消息队列(RocketMQ与Kafka)
它会检查消息的MagicCode(魔法值)。如果 MagicCode 非法,说明这块磁盘空间还没写过数据或者是脏数据。
为什么需要消息队列?
在单体应用中,一切都是同步的;但在分布式架构中,同步调用会导致严重的耦合和性能瓶颈。MQ 的出现解决了三个核心痛点:
A. 异步处理(Asynchronous)
-
场景:用户注册,需要发送短信、发邮件、赠送积分。
-
痛点:如果同步调用,响应时间 = 注册 + 短信 + 邮件 + 积分。只要其中一个慢了,用户就会卡死。
-
MQ 做法:注册成功后,丢一条消息到 MQ,直接给用户返回“成功”。剩下的杂活由后台慢慢处理。
B. 应用解耦(Decoupling)
-
场景:订单系统成功后,需要通知库存系统减库存。
-
痛点:订单系统必须知道库存系统的接口。如果库存系统宕机或者换了接口,订单系统也要改代码。
-
MQ 做法:订单系统只管发消息到 MQ。谁感兴趣(库存、物流、营销)谁就去订阅,订单系统根本不需要知道它们的存在。
C. 削峰填谷(Peak Shaving)
-
场景:秒杀活动,瞬时流量是平时的 100 倍。
-
痛点:数据库每秒只能扛 2000 并发,瞬时来了 2 万请求,数据库会直接瞬间崩溃。
-
MQ 做法:请求先全部进 MQ。后端服务根据自己的节奏(每秒 1000 条)从 MQ 里拉取并处理。MQ 就像大坝,挡住了洪峰。
消息队列的“代价”
引入 MQ 后,系统复杂度呈几何倍数增长。你必须面对以下问题:
-
系统可用性降低:MQ 挂了,整个链路就断了。
-
复杂度提高:你需要处理消息丢失、消息重复(幂等性)、消息顺序性等一系列头疼的问题。
-
一致性问题:A 系统改完数据库发了消息,B 系统处理消息失败了怎么办?分布式事务怎么搞?
三大主流 MQ
| 特性 | RabbitMQ | Kafka | RocketMQ |
| 出身 | Erlang 语言开发,老牌劲旅。 | LinkedIn 出身,Apache 顶级项目。 | 阿里双 11 洗礼,金融级可靠。 |
| 单机吞吐量 | 万级(相对较慢)。 | 十万/百万级(极高)。 | 十万级。 |
| 时延 | 微秒级(极低,最快)。 | 毫秒级。 | 毫秒级。 |
| 可靠性 | 极高(数据不易丢失)。 | 较高(追求极致吞吐)。 | 极高(分布式事务支持)。 |
| 适用场景 | 中小型项目、实时性要求极高、逻辑复杂。 | 大数据处理、日志采集、高吞吐监控。 | 电商、金融、需要严格顺序或事务的场景。 |
Kafka和RocketMQ如何选型?
A. 吞吐量 vs 延迟与可靠性
-
Kafka 的设计初衷是处理海量日志。它采用了批处理的思想,消息是按“攒一堆”的方式发送和读取的。这种设计在大数据采集、实时分析(如接入 Flink/Spark)场景下简直是无敌的存在。
-
RocketMQ 采用的是 长轮询拉取(Pull with Long Polling),在保持高吞吐的同时,更注重单条消息的低延迟和高可靠。如果你是做分布式事务(如订单扣款、库存同步),RocketMQ 的事务消息机制能让你少写很多兜底代码。
B. 业务逻辑的“重”与“轻”
-
场景一:简单的“通知”与“流” 。如果你的需求只是把日志传给 Elasticsearch,或者把用户点击数据传给推荐引擎,Kafka 是首选。它的生态位极其稳固,所有大数据组件都默认支持它。
-
场景二:复杂的“业务闭环” 。如果你需要延迟消息(比如 15 分钟未支付取消订单)、顺序消息(比如同一个用户的操作必须按顺序执行)、或者消费重试(消息处理失败了,自动隔几秒重试一次),RocketMQ 的开箱即用会让开发效率大幅提升。
C. 消息持久化
Kafka 在分区数达到几千个之后性能会断崖式下跌,而 RocketMQ 却能扛住上万个 Queue。
- 在 Kafka 中,一个 Partition(分区) 在物理磁盘上对应一个文件夹。当分区达到几千个时,如果有成千上万个线程或客户端并发向不同分区发送消息,操作系统需要同时维护数万个文件句柄。磁盘磁头必须在成千上万个文件之间频繁跳跃(Seek),原本的顺序写在 OS 层级退化成了随机写。
- 在RocketMQ,无论你有 10 个 Topic 还是 10,000 个 Queue,所有的生产者消息到达 Broker 后,都会被追加到当前的 CommitLog 末尾。对磁盘来说,它永远只在做一件事:单文件顺序追加。这极大发挥了磁盘的吞吐性能。
- RocketMQ 有一个后台线程(ReputMessageService)异步地将 CommitLog 中的消息位置分发到对应的 ConsumeQueue 中。即使 Queue 再多,也只是增加了少量的索引写入,不会破坏主数据的顺序写。
什么时候选 Kafka?
-
大数据场景:日志收集、用户行为追踪、流计算集成。
-
极致吞吐:数据量达到 PB 级,或者每秒有百万级的消息输入。
-
管道角色:数据只是通过 MQ 进行中转,不涉及复杂的业务逻辑处理。
什么时候选 RocketMQ?
-
电商/金融业务:涉及交易、支付、订单等对数据一致性极其敏感的场景。
-
业务特性依赖:需要使用延迟队列、顺序消费、分布式事务。
-
海量 Topic:单集群需要支持上万个 Topic(RocketMQ 的单物理文件存储设计使得它在 Topic 增多时性能波动较小)。
基本概念
生产者 (Producer)
生产者是消息的源头,负责创建并发送数据到消息队列。
-
职责:将业务产生的数据封装成“消息”,并选择合适的“话题”发送给消息服务器(Broker)。
-
特性:
-
独立性:生产者只负责发,不需要知道谁会接收,也不需要等待接收者的响应。
-
多样性:一个系统可以有成千上万个生产者,如订单系统、日志采集插件或移动端 App。
-
消息 (Message)
消息是信息的载体,是生产者与消费者之间传递的最小数据单位。
-
组成部分:
-
Header(消息头):包含元数据,如消息 ID、时间戳、优先级、路由 key 等。
-
Body(消息体):真实的业务数据,通常以 JSON、XML 或二进制流(如 Protobuf)的形式存在。
-
-
生命周期:从被创建开始,经历发送、存储、投递,直到被消费者确认(ACK)后从队列中删除。
话题 (Topic/Topic)
在 发布/订阅 (Pub/Sub) 模型中,话题是对消息进行逻辑分类的单位。
-
逻辑作用:它像是一个“公共频道”。生产者将消息发布到特定的 Topic,而消费者则通过订阅该 Topic 来接收消息。
-
物理实现:在 Kafka 或 RocketMQ 等系统中,一个 Topic 通常会进一步划分为多个 分区(Partition/Queue),以实现并发处理和存储的水平扩展。
-
P2P vs. Topic:
-
点对点 (Queue):消息只能被一个消费者拿走。
-
话题 (Topic):消息可以像广播一样,被所有订阅了该话题的消费者(群组)接收。
-
消费者 (Consumer)
消费者是消息的终点,负责从消息队列中获取并处理数据。
-
两种获取模式:
-
Pull(拉取):消费者主动询问 Broker:“有我的消息吗?给我来 10 条。”(如 Kafka)。
-
Push(推送):Broker 主动把消息塞给消费者:“来新活了,快接住。”(如 RabbitMQ)。
-
-
消费者组 (Consumer Group):这是一个高级概念。多个消费者可以组成一个群组,共同平摊一个 Topic 下的海量消息,从而实现负载均衡。
消息发送与接收
第一阶段:消息发送流程(生产者 --> Broker)
这是消息的“起航”阶段。
-
消息构建:
生产者(Producer)将业务数据序列化,并封装进 Message 对象,包含消息体(Body)和属性(Properties,如:Key、Tag)。
-
路由选择(Routing):
生产者查询本地缓存或注册中心(如 NameServer),确定该 Topic 对应的 Broker 地址及具体的 分区/队列(Partition/Queue)。
-
高级逻辑:如果是顺序消息,会根据 Sharding Key 固定发送到某个分区。
-
-
网络传输:
通过 TCP 长连接将数据包发送给 Broker。此时通常会涉及重试机制:如果网络闪断,客户端会自动重试(通常 2-3 次)。
-
Broker 接收与持久化:
Broker 收到消息后,将其顺序写入物理磁盘(如 RocketMQ 的 CommitLog 或 Kafka 的 Segment)。
-
同步刷盘 vs 异步刷盘:同步刷盘确保数据落盘后才返回;异步刷盘则先写内存,性能更高但有丢数据风险。
-
-
发送确认(Send Result/Confirm):
数据存储成功后,Broker 向生产者返回一个 ACK。生产者收到此信号,认为该消息发送成功。
第二阶段:消息存储与管理(Broker 内部)
消息在 Broker 里的短暂停留决定了它的“寿命”。
-
索引构建: 主数据存入物理文件后,Broker 会异步构建逻辑索引(如 ConsumeQueue),指向消息在物理文件中的位置。
-
副本同步(Replication): 如果是高可用集群,主节点(Master)会将数据同步给从节点(Slave/Follower)。
-
关键点:只有当指定数量的副本都写成功,消息才被视为“可消费”状态。
-
第三阶段:消息消费流程(Broker --> 消费者)
这是消息的“抵达”与“执行”阶段。
-
建立连接与订阅:
消费者(Consumer)启动并订阅特定 Topic。消费者组(Consumer Group)会进行 Rebalance(负载均衡),决定哪个消费者负责哪个分区。
-
消息拉取/推送(Pull/Push):
-
Pull:消费者主动询问 Broker 是否有新消息。
-
Push:Broker 有新消息时主动推送(底层通常也是长轮询拉取)。
-
-
业务逻辑执行:
消费者接收到消息,进行反序列化,执行核心业务代码(如:修改数据库、发送通知)。
-
消费确认(ACK/Commit Offset):
这是保证不丢消息的关键。
-
手动确认(Recommended):业务处理成功后,调用
ack()。Broker 收到后更新 Offset(偏移量)。 -
自动确认:消息一发给消费者就认为成功。风险极高,如果业务执行时崩溃,消息就丢了。
-
-
异常处理(Retry/DLQ):
如果业务执行失败,消费者返回
RECONSUME_LATER。消息会被投入重试队列。如果多次重试(如 16 次)依然失败,消息会进入死信队列(Dead Letter Queue)。
RocketMQ
存储模型
在分布式消息中间件中,磁盘 I/O 永远是性能的瓶颈。RocketMQ 之所以能在高性能的同时保证高可靠,其精髓就在于其“顺序写、随机读”的存储模型。
RocketMQ 的所有数据文件默认存储在 ${USER_HOME}/store 目录下。
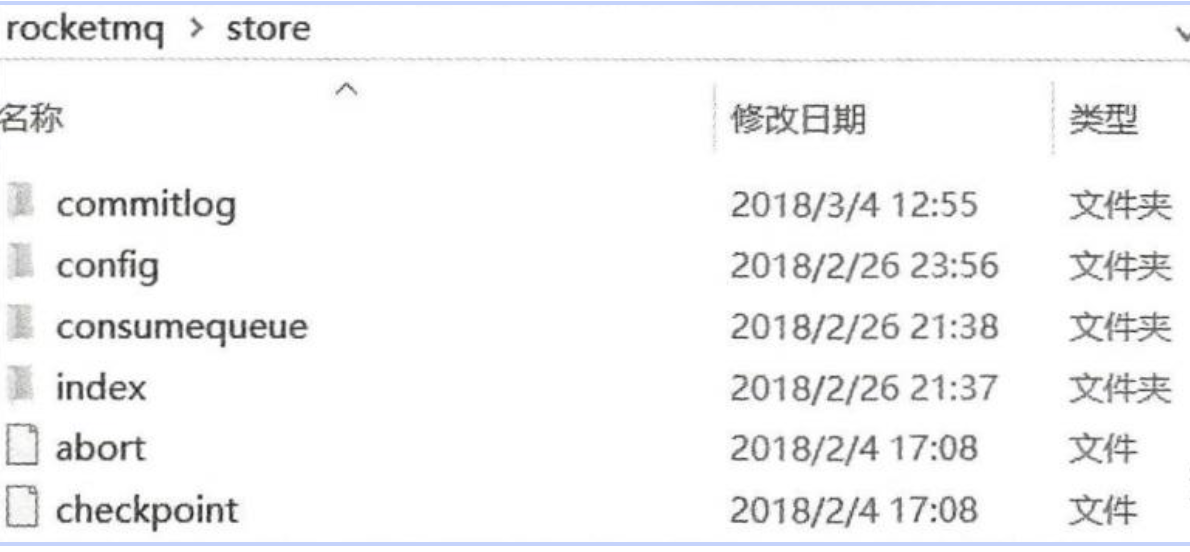
A. CommitLog(物理实体)
-
职责:存储所有的消息元数据和消息内容。
-
特征:
-
全局唯一:整个 Broker 只有一套
CommitLog(物理上由多个 1GB 的文件组成)。 -
顺序追加:不论是哪个 Topic 的消息,到达 Broker 后统统按顺序追加到
CommitLog末尾。 -
大小固定:每个文件默认 1GB,文件名长度为20位,左边补零,剩余为起始偏移量,比如00000000000000000000代表了第一个文件,起始偏移量为0,文件大小为1G=1073741824;当第一个文件写满了,第二个文件为00000000001073741824,起始偏移量为1073741824,以此类推。写满后自动创建新文件。

-
B. ConsumeQueue(逻辑索引)
-
职责:供消费者使用的“消费队列”。由于RocketMQ是基于主题topic的订阅模式,消息消费是针对主题进行的,如果要遍历commitlog文件中根据topic检索消息是非常低效的。
-
特征:
-
分类存储:按照
Topic/Queue维度划分。 -
极度轻量:它不存消息正文,只存索引。每个条目固定 20 字节,包括:
-
消息在
CommitLog中的起始 Offset (8 字节) -
消息体 Size (4 字节)
-
消息 Tag 的 HashCode (8 字节)
-
-
-
作用:消费者先查
ConsumeQueue找到位置,再去CommitLog读数据。

C. IndexFile(哈希索引)
-
职责:提供根据 Key 或 时间戳 查询消息的能力。
-
特征:
-
基于 HashMap 结构的索引文件。
-
它允许你在不遍历
CommitLog的情况下,通过消息的Unique Key快速定位到消息。
-
三者的协作关系:Reput 机制
消息在 RocketMQ 中的“落户”过程并非同步写完这三个文件,而是一个“主从同步+异步分发”的过程:
-
写 CommitLog:生产者消息到达,Broker 立即将其顺序写入
CommitLog。此时对生产者来说,消息已经发送成功。 -
异步构建索引(Reput):Broker 内部有一个后台线程
ReputMessageService。它持续监控CommitLog的写入进度。 -
分发数据:一旦有新消息,该线程立即读取消息内容,并将索引信息分发到对应的
ConsumeQueue和IndexFile。 -
消费读取:
-
消费者向 Broker 请求消息,先读
ConsumeQueue。 -
根据其中的 Offset 和 Size,直接去
CommitLog中进行随机读取。
-
为什么RocketMQ能支持上万个 Topic?
Kafka 的痛点(分区过多导致随机写)
在 Kafka 中,每个 Partition 都对应磁盘上的物理文件。
-
如果你有 10,000 个 Topic/Partition,磁盘上就有 10,000 个文件。
-
当大量消息并发进入时,磁头必须在这些文件之间频繁寻址(Seek),顺序写退化为随机写,导致 IOPS 飙升,性能大幅下降。
RocketMQ 的解法
RocketMQ 通过“逻辑与物理分离”的设计巧妙地绕过了这个问题:
-
始终顺序写:无论 Topic 增加到一万还是十万,Broker 永远只在往唯一的
CommitLog文件末尾顺序追加。磁盘的顺序写性能得到了极致的保护。 -
轻量的逻辑索引:
ConsumeQueue虽然多,但由于它极其小(仅存储 20 字节的定长数据),且由于采用了mmap(内存映射),写入开销非常低。 -
Page Cache 友好:所有的写入都在
CommitLog尾部,这使得操作系统能非常高效地利用 Page Cache 进行缓存预热,减少了真实的磁盘交互。
当 Broker 突然宕机时,RocketMQ如何保证数据不丢失?
