基于麻雀搜索优化kmeans(SSA-kmeans)的图像分割算法(Matlab代码实现)
K - means算法是一种常用的聚类算法,基本流程包括假设将数据分成k个cluster,从所有点中随机选k个点作为初始中心点,计算其他点与这些中心点的距离,将点划分到距离最近的簇中,然后根据簇内的点重新计算簇中心,不断重复这个过程。通过引入麻雀搜索算法对K - means算法进行优化,克服了K - means算法在初始化阶段容易陷入局部最优的问题,从而提高了图像分割的精度,能够更精确地对图像中的
💥💥💞💞欢迎来到本博客❤️❤️💥💥
🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。
⛳️座右铭:行百里者,半于九十。
💥1 概述
麻雀搜索算法是一种基于群体智能的算法,它的基本思想是将问题抽象为一个个体的适应度函数,在群体的协作下逐步逼近最优解。在图像分割问题中,麻雀搜索算法可以被用作优化KMeans算法的初始化和结果后处理,从而对图像进行更精确的分割。
具体实现步骤如下:
1. 对输入图像进行预处理,例如缩小或降采样,以节省计算资源和时间。
2. 初始化麻雀种群。将像素点的RGB值作为特征向量,随机生成若干个麻雀作为初始种群。
3. 对每个麻雀计算适应度函数。在适应度函数中,将一个麻雀看作是KMeans算法的一个聚类中心,将每个像素点归类到最近的聚类中心上。
4. 计算种群中的个体适应度值的最大值和最小值,以及每个个体的适应度占比。
5. 根据适应度占比确定麻雀之间的竞争关系,并随机选择一部分优胜的麻雀生成新的种群。
6. 对新生成的种群中的每个麻雀进行变异和交叉操作,并对变异和交叉后的个体计算适应度函数。
7. 轮流执行步骤4-6,直到达到预定的迭代次数或者收敛阈值。
8. 使用优化后的聚类中心进行最终的图像分割。
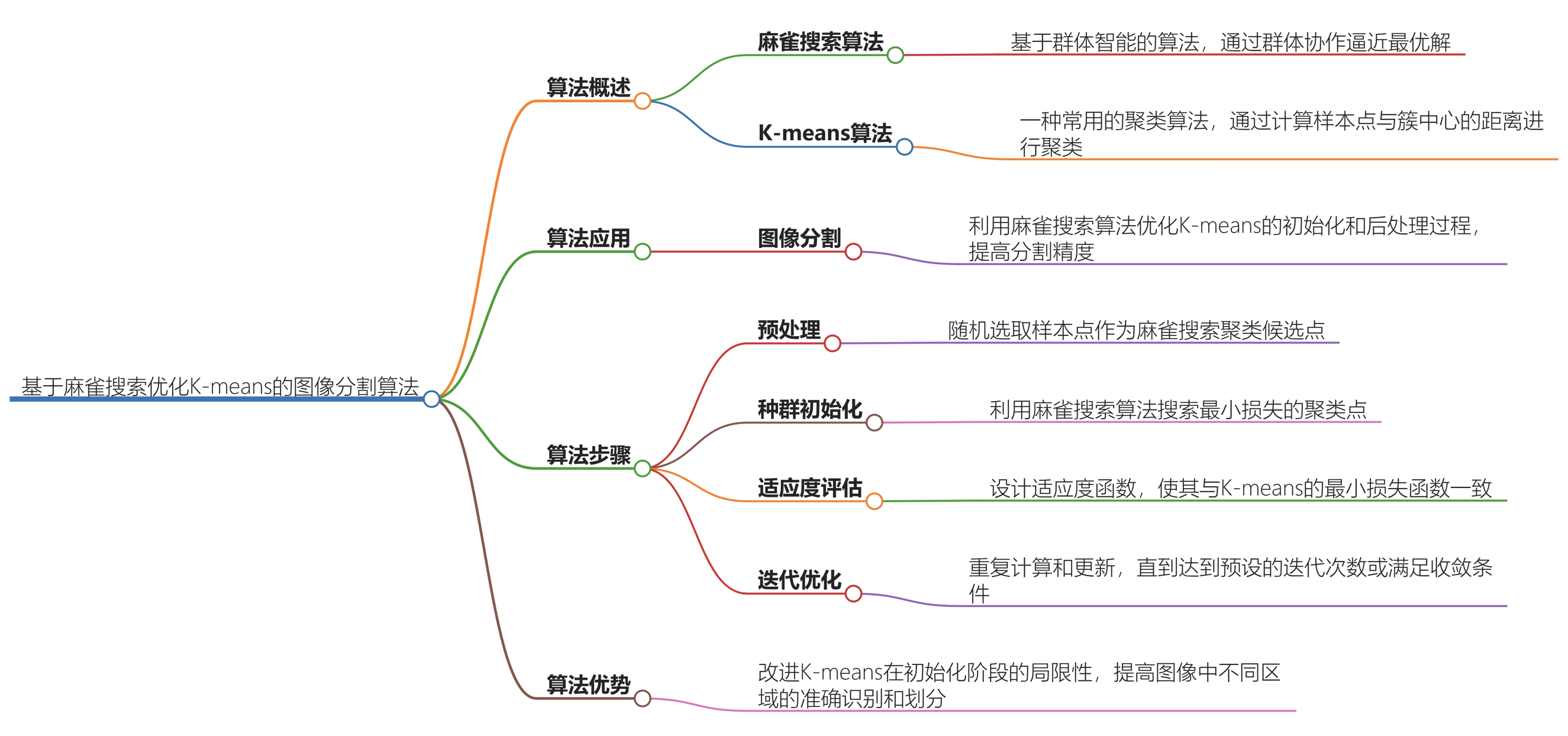
一、算法概述
-
麻雀搜索算法简介
-
麻雀搜索算法是一种基于群体智能的算法,它的基本思想是将问题抽象为一个个体的适应度函数,在群体的协作下逐步逼近最优解[1] 。
-
-
K - means算法及其局限性
-
K - means算法是一种常用的聚类算法,基本流程包括假设将数据分成k个cluster,从所有点中随机选k个点作为初始中心点,计算其他点与这些中心点的距离,将点划分到距离最近的簇中,然后根据簇内的点重新计算簇中心,不断重复这个过程。但是其得到的聚类结果严重依赖于初始簇中心的选择,如果初始簇中心选择不好,就会陷入局部最优解[3] 。
-
二、基于麻雀搜索优化K - means的图像分割算法
(一)算法原理
-
优化目标
-
利用麻雀搜索算法对K - means算法的初始簇中心进行优化,改进其容易陷入局部最优的特点,以提高图像分割的效果。
-
-
适应度函数
-
在利用麻雀搜索算法改进K - means时,以聚类中心作为麻雀算法的优化变量,适应度函数与K - means的最小损失函数一致[3] 。
-
(二)算法步骤
-
预处理
-
对于图像,选取一定比例(例如10%)的像素点作为聚类候选点[3] 。
-
-
种群初始化
-
随机抽样待分类数据点,作为麻雀搜索聚类候选点[3] 。
-
-
适应度评估
-
利用麻雀搜索算法搜索最小损失的聚类点,这里涉及到计算种群中的个体适应度值的最大值和最小值,以及每个个体的适应度占比等操作[1] 。
-
-
迭代优化
-
