opencv视频21-30
频域通过“上帝视角”忽略具体时间点,仅提取周期性特征。数学上,任何周期信号均可分解为不同频率正弦波的叠加。例如,矩形波可通过无限多个正弦波逼近,其公式表示为:高频分量对应图像中变化剧烈的灰度分量,如边缘、纹理或噪声。在频域中表现为远离中心的外围区域。示例:物体边界(船与水的交界处)或快速变化的像素值。低频分量对应图像中变化平缓的灰度分量,如整体背景或平滑区域。在频域中集中在中心区域。示例:均匀的大
掩码创建与应用
掩码是一个二值矩阵,通常用0和255表示黑色和白色区域。创建掩码需要定义掩码类型、指定图像大小和shift值,并使用无符号整形数据类型。掩码的大小必须与图像大小一致,覆盖区域置为255(保留),其余区域置为0(舍弃)。
掩码操作可以实现图像截取和局部处理。将掩码覆盖到图像上,保留掩码为255的区域,舍弃为0的区域。这种方法适用于对图像中的特定区域进行单独处理或提取。
直方图统计与均衡化
直方图用于统计图像中每个像素点的数量,反映图像的亮度或色彩分布。通过分析直方图,可以判断图像的对比度和曝光情况。
直方图均衡化通过统计像素点的灰度值分布,计算累积概率并进行映射变换,使灰度值分布更加均匀。映射变换公式为:
[
s_k = (L-1) \cdot \sum_{j=0}^{k} \frac{n_j}{N}
]
其中,( s_k ) 为映射后的灰度值,( L ) 为灰度级数,( n_j ) 为第j级灰度的像素数,( N ) 为总像素数。
直方图均衡化实现步骤
统计原始图像的灰度直方图,计算每个灰度级的概率分布。
计算累积分布函数(CDF),并对CDF进行归一化处理。
将归一化的CDF映射到新的灰度值,生成均衡化后的图像。均衡化后的图像具有更均匀的亮度分布,对比度得到显著提升。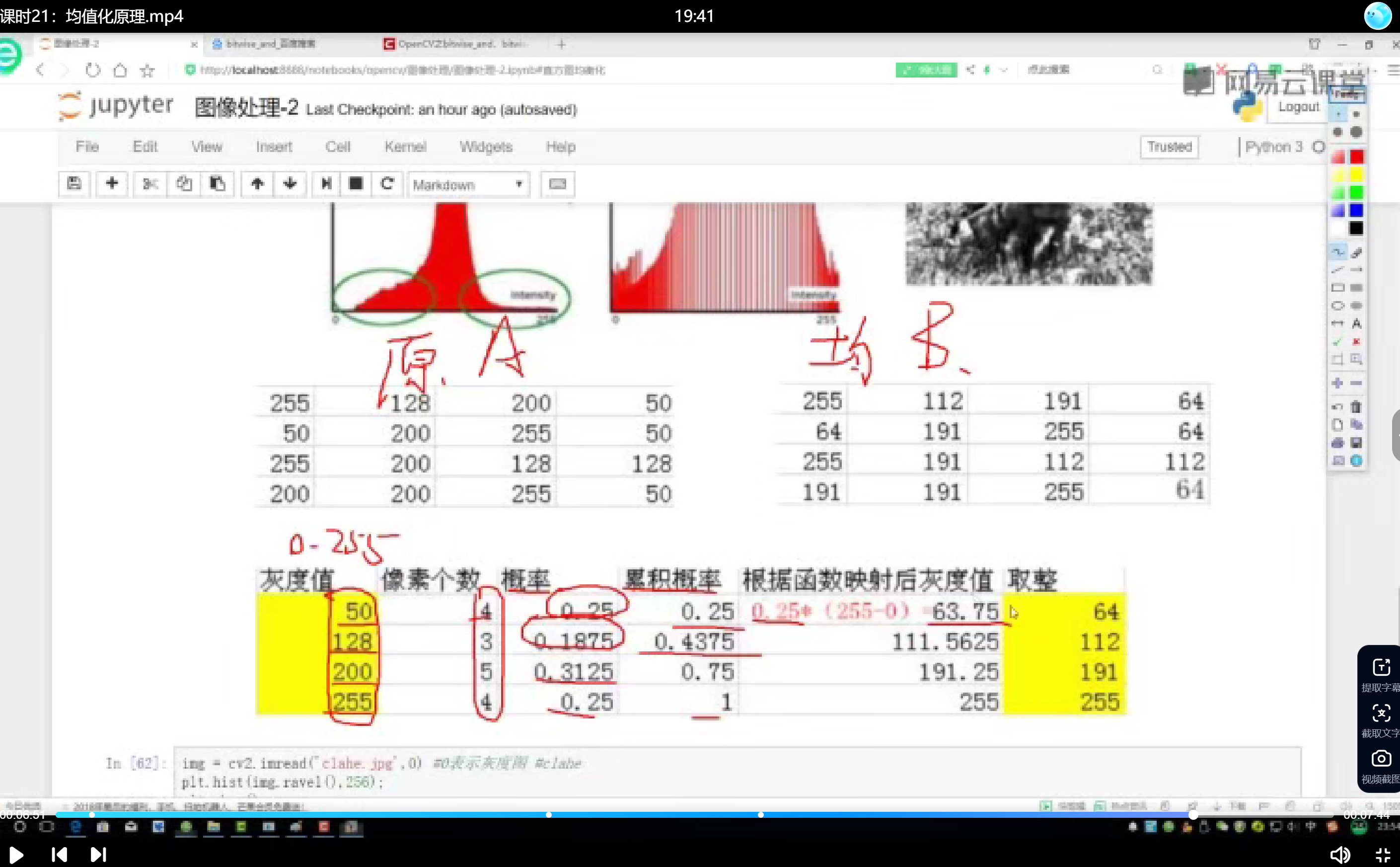
掩码(Mask)原理
黑白二值矩阵(0/255)用于图像区域选择,核心是通过矩阵运算实现图像局部提取。创建与图像同尺寸的无符号矩阵,目标区域设为255,其余为0。与原始图像进行按位与操作时,白色区域保留原图,黑色区域像素置零。
猫图像局部提取示例中,掩码白色区域对应猫的轮廓,黑色区域为背景,叠加后仅保留猫的可见部分。
