AI 应用的前端性能优化:流式渲染、Token 节约与缓存策略
AI 应用的前端性能优化,核心就是三板斧流式渲染——让用户感觉快▸streamTextuseChat实现开箱即用的流式▸合并更新减少重渲染▸Markdown 增量解析 + 代码块延迟高亮▸实现中断生成Token 节约——让老板省心▸Prompt 压缩:System Prompt 精简到 < 200 token▸滑动窗口:只保留最近 N 轮 + 历史摘要▸模型路由:简单问题走 mini 模型,成本降
点击上方 前端Q,关注公众号
回复加群,加入前端Q技术交流群
上一篇我们用 RAG 给 AI 产品接上了知识库——现在 Agent 能查资料、能回答、能引用来源了。
但上线后你会发现一个扎心的现实:用户觉得太慢了。
点击发送后等 5 秒才开始出字,一个复杂问题烧掉几万 token,月底账单看得心惊肉跳。更要命的是,同样的问题用户问了 10 遍,后端就老老实实调了 10 次 LLM——每次都花钱、每次都慢。
传统前端性能优化讲的是首屏渲染、代码分割、CDN 缓存。AI 应用的性能优化有自己的一套逻辑——快不快看流式、省不省看 Token、值不值看缓存。
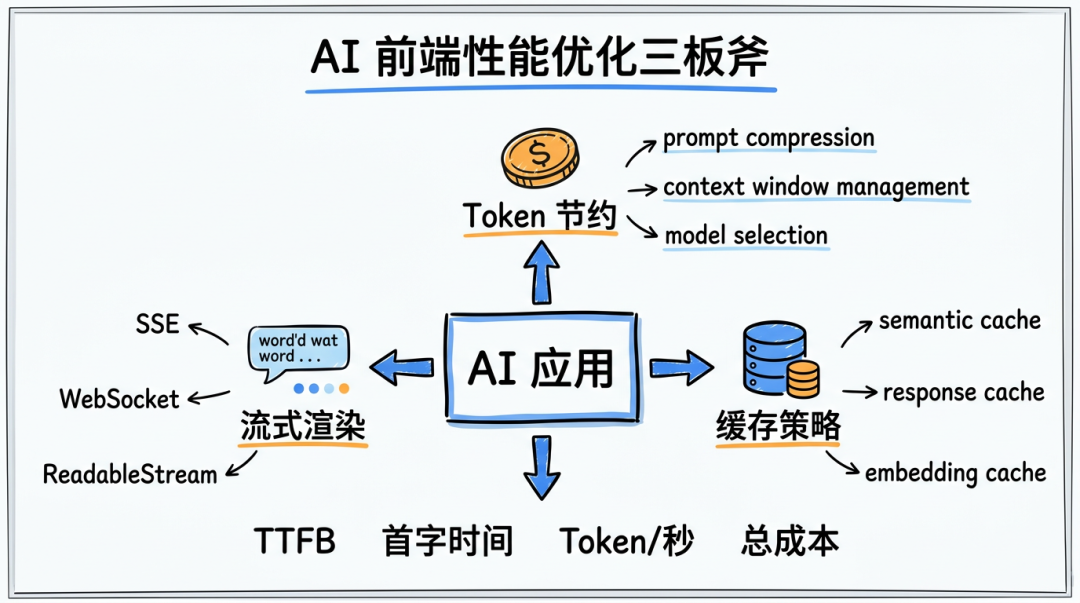
流式渲染:让用户"感觉"快
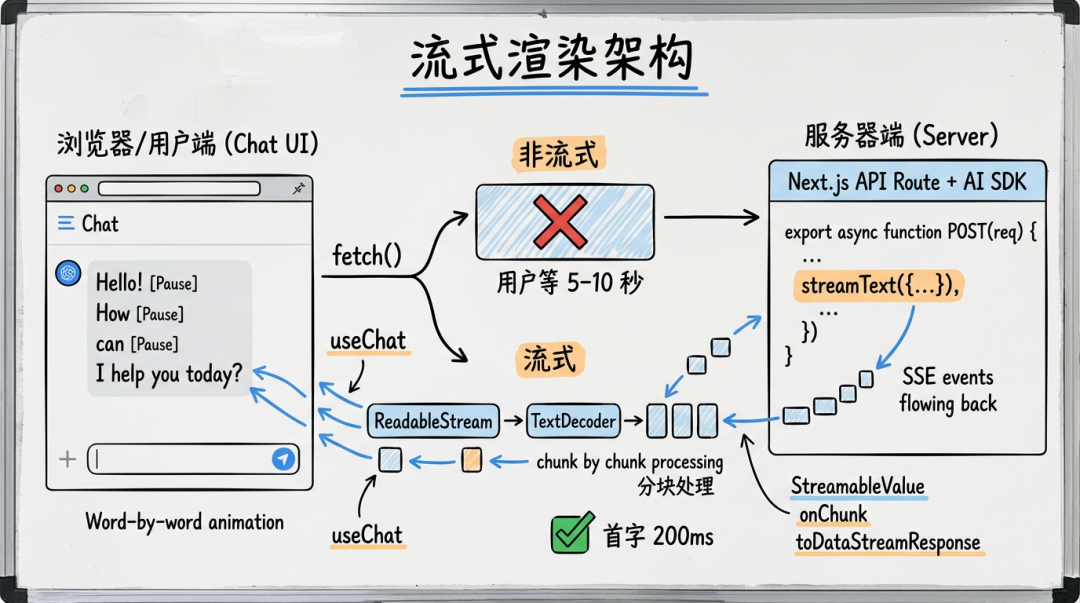
AI 应用最影响体验的不是总耗时,而是首字时间(Time to First Token)——用户点击发送后多久看到第一个字。
非流式请求:用户等 5~10 秒,然后"啪"一下全出来。流式请求:200ms 就开始出字,一个一个蹦出来,总时间可能一样长,但用户感知完全不同。
这跟前端的 SSR 流式渲染是一个道理——不等数据全齐了再渲染,边到边渲染。
▎基础:用 AI SDK 实现流式
Vercel AI SDK 把流式封装得非常简洁——后端用 streamText,前端用 useChat,开箱即用。
后端 API Route:
// app/api/chat/route.ts
import { streamText } from "ai";
import { openai } from "@ai-sdk/openai";
export async function POST(req: Request) {
const { messages } = await req.json();
const result = streamText({
model: openai("gpt-4o"),
messages,
});
return result.toDataStreamResponse();
}
前端组件:
"use client";
import { useChat } from "ai/react";
export default function Chat() {
const { messages, input, handleInputChange, handleSubmit, isLoading } =
useChat();
return (
<div>
{messages.map((msg) => (
<div key={msg.id}>{msg.content}</div>
))}
<form onSubmit={handleSubmit}>
<input value={input} onChange={handleInputChange} />
<button type="submit" disabled={isLoading}>发送</button>
</form>
</div>
);
}
useChat 内部做了这些:
- 发起 POST 请求到
/api/chat - 拿到
ReadableStream响应 - 用
TextDecoder逐 chunk 解析 SSE 事件 - 实时更新
messages状态,触发 React 重渲染
▎底层:手动处理 SSE 流
如果不用 AI SDK,自己处理流式也不复杂。核心是 ReadableStream + TextDecoder:
async function streamChat(messages: Message[]) {
const response = await fetch("/api/chat", {
method: "POST",
headers: { "Content-Type": "application/json" },
body: JSON.stringify({ messages }),
});
const reader = response.body!.getReader();
