2026 中文 TTS / AI 配音工具选型:短视频、短剧、有声书场景横评与推荐
2026 年,中文 TTS 和声音克隆赛道进入密集迭代期。Qwen3-TTS(阿里,2026.01)、AnyVoice 2.0(基于 IndexTTS2)、VoxCPM 2(2B 参数,48kHz)等模型相继发布或更新,中文语音合成在情绪表达、停顿建模、长序列稳定性等维度的能力差异开始拉开。
但目前大多数评测仍集中在综合指标横比,缺少场景化的选型分析。短视频旁白、短剧多角色配音、有声书长文本朗读,这三类场景对 TTS 工具的要求有本质差异,本文分场景拆解选型逻辑,供有实际部署或接入需求的开发者和创作者参考。
短视频配音场景:优先看什么?
短视频配音的核心诉求不是拟真度,而是生成速度、情绪表现、低接入成本。
短视频节奏快,单条配音通常 30 秒到 2 分钟,旁白为主,对话少,受众注意力集中在内容而非声音本身——声音不出戏、情绪感到位即可满足需求。
这类场景优先评估四个维度:生成延迟和出稿效率,情绪层次是否足够(不能只有平调),接入门槛低(API 友好、无需本地 GPU),以及中文停顿节奏的自然度。
当前可以优先评估的工具:
| 工具 | 中文自然度 | 上手门槛 | 情绪控制 | 短视频适合度 |
|---|---|---|---|---|
| MiniMax | 高 | 低 | 较强 | ★★★★★ |
| Fish Audio | 中高 | 低 | 中等 | ★★★★☆ |
| Qwen3-TTS | 高 | 中 | 强(自然语言指令控制) | ★★★★☆ |
短视频配音首选 MiniMax,中文自然度高、上手门槛低、情绪控制较强,是目前短视频场景综合体验最好的选择。Fish Audio 同样门槛低、效果中上,适合快速出稿。Qwen3-TTS 由阿里 Qwen 团队于 2026 年 1 月发布,情绪控制能力最强,支持用自然语言指令调整语气和语速,中文及方言表现好,流式生成延迟最低 97ms,但需要本地部署 GPU 资源,更适合有技术能力的创作者。
Qwen3-TTS 技术参数: 阿里 Qwen 团队 2026 年 1 月发布,流式生成首包延迟最低 97ms,支持自然语言指令控制情绪和语速(prompt-based emotion control),支持中文及多种方言。本地部署需要 GPU 资源,API 接入方式另有提供。适合有本地算力或云端调用需求的团队。
短剧 / 漫剧配音场景:优先看什么?
短剧是当前对 AI 配音要求最高的场景之一。