数据的冗余是为了可靠,索引的冗余是为了容灾。
当 RocketMQ 的 Broker 进程突然崩溃(比如 kill -9 或断电)时,内存中尚未刷盘的索引数据会丢失,但只要物理上的 CommitLog 还在,一切就都有救。
1. abort 文件
在 RocketMQ 的存储目录(默认 ~/store)下,有一个名为 abort 的空文件。Broker 启动的第一件事就是寻找 abort 文件。
-
正常启动:Broker 启动时会通过
DefaultMessageStore.createAbortFile()创建这个文件。 -
正常关闭:Broker 在调用
shutdown()正常关闭时会删掉这个文件。 -
异常宕机:如果 Broker 崩溃,这个文件会残留在磁盘上。上次关闭没有走正常的生命周期,可能发生了:进程被
kill -9、系统 OOM、硬件掉电或内核崩溃
机制:当下一次启动时,Broker 只要发现 abort 文件存在,就知道上次是非正常关机,随即触发异常恢复流程。
2. checkpoint 文件
checkpoint 文件记录了磁盘上最重要三个组件的最后一次物理刷盘时间戳:
-
physicMsgTimestamp:CommitLog 的最后刷盘时间。 -
logicsMsgTimestamp:ConsumeQueue 的最后刷盘时间。 -
indexMsgTimestamp:IndexFile 的最后刷盘时间。
恢复流程
当触发异常恢复逻辑时,RocketMQ 并不是盲目地从头扫描几百 GB 的文件,而是采用“寻找断点,局部扫描”的策略:
1. 定位起始扫描点(Checkpoint)
我们不可能为了恢复而扫描整个磁盘上 TB 级别的 CommitLog,那样启动会耗时几个小时。RocketMQ 会利用 checkpoint 文件来缩小搜索范围。
checkpoint 记录了三个关键点。在异常恢复中,Broker 会取这三个时间戳的最小值。
-
physicMsgTimestamp:最后一次CommitLog刷盘时间。 -
logicsMsgTimestamp:最后一次ConsumeQueue刷盘时间。 -
indexMsgTimestamp:最后一次IndexFile刷盘时间。
为什么要取最小值? 因为索引(CQ)和物理数据(CL)是异步分发的。通常 CL 跑得快,CQ 跑得慢。为了确保不漏掉任何一条可能没来得及建索引的数据,我们必须从最落后的那个时间点开始检查。
2. CommitLog 的物理校准
确定了时间点后,Broker 会找到对应时间戳所在的 MappedFile(即物理文件段)。
-
逆序扫描与正序校验: Broker 会从最后一个文件开始向前找。它会检查消息的 MagicCode(魔法值)。如果 MagicCode 非法,说明这块磁盘空间还没写过数据或者是脏数据。
-
消息完整性验证: 一旦找到了可能有数据的起始点,它就开始正序扫描:
-
读取消息的总长度。
-
校验消息的 CRC 码(确保数据没在断电瞬间损坏)。
-
校验属性长度和 Body 长度。
-
-
确定“合法物理偏移量”: 扫描会一直持续到遇到第一条非法消息或文件末尾。这个位置之前的都被认为是“既定事实”,这个位置之后的被认为是“无效残留”。
-
物理截断(Truncate): Broker 会调用
MappedFile.setWrotePosition()和setCommittedPosition(),将文件末尾的残余数据彻底抹除。这确保了 CommitLog 绝对的物理真实。
3. 索引对齐与重建(Reput 机制)
现在物理数据(CommitLog)已经干净了,但逻辑索引(ConsumeQueue)可能还处于混乱状态:它可能多了一部分(指向了被截断的无效数据),也可能少了一部分(消息写进了 CL 但没来得及写进 CQ)。
-
ConsumeQueue 的截断: Broker 会检查每一个
ConsumeQueue文件。如果索引条目指向的CommitLog偏移量超过了刚才确定的“合法物理偏移量”,这些索引会被直接删掉。 -
重放(Reput)开始: 这是最核心的修复动作。Broker 启动
ReputMessageService线程:-
它从
ConsumeQueue目前记录的最大 Offset 开始,去CommitLog中拉取原始数据。 -
每读到一条消息,就重新提取出它的 Topic、QueueId、Tags、Keys。
-
重新写入索引:将这些元数据重新写入
ConsumeQueue条目。 -
重新填充哈希:将消息 Key 重新存入
IndexFile。
-
-
对齐完毕: 当
ReputMessageService处理到的偏移量等于CommitLog的最大合法偏移量时,逻辑与物理正式对齐。
这里要区分两种情况:
-
异步刷盘 (Async Flush):如果宕机瞬间消息还在 Page Cache 里没进磁盘,这部分数据确实会丢失。
-
同步刷盘 (Sync Flush):消息只有在磁盘写入成功后才会返回给生产者。此时宕机,虽然
ConsumeQueue(索引)可能没写,但物理数据已经在磁盘里了。通过上述的 Reput 机制,索引可以被完美还原。
工作流程
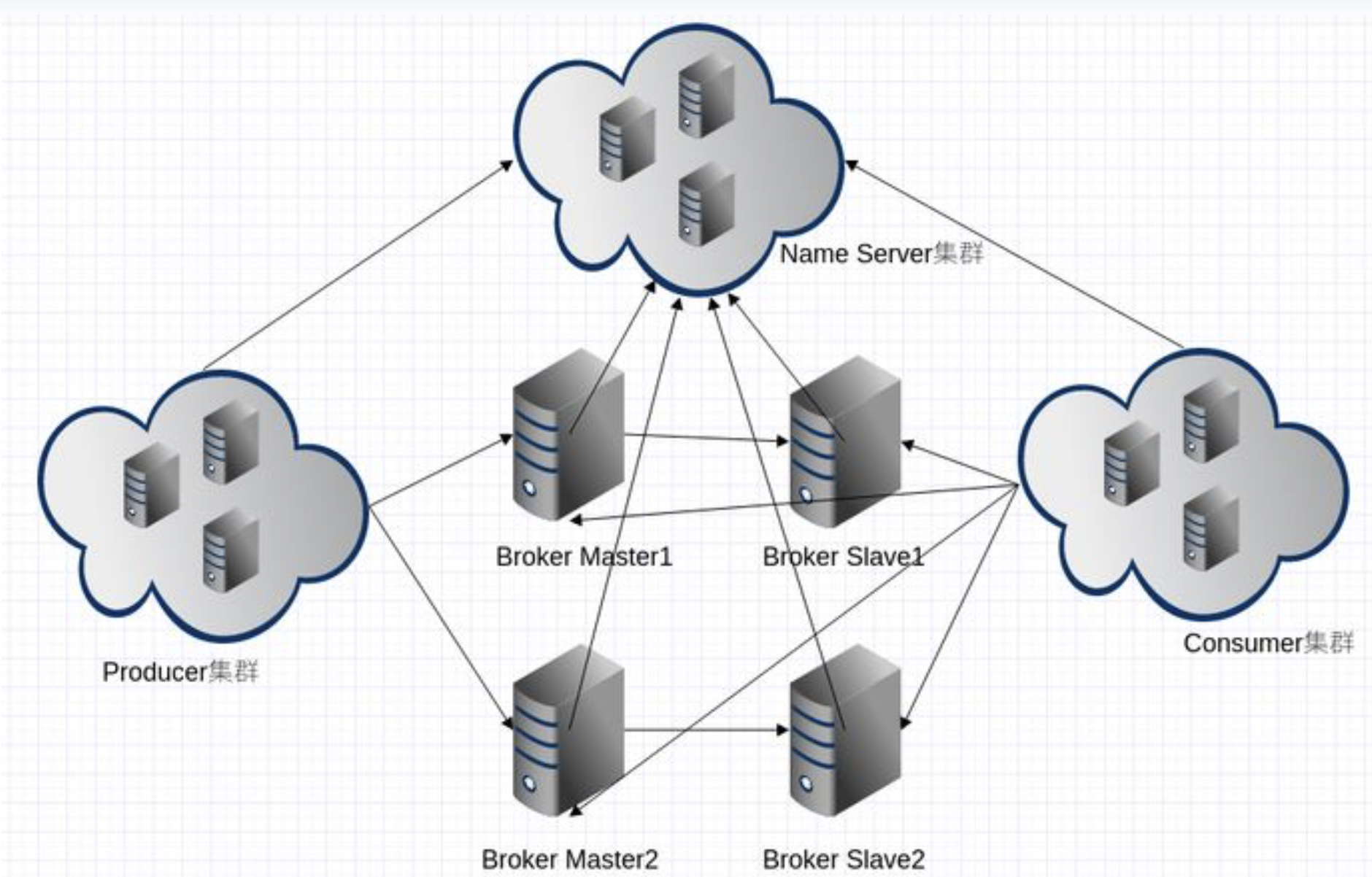
在聊流程之前,我们先明确四个核心角色的职责:
-
NameServer(注册中心):无状态,负责维护路由信息。它不直接处理消息,只告诉别人“谁在哪”。
-
Broker(处理中心):负责消息的存储、投递和查询。它是整个系统的体力活承担者。
-
Producer:负责产生并发送消息。
-
Consumer:负责订阅并处理消息。
第一阶段:启动与心跳(建立连接)
-
NameServer 启动:先于所有角色启动,静默等待连接。
-
Broker 注册:
-
Broker 启动后,会遍历所有的 NameServer 地址,并与每一个 NameServer 建立长连接。
-
定时上报:每隔 30s,Broker 会向所有 NameServer 发送心跳包,内容包含自己的 IP、Topic 信息、队列配置等。
-
-
心跳检测:
-
NameServer 每隔 10s 扫描一次 Broker 列表。
-
如果超过 120s 没收到某个 Broker 的心跳,NameServer 就会认为它挂了,将其从路由表中剔除。
-
第二阶段:路由发现
Producer 和 Consumer 在干活前,得先知道去哪找 Broker。
-
拉取路由:Producer/Consumer 启动后,会向 NameServer 请求特定 Topic 的路由信息。
-
本地缓存:为了性能,它们会将路由表缓存到本地内存中。
-
动态更新:Producer/Consumer 会每隔 30s 定期向 NameServer 更新一次路由信息,确保在 Broker 扩容或宕机时能及时调整。
第三阶段:消息生产流程
-
负载均衡:如果一个 Topic 分布在多个 Broker 上,Producer 会通过轮询(Round Robin)或自定义策略选择一个
MessageQueue。 -
发送模式选择:
-
同步发送:等结果返回(最常用,最稳)。
-
异步发送:传个回调,发完就走(追求高吞吐)。
-
单向发送:发完不管(用于日志,丢了也没事)。
-
-
故障规避(Fault Latency Strategy):
如果 Producer 发现某个 Broker 响应很慢或不可用,它会暂时“拉黑”这个 Broker 一段时间,将请求转给其他健康的 Broker。
第四阶段:Broker 存储流程(落盘)
-
写入 CommitLog:消息被顺序追加到物理文件。
-
同步/异步复制:如果是集群模式,Master 会将数据传给 Slave。
-
刷盘(Flush):数据从 Page Cache 进入物理硬盘。
-
构建索引:后台线程异步将数据分发到
ConsumeQueue和IndexFile
第五阶段:消息消费流程(抵达)
消费端的逻辑比发送端更复杂,因为它涉及状态维护。
-
负载均衡(Rebalance):
-
如果一个 ConsumerGroup 有多个成员,它们会通过算法(如平均分配)平摊该 Topic 下的所有
MessageQueue。 -
核心准则:一个
MessageQueue同一时间只能被同一个组内的一个 Consumer 消费。
-
-
消息拉取(Long Polling):
-
Consumer 并不是死板地“拉”或者被动地“接”,而是使用长轮询。
-
它向 Broker 发起请求,如果有消息则立即返回;如果没有消息,Broker 会把连接挂起一段时间(通常是 15s),期间一旦有消息就立即唤醒返回。
-
-
业务处理与 ACK:
-
业务代码执行。
-
手动/自动提交 Offset:告诉 Broker“我处理到第几条了”。
-
NameServer
在没有 NameServer 之前,生产者发消息得知道每个 Broker 的 IP,这在动态增减机器的云原生时代是不可接受的。
它是做什么的?
NameServer 是一个几乎无状态的注册中心。它的核心任务只有两个:
-
管理 Broker 路由:Broker 启动后向它报到,告诉它:“我负责哪些 Topic,我的 IP 是多少”。
-
提供路由查询:Producer 和 Consumer 定期来问:“我要发/收 Topic A 的消息,该去哪台机器?”
故障延迟规避(Fault Latency Strategy) 机制(NameServer全面宕机怎么办)
生产者在启动后或运行期间,会定期(每 30 秒)从 NameServer 获取最新的 TopicRouteData 并缓存到内存中。
-
脱离依赖:当 NameServer 全部宕机时,生产者会继续使用这份缓存的路由信息进行消息发送。
-
静态视图:此时生产者眼中 Brokers 的列表是固定的,如果某个 Broker 此时宕机,生产者必须具备“自我识别”的能力。
RocketMQ 的生产者通过 本地路由缓存 保证了基础连通性,而通过 故障延迟规避(Fault Latency Strategy) 机制,则实现了在没有“大脑”(NameServer)指挥的情况下,自主识别并踢除故障 Broker 的能力。
故障延迟规避机制通过 sendLatencyFaultEnable 开关控制(默认值为 false)。其核心逻辑在于将 “发送耗时/发送失败” 转化为 “不可用时长”。
A. 实时评估:updateFaultItem
每次消息发送结束后,无论成功或失败,生产者都会调用该方法更新对应 Broker 的“健康分”:
-
发送成功:记录此次请求的耗时(Latency)。
-
发送失败/超时:此时会进行“隔离(Isolation)”,通常默认赋予一个较大的延迟值(如 30,000ms)。
B. 阶梯退避:计算不可用时长
生产者根据记录的延迟时间,通过预设的阶梯表计算该 Broker 需要被“屏蔽”多久:
| 发送耗时 (Latency) | 规避/不可用时长 (Duration) |
| 550ms | 30,000ms (30秒) |
| 1,000ms | 60,000ms (60秒) |
| 3,000ms | 180,000ms (3分钟) |
| 15,000ms | 600,000ms (10分钟) |
自动切换流程:selectOneMessageQueue
当生产者需要发送下一条消息时,其选择队列的逻辑会发生变化:
-
优先轮询健康 Broker: 生产者会遍历缓存中的所有
MessageQueue,但会优先校验该队列所属的 Broker 是否处于“规避期”内。如果 Broker 的startTimestamp显示它还未恢复,则直接跳过该队列,选择下一个健康 Broker 的队列。 -
故障规避与切换: 如果缓存中的所有 Broker 都曾出现过延迟或故障,生产者会通过
pickOneAtLeast()方法尝试从失败列表中选择一个相对延迟最小或规避时间最短的 Broker 进行尝试,而不是卡死。 -
重试机制的配合: 在同步发送(SYNC)模式下,如果发送给 Broker A 失败,触发重试时,规避机制会确保下一次尝试自动切换到 Broker B 或其他可用节点,从而实现故障的瞬时平滑切换。
为什么不选 Zookeeper?