const decoder = new TextDecoder();
let buffer = "";
while (true) {
const { done, value } = await reader.read();
if (done) break;
buffer += decoder.decode(value, { stream: true });
const lines = buffer.split("\n");
buffer = lines.pop() || "";
for (const line of lines) {
if (!line.startsWith("data: ")) continue;
const data = line.slice(6);
if (data === "[DONE]") return;
const parsed = JSON.parse(data);
const token = parsed.choices?.[0]?.delta?.content;
if (token) {
onToken(token); // 逐 token 回调,更新 UI
}
}
}
}
▎流式渲染的 3 个优化技巧
技巧 1:防抖更新,减少重渲染。
每个 token 都触发 setState 的话,一秒可能更新 30~50 次。用 requestAnimationFrame 合并更新:
let pendingText = "";
let rafId: number | null = null;
function onToken(token: string) {
pendingText += token;
if (!rafId) {
rafId = requestAnimationFrame(() => {
setText((prev) => prev + pendingText);
pendingText = "";
rafId = null;
});
}
}
技巧 2:Markdown 增量解析。
AI 返回的内容通常是 Markdown 格式。如果每次都重新解析整个字符串,性能很差。推荐用增量解析:
import { marked } from "marked";
const renderedRef = useRef("");
const rawRef = useRef("");
function onToken(token: string) {
rawRef.current += token;
// 只在段落结束时重新解析,避免频繁 DOM 更新
if (token.includes("\n") || token.includes("E6DB74">```")) {
renderedRef.current = marked.parse(rawRef.current);
forceUpdate();
}
}
技巧 3:代码块延迟高亮。
代码块在流式过程中是不完整的——等到 \\\` 闭合后再做语法高亮,否则 Prism.js / highlight.js 会反复解析半成品代码:
function renderContent(content: string) {
const codeBlockRegex = /``E6DB74">`(\w+)?\n([\s\S]*?)```/g;
return content.replace(codeBlockRegex, (match, lang, code) => {
// 只有完整的代码块才高亮
return highlightCode(code, lang);
});
// 未闭合的代码块保持原始文本
}
▎中断生成:AbortController
用户不想等了,点「停止生成」——前端要能取消正在进行的流式请求:
const abortControllerRef = useRef<AbortController | null>(null);
async function handleSubmit() {
abortControllerRef.current = new AbortController();
const response = await fetch("/api/chat", {
method: "POST",
body: JSON.stringify({ messages }),
signal: abortControllerRef.current.signal,
});
// 处理流式响应...
}
function handleStop() {
abortControllerRef.current?.abort();
}
