TPAMI 2025 | SDNet-A 融合注意力与多尺度对比特征编码,实现轻量级显著目标检测精度突破
近期,Zhuo Su等学者提出的SDNet/STDNet模型,凭借像素差分卷积(PDC)和差分卷积重参数化(DCR)等核心创新,在参数量不足1M的前提下,实现了图像/视频显著目标检测的极致效率与精度平衡:在Jetson AGX Orin嵌入式设备上,图像检测速度达46 FPS,视频检测更是突破150 FPS,远超同类轻量模型,同时保持顶尖检测精度。此外,STDC还借鉴了LBP-TOP的设计思想,但
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达在物联网、嵌入式设备普及的当下,计算机视觉任务对模型的效率和精度提出了双重挑战——既要跑得快,又要认得准。显著目标检测(SOD)作为计算机视觉的基础任务,更是如此:它需要快速定位图像/视频中最具视觉辨识度的区域,却常因模型复杂、计算成本高,难以在资源受限的设备上落地。
近期,Zhuo Su等学者提出的SDNet/STDNet模型,凭借像素差分卷积(PDC)和差分卷积重参数化(DCR)等核心创新,在参数量不足1M的前提下,实现了图像/视频显著目标检测的极致效率与精度平衡:在Jetson AGX Orin嵌入式设备上,图像检测速度达46 FPS,视频检测更是突破150 FPS,远超同类轻量模型,同时保持顶尖检测精度。今天,我们就来拆解这篇聚焦实时显著目标检测的优质研究。
