分布式微服务日志采集常用方案及其优缺点
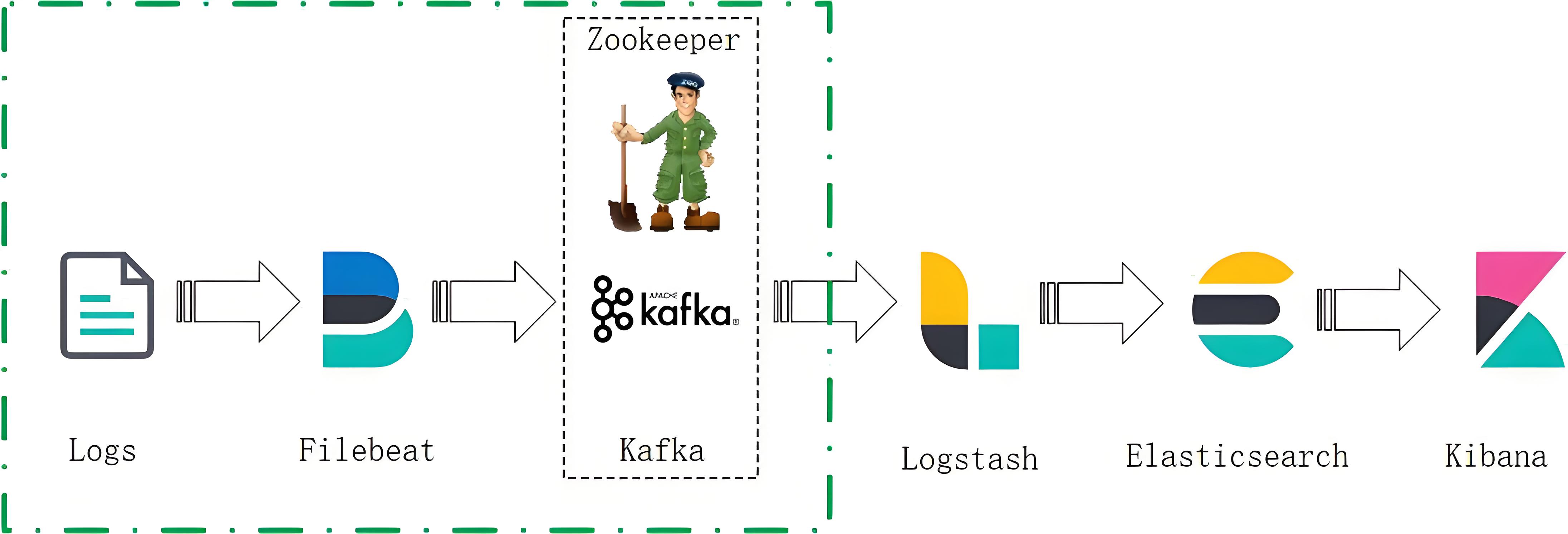
FK+ELK架构图
主流的日志采集方案对比
在分布式微服务架构中,日志采集面临高并发、高分散、强实时性等挑战。以下是当前主流的日志采集方案及其核心优缺点对比
| 方案 | 核心组件 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| Filebeat + ELK(Elastic Stack) | Filebeat、Logstash、Elasticsearch、Kibana | - Filebeat 轻量级,资源占用低(CPU < 0.1核,内存约100MB),适合部署在每个微服务节点上。 - 完整生态,支持丰富的日志解析(Grok)、过滤、富化(如Kubernetes元数据)。 - Elasticsearch 提供强大的全文检索和聚合分析能力,Kibana 可视化界面友好。 - 支持断点续传,可靠性高,避免日志丢失。 |
- 架构复杂,组件多(Filebeat、Logstash、ES、Kibana),部署和运维成本高。 - Logstash 基于JVM,内存消耗大(建议2GB+),可能成为性能瓶颈。 - 对多行日志(如Java异常栈)处理需额外配置(multiline插件)。 - 存储成本高,需精心设计索引生命周期管理(ILM)。 |
中大型企业,对日志分析、搜索和可视化有高要求,且拥有专职运维团队的场景。 |
| Fluentd / Fluent Bit + Loki | Fluentd/Fluent Bit、Loki、Grafana | - Fluent Bit 极其轻量(内存占用可低至几MB),专为容器和Kubernetes环境优化,是CNCF毕业项目。 - Loki 架构简单,不建立倒排索引,存储成本远低于Elasticsearch,与Prometheus生态集成好。 - 配置相对简洁,适合云原生环境。 |
- Loki 的查询功能和搜索能力弱于Elasticsearch,不支持复杂的全文检索。 - Fluentd 插件生态虽丰富,但配置复杂度高于Filebeat。 - 可视化依赖Grafana,功能不如Kibana丰富。 |
云原生(Kubernetes)环境、对成本敏感、追求轻量级和高效率的中小型团队或新兴项目。 |
| Vector | Vector | - 由Rust编写,性能极高,资源消耗极低(接近Fluent Bit),同时支持高可靠交付保证。 - 单一进程即可完成采集、转换、传输,架构简洁,减少组件间依赖。 - 支持丰富的输入源(文件、syslog、Kafka等)和输出目标(S3、Kafka、Loki、ES等)。 |
- 相对较新,社区规模和文档生态不如ELK或Fluentd成熟。 - 功能迭代快,可能在稳定性上需更长时间验证(但官方提供代码稳定性保证)。 |
追求极致性能、低资源消耗和架构简洁性的现代云原生环境,尤其适合资源受限的边缘节点或高吞吐场景。 |
| 基于消息队列(Kafka/RabbitMQ) | 业务应用 + Kafka/RabbitMQ + 消费者 | - 解耦生产与消费,削峰填谷,保障高吞吐和可靠性10。 - Kafka 吞吐量极高(>100k条/秒),适合海量日志场景。 - 可灵活接入多种处理引擎(Spark、Flink、Logstash)进行实时或离线分析。 - bizLog等框架可与RabbitMQ结合,实现业务操作日志的精准采集。 |
- 需要额外维护消息队列集群,增加系统复杂性。 - 实时性依赖消费者处理速度,可能存在延迟。 - 不如专用Agent(如Filebeat)对文件日志的采集能力强,需应用改造以支持直接发送日志消息。 |
