基于图像处理与深度学习的工人安全作业监测系统的设计与实现
工人安全作业监测系统运用了改进的YOLOv8-MEU算法解决了建筑工地工人安全帽佩戴实时检测的问题,实现了图片、视频和实时摄像头流的安全帽佩戴状态监测功能。对于计算机专业、软件工程专业、人工智能专业、大数据专业的毕业生而言,选择一个合适的毕业设计选题至关重要。在这个毕业设计选题合集中,我们精心收集了各种有趣且具有挑战性的选题,旨在帮助学生们在毕业设计中展现他们的技术实力和创新能力。不论是对于对深度
目录
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
选题指导:
大家好,这里是海浪学长毕设专题,本次分享的课题是:
🎯基于图像处理与深度学习的工人安全作业监测系统的设计与实现
选题意义背景
建筑行业的快速发展和智能化转型,工地安全管理面临着新的机遇与挑战。建筑施工安全一直是工程建设领域的重要关注点,其中工人安全帽的正确佩戴是保障施工人员生命安全的基本要求。然而,传统的人工巡检方式存在效率低下、覆盖范围有限、容易出现人为疏忽等问题,难以满足现代建筑工地大规模、复杂化的安全管理需求,随着计算机视觉技术和深度学习算法的飞速发展,基于人工智能的安全监测系统逐渐成为建筑安全管理的新趋势。期间,深度学习在目标检测领域取得了显著突破,特别是以YOLO系列为代表的单阶段目标检测算法,在实时性和准确性方面都达到了新的高度。这些技术的成熟为实现自动化、智能化的工人安全作业监测提供了坚实的技术基础。
智慧工地理念强调通过信息技术提升建筑工地的精细化管理水平,其中安全管理是核心内容之一。基于深度学习的工人安全作业监测系统作为智慧工地的重要组成部分,可以与其他管理系统集成,形成全方位、多层次的安全防护体系,推动建筑行业向更加安全、高效、智能的方向发展,随着计算机视觉技术在各行各业的广泛应用,基于深度学习的目标检测算法也在不断优化和创新。近年,轻量级网络架构、注意力机制、先进损失函数等技术的发展,为解决复杂场景下的目标检测问题提供了新的思路。将这些最新技术应用于工人安全作业监测领域,不仅可以提升系统性能,还可以推动相关技术的落地应用和创新发展。
数据集
本研究构建了一个全面且高质量的安全帽检测数据集,用于训练和评估改进的YOLOv8-MEU模型。数据集的构建过程包括数据获取、数据预处理、数据标注和数据分割等多个环节,确保了数据的多样性、准确性和有效性。
数据获取
为了构建丰富多样的数据集,研究采用了多种数据获取方式:
-
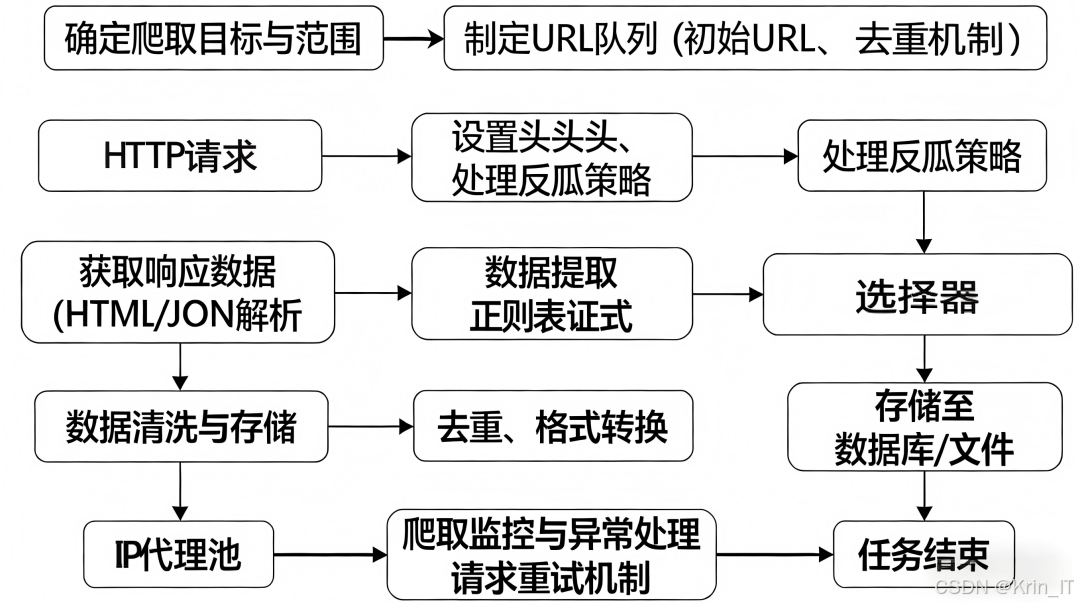
网络爬虫采集:通过设计专门的网络爬虫程序,从互联网上收集了大量与安全帽相关的图像数据。爬虫程序针对建筑施工、工业生产等场景,定向搜索包含工人佩戴或未佩戴安全帽的图片资源。在爬取过程中,严格遵守相关网站的robots协议和版权规定,确保数据获取的合法性和合规性。
-
视频截取:收集了多个建筑工地的监控视频,通过视频帧提取技术,从视频中截取关键帧作为数据集的重要组成部分。这些视频数据包含了真实施工场景中的各种情况,如不同时间段、不同天气条件下的工人作业状态,为模型提供了丰富的真实场景样本。
-
现场拍摄:在确保安全的前提下,研究团队还在部分建筑工地进行了现场拍摄,获取了第一手的真实数据。现场拍摄特别关注了不同角度、不同距离下工人的安全帽佩戴情况,以及各种复杂环境因素(如强光、阴影、遮挡等)对检测的影响。
数据格式
收集到的图像数据主要为JPG和PNG格式,分辨率从320×240到1920×1080不等。为了统一处理,对所有图像进行了标准化处理,将其调整为统一的尺寸格式。处理后的数据集包含以下基本信息:
- 总图像数量:23088张
- 图像格式:统一为JPG格式
- 标准分辨率:640×640像素
- 数据存储:按类别和来源进行分类存储,便于管理和使用
数据集的规模在经过筛选和处理后,最终用于模型训练和测试的图像数量为7581张,其中包含了不同场景下工人佩戴和未佩戴安全帽的各种情况,确保了数据集的多样性和代表性。
数据集的类别定义主要分为两个类别:
- 佩戴安全帽(helmet):包含所有正确佩戴安全帽的工人头部区域
- 未佩戴安全帽(head):包含所有未佩戴安全帽的工人头部区域
在类别定义过程中,特别注意了以下几点:
- 对于部分被遮挡但仍可判断为佩戴安全帽的情况,归为helmet类别
- 对于手持安全帽但未佩戴在头部的情况,归为head类别
- 对于头部被严重遮挡无法判断的情况,不纳入数据集
- 对于多人场景,分别标记每个人的头部区域及其状态
这种明确的类别定义确保了数据标注的一致性和准确性,为后续的模型训练提供了可靠的标签信息。
数据预处理
为了提升数据集的质量和模型的训练效果,对收集到的数据进行了全面的预处理:
-
图像去噪:采用均值滤波方法对图像进行去噪处理。均值滤波通过计算像素点周围邻域内像素的平均值来替代原像素值,有效去除了图像中的高斯噪声和椒盐噪声。具体步骤包括:定义合适的滤波窗口大小(本研究选用3×3窗口)、遍历图像中每个像素点、计算邻域像素平均值并替换原像素值。