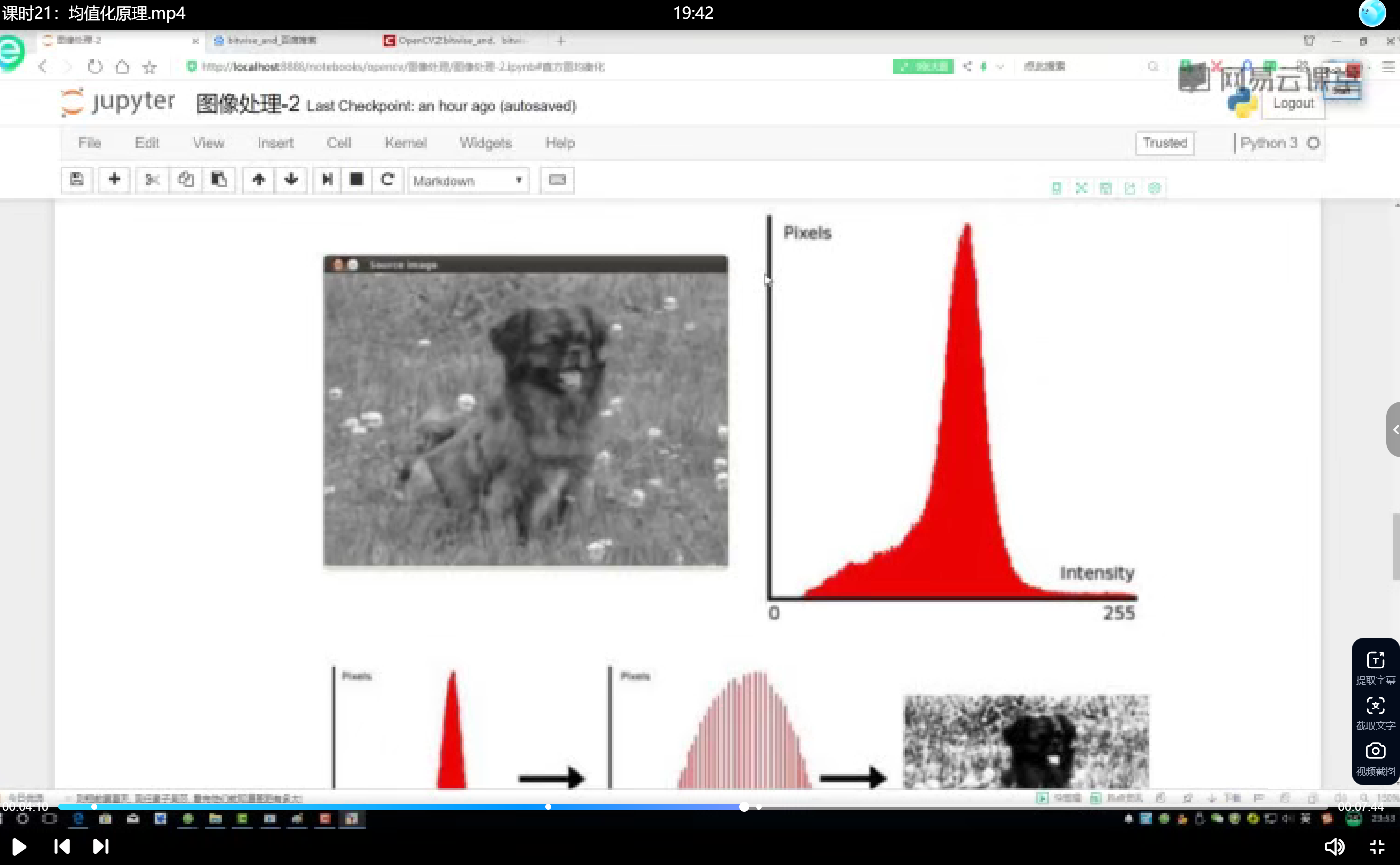
直方图均衡化
通过概率分布映射改善图像对比度,核心是重新分配像素亮度值。统计各灰度级出现频率,计算累积分布函数,最终映射到新灰度级。公式为:
新灰度值 = 累积概率 × 255
狗图像处理中,原始集中分布的灰度值经过均衡化后,动态范围明显扩大,暗部细节更清晰。
掩码实操步骤
使用OpenCV实现时需注意数据类型一致性。np.zeros()初始化矩阵,通过image.shape确保尺寸匹配,指定ROI区域赋值为255。关键代码示例:
mask = np.zeros(image.shape[:2], dtype=np.uint8)
cv2.rectangle(mask, (x,y), (x+w,y+h), 255, -1)
result = cv2.bitwise_and(image, image, mask=mask)
直方图对比分析
均衡化前后数据差异显著。原始直方图通常呈现窄而高的单峰分布,均衡后变为宽而平的分布。亮度通道变化最明显,如低对比度的人脸图像处理后,五官轮廓更突出。