AI SDK 的 useChat 内置了 stop() 方法,更简洁:
const { messages, stop, isLoading } = useChat();
// 直接调用
<button onClick={stop} disabled={!isLoading}>停止生成</button>
Token 节约:花更少的钱办更多的事
LLM 的计费方式是按 token 收费——输入 token + 输出 token。一个中型 AI 应用,日均几万次请求,Token 成本很容易失控。
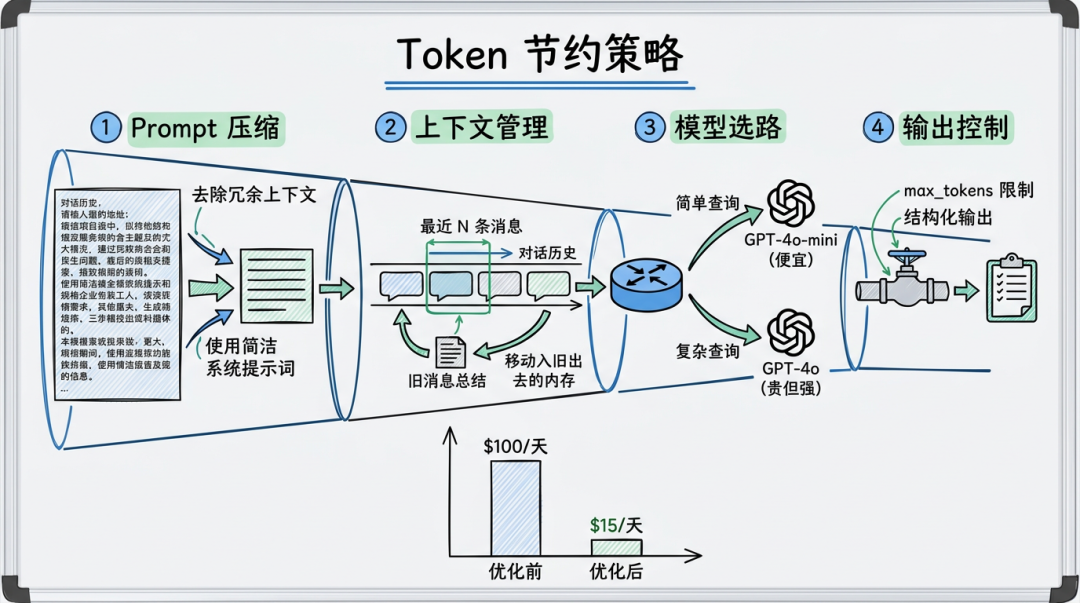
▎策略 1:Prompt 压缩
System Prompt 是每次请求都要发的——它越长,每次请求的基础成本越高。
// ❌ 冗余的 System Prompt(约 500 token)
const systemPrompt = `
你是一个非常专业的前端技术助手。你的目标是帮助用户解决各种前端开发中遇到的问题。
你应该用通俗易懂的语言来解释技术概念,同时提供可运行的代码示例。
在回答问题时,你需要考虑到用户可能是初级开发者,所以要避免使用过于专业的术语。
如果你不确定答案,请诚实地告诉用户,而不是编造一个可能错误的答案。
你应该始终保持友好和耐心的态度...(省略 300 字)
`;
// ✅ 精简的 System Prompt(约 80 token)
const systemPrompt = `前端技术助手。通俗解释,附可运行代码。不确定时如实说明。`;
效果一样,但每次请求省了 400+ token。假设日均 10 万次请求,一天就省了 4000 万 token。
▎策略 2:对话历史滑动窗口
多轮对话中,完整历史越来越长。只保留最近 N 轮 + 早期对话的摘要:
function trimMessages(messages: Message[], maxTokens: number = 4000) {
let totalTokens = 0;
const trimmed: Message[] = [];
// 从最新消息往前保留
for (let i = messages.length - 1; i >= 0; i--) {
const msgTokens = estimateTokens(messages[i].content);
if (totalTokens + msgTokens > maxTokens) break;
trimmed.unshift(messages[i]);
totalTokens += msgTokens;
}
// 如果有被截断的历史,加一条摘要
if (trimmed.length < messages.length) {
const droppedMessages = messages.slice(0, messages.length - trimmed.length);
const summary = await summarizeMessages(droppedMessages);
trimmed.unshift({
role: "system",
content: E6DB74">`之前的对话摘要:${summary}`,
});
}
return trimmed;
}
function estimateTokens(text: string): number {
// 粗略估算:中文 1 字 ≈ 2 token,英文 1 词 ≈ 1.3 token
return Math.ceil(text.length * 1.5);
}
▎策略 3:模型路由——简单问题用便宜模型
不是所有问题都需要 GPT-4o。"今天星期几"用 GPT-4o-mini 就够了。
import { openai } from "@ai-sdk/openai";
import { generateText } from "ai";
async function routeToModel(query: string) {
// 先用便宜模型判断复杂度
const { text: complexity } = await generateText({
model: openai("gpt-4o-mini"),
prompt: `判断以下问题的复杂度,回答 simple 或 complex:\n${query}`,
maxTokens: 10,
});
const model = complexity.trim() === "simple"
? openai("gpt-4o-mini") // $0.15 / 1M input tokens