-
图像增强:为了提高模型的泛化能力,对图像进行了多种增强处理:
- 亮度调整:随机调整图像的亮度,模拟不同光线条件下的场景
- 对比度增强:增强图像的对比度,使目标特征更加明显
- 旋转变换:对图像进行随机旋转,增加模型对不同角度目标的识别能力
- 缩放变换:对图像进行随机缩放,提升模型对不同距离目标的检测效果
- 翻转操作:包括水平翻转和垂直翻转,增加数据多样性
-
图像标准化:对所有处理后的图像进行标准化处理,包括尺寸统一(调整为640×640)、像素值归一化(将像素值缩放到0-1范围)等,确保数据格式的一致性。
-
数据清洗:通过人工筛选和自动检测相结合的方式,去除了低质量图像、重复图像和标注不准确的图像,确保数据集的纯净度。
数据标注
数据标注是构建高质量数据集的关键环节。本研究采用了以下标注策略:
-
标注工具选择:使用LabelImg软件进行数据标注。LabelImg是一款开源的图像标注工具,支持矩形框标注和XML格式输出,操作简便且功能强大。
-
标注方法对比与选择:在标注过程中,对比了两种标注方法:
- 方法一:标注整个头部区域,并根据是否佩戴安全帽进行分类
- 方法二:仅标注安全帽部分(如果佩戴)或头顶部分(如果未佩戴)
通过对比实验发现,方法一的召回率更高,更适合安全帽检测任务。因为在实际应用中,需要先定位到人的头部,再判断是否佩戴安全帽。因此,最终选择了方法一对数据集进行标注。
-
标注格式转换:LabelImg生成的标注文件为XML格式,而YOLOv8模型需要TXT格式的标注文件。因此,开发了专门的格式转换脚本,将XML格式转换为YOLO格式,便于模型训练。
-
标注质量控制:采用多人交叉验证的方式,确保标注的准确性和一致性。对于有争议的样本,通过团队讨论达成共识,避免标注误差。
为了合理评估模型的性能,将处理好的数据集按照8:2的比例划分为训练集和测试集:
- 训练集:6064张图像,用于模型的训练过程
- 测试集:1517张图像,用于模型性能的评估和验证
在数据分割过程中,确保了训练集和测试集中各类别的样本比例一致,避免因数据分布不均导致的模型偏差。同时,对训练集进行了随机打乱处理,提高模型训练的稳定性。
功能模块介绍
基于深度学习的工人安全作业监测系统由多个功能模块组成,各模块之间协同工作,共同实现了对工人安全帽佩戴状态的实时监测。以下是系统的主要功能模块详细介绍:
用户验证登录模块
用户验证登录模块是系统的门户,负责确保只有授权用户才能访问系统功能。该模块采用了安全可靠的身份验证机制,有效防止未经授权的访问:
-
用户注册功能:新用户可以通过注册界面提交相关信息,包括用户名、密码、邮箱等。系统对用户输入进行验证,确保信息的有效性和完整性,并对密码进行加密存储,保障用户信息安全。注册成功后,用户可以使用注册的账号登录系统。
-
用户登录功能:已注册用户可以通过登录界面输入用户名和密码进行身份验证。系统对用户凭据进行验证,只有验证通过的用户才能进入主功能界面。
-
登录状态管理:系统维护用户的登录状态,确保在同一会话中用户不需要重复登录。当用户长时间未操作或主动退出时,系统会自动清除登录状态,保障系统安全。
用户验证登录模块采用了PyQt5框架实现图形界面,结合SQLite数据库存储用户信息。密码存储采用了加盐哈希处理,确保即使数据库被泄露,用户密码也不会被轻易破解。界面设计简洁直观,操作流程符合用户习惯,提供了良好的用户体验。作为系统的安全屏障,确保了只有经过授权的管理人员才能访问系统的核心功能,有效防止了未经授权的操作和数据泄露风险。
媒体文件检测模块
媒体文件检测模块是系统的核心功能之一,支持用户上传图片或视频文件进行安全帽佩戴状态检测。该模块能够快速、准确地分析媒体文件中的内容,并标记出工人的安全帽佩戴情况:
-
图片检测功能:
- 单张图片检测:用户可以选择单张图片进行检测,系统实时显示检测结果
- 批量图片检测:支持多张图片的批量导入和检测,提高工作效率
- 检测结果展示:在图片上标记出检测到的目标,包括目标位置、类别(佩戴/未佩戴安全帽)、置信度等信息
- 结果保存:支持将检测结果保存为新的图片文件,便于后续查看和分析
-
视频检测功能:
- 视频文件导入:支持常见视频格式的导入和检测
- 逐帧分析:对视频的每一帧进行分析,实时检测工人的安全帽佩戴状态
- 实时信息显示:在视频播放界面显示检测结果信息,包括目标数量、位置坐标、置信度、处理时间等
- 结果记录:记录视频中检测到的未佩戴安全帽行为,便于后续追溯和处理
媒体文件检测模块的核心是YOLOv8-MEU深度学习模型。系统使用OpenCV库读取和处理图像/视频文件,将处理后的图像帧输入到预训练的YOLOv8-MEU模型中进行推理,获取目标检测结果。检测结果通过PyQt5界面实时展示给用户,同时支持结果的保存和导出。在实现过程中,特别优化了视频处理的性能,通过多线程技术和帧缓冲机制,确保视频检测的流畅性和实时性。对于批量图片检测,采用了并行处理策略,显著提高了检测效率。
