YOLO 多版本实战贝壳识别:模型训练与效果对比
·
前言
在海洋生物分类、贝壳标本数字化管理等场景中,贝壳识别的自动化需求日益提升,目标检测技术成为实现该需求的核心手段。YOLO 系列算法凭借端到端检测、速度快、精度高的优势,广泛应用于各类目标识别任务。本次实验基于自建贝壳识别数据集,分别采用 YOLOv5、v8、v11、v12、v26 五个版本开展训练,对比不同版本模型在贝壳识别任务中的表现,为同类细粒度目标检测场景提供实操参考。
一、数据集基本信息
本次实验采用自建贝壳识别数据集,所有样本均经过人工精细标注,标注格式为 YOLO 标准 txt 格式,可直接适配各版本 YOLO 模型训练,有效保证标注精度与数据集可用性。为兼顾模型训练效果与泛化能力,采用随机划分方式将数据集分为训练集、验证集、测试集,无样本重叠,各集样本数量明确:训练集 288 张,用于模型核心参数的学习与拟合;验证集 28 张,用于训练过程中超参数调优、模型早停及过拟合抑制;测试集 13 张,用于独立评估各模型最终的实际检测性能。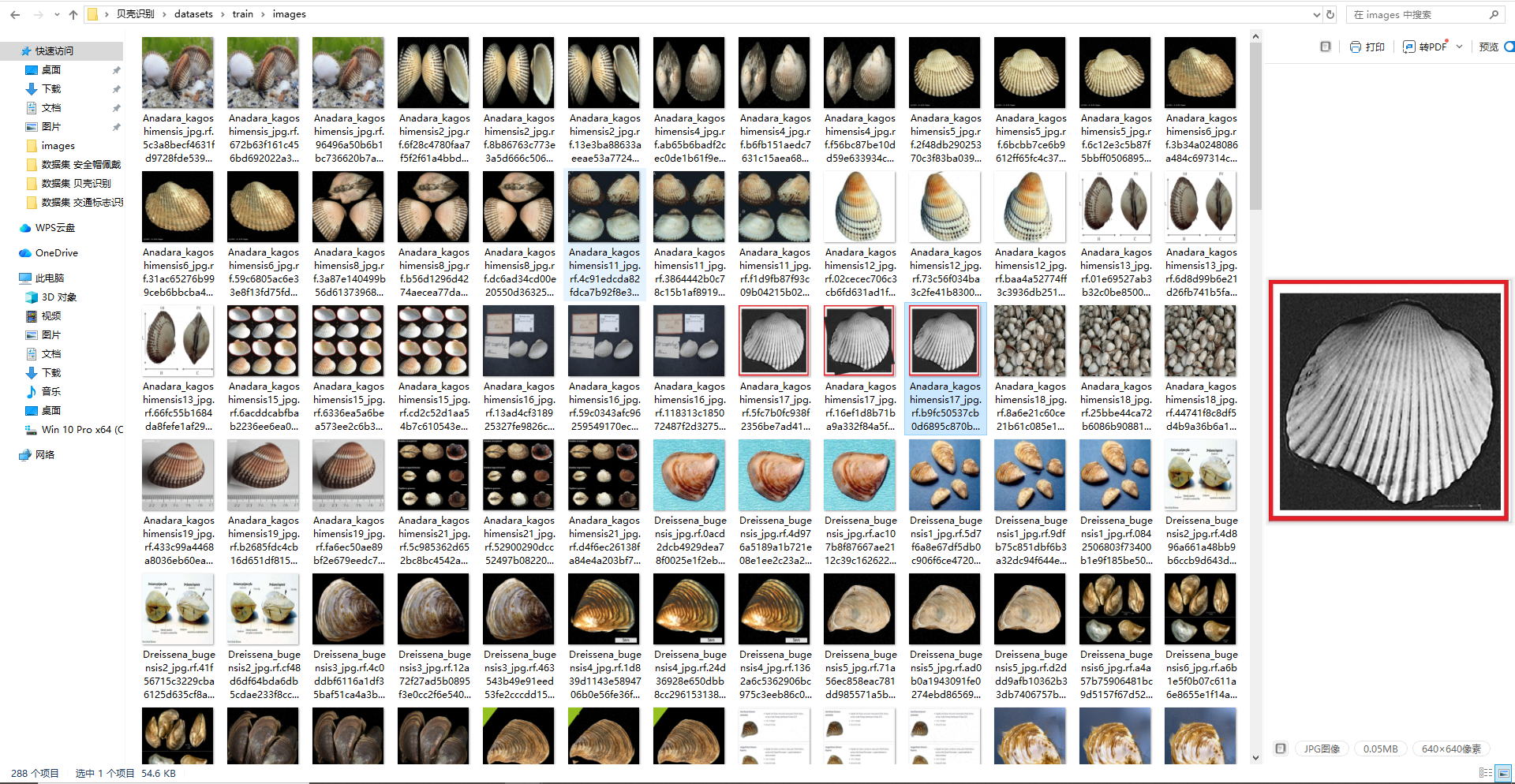
二、模型训练相关说明
- 训练模型选择:本次实验选取 YOLO 系列 5 个典型版本,覆盖经典轻量化、中端平衡型、前沿大尺度模型,分别为 YOLOv5、YOLOv8、YOLOv11、YOLOv12、YOLOv26,全面对比不同架构模型在贝壳识别任务中的适配性。
- 统一训练规范:为保证对比结果的公平性,所有版本模型采用完全一致的训练设置:输入图片尺寸为 640×640(YOLO 系列标准尺寸),搭配相同的批次大小、训练轮数及数据增强策略;均加载官方 COCO 数据集预训练权重,基于迁移学习实现快速收敛,避免小数据集过拟合问题。
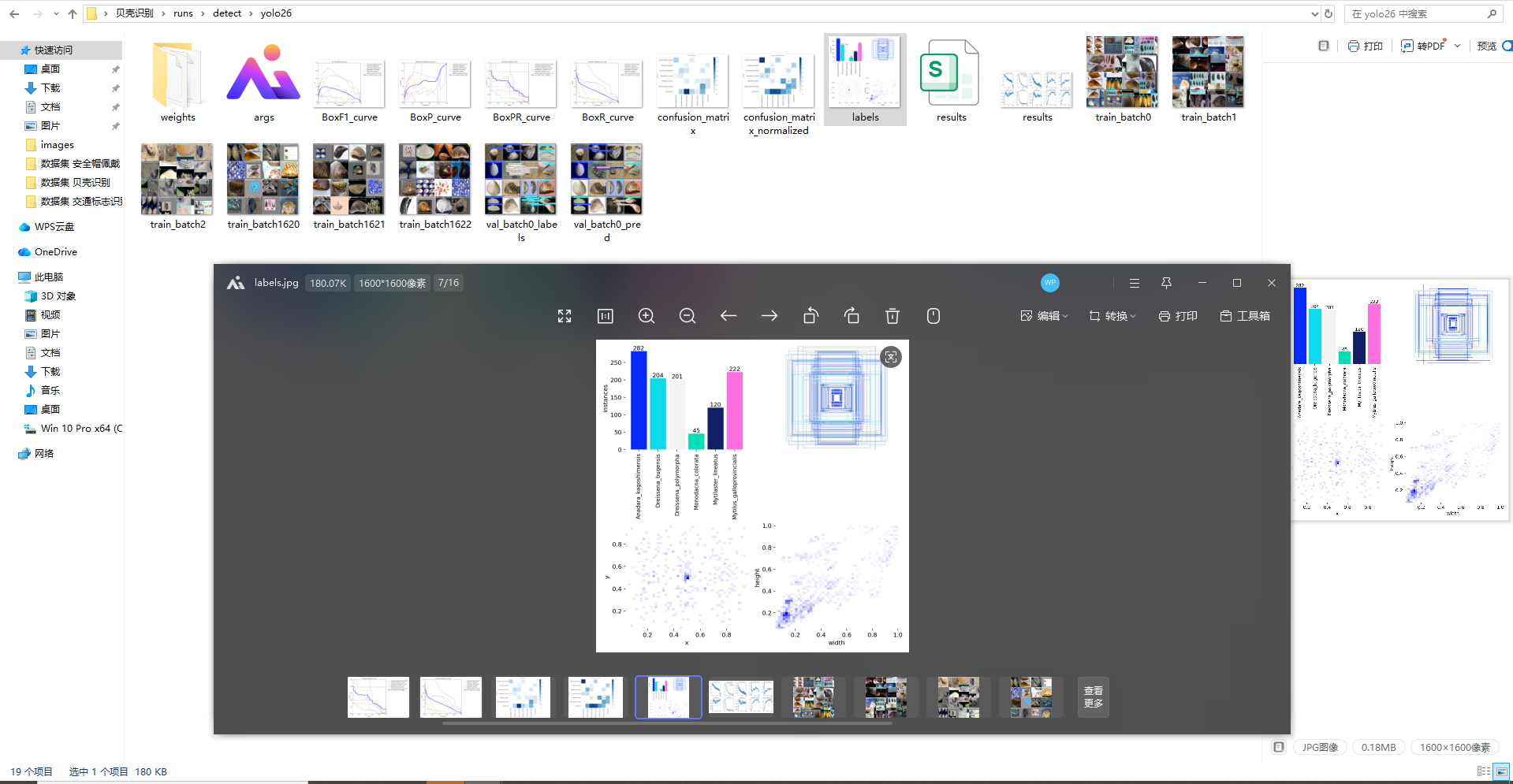