这是必须理解的 CAP 定理取舍。
-
可用性优先:AP 与 CP 的抉择
根据 CAP理论,任何分布式系统最多只能同时满足两个点。
-
ZooKeeper 追求的是 CP(一致性 + 分区容错性):
-
在进行 Leader 选举时,整个 ZooKeeper 集群会处于不可用状态。
-
对于注册中心而言,短时间的不可用会导致服务发现停滞,这在消息中间件这种对高可用要求极高的场景下是难以接受的。
-
-
NameServer 追求的是 AP(可用性 + 分区容错性):
-
NameServer 节点之间互不通信,是完全去中心化的。
-
只要有一台 NameServer 在线,整个集群的发现功能就是可用的,这极大提升了系统的抗风险能力。
-
-
-
性能与水平扩展的博弈
NameServer 的设计目标是“极简”与“高性能”。
-
轻量级实现:NameServer 逻辑非常简单,主要是内存中的
HashMap,因此处理速度极快。 -
水平扩展性:可以通过简单地增加机器来提升集群的抗压能力。
-
-
ZooKeeper 的局限性:ZooKeeper 的写操作无法通过增加节点来扩展,因为所有的写请求都必须经过 Leader 并达成共识(Quorum机制)。
-
为了解决写扩展问题,往往需要划分多个 ZK 集群或领域,但这增加了系统的复杂性,且可能导致服务之间的不连通。
-
持久化机制的“重量”对比
-
ZooKeeper 的 ZAB 协议太“重”:ZooKeeper 为了保证强一致性,每一个写请求都要记录事务日志,并定期生成内存快照(Snapshot)落盘。
-
定制化需求:对于一个仅存储 Broker 路由信息的注册中心来说,这种复杂的持久化和一致性协议是不必要的开销。NameServer 存储的数据高度定制化且通常较小,没必要引入过于沉重的方案。
工程实践中的“弱依赖”设计
RocketMQ 的设计哲学是尽量减少对注册中心的强实时依赖。
-
本地缓存机制:生产者和消费者在第一次从 NameServer 获取路由信息后,会将其缓存到本地内存中。
-
容错能力:即使 NameServer 集群整体宕机,只要 Broker 依然存活,生产者和消费者在短时间内仍能利用本地缓存的地址进行通信,系统不会立即瘫痪。
MessageQueue
它是 Topic 在 Broker 上的物理/逻辑分区。一个 Topic 默认会有多个 MessageQueue(比如 4 个或 8 个),分布在不同的 Broker 上。
-
并行能力的来源:消息不是挤在一个坑里,而是分散在多个 Queue 中。这意味着你可以同时起多个线程或多台机器去消费,速度翻倍。
-
顺序消费的基石:RocketMQ 保证在单个 MessageQueue 内的消息是先进先出的(FIFO)。如果你要求订单 A 的“创建”和“支付”必须按顺序处理,只要把它们发到同一个 MessageQueue 即可。
-
负载均衡的单位:在重平衡(Rebalance)时,系统是以 MessageQueue 为单位分配给消费者的。
ConsumerGroup
ConsumerGroup(消费者组) 是一个逻辑概念,它将一堆执行相同业务逻辑的消费者实例(Consumer Instance)打成一个包。
它定义了消息如何被“瓜分”。同一个组内的所有消费者,共享一个 Group ID。
两种核心消费模式:
-
集群模式(Clustering - 默认且最常用): 消息平均分配。一条消息发出来,组内 10 个实例,只有其中 1 个会收到。这实现了天然的负载均衡。
-
广播模式(Broadcasting): 消息全量分发。一条消息发出来,组内 10 个实例,每人都会收到一份。常用于刷新本地缓存。
一个 MessageQueue 同一时间只能被同一个 ConsumerGroup 里的一个消费者实例消费。
-
如果 Queue 有 4 个,Consumer 有 8 个,那么有 4 个 Consumer 会处于闲置状态(白费粮草)。
-
所以,增加消费能力的第一步往往是增加 MessageQueue 的数量。
RocketMQ是怎么对文件进行读写的?
MappedFile 与 MappedFileQueue
在 RocketMQ 的源码里,所有的文件操作都被封装在两个核心类中:
-
MappedFile:对应磁盘上的一个物理文件(如 1GB 的 CommitLog)。它内部通过 Java 的FileChannel.map()将文件映射到内存。 -
MappedFileQueue:管理一组MappedFile。它将多个物理文件在逻辑上串联成一个无限长的“连续空间”。
读取文件
一:逻辑寻址(找到数据在哪)
由于物理文件 CommitLog 动辄数百 GB,直接遍历是不现实的。读取的第一步是利用“索引”进行定位。
-
定位 ConsumeQueue:消费者根据
Topic和QueueId,首先访问对应的逻辑队列文件ConsumeQueue。 -
提取索引单元:从
ConsumeQueue中读取一个固定 20 字节 的数据块。-
物理偏移量 (Offset):该消息在
CommitLog中的起始位置(8 字节)。 -
消息长度 (Size):该消息的总大小(4字节)。
-
Tag HashCode:用于初步过滤消息(8 字节)。
-
-
回表查询:拿着提取到的 Offset 和 Size,跳转到物理存储文件
CommitLog中准备提取真实的报文内容。
二:内存映射(跨过慢速磁盘)
RocketMQ 并不直接使用传统的磁盘 I/O(如 read 系统调用),而是利用 mmap 技术将文件“搬”进内存。
-
MappedFile 管理:所有的
CommitLog文件都被封装在MappedFile对象中,每个文件默认 1GB。-
文件预热(缺页中断消除):mmap 刚建立时,文件并没有真正载入内存。RocketMQ 在创建新的
MappedFile后,会每隔 4KB 写入一个0。这个动作会强制操作系统分配物理内存页,提前填充 PageCache。 -
内存锁定 (mlock):通过系统调用
mlock锁定这块内存。这样可以防止操作系统因为内存压力大,将 PageCache 里的消息数据“交换(Swap)”到虚拟内存(磁盘)中。对于 MQ 来说,一旦发生 Swap,读取延迟会从纳秒级直接退化到毫秒级
-
-
建立映射 (mmap):通过 Java 的
FileChannel.map()方法,将磁盘上的CommitLog或ConsumeQueue文件(物理大小通常为 1GB)映射到进程的虚拟内存地址空间。映射完成后,程序对内存的读写直接作用于 PageCache。如果数据不在内存中,内核会触发“缺页中断”,将磁盘数据加载到 PageCache;如果是在写入,数据进入 PageCache 后即视为逻辑写入完成。-
传统 I/O:数据需要在 磁盘 --> 内核缓冲区 (PageCache) --> 用户缓冲区 之间进行多次拷贝。用户程序只能操作自己内存里的“用户缓冲区”。
-
mmap (FileChannel.map):它将进程虚拟地址空间的一段地址,直接映射到磁盘文件在内核层面的 PageCache 上。
-
-
内存化操作:对应用程序来说,读取文件就像读取内存数组一样简单,不再需要昂贵的内核态与用户态之间的数据拷贝。
第三层:内核交互
即便有了 mmap,如果数据不在物理内存(Page Cache)中,依然会触发磁盘读取。RocketMQ 通过以下手段确保“命中率”:
| 优化技术 | 实现机制 | 核心目的 |
| 文件预热 (Warm-up) | 创建新文件后,每隔 4KB写入一个 0,强制内核分配物理内存页。 | 避免运行时触发“缺页中断”导致的瞬间卡顿。 |
| 内存锁定 (mlock) | 调用系统指令将映射的内存区域锁定。 | 防止操作系统将这些热数据交换(Swap)到虚拟磁盘。 |
| 顺序预读 (madvise) | 暗示内核后续将进行顺序访问。 | 触发内核提前将相邻的磁盘块加载到 Page Cache 中。 |
| 冷热隔离 (Tiered) | 将冷数据(旧消息)转存至云端或对象存储。 | 防止读取旧消息时污染 Page Cache,保护热数据的读取性能。 |
PageCache
PageCache 是由 Linux 内核维护的、位于物理内存(RAM)中的磁盘数据缓存。
-
基本单位:内核以“页(Page)”为单位管理内存,通常一页的大小为 4KB。
-
存储内容:它存储了最近访问过的磁盘文件数据。
-
核心目标:尽可能多地让 I/O 操作在内存中完成,减少昂贵的物理磁盘磁头寻址开销。
工作机制
A. 读操作:预读与命中
当应用程序请求读取文件数据时:
-
查找:内核首先在 PageCache 中查找该数据所在的页。
-
命中(Cache Hit):如果数据已在内存中,直接返回,速度是纳秒级的。
-
缺失(Cache Miss):如果数据不在内存,触发缺页中断(Page Fault),内核从磁盘读取数据填充到 PageCache,再返回给应用。
-
预读(Read Ahead):内核会根据你的访问习惯(如顺序读),预测性地提前将后续数据加载到 PageCache。
B. 写操作:延迟写入与“脏页”
当应用程序写入数据时:
-
写入缓存:数据首先被写入 PageCache,该页被标记为脏页(Dirty Page)。
-
立即返回:此时对应用来说,写入已经完成,响应极快。
-
异步刷盘:内核线程(如
pdflush)会定期扫描脏页,将其批量写回磁盘。 -
强制刷盘:应用也可以调用
fsync等指令强制要求内核立即将脏页写回磁盘。
零拷贝(Zero-Copy)
零拷贝(Zero-Copy) 是一项旨在减少 CPU 开销和内存带宽消耗的优化技术。简单来说,它的核心目标是:在数据传输过程中,尽可能减少甚至消除 CPU 将数据从一个内存区域拷贝到另一个内存区域的次数。
要理解零拷贝,必须先看传统的 I/O(如 read + write)有多么低效。当我们将磁盘文件通过网络发送出去时,数据经历了以下过程:
-
磁盘 --> 内核缓冲区(PageCache):通过 DMA 拷贝。
-
内核缓冲区 --> 用户缓冲区:CPU 参与拷贝(上下文切换:内核态 --> 用户态)。
-
用户缓冲区 --> Socket 缓冲区:CPU 参与拷贝(上下文切换:用户态 --> 内核态)。
-
Socket 缓冲区 --> 网卡(NIC):通过 DMA 拷贝。
传统 I/O 的代价:
-
4 次上下文切换。
-
4 次数据拷贝(其中 2 次是由 CPU 亲自搬运的)。
对于高性能中间件(如 RocketMQ 或 Kafka)来说,这种重复的搬运不仅浪费 CPU,更会挤占内存带宽。
零拷贝并不是真的“零”拷贝,而是指 “没有 CPU 参与的内存拷贝”。目前主流的实现方案有以下几种:
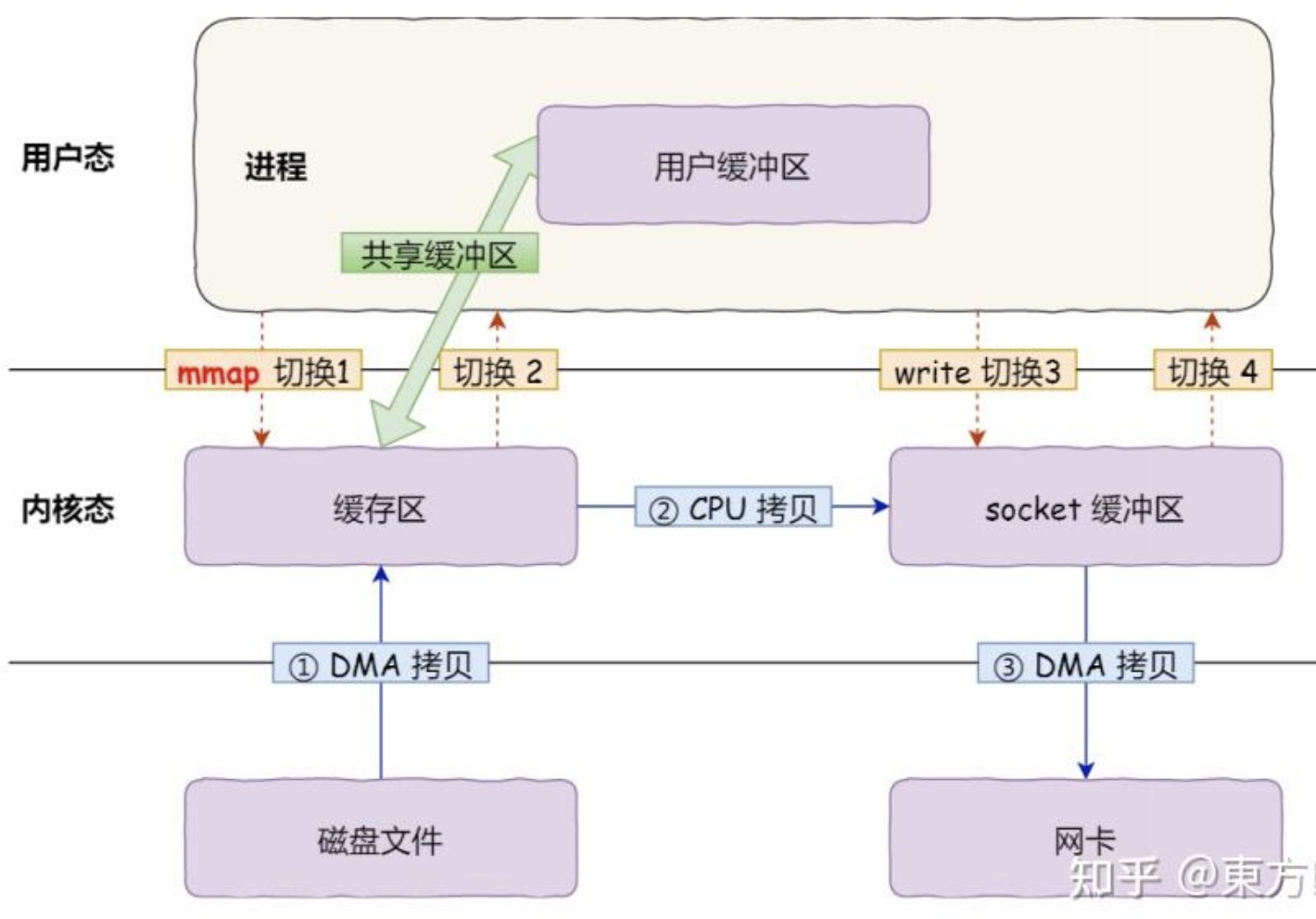
A. mmap + write
我们在讨论 RocketMQ 时多次提到这个方案。
-
原理:利用
mmap系统调用,将内核缓冲区(PageCache)的地址与用户空间的虚拟地址进行映射。 -
流程:
-
磁盘 --> 内核缓冲区(DMA 拷贝)。
-
用户空间直接访问内核缓冲区。
-
内核缓冲区 --> Socket 缓冲区(CPU 拷贝)。
-
Socket 缓冲区 --> 网卡(DMA 拷贝)。
-
-
性能:3 次拷贝 + 4 次上下文切换。虽然还是有 CPU 拷贝,但省去了内核与用户空间之间的大量重复数据搬运。
B. sendfile
Linux 2.1 版本引入的系统调用。
-
原理:数据直接在内核空间内部进行传输,不再经过用户空间。
-
流程:
-
磁盘 --> 内核缓冲区(DMA 拷贝)。
-
内核缓冲区 --> Socket 缓冲区(CPU 拷贝)。
-
Socket 缓冲区 --> 网卡(DMA 拷贝)。
-
-
性能:3 次拷贝 + 2 次上下文切换。
C. sendfile + DMA Gather Copy(真正的零拷贝)
这是目前最极致的方案,需要硬件(网卡)的支持。
-
原理:不仅不需要用户空间参与,甚至不需要将数据拷贝到 Socket 缓冲区,而是只将数据的位置(地址)和长度记录到 Socket 缓冲区。
-
流程:
-
磁盘 --> 内核缓冲区(DMA 拷贝)。
-
只拷贝文件描述符/指针到 Socket 缓冲区(几乎忽略不计)。
-
网卡根据指针直接从内核缓冲区提取数据(DMA 拷贝)。
-
-
性能:2 次拷贝(全部为 DMA 拷贝)+ 2 次上下文切换。
为什么 RocketMQ 偏爱 mmap 而 Kafka 偏爱 sendfile?