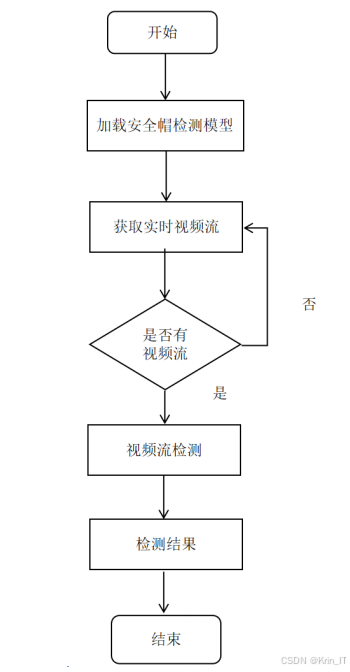
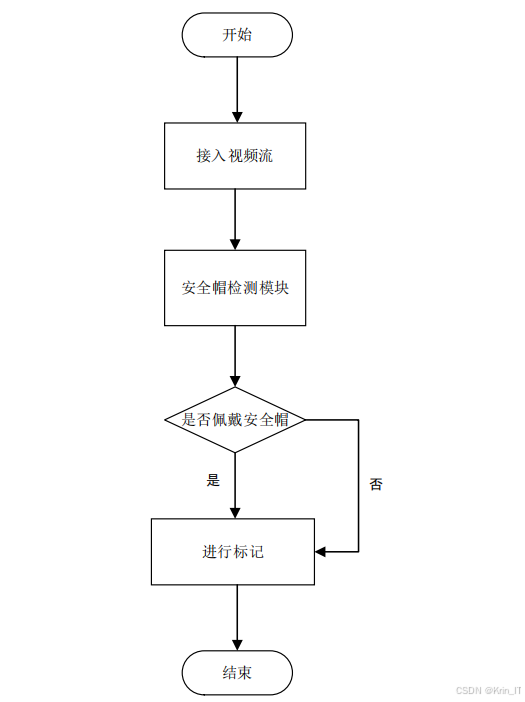
实时视频监测模块
实时视频监测模块是系统的另一个核心功能,能够通过摄像头实时获取视频流,并进行安全帽佩戴状态的实时检测和分析。该模块适用于施工现场的实时监控场景,能够及时发现和预警未佩戴安全帽的行为。
-
摄像头接入:
- 支持电脑内置摄像头的接入和使用
- 支持外接USB摄像头或网络摄像头的接入
- 提供摄像头参数设置功能,如分辨率、帧率等
-
实时检测:
- 对摄像头捕获的每一帧图像进行实时分析
- 实时标记出画面中的工人及其安全帽佩戴状态
- 当检测到未佩戴安全帽的情况时,系统可以发出预警提示
-
信息显示:
- 实时显示检测到的目标数量、位置、置信度等信息
- 显示系统的处理时间,确保满足实时性要求
- 提供监控画面的缩放、全屏等操作功能
-
监控记录:
- 支持监控视频的录制和保存
- 记录检测到的异常情况(如未佩戴安全帽),包括时间戳和截图
- 提供异常事件的查询和回放功能
实时视频监测模块同样基于YOLOv8-MEU模型进行目标检测。系统通过OpenCV库获取摄像头的视频流,采用多线程技术实现视频捕获和处理的并行执行,确保系统的实时性能。在界面实现上,使用PyQt5的QThread类创建独立的工作线程处理视频流,避免界面卡顿。同时,通过优化模型推理过程,减少图像处理的计算量,进一步提升了系统的实时性能。对于预警功能,系统设计了声音提示和视觉标记相结合的方式,当检测到未佩戴安全帽的情况时,不仅在界面上用醒目的颜色标记目标,还会发出警报声,提醒管理人员及时处理。
数据管理模块
数据管理模块负责系统的检测结果存储、查询和管理功能,为安全管理提供数据支持和决策依据。
-
检测结果存储:
- 存储图片和视频检测的历史记录
- 记录每次检测的详细信息,包括检测时间、文件路径、检测结果等
- 对异常事件(如未佩戴安全帽)进行特殊标记和重点存储
-
数据查询和统计:
- 支持按时间、检测类型、检测结果等条件进行数据查询
- 提供数据统计功能,生成各类报表和统计图表
- 支持数据导出功能,便于与其他系统进行数据交互
-
系统日志管理:
- 记录系统的运行日志,包括用户登录、操作记录等
- 提供日志查询和分析功能,便于系统维护和问题排查
数据管理模块采用SQLite数据库存储系统数据,包括检测记录、用户信息、系统日志等。数据库设计采用了合理的表结构和索引策略,确保数据存储的高效性和查询的便捷性。在数据展示方面,使用PyQt5的表格组件和图表组件,实现了数据的可视化展示。对于统计分析功能,结合了Python的数据处理库(如pandas)和可视化库(如matplotlib),生成各类统计图表,直观展示安全监测的结果和趋势。
算法理论
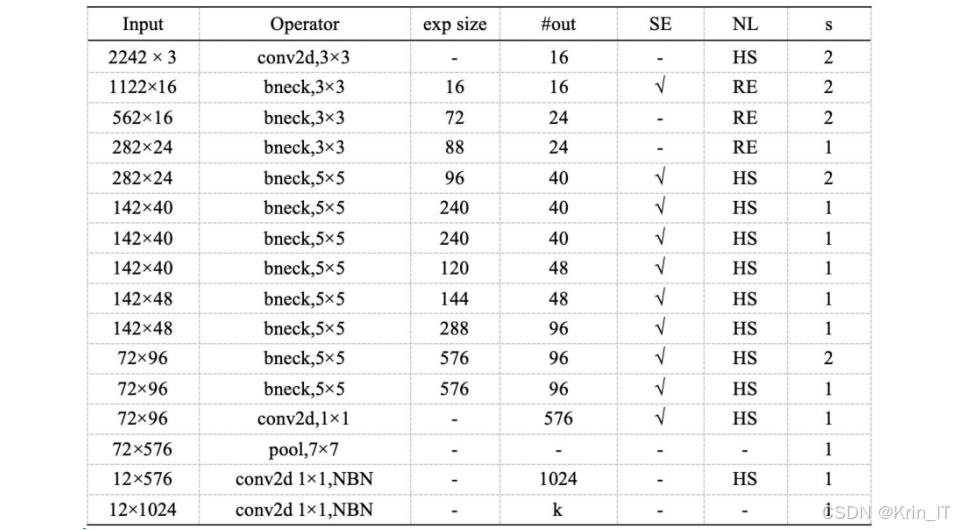
为了适应工人安全作业监测的特殊需求,本研究提出了YOLOv8-MEU改进算法,通过引入MobileNetV3-Small主干网络、ECA注意力机制和EIoU损失函数,显著提升了模型在安全帽检测任务中的性能。MobileNetV3-Small是一种轻量级卷积神经网络,专为移动设备和边缘计算设计,具有参数量少、计算效率高的特点。将其应用于YOLOv8的主干网络替换,主要基于以下考虑:
-
轻量级设计:MobileNetV3-Small通过深度可分离卷积和瓶颈结构,大幅减少了模型参数和计算量,使得模型在保持较高精度的同时,推理速度得到显著提升。这对于需要实时检测的安全帽监测系统至关重要。
-
自适应网络宽度:MobileNetV3-Small通过NAS(Neural Architecture Search)技术优化了网络结构,针对不同的任务自适应调整网络宽度,在资源受限的情况下实现最佳性能。
-
激活函数优化:使用h-swish激活函数替代传统的ReLU激活函数,在保持相似性能的同时,降低了计算复杂度。
在实现过程中,为了精简模型并保持检测精度,研究移除了MobileNetV3-Small网络的最后四层,仅保留关键模块来替代YOLOv8n的主干部分。同时,保留了原YOLOv8n网络中的SPPF模块,以解决尺度多样性问题,提高对安全帽的检测精度。
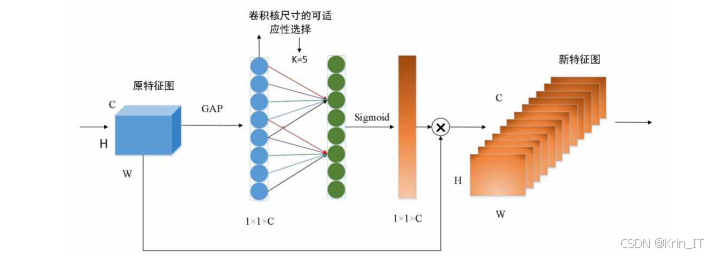
ECA是一种轻量级的通道注意力机制,通过自适应学习不同通道的重要性权重,增强了模型对关键特征的提取能力。在安全帽检测任务中引入ECA注意力机制,主要基于以下考虑:
-
小目标检测增强:在建筑工地场景中,部分工人可能距离摄像头较远,呈现为小目标。ECA注意力机制能够自适应地增强对小目标特征的关注度,提高小目标的检测准确率。
-
轻量级设计:ECA注意力机制通过一维卷积实现通道间的信息交互,参数量少,计算效率高,适合与轻量级主干网络配合使用。