论文信息
题目: Rapid Salient Object Detection With Difference Convolutional Neural Networks
基于差分卷积神经网络的快速显著目标检测
作者: Zhuo Su, Li Liu, Matthias Müller, Jiehua Zhang, Diana Wofk, Ming-Ming Cheng, Matti Pietikäinen
一、痛点:现有SOD模型的效率与精度难以两全
显著目标检测模拟人类视觉系统,能快速定位图像/视频中最突出的区域,是自动驾驶、视频监控、移动端视觉应用等场景的核心基础。但现有方法存在两大痛点:
-
经典方法依赖手工设计特征,虽轻量但精度低,无法捕捉复杂场景的显著特征;
-
深度学习方法虽精度提升,但多依赖复杂架构或重型骨干网络,参数量大、推理慢,在嵌入式设备上难以实时运行。
即便部分轻量级SOD模型试图平衡效率与精度,也因结构设计缺陷(如特征表示能力不足、多分支计算冗余),最终陷入“精度高则速度慢,速度快则精度差”的困境(见图1)。
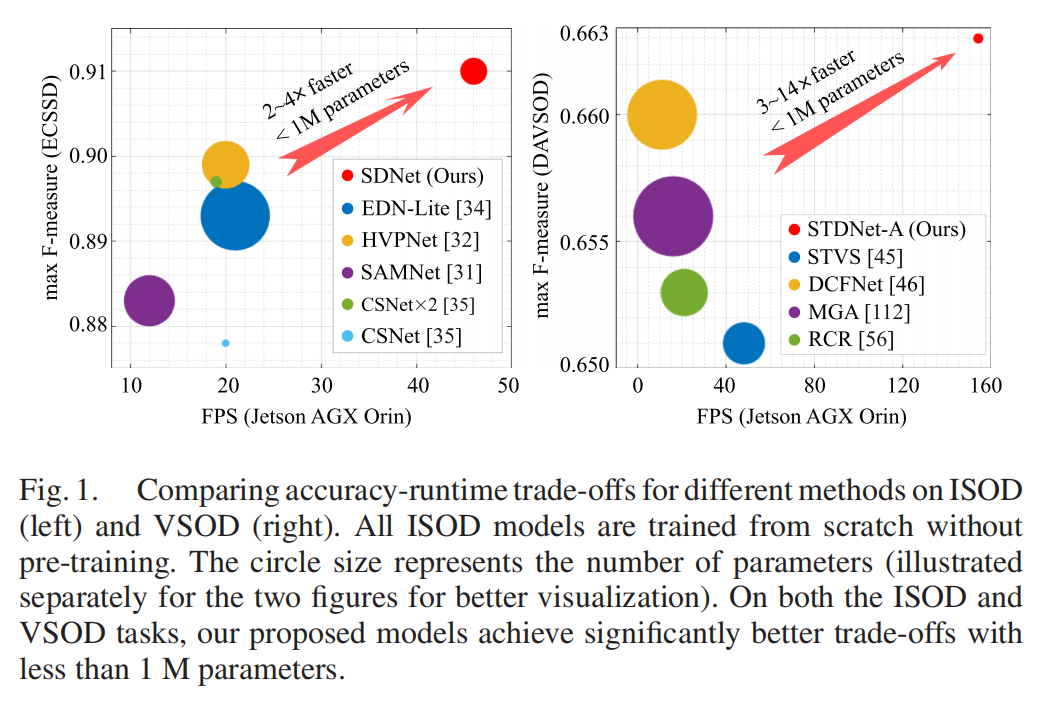 图1:现有轻量级SOD模型的效率-精度权衡普遍不理想
图1:现有轻量级SOD模型的效率-精度权衡普遍不理想
