艾体宝产品|AI应用的关键基础设施:Arango 上下文数据平台解析
2026 年的共识是:模型能力正在商品化,真正的壁垒在于企业特有的上下文数据。谁能够更高效地采集、关联、检索和演化这些上下文数据,谁的 AI 应用就能更懂业务、更快响应、更低成本地迭代。这不是要企业扔掉现有的 PostgreSQL、Elasticsearch 或 Neo4j。恰恰相反,Arango v4.0 是架设在它们之上的 “AI 上下文语义层”。它专门负责回答 AI 提出的复杂关联性问题,而
1. 一个被忽略的事实:AI 落地的瓶颈早已不是模型
2026 年,企业不再问“要不要上大模型”,而是问“为什么上了大模型,业务效果还是出不来”。答案往往指向同一个方向:**数据缺乏上下文结构(Context)**。
传统的数据架构是为“应用系统”设计的,而非为“智能体(AI Agent)”设计。当 AI 试图理解一个客户工单、分析一份合同、推荐一个供应链决策时,它需要的不是孤立的一行记录,而是围绕这个对象的完整上下文——实体关系、历史轨迹、业务约束、实时状态。
当一个 AI 应用需要完成如下任务时:
- 理解客户工单的历史处理链路
- 分析一份合同在企业风险体系中的位置
- 判断某个供应链决策对上下游的影响
它需要的不仅是孤立的数据记录,而是围绕某个对象的完整上下文,包括:
- 实体关系(Entity Relationship)
- 历史事件(Event History)
- 业务规则(Business Constraints)
- 实时状态(Operational State)
在这种需求下,传统的 RAG(Retrieval-Augmented Generation) 架构逐渐暴露出局限。向量检索能够回答的问题主要是:
“哪些内容与当前问题在语义上相似?”
但在真实业务场景中,AI 更常需要回答的是:
“哪些对象之间存在关系?这种关系为何成立?”
于是我们看到了一个清晰的趋势:RAG(检索增强生成)在快速向 GraphRAG(图检索增强生成) 演进。因为向量检索只能回答“和什么相似”,而图检索能回答“和什么相关、为什么相关”。
这个趋势指向一个明确的需求缺口——AI 需要一个专门处理上下文数据的基础设施。
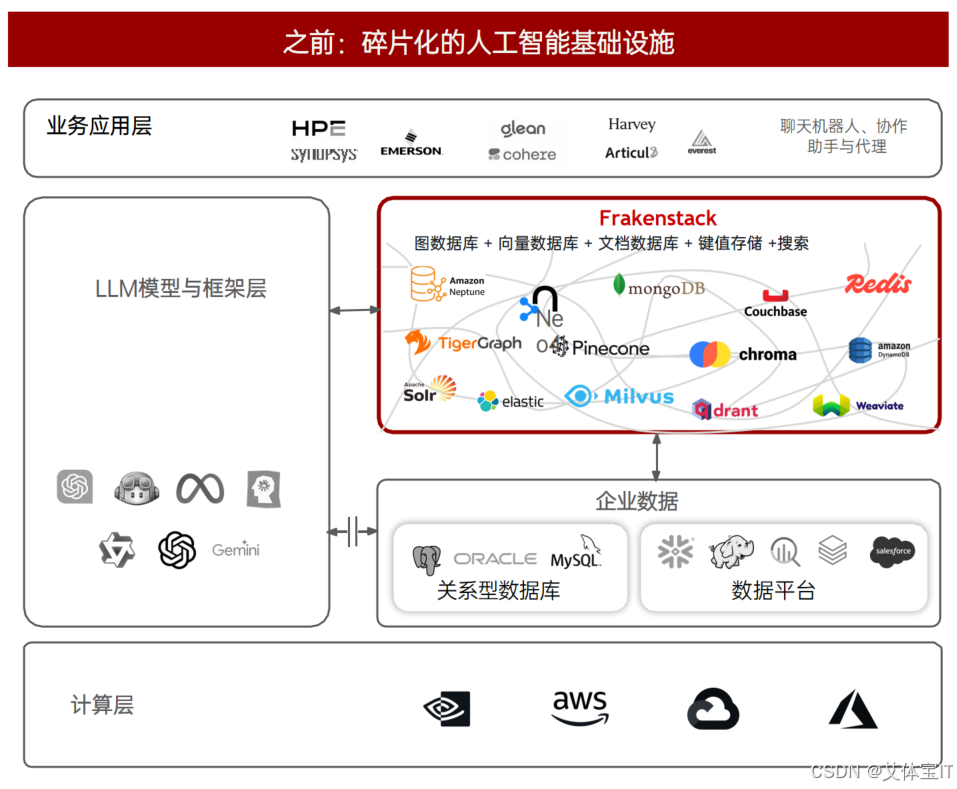