-
自适应卷积核大小:ECA机制能够根据通道数量自适应地确定一维卷积核的大小,避免了手动调参的复杂性,同时保持了通道间的适当交互范围。
在YOLOv8-MEU中,ECA注意力机制被添加在主干网络的SPPF模块之后,对提取的特征进行进一步增强,提高了模型对安全帽特征的表达能力。
边界框回归是目标检测中的关键任务,损失函数的设计直接影响到检测的精度和稳定性。EIoU(Effective Intersection over Union)损失函数是对传统IoU损失函数的重要改进,具有以下优势:
-
全面的距离度量:EIoU损失函数综合考虑了预测框与真实框之间的重叠面积、中心点距离以及宽高比差异,能够更全面地评估两者之间的相似性。
-
解决包含关系问题:当预测框与真实框存在包含关系时,传统的IoU和GIoU损失函数可能失效,而EIoU通过将宽高比影响因子分开计算,能够更精确地调整预测框的形状。
-
更快的收敛速度:EIoU损失函数提供了更丰富的梯度信息,使得模型在训练过程中能够更快地收敛到最优解。
在安全帽检测任务中,使用EIoU损失函数替代传统的IoU损失函数,显著提升了模型对安全帽的定位精度,减少了误检测,增强了算法的整体稳定性和可靠性。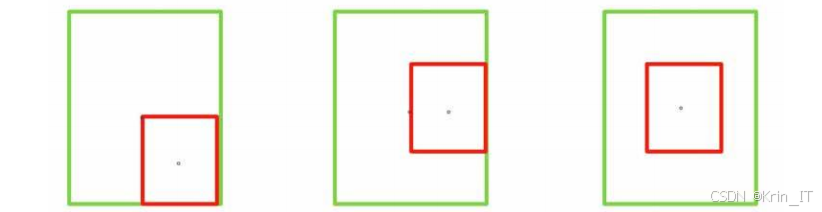
核心代码介绍
改进YOLOv8模型定义代码
YOLOv8-MEU模型的整体架构,是整个系统的核心部分。该代码首先导入必要的深度学习库和组件,然后创建了一个继承自nn.Module的YOLOv8MEU类。在模型初始化方法中,使用MobileNetV3Small作为主干网络,并根据研究需求移除了其最后四层以精简模型结构。接着添加了SPPF模块,用于处理不同尺度的特征,提高检测精度。随后引入了ECA注意力机制,通过自适应学习通道权重来增强关键特征的表达能力。模型还包含了FPN-PAN结构用于多尺度特征融合,以及解耦检测头用于最终的目标预测。
class YOLOv8MEU(nn.Module):
def __init__(self, num_classes=2, pretrained=True):
super(YOLOv8MEU, self).__init__()
# 使用MobileNetV3-Small作为主干网络
self.backbone = MobileNetV3Small(pretrained=pretrained)
# 移除最后四层,精简模型结构
self.backbone.layers = nn.Sequential(*list(self.backbone.layers.children())[:-4])
# 添加SPPF模块
self.sppf = SPPF(in_channels=576, out_channels=576)
# 添加ECA注意力机制
self.eca = ECA(in_channels=576)
# FPN-PAN Neck结构
self.fpn_pan = FPNPAN(in_channels=[160, 240, 576])
# 解耦检测头
self.head = DecoupledHead(num_classes=num_classes, in_channels=256)
def forward(self, x):
# 主干网络特征提取
features = self.backbone(x)
# 获取不同尺度的特征图
small_feat = features[0] # 小尺度特征
medium_feat = features[1] # 中尺度特征
large_feat = features[2] # 大尺度特征
# 对大尺度特征应用SPPF和ECA
large_feat = self.sppf(large_feat)
large_feat = self.eca(large_feat)
# 特征融合
fused_features = self.fpn_pan([small_feat, medium_feat, large_feat])
# 检测头预测
outputs = self.head(fused_features)
return outputs
在前向传播方法中,输入图像首先通过主干网络提取特征,获取小、中、大三个不同尺度的特征图。然后对大尺度特征图应用SPPF模块和ECA注意力机制,增强特征表达。接着,通过FPN-PAN结构对不同尺度的特征进行融合,充分利用各尺度的特征信息。最后,使用解耦检测头对融合后的特征进行处理,输出最终的检测结果。
该代码设计体现了YOLOv8-MEU算法的核心改进点:MobileNetV3-Small轻量级主干网络、ECA注意力机制以及多尺度特征融合,这些改进共同提升了模型在安全帽检测任务中的性能和效率。
ECA注意力机制实现代码