二、核心思路:把“对比线索”嵌进卷积,还能无损重参数化
针对上述问题,研究团队的核心思路是:借鉴经典SOD“中心-周边对比”的启发式思想,将“特征对比”直接编码到卷积操作中,同时通过重参数化消除推理阶段的计算冗余,实现“训练时多分支学特征,推理时单分支快运行”。
1. 整体架构:SDNet(图像)与STDNet(视频)
先来看模型的整体架构,这也是理解核心创新的基础:
-
SDNet(空间差分网络):针对图像显著目标检测,以PiDiNet为基础,在骨干层融合多种像素差分卷积(PDC)和标准卷积,通过自顶向下的特征细化流程生成全分辨率显著图(见图3、图4);
-
STDNet(时空差分网络):针对视频显著目标检测,在SDNet骨干基础上,新增时空差分模块(STDM),通过时空差分卷积(STDC)捕捉运动与外观的动态变化,最终实现时空特征的融合与细化(见图8)。
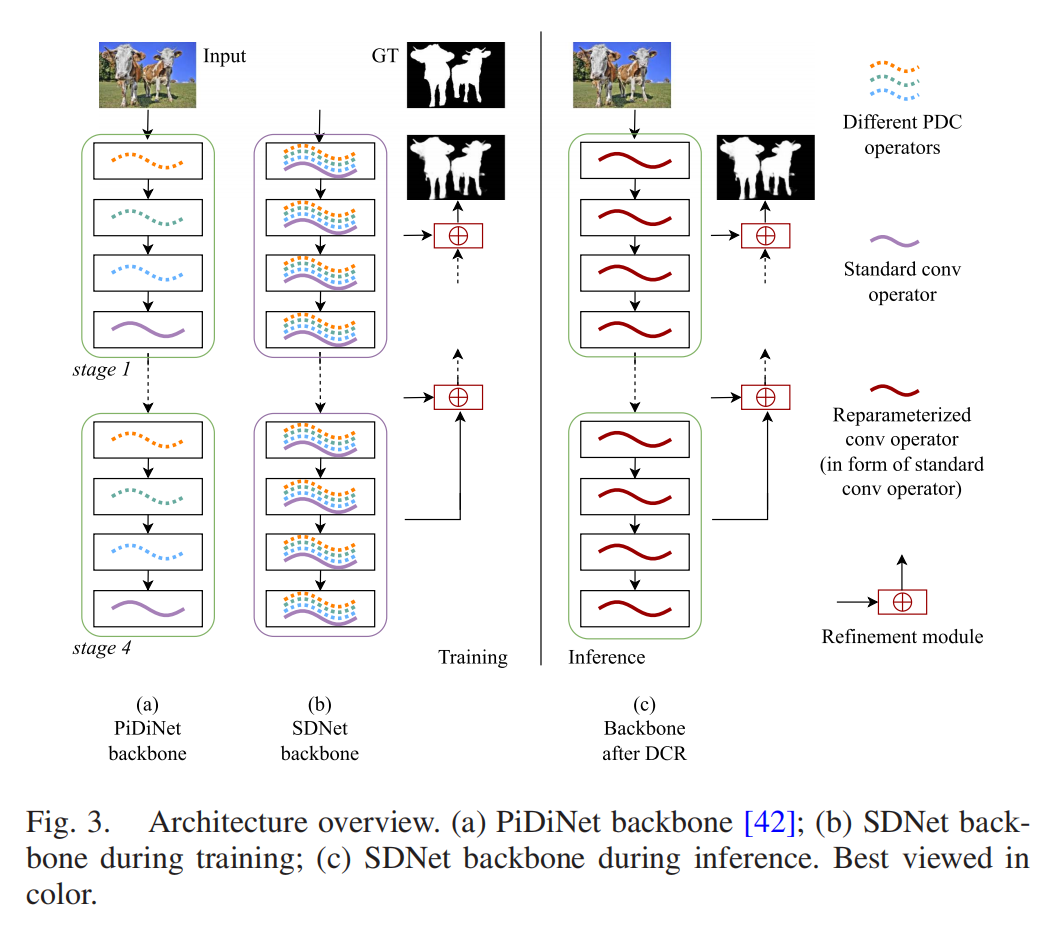 图3:SDNet骨干网络结构示意
图3:SDNet骨干网络结构示意
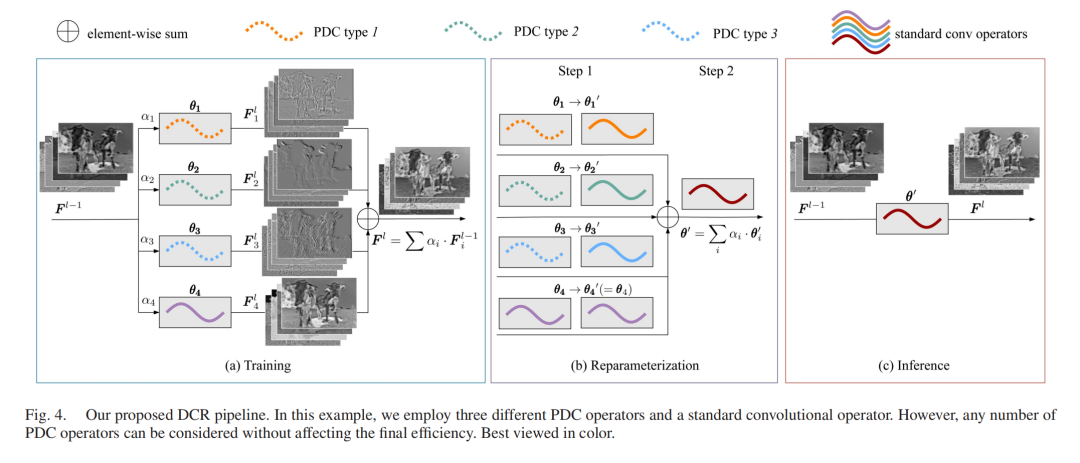 图4:SDNet特征细化与显著图生成流程
图4:SDNet特征细化与显著图生成流程
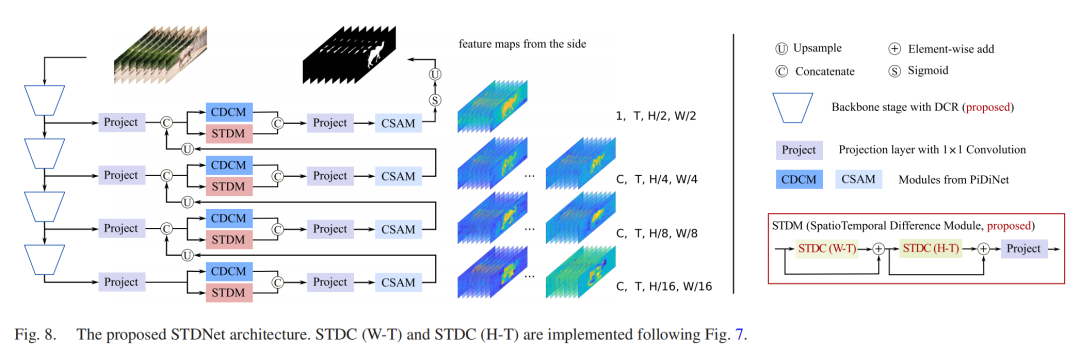 图8:STDNet整体架构(视频显著目标检测)