可视化对比时,建议并排显示原始图像、直方图及处理后的结果,直观展示灰度值分布变化。
技术要点
- 掩码参数:必须为8位无符号整型(
dtype=np.uint8),否则按位运算会报错。 - 均衡化计算:需先归一化灰度频率为概率分布,映射后四舍五入取整。
- 通道处理:彩色图像通常转换到HSV空间后仅对V通道均衡化,避免颜色失真。
代码中需特别检查矩阵类型,错误使用浮点型会导### 直方图均衡化技术详解
全局直方图均衡化实现
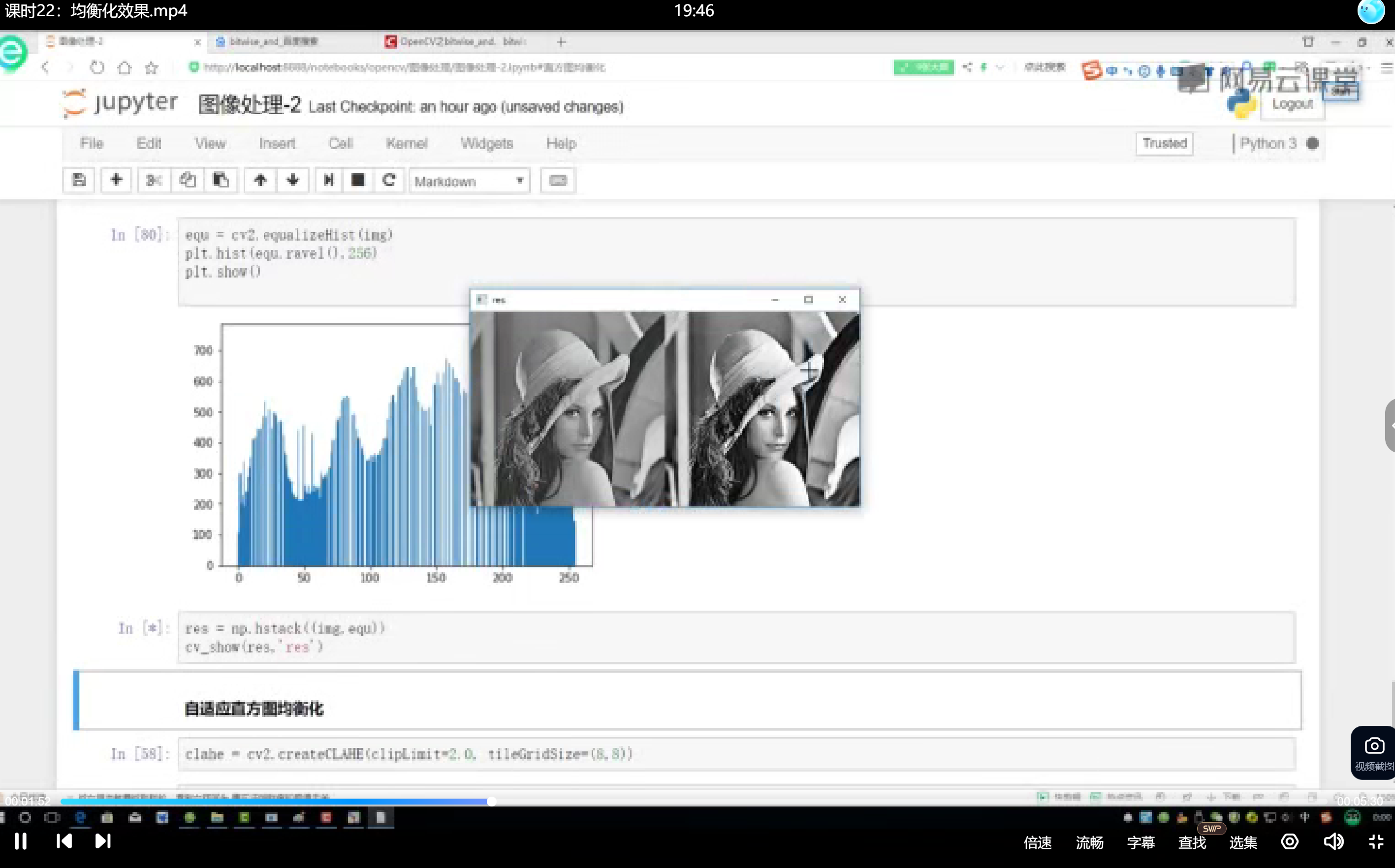
使用OpenCV的cv2.equalizeHist()函数处理单通道灰度图像,该函数会自动完成像素值重新分布。典型代码示例:
import cv2
gray_img = cv2.imread('input.jpg', 0)
equalized_img = cv2.equalizeHist(gray_img)
处理后的直方图分布会从原始尖峰形态转变为相对平坦的分布,特别是原本占比少的灰度值区域会得到显著扩展。
