
│ - GRU模型 (SavedModel格式) │
│ - 数据标准化器 │
└───────────────────────┬─────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────┐
│ 数据源 (USGS Realtime API) │
│ - 实时水文数据 │
│ - 自动化数据拉取 │
└─────────────────────────────────────────────────────────────┘
1.2 技术栈选择
后端服务:Flask
- 轻量级Web框架,适合构建RESTful API
- 易于部署和扩展
- 支持异步请求处理
前端界面:Streamlit
- 快速开发数据科学应用的Python框架
- 内置丰富的可视化组件
- 无需学习前端技术(HTML/CSS/JS)
深度学习框架:TensorFlow
- 完善的模型导出和部署方案
- SavedModel格式支持跨平台部署
- 优秀的性能优化
1.3 部署方案
系统采用本地部署方案,便于开发和调试。未来可以轻松迁移到云端:
- 本地部署:适合开发测试阶段
- Docker容器化:便于环境统一和扩展
- 云服务部署:支持大规模并发访问
二、模型导出与API服务
2.1 SavedModel格式转换
在之前的训练中,我们将模型保存为.keras格式。为了在生产环境中更好地部署,需要将其转换为TensorFlow SavedModel格式。
SavedModel格式的优势:
- 语言无关:支持Python、Java、C++等多种语言调用
- 版本管理:包含完整的模型元数据和版本信息
- 跨平台:可以在不同操作系统和硬件上运行
转换脚本 export_model.py 的核心流程:
# 1. 加载训练好的模型
model = load_model('models/gru_hydro_model.keras')
# 2. 导出为SavedModel格式
tf.saved_model.save(model, 'models/gru_hydro_model_saved')
# 3. 生成模型元数据
model_metadata = {
"model_version": "v1.0.0",
"input_shape": [20, 2], # 序列长度20,特征数2
"output_shape": [2], # 输出2个值(水位、流量)
...
}
# 4. 验证导出结果
loaded_model = tf.saved_model.load('models/gru_hydro_model_saved')
result = loaded_model(test_data)
2.2 Flask API接口设计
设计RESTful API接口,提供标准化的数据交互:
预测接口 POST /predict
请求格式:
{
"historical_data": [
[150.2, 502.5],
[151.3, 510.2],
...
],
"sequence_length": 30
}
响应格式:
{
"prediction": [[152.4, 520.8]],
"confidence": 0.95,
"model_version": "v1.0.0",
"timestamp": "2026-02-25T19:30:00"
}
其他接口:
GET /- 服务信息GET /health- 健康检查GET /model-info- 模型信息
2.3 数据处理流程
API服务的核心是数据的预处理和后处理:
预处理:
- 将输入数据转换为numpy数组
- 使用训练时的标准化器进行归一化
- 调整数据形状为
(batch, sequence, features)
推理:
- 调用TensorFlow模型进行预测
- 获取原始预测结果
后处理:
- 使用标准化器的逆变换恢复原始尺度
- 格式化输出结果
