缝缝补补---模型量化基础原理与Onnx实践
本章主要了解与学习量化的基础原理,并使用Onnx对yolov8进行动态与静态量化实践。
本章主要了解与学习量化的基础原理,并使用Onnx对yolov8进行动态与静态量化实践。
一、什么是量化
通过降低神经网络中权重和激活值的数值精度(从32位浮点数降为16位浮点、8位整数、4位整数或更低),实现模型压缩和推理加速。
二、量化方式分类(量化阶段分)
2.1 训练后量化(PTQ)
在模型训练完成后直接进行量化,无需重新训练。适用于快速部署,但可能引入精度损失。
包含动态量化与静态量化。主要区别在于激活值的缩放因子(scale)和零点(zero_point)是否在推理前固定。
典型方法:GPTQ、SmoothQuant、AWQ
2.2 感知量化训练(QAT)
在训练过程中模拟量化误差,使模型主动适应低精度表示。精度保持更好,可支持极低位宽(如 2-bit),但是需重新训练,计算成本高
典型方法:QLoRA、PEQA
三、训练后量化—动态量化
3.1 概念
不在推理前固定激活值的量化参数,而是在每次前向传播时实时计算其范围并动态生成 scale 和 zero_point,仅权重通常被静态量化。
3.2 特点
1、灵活性强:能适应输入长度或分布变化大的场景(如 NLP 中变长序列)
2、实现简单:无需额外校准步骤,也不依赖校准数据集
3.3 缺点
1、推理开销略高:每次推理需额外计算激活分布,可能影响延迟稳定性
2、内存占用较高:相比静态量化,运行时内存需求更大
3.4 适用场景
自然语言处理(NLP)、语音识别等输入动态变化的任务,尤其适合大模型中 KV Cache 或激活值波动较大的情况。
3.5 流程
1、准备原始 ONNX 模型
确保模型已转换为 ONNX 格式,且结构支持动态量化(如包含 MatMul、Conv 等算子)。
2、导入量化工具
使用 ONNX Runtime 提供的量化接口,例如 from onnxruntime.quantization import quantize_dynamic, QuantType。
3、指定量化参数
设置权重量化类型,如 weight_type=QuantType.QInt8(INT8)。
可选择是否启用逐通道量化(per_channel=True)以提升精度。
控制是否优化模型结构(optimize_model=True)。
4、执行动态量化
调用 quantize_dynamic() 函数,传入原始模型路径、输出模型路径及配置参数。该过程会在推理时动态计算激活值的量化参数,无需额外校准数据。
5、 验证量化结果
加载量化后的模型,进行推理测试,评估精度和性能是否满足预期。
3.6 代码实践(yolov8)
import torch
import onnx
import onnxruntime as ort
from onnxruntime.quantization import quantize_dynamic, QuantType, quantize_static, CalibrationDataReader
import numpy as np
from ultralytics import YOLO # YOLOv8官方库
from onnx import shape_inference
import cv2
# ===================== 第一步:先导出YOLOv8的ONNX模型(基础前提) =====================
def export_yolov8_to_onnx(ptModel_path):
# 加载YOLOv8模型
model = YOLO(ptModel_path)
model.eval()
# 准备输入张量(640x640是YOLOv8默认尺寸)
x = torch.randn(1, 3, 640, 640).to('cpu')
# 用PyTorch导出ONNX模型
torch.onnx.export(
model.model, # YOLOv8内部封装的模型核心
x, # 示例输入(用于追踪计算图)
"yolov8n_origin.onnx", # 原始ONNX模型
export_params=True, # 导出时包含权重参数(必须为True)
opset_version=12, # 兼容ONNX Runtime所有版本
do_constant_folding=True, # 常量折叠优化(减少计算量)
input_names=['input'], # 输入节点名称(方便后续推理时指定输入)
output_names=['output0', 'output1', 'output2'], # YOLOv8的3个输出层
# 动态轴配置(支持可变batch_size) 让导出的 ONNX 模型支持任意 batch_size(比如 1、2、4),而不是固定为 1。
dynamic_axes={
'input': {0: 'batch_size'}, # 支持动态批处理
'output0': {0: 'batch_size'},
'output1': {0: 'batch_size'},
'output2': {0: 'batch_size'}
}
)
# 改用官方导出接口(自动处理输出层、动态轴、算子兼容)
# model.export(
# format='onnx',
# imgsz=640, # 输入尺寸
# batch=1, # 批次
# dynamic=True, # 启用动态批处理
# opset=12, # 算子集版本
# simplify=True, # 简化模型(移除冗余节点)
# name='yolov8n' # 输出模型名:yolov8n_origin.onnx
# )
# 验证导出的ONNX模型是否有效
onnx_model = onnx.load("yolov8n_origin.onnx")
onnx.checker.check_model(onnx_model)
print("原始ONNX模型导出并验证完成!")