-
Kafka (sendfile):Kafka 的逻辑非常纯粹——它只是一个“搬运工”。数据从磁盘进来,原封不动地通过网卡发出去,所以它使用
sendfile追求最少的上下文切换和极致的吞吐。 -
RocketMQ (mmap):RocketMQ 需要在 Broker 端对消息进行各种操作(比如根据 Tag 过滤、消息重试处理等)。
mmap能够让程序在用户态像操作内存一样读写文件,虽然多了一次上下文切换,但赋予了程序极大的灵活性。
写文件
CommitLog 的追加艺术
在 RocketMQ 中,所有的消息写操作最终都指向物理文件 CommitLog。
-
全局顺序写:无论消息属于哪个 Topic,Broker 都会将其按到达顺序追加到当前
CommitLog文件的末尾。这种“只增不改”的模式避开了磁盘磁头频繁寻道的开销,使写入速度接近物理极限。 -
定长管理:每个
CommitLog文件默认大小为 1GB。当一个文件写满后,Broker 会创建一个新的文件,文件名即为该文件起始的物理偏移量。
写入流程:从内存到磁盘
消息的写入并不是直接打到磁盘上,而是经历了一个多级的“缓冲”过程。
写入内存(MappedFile)
-
映射文件:Broker 通过
mmap(内存映射)技术,将CommitLog文件映射到虚拟内存空间。 -
指针移动:写入时,程序直接在内存中操作
MappedFile对象的指针,将消息序列化后的字节流写入对应位置。 -
逻辑完成:一旦数据进入了 PageCache(页缓存),对发送者来说,如果不要求同步刷盘,这次写入就已经“逻辑成功”了。
在高并发场景下,为了减轻 PageCache 的压力,RocketMQ 引入了暂存池(TransientStorePool)机制:
-
堆外内存缓冲:开启该功能后,消息会先写入一块 DirectByteBuffer(堆外内存)。
-
异步提交(Commit):随后由专门的线程将数据从堆外内存
commit到MappedFile(即 PageCache)。 -
读写隔离:这种方式让“写”发生在堆外内存,“读”发生在 PageCache,极大地缓解了在高负载下的内存竞争和 Page Cache 抖动。
数据进入内存后是不安全的。RocketMQ 通过两种刷盘策略来平衡性能与可靠性:
| 策略名称 | 运作机制 | 优缺点 |
| 异步刷盘 (Async) | 消息写到 PageCache 后立即返回“成功”。后台线程定时(默认 500ms)调用 fsync 将脏页刷入磁盘。 |
吞吐量极大,但如果系统掉电,会丢失极少量未落盘的消息。 |
| 同步刷盘 (Sync) | 消息写到 PageCache 后,必须等待刷盘线程执行完 fsync 成功后再给客户端返回。 |
数据安全性极高,但由于受限于磁盘 I/O 速度,吞吐量会有显著下降。 |
高并发场景下的CommitLog写入问题
在高并发写入场景下,RocketMQ 的 CommitLog 是一个单管道、顺序追加的物理文件。由于所有线程都必须争抢“末尾追加”的权限,锁竞争成为了决定吞吐量的关键瓶颈。
RocketMQ 并没有默认在运行时根据负载“自动”实时切换锁,而是通过配置参数 useReentrantLockWhenPutMessage(默认为 false,即默认使用自旋锁)允许开发者根据磁盘的 I/O 特性进行手动切换。
以下是两种锁的设计逻辑以及在 IO Wait 过高时的优化思路:
1. 自旋锁 (Spin Lock):追求极致的低延迟
RocketMQ 默认使用的是 PutMessageSpinLock。
-
实现原理:当线程尝试获取锁失败时,它不会进入阻塞状态,而是利用 CPU 进行忙循环(Busy-Waiting),不断尝试重新获取锁。
-
适用场景:适用于 PageCache 极其健康、写入几乎能在纳秒级完成的场景。
-
优缺点:
-
优点:避免了线程从“运行态”切换到“等待态”再被唤醒的上下文切换开销。
-
缺点:如果锁被占用的时间变长(例如磁盘响应变慢),自旋会白白消耗大量 CPU 资源
-
当磁盘负载过高,PageCache 刷盘变慢,甚至触发了系统的强制回收时,消息追加(Append)的时间会从纳秒级上升到毫秒级。此时,成百上千个线程都在 CPU 上“疯狂自旋”,不仅无法加速 I/O,反而会让 CPU 负载爆表,进一步恶化系统性能。
在这种极端情况下,切换到重入锁可以让线程在等待磁盘完成操作时进入休眠。这虽然看起来慢了,但实际上释放了 CPU 资源去处理网卡数据接收或其他的管理逻辑,防止了系统彻底卡死(Broker Busy)。
所以,当磁盘 I/O 负载(IO Wait)较高或出现频繁抖动时,我会通过配置切换到重入锁。这样做可以有效避免 CPU 在 I/O 阻塞期间无效自旋,保护系统在极端压力下的稳定性。
2. 重入锁 (Reentrant Lock):应对高 I/O 抖动
通过将配置设为 true,系统将使用 PutMessageReentrantLock。
-
实现原理:基于 Java 的
ReentrantLock,当线程获取锁失败时,会被挂起(进入 Wait 状态),让出 CPU 资源。 -
适用场景:适用于磁盘性能较差、经常出现 IO Wait 或系统负载极高的场景。
-
优缺点:
-
优点:当写入过程因为磁盘 I/O 繁忙而变慢时,挂起线程可以保护 CPU 不被空转消耗。
-
缺点:每次加锁/释放锁可能涉及操作系统的调度,增加了微小的延迟损耗。
-
单纯换锁可能还不够。当 IO Wait 严重时,RocketMQ 通常建议开启 transientStorePoolEnable:
-
机制:写操作先进入 DirectByteBuffer(堆外内存),而不直接冲击 PageCache。
-
效果:这相当于在锁竞争之前又加了一层缓冲。写和读在物理内存上分离,减少了对同一块 PageCache 的锁定频率,从而间接降低了锁竞争的激烈程度。
如果出现了更极端的场景,CommitLog 的锁竞争已经无法通过换锁解决,怎么办?
当单机 CommitLog 的写入锁竞争(Lock Contention)达到物理瓶颈,且单纯依靠切换“自旋锁”或“重入锁”已无法显著提升性能时,我们需要从单点串行向并发分片的架构演进。
在 RocketMQ 的标准架构中,单台 Broker 默认使用单一的 CommitLog 来确保全局顺序写。要实现“单机吞吐极限”的进一步突破,通常有以下几种分片与扩展思路:
1. 逻辑分片:MessageQueue 的横向水平扩展
RocketMQ 实现并发处理的核心在于将 Topic 拆分为多个 MessageQueue。
-
多 Broker 部署(集群扩展):这是最标准、最推荐的“分片写入”方式。通过在多台物理机器上部署多个 Broker,Topic 的不同 MessageQueue 会分布在不同的 Broker 实例上。
-
流量均衡:生产者通过轮询或其他路由算法,将消息分散发送到不同 Broker 的不同 MessageQueue 中。此时,每个 Broker 维护自己的 CommitLog,从而在系统整体层面消除了单点锁竞争。
2. 物理分片:单机多 Broker 实例部署
如果在极端的万兆网卡或高性能 NVMe 磁盘场景下,单个 Broker 进程由于单线程写入锁(Write Lock)无法跑满硬件性能,可以采取单机多实例方案。
-
资源隔离:在同一台高性能服务器上启动多个 Broker 进程,每个进程监听不同端口并管理独立的存储路径(独立的 CommitLog 和 ConsumeQueue)。
-
吞吐翻倍:这种方式本质上是在单机内部创建了多个 CommitLog 实例。由于每个进程拥有独立的写入锁,并发写入能力会随着实例数量线性增长,从而彻底压榨磁盘的 IOPS 潜能。
负载均衡
发送端负载均衡(Producer Load Balance)
发送端负载均衡的主要任务是:将消息均匀地分发到 Topic 对应的所有 MessageQueue 中。
-
水平扩展:通过将消息分散到分布在不同 Broker 上的队列,利用多机并行处理能力来提升整体吞吐。
-
避免热点:防止某个单独的 Broker 因为承载过多消息而成为性能瓶颈。
生产者并不是盲目发送消息,它拥有一张“实时地图”:
-
注册中心依赖:Producer 启动后会与 NameServer 建立长连接,获取指定 Topic 的路由信息(包含 Broker 地址、读写队列数量等)。
-
动态更新:Producer 每隔 30 秒 会定期向 NameServer 拉取最新的路由数据并更新本地缓存。
-
故障容错:如果 NameServer 全挂了,Producer 会依靠本地缓存的路由信息继续工作,直到缓存失效或所有 Broker 不可用。
在默认情况下(即未开启故障规避开关时),RocketMQ 采用简单的轮询算法:
-
顺序选择:Producer 内部维护一个自增的计数器,每次发送消息时对可用的
MessageQueue列表进行取模运算,按序选择下一个队列。 -
重试切换:在同步发送模式下,如果发送给某个队列失败,重试逻辑会自动避开上一次失败的队列,尝试发送到该 Topic 下的其他队列。
进阶策略:故障延迟规避 (Fault Latency Strategy)
简单的轮询在遇到“亚健康”状态的 Broker(响应极慢但未完全断开)时,会导致大量的发送超时。
通过设置 sendLatencyFaultEnable = true 开启此机制:
-
性能监控:Producer 会记录每次发送到 Broker 的耗时(Latency)。
-
故障评估:如果某次发送耗时过长或直接失败,Producer 会通过
updateFaultItem将该 Broker 标记为“不可用”。 -
阶梯避让:根据耗时等级,该 Broker 会被“隔离”一段时间。
| 发送耗时 (Latency) | 规避时长 (Duration) |
| 550ms | 30,000ms (30秒) |
| 1,000ms | 60,000ms (60秒) |
| 15,000ms | 600,000ms (10分钟) |
消费端负载均衡
RocketMQ消费端(Push/Pull模式)的负载均衡,其目标是将Broker上某个Topic的多个消息队列(MessageQueue)合理分配给同一个消费者组(ConsumerGroup)下的所有消费者实例。核心原则是:一个MessageQueue在同一时刻只能被组内的一个Consumer消费,但一个Consumer可以同时消费多个MessageQueue。
1. 触发与准备
负载均衡由一个独立的 RebalanceService 线程驱动,默认每20秒执行一次。触发时,会进行两方面的数据准备:
-
获取消息队列(MessageQueue)列表:从本地缓存
topicSubscribeInfoTable中获取该Topic下所有的MessageQueue集合(mqSet)。 -
获取消费者列表:以Topic和ConsumerGroup为参数,向Broker查询当前在线的所有消费者ID列表。
2. 执行分配算法
收集到元数据后,会对MQ列表和消费者ID列表进行排序,然后采用指定的策略进行分配。默认策略是 AllocateMessageQueueAveragely(平均分配算法)。
-
算法类比:该算法类似于数据库分页。将所有MessageQueue视为“记录”,所有Consumer视为“页数”,计算出每页(每个Consumer)应承载的记录范围(
range),从而确定当前Consumer实例应负责哪些MessageQueue。
3. 更新本地任务队列(processQueueTable)
计算出当前Consumer应负责的MessageQueue集合(mqSet)后,会与本地正在处理的队列缓存processQueueTable进行比对和更新:
-
红色部分(需移除的队列):对于
processQueueTable中存在但不在新mqSet中的队列,会将其标记为Dropped=true,并尝试获取该队列锁。若1秒内获得锁,则将其从processQueueTable中移除,停止消费。 -
绿色部分(保留的队列):对于
processQueueTable中且仍在新mqSet中的队列,在Push模式下会检查其状态并可能触发相关更新。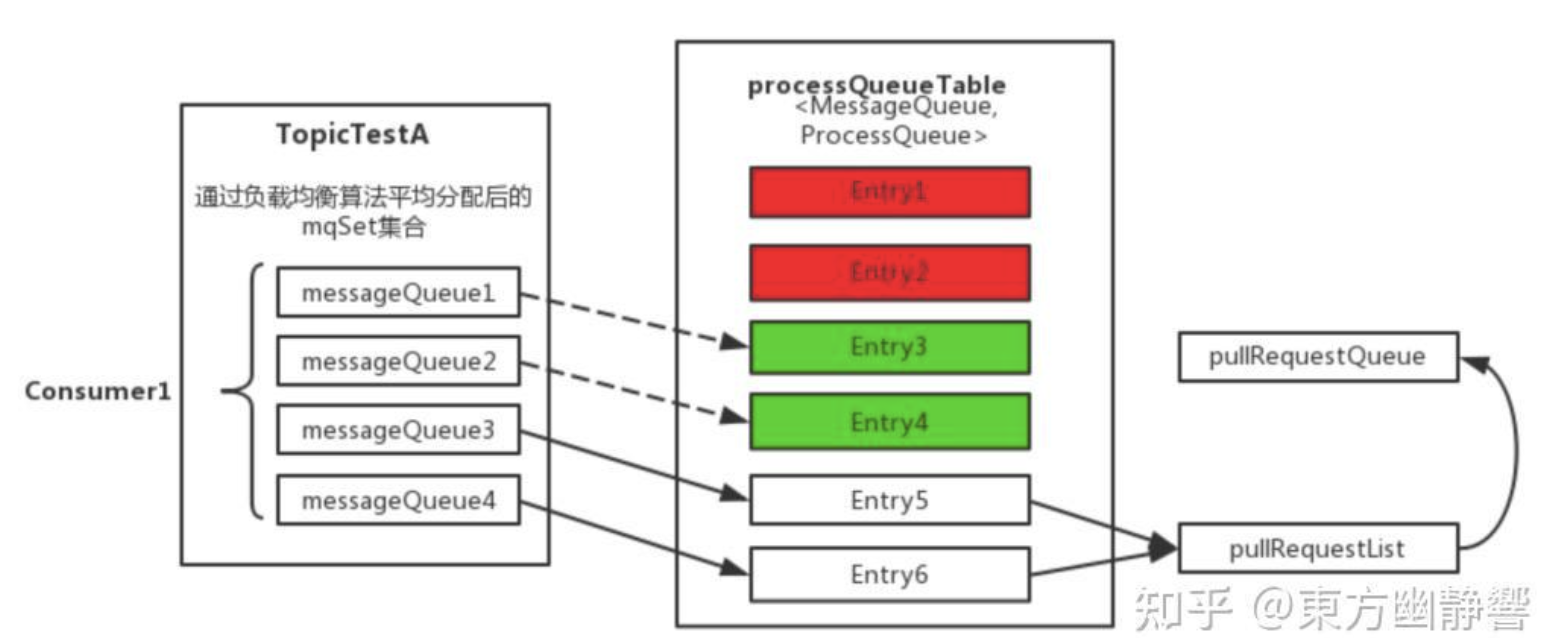
4. 创建拉取请求
为新分配的MessageQueue(即mqSet中新增的部分)执行以下操作:
-
为每个MessageQueue创建一个
ProcessQueue对象(消费过程快照),存入processQueueTable。 -
调用
computePullFromWhere方法,计算该队列应从哪个消费位点(offset)开始拉取。 -
将以上信息封装成一个
PullRequest(拉取请求)对象。
5. 提交请求并拉取消息
将创建好的PullRequest对象,放入 PullMessageService 服务线程的阻塞队列pullRequestQueue中。该服务线程会不断从队列中取出PullRequest,并向Broker发起真正的Pull消息请求,从而开始消费。
总结:通过以上周期性的负载均衡,RocketMQ能够动态地根据消费者数量的变化,将消息队列的消费压力均匀地分摊到整个消费者组,实现了可扩展、高可用的消费能力。您提供的图片资料完整覆盖了从触发、计算、资源清理到任务执行的全链路,是理解该机制的优秀材料。
消息长轮询
长轮询要解决什么问题?