: openai("gpt-4o"); // $2.50 / 1M input tokens
return model;
}
实际效果:70% 的请求走 mini 模型,成本直降 80%。
▎策略 4:控制输出长度
用户问"React 是什么",不需要输出 2000 字的长文。
const result = streamText({
model: openai("gpt-4o"),
messages,
maxTokens: 500, // 限制输出长度
});
结合结构化输出,让 LLM 按固定格式回答,避免"废话":
import { z } from "zod";
import { generateObject } from "ai";
const { object } = await generateObject({
model: openai("gpt-4o"),
schema: z.object({
answer: z.string().describe("简洁的回答,不超过 200 字"),
codeExample: z.string().optional().describe("代码示例(如有必要)"),
references: z.array(z.string()).optional().describe("参考资料链接"),
}),
prompt: userQuestion,
});
▎成本对照表
| 模型 | 输入价格(每百万 token) | 输出价格(每百万 token) | 适合场景 |
|---|---|---|---|
| GPT-4o | $2.50 | $10.00 | 复杂推理、代码生成 |
| GPT-4o-mini | $0.15 | $0.60 | 简单问答、分类、路由 |
| Claude 3.5 Sonnet | $3.00 | $15.00 | 长文本、复杂分析 |
| Claude 3.5 Haiku | $0.80 | $4.00 | 快速响应、轻量任务 |
经验法则:先在 mini 上跑,效果不够再切大模型。别一上来就用最贵的。
缓存策略:同样的问题不要重复花钱
AI 应用的一个特点:很多用户会问类似的问题。 "React hooks 怎么用"和"如何使用 React hooks"本质是同一个问题——但没有缓存的话,每次都要调 LLM。
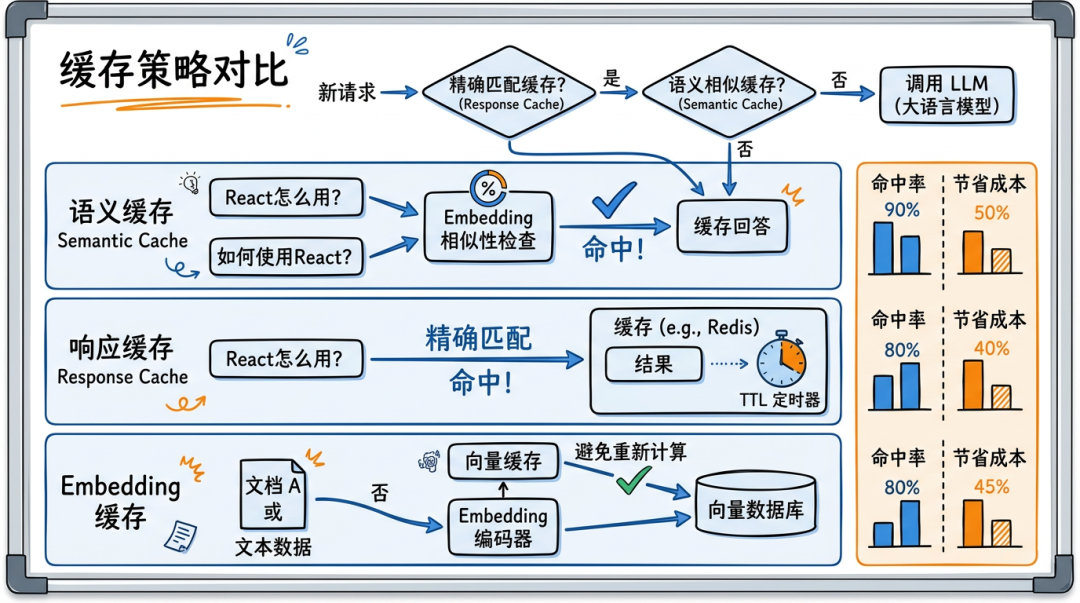
▎第一层:精确匹配缓存
最简单——完全相同的输入直接返回缓存结果:
import { Redis } from "ioredis";
import { createHash } from "crypto";
const redis = new Redis();
function getCacheKey(messages: Message[]): string {
const content = JSON.stringify(messages);
return `ai:chat:${createHash("md5").update(content).digest("hex")}`;
}
async function cachedChat(messages: Message[]) {
const key = getCacheKey(messages);
// 查缓存
const cached = await redis.get(key);
if (cached) {
console.log("Cache hit!");
return JSON.parse(cached);
}
// 没命中,调 LLM
const result = await generateText({
model: openai("gpt-4o"),
messages,
});
// 写缓存,TTL 1 小时
await redis.setex(key, 3600, JSON.stringify(result.text));
return result.text;
}
局限:必须完全一样才命中。"React hooks 怎么用"和"react hooks 怎么用"(大小写不同)就是两个 key。
▎第二层:语义缓存(Semantic Cache)
用 Embedding 相似度匹配——"React hooks 怎么用"和"如何使用 React hooks"能命中同一条缓存。
import { OpenAIEmbeddings } from "@langchain/openai";
import { MemoryVectorStore } from "langchain/vectorstores/memory";