ECA 注意力机制,是YOLOv8-MEU算法的重要组成部分。ECA注意力机制的核心思想是通过自适应学习不同通道的重要性权重,增强模型对关键特征的提取能力。在初始化方法中,根据输入特征的通道数,使用公式k = φ© = |(log2© + b)/γ|odd自适应计算一维卷积核的大小,其中C为通道数,γ和b为超参数,本实验中分别设置为2和1。这种自适应计算方式避免了手动调参的复杂性,同时保持了通道间的适当交互范围。
在前向传播方法中,首先对输入特征图进行全局平均池化,将每个通道的二维特征图压缩为一个标量,形成通道描述符。然后,通过一维卷积对这些通道描述符进行处理,实现通道间的信息交互。接着,使用sigmoid激活函数将处理后的特征转换为0-1之间的注意力权重,表示每个通道的重要程度。最后,将注意力权重与原始特征图相乘,实现对特征的自适应增强,突出重要特征,抑制无关特征。
class ECA(nn.Module):
def __init__(self, in_channels, gamma=2, b=1):
super(ECA, self).__init__()
# 根据通道数自适应计算卷积核大小
t = int(abs((math.log2(in_channels) + b) / gamma))
k = t if t % 2 else t + 1
# 一维卷积用于通道间信息交互
self.conv = nn.Conv1d(1, 1, kernel_size=k, padding=(k - 1) // 2, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
# 全局平均池化,将特征图转换为通道描述符
y = x.mean((2, 3), keepdim=True)
# 一维卷积计算通道权重
y = self.conv(y.squeeze(-1).transpose(-1, -2))
y = y.transpose(-1, -2).unsqueeze(-1)
# 通过sigmoid激活函数生成注意力权重
y = self.sigmoid(y)
# 将注意力权重应用到原始特征图
return x * y.expand_as(x)
ECA注意力机制的优势在于其轻量级设计和高效的计算性能。与传统的通道注意力机制不同,ECA通过一维卷积实现通道间的信息交互,参数量少,计算复杂度低,同时保持了通道间的适当交互范围。这使得它非常适合与轻量级主干网络配合使用,在不显著增加计算负担的情况下,有效提升模型的特征提取能力。
EIoU损失函数实现代码
EIoU损失函数,用于优化目标检测模型的边界框回归性能。EIoU损失函数是对传统IoU损失函数的重要改进,通过综合考虑预测框与真实框之间的重叠面积、中心点距离以及宽高比差异,能够更全面地评估两者之间的相似性,从而提升定位精度。
def eioU_loss(pred_boxes, target_boxes):
# 计算IoU
intersection = calculate_intersection(pred_boxes, target_boxes)
union = calculate_union(pred_boxes, target_boxes)
iou = intersection / (union + 1e-6)
# 计算中心点距离
pred_center = get_center(pred_boxes)
target_center = get_center(target_boxes)
center_distance = torch.pow(pred_center - target_center, 2).sum(dim=-1)
# 计算最小外接矩形的对角线长度
cw = torch.max(pred_boxes[:, 2], target_boxes[:, 2]) - torch.min(pred_boxes[:, 0], target_boxes[:, 0])
ch = torch.max(pred_boxes[:, 3], target_boxes[:, 3]) - torch.min(pred_boxes[:, 1], target_boxes[:, 1])
c = torch.pow(cw, 2) + torch.pow(ch, 2)
# 计算宽高损失
pred_width = pred_boxes[:, 2] - pred_boxes[:, 0]
pred_height = pred_boxes[:, 3] - pred_boxes[:, 1]
target_width = target_boxes[:, 2] - target_boxes[:, 0]
target_height = target_boxes[:, 3] - target_boxes[:, 1]
width_loss = torch.pow((target_width - pred_width) / (torch.max(target_width, pred_width) + 1e-6), 2)