在消息队列中,消费者获取消息主要有两种方式:
-
推模式:Broker 主动将消息推送给 Consumer。优点是实时性高,但缺点是无法感知 Consumer 的负载能力,可能造成 Consumer 过载甚至崩溃。
-
拉模式:Consumer 主动向 Broker 拉取消息。优点是消费节奏可控,但缺点是实时性依赖拉取频率。如果采用简单的短轮询(例如每秒请求一次),在无消息时会产生大量无效请求,浪费网络和计算资源。
长轮询 的设计目标就是在拉模式的基础上,最大限度地减少无效请求,同时保证消息的实时性。
长轮询的工作原理
长轮询的核心思想是:当 Consumer 发起拉取请求后,如果 Broker 端没有新消息,不会立即返回空结果,而是将这个请求“挂起”一段时间。在此期间,一旦有新消息到达或挂起超时,Broker 再响应这个请求。
Broker 端的实现
Broker 端是长轮询机制实现的关键,主要由 PullMessageProcessor和 PullRequestHoldService两个组件协同工作。
-
请求接收与判断
-
Consumer 发送的拉取请求包含了 Topic、队列 ID、拉取偏移量等关键信息。
-
PullMessageProcessor处理请求,首先根据偏移量查询指定队列。如果有消息,立即返回。 -
如果没有新消息,并且请求允许挂起,则进入长轮询流程。
-
-
请求挂起
-
Broker 会将这个 PullRequest 封装起来,并以
Topic@QueueId为键,存储在一个名为pullRequestTable的并发映射表中。这个过程就是“挂起”。 -
此时,Broker 会将响应设置为
null,不会立即向客户端返回任何数据,客户端的网络连接会保持等待状态。
-
-
请求唤醒与超时控制
挂起的请求如何被唤醒并返回呢?这里有三种触发机制:
-
新消息到达时唤醒(最优路径):当生产者向某个队列成功写入一条新消息后,会触发一个通知事件。
PullRequestHoldService会检查pullRequestTable,找出所有在等待这个队列消息的挂起请求,并立即唤醒它们,让它们重新尝试拉取消息。这保证了消息的极致实时性。 -
定时轮询检查(兜底路径):
PullRequestHoldService自身也是一个定时任务,默认每 5 秒会扫描一次pullRequestTable。对于每个挂起的请求,它会检查该队列的最大偏移量是否大于请求的偏移量。如果是,说明有新消息了,便会唤醒对应的请求。 -
客户端超时控制:Consumer 在发送请求时会设置一个挂起超时时间,由参数
brokerSuspendMaxTimeMillis控制(默认 15-30 秒)。如果挂起时间超过此限值,即使没有新消息,Broker 也会强制返回一个空响应,避免连接无限期占用。
-
消费端的配置
消费端有两个关键参数来控制长轮询行为:
-
brokerSuspendMaxTimeMillis:决定请求在 Broker 端最多挂起多久。 -
consumerTimeoutMillisWhenSuspend:消费端网络请求本身的超时时间,必须大于brokerSuspendMaxTimeMillis,以确保能给长轮询留出足够的挂起时间。
rocketmq是如何保证消息的可靠性/不丢失?
RocketMQ 通过在其消息生命周期的三个关键阶段——生产发送、Broker存储和消费处理——实施一系列精细的机制,来提供高可靠性的消息保障。
生产阶段:确保消息成功送达 Broker
这个阶段的目标是,只要 Producer 没有收到明确的成功响应,就认为消息可能丢失并触发重试。
-
使用同步发送
-
核心机制:调用
producer.send()方法后,线程会阻塞等待,直到收到 Broker 返回的SendResult。如果返回状态为SEND_OK,表明消息已被 Broker 成功接收。 -
规避风险:避免使用单向发送(
sendOneway),因为这种方式不关心发送结果,网络波动可能导致消息丢失。
-
-
配置发送重试
-
内置策略:RocketMQ 的 Producer 内置了重试机制。默认情况下,如果发送失败或超时,会自动重试 2 次。
-
灵活配置:你可以通过
producer.setRetryTimesWhenSendFailed(N)来调整重试次数。同时,RocketMQ 支持自动故障切换,当某个 Broker 失败时,会自动将消息重试发送到同一主题下的其他 Broker。
-
-
应对极端场景:事务消息
-
解决难题:对于需要先执行本地数据库事务再发送消息的场景,普通消息无法保证本地事务成功和消息发送成功的原子性。事务消息通过两阶段提交解决此问题。
-
工作流程:
-
Producer 向 Broker 发送 半消息,它对 Consumer 不可见。
-
Producer 执行本地事务。
-
根据本地事务结果,Producer 向 Broker 提交 Commit 或 Rollback 指令。
-
如果 Broker 未收到确认指令,会回查 Producer 的本地事务状态。
-
-
价值:这确保了只要本地事务成功,消息最终一定会被发送;反之,消息会被回滚。从而避免了业务处理成功但消息丢失的关键难题。
-
存储阶段:确保消息在 Broker 安全持久化
这是保证消息不丢失的最核心环节,重点在于通过多副本和持久化技术,防止单点故障。
同步刷盘
-
机制对比:Broker 将消息写入内存的 PageCache 后,刷盘策略是关键。
-
异步刷盘:写入 PageCache 后就返回成功,性能极高,但若 Broker 宕机,内存中未写入磁盘的消息会丢失。
-
同步刷盘:必须等待消息真正持久化到磁盘后,才向 Producer 返回成功。这是最安全的方式。
-
-
配置:在
broker.conf中设置flushDiskType = SYNC_FLUSH。
主从复制
-
单点风险:即使配置了同步刷盘,如果磁盘损坏,消息依然会丢失。因此需要多副本。
-
复制模式:
-
异步复制:主节点成功后就返回,性能好,但主节点宕机且无法恢复时,未同步到从节点的消息会丢失。
-
同步复制:主节点必须等待消息被至少一个从节点成功复制后,才返回成功。这可以保证即使主节点磁盘损坏,从节点上也存在完整消息。
-
-
配置:设置
brokerRole = SYNC_MASTER。
新一代高可用架构:DLedger
-
更进一步:在 RocketMQ 4.5+ 版本中,引入了基于 Raft 协议的 DLedger 模式。
-
优势:DLedger 在数据一致性、故障自动转移和恢复方面比传统主从复制更强大。它要求消息写入多数派节点才算成功,提供了更高等级的数据可靠性。
消费阶段:确保消息被成功处理
此阶段遵循 At Least Once 原则,保证消息不会被遗漏,但可能需要消费端处理重复消息。
-
正确的 ACK 时机
-
核心原则:Consumer 必须在业务逻辑成功执行完毕后,再向 Broker 返回
CONSUME_SUCCESS状态。 -
规避风险:切勿先返回成功再处理业务,否则若消费端宕机,消息将丢失。
-
-
消费重试与死信队列
-
自动重试:当消费失败(如抛出异常)或超时时,Consumer 应返回
RECONSUME_LATER。Broker 会将该消息投递到重试队列,并按照延迟级别(如 5s, 10s, 30s, 1m...)在后续时间点重新投递。 -
最终保障:如果消息重试16次后仍然失败,它会被移入死信队列。此时需要人工介入处理,但消息本身被永久保存,不会丢失。
-
-
消费端幂等性
-
必备措施:由于重试机制和网络不确定性,同一条消息可能被多次投递。因此,消费端业务逻辑必须实现幂等性。
-
实现方案:
-
利用数据库唯一键约束(如订单ID)。
-
使用 Redis 的
setnx命令或原子操作进行去重。 -
维护一张消费记录表,在事务中判断消息是否已处理。
-
-
rocketmq如何处理消息重复?
处理重复消息的核心责任在于消费者端实现幂等性。RocketMQ不保证消息绝对不重复,而是要求消费端业务逻辑自行实现“幂等性”来解决此问题。
消息为何会重复?
消息重复并非Bug,而是分布式系统在高可用、高可靠要求下的必然结果。主要发生在三个环节:
-
发送阶段重复
-
场景:生产者发送消息后,由于网络抖动未能收到Broker的成功确认。由于生产者配置了重试机制,它会再次发送同一消息。实际上,Broker可能已成功保存了第一条消息。
-
根本原因:网络不可靠与重试机制共同作用。
-
-
投递阶段重复
-
场景:消费者处理完消息后,在向Broker返回消费成功确认(ACK)时发生网络闪断或消费者突然宕机。Broker未收到ACK,会认为该消息消费失败,从而在后续重新投递。
-
根本原因:为确保消息“至少被消费一次”的可靠性机制。
-
-
系统运维与负载均衡
-
场景:当Broker或消费者集群重启、扩容或缩容时,会触发
Rebalance,消息队列会被重新分配。此过程可能导致部分已处理但未及时提交偏移量(Offset)的消息被再次消费。
-
核心对策:实现消费端幂等性
既然消息重复无法从根源上完全避免,最有效的方案就是让消费逻辑具备幂等性。幂等性是指:无论同一消息被消费多少次,其对业务数据状态造成的结果都与消费一次相同。
以下是几种经过验证的常用方案:
1. 利用数据库唯一约束
这是实现强幂等性最经典、最可靠的方法,尤其适用于交易、金融等核心业务场景。
-
原理:为消息体中的业务唯一标识(如订单ID)在数据库中建立唯一索引。消费者在处理消息时,首先尝试将该唯一标识插入到专用的“防重表”或业务主表中。
-
流程:
-
消费者接收到消息。
-
获取消息中的业务唯一标识(例如,订单ID)。
-
执行INSERT语句,尝试将该标识插入防重表。
-
如果插入成功,说明是首次消费,继续执行业务逻辑。
-
如果捕获到
DuplicateKeyException等唯一键冲突异常,则表明该消息已被处理过,直接跳过即可。
-
-
优势:利用数据库的原子性和唯一约束,简单、可靠,能提供强一致性保证。
-
注意:务必使用业务唯一标识而非RocketMQ自带的Message ID,因为重发的消息会拥有不同的Message ID。
2. 使用Redis的原子操作
适用于对性能要求极高的高并发场景,如秒杀、抢购。
-
原理:利用Redis的
SETNX(SET if Not eXists)命令或set key value NX EX的原子性,将业务唯一标识作为Key写入Redis。(或者为订单设置一个token) -
流程:
-
消费者接收到消息。
-
使用业务唯一标识作为Key,向Redis发起一个
SETNX操作,并设置合理的过期时间(TTL)。 -
如果命令返回
true(或1),表示成功获取锁,是首次消费,执行业务逻辑。 -
如果返回
false(或0),表示Key已存在,说明消息正在被处理或已处理过,直接跳过。
-
-
优势:性能极高,远快于数据库操作。
-
注意:需要妥善处理Redis的可用性问题,并确保设置的过期时间能覆盖业务处理时长,避免因锁过早失效而导致幂等性被破坏。
3. 基于业务状态机
如果业务逻辑本身具有清晰的状态流转,这是一种非常自然且高效的方案。
-
原理:在业务数据表中设计一个状态字段(如
status),所有业务操作都必须是状态驱动的。只有当前状态符合预期时,操作才能执行成功。 -
流程:以订单支付为例,订单状态可能为:
待支付->已支付->已完成。-
消费者收到支付成功消息后,执行更新的SQL可能为:
UPDATE orders SET status = '已支付' WHERE order_id = ? AND status = '待支付'。 -
随后检查该SQL执行后影响的行数。如果影响行数为1,说明是第一次处理且状态更新成功。如果影响行数为0,则说明订单已处于非“待支付”状态,可能是重复消息。
-
-
优势:无需额外组件,直接与业务逻辑结合,效率高。
-
注意:适用于业务本身有清晰、可控状态流转的场景。
rocketmq如何处理消息积压?
第一步:诊断积压原因
发现积压后,首先要确定瓶颈在哪里。
-
查看堆积情况:通过 RocketMQ 控制台或
mqadmin命令(如consumerProgress)查看消费者组的 Lag(未消费消息数)和消费进度 。 -
判断堆积位置:查看客户端日志文件(如
ons.log),如果出现the cached message count exceeds the threshold这样的日志,说明消息积压在客户端,即消息已经从Broker拉取到本地,但消费逻辑处理不过来 。否则,积压可能发生在服务端(Broker),需要检查Broker的磁盘、CPU和网络资源 。 -
定位消费瓶颈:检查消费者线程的堆栈信息(使用
jstack工具,关注ConsumeMessageThread线程)。如果线程阻塞在数据库查询、远程调用或复杂的业务计算上,这就是消费慢的根本原因 。
第二步:针对性解决方案
根据诊断结果,可以从以下几个层面入手解决。
1. 提升消费能力(最常用)
这是解决积压最直接的方法,核心是提高消费者的并行处理能力。
-
增加消费者实例:这是最有效的横向扩展方法。但必须遵循一个核心原则:消费者实例数量不能超过其订阅Topic的队列(MessageQueue)数量 。如果实例数已经等于队列数,就需要先扩容队列。
-
增加消费线程数:调整消费者参数
consumeThreadMin和consumeThreadMax,增加并发消费线程数 。 -
启用批量消费:如果业务允许,开启批量消费模式,一次拉取多条消息处理,可以大幅减少网络交互和设备IO次数,提升吞吐量
2. 扩容队列与系统重构
当消费者实例数已经等于队列数时,扩容队列本身是提升并行度的根本办法。
-
扩容队列数:RocketMQ 5.0前,队列数在创建Topic时就固定了,修改需要新建Topic。可以采用 “临时Topic分流” 的方案 :
-
创建一个队列数更多的临时Topic。
-
编写一个临时的消费者程序,从原Topic快速消费消息(不做复杂业务逻辑),然后直接转发到新的临时Topic。
-
让真正的消费者业务逻辑去消费新的临时Topic。
-
-
优化消费逻辑:这是治本之策。例如,将多次数据库交互优化为批量操作,或将耗时操作异步化 。检查消费逻辑,确保没有不必要的锁或阻塞调用。
3. Broker端与紧急处理
-
Broker端优化:如果Broker成为瓶颈,可以调整刷盘策略为
ASYNC_FLUSH(异步刷盘)以提升性能 。在极高写入压力下,可以启用transientStorePoolEnable机制,先将消息写入堆外内存池,再异步刷盘,以缓解PageCache压力 。 -
紧急处理与降级:在积压严重威胁系统稳定时,可以考虑降级方案。
-
跳过非核心消息:如果业务允许,可以监控队列偏移量差距(
diff),当积压超过一定阈值时,直接返回消费成功,跳过部分非关键消息的处理 。 -
重置消费位点:如果积压的消息可以丢弃,可以通过控制台或命令将消费位点重置到最新位置,从当前时刻开始消费,快速恢复业务 。
-
rocketmq如何保证消息有序?
RocketMQ 通过一套精巧的协作机制来保证消息的有序性,其核心在于确保同一组逻辑上相关的消息(如同一订单ID的所有消息)被发送到同一个消息队列,并由单个线程按顺序消费。
生产阶段:确保消息发送至同一队列
消息有序性的基础在发送时就已奠定。生产者必须保证有顺序要求的消息被写入同一个 MessageQueue(消息队列)。
-
关键接口
MessageQueueSelector:生产者发送消息时,需要实现此接口的select方法。该方法接收一个参数(通常是一个业务键,如订单ID),通过计算(如对队列总数取模)来恒定地选择同一个队列 。 -
必须使用同步发送:异步或单向发送无法保证消息到达Broker的顺序,因此顺序消息必须采用同步发送方式
存储阶段:Broker 保障队列内顺序
当消息进入Broker后,其存储机制天然支持了队列内的顺序性。
-
顺序写入:对于单个
MessageQueue,RocketMQ 会将消息顺序追加到 CommitLog 文件中。同时,每个队列对应的 ConsumeQueue 索引文件也是顺序构建的,这保证了消息在队列内部是严格FIFO的 。 -
队列是基础:只要生产端能正确地将顺序消息路由到同一队列,Broker 端就能保证其存储和提供的顺序与写入顺序一致 。
消费阶段:核心的“顺序消费”机制
这是实现顺序消费最复杂也最关键的一环。消费者必须使用顺序消费模式 。
-
使用
MessageListenerOrderly:消费者需要注册顺序消息监听器,而不是默认的并发监听器 。 -
“三把锁”机制(核心原理):
MessageListenerOrderly并非简单单线程,而是通过一套精细的加锁机制来保证顺序 :-
分布式锁:消费者启动时,会向Broker申请当前
MessageQueue的锁。成功获取锁的消费者实例才有权消费该队列,这保证了在集群环境下,一个队列在同一时刻只被一个消费者消费 。 -
本地队列锁:在消费者实例内部,对于同一个
MessageQueue,会使用synchronized锁确保只有一个线程可以处理其中的消息,防止多线程并发导致乱序 。 -
ProcessQueue 锁:在处理一批消息前后,会对本地的
ProcessQueue(处理队列)加ReentrantLock。这主要是在发生 Rebalance(重平衡,如消费者数量变化)时,防止队列被分配给新消费者的过程中,原有消费者正在处理的消息被中断或重复消费,从而破坏顺序性 。
-
上述机制实现的是局部(分区)有序,即同一业务键(如订单)的消息有序。这是99%的业务场景所采用的方式,因为它能在保证业务正确性的同时,通过多个队列并行处理来维持高吞吐 。
实现 RocketMQ 消息的全局有序,需要确保一个 Topic 下的所有消息严格按照先进先出(FIFO)的原则进行处理。其核心在于,通过限制并行度来换取严格的顺序性。
实现全局有序需要同时满足以下三个关键条件:
-
单一消息队列:将 Topic 的读写队列数量均设置为 1 (
writeQueueNums=1,readQueueNums=1)。这是实现全局有序的基础,因为所有消息都会被写入同一个队列,并由同一个队列被消费,从而天然保证了全局的 FIFO 顺序。-
操作命令示例:
mqadmin updateTopic -t YourTopicName -c DefaultCluster -r 1 -w 1。
-
-
单一生产者与同步发送:使用一个生产者实例,并采用同步发送模式。这确保了消息能够按照调用
send方法的顺序被依次写入到 Broker 的单一队列中。多生产者或异步发送都无法保证消息到达 Broker 的绝对顺序。 -
单一消费者与顺序监听器:使用一个消费者实例,并注册
MessageListenerOrderly 监听器。即使只有一个队列,RocketMQ 的默认机制也可能在消费者内部采用多线程处理。MessageListenerOrderly监听器会通过加锁机制,确保同一时刻只有一个线程消费该队列中的消息,从而在消费端维持顺序。
rocketmq如何实现消息过滤?