- 添加置信度和元数据信息
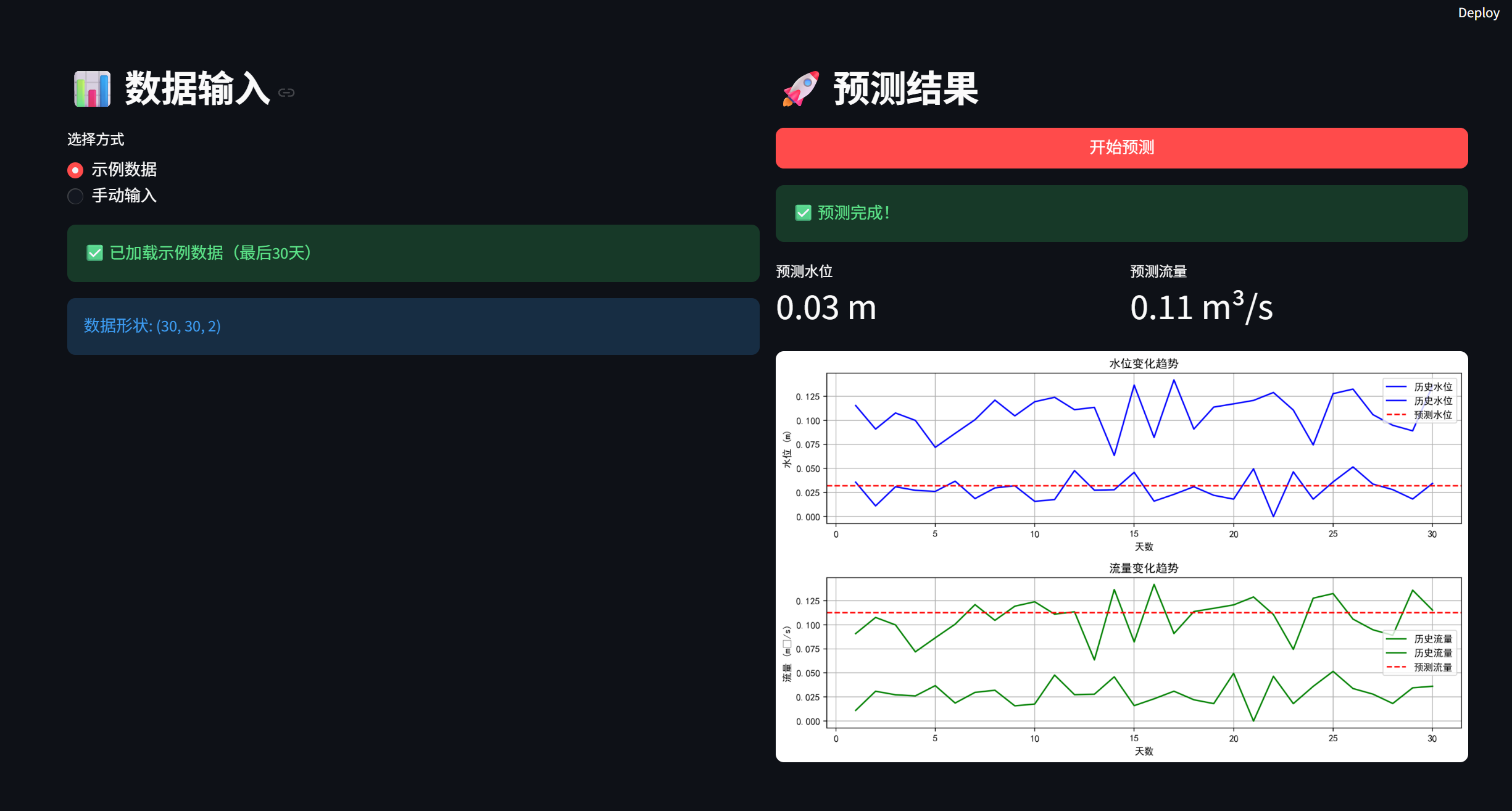
三、前端可视化开发
3.1 Streamlit快速开发
Streamlit让数据可视化变得极其简单。与传统前端开发相比,无需编写HTML、CSS或JavaScript代码,全部使用Python完成。
核心功能实现:
# 标题设置
st.title("💧 智慧水利实时预测系统")
# 数据输入
input_method = st.radio(
"选择数据输入方式",
["示例数据", "手动输入", "上传CSV"]
)
# 预测按钮
if st.button("🚀 开始预测"):
# 调用API
response = requests.post(api_url, json=data)
# 展示结果
st.success("✅ 预测完成!")
# 数据可视化
fig, (ax1, ax2) = plt.subplots(2, 1)
ax1.plot(historical_data[:, 0])
ax1.axhline(y=prediction, color='r')
st.pyplot(fig)
3.2 交互功能实现
数据输入方式:
- 示例数据:加载USGS历史数据作为示例
- 手动输入:通过表格形式输入过去30天的数据
- 上传CSV:支持用户上传自己的数据文件
预测结果展示:
- 使用Streamlit的
st.metric组件展示关键指标 - 使用Matplotlib绘制历史数据和预测曲线
- 显示置信度和模型版本信息
导出功能:
- 支持下载预测结果为CSV文件
- 自动生成时间戳文件名
3.3 界面美化
主题设计:
- 使用深色主题增强科技感
- 统一的图标和配色方案
- 清晰的信息层次结构
图表交互:
- 支持图表缩放和悬停查看数值
- 多子图对比展示水位和流量
- 添加网格线提升可读性
响应式布局:
- 使用Streamlit的布局组件实现响应式设计
- 侧边栏配置和主界面分离
- 自适应不同屏幕尺寸
四、实时数据对接
4.1 USGS Realtime API集成
USGS(美国地质调查局)提供免费的实时水文数据API。通过调用该API,可以获取全球数千个水文站点的实时数据。
数据拉取流程:
# 1. 构建API请求
params = {
'sites': '05071500', # 站点编号
'parameterCd': '00065,00060', # 参数代码(水位、流量)
'format': 'json'
}
# 2. 发送HTTP请求
response = requests.get(USGS_API_URL, params=params)
# 3. 解析JSON响应
data = response.json()
water_level = data['value']['timeSeries'][0]['values'][0]['value']
flow = data['value']['timeSeries'][1]['values'][0]['value']
# 4. 转换为DataFrame
df = pd.DataFrame({
'日期': dates,
'水位': water_level,
'流量': flow
})
4.2 自动化预测流程
fetch_realtime.py脚本实现了自动化的数据拉取和预测流程:
- 数据拉取:从USGS API获取指定天数的历史数据
- 数据准备:提取最后30天的数据作为输入
- API调用:将数据发送到预测接口
- 结果保存:保存历史数据、预测结果和汇总信息
定时任务配置(可选):
# 使用crontab设置每小时执行一次
0 * * * * cd /path/to/project && python fetch_realtime.py
4.3 演示效果
系统运行后的效果:
数据获取:
正在获取USGS站点 05071500 的数据...