将麻雀搜索得到的聚类点作为K - means算法的初始聚类点,然后利用K - means算法获得最终的聚类点。在这个过程中,可能还需要对新生成的种群中的每个麻雀进行变异和交叉操作,并对变异和交叉后的个体计算适应度函数[1] 。
-
三、算法实现(Matlab代码示例)
-
以下是基于麻雀搜索优化K - means图像分割算法的Matlab代码实现的大致框架:
-
数据读取与预处理部分
-
读取图像数据,并按照前面提到的选取部分像素点作为聚类候选点。
-
-
麻雀搜索算法相关函数定义
-
定义麻雀搜索算法中的适应度函数计算、种群初始化、变异和交叉操作等函数。
-
-
K - means算法结合麻雀搜索的实现
-
根据麻雀搜索得到的优化后的初始聚类中心,运行K - means算法得到图像分割结果。
-
-
四、算法的优势与应用场景
-
优势
-
通过引入麻雀搜索算法对K - means算法进行优化,克服了K - means算法在初始化阶段容易陷入局部最优的问题,从而提高了图像分割的精度,能够更精确地对图像中的不同区域进行准确识别和划分。
-
-
应用场景
-
适用于诸如图像背景分割、物体检测等应用场景,在这些场景中,准确的图像分割是进行后续处理(如目标识别、特征提取等)的重要基础[3] 。
-
📚2 运行结果




部分代码:
%_________________________________________________________________________%
% 麻雀优化算法 %
%_________________________________________________________________________%
function [Best_pos,Best_score,curve]=SSA(pop,Max_iter,lb,ub,dim,fobj)
ST = 0.6;%预警值
PD = 0.7;%发现者的比列,剩下的是加入者
SD = 0.2;%意识到有危险麻雀的比重
PDNumber = pop*PD; %发现者数量
SDNumber = pop - pop*PD;%意识到有危险麻雀数量
if(max(size(ub)) == 1)
ub = ub.*ones(1,dim);
lb = lb.*ones(1,dim);
end
%种群初始化
X0=initialization(pop,dim,ub,lb);
X = X0;
%计算初始适应度值
fitness = zeros(1,pop);
for i = 1:pop
fitness(i) = fobj(X(i,:));
end
[fitness, index]= sort(fitness);%排序
BestF = fitness(1);
WorstF = fitness(end);
GBestF = fitness(1);%全局最优适应度值
for i = 1:pop
X(i,:) = X0(index(i),:);
end
curve=zeros(1,Max_iter);
GBestX = X(1,:);%全局最优位置
X_new = X;
for i = 1: Max_iter
BestF = fitness(1);
WorstF = fitness(end);
R2 = rand(1);
for j = 1:PDNumber
if(R2<ST)
X_new(j,:) = X(j,:).*exp(-j/(rand(1)*Max_iter));
else
X_new(j,:) = X(j,:) + randn()*ones(1,dim);
end
end
for j = PDNumber+1:pop