RocketMQ 的消息过滤机制是其作为一个企业级消息中间件的核心能力之一,它允许消费者只接收自己关心的消息,极大地提升了消息系统的效率和业务处理的清晰度。其实现原理可以概括为 “生产者打标,Broker过滤,消费者订阅” 的协作模式,并在底层采用了精巧的双层过滤架构来平衡性能与灵活性。
TAG 过滤:简单高效的分类机制
TAG 过滤是 RocketMQ 中最基础且高效的过滤方式,其设计目标是快速处理简单的消息分类场景。
-
基本用法:生产者在发送消息时,为每条消息设置一个唯一的
Tag字符串(例如"PAY_SUCCESS")。消费者在订阅时,通过指定Tag表达式(如"TagA"或"TagA||TagB")来告知 Broker 自己需要哪些消息。 -
核心原理:基于哈希码的快速匹配
RocketMQ 为了追求极致的性能,在消息存储时进行了优化。当消息被写入主日志文件后,系统会计算该消息
Tag字符串的哈希码,并将这个哈希值(一个long类型整数)存储在与消息队列对应的索引文件ConsumeQueue中。-
服务端粗筛:当消费者拉取消息时,Broker 会先将消费者订阅的
Tag表达式也转换为哈希码集合,然后与ConsumeQueue中存储的每条消息的Tag哈希码进行比对。这是一个非常快速的内存整数比较操作。匹配成功,则意味着该消息可能是消费者需要的。 -
客户端精筛:由于存在哈希冲突的可能性(不同的字符串可能计算出相同的哈希码),RocketMQ 在消费端最终处理消息前,还会用原始的
Tag字符串进行一轮精确匹配。这确保了最终被应用程序消费的消息一定是精确符合订阅条件的。
-
SQL92 过滤:强大灵活的表达式查询
当过滤条件超出简单的标签匹配,需要基于多个消息属性进行复杂判断时,SQL92 过滤提供了更强的表达能力。
-
基本用法:生产者在发送消息时,可以通过
putUserProperty方法为消息设置多个自定义属性(键值对)。消费者订阅时,则可以使用类似 SQL 的语法表达式来定义规则,例如"region = 'Hangzhou' AND price > 100"。 -
核心原理:表达式编译与运行时计算
与 TAG 过滤不同,SQL92 过滤的条件无法通过简单的哈希值来表征,其实现过程相对复杂。
-
表达式编译:消费者上报订阅关系时,Broker 会使用 JavaCC 工具将 SQL92 表达式编译成一个可执行的 Expression 对象(一个语法树)。这个过程只需一次,编译结果会被缓存起来以供后续重复使用。
-
消息过滤:当进行消息匹配时,Broker 需要从
CommitLog(消息主体存储文件)中读取消息的完整属性信息,然后将其作为上下文代入编译好的Expression中进行计算。只有表达式结果为true的消息才会被投递给消费者。
-
性能优化:布隆过滤器
由于 SQL92 过滤需要读取和解析消息内容,其性能开销远大于 TAG 过滤。为了缓解这个问题,RocketMQ 提供了可选的布隆过滤器 优化机制。
-
当开启相关配置后,在消息存储阶段,Broker 会预先为每个消息计算一个布隆过滤器位图,标识该消息可能匹配哪些消费组的过滤条件。
-
在拉取消息时,先使用布隆过滤器进行快速判断,如果位图显示消息不可能匹配当前消费者,则直接跳过,避免昂贵的表达式计算。这相当于在 SQL92 过滤之前增加了一层高性能预过滤。
rocketmq如何实现延时消息?
ocketMQ 的延时消息并非支持任意时间精度,而是预设了 18 个延迟级别。每个级别对应一个固定的延迟时间。
-
默认延迟级别:
1s 5s 10s 30s 1m 2m 3m 4m 5m 6m 7m 8m 9m 10m 20m 30m 1h 2h。 -
客户端设置:生产者发送消息时,通过调用
setDelayTimeLevel(level)方法指定延迟级别。例如,setDelayTimeLevel(3)表示这条消息将在 10 秒后被消费。
核心实现原理
1. 消息接收与暂存
当 Broker 接收到一条延时消息时,会在存储前进行关键处理:
-
主题与队列重定向:Broker 会将消息的原始 Topic 和 QueueId 备份到消息的属性中,然后将消息的实际 Topic 修改为专用的内部主题
SCHEDULE_TOPIC_XXXX,并将 QueueId 设置为delayLevel - 1。这意味着不同延迟级别的消息会被路由到SCHEDULE_TOPIC_XXXX这个内部主题的不同队列中。 -
属性备份:原始 Topic 和 QueueId 被保存在消息的
PROPERTY_REAL_TOPIC和PROPERTY_REAL_QUEUE_ID属性中,以便后续恢复。
2. 定时调度与消息投递
这是延时功能的核心,由 ScheduleMessageService类负责。
-
服务启动:Broker 启动时,
ScheduleMessageService会根据配置的延迟级别,为每个级别创建一个对应的定时任务DeliverDelayedMessageTimerTask,专门扫描其对应的延迟队列。 -
消息扫描与判断:定时任务会持续检查对应队列中的消息。它从
ConsumeQueue中读取消息的存储时间戳和延迟级别,计算出消息的精确到期时间,并与当前时间进行比较。 -
到期投递:一旦发现消息到期,该服务会执行以下操作:
-
从
CommitLog中加载完整的消息内容。 -
从消息属性中恢复其原始的 Topic 和 QueueId。
-
清除消息的延迟级别属性。
-
将消息作为一条普通消息,重新存入
CommitLog,但这次是写入其原始目标队列。此后,订阅该原始 Topic 的消费者就能像消费普通消息一样收到它了。
-
为了保证 Broker 重启后不丢失延迟消息的投递进度,ScheduleMessageService会定期将每个延迟队列的消费偏移量(offset)持久化到磁盘文件 delayOffset.json中。这样重启后可以从上次的进度继续执行,避免消息被重复投递或丢失
分布式事务消息(半消息)
RocketMQ 的分布式事务消息是其一项核心高级特性,它通过创新的 “半消息” 和 “事务状态回查” 机制,在普通消息基础上实现了类似两阶段提交(2PC)的效果,旨在解决跨服务场景下,本地事务执行与消息发送的最终一致性问题。其核心设计目标可以概括为:确保本地事务成功,消息一定能被投递;本地事务失败,消息一定不会被消费。
第一阶段:发送与暂存半消息
-
发送半消息:生产者发送一条“半消息”到 RocketMQ Broker。这条消息包含了最终要发送的所有业务内容,但其关键区别在于,它会被标记为一个特殊的状态。
-
暂存至特殊Topic:Broker 收到半消息后,会将其持久化存储,但并非存入业务指定的目标Topic。而是将其存入一个名为
RMQ_SYS_TRANS_HALF_TOPIC的内部特殊Topic中。正因为消费者订阅的是真实的业务Topic,所以它们无法看到和消费存储在内部Topic中的半消息,从而实现了对消费者的“隐身”。 -
Broker 响应:存储成功后,Broker 会向生产者返回一个确认响应(Ack)。
第二阶段:执行本地事务与确认
-
执行本地事务:生产者收到半消息发送成功的Ack后,开始执行本地事务(例如,扣减库存、更新订单状态等)。
-
提交二次确认:本地事务执行完毕后,生产者根据结果向 Broker 发送一个二次确认指令:
-
Commit(提交):如果本地事务成功,生产者发送 Commit 指令。Broker 会将该半消息从内部Topic中取出,恢复其原始的业务Topic和队列信息,并将其转存到真正的业务Topic中。此后,这条消息对消费者变为可见,可以被正常消费。
-
Rollback(回滚):如果本地事务失败,生产者发送 Rollback 指令。Broker 则会直接丢弃(删除)这条半消息。
-
容错机制:事务状态回查
这是保障一致性的关键环节。在分布式环境下,可能因为网络闪断、生产者应用重启等原因,导致 Broker 始终无法收到生产者的二次确认指令,使得消息长期处于“半消息”的悬而未决状态。
为了解决这个问题,RocketMQ 引入了事务状态回查机制:
-
定时扫描:Broker 会启动一个后台服务(
TransactionalMessageCheckService),定期扫描RMQ_SYS_TRANS_HALF_TOPIC中的半消息。 -
发起回查:对于长时间未得到确认的半消息,Broker 会向消息所属的生产者组内的任一可用生产者实例发起回查请求,询问该消息对应的本地事务最终状态。
-
检查并回复:生产者收到回查请求后,需要实现一个
TransactionListener接口,在其checkLocalTransaction方法中,根据消息中的业务唯一标识(如订单ID)去检查本地事务的最终执行结果(例如,查询数据库确认订单状态是否已更新),然后将结果(Commit 或 Rollback)回复给 Broker。 -
推进消息状态:Broker 根据回查结果,按照上述第二阶段的方式,将消息转为可投递或丢弃。
rocketmq如何实现死信队列?
消息进入死信队列主要有以下两种情况:
-
最大重试次数超限:这是最常见的原因。RocketMQ 默认允许一条消息最多被重试 16 次。如果重试 16 次后仍然消费失败,Broker 会自动将这条消息转移到死信队列。这个阈值可以通过参数
maxReconsumeTimes调整。 -
消费超时或ACK丢失:消费者在处理消息时发生超时,或者在返回消费成功确认(ACK)时发生网络异常导致Broker未收到,消息会被重新投递。若此类失败累计达到最大重试次数,同样会进入死信队列。
死信队列在设计上具有几个核心特性,确保其能有效发挥作用:
-
自动创建与隔离:死信队列由 RocketMQ 自动为每个消费者组创建,无需手动干预。其命名规则为
%DLQ%<ConsumerGroupName>。例如,消费者组OrderConsumerGroup对应的死信队列Topic为%DLQ%OrderConsumerGroup。这种命名方式实现了与正常业务Topic的严格隔离,避免对正常消息流造成污染。 -
只读性与持久化:消息一旦进入死信队列,便不再有任何自动重试机制。这些消息会被持久化存储,默认保留时间为72小时(部分资料显示为48小时,具体可通过Broker配置调整),为问题排查和修复留出充足时间。
如何管理和处理死信消息?
对于死信队列中的消息,需要人工或通过编程方式介入处理。
-
查看死信消息
-
通过控制台:RocketMQ 提供的管理控制台通常有专门的“死信队列”页面,可以按消费组查询和查看死信消息的详细信息,包括消息ID、重试次数、产生时间等。
-
通过命令行工具:可以使用
mqadmin命令进行查询,例如sh mqadmin queryMsgByTopic -n <namesrv_addr> -t %DLQ%YourConsumerGroup。
-
-
处理死信消息
处理死信消息的常见思路如下:
-
分析原因:首先需要查看消息内容和日志,定位消费失败的根本原因,是代码Bug、数据问题还是依赖服务不可用。
-
手动重投:如果问题已经修复,可以通过控制台或Admin工具将死信消息重新发送回原始的业务Topic,让其能够被正常消费。
-
编写专用消费者:可以创建一个专用的消费者程序来订阅死信队列的Topic,实现自动化的告警、记录或条件性修复与重投。
-
如何保证rocketmq的高可用?
