<span class=“js_title_inner“>扩展 PostgreSQL,以支撑 8 亿 ChatGPT 用户</span>
(我们曾与 CMU 的 Andy Pavlo 教授写过一篇深入分析这些问题的文章:《The Part of PostgreSQL We Hate the Most》,甚至被引用进了 PostgreSQL 的维基百科。为了支撑这一增长,我们在应用层和 PostgreSQL 数据库层面都迅速做了大量优化,同时通过**纵向扩容(增大实例规格)和横向扩容(增加只读副本)**来扩展能力。我们是如何通过严谨的
多年来,PostgreSQL 一直是支撑 ChatGPT 和 OpenAI API 等核心产品的关键底层数据系统之一。随着用户规模的快速增长,我们对数据库的需求也呈指数级上升。过去一年里,我们的 PostgreSQL 负载增长了 10 倍以上,而且仍在持续攀升。
在推进生产基础设施以支撑这一增长的过程中,我们得出了一个新的认知:PostgreSQL 在读密集型场景下的可扩展性,远比许多人以为的要强得多。这个系统最初由加州大学伯克利分校的一组科学家创建,如今我们已经能够依靠 一个主实例(Primary)+ 近 50 个分布在全球多个区域的只读副本(Azure PostgreSQL Flexible Server),支撑全球范围内的海量流量。
这篇文章将讲述:我们是如何通过严谨的工程实践和大量优化,把 PostgreSQL 扩展到每秒数百万次查询(QPS),服务 8 亿用户的;同时也会分享过程中得到的关键经验。
初始架构中的裂缝
ChatGPT 发布后,流量以史无前例的速度增长。为了支撑这一增长,我们在应用层和 PostgreSQL 数据库层面都迅速做了大量优化,同时通过**纵向扩容(增大实例规格)和横向扩容(增加只读副本)**来扩展能力。这套架构在很长一段时间内运行良好,并且随着持续优化,依然为未来增长提供了充足空间。
乍一听,单主(single-primary)架构似乎难以支撑 OpenAI 这种规模,但真正把它跑稳并不简单。我们经历过多次由于 PostgreSQL 过载导致的 SEV 级事故,而且模式高度相似:
- 上游异常导致数据库负载突然飙升,例如缓存层失效引发大规模 cache miss
- 大量复杂多表 join 的查询瞬间把 CPU 打满
- 新功能上线引发写入风暴(write storm)
当资源利用率持续上升时,查询延迟开始增加、请求超时,随后重试进一步放大负载,形成恶性循环,甚至可能拖垮整个 ChatGPT 和 API 服务。

写负载的核心挑战:MVCC
尽管 PostgreSQL 在读密集型场景下扩展性很好,但在高写入压力下仍然存在明显挑战,根源在于其 MVCC(多版本并发控制)实现。
举例来说:
- 即使只更新一行中的一个字段,也会复制整行生成新版本
- 在高写入场景下,这会导致严重的写放大
- 同时也会引入读放大,因为查询需要扫描多个版本(dead tuples)才能找到最新数据
此外,MVCC 还会带来表和索引膨胀、更高的索引维护成本,以及复杂的 autovacuum 调优问题。(我们曾与 CMU 的 Andy Pavlo 教授写过一篇深入分析这些问题的文章:《The Part of PostgreSQL We Hate the Most》,甚至被引用进了 PostgreSQL 的维基百科。)
将 PostgreSQL 扩展到百万级 QPS
为了解决写入瓶颈、降低主库压力,我们已经(并仍在持续)将可分片、写密集型的工作负载迁移到分片系统中,例如 Azure Cosmos DB,同时在应用逻辑层减少不必要的写操作。
当前策略是:
- 不再允许在现有 PostgreSQL 集群中新建表
- 所有新工作负载默认使用分片系统
- PostgreSQL 继续保持单主、不分片架构
原因很现实:对现有应用进行 PostgreSQL 分片极其复杂,需要改动数百个接口,可能耗时数月甚至数年。而我们的整体负载仍以读为主,在大量优化之后,现有架构依然有足够的增长空间。因此,虽然未来不排除分片 PostgreSQL,但这并非短期优先事项。
接下来,我们将详细介绍一系列关键挑战,以及对应采取的优化手段。
降低主库负载
挑战单主架构无法横向扩展写入,高峰写入很容易压垮主库。
解决方案
- 尽可能把读请求下沉到只读副本
- 仅在事务必须的情况下,才在主库上执行读
- 将写密集型、可分片负载迁移到 Cosmos DB
- 修复应用中导致重复写入的 bug
- 引入 lazy write,平滑写入峰值