- 训练过程与结果输出:按 YOLO 标准格式组织数据集并配置对应 yaml 文件,依次完成各版本模型的加载与训练;训练过程中实时监控损失曲线、精度(P)、召回率(R)等核心指标,训练结束后保存各版本最优模型权重,同时生成完整的损失曲线、PR 曲线、mAP 曲线等训练结果图,为后续效果分析提供直观依据。
三、实验总结
本次实验完成了 YOLOv5、v8、v11、v12、v26 五个版本在贝壳识别数据集上的全流程训练,各模型均实现良好收敛,无明显过拟合现象,整体检测效果均能满足贝壳识别基本需求,且不同版本模型展现出差异化优势:
- YOLOv11 作为轻量级模型,收敛速度最快,模型体积最小,推理效率最优,在对检测速度要求高、部署资源有限的场景中具备显著优势;
- YOLOv26 作为前沿大尺度模型,虽因网络参数更多导致收敛稍慢,但在 mAP@0.5、精度、召回率等核心检测指标上表现最优,贝壳的定位与分类精度更高,适配对识别精度有严格要求的场景;
- YOLOv8、v12 实现了精度与速度的均衡表现,各项指标处于中等偏上水平,是常规贝壳识别场景的高性价比选择;
- YOLOv5 作为经典版本,整体训练过程稳定,检测效果表现均衡,社区生态完善、易上手,适合入门级实操与常规场景应用。
本次实验验证了不同版本 YOLO 算法在贝壳识别细粒度目标检测任务中的适用性,实际应用中可根据部署环境、精度需求、速度要求灵活选择模型:追求极致部署速度选 YOLOv11,要求高精度识别选 YOLOv26,兼顾精度与速度则优先考虑 YOLOv8、v12,入门实操与常规场景可选择 YOLOv5。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 7
7 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)