height_loss = torch.pow((target_height - pred_height) / (torch.max(target_height, pred_height) + 1e-6), 2)
# 计算EIoU损失
eioU = iou - (center_distance / (c + 1e-6)) - width_loss - height_loss
loss = 1 - eioU
return loss.mean()
# 辅助函数:计算交集
def calculate_intersection(box1, box2):
x1 = torch.max(box1[:, 0], box2[:, 0])
y1 = torch.max(box1[:, 1], box2[:, 1])
x2 = torch.min(box1[:, 2], box2[:, 2])
y2 = torch.min(box1[:, 3], box2[:, 3])
intersection = torch.clamp(x2 - x1, min=0) * torch.clamp(y2 - y1, min=0)
return intersection
# 辅助函数:计算并集
def calculate_union(box1, box2):
area1 = (box1[:, 2] - box1[:, 0]) * (box1[:, 3] - box1[:, 1])
area2 = (box2[:, 2] - box2[:, 0]) * (box2[:, 3] - box2[:, 1])
intersection = calculate_intersection(box1, box2)
union = area1 + area2 - intersection
return union
# 辅助函数:获取中心点
def get_center(boxes):
center_x = (boxes[:, 0] + boxes[:, 2]) / 2
center_y = (boxes[:, 1] + boxes[:, 3]) / 2
return torch.stack([center_x, center_y], dim=-1)
EIoU损失函数的计算过程主要分为以下几个步骤:
- 计算预测框与真实框之间的交并比(IoU),这是衡量两个框重叠程度的基本指标。然后,计算两个框中心点之间的欧氏距离,这反映了预测框与真实框在位置上的偏差。接着,计算能够同时容纳两个框的最小外接矩形的对角线长度,用于归一化中心点距离。最后,分别计算预测框与真实框在宽度和高度上的差异损失,这部分是EIoU相比之前损失函数的重要创新,通过将宽高比影响因子分开计算,能够更精确地调整预测框的形状。
EIoU损失函数的表达式为:L_EIoU = 1 - IoU + ρ²(b,bgt)/c² + ρ²(w,wgt)/Cw² + ρ²(h,hgt)/Ch²,其中ρ表示欧氏距离,b和bgt表示预测框和真实框的中心点,w和h表示预测框的宽和高,wgt和hgt表示真实框的宽和高,c表示最小外接矩形的对角线长度,Cw和Ch分别表示与宽和高相关的归一化参数。
在安全帽检测任务中,EIoU损失函数的使用显著提升了模型对安全帽的定位精度,特别是在处理遮挡、重叠等复杂情况时,表现出了更好的性能。同时,由于EIoU提供了更丰富的梯度信息,使得模型在训练过程中能够更快地收敛到最优解。
视频实时检测实现代码
基于YOLOv8-MEU模型的视频实时检测功能,是系统中用于实时监控的核心组件。该代码定义了一个VideoDetector类,封装了模型加载、图像预处理、模型推理、结果后处理等功能,实现了从摄像头获取视频流并进行实时安全帽检测的完整流程。在初始化方法中,代码加载了预训练的YOLOv8-MEU模型,并设置了置信度阈值、类别标签和颜色映射。颜色映射用于在可视化时区分不同的类别,未佩戴安全帽(head)用红色标记,佩戴安全帽(helmet)用绿色标记,直观地展示检测结果。
class VideoDetector:
def __init__(self, model_path, conf_threshold=0.5):
# 加载模型
self.model = self.load_model(model_path)
self.conf_threshold = conf_threshold
# 类别标签
self.class_names = ['head', 'helmet']
# 类别颜色映射
self.colors = [(0, 0, 255), (0, 255, 0)] # head:红色, helmet:绿色
def load_model(self, model_path):
# 加载训练好的YOLOv8-MEU模型
model = YOLOv8MEU(num_classes=2)
model.load_state_dict(torch.load(model_path, map_location='cpu'))
model.eval()