const embeddings = new OpenAIEmbeddings({
modelName: "text-embedding-3-small",
});
interface CacheEntry {
question: string;
answer: string;
embedding: number[];
}
const cacheStore = await MemoryVectorStore.fromTexts([], [], embeddings);
const cacheMap = new Map<string, string>();
async function semanticCachedChat(question: string) {
// 1. 语义检索:找相似问题
const results = await cacheStore.similaritySearchWithScore(question, 1);
if (results.length > 0) {
const [doc, score] = results[0];
// 相似度 > 0.92 认为是同一个问题
if (score > 0.92) {
console.log(`Semantic cache hit! (similarity: ${score.toFixed(3)})`);
return cacheMap.get(doc.pageContent);
}
}
// 2. 没命中,调 LLM
const { text: answer } = await generateText({
model: openai("gpt-4o"),
prompt: question,
});
// 3. 写入缓存
await cacheStore.addDocuments([
{ pageContent: question, metadata: {} },
]);
cacheMap.set(question, answer);
return answer;
}
语义缓存的命中率远高于精确缓存——实际测试中,语义缓存能把命中率从 15% 提升到 60%+。
▎第三层:Embedding 缓存
RAG 场景中,每次用户提问都要把问题转成 Embedding 向量。这个 Embedding 调用虽然便宜,但积少成多也是成本。
const embeddingCache = new Map<string, number[]>();
async function cachedEmbed(text: string): Promise<number[]> {
const key = text.trim().toLowerCase();
if (embeddingCache.has(key)) {
return embeddingCache.get(key)!;
}
const result = await embeddings.embedQuery(text);
embeddingCache.set(key, result);
return result;
}
▎缓存失效策略
| 策略 | 做法 | 适合场景 |
|---|---|---|
| TTL | 固定时间过期(如 1 小时) | 信息时效性不强 |
| LRU | 淘汰最久未使用的 | 缓存空间有限 |
| 知识库更新时清除 | 文档变更后清缓存 | RAG 场景 |
| 版本标记 | 模型/Prompt 变了就失效 | 迭代频繁 |
UX 优化:让 AI 应用"像人一样"
技术优化之外,UX 设计对 AI 应用的体验影响巨大。
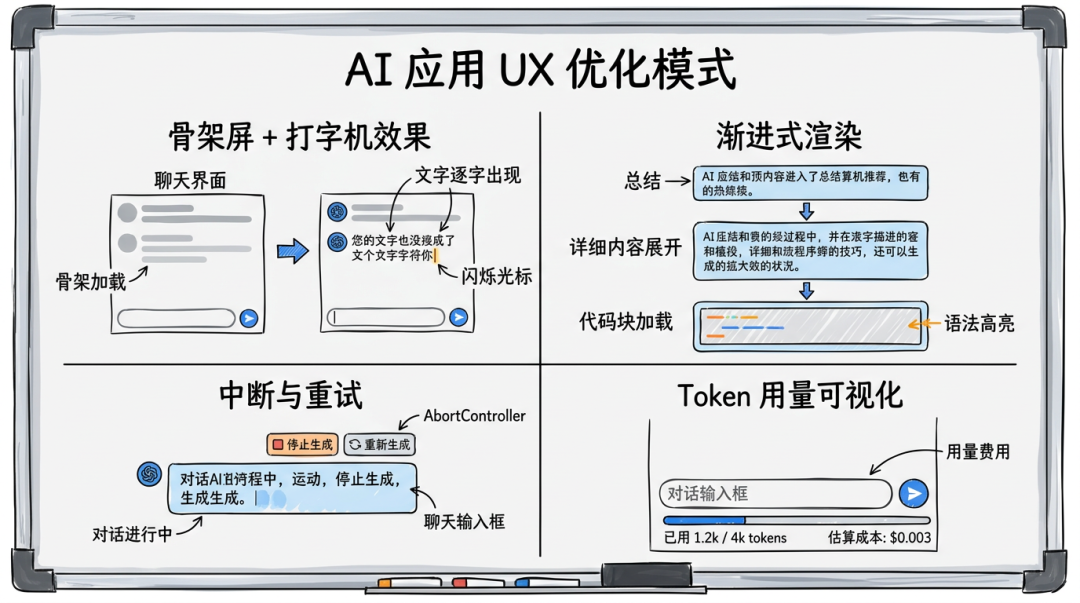
▎骨架屏 + 打字机效果
用户点击发送后,立即展示占位 UI,避免"空白等待":
function AIMessage({ content, isStreaming }: { content: string; isStreaming: boolean }) {
if (!content && isStreaming) {
return (
<div className="flex items-center gap-2 text-gray-400">
<span className="animate-pulse">●</span>
<span className="animate-pulse delay-100">●</span>
<span className="animate-pulse delay-200">●</span>
<span className="ml-2">思考中...</span>
</div>
);
}
return (