图8:STDNet整体架构(视频显著目标检测)
2. 像素差分卷积(PDC):让卷积直接学“对比特征”
传统卷积通过核权重与像素强度的内积计算输出,只能捕捉像素的“绝对强度”;而PDC则先计算局部区域内的像素差值,再与核权重做内积,直接编码“像素间的对比线索”——这正是显著目标检测的核心:显著区域往往因与周边像素的视觉差异(颜色、纹理、亮度)而突出。
研究团队设计了多种PDC变体:中心PDC、角度PDC、径向PDC,分别从中心-周边、角度、径向方向捕捉特征对比(见图2)。这些PDC算子能像高通滤波器一样,突出图像中的高频信号(如物体边界),而标准卷积则保留低频信号(如物体内部区域),两者结合让模型既能精准定位显著目标,又能完整保留目标轮廓。
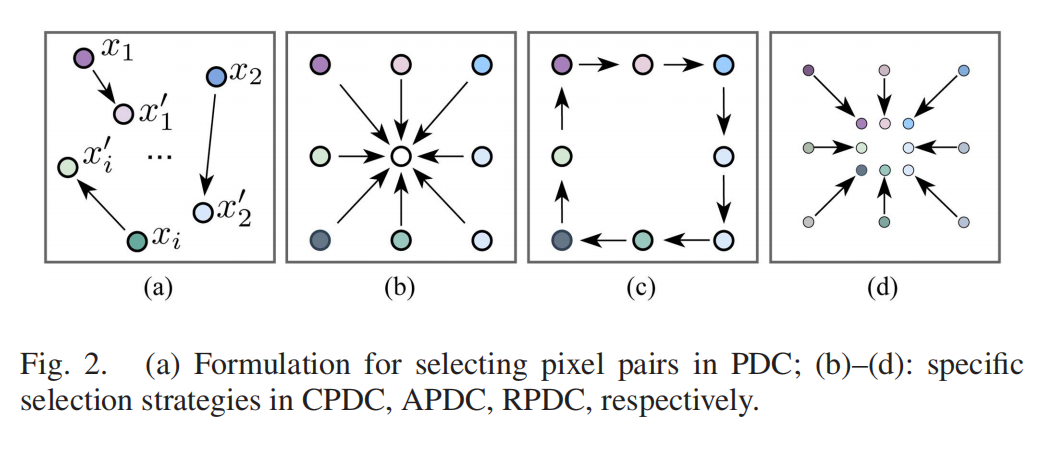 图2:不同类型像素差分卷积(PDC)的像素对选择策略
图2:不同类型像素差分卷积(PDC)的像素对选择策略
3. 差分卷积重参数化(DCR):训练多分支,推理单分支
PDC虽能提升精度,但多分支的PDC+标准卷积会增加推理时的计算开销。为此,研究团队提出DCR策略:
-
训练阶段:每层同时使用多种PDC和标准卷积分支,学习不同维度的对比特征与基础特征,通过加权求和融合分支输出;
-
推理阶段:将所有PDC分支转换为标准卷积,再融合所有分支的参数,最终每层仅保留一个标准卷积核。