# ===================== 第二步:ONNX Runtime量化(两种常用方式) =====================
# 方式1:动态量化(最简单,无需校准数据,适合快速实现)
def dynamic_quant_onnx():
# 核心函数:quantize_dynamic
# 直接对原始ONNX模型做INT8动态量化
quantize_dynamic(
model_input="yolov8n_origin.onnx", # 输入原始ONNX模型
model_output="yolov8n_dynamic_int8.onnx", # 输出量化后的模型
weight_type=QuantType.QUInt8, # 量化权重为无符号8位整数(INT8)
op_types_to_quantize=['Conv', 'MatMul'] # 只量化卷积、矩阵乘法(YOLOv8核心算子)
)
print("ONNX动态量化完成!量化后模型:yolov8n_dynamic_int8.onnx")
# ===================== 第三步:加载量化后的ONNX模型推理(验证) =====================
def infer_quant_onnx(quant_model_path="yolov8n_dynamic_int8.onnx", ori_model_path="yolov8n_origin.onnx", contrast_model=False):
# 加载量化后的模型
sess = ort.InferenceSession(
quant_model_path,
providers=['CPUExecutionProvider'] # 若有GPU,可添加CUDAExecutionProvider:providers=['CUDAExecutionProvider', 'CPUExecutionProvider']
)
# 准备测试输入
test_input = np.random.randn(1, 3, 640, 640).astype(np.float32)
# 执行推理
input_name = sess.get_inputs()[0].name
time1 = time.time()
outputs = sess.run(None, {input_name: test_input}) # 推理:None表示输出所有节点,字典传输入
end_time1 = (time.time() - time1) * 1000
# 输出维度类似 [(1, 84, 8400), (1, 64, 8400), (1, 80, 8400), (1, 64, 80, 80), (1, 128, 40, 40), (1, 256, 20, 20)]
# 包含「检测结果张量」和「中间特征层张量」,第一个为最终检测结果,后两个为辅助检测层,剩下两个为中间特征层;使用ultralytics内的export,推理输出仅为检测结果
print(f"量化模型推理完成!输出维度:{[o.shape for o in outputs]}")
if contrast_model:
# 加载量化后的模型
sess2 = ort.InferenceSession(
ori_model_path,
providers=['CPUExecutionProvider']
# 若有GPU,可添加CUDAExecutionProvider:providers=['CUDAExecutionProvider', 'CPUExecutionProvider']
)
# 准备测试输入
test_input = np.random.randn(1, 3, 640, 640).astype(np.float32)
# 执行推理
input_name = sess2.get_inputs()[0].name
time2 = time.time()
outputs = sess2.run(None, {input_name: test_input}) # 推理:None表示输出所有节点,字典传输入
end_time2 = (time.time() - time2) * 1000
original_size = os.path.getsize(ori_model_path) / (1024 * 1024)
quantized_size = os.path.getsize(quant_model_path) / (1024 * 1024)
print(f"\n[模型大小对比]")
print(f" 原始模型: {original_size:.2f} MB")
print(f" 量化模型: {quantized_size:.2f} MB")
print(f" 压缩比例: {(1 - quantized_size / original_size) * 100:.1f}%")
print(f"\n[推理速度对比] (20次平均)")
print(f" 原始模型: {np.mean(end_time2):.2f} ms ({1000/np.mean(end_time2):.1f} FPS)")
print(f" 量化模型: {np.mean(end_time1):.2f} ms ({1000/np.mean(end_time1):.1f} FPS)")
speedup = np.mean(end_time2) / np.mean(end_time1)
print(f" 加速比: {speedup:.2f}x")
# ===================== 主函数:一键执行所有流程 =====================
if __name__ == "__main__":
set_seed(seed=42)
ptModel_path = 'F:\\ObjectDetection\\deeplearning\\yolo\\new_try\\yolov8n.pt'
# 1. 导出原始ONNX模型
export_yolov8_to_onnx(ptModel_path)
# 2. 动态量化(推荐入门先跑这个)
dynamic_quant_onnx()
# 3. 验证量化模型
infer_quant_onnx("yolov8n_dynamic_int8.onnx", "yolov8n_origin.onnx", contrast_model=True)
输出维度类似 [(1, 84, 8400), (1, 64, 8400), (1, 80, 8400), (1, 64, 80, 80), (1, 128, 40, 40), (1, 256, 20, 20)],包含「检测结果张量」和「中间特征层张量」,第一个为最终检测结果,后两个为辅助检测层,剩下两个为中间特征层
可使用ultralytics内的export,推理输出仅为检测结果,在代码中有,不过如果运行要换一下保存的onnx名字,我这里有一些问题,改一下不影响核心运行。
最后还添加了
1、随机种子的设定不然每次运行量化后的大小有偏差,但推理时间是一定有偏差的涉及到操作系统的资源调度;
2、量化前与量化后的模型大小对比与运行时间对比,预测精度没有对比哈。
自己改一下模型路径。