2. Context Data:AI 时代的“数据新范式”
过去十年,我们习惯了三种数据范式:事务型数据(OLTP)、分析型数据(OLAP)、搜索型数据(全文/向量检索)。
但在 AI 应用中,第四种范式正在成为刚需:上下文数据(Context Data)。
上下文数据的特征很鲜明:
- 高度关联:客户、产品、订单、设备、文档之间存在着复杂的多对多关系,这种关系网络很难用单一表结构表达;
- 多模态并存:同一实体的上下文可能包含结构化字段、JSON 文档、向量 embedding、时序轨迹;
- 实时演化:上下文不是静态快照,AI Agent 在执行任务时会持续更新和扩展上下文图;
- 图原生:自然语言中的“谁、和谁、做了什么、在哪、为什么”本身就是一张图。
当一个 AI 应用试图回答“请帮我整理一下上周王经理签过的所有合同里,涉及数据安全条款的部分”时,单纯靠向量搜索或 SQL 查询都会显得吃力。这个问题需要同时跨越人员关系(图)、文档实体(文档)、时间维度(时序)、关键词匹配(全文)——这正是上下文数据平台的典型工作负载。
3. 从 GraphRAG 到上下文数据平台:Arango v4.0 的定位
面对上述挑战,市面上常见的解决思路是“拼盘式架构”:用 PostgreSQL 存关系、用 Elasticsearch 做搜索、用 Neo4j 存图、用 Milvus 做向量、用 Kafka 传实时数据。
这种架构在 Demo 环境可以工作,但一旦进入生产:
- 数据一致性成为噩梦:跨系统同步导致数据版本难以保证一致。;
- 跨系统 Join 性能断崖式下跌:Graph 查询与向量检索之间往往需要额外的数据搬运;
- 上下文构建的延迟让 Agent 决策变慢:AI Agent 在执行任务时需要快速获取上下文,而分布式拼接会增加延迟。
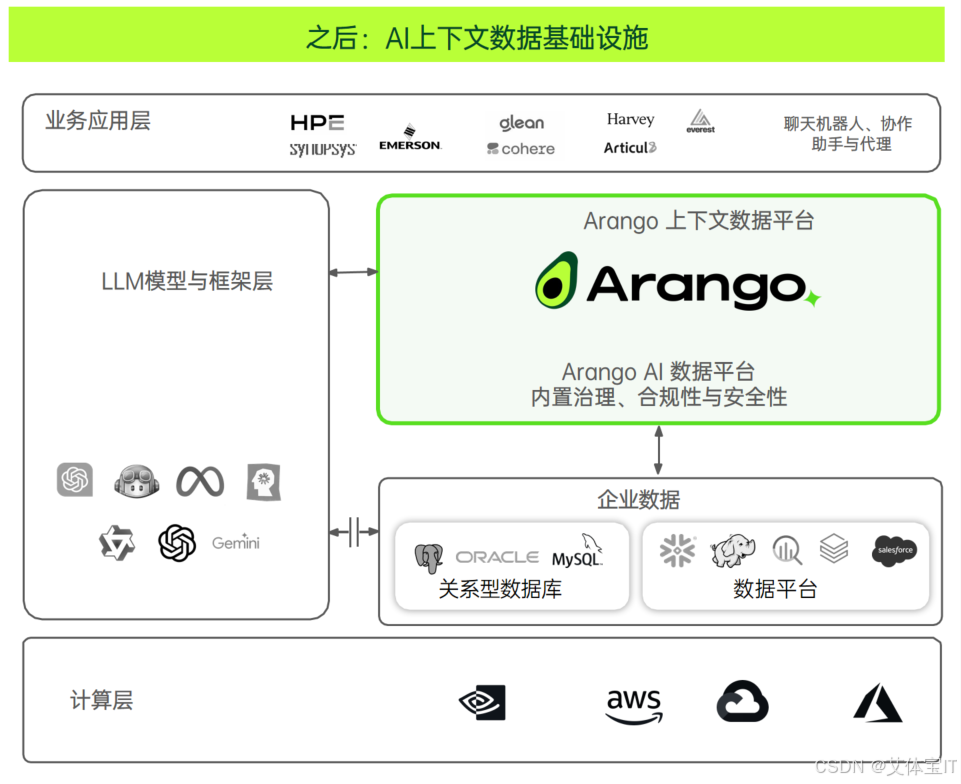
Arango 上下文数据平台 v4.0 要解决的正是这个问题:在一个平台内,原生统一处理多模态上下文数据。
它不是“又一个多模数据库”。Arango v4.0 的架构设计目标很明确——成为 AI 应用的数据底座。这个定位体现在三个核心设计上:
① 原生的图-文档-键值-向量-全文统一引擎
Arango v4.0 的核心仍是其久经考验的图引擎与文档模型的融合,但 v4.0 版本将向量索引和全文检索提升为与图遍历同等的“一等公民”。这意味着开发者可以在一次查询中混合使用:
- 图遍历(查找某人所在部门的所有同事)
- 向量检索(在这些同事的文档库中找语义最接近的段落)
- 过滤条件(只取近 30 天的数据)
② 专为 AI Agent 设计的“上下文窗口构建 API”
AI 应用通常需要构建 **上下文窗口(Context Window)**,作为 LLM 推理的输入。
Arango v4.0 引入了一系列面向 AI 应用的接口,用于自动构建上下文图。例如:
- 以某个实体为中心展开 N 层关系
- 检索关联文档的语义片段
- 按时间或业务规则过滤上下文
这些能力可以将复杂的跨数据模型查询封装为统一接口。
③ 实时可写图的增量上下文更新
在 AI Agent 执行任务过程中,新的实体关系会不断被发现(例如“用户刚提到合同 A 和项目 B 有关联”)。Arango v4.0 支持高频的图增量写入,并能在后续查询中立即生效——这对于需要多轮交互、长记忆的 Agent 应用至关重要。

4. 两个典型应用场景
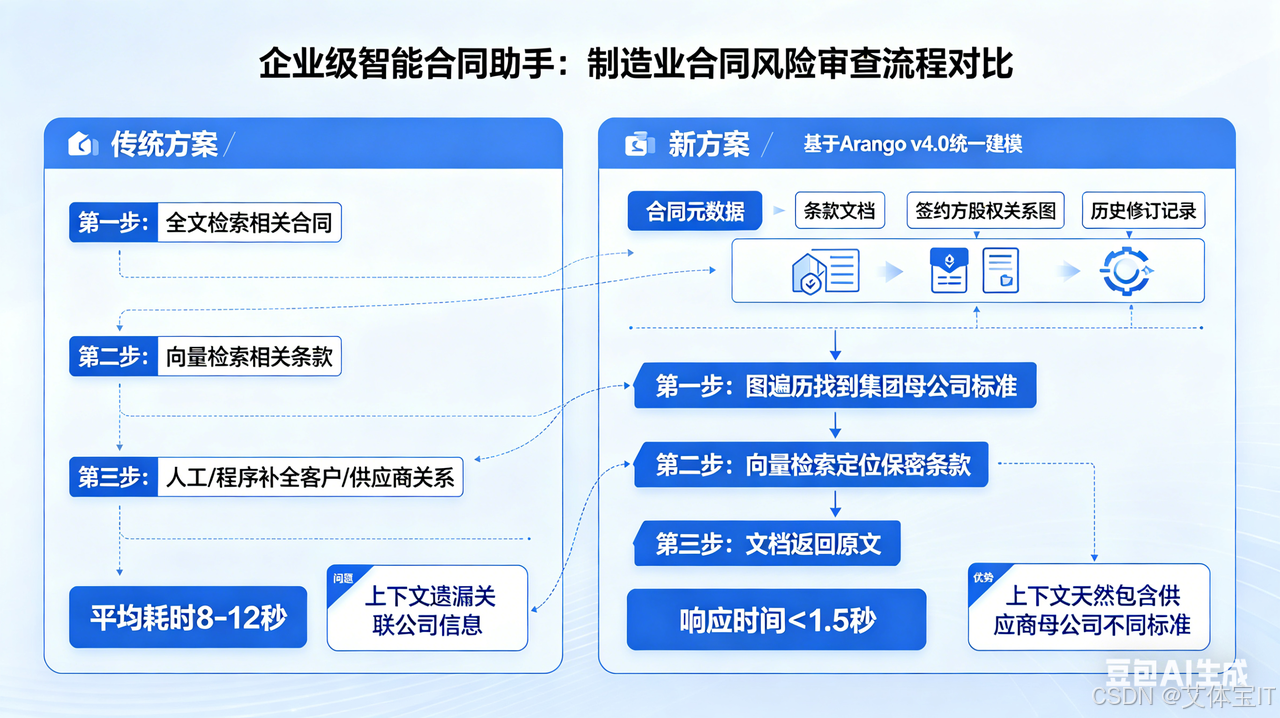
场景一:企业级智能合同助手
一家制造业企业用大模型做合同风险审查。传统方案是先全文检索相关合同,然后向量检索相关条款,再人工或程序补全客户/供应商关系。这个过程平均耗时 8–12 秒,且上下文经常遗漏关联公司信息。
迁移至 Arango v4.0 后,合同的全部元数据、条款文档、签约方的股权关系图、历史修订记录被统一建模。一次典型的“审查本合同中的保密期限是否与集团标准冲突”查询,在图遍历找到集团母公司标准 + 向量检索定位保密条款 + 文档返回原文的组合操作下,响应时间降至 1.5 秒以内。更重要的是,Agent 得到的上下文天然包含了“该供应商的母公司另有不同标准”这样的隐藏关系。
场景二:金融领域的实时事理图谱
某券商需要为研究员提供基于实时新闻的产业链影响分析。一条“某芯片厂商宣布涨价”的新闻,需要触发对下游消费电子、汽车零部件、相关基金持仓的多层关系推理。
在传统方案中,图关系在 Neo4j 中、新闻文本在 ES 中、股价时序在 ClickHouse 中。跨系统分析意味着数秒的延迟和复杂的代码维护。