<div className="prose">
<ReactMarkdown>{content}</ReactMarkdown>
{isStreaming && <span className="animate-blink">▎</span>}
</div>
);
}
▎重试与反馈
AI 的回答不一定对——给用户"重新生成"和"反馈"的能力:
function MessageActions({ messageId, onRegenerate }: Props) {
const [feedback, setFeedback] = useState<"up" | "down" | null>(null);
return (
<div className="flex gap-2 mt-2 text-gray-400">
<button
onClick={onRegenerate}
className="hover:text-blue-500"
title="重新生成"
>
🔄
</button>
<button
onClick={() => {
setFeedback("up");
trackFeedback(messageId, "positive");
}}
className={feedback === "up" ? "text-green-500" : "hover:text-green-500"}
>
👍
</button>
<button
onClick={() => {
setFeedback("down");
trackFeedback(messageId, "negative");
}}
className={feedback === "down" ? "text-red-500" : "hover:text-red-500"}
>
👎
</button>
</div>
);
}
▎Token 用量可视化
让用户知道"这次对话花了多少钱",有助于控制使用:
function TokenUsage({ usage }: { usage: { input: number; output: number } }) {
const cost = (usage.input * 2.5 + usage.output * 10) / 1_000_000;
return (
<div className="text-xs text-gray-400 flex gap-4">
<span>输入: {usage.input.toLocaleString()} tokens</span>
<span>输出: {usage.output.toLocaleString()} tokens</span>
<span>≈ ${cost.toFixed(4)}</span>
</div>
);
}
AI SDK 返回的结果中包含 usage 字段:
const result = await generateText({
model: openai("gpt-4o"),
messages,
});
console.log(result.usage);
// { promptTokens: 150, completionTokens: 280, totalTokens: 430 }
性能监控:建立 AI 应用的指标体系
传统前端用 LCP、FID、CLS 衡量性能。AI 应用需要一套新指标。

▎核心指标
| 指标 | 含义 | 达标线 | 怎么测 |
|---|---|---|---|
| TTFT | Time to First Token,首字时间 | < 1s | 从请求发出到第一个 token 到达 |
| TPS | Tokens Per Second,生成速度 | > 30 | 输出 token 数 ÷ 生成时间 |
| 总延迟 | 从发送到完成的总时间 | < 10s | 端到端计时 |
| 缓存命中率 | 命中缓存的请求比例 | > 50% | cache hit / total requests |
| 单次成本 | 每次请求的 token 花费 | < $0.01 | (input + output) × unit price |
| 错误率 | 请求失败或超时的比例 | < 1% | error count / total |
▎前端埋点方案
function trackAIMetrics(metrics: {
ttft: number;
totalLatency: number;
inputTokens: number;
outputTokens: number;
model: string;
cached: boolean;