四、训练后量化—静态量化
4.1 概念
在模型部署前,使用少量校准数据(calibration data)统计激活值的分布,预先计算并固定量化参数(scale 和 zero_point),推理时直接复用这些参数。
4.2 特点
1、推理效率高:无需实时计算量化参数,延迟稳定
2、内存占用低:适合边缘设备、嵌入式系统等资源受限场景
4.3 缺点
1、依赖校准数据代表性:若实际输入分布与校准数据差异大,精度可能下降
2、适用场景:数据分布相对固定的任务,如图像分类、固定领域文本处理、云端高并发推理等。
4.4 典型应用
图像分类、边缘部署
4.5 基本流程
1、准备原始 ONNX 模型
确保模型已转换为 ONNX 格式,且结构支持静态量化。
2、准备校准数据集
收集一小部分代表性推理数据(通常 100-500 个样本),用于统计激活值的分布情况。
3、导入量化工具
使用 ONNX Runtime 提供的量化接口,例如 from onnxruntime.quantization import quantize_static, QuantType。
4、指定量化参数
设置权重量化类型,如 weight_type=QuantType.QInt8(INT8)。
可选择是否启用逐通道量化(per_channel=True)以提升精度。
控制是否优化模型结构(optimize_model=True)。
指定校准方法,如 calibration_method=CalibrationMethod.MinMax 或 Entropy。
5、执行静态量化
调用 quantize_static() 函数,传入原始模型路径、输出模型路径、校准数据集及配置参数。该过程会基于校准数据计算激活值的量化参数(scale 和 zero_point)。
6、验证量化结果
加载量化后的模型,进行推理测试,评估精度和性能是否满足预期。
4.6 代码实践(yolov8)
数据自行准备。
静态量化的精度高,需要配置的参数相较于动态量化复杂的多。在调试过程中涉及到onnx版本问题、预处理问题、参数的设置等。
import onnx
from onnx import version_converter
from onnxruntime.quantization import quantize_static, CalibrationDataReader, QuantType, QuantFormat
from onnxruntime.quantization.preprocess import quant_pre_process
import numpy as np
import cv2
import os
from utils import set_seed, infer_quant_onnx, export_yolov8_to_onnx
class YOLOCalibrationDataReader(CalibrationDataReader):
"""YOLO校准数据读取器"""
def __init__(self, calibration_dataset, input_shape=(640, 640), batch_size=1):
"""
Args:
calibration_dataset: 校准数据集路径列表
input_shape: 输入尺寸 (H, W)
batch_size: 批处理大小
"""
self.dataset = calibration_dataset
self.input_shape = input_shape
self.batch_size = batch_size
self.current_index = 0
def get_next(self):
"""获取下一个校准数据批次"""
if self.current_index >= len(self.dataset):
return None
batch_data = []
for _ in range(self.batch_size):
if self.current_index >= len(self.dataset):
break
img_path = self.dataset[self.current_index]
# 预处理图像
img = self.preprocess_image(img_path)
batch_data.append(img)
self.current_index += 1
if not batch_data:
return None
# 堆叠为批次
batch_array = np.stack(batch_data, axis=0).astype(np.float32)
return {'input': batch_array}
def preprocess_image(self, img_path):
"""图像预处理"""
# 读取图像
img = cv2.imread(img_path)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# 调整大小
img = cv2.resize(img, self.input_shape)
# 归一化 (0-1)
img = img / 255.0
# 转换为CHW格式
img = np.transpose(img, (2, 0, 1))
# 添加批次维度
# img = np.expand_dims(img, axis=0)
return img
def quantize_yolov8_onnx(model_path, calibration_dataset, output_path):
"""
量化YOLOv8 ONNX模型
Args:
model_path: ONNX模型路径
calibration_dataset: 校准数据集路径列表
output_path: 量化模型输出路径
"""
# 步骤1:升级 opset 版本到 13+(Per-Channel 量化需要)
print("正在升级 opset 版本...")
onnx_model = onnx.load(model_path)
print(f"原始 opset 版本: {onnx_model.opset_import[0].version}")
if onnx_model.opset_import[0].version < 13:
# 升级到 opset 13
converted_model = version_converter.convert_version(onnx_model, 13)
upgraded_model_path = "yolov8n_opset13.onnx"
onnx.save(converted_model, upgraded_model_path)
print(f"已升级 opset 到版本 13,保存到: {upgraded_model_path}")
else:
upgraded_model_path = model_path
print("opset 版本已满足要求")
# 步骤2:预处理模型 ONNX 模型在量化前需要进行预处理(preprocessing),包括形状推断、常量折叠等优化
print("正在预处理模型...")