这一操作让模型在训练时充分学习丰富的对比特征,推理时却无额外计算和参数开销——相当于“训练时多学多练,推理时轻装上阵”。从频域角度看,DCR让单个标准卷积既能保留低频特征,又能继承PDC突出高频特征的能力(见图5),这是单纯重参数化多个标准卷积无法实现的。
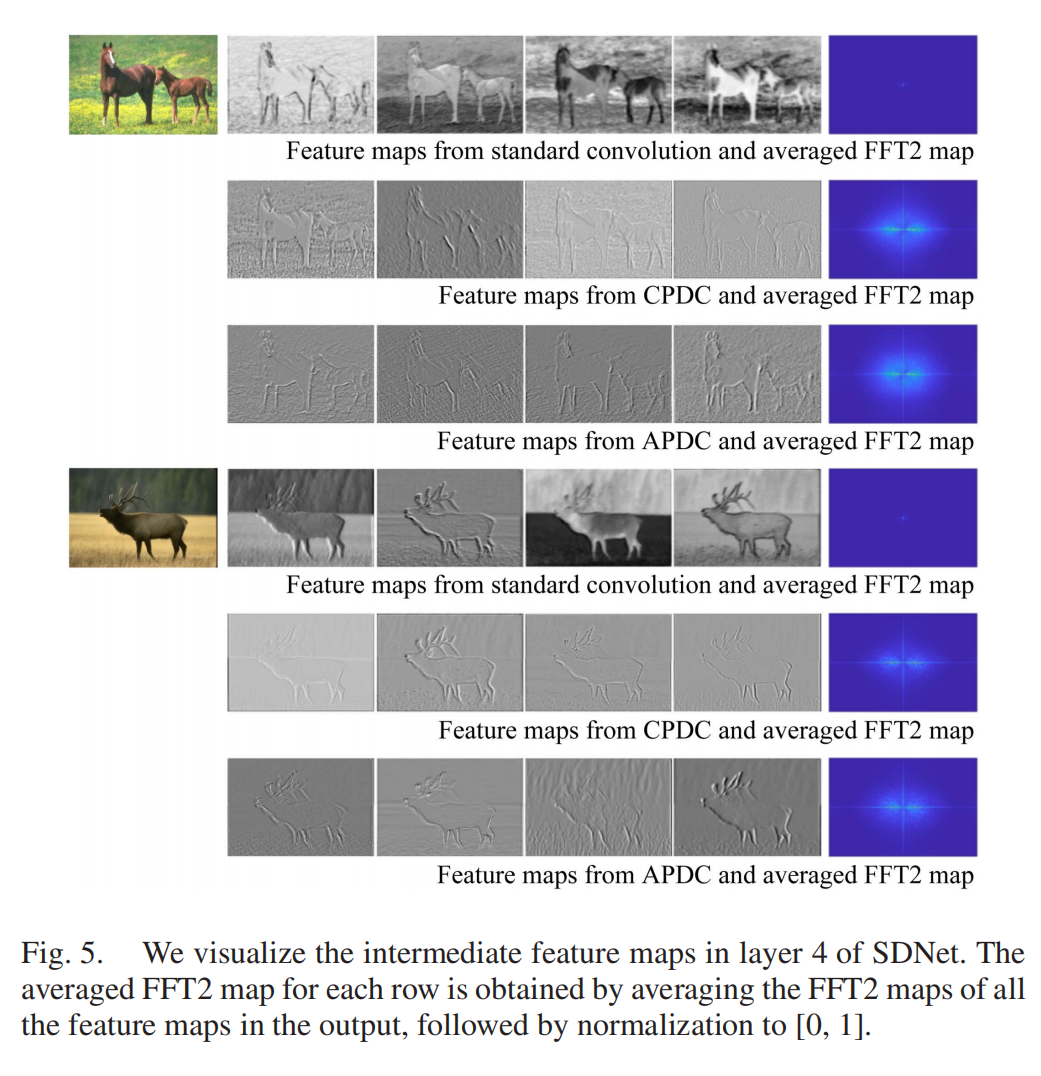 图5:PDC增强高频信号(FFT2结果),DCR保留这一优势
图5:PDC增强高频信号(FFT2结果),DCR保留这一优势
4. 时空差分卷积(STDC):把PDC扩展到视频领域
针对视频显著目标检测(VSOD),团队将PDC从空间域扩展到时空域,提出STDC:把3D时空体积切片为W-T(时间-宽度)和H-T(时间-高度)平面,在这些平面上部署类似PDC的卷积操作(见图6),捕捉视频帧间的运动对比与空间对比。
STDC保留了PDC“像素差值编码对比”的核心,同时兼容DCR策略——训练时用多分支STDC+标准卷积学习时空特征,推理时融合为单分支标准卷积,确保视频检测的实时性。此外,STDC还借鉴了LBP-TOP的设计思想,但相比传统LBP-TOP的固定规则,STDC的核权重可从数据中学习,能自适应捕捉视频中的动态显著特征(见图7)。
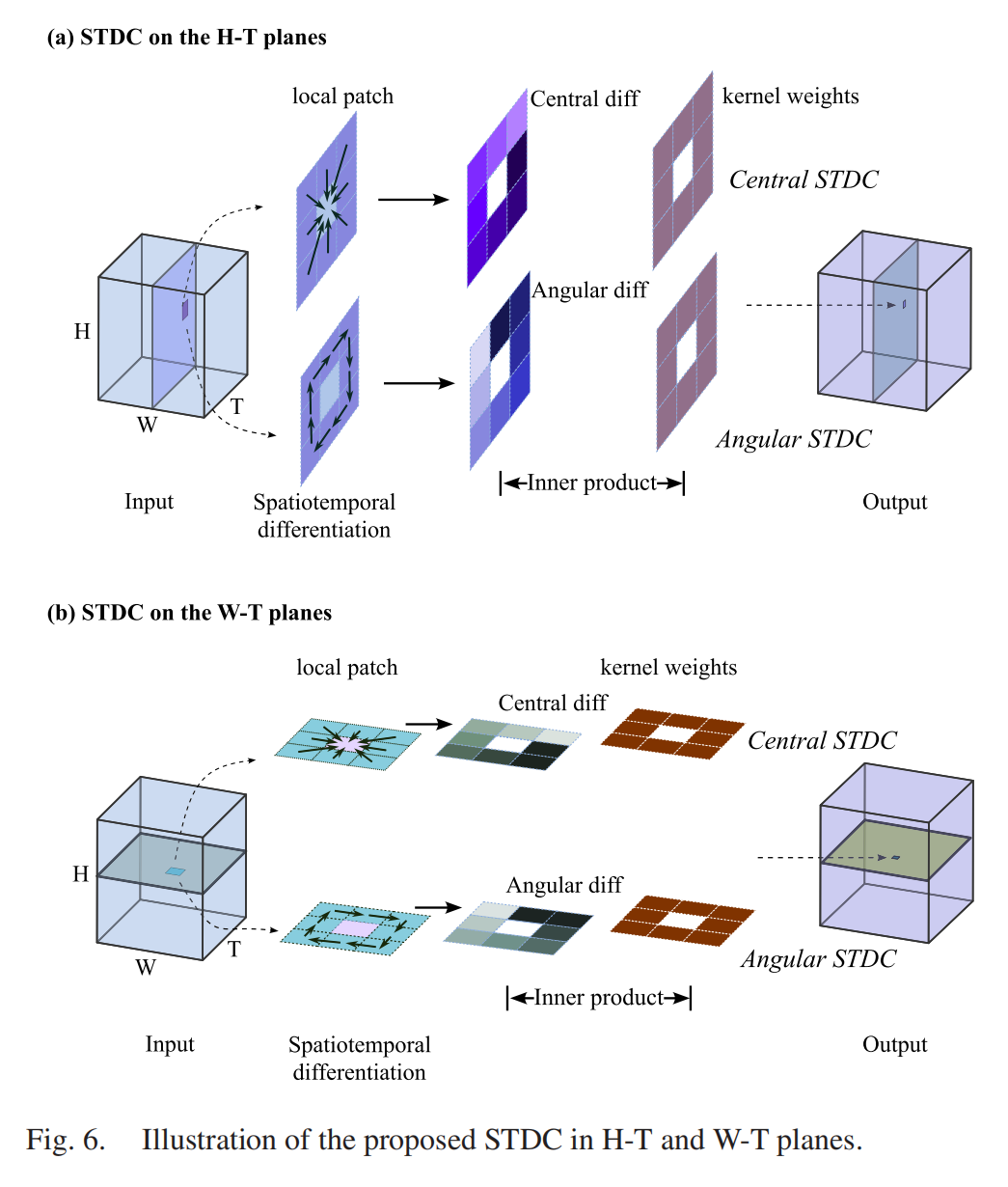 图6:时空差分卷积(STDC)的正交切片策略