NameServer 集群
NameServer 是 RocketMQ 的“大脑”,负责管理所有 Broker 的路由信息。它的高可用设计非常简洁高效。
-
无状态与去中心化:NameServer 节点之间互不通信,每个节点都独立维护一份完整的路由信息表。这种去中心化设计避免了复杂的同步逻辑,使得单个节点故障完全不影响其他节点 。
-
最终一致性:Broker 会定时向所有 NameServer 发送心跳(默认30秒一次),注册自己的信息。NameServer 则通过一个定时任务(默认10秒一次)来扫描并剔除超过120秒未上报心跳的 Broker,从而实现路由信息的最终一致性 。
-
客户端连接策略:Producer 和 Consumer 在启动时,会配置多个 NameServer 地址。它们会随机选择一个节点连接,如果失败则自动切换到下一个。在运行中,客户端也会定时从 NameServer 拉取最新的路由信息 。
总结:只要有一个 NameServer 节点存活,就能提供完整的路由服务,保证了路由层的极高可用性。
Broker 集群与主从复制
Broker 是消息存储和转发的核心,其高可用主要通过主从(Master-Slave)架构和数据复制来实现。
1. 集群部署模式
根据业务需求,可以选择不同的集群模式 :
|
部署模式 |
优点 |
缺点 |
适用场景 |
|---|---|---|---|
|
多Master多Slave |
数据零丢失,服务与数据均无单点故障 |
性能略低(约10%),RT略高 |
金融、交易等核心业务,对数据强一致性要求极高 |
|
多Master多Slave |
性能高,几乎接近多Master模式,Master宕机后消费者仍可从Slave消费 |
可能丢失少量消息(Master宕机且数据未同步时) |
绝大多数业务场景,在性能和数据可靠性间取得平衡 |
|
多Master |
配置简单,性能最高 |
任意Master宕机,其上的消息将不可消费,实时性受影响 |
非核心业务,允许消息短暂不可用 |
生产环境推荐使用“多Master多Slave”模式,并根据业务要求选择同步或异步复制 。
2. 复制与刷盘机制
这是保证消息不丢的关键配置,主要体现在两个环节:
-
主从复制(Replication):指消息在 Master 和 Slave 节点间的同步方式。
-
同步复制(SYNC_MASTER):Producer 发送消息到 Master 后,Master 会等待 Slave 成功复制完数据后才向 Producer 返回成功。这确保了即使 Master 宕机,Slave 上也有一份完整的数据 。
-
异步复制(ASYNC_MASTER):Master 收到消息后立即返回成功,然后异步地将数据复制给 Slave。性能更好,但存在少量数据丢失风险 。
-
-
刷盘策略(Flush):指消息从内存(PageCache)持久化到磁盘的方式。
-
同步刷盘(SYNC_FLUSH):Broker 将消息写入内存后,会立即强制刷盘,等待磁盘写入成功后才返回。非常可靠,但性能损耗大。
-
异步刷盘(ASYNC_FLUSH):Broker 将消息写入内存后立即返回,由后台线程定期刷盘。性能高,是默认配置,但若Broker宕机可能丢失内存中未刷盘的消息。
-
最佳实践组合:通常采用 异步刷盘(保证性能) + 同步复制(保证数据冗余) 的组合,以兼顾性能和数据可靠性
持久化与底层保障
即使软件层面配置完善,硬件故障(如磁盘损坏)仍是威胁。现代云平台提供了更强大的基础设施层高可用方案。
-
云盘三副本机制:以腾讯云为例,其 RocketMQ 服务利用云硬盘(CBS)的数据三副本机制 。当 Broker 写入消息时,数据会被自动、同步地复制到三个不同的物理设备上。只有三份拷贝都写入成功,操作才会返回。这意味着,单块甚至两块磁盘损坏都不会导致数据丢失,极大地简化了数据高可用的实现 。
-
跨可用区(AZ)部署:将 NameServer 和 Broker 节点分散在同一个地域的多个可用区(可理解为相互隔离的数据中心)。这样,即使整个机房发生故障,服务仍能由其他可用区的节点提供,实现机房级别的容灾 。
容错与负载均衡
Producer 和 Consumer 的智能容错是保证业务连续性的最后一道防线。
-
生产端容错:
-
重试机制:发送消息失败时,Producer 会自动重试(默认2次)。对于同步发送,这是保证消息成功投递的重要手段 。
-
故障延迟机制:当发送某个 Broker 失败时,Producer 会在一段时间内避免向该 Broker 发送消息,而是将消息发往集群中的其他健康 Broker,实现快速的故障转移 。
-
-
消费端容错:
-
集群模式与重平衡:在集群消费模式下,如果某个 Consumer 实例宕机,Broker 会触发重平衡(Rebalance),将其负责的消息队列重新分配给组内其他存活的 Consumer,实现消费任务的自动接管 。
-
重试与死信队列:若某条消息消费失败,RocketMQ 会将其投递到重试队列,按照延迟时间(如5s、10s、30s...)进行重试。若重试16次后仍失败,消息会被转入死信队列(Dead-Letter Queue),等待人工干预。这保证了即使业务逻辑有问题,消息也不会丢失 。
-
Kafka
存储模型
Kafka 的存储采用了一种清晰的分层逻辑,从抽象到具体依次为 Topic、Partition 和 Segment。
-
Topic(主题):消息的逻辑分类,比如
order-topic专门用于处理订单消息。它本身不涉及物理存储,只是一个命名空间。 -
Partition(分区):这是 物理存储和并行处理的基本单位。一个 Topic 可以被划分为多个 Partition,每个 Partition 是一个有序的、不可变的消息队列。消息被不断追加到队列末尾。Partition 可以分布在不同的 Broker 上,实现了数据的分布式存储和负载均衡。
-
目录结构:在磁盘上,每个 Partition 对应一个物理目录,命名规则为
<topic_name>-<partition_id>。例如,Topicorder-topic的第 0 个分区,其目录名就是order-topic-0。
-
-
Segment(段):为了防止单个 Partition 文件过大,Kafka 又将每个 Partition 在物理上划分为多个 Segment。当前正在写入的 Segment 称为 活跃段(active segment),只有它才能接受写入。当活跃段达到一定大小(默认 1GB)或时间后,就会滚动(roll)创建一个新的 Segment。这种设计使得 Kafka 可以轻松地删除或归档旧的、已消费的数据,只需清理对应的 Segment 文件即可,非常高效。
每个 Segment 由一组成对出现的文件组成,它们拥有相同的前缀(起始偏移量),但后缀不同。
|
文件类型 |
作用 |
文件名示例 |
|---|---|---|
|
数据文件(.log) |
存储实际的消息数据。 |
|
|
偏移量索引文件(.index) |
建立 Offset 到消息在 .log 文件中物理位置的映射。 |
|
|
时间戳索引文件(.timeindex) |
建立 时间戳 到 Offset 的映射,主要用于按时间戳快速定位消息。 |
|
单条消息的物理结构(存储在 .log 文件中)包括:
-
offset(8字节): 消息在 Partition 中的唯一标识。 -
message size(4字节): 消息体大小。 -
CRC32(4字节): 用于校验消息完整性。 -
magic(1字节): 标识协议版本。 -
attributes(1字节): 标识压缩或编码类型。 -
key length和key(可选): 消息的键。 -
value length和value: 实际的消息体(payload)。
工作流程
消息生产阶段
-
生产者初始化与配置
生产者 (
KafkaProducer) 启动时,会配置关键参数,如集群地址 (bootstrap.servers)、序列化器 (key.serializer,value.serializer)、以及确认机制 (acks) 等 。 -
消息发送核心流程
-
序列化与分区:当调用
send()方法后,生产者首先将消息的 Key 和 Value 序列化为字节数组。接着,分区器 (Partitioner) 会决定消息应被发送到主题的哪个分区。若有 Key,则对 Key 进行哈希后取模,确保相同 Key 的消息总进入同一分区(保证顺序性);若无 Key,则采用粘性分区策略,随机选择分区并在一段时间内批量发送,以提高性能 。 -
批处理与异步发送:消息并非立即发出,而是被存入内存中的消息累加器 (RecordAccumulator),按分区组织成批次 (Batch)。这是一个异步过程,主线程在将消息放入累加器后便可继续执行。独立的 Sender 线程 会负责将已满或等待超时的批次打包,通过
NetworkClient批量发送到对应的 Broker。这种批处理机制是 Kafka 高吞吐量的关键 。
-
-
Broker 确认与可靠性
消息被发送到目标分区的 Leader Broker。Broker 根据生产者设置的
acks参数进行确认 :-
acks=0:生产者不等待确认,速度最快,但可能丢失消息。 -
acks=1(默认):等待 Leader 副本写入本地日志即确认。是性能和数据可靠性的折中方案。 -
acks=all:等待 Leader 和所有处于同步状态的副本 (ISR, In-Sync Replicas) 都写入成功才确认。可靠性最高,但延迟也最高 。
-
消息存储与集群协调
-
分布式存储与副本同步
-
Kafka 将每个分区的数据以仅追加日志 (Append-only Log) 的形式持久化到磁盘。每个分区在物理上由多个日志段 (Segment) 文件组成,便于管理和清理 。
-
为了高可用,每个分区有多个副本。生产者只与 Leader 副本交互。Leader 负责将数据同步到 Follower 副本。只有与 Leader 保持同步的副本才在 ISR 集合中。若 Leader 宕机,Kafka 会从 ISR 中自动选举新的 Leader,确保服务不间断 。
-
-
消费组与重平衡
-
消费者以消费者组 (Consumer Group) 的形式工作。一个主题的一条消息只能被同一个消费者组内的一个消费者消费,从而实现点对点或发布订阅模式 。
-
当消费者组内的消费者数量发生变化(如增删)或主题的分区数变化时,会触发重平衡 (Rebalance)。此过程由组协调者 (Group Coordinator) 管理,它会重新分配分区给组内的存活消费者,确保每个分区都有唯一的消费者处理 。重平衡期间,整个消费者组会短暂暂停消费。
-
消息消费阶段
-
消费者初始化与分区分配
消费者 (
KafkaConsumer) 启动后,会订阅主题并加入一个消费者组。随后,组协调者会触发重平衡,为每个消费者分配其要消费的分区 。 -
拉取消息与处理
-
消费者采用 拉取 (Pull) 模式,主动向 Broker 发起
poll()请求来获取消息。这种方式允许消费者根据自身处理能力控制消费速率 。 -
拉取到的消息由消费者进行业务逻辑处理。
-
-
偏移量提交与语义保证
-
消费者需要定期提交偏移量 (Offset),即记录当前已消费到的位置。偏移量默认存储在 Kafka 内部的
__consumer_offsets主题中 。 -
提交方式决定了消息的消费语义 :
-
自动提交:可能因消费者崩溃在处理完消息后、提交偏移量前发生,导致消息被重复消费(至少一次语义)。
-
手动提交:在处理完消息后手动提交偏移量,可以更精确地控制,实现至少一次或通过“先处理再提交”实现正好一次(需结合事务等机制)。
-
-
高可用
副本机制
Kafka 为每个主题分区维护多个副本,这些副本分布在不同的 Broker 上。它们有明确的角色划分,遵循“主写主读”原则。
-
Leader 副本:
-
读写流量唯一入口:所有生产者的写入请求和消费者的读取请求必须直接发送到分区的 Leader 副本。这是为了简化一致性模型,避免多主写入带来的数据冲突 。
-
数据同步的源头:负责接收新消息,并将其同步给所有的 Follower 副本 。
-
状态维护者:跟踪所有 Follower 副本的同步进度,并据此维护一个关键指标——高水位(High Watermark, HW) 。
-
-
Follower 副本:
-
数据冗余备份:其核心职责是被动地、异步地从 Leader 副本拉取消息,并将其持久化到自己的本地日志中,从而实现数据冗余 。
-
故障备援:Follower 副本不处理任何客户端请求。它们的唯一价值在于,当 Leader 副本所在的 Broker 发生故障时,其中一个 Follower 副本能被选举为新的 Leader,从而快速恢复服务,实现高可用 。
-
数据同步不是简单的“发出即忘”,Kafka 通过一套精巧的机制来保证副本间的一致性。
-
同步过程(Pull 模式)
-
生产者写入:生产者将消息发送给分区的 Leader 副本 。
-
Leader 本地持久化:Leader 将消息顺序追加到本地的 Commit Log 中,并更新自己的 LEO(Log End Offset,日志末端偏移量)。
-
Follower 拉取:各个 Follower 副本会启动独立的线程(如
ReplicaFetcherThread),定期向 Leader 发送 FETCH 请求,拉取新消息 。 -
Follower 本地持久化:Follower 将拉取到的消息写入自己的本地日志,并更新自身的 LEO,然后向 Leader 返回一个确认(ACK)。
-
-
ISR 机制与动态成员管理
ISR 是理解 Kafka 副本机制的关键。它不是一个固定的集合,而是一个与 Leader 保持“同步”的 Follower 副本的动态列表(包括 Leader 自身)。
-
入队标准:一个 Follower 副本若能持续地、在配置的时间阈值(
replica.lag.time.max.ms,如10秒)内与 Leader 保持同步(即追赶 Leader 的 LEO),就会被保留在 ISR 中 。 -
出队机制:如果一个 Follower 副本落后 Leader 太多(例如,由于网络故障或自身负载过高),并且持续时间超过了阈值,Leader 会将其从 ISR 中移除,放入 OSR(Out-of-Sync Replicas)集合。这意味着它暂时失去了被选举为 Leader 的资格 。
-
-
高水位与消息可见性
-
HW 的定义:高水位是一个分区级别的偏移量标记。它被定义为 ISR 集合中所有副本 LEO 的最小值 。它代表了一个消息提交的界限。
-
消息安全性:只有位移小于 HW 的消息才被认为是“已提交的”。这意味着这些消息已经被 ISR 中的所有副本成功复制,即使 Leader 立刻崩溃,数据也不会丢失 。
-
消费者可见性:消费者只能消费到 HW 之前的消息。HW 之后的消息,即使已经被 Leader 写入,但对消费者是不可见的,因为它们尚未被足够多的副本确认,处于“未提交”的不安全状态 。
-
当故障发生时,这套机制能自动恢复。
-
Leader 选举:当 Leader 副本失效时,Kafka 集群的 Controller 组件会立即介入,并从当前ISR 集合中选举一个新的 Leader(默认是 ISR 中的第一个副本)。优先从 ISR 中选举能最大程度保证数据一致性,因为新 Leader 拥有最完整的数据。
-
数据修复与截断:新的 Leader 开始工作后,其他 Follower 会从它这里同步数据。如果某个 Follower 副本之前因为故障持有一些未提交的脏数据(HW 之后的消息),在恢复同步时,它需要将这些数据截断,并重新从新的 Leader 拉取,以保持数据一致 。
ISR机制
ISR 的全称是 In-Sync Replicas(同步副本集)。要理解它,我们首先需要了解几个基本概念:
-
AR (Assigned Replicas):指分配给某个分区的所有副本的集合。
-
Leader 副本:负责处理该分区所有读写请求的副本。生产者发送的消息总是先写入 Leader 副本。
-
Follower 副本:从 Leader 副本异步拉取数据,作为数据冗余的备份副本。
-
OSR (Out-of-Sync Replicas):指那些由于网络延迟、机器故障等原因,导致其数据进度显著落后于 Leader 的 Follower 副本集合。
因此,这三者的关系是:AR = ISR + OSR。ISR 就是 AR 中那些与 Leader 副本保持“同步”的“健康”子集,通常包括 Leader 本身和那些同步进度良好的 Follower 副本
ISR 机制的核心在于其动态性和基于时间的判断标准。
-
动态维护:Leader 副本负责实时监控所有 Follower 副本的同步状态。判断一个 Follower 是否“同步”的关键参数是
replica.lag.time.max.ms(默认10秒或30秒)。如果一个 Follower 副本在此时间窗口内未能成功从 Leader 拉取数据(例如,没有发送拉取请求或其数据进度落后),Leader 就会将其从 ISR 列表中移除,降级为 OSR。反之,当 OSR 中的副本重新追上了 Leader 的数据进度,又会被重新纳入 ISR。 -
高水位线 (HW) 与消息提交:这是保证一致性的关键。HW(High Watermark)代表已提交消息的偏移量,即消费者可以读取到的最大位置。一条消息只有在被 ISR 中所有副本都成功复制后,Leader 才会推进 HW,这条消息才被视为“已提交”,从而对消费者可见。这样可以防止消费者读到那些仅存在于 Leader 但可能因故障丢失的“未提交”消息。
ISR 如何平衡一致性与可用性?
ISR 机制的精妙之处在于它没有采用代价高昂的“全部副本确认”的强一致性方案,也没有采用风险较高的“Leader确认即成功”的弱一致性方案,而是找到了一个动态的平衡点。
下表清晰地展示了 ISR 机制在不同场景下如何通过关键配置来权衡一致性和可用性:
|
机制/场景 |
对一致性的影响 |
对可用性的影响 |
关键配置参数 |
|---|---|---|---|
|
生产者 ACK 机制 |
|
|
|
|
Leader 选举 |
|
若 ISR 全挂,分区不可用,牺牲可用性。 |
|
|
最小同步副本数 |
|
若存活副本数少于设定值,分区拒绝写入,牺牲可用性。 |
|
高水位(HW)和日志末端位移(LEO)
|
概念 |
全称 |
定义 |
核心作用 |
|---|---|---|---|
|
LEO |
Log End Offset |
每个副本(包括Leader和Follower)独有的指针,指向其日志文件中下一条待写入消息的位置。例如,若已写入10条消息(offset 0-9),则LEO=10。 |
跟踪每个副本的实时写入进度。 |
|
HW |
High Watermark |
分区级别的全局标记,其值是所有处于同步状态的副本(ISR)的LEO中的最小值。它标识了已提交消息的边界。 |
定义消息的可见性和安全性。消费者只能消费HW之前的消息。 |
核心关系:在一个分区内,任何副本的 HW ≤ 其自身的 LEO。并且,对于Leader副本,其 HW = min(ISR中所有副本的LEO)。
如何保证数据不丢失?
Kafka通过一套精巧的流程,让HW和LEO协同工作,确保数据在分布式环境下不会丢失。这套机制的核心是 “已提交” 状态。
1. 消息提交与可见性
-
一条消息只有在被ISR中的所有副本都成功复制后,才被认为是“已提交”。
-
HW的推进标志着消息的提交。只有HW之前的消息才对消费者可见。这意味着,即使Leader副本所在Broker突然宕机,由于ISR中至少有一个Follower副本也拥有了这条消息,数据不会丢失。
2. 故障恢复与数据一致性
当故障发生时,HW是恢复数据一致性的基准:
-
Follower副本故障:当发生故障的Follower副本恢复后,它会将自己的日志截断到本地记录的HW处,然后从Leader重新同步HW之后的数据。这确保了它不会含有任何未被ISR确认的“脏数据”。
-
Leader副本故障:当Leader宕机,Kafka会从ISR中选举一个新的Leader。新Leader上台后,所有Follower副本会将自己的日志截断到各自记录的HW处,然后从新Leader同步。这个过程会丢弃所有HW之后未被确认的消息,虽然可能造成少量数据丢失,但严格保证了分区内所有副本的数据最终一致性。
Kafka为什么这么快?