preprocessed_model_path = "yolov8n_preprocessed.onnx"
quant_pre_process(upgraded_model_path, preprocessed_model_path, auto_merge=True)
print(f"预处理模型已保存到: {preprocessed_model_path}")
# 创建校准数据读取器
calibration_data_reader = YOLOCalibrationDataReader(
calibration_dataset=calibration_dataset,
input_shape=(640, 640),
batch_size=1
)
# 量化配置(使用 QDQ 格式)
quant_config = {
'quant_format': QuantFormat.QDQ, # 指定量化后 ONNX 模型的格式为「QDQ 格式」(Quantize-DeQuantize,量化 - 反量化)
'per_channel': True, # 开启「按通道量化」(也叫 per-channel)
'weight_type': QuantType.QInt8, # 权重量化类型
'activation_type': QuantType.QInt8, # 激活量化类型
'nodes_to_quantize': [], # 空列表表示量化所有节点
'nodes_to_exclude': [], # 需要排除的节点
'extra_options': {
'ActivationSymmetric': False,
'WeightSymmetric': True,
'EnableSubgraph': False
}
}
# 执行量化
quantize_static(
model_input=preprocessed_model_path,
model_output=output_path,
calibration_data_reader=calibration_data_reader,
quant_format=quant_config['quant_format'],
per_channel=quant_config['per_channel'],
weight_type=quant_config['weight_type'],
activation_type=quant_config['activation_type'],
nodes_to_quantize=quant_config['nodes_to_quantize'],
nodes_to_exclude=quant_config['nodes_to_exclude'],
extra_options=quant_config['extra_options']
)
print(f"量化模型已保存到: {output_path}")
# 清理临时文件
for temp_file in [upgraded_model_path, preprocessed_model_path]:
if temp_file != model_path and os.path.exists(temp_file):
os.remove(temp_file)
print(f"已清理临时文件: {temp_file}")
return output_path
# ===================== 主函数:一键执行所有流程 =====================
if __name__ == "__main__":
set_seed(seed=42)
ptModel_path = 'F:\\ObjectDetection\\deeplearning\\yolo\\new_try\\yolov8n.pt'
# 1. 导出原始ONNX模型
export_yolov8_to_onnx(ptModel_path)
# 使用示例
calibration_images = [
'F:\\ObjectDetection\\deeplearning\\yolo\\new_try\\PB300346.JPG',
]
quantize_yolov8_onnx(
model_path='yolov8n_origin.onnx',
calibration_dataset=calibration_images,
output_path='yolov8n_static_int8.onnx'
)
infer_quant_onnx("yolov8n_static_int8.onnx", "yolov8n_origin.onnx", contrast_model=True)
其他知识补充
- onnx与onnxruntime
onnx 定义了 ONNX 模型的规范,onnxruntime 是遵循这个规范的高性能推理引擎;没有onnx的标准,onnxruntime就没有统一的模型格式可执行;没有onnxruntime,onnx模型只是一个 “静态文件”,无法落地运行。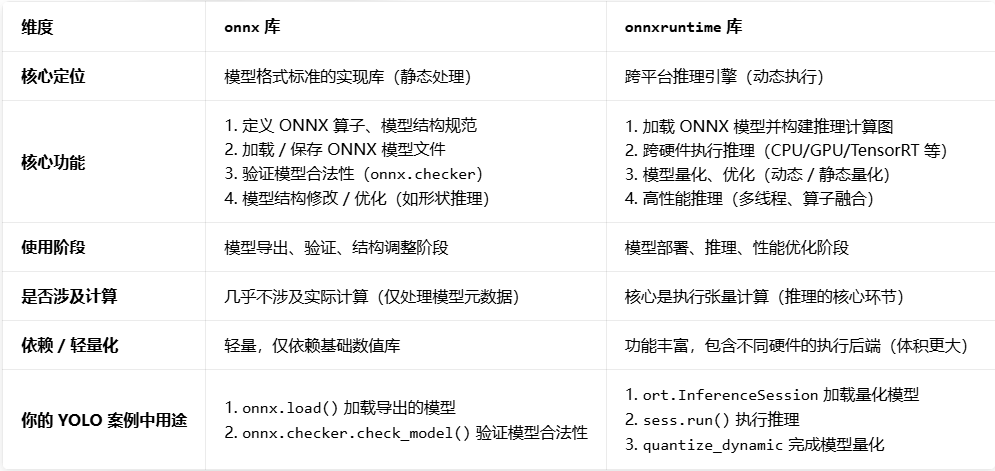
完整代码

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 6
6 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)