图6:时空差分卷积(STDC)的正交切片策略
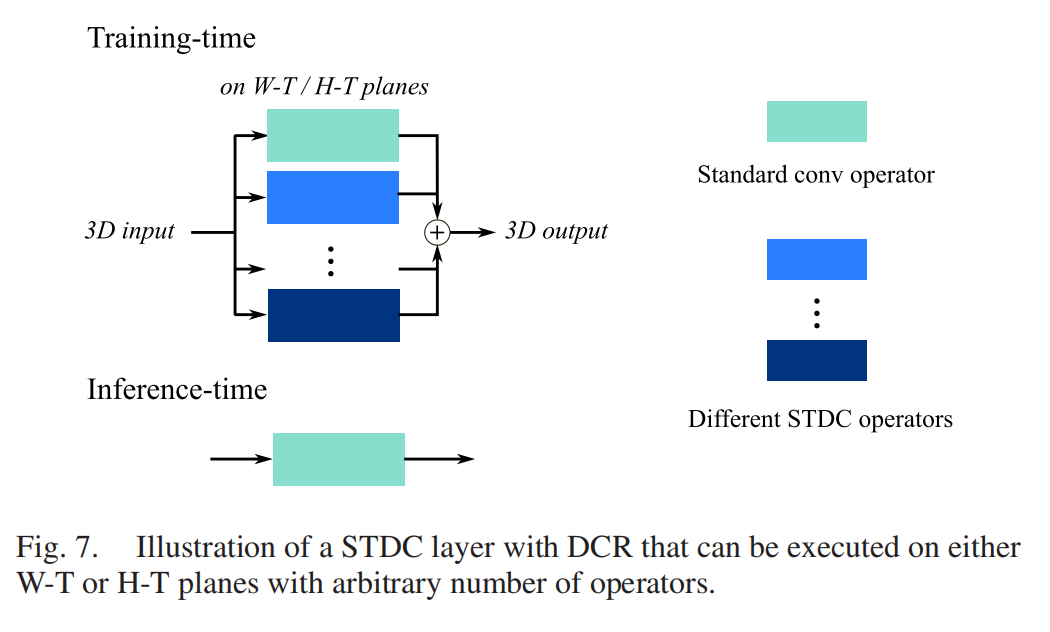 图7:H-T/W-T平面上的中心/角度STDC示意
图7:H-T/W-T平面上的中心/角度STDC示意
三、实验:参数不足1M,速度精度双碾压
研究团队在多个主流数据集(DUTS、ECSSD、DAVSOD等)和硬件平台(RTX 2080 Ti、Jetson AGX Orin、Jetson Xavier NX)上开展实验,验证了模型的性能:
1. 图像显著目标检测(ISOD)
SDNet参数量<1M,在RTX 2080 Ti上推理速度达252 FPS,Jetson AGX Orin上达46 FPS——比同类轻量模型快2~6倍;精度上,SDNet在ECSSD数据集上的最大F-measure达0.910,远超次优模型(0.899),且物体边界检测更清晰(见图9)。
即便引入MobileViTv2的轻量级注意力模块(SDNet-A),模型仍保持轻量性,在ImageNet预训练后精度进一步提升,成为“速度最快+精度顶尖”的轻量级ISOD模型(见表2、表3)。
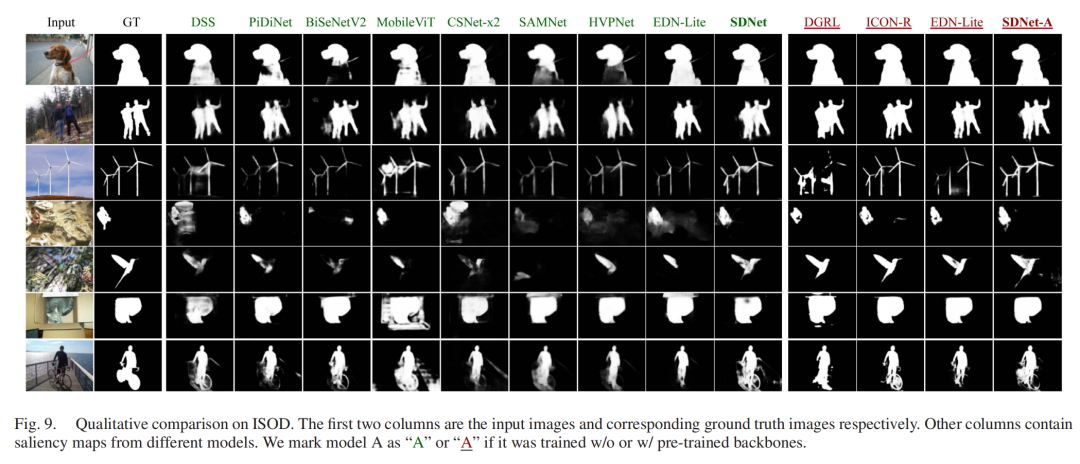 图9:SDNet与其他模型的定性对比(物体边界更清晰)
图9:SDNet与其他模型的定性对比(物体边界更清晰)