写入优化:将随机写变为顺序写
这是Kafka高性能的基石。
-
顺序追加写入:Kafka 将所有消息严格按顺序追加到日志文件末尾,只进行追加操作而不修改已有数据。这种顺序I/O 的性能远超随机I/O,因为在传统机械硬盘上,顺序I/O可以避免磁头频繁寻道,其性能可能与内存的随机读写相当甚至更快。即便是固态硬盘,顺序I/O也能更好地发挥其性能。
-
批处理与延迟:生产者发送消息时并非“来一条发一条”,而是会在内存中积攒一批消息,然后一次性发送到Broker。这通过参数
batch.size(批量大小)和linger.ms(等待时间)控制。它将大量小的网络IO请求合并为少量大的IO,极大地提高了网络吞吐量和Broker的写入效率。
存储优化:高效的数据组织与缓存
-
分段日志与稀疏索引:一个主题的分区在物理上被划分为多个段。当某个日志段文件达到一定大小后,就会滚动创建新的文件。这样做便于老旧数据的删除和索引的维护。Kafka还为每个日志段建立了稀疏索引,它不会为每条消息创建索引项,而是每隔一定字节的数据建立一条索引。在查找消息时,先通过索引快速定位到大致区域,再在该区域内进行少量顺序扫描,从而在索引文件大小和查询效率之间取得完美平衡。
-
利用页缓存:Kafka 重度依赖操作系统的页缓存,而非在JVM堆内存中缓存数据。消息写入时,直接进入页缓存;消息读取时,也优先从页缓存中查找。这样做的好处极大:
-
避免GC开销:避免了在JVM中管理大量缓存对象带来的垃圾回收开销。
-
利用OS优化:操作系统会使用空闲内存作为页缓存,读写速度接近内存。
-
重启缓存不失效:即使Broker重启,页缓存中的数据也不会立刻清空,热数据依然有效
-
读取优化:零拷贝与并行消费
-
零拷贝技术:这是提升消费端性能的关键。在传统的数据读取流程中,数据从磁盘到网卡需要经历4次上下文切换和4次数据拷贝。而Kafka通过调用
sendfile系统调用,实现了零拷贝,数据可以直接从磁盘的页缓存通过网络接口卡发送出去,无需拷贝到用户空间。这消除了不必要的CPU拷贝和上下文切换,显著降低了CPU开销和延迟。 -
分区与消费者组:Kafka通过分区实现了数据的天然并行。一个主题可以被分为多个分区,分散在不同的Broker上。消费者组模型允许多个消费者并行消费同一个主题的不同分区,水平扩展了消费能力。这是Kafka能够支撑高吞吐读请求的架构基础。
整体协作与其它优化
-
高效的序列化与压缩:生产者支持在发送前对整批消息进行压缩,减少网络传输和磁盘占用的带宽。Kafka内部使用高效的二进制格式进行通信,进一步减少了开销。
-
无锁设计:在Broker端,每个分区的Leader在处理写入请求时,由于是顺序追加,可以避免复杂的锁竞争,简化了处理流程,提高了并发性。
顺序I/O
Kafka 之所以能实现极高的吞吐量,其核心秘诀之一就在于它彻底摒弃了随机磁盘I/O,转而全面拥抱顺序I/O(追加写)。
传统观念认为“磁盘慢”,但这其实是对随机I/O而言的。磁盘操作中最耗时的部分是寻道(移动磁头到正确磁道)和旋转延迟(等待盘片旋转到正确扇区),这个过程可能耗时数毫秒至十几毫秒。而真正传输数据的时间反而很短。
Kafka 的巧妙之处在于,它通过只追加(Append-only) 的方式写入消息,将大量的随机小写操作转换为连续的批量大顺序写。这样,磁头几乎无需大幅度移动,可以持续不断地写入数据,从而将磁盘的顺序读写性能(机械硬盘可达 100-200 MB/s,SSD 可达数 GB/s)发挥到极致,其性能甚至可以媲美内存的随机访问。
Kafka 的 I/O 设计哲学深受日志结构文件系统的影响。
-
只追加的日志:Kafka 将每个分区(Partition) 本质上视为一个只能追加写入的日志文件。生产者发送的新消息被严格地、连续地追加到文件的末尾,永不允许修改或删除已有数据。这种不可变性(Immutable)简化了并发控制和数据一致性保证。
-
分段滚动:为了防止单个日志文件无限增大,Kafka 采用了分段(Segment) 机制。当当前活跃的日志文件达到一定大小(例如 1GB)后,就会“滚动”创建一个新的文件继续写入。这种机制不仅便于文件管理,也使得清理过期数据变得非常简单高效——直接删除整个旧的 Segment 文件即可,这依然是顺序大块操作,避免了在文件内部随机删除导致的碎片化和性能抖动。
Kafka中的零拷贝
传统方法 read+ write低效。当需要发送一个文件时,传统的步骤是:
-
读取文件:程序调用
read函数。这会导致一次上下文切换(从用户态切换到内核态)。然后,数据通过 DMA 技术从硬盘直接拷贝到内核缓冲区。接着,数据又由 CPU 从内核缓冲区拷贝到用户缓冲区,此时发生第二次上下文切换(切换回用户态)。 -
发送数据:程序调用
write函数。这引发第三次上下文切换(用户态到内核态)。CPU 再次将数据从用户缓冲区拷贝到内核的 Socket 缓冲区。最后,数据通过 DMA 从 Socket 缓冲区拷贝到网卡进行发送。完成后,第四次上下文切换发生(内核态回用户态)。
sendfile系统调用设计得非常巧妙,它通过“绕过”用户空间,直接在操作系统内核中完成文件数据的传输。其核心流程如下:
- DMA 将文件数据从磁盘拷贝到内核缓冲区(读缓存)。这一步由 DMA 完成,无需 CPU 参与。
- 然后,内核将数据直接从内核缓冲区拷贝到相关的内核 Socket 缓冲区。注意,这个拷贝操作是在内核内部完成的,不需要将数据拷贝到用户空间。
- 最后,DMA 将数据从 Socket 缓冲区拷贝到网卡,发送出去。
基于上述原理,sendfile带来的性能提升主要来自两方面:
-
减少数据拷贝次数:这是最直接的收益。它消除了两次不必要的 CPU 数据拷贝(内核缓冲区到用户缓冲区,用户缓冲区到 Socket 缓冲区),将 4 次拷贝减少到 2 次,显著降低了 CPU 的负担。
-
减少上下文切换:由于整个过程都在内核态完成,避免了在用户态和内核态之间频繁切换(从 4 次减少到 2 次)。上下文切换是昂贵的系统操作,减少它能有效提升系统效率。
批处理和消息压缩
如果 Producer 每产生一条消息就立即发送,会产生大量的小网络数据包,导致网络利用率低下,并给 Broker 带来巨大的请求处理压力。批处理就是解决这个问题的方案。
核心组件:RecordAccumulator
Producer 内部有一个核心的内存缓冲区,称为 RecordAccumulator。
-
按分区打包:
RecordAccumulator为每个分区维护一个Deque<ProducerBatch>(双端队列),里面存放着多个ProducerBatch(生产批次)。当消息经过序列化和分区计算后,会被追加到对应分区的队列中。如果当前批次未满且有空间,则直接追加;如果批次已满或没有可用批次,则创建一个新的批次。 -
ProducerBatch:这是批处理的基本单位。一个ProducerBatch包含了一批消息(多条ProducerRecord),它最终会被封装成一个网络请求ProduceRequest发送给 Broker。
发送触发条件
Sender 线程不会无休止地等待。它会在以下条件满足之一时,将批次从 RecordAccumulator中取出并发送:
-
批次已满:一个
ProducerBatch的大小达到了配置的batch.size(例如 16KB)。 -
等待超时:从第一条消息进入批次开始计时,超过了配置的
linger.ms(例如 0ms,表示立即发送;或设为 5ms 以等待更多消息填充批次)。 -
其他条件:
RecordAccumulator内存耗尽、Producer 即将关闭等。
即使消息被打包成批次,如果消息内容本身很大(例如 JSON 日志),网络传输和磁盘存储的成本依然很高。消息压缩就是在发送前,将整个批次的消息进行压缩,以节省带宽和存储空间。
压缩的时机与粒度
-
Producer 端压缩:压缩发生在 Producer 客户端,在 Sender 线程将批次发送到网络之前。压缩的最小单位是整个
ProducerBatch,而不是单条消息。这意味着,更大的批次通常能获得更好的压缩率。 -
端到端压缩:被压缩的批次会保持压缩状态发送到 Broker,并以压缩形式存储在磁盘上。当 Consumer 拉取消息时,收到的仍然是压缩的数据,需要在 Consumer 端进行解压。这种设计避免了 Broker 解压和再压缩
Kafka 支持多种压缩算法,各有优劣:
|
算法 |
压缩比 |
压缩/解压速度 |
CPU 开销 |
适用场景 |
|---|---|---|---|---|
|
GZIP |
最高 |
最慢 |
高 |
网络带宽极其昂贵,且对延迟不敏感的场景。 |
|
Snappy |
中等 |
非常快 |
低 |
通用推荐,在压缩比和速度间取得了良好平衡,由 Google 开发。 |
|
LZ4 |
中等偏高 |
最快 |
非常低 |
极致性能场景,当 CPU 资源紧张或追求最低延迟时首选。 |
|
Zstandard (zstd) |
接近 GZIP |
比 Snappy 稍慢,但比 GZIP 快很多 |
中等 |
新一代算法,在压缩比和速度上都有很好表现,是未来趋势。 |
选择时需要考虑:
-
如果网络带宽是瓶颈,优先选择压缩比高的算法(如 GZIP, zstd)。
-
如果CPU 资源是瓶颈,或追求端到端最低延迟,优先选择速度快的算法(如 LZ4, Snappy)。
一些基本问题
如何保证消息不丢失
Kafka 通过生产、存储、消费三个环节的协同机制来保证消息不丢失。
生产者端保证
-
acks=all(或-1):要求 Leader 收到消息后,必须等待所有 ISR 中的副本都同步成功才返回确认。这是最强的可靠性保证。 -
min.insync.replicas:与acks=all配合使用,定义 ISR 的最小副本数(包括 Leader)。例如设置为 2,即使只有一个副本存活,写入也会失败,防止数据冗余不足。 -
重试机制:设置
retries为较大值(如Integer.MAX_VALUE)并启用幂等性(enable.idempotence=true),确保网络抖动等临时故障不会导致消息丢失。 -
同步发送:使用
send().get()或带回调的异步发送,确保及时获知发送失败并进行处理。
Broker 端保证
-
副本机制:设置
replication.factor >= 3,确保消息有多个副本。 -
ISR 机制:Leader 维护一个同步副本列表(ISR),只有 ISR 中的副本才参与选举和数据同步,防止落后副本成为 Leader 导致数据丢失。
-
持久化:虽然 Kafka 依赖操作系统页缓存异步刷盘,但可通过
flush.messages和flush.ms控制刷盘频率,极端情况下可设置log.flush.interval.messages=1和log.flush.interval.ms=1000来更频繁刷盘(但会牺牲性能)。
消费者端保证
-
手动提交偏移量:禁用自动提交(
enable.auto.commit=false),在消息处理完成后再手动提交偏移量,确保“消费后才提交”。 -
正确处理偏移量:在消费者均衡(Rebalance)或重启时,确保偏移量提交到正确的消息位置,避免重复消费或丢失。
如何处理消息重复
Kafka 提供“至少一次”语义,消息重复不可避免,需在消费端实现幂等性。
重复产生的原因
-
生产者重试:网络超时导致生产者未收到确认而重发,Broker 可能收到重复消息。
-
消费者重平衡:消费者组发生重平衡时,可能重复提交偏移量,导致消息被重复消费。
-
消费者提交偏移量失败:消息处理后,提交偏移量前消费者崩溃,重启后从上次提交的偏移量重新消费。
解决方案
-
生产者端:启用幂等性(
enable.idempotence=true),Kafka 会为每个生产者分配唯一 ID 并为消息分配序列号,Broker 据此去重。 -
消费者端:实现业务逻辑的幂等性,常用方法:
-
数据库唯一约束:利用主键或唯一索引去重。
-
Redis 原子操作:使用
SETNX命令或分布式锁。 -
状态机:业务状态流转时,确保只有当前状态才能转到下一状态。
-
如何处理消息积压
消息积压是消费速度低于生产速度导致的。处理思路是“先治标,再治本”。
临时扩容(治标)
-
增加分区数:分区是并行消费的最小单位。增加分区数可提升消费能力,但需重启集群。
-
增加消费者实例:确保消费者实例数不超过分区数,否则多余的消费者闲置。
-
调整消费者参数:
-
fetch.min.bytes:增加每次拉取的最小字节数,提高吞吐量但增加延迟。 -
max.poll.records:增加单次拉取的消息数。 -
调整
session.timeout.ms和max.poll.interval.ms,避免误判消费者死亡而触发重平衡。
-
优化消费逻辑(治本)
-
批量处理:将多次数据库操作合并为批量操作,减少 I/O。
-
异步处理:将非关键操作异步化,避免阻塞主流程。
-
优化代码:检查消费逻辑是否存在性能瓶颈,如复杂计算、低效查询等。
如何保证消息有序
Kafka 仅保证分区内有序,不保证全局有序。
分区内有序
-
生产者:将需要有序的消息指定相同的 Key,Kafka 根据 Key 的哈希值将消息发送到同一分区。设置
max.in.flight.requests.per.connection=1可确保同一连接上的消息按发送顺序写入,但会降低吞吐量。 -
消费者:使用单线程按分区消费,一个分区只能被一个消费者线程消费。
全局有序
-
将 Topic 设置为单分区,但会严重限制吞吐量,仅适用于消息量极小的场景。
-
使用事务和幂等性生产者确保跨分区的原子性写入,但无法保证跨分区消费的顺序。
如何实现消息过滤
Kafka 本身不提供类似 RocketMQ 的 Tag 或 SQL 过滤功能,但可通过以下方式实现:
消费者端过滤
-
代码中过滤:消费者拉取消息后,在业务代码中根据条件过滤。简单但浪费带宽和 CPU。
for (ConsumerRecord<String, String> record : records) { if (record.key().equals("important")) { process(record); } }
流处理过滤
-
Kafka Streams:使用 Kafka Streams API 将原始 Topic 过滤后写入新 Topic,消费者消费新 Topic。
KStream<String, String> source = builder.stream("source-topic");
KStream<String, String> filtered = source.filter((key, value) -> value.contains("important"));
filtered.to("filtered-topic");使用 Connect 或第三方工具
-
Kafka Connect:配合单消息转换(SMT)进行过滤。
-
Flink/Spark Streaming:使用流处理框架进行复杂过滤和转换。
分区策略过滤
-
将不同类型的数据写入不同的 Topic,消费者按需订阅。
-
使用 Key 进行分区,相同类型的数据集中在特定分区,消费者可选择消费特定分区(但不推荐,破坏了负载均衡)。
如何实现延时消息
Kafka 原生不支持延时消息,需通过以下方式模拟:
消费者轮询(延迟消费)
-
消息包含期望的执行时间戳,消费者拉取后,若未到时间则暂停消费该分区(使用
pause()),并记录该消息。通过定时任务或延迟队列在到期后恢复消费(resume())。 -
缺点:实现复杂,可能影响其他消息的消费。
多级 Topic 方案
-
创建多个延迟级别 Topic(如
delay-1s、delay-5s、delay-30s)。 -
生产者将延迟消息发送到对应延迟级别的 Topic。
-
消费者消费延迟 Topic,到期后转发到目标 Topic。
-
最终消费者消费目标 Topic。
如何实现死信队列
Kafka 没有内置死信队列(DLQ),但可基于其重试机制模拟实现。
重试机制
-
消费者消费失败时,可将消息发送到重试 Topic,并设置延迟时间(通过时间戳或延迟 Topic 方案)。
-
重试 Topic 由专门的重试消费者消费,失败多次后转入死信 Topic。
实现步骤
-
定义重试 Topic 和死信 Topic:
-
original-topic:原始 Topic。 -
retry-topic-1、retry-topic-2:多级重试 Topic。 -
dead-letter-topic:死信 Topic。
-
-
消费者逻辑:
try { process(message); consumer.commitSync(); } catch (Exception e) { int retryCount = getRetryCount(message); if (retryCount >= MAX_RETRIES) { // 发送到死信队列 sendToDeadLetterTopic(message); consumer.commitSync(); // 跳过该消息 } else { // 发送到重试队列,设置延迟时间 sendToRetryTopic(message, retryCount + 1); consumer.commitSync(); } } -
重试消费者:消费重试 Topic,将消息重新发送回原始 Topic 或下一级重试 Topic。、
-
使用 Kafka Streams 的
branch()或flatMap()将处理失败的消息路由到死信 Topic。KStream<String, String> stream = builder.stream("input-topic"); KStream<String, String>[] branches = stream.branch( (key, value) -> processSuccessfully(value), // 成功 (key, value) -> true // 失败 ); branches[0].to("success-topic"); branches[1].to("dead-letter-topic");
-
Kafka 在消息不丢失、顺序性方面提供了较强的原生支持,但在消息过滤、延时消息、死信队列等方面需要结合业务逻辑或外部系统实现。理解其设计哲学(追求高吞吐、可扩展性)有助于合理选择解决方案。在实际应用中,常将 Kafka 与流处理框架(如 Kafka Streams、Flink)结合,构建更复杂的消息处理管道。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 14
14 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)