return model
def preprocess(self, frame):
# 图像预处理
img = cv2.resize(frame, (640, 640))
img = img.transpose(2, 0, 1) # HWC -> CHW
img = img / 255.0 # 归一化
img = torch.from_numpy(img).float().unsqueeze(0)
return img
def postprocess(self, frame, outputs, img_shape):
# 后处理检测结果
h, w = frame.shape[:2]
scale_h, scale_w = h / 640, w / 640
for output in outputs:
boxes = output['boxes']
scores = output['scores']
classes = output['classes']
for i in range(len(boxes)):
if scores[i] > self.conf_threshold:
# 调整边界框坐标到原始图像尺度
x1, y1, x2, y2 = boxes[i]
x1 = int(x1 * scale_w)
y1 = int(y1 * scale_h)
x2 = int(x2 * scale_w)
y2 = int(y2 * scale_h)
# 绘制边界框
cls = int(classes[i])
color = self.colors[cls]
cv2.rectangle(frame, (x1, y1), (x2, y2), color, 2)
# 绘制类别标签和置信度
label = f'{self.class_names[cls]}: {scores[i]:.2f}'
cv2.putText(frame, label, (x1, y1 - 10),
cv2.FONT_HERSHEY_SIMPLEX, 0.5, color, 2)
return frame
def detect_realtime(self, camera_id=0):
# 打开摄像头
cap = cv2.VideoCapture(camera_id)
while True:
# 读取一帧图像
ret, frame = cap.read()
if not ret:
break
# 记录开始时间
start_time = time.time()
# 预处理
img = self.preprocess(frame)
# 模型推理
with torch.no_grad():
outputs = self.model(img)
# 后处理
result_frame = self.postprocess(frame, outputs, img.shape)
# 计算FPS
fps = 1 / (time.time() - start_time)
cv2.putText(result_frame, f'FPS: {fps:.2f}', (10, 30),
cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 0, 255), 2)
# 显示结果
cv2.imshow('Helmet Detection', result_frame)
# 按ESC键退出
if cv2.waitKey(1) == 27:
break
cap.release()
cv2.destroyAllWindows()
preprocess方法负责对输入图像进行预处理,包括调整图像大小、通道转换和归一化,使其符合模型的输入要求。postprocess方法则处理模型的输出结果,将边界框坐标调整到原始图像尺度,并在图像上绘制边界框、类别标签和置信度,生成可视化的检测结果。
detect_realtime方法是整个视频检测的核心,它打开摄像头,循环读取视频帧,对每一帧进行预处理、模型推理和后处理,最后显示处理结果。同时,该方法还计算并显示每秒处理的帧数(FPS),用于评估系统的实时性能。
这段代码的设计充分考虑了实时性能的需求,通过使用torch.no_grad()关闭梯度计算、优化图像预处理流程等方式,确保了系统能够高效地处理视频流。此外,代码还提供了灵活的参数设置,如摄像头ID和置信度阈值,可以根据实际需求进行调整。
总结
本研究成功设计并实现了一套基于深度学习的工人安全作业监测系统,该系统运用改进的YOLOv8-MEU算法,能够实时、准确地检测工人的安全帽佩戴状态,为建筑工地等场所的安全管理提供了有效的技术支持。
研究的主要成果和贡献包括:
-
构建了一个高质量的安全帽检测数据集。通过网络爬虫采集、视频截取和现场拍摄等多种方式,收集了大量真实场景下的图像数据,并进行了系统性的预处理和标注。数据集涵盖了各种不同的场景、光线条件、角度和距离,为训练高性能的检测模型提供了坚实的数据基础。
-