2. 视频显著目标检测(VSOD)
STDNet/STDNet-A参数量仍<1M,在RTX 2080 Ti上达482 FPS,Jetson AGX Orin上达150 FPS(比同类模型快3倍以上),即便在资源更受限的Jetson Xavier NX上,也能达到28 FPS的实时帧率。
精度上,STDNet-A在DAVSOD、VOS等数据集上的F-measure和MAE指标均优于现有轻量模型,且STDM模块有效增强了视频帧的时间一致性,避免显著目标在帧间“跳变”(见图12、图13)。
 图12:STDM增强视频帧时间一致性(右侧为STDNet结果)
图12:STDM增强视频帧时间一致性(右侧为STDNet结果)
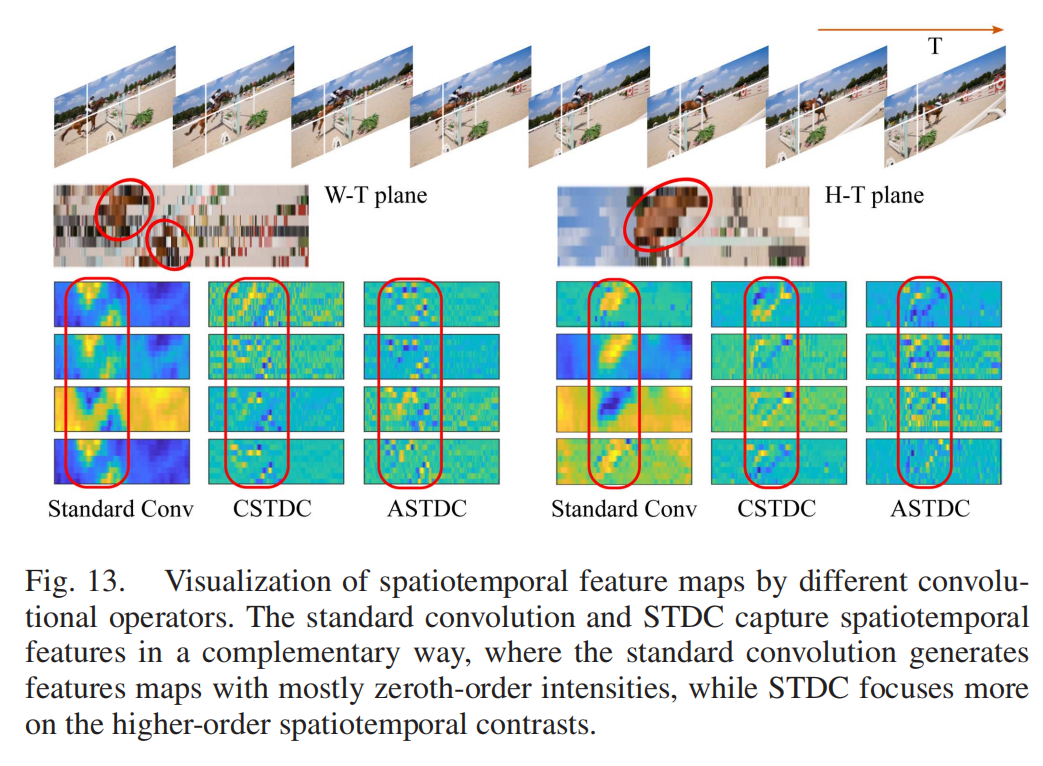 图13:STDC vs 标准卷积(STDC捕捉运动线索更精准)
图13:STDC vs 标准卷积(STDC捕捉运动线索更精准)
3. 消融实验:核心模块的有效性验证
团队还通过消融实验验证了各模块的价值:
-
DCR+PDC组合显著优于仅用标准卷积的基线模型,证明“对比特征编码”对SOD的必要性(见表6);
-
PDC分支的系数更大,说明模型需通过权重补偿像素差值的低幅值,同时依赖标准卷积的低频特征(见图11);
-
STDM模块是视频检测的核心,移除后精度大幅下降,证明时空对比线索的重要性(见表7)。
 图11:PDC与标准卷积分支的系数/输出值对比
图11:PDC与标准卷积分支的系数/输出值对比
四、总结:轻量级SOD的新范式
这篇研究的核心价值,在于为资源受限场景下的显著目标检测提供了全新范式:
-
把经典SOD的“对比思想”与现代CNN结合,用PDC/STDC直接编码对比特征,摆脱了“手工设计特征”和“重型网络堆精度”的困境;
-
DCR策略实现了“训练丰富性”与“推理高效性”的统一,为轻量级网络设计提供了新思路;
-
模型参数量<1M,却在嵌入式设备上实现实时帧率,且精度领先,真正落地“轻量、快速、高精度”的目标。
无论是图像还是视频显著目标检测,SDNet/STDNet都为物联网、嵌入式视觉应用提供了高性价比的解决方案,也为其他密集预测任务的轻量级设计提供了参考。
下载1:OpenCV-Contrib扩展模块中文版教程
在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。
下载2:Python视觉实战项目52讲
在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~



腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 16
16 0
0- 0



 已为社区贡献178条内容
已为社区贡献178条内容

所有评论(0)