日志量极大、对系统解耦和可靠性要求极高,或需要将业务操作日志(如“用户下单”)与系统日志统一处理的场景。 |
| Sidecar模式(Kubernetes原生) | 每个Pod部署日志Agent容器 | - 与应用Pod生命周期绑定,隔离性好,避免宿主机污染。 - 无需在应用镜像中内置Agent,部署灵活。 - 与Kubernetes API深度集成,可自动发现容器日志。 |
- 每个Pod增加一个Sidecar容器,资源开销翻倍(CPU、内存)。 - 管理和监控多个Agent容器的配置和状态更复杂。 - 仅适用于Kubernetes环境,不适用于物理机或虚拟机。 |
完全基于Kubernetes的微服务架构,且对日志采集的隔离性和自动化有强需求的场景。 |
典型架构组件与职责
- 采集层:Filebeat、Fluent Bit、Fluentd 等轻量 Agent,部署于每个节点/容器。
- 缓冲/传输层:Kafka、Pulsar 等消息队列,用于削峰填谷、保障可靠性 。
- 处理层:Logstash 或 Flink,用于结构化、脱敏、富化日志 。
- 存储层:Elasticsearch(热数据)、ClickHouse(分析)、对象存储(冷数据)。
- 展示层:Kibana、Grafana,提供可视化与告警 。
优化实践建议
- 结构化日志:输出为 JSON 格式,减少解析开销 。
- 异步写入:避免阻塞业务线程(如使用 Logback AsyncAppender)。
- 冷热分层:热数据存 Elasticsearch,冷数据归档至 S3/OSS 。
- Trace 关联:通过 OpenTelemetry 将日志与分布式追踪链路绑定,加速故障定位 。
当前(2026年)主流生产环境多采用 EFK 或 Fluent Bit + Kafka + Elasticsearch 架构,兼顾轻量、可靠与可扩展性
附件一:Filebeat和Fluent Bit对比(精练)
| 特性 | Filebeat | Fluent Bit |
|---|---|---|
| 开发语言 | Go | C |
| 内存占用 | 30-50 MB | <10 MB |
| CPU 使用率 | 极低 | 极低 |
| 吞吐量 | 中等 | 高 |
| 数据处理能力 | 简单转发 | 强大过滤与路由 |
| 适用场景 | Elastic Stack 集成、轻量采集 | 高性能、容器化、边缘计算 |
| 插件支持 | 较少 | 较多 |
在选择时,若追求与 Elasticsearch 等 Elastic Stack 工具的无缝对接,并且对性能要求不高,Filebeat 是一个可靠的选择;若需要更高的吞吐量、更低的资源消耗以及更灵活的数据处理能力,则 Fluent Bit 更具优势。
附件二:分布式微服务日志采集组件整理
分布式微服务架构下,日志采集是可观测性的核心环节。为满足高可用、低延迟、可扩展的日志收集需求,业界已形成以 ELK、EFK、Loki 等为代表的主流方案。以下是涵盖主流组件的全面清单,按功能层级分类整理,便于选型与架构设计。
一、核心日志采集组件(Agent/Collector)
这些组件部署在应用服务器或容器节点上,负责从源头采集日志。
| 组件 | 类型 | 特点 | 适用场景 |
|---|---|---|---|
| Filebeat | 轻量级采集器(Beats家族) | 基于Go开发,资源占用极低,专为日志文件设计,支持多行日志合并、文件旋转跟踪。可直接输出到Elasticsearch或经Logstash处理。 | 传统服务器、Kubernetes Sidecar模式日志采集 |
| Metricbeat | Beats家族 | 采集系统指标(CPU、内存、磁盘等),适用于监控场景 | 服务性能监控与日志联动分析 |