- 对回填(backfill)操作实施严格限速
查询优化
挑战少数昂贵查询在流量突增时,会消耗大量 CPU,直接影响服务稳定性。
解决方案
- 持续审计和优化 SQL,避免 OLTP 反模式
- 避免复杂多表 join(我们曾发现一个 join 了 12 张表的查询,直接引发 SEV)
- 必要时拆分查询,把复杂 join 逻辑挪到应用层
- 仔细审查 ORM 生成的 SQL
- 设置
idle_in_transaction_session_timeout,防止空闲事务阻塞 autovacuum
单点故障的缓解
挑战单主意味着单点故障,一旦主库宕机,服务整体受影响。
解决方案
- 将关键读请求迁移到只读副本,即使主库不可用,读服务仍可继续
- 主库运行在 高可用(HA)模式,配备热备实例
- 主库故障或维护时,快速提升 standby
- 每个区域部署多个只读副本,避免单副本失败导致区域级事故
工作负载隔离(Noisy Neighbor)
挑战某些请求会异常消耗资源,影响同实例上的其他请求。
解决方案
- 将请求分为高优先级和低优先级
- 路由到不同实例,避免互相干扰
- 同样的隔离策略也应用于不同产品之间
连接池(PgBouncer)
挑战连接数有限(Azure PostgreSQL 上限 5000),容易被连接风暴耗尽。
解决方案
- 使用 PgBouncer 进行连接池化
- 使用 statement / transaction pooling
- 平均建连时间从 50ms 降至 5ms
- Proxy、客户端和副本同区域部署
- 精细配置 idle timeout,避免连接泄漏
缓存保护
挑战缓存命中率骤降会导致数据库瞬时读洪峰。
解决方案
- 实现 cache locking / leasing
- 同一个 key 只有一个请求回源数据库
- 其他请求等待缓存更新
- 有效防止 cache miss 风暴拖垮 PostgreSQL
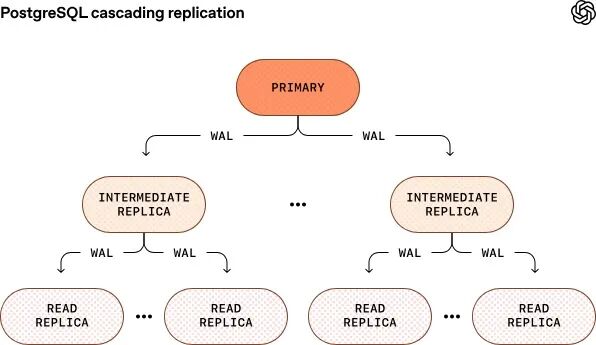
扩展只读副本
挑战副本越多,主库需要发送的 WAL 越多,网络和 CPU 压力上升。
解决方案
- 当前在全球部署近 50 个只读副本
- 与 Azure PostgreSQL 团队合作测试 级联复制(cascading replication)
- 由中间副本向下游副本转发 WAL
- 未来可扩展到上百副本,但需谨慎处理故障切换复杂性
限流(Rate Limit)
挑战流量突增、昂贵查询或重试风暴会迅速耗尽系统资源。
解决方案
- 在 应用层、连接池、代理层、查询层 多层限流
- 避免过短的重试间隔
- 在 ORM 层支持对特定 query digest 的限流甚至封禁
- 精准降载,加快系统恢复
Schema 管理
挑战即使是小的 schema 变更,也可能触发表级重写。
解决方案
- 仅允许轻量级 schema 变更
- 严格限制 schema 变更超时(5 秒)
- 索引使用
CONCURRENTLY创建 / 删除 - 新表只能建在分片系统中
- 回填操作严格限速,即便耗时一周也优先保证稳定性
结果与未来
这次实践证明:只要设计得当、优化到位,Azure PostgreSQL 可以支撑全球最大规模的生产负载之一。
- 支撑 数百万 QPS 的读请求
- 为 ChatGPT 和 API 提供核心存储能力
- 近 50 个副本,复制延迟接近 0
- 全球低延迟读
- p99 延迟稳定在 个位数到低双位毫秒
- 达到 99.999% 可用性
过去 12 个月里,我们只经历过 一次 SEV-0 的 PostgreSQL 事故(发生在 ChatGPT ImageGen 病毒式发布期间,写入流量在一周内暴涨 10 倍以上)。
展望未来:
- 继续迁移剩余写密集型负载
- 推进级联复制
- 探索 PostgreSQL 分片或其他分布式系统
PostgreSQL 仍在被不断推向极限,但它依然给了我们足够长的“增长跑道”。
原文链接:https://openai.com/index/scaling-postgresql/[1]
References
- https://openai.com/index/scaling-postgresql/: https://openai.com/index/scaling-postgresql/

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 0
0 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)