}) {
// 上报到你的监控系统(DataDog / Grafana / 自建)
analytics.track("ai_request", {
...metrics,
tps: metrics.outputTokens / (metrics.totalLatency / 1000),
cost:
(metrics.inputTokens * getInputPrice(metrics.model) +
metrics.outputTokens * getOutputPrice(metrics.model)) /
1_000_000,
});
}
// 在 useChat 的回调中埋点
const { messages } = useChat({
onResponse(response) {
startTime.current = Date.now();
},
onFinish(message) {
trackAIMetrics({
ttft: firstTokenTime.current - startTime.current,
totalLatency: Date.now() - startTime.current,
inputTokens: message.usage?.promptTokens ?? 0,
outputTokens: message.usage?.completionTokens ?? 0,
model: "gpt-4o",
cached: response.headers.get("x-cache") === "HIT",
});
},
});
实战清单:AI 应用上线前的性能检查
把上面的内容整理成一个可执行的清单,上线前逐条检查:
| 检查项 | 具体做法 | 优先级 |
|---|---|---|
| ✅ 流式渲染 | 用 streamText + useChat,确保首字 < 1s |
P0 |
| ✅ 中断能力 | 实现「停止生成」按钮,用 AbortController | P0 |
| ✅ 模型路由 | 简单问题走 mini,复杂问题走大模型 | P1 |
| ✅ Prompt 精简 | System Prompt < 200 token | P1 |
| ✅ 对话历史裁剪 | 滑动窗口 + 摘要,控制在 4k token 以内 | P1 |
| ✅ 精确缓存 | Redis 缓存完全相同的请求 | P1 |
| ✅ 语义缓存 | Embedding 相似度匹配相似问题 | P2 |
| ✅ 输出长度控制 | maxTokens + 结构化输出 |
P2 |
| ✅ 错误重试 | 加重试逻辑 + 降级策略 | P1 |
| ✅ 性能监控 | TTFT、TPS、成本、缓存命中率全量埋点 | P1 |
| ✅ UX 反馈 | 骨架屏、打字机效果、重新生成、反馈按钮 | P1 |
避坑指南
▎坑 1:流式渲染导致 Markdown 闪烁
每个 token 都重新解析 Markdown,导致页面闪烁——尤其是代码块和表格。
// ❌ 每个 token 都重新渲染
useEffect(() => {
setHtml(marked.parse(content));
}, [content]);
// ✅ 用 useDeferredValue 或节流
const deferredContent = useDeferredValue(content);
const html = useMemo(() => marked.parse(deferredContent), [deferredContent]);
▎坑 2:缓存了错误的回答
LLM 有时会给出不正确的答案——如果缓存了,所有后续用户都会看到错误答案。
解法:
- ▸缓存前做质量检查(用 LLM-as-Judge 打分,低于阈值不缓存)
- ▸TTL 不要太长(1~4 小时)
- ▸提供「反馈」按钮,用户标记错误后自动清除缓存
▎坑 3:模型路由判断本身就花 Token
用 GPT-4o-mini 判断复杂度,虽然便宜,但也是一次额外调用。
解法:用规则优先,模型兜底:
function quickRouting(query: string): "simple" | "complex" | "unknown" {
// 规则判断:短问题大概率简单
if (query.length < 20) return "simple";
// 包含代码关键词大概率复杂
if (/写.*代码|实现.*功能|重构|优化/.test(query)) return "complex";
return "unknown";
}
async function getModel(query: string) {
