pytorch模型部署的基础知识,将pytorch模型转化为ONNX格式,用ONNXRuntime进行推理
一、模型部署的基本步骤
模型部署有三个步骤:训练框架(pytorch)——>中间表示(ONNX)——>推理框架(引擎)有ONNX Runtime、TensorRT等
二、以LeNet网络为例,将训练的Lenet转化为ONNX中间表示
import torch
from torch import nn
class LeNet(nn.Module):
def __init__(self):
super(LeNet, self).__init__()
self.net = nn.Sequential(
nn.Conv2d(1, 6, kernel_size=5),
nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2),
nn.Conv2d(6, 16, kernel_size=5),
nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2),
nn.Flatten(),
nn.Linear(16*5*5, 120),
nn.Sigmoid(),
nn.Linear(120, 84),
nn.Sigmoid(),
nn.Linear(84, 10)
)
def forward(self, img):
return self.net(img)
model = LeNet()
model.eval()
x=torch.rand(size=(1, 1, 32, 32), dtype=torch.float32)
torch.onnx.export(model, x, f='lenet.onnx', input_names=['input'],
output_names=['output'], opset_version=11)1、基本操作的概念
class:构造类,继承nn.Module
super(LeNet, self).__init__():调用父类nn.Module的构造函数
self.net = nn.Sequential:定义网络的核心序列容器nn.Sequential:按顺序堆叠层,前一层输出作为后一层输入,简化网络结构定义
2、关于pytroch基本函数的概念
①卷积函数,卷积函数中Conv2d的1d,2d,3d对应处理「1 维 / 2 维 / 3 维」的结构化数据;同理AvgPool1d、AvgPool2d与AvgPool3d中也是对应一维二维三维平均池化操作。
nn.Conv1d
nn.Conv2d
nn.Conv3d②Flatten函数:Flatten(展平)是卷积 / 池化层与全连接层(nn.Linear)之间的关键桥梁:它将「多维特征图张量」转换为「一维向量(保留批量维度)」,因为全连接层(Linear)仅接受二维张量(batch_size, 特征数) 作为输入(第一维是批量,第二维是特征数),而卷积 / 池化层输出的是高维特征图(如 (1, 16, 5, 5))
③关于池化操作后的特征图维度的计算
卷积 / 池化后输出尺寸 = ⌊(输入尺寸 - 核尺寸) / 步长 + 1⌋(⌊ ⌋ 表示向下取整);其中kernel_size是核尺寸,stride为步长
④model.eval:使用 model.eval () 是为了将模型切换到推理 / 评估模式,关闭 Dropout、BatchNorm 等仅训练阶段生效的层,固定模型行为,确保推理或导出(如 ONNX)时结果稳定、一致且符合部署预期
⑤x=torch.rand(size=(1, 1, 32, 32), dtype=torch.float32)
生成一个维度为(1, 1, 32, 32)、数据类型为 32 位浮点型的张量,张量内元素是[0, 1)区间均匀分布的随机数,作为 ONNX 导出时的示例输入(匹配 LeNet 模型输入维度:批量大小 1、单通道、32×32 尺寸的灰度图;LeNet要求输入维度是(batch_size, 1, 32, 32))
⑥torch.onnx.export(model, x, f='lenet.onnx', input_names=['input'],
output_names=['output'], opset_version=11)
代码调用torch.onnx.export将指定的 LeNet 模型(model),以示例输入张量 x 为依据,导出保存为名为 lenet.onnx 的 ONNX 文件,同时设置 ONNX 图中输入节点名称为 input、输出节点名称为 output,并指定使用版本 11 的 ONNX 算子集
3、使用lenet.onnx工具
netron.app 是一款免费、开源、无门槛的神经网络模型可视化工具(网页版 + 桌面版),核心作用是将 ONNX、PyTorch、TensorFlow 等格式的模型文件,以图形化、可交互的方式展示网络结构,可以直观校验模型的层连接、参数、维度等是否符合预期
使用方式:打开网站,导入生成的.onnx文件
网站左上角三个横线点开:其中的 Properties:查看属性信息
4、关于netron.app中导入lenet.onnx模型的解释