视觉对比效果
通过np.hstack()水平拼接原图与均衡化结果可直观比较:
- 原始图像常表现为整体灰暗、细节模糊
- 均衡化图像呈现更高对比度,暗部细节更明显
- 可能伴随高光区域过曝(如面部反光区域亮度溢出)
数学原理
灰度映射公式为:
s_k = (L-1) \sum_{j=0}^k p_r(r_j)
其中L为灰度级数(通常256),p_r为灰度值概率分布。该计算过程会将累积分布函数线性拉伸到整个灰度范围。
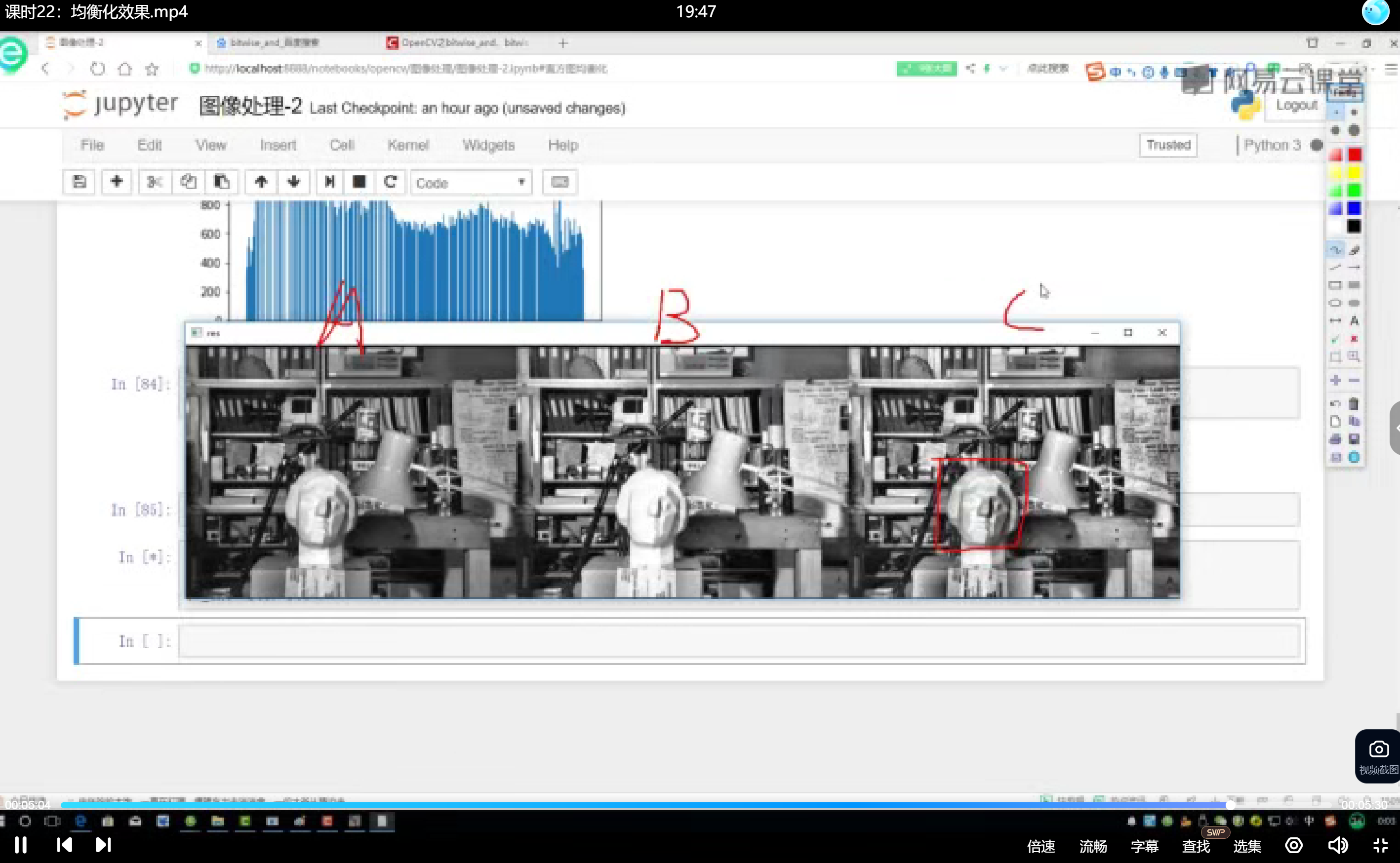
自适应直方图均衡化(CLAHE)
改进方法采用局部区域处理,关键参数:
clipLimit=2.0:控制对比度增强幅度tileGridSize=(8,8):定义局部处理块大小
实现代码:
clahe = cv2.createCLAHE(clipLimit=2.0, tileGridSize=(8,8))
adaptive_img = clahe.apply(gray_img)
技术对比分析
| 维度 | 全局均衡化 | CLAHE |