const quick = quickRouting(query);
if (quick !== "unknown") {
return quick === "simple" ? openai("gpt-4o-mini") : openai("gpt-4o");
}
// 规则搞不定再用模型判断
return await routeWithLLM(query);
}
▎坑 4:流式请求没做错误处理
SSE 连接断了、服务端 500 了——前端一片空白,用户不知道发生了什么。
const { messages, error, reload } = useChat({
onError(err) {
toast.error("AI 服务暂时不可用,请稍后重试");
},
});
// 显示错误状态 + 重试按钮
{error && (
<div className="text-red-500 flex items-center gap-2">
<span>出错了:{error.message}</span>
<button onClick={reload} className="underline">重试</button>
</div>
)}
▎坑 5:忽略了并发控制
用户疯狂点击发送——前端同时发了 10 个请求,后端 token 烧到冒烟。
const isLoadingRef = useRef(false);
async function handleSubmit() {
if (isLoadingRef.current) return; // 防重复提交
isLoadingRef.current = true;
try {
await sendMessage();
} finally {
isLoadingRef.current = false;
}
}
AI SDK 的 useChat 已经内置了这个——isLoading 为 true 时不会重复发送。
总结
AI 应用的前端性能优化,核心就是三板斧:
流式渲染——让用户感觉快
- ▸
streamText+useChat实现开箱即用的流式 - ▸
requestAnimationFrame合并更新减少重渲染 - ▸Markdown 增量解析 + 代码块延迟高亮
- ▸
AbortController实现中断生成
Token 节约——让老板省心
- ▸Prompt 压缩:System Prompt 精简到 < 200 token
- ▸滑动窗口:只保留最近 N 轮 + 历史摘要
- ▸模型路由:简单问题走 mini 模型,成本降 80%
- ▸输出控制:
maxTokens+ 结构化输出
缓存策略——让重复问题零成本
- ▸精确缓存:Redis 存完全相同的请求
- ▸语义缓存:Embedding 相似度匹配,命中率 60%+
- ▸Embedding 缓存:避免重复向量化
- ▸合理的 TTL + 质量检查兜底
这三板斧下来,一个 AI 应用的体验和成本都能优化一个量级。
到这里,第三模块「AI Agent 工程化」的 10 篇文章就全部写完了——从第一个 Agent、到 ReAct 模式、到 Memory、到 LangGraph、到多 Agent 协作、到 RAG、再到今天的性能优化,走完了 Agent 工程化的全链路。
下一个模块我们进入原理与趋势篇——前端视角拆解 Agent 运行原理、Tool Calling 底层机制、Cursor 的代码补全是怎么做的,以及 AI × 前端的下一站。
推荐资源:
- ▸Vercel AI SDK 文档:https://sdk.vercel.ai/docs
- ▸OpenAI 计费说明:https://openai.com/pricing
- ▸GPTCache(开源语义缓存):https://github.com/zilliztech/GPTCache
- ▸LangChain.js Caching:https://js.langchain.com/docs/integrations/llm_caching

往期推荐
Multi-Agent Teams:让多个专家 Agent 像团队一样协作

AI Agent 是怎么"想一步做一步"的?拆解 ReAct 模式

从零开始:用 LangChain.js 构建你的第一个 Tool-Calling Agent

最后

点个在看支持我吧


腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 8
8 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)