提出了YOLOv8-MEU改进算法。该算法通过引入MobileNetV3-Small轻量级主干网络、ECA注意力机制和EIoU损失函数,在保持较高检测精度的同时,显著提升了检测速度和小目标检测能力。
-
设计并实现了完整的工人安全作业监测系统。系统集成了用户验证登录、媒体文件检测、实时视频监测、数据管理等功能模块,支持图片、视频和实时摄像头流的输入和处理,能够满足不同场景下的安全监测需求。系统界面友好,操作简便,具备良好的用户体验。
-
进行了大量的实验验证和性能测试。通过消融实验、对比实验、时间检测实验、小目标检测实验和精度检测实验等多种方式,全面评估了算法和系统的性能。实验结果充分证明了YOLOv8-MEU算法和整个监测系统在安全帽检测任务中的有效性和实用性。
本研究的成果具有重要的理论意义和实际应用价值。在理论方面,丰富了目标检测算法在特定领域的应用研究,为轻量级目标检测算法的设计和优化提供了新的思路和方法。在实际应用方面,开发的工人安全作业监测系统可以广泛应用于建筑工地、工厂车间等场所,实现对工人安全帽佩戴状态的自动监测,有效预防安全事故,保障工人生命安全,推动安全管理向智能化、精细化方向发展。
未来的研究可以进一步从以下几个方面展开:一是扩展检测目标的范围,除了安全帽外,还可以检测其他安全防护装备,如安全带、防护服等;二是加强系统的环境适应能力,提高在恶劣天气、复杂光照等条件下的检测性能;三是与物联网技术相结合,实现更广泛的安全监测网络和更智能的预警机制;四是进一步优化模型结构,在保证性能的同时,降低计算资源需求,使系统能够部署在更多的边缘设备上。
参考文献
[1] Redmon J, Divvala S, Girshick R, et al. You Only Look Once: Unified, Real-Time Object Detection[C]. 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas, NV, USA: IEEE, 2016.
[2] Wang C Y, Mark Liao H Y, Wu Y H, et al. CSPNet: A New Backbone that can Enhance Learning Capability of CNN[C]. 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW). Seattle, WA, USA: IEEE, 2020.
[3] Liu S, Qi L, Qin H, et al. Path aggregation network for instance segmentation[C]. Proceedings of the IEEE conference on computer vision and pattern recognition. 2018.
[4] Zhu C, He Y, Savvides M. Feature Selective Anchor-Free Module for Single-Shot Object Detection[C]. 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Long Beach, CA, USA: IEEE, 2019.
[5] Tian Z, Shen C, Chen H, et al. FCOS: Fully Convolutional One-Stage Object Detection[C]. 2019 IEEE/CVF International Conference on Computer Vision (ICCV). Seoul, Korea (South): IEEE, 2019.
[6] RAHMAN M A, WANG Y. Optimizing intersection-over-union in deep neural networks for image segmentation[C]. International symposium on visual computing: Springer, 2016.
[7] He K, Zhang X, Ren S, et al. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2015, 37(9): 1904-1916.
[8] Carion N, Massa F, Synnaeve G, et al. End-to-End Object Detection with Transformers[M]. arXiv, 2020.
最后

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 10
10 0
0- 0



 已为社区贡献200条内容
已为社区贡献200条内容

所有评论(0)