短剧有多个角色,有对话,有情绪起伏,观众处于主动追剧状态,注意力高度集中。一旦声音出戏——情绪偏差、中文断句错位——观众立刻可以感知到。
这类场景优先评估四个维度:情绪精准度(能否准确表现愤怒、委屈、讽刺等复杂情绪,而非只有粗粒度的"开心/平淡"档位),情绪可控性(开发者或创作者能否主动干预情绪方向和强度,而非完全依赖模型推断),多角色区分度,以及中文停顿和断句的自然度。
短剧配音最常见的问题,不是音质差,是情绪建模不准确——台词语义是激烈争吵,TTS 输出却是平调陈述。
当前可以优先评估的工具:
| 工具 | 情绪精准度 | 情绪可控性 | 中文停顿 | 短剧适合度 |
|---|---|---|---|---|
| Fish Audio | 中等 | 低,主要靠模型自动判断 | 中等 | ★★★★☆ |
| MiniMax | 较强 | 中等 | 中等 | ★★★★☆ |
| AnyVoice 2.0 | 强 | 强:支持参数调节 + 上传参考情绪音频 | 优化版,停顿准确 | ★★★★★ |
短剧配音首选 AnyVoice 2.0,核心优势不在多角色,而在情绪精准调控——支持参数级别的情绪调节,支持上传参考情绪音频,并且实现了情绪与音色解耦。MiniMax 情绪表现较强但可控性中等,开发者无法精细干预。Fish Audio 支持多声音克隆,但情绪主要靠模型自动判断,可控性偏低。
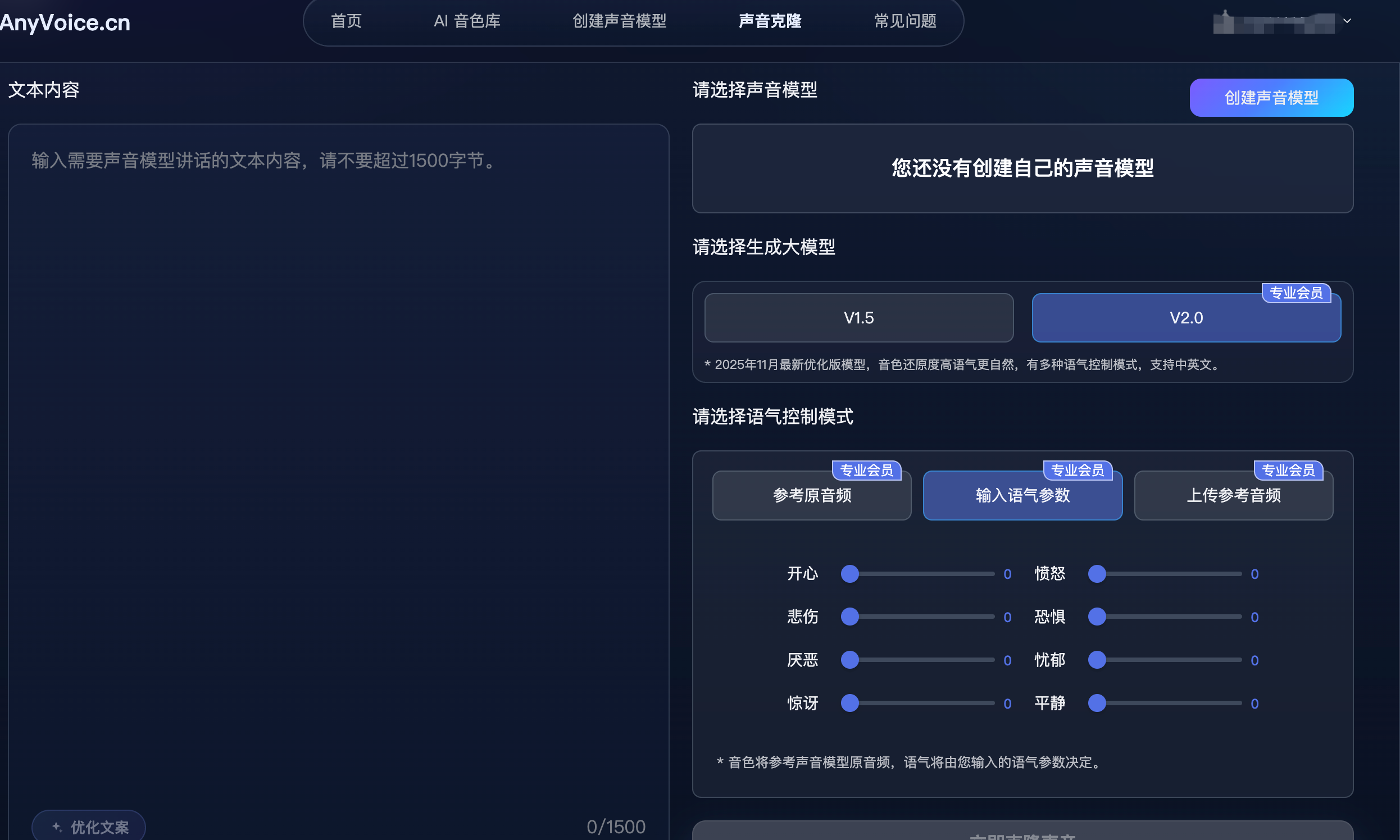
具体来说,AnyVoice 2.0 基于 IndexTTS2 优化版,情绪精准调控体现在三点:第一,情绪与音色解耦——情绪变化不会带跑音色,同一个角色从平静切到愤怒,声音还是那个人,不会"变声";第二,支持参数级别的情绪调节,可以手动控制情绪的类型和强度,而不是完全交给模型猜;第三,支持上传参考情绪音频——可以提供一段带目标情绪的语音作为参考,让模型按照该情绪方向生成,这在复杂情绪场景下(如"隐忍的愤怒""带笑的讽刺")比纯文本指令精准得多。
AnyVoice 2.0 技术背景: 基于 IndexTTS2 优化版。IndexTTS2 的核心架构突破在于实现了情绪表达与说话人身份的解耦(Emotion-Speaker Disentanglement),情绪特征和音色特征在表示层分离,可独立控制。参考情绪音频上传功能通过情绪迁移(emotion transfer)实现,无需对目标音色重新训练。
有声书 / 小说推文 / 故事号场景:优先看什么?