在 Arango v4.0 中,事理图谱的节点(公司、人物、产品)和边(供应、竞争、持股)与新闻文档、股价快照共处一库。一个“找出受此次涨价影响最大的五家下游公司,并检索它们最近的公告情绪”的查询,通过图遍历 + 向量情感分析 + 文档检索在毫秒级完成。这才是 AI 研究员能够实时对话的基础。
5. 为什么说 Arango 是一种基础设施
回顾计算行业的演进历史:
- 应用服务器出现之前,开发者需要自己处理 socket 和线程;
- OLAP 数据库出现之前,分析师需要手工用脚本跑报表;
- 向量数据库出现之前,AI 应用只能把 embedding 硬塞进关系表。
Arango 上下文数据平台 v4.0 成为的是 AI 时代“上下文数据处理”的基础设施层。 它抽象掉了底层多模态数据协同的复杂性,让上层的 AI 应用和 Agent 专注于业务逻辑,而非数据拼接。
对于企业而言,选择 Arango v4.0 作为 AI 数据底座,意味着两件事:
- 简化 AI 数据架构:它并不是要替换您现有的交易数据库或数仓,而是在这些基础之上,构建一个专用的上下文数据层。Arango v4.0 将分散在图库、文档库、向量库中用于 AI 推理的那部分数据提取并统一建模,让大模型能够在一个地方、用一种查询语言看懂所有关联——而不是让 AI 应用去四处拼接数据。
- 面向未来:你的 AI 应用从第一天起就构建在可扩展、可演进的上下文数据模型上。数据可以留在原地,但“理解数据的智能”汇聚于此。
6.写在最后:AI 的竞争,正在从模型层下沉到数据层
2026 年的共识是:模型能力正在商品化,真正的壁垒在于企业特有的上下文数据。谁能够更高效地采集、关联、检索和演化这些上下文数据,谁的 AI 应用就能更懂业务、更快响应、更低成本地迭代。
这不是要企业扔掉现有的 PostgreSQL、Elasticsearch 或 Neo4j。恰恰相反,Arango v4.0 是架设在它们之上的 “AI 上下文语义层” 。它专门负责回答 AI 提出的复杂关联性问题,而高频业务写入和报表分析仍然交给最擅长它们的传统数据库。
你们团队在构建 AI 应用时,上下文数据的瓶颈出现在哪个环节?欢迎留言交流。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 10
10 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)