| Packetbeat | Beats家族 | 抓取网络流量数据,分析服务间通信 | 微服务调用链路监控、网络延迟分析 |
| Winlogbeat | Beats家族 | 专用于Windows事件日志采集 | Windows服务器环境日志统一管理 |
| Fluent Bit | 轻量级日志处理器 | 比Fluentd更轻,C语言编写,启动快,内存占用少。支持过滤、解析、路由,常用于Kubernetes环境。 | 容器化环境、边缘计算节点 |
| Fluentd | 日志收集器 | 功能强大,插件丰富(超过500个),支持结构化日志处理,是Kubernetes官方推荐的日志方案之一。 | 需要复杂日志处理逻辑的场景 |
二、日志处理与缓冲组件(Processor/Buffer)
用于日志的格式化、过滤、脱敏及流量削峰。
| 组件 | 功能 | 特点 | 参考 | |
|---|---|---|---|---|
| Logstash | 日志处理管道 | 支持丰富的输入、过滤、输出插件,可实现日志解析(如Grok)、字段提取、JSON化、脱敏等。但资源消耗较高,通常不直接部署在应用节点。 | 需要深度日志清洗和转换的场景 | |
| Kafka | 消息队列缓冲 | 解耦采集与处理,应对日志洪峰,保障系统稳定性。支持多消费者、持久化、高吞吐。 | 大规模微服务、高并发日志场景 | |
| Redis | 缓冲/临时存储 | 可作为轻量级缓冲层,适合中小规模系统 | 成本敏感型项目 |
三、日志存储与搜索引擎(Storage & Search)
负责日志的集中存储、索引构建与高效检索。
| 组件 | 功能 | 特点 | 参考 | |
|---|---|---|---|---|
| Elasticsearch (ES) | 分布式搜索引擎 | 基于Lucene,支持近实时检索、聚合分析、高可用分片机制。是ELK/EFK架构的核心存储引擎 | 全文检索、复杂查询、可视化分析 | |
| Loki | 云原生日志系统 | 由Grafana推出,不索引日志内容,仅索引元数据(标签),成本低,适合与Prometheus/Grafana集成。 | 成本敏感、监控告警一体化场景 |
四、可视化与分析平台(Visualization)
提供Web界面进行日志查询、仪表盘展示与告警。
| 组件 | 功能 | 特点 | 参考 | |
|---|---|---|---|---|
| Kibana | ELK官方可视化工具 | 提供丰富的图表、仪表盘、地图、机器学习异常检测等功能,与Elasticsearch深度集成。 | ELK生态标准搭配 | |
| Grafana | 多数据源可视化平台 | 支持Elasticsearch、Loki、Prometheus等多种数据源,统一监控视图,适合云原生环境。 | 多系统统一监控大屏 |
五、典型架构组合推荐
-
ELK(经典方案)
Filebeat → Logstash → Elasticsearch → Kibana
适用于需要强大日志处理能力的企业级系统。 -
EFK(Kubernetes推荐)
Fluentd/Fluent Bit → Elasticsearch → Kibana
官方推荐,适合容器化环境。 -
ELK + Kafka(高吞吐场景)
Filebeat → Kafka → Logstash → ES → Kibana
通过Kafka解耦,提升系统稳定性。 -
Loki 栈(轻量高效)
Promtail (采集) → Loki (存储) → Grafana (可视化)
适合云原生、成本敏感型项目。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 30
30 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)