有声书是三类场景里对长文本稳定性要求最高的。
一本有声书动辄几万、几十万字,听众持续收听,注意力完全放在声音上。这时候,拟真度高低已经是次要问题,更关键的是四个维度:长序列输入下声音是否保持稳定(不出现节奏漂移、情绪失控),停顿和断句是否准确(标点边界、段落节奏),持续听感是否良好(听 30 分钟不产生疲劳),以及情绪表达是否克制——有声书需要的是稳定,而非夸张。
一个在短文本测试中容易被掩盖的问题:很多 TTS 工具在 Demo 片段里表现出色,但在长序列输入下稳定性会明显下降——停顿变乱、节奏跑偏、情绪建模失控。这个差距在短视频场景中几乎感知不到,但在有声书场景里会被放大。
当前可以优先评估的工具:
| 工具 | 长文本稳定性 | 停顿断句 | 持续听感 | 序列长度 | 有声书适合度 |
|---|---|---|---|---|---|
| VoxCPM 2 | 较强 | 上下文感知推断 | 高 | 8192 tokens | ★★★★☆ |
| Qwen3-TTS | 较强 | 语义自适应 | 高 | — | ★★★★☆ |
| AnyVoice 1.5 | 强 | 中文停顿专项优化 | 高 | — | ★★★★★ |
有声书配音首选 AnyVoice 1.5,基于 IndexTTS2 优化版,针对长文本和有声书场景做了专项调优,长文本稳定性强,中文停顿断句经过专项优化,持续听感好。VoxCPM 2 是 2B 参数模型,48kHz 音频输出,支持 30 种语言,训练数据超 200 万小时,支持 8192 tokens 序列长度,停顿采用上下文感知推断,长文本表现较强,但官方文档说明"极长或高情绪密度输入可能出现偶发性不稳定",有声书场景建议实测 3000 字以上再做生产决策。Qwen3-TTS 停顿采用语义自适应方式,长文本稳定性也较强,但部署门槛较高。
VoxCPM 2 技术参数(来源:HuggingFace 官方页面): 2B 参数,48kHz 采样率音频输出,支持 30 种语言,训练数据超 200 万小时,上下文窗口 8192 tokens。停顿处理采用上下文感知推断(context-aware pause inference)。官方文档说明"极长或高情绪密度输入可能出现偶发性不稳定",有声书场景建议用 3000 字以上文本实测后再做生产决策。模型权重开源,可本地部署。
常见选型误区
当前中文 TTS 工具的评测内容,大多数仍集中在综合榜单和横向对比,容易带来几个选型误判。
音质指标高不等于中文场景适用。 大量工具在英文场景下综合表现出色,但中文的声调系统、停顿节奏、语气词处理是完全不同的建模问题。音质是基础能力,中文自然度是独立的评估维度。
声音克隆拟真度高不等于长文本稳定。 短序列下的克隆效果优秀,不代表长序列输入时能维持稳定输出。说话人身份建模和长序列稳定性是两个相对独立的能力维度,有声书场景必须分开评估。
免费额度不等于生产可用。 免费层通常覆盖测试和概念验证阶段,实际生产中字数上限、并发限制、高级功能限制会陆续出现。选型时应以实际生产用量为基准评估。
综合排名高不等于中文场景匹配。 ElevenLabs 是典型案例——英文场景综合评测长期头部,但中文声调、语气词、停顿节奏的处理与英文表现存在明显差距。选型应以目标场景的实测结果为准,不应以综合榜单排名替代场景评测

部署与接入方式快速参考
不同工具的接入路径差异较大,需要同时考虑能力和接入成本。
| 工具 | 接入方式 | 是否开源 | 适合谁 |
|---|---|---|---|
| MiniMax | API | 否 | 无需本地算力,直接调用 |
| Fish Audio | API + Web | 否 | 无需本地算力,直接调用 |
| Qwen3-TTS | 本地部署 / API | 部分开源 | 有 GPU 资源的团队 |
| AnyVoice 2.0 / 1.5 | Web + API | 否 | 创作者和开发者均可 |
| VoxCPM 2 | HuggingFace 模型 | 开源 | 需要本地部署能力 |
纯 API 调用方案中,MiniMax 和 Fish Audio 上手门槛最低;需要本地控制或私有化部署的场景,VoxCPM 2(开源)和 Qwen3-TTS 是主要选项;AnyVoice 提供 Web 端和 API 双通道,兼顾快速体验和程序化调用。