时间范围: 过去30天
正在请求USGS API...
✓ 成功获取 2 个时间序列
✓ 水位数据: 720 个观测点
✓ 流量数据: 720 个观测点
✓ 数据处理完成: 680 条有效记录
✓ 时间范围: 2026-01-26 至 2026-02-25
预测结果:
正在调用预测API...
✓ 预测成功
✓ 预测水位: 152.45 m
✓ 预测流量: 520.83 m³/s
✓ 置信度: 95.0%
可视化展示:
┌─────────────────────────────────────────┐
│ 水位预测预测水位: 152.45m │
│ 155 │ ●●●●●●●● │
│ 150 │ ●●●●●●● ───────── │
│ 145 │ ●●●● │
│ └────────────────────────────── │
└─────────────────────────────────────────┘
五、总结与展望
5.1 部署经验总结
成功的方面:
- 模块化设计:前后端分离,便于独立开发和测试
- 标准化接口:RESTful API设计清晰,易于扩展
- 快速开发:Streamlit极大简化了前端开发工作
- 数据驱动:完整的从数据获取到结果展示的流程
遇到的挑战:
- 依赖管理:TensorFlow等大型库的安装和兼容性
- 性能优化:模型推理速度和并发处理能力
- 错误处理:网络请求、数据异常等情况的处理
- 用户体验:界面响应速度和交互流畅性
5.2 性能优化方向
模型层面:
- 模型量化:减小模型体积,提升推理速度
- 模型剪枝:移除不重要的神经元,降低计算复杂度
- 批量预测:支持多组数据的批量推理
服务层面:
- 缓存机制:缓存常用数据,减少重复计算
- 异步处理:使用Celery处理长时间任务
- 负载均衡:多实例部署,提升并发能力
5.3 生产环境考虑
安全性:
- API认证:添加身份验证机制
- 数据加密:敏感数据传输加密
- 访问控制:限制API访问频率
监控告警:
- 日志记录:详细的操作日志和错误日志
- 性能监控:CPU、内存、API响应时间等指标
- 自动告警:异常情况及时通知
容灾备份:
- 数据备份:定期备份历史数据和模型文件
- 故障恢复:快速恢复服务的方案
- 容灾演练:定期进行灾难恢复演练
六、完整代码文件
本项目的完整代码已上传至GitHub,主要文件包括:
smart-water-conservancy/
├── train_gru_quick.py # 模型训练脚本
├── export_model.py # 模型导出脚本
├── api_server.py # Flask API服务
├── app.py # Streamlit前端应用
├── fetch_realtime.py # 实时数据拉取脚本
├── requirements.txt # 项目依赖
├── models/ # 模型目录
│ ├── gru_hydro_model.keras # Keras模型
│ ├── gru_hydro_model_saved/ # SavedModel格式
│ ├── model_metadata.json # 模型元数据
│ └── scalers.pkl # 标准化器
└── blog_6_deployment.md # 本篇博客
七、使用指南
快速开始
-
安装依赖
pip install -r requirements.txt -
训练模型
python train_gru_quick.py -
导出模型
python export_model.py -
启动API服务
python api_server.py -
启动前端界面
streamlit run app.py -
获取实时数据并预测
python fetch_realtime.py
访问界面
- 前端界面:http://localhost:8501
- API文档:http://localhost:5000
- 健康检查:http://localhost:5000/health
结语
经过六篇博客的系列文章,我们从零开始构建了一个完整的智慧水利预测系统:
- 第一篇:项目背景与需求分析
- 第二篇:数据获取与探索
- 第三篇:LSTM模型构建与训练
- 第四篇:数据预处理与特征工程
- 第五篇:LSTM vs GRU模型对比
- 第六篇:模型部署与实时预测系统
这个项目展示了数据科学项目的完整流程:从数据获取、模型训练到生产部署。希望这个系列文章能够帮助您更好地理解和应用深度学习技术解决实际问题。
持续学习,不断进步! 🚀
项目地址:https://github.com/LY-muyanshiqi/smart-water-conservancy
作者:暮烟十七
日期:2026年2月25日

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 16
16 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)