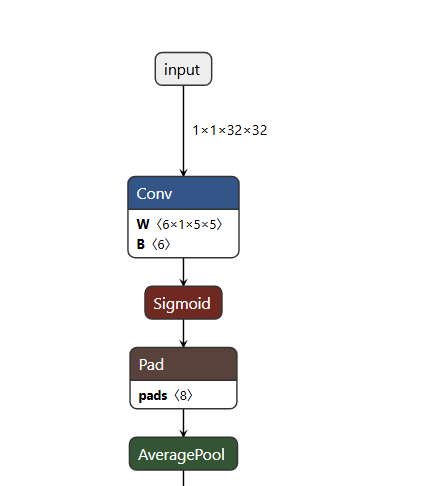
①其中Conv中的W <6×1×5×5>:卷积核权重(Weight)<out_channels × in_channels × kernel_height × kernel_width>
6×1×5×5:分别表示输出通道数,输入通道数,卷积核的高和宽
②关于Pad的解释
LeNet 代码里,AvgPool2d 默认带了padding=2;
netron 里:这个padding=2被拆成了独立的 Pad 层(显示 pads<8>,因为上下左右各补 2,2+2+2+2=8)
为什么要有这个操作?ONNX格式中Avg函数默认的Pad类型时List格式,但是Pytorch给的整数(数字);
详细解释:
写 PyTorch 代码时,给 “缩小特征图的池化层(AvgPool2d)” 加了个 padding=2(就一个数字),PyTorch 能明白这是 “给特征图的上下左右都补 2 圈 0”;但 ONNX 这个格式不认 “一个数字”,必须让你把 “左补 2、上补 2、右补 2、下补 2” 明明白白列出来(就是列表 [2,2,2,2])。
所以 PyTorch 导出 ONNX 时,就把你写的 “一个带 padding 的池化层”,拆成了两步:先单独搞个 Pad 层(专门负责补 0,总共补了 8 个位置的 0,所以显示 pads<8>),再做纯纯的池化(不补 0 了)。
说白了,就是 PyTorch 和 ONNX “说话的规矩不一样”,PyTorch 能懂的 “简略说法(一个数字)”,ONNX 非要 “详细说法(列 4 个数)”,导出时就把一步拆成两步,那个 Pad 层就是拆出来的 “补 0 步骤”,功能没变,就是格式要求
③Gemm操作:表示全连接层,Linear函数
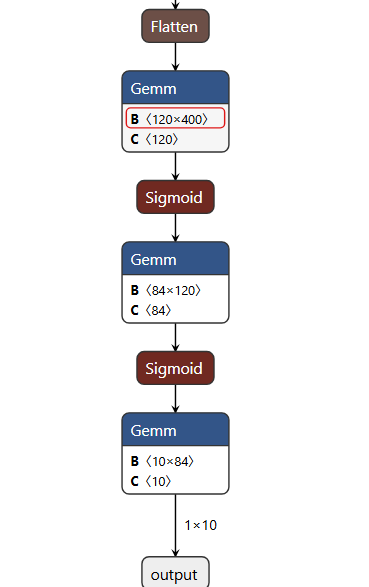
5、查看ONNX算子集:ONNX Operators - ONNX 1.21.0 documentation
三、推理阶段
注意,首先下载好onnxruntime包
import onnxruntime as ort
import numpy as np
# 加载模型
session = ort.InferenceSession('lenet.onnx')
# 随机输入
input_data = np.random.randn(1, 1, 32, 32).astype(np.float32)
# 推理
outputs = session.run(None, {'input': input_data})
raw_predictions = outputs[0][0] # 取batch中第一个结果
# 转换为概率(softmax)
probabilities = np.exp(raw_predictions) / np.sum(np.exp(raw_predictions))
# 找出最可能的数字
predicted_digit = np.argmax(probabilities)
confidence = probabilities[predicted_digit]
print(f"最可能的数字: {predicted_digit}")
print(f"置信度: {confidence:.2%}")
print("\n所有数字的概率:")
for i, prob in enumerate(probabilities):
print(f" 数字{i}: {prob:.4f} ({prob*100:.1f}%)")1、代码解释
session = ort.InferenceSession('lenet.onnx')创建一个ONNX Runtime的推理会话,加载名为 lenet.onnx 的模型文件
input_data = np.random.randn(1, 1, 32, 32).astype(np.float32)随机生成一个 (1, 1, 32, 32) 数组,和前面章节2的size相同,(batch,channel,height,width);在生成 lenet.onnx 模型的时候,选择的数据类型是float32(代码:x=torch.rand(size=(1, 1, 32, 32), dtype=torch.float32) ),因此在进行推理的是也需要保持一致
outputs = session.run(None, {'input': input_data})
raw_predictions = outputs[0][0] 进行推理,session.run(None, {'input': input_data})中None表示获取所有输出节点;第二个参数{'input': input_data}:输入字典,键'input'必须与模型输入节点名称匹配
outputs[0][0]:
outputs[0]:第一个输出节点的结果,形状为(1, 10) - 10个类别的原始分数
[0]:取batch中的第一个样本,得到长度为10的数组

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 15
15 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)