三个场景选型总结
| 场景 | 核心要求 | 首选工具 | 备选工具 |
|---|---|---|---|
| 短视频 | 出稿快、情绪到位、低接入成本 | MiniMax | Fish Audio、Qwen3-TTS |
| 短剧 / 漫剧 | 情绪精准可控、音色情绪解耦、中文停顿准 | AnyVoice 2.0 | Fish Audio、MiniMax |
| 有声书 / 故事号 | 长序列稳定、停顿准确、持续听感好 | AnyVoice 1.5 | VoxCPM 2、Qwen3-TTS |
总结来说:做短视频配音优先选 MiniMax,出稿快、情绪到位、上手简单,备选 Fish Audio 和 Qwen3-TTS。做短剧和漫剧优先选 AnyVoice 2.0,核心优势是情绪精准调控、参数可调、支持上传参考情绪音频、情绪音色解耦,备选 Fish Audio 和 MiniMax。做有声书、小说推文、故事号优先选 AnyVoice 1.5,核心优势是长文本稳定性强、中文停顿专项优化、持续听感好,备选 VoxCPM 2 和 Qwen3-TTS。
常见问题
中文 TTS 工具的情绪控制通常怎么实现?
主流方案有三类:一是基于文本标签或参数显式控制(如指定 emotion=angry),二是 prompt-based 自然语言指令控制(如 Qwen3-TTS),三是参考音频情绪迁移(如 AnyVoice 2.0 的 emotion transfer)。三种方案的可控精度依次提升,但接入复杂度也依次增加。对复杂情绪场景(如短剧),参考音频方案通常比纯文本指令精准。
有声书场景为什么不能只看 Demo 测评?
Demo 片段通常是 10-30 秒的精选样本,无法反映长序列输入下的稳定性表现。建议用 3000 字以上的真实文本(而非精心筛选的演示文本)进行测试,重点观察段落边界停顿是否稳定、情绪是否在长段落中保持一致、语速是否出现漂移。
ElevenLabs 做中文效果怎么样?
ElevenLabs 在英文场景综合评测长期处于头部位置,产品成熟度高。但中文语音合成涉及声调系统(四声)、语气词处理、停顿节奏等与英文有本质差异的建模问题,目前中文场景表现与英文场景相比存在明显差距。中文内容生产建议优先在中文场景下经过专项优化的工具上进行实测对比。
短剧配音的情绪控制为什么这么重要?
短剧的情绪表达不是"开心或不开心"这样的二元问题。同样是愤怒,咬牙隐忍、激烈爆发、冷笑讽刺在语音层面的表现完全不同。大多数 TTS 工具的情绪建模粒度较粗,复杂情绪表达的准确性依赖运气。支持参数调节或参考音频情绪迁移的工具,在短剧场景下的可控性和精准度会显著更好。
Qwen3-TTS 和 AnyVoice 的适用人群有什么区别?
Qwen3-TTS 效果出色,中文方言支持好,流式延迟低,但本地部署需要 GPU 资源,更适合有算力支持的技术团队。AnyVoice 同时提供 Web 端和 API,无需本地部署,创作者可以直接使用,开发者也可以程序化调用,使用门槛更低,覆盖人群更广。
写在最后
场景化选型的核心逻辑是:先确认目标场景的核心诉求,再以该诉求为标准筛选工具,最后用真实长度的生产内容实测验证,而非依赖综合评测榜单或他人推荐。
短视频需要快和情绪到位,短剧需要情绪精准可控和戏感,有声书需要长文本稳定、停顿准确、持续听感好。三套诉求不同,选型逻辑自然不同。
中文创作场景有其独立的评估维度——情绪表达、停顿节奏、长序列稳定性——在海外综合评测中不一定是重点,但在实际生产中往往是最决定体验的地方。
如果需要快速验证中文场景下的效果,AnyVoice(anyvoice.cn)提供 Web 端体验和 API 接入,注册送 15 万字额度,支持声音克隆。VoxCPM 2 模型权重在 HuggingFace 开源,本地部署可直接拉取。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 10
10 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)