% if(j>(pop/2))
if(j>(pop - PDNumber)/2 + PDNumber)
X_new(j,:)= randn().*exp((X(end,:) - X(j,:))/j^2);
else
%产生-1,1的随机数
A = ones(1,dim);
for a = 1:dim
if(rand()>0.5)
A(a) = -1;
end
end
AA = A'*inv(A*A');
X_new(j,:)= X(1,:) + abs(X(j,:) - X(1,:)).*AA';
end
end
Temp = randperm(pop);
SDchooseIndex = Temp(1:SDNumber);
for j = 1:SDNumber
if(fitness(SDchooseIndex(j))>BestF)
X_new(SDchooseIndex(j),:) = X(1,:) + randn().*abs(X(SDchooseIndex(j),:) - X(1,:));
elseif(fitness(SDchooseIndex(j))== BestF)
K = 2*rand() -1;
X_new(SDchooseIndex(j),:) = X(SDchooseIndex(j),:) + K.*(abs( X(SDchooseIndex(j),:) - X(end,:))./(fitness(SDchooseIndex(j)) - fitness(end) + 10^-8));
end
end
%边界控制
for j = 1:pop
for a = 1: dim
if(X_new(j,a)>ub)
X_new(j,a) =ub(a);
end
if(X_new(j,a)<lb)
X_new(j,a) =lb(a);
end
end
end
%更新位置
for j=1:pop
fitness_new(j) = fobj(X_new(j,:));
end
for j = 1:pop
if(fitness_new(j) < GBestF)
GBestF = fitness_new(j);
GBestX = X_new(j,:);
end
end
X = X_new;
fitness = fitness_new;
%排序更新
[fitness, index]= sort(fitness);%排序
BestF = fitness(1);
WorstF = fitness(end);
for j = 1:pop
X(j,:) = X(index(j),:);
end
curve(i) = GBestF;
end
Best_pos =GBestX;
Best_score = curve(end);
end
🎉3 参考文献
文章中一些内容引自网络,会注明出处或引用为参考文献,难免有未尽之处,如有不妥,请随时联系删除。
[1]吕鑫,慕晓冬,张钧.基于改进麻雀搜索算法的多阈值图像分割[J].系统工程与电子技术, 2021.DOI:10.12305/j.issn.1001-506X.2021.02.05.
[2]胡春安,王丰奇,朱东林.改进麻雀搜索算法及其在红外图像分割的应用[J].红外技术, 2023, 45(6):605-612.
🌈4 Matlab代码实现

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 0
0 0
0- 0



 已为社区贡献43条内容
已为社区贡献43条内容

所有评论(0)