|---|---|---|
| 处理速度 | 快(单次计算) | 慢(分块计算+插值) |
| 细节保留 | 局部特征可能丢失 | 保持纹理结构 |
| 适用场景 | 整体低对比度图像 | 局部亮度差异大的图像 |
| 参数复杂度 | 无需调参 | 需调整clipLimit和网格尺寸 |
应用选择建议
- 医学影像处理优先考虑CLAHE,可增强病灶区域同时保留正常组织细节
- 监控视频增强适合全局均衡化,满足实时性要求
- 人脸识别预处理推荐结合两种方法,在ROI区域使用自适应处理
注意事项
- 彩色图像需转换到YUV/YCrCb空间仅处理亮度通道
- 高噪声图像需先降噪再均衡化
- 文档类图像可能因过度增强导致文字笔画粘连
- 分块尺寸不宜过小(建议不小于32x32)避免网格伪影
扩展应用技巧
- 结合伽马校正调节中间调对比度
- 对特定灰度区间进行分段均衡化
- 使用直方图规定化匹配特定分布模板
效果评估指标
- 信息熵:均衡化后图像熵值应增大
- 边缘梯度:有效增强时平均梯度提升20%-50%
- 局部对比度:通过SSIM指数评估细节保持度致掩码失效。
时域与频域对比
时域分析以时间为参照,描述事件随时间变化的动态过程,例如具体时间点的行为记录。频域分析从周期性角度出发,关注事件的重复规律,例如行为的周期性模式。时域呈现动态过程,频域则抽象为静态的频率成分。
频域定义与数学本质
频域通过“上帝视角”忽略具体时间点,仅提取周期性特征。数学上,任何周期信号均可分解为不同频率正弦波的叠加。例如,矩形波可通过无限多个正弦波逼近,其公式表示为:
f(t) = \sum_{k=1}^{\infty} \frac{4}{(2k-1)\pi} \sin((2k-1)\omega t)
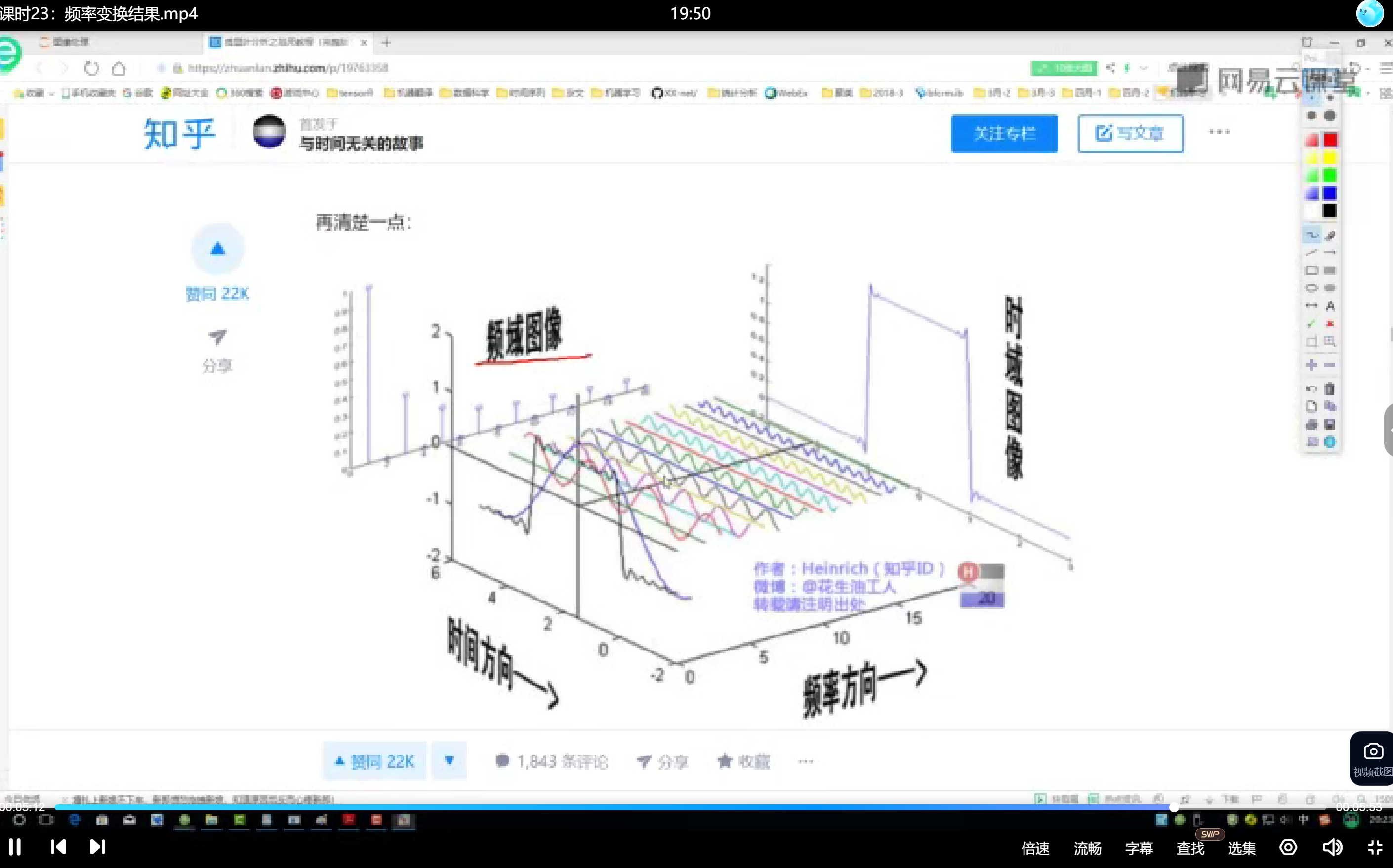
频域图像与叠加原理
频域图像横轴为频率,纵轴为振幅。低频成分对应平缓变化且振幅较大,高频成分对应快速变化且振幅较小。例如:
- 单一正弦波:\cos(x)
- 叠加两个正弦波:\cos(x) + a\cos(3x)
- 叠加更多正弦波可逼近复杂波形(如矩形波)。
傅里叶变换在图像处理中的应用
高频分量对应图像边缘和细节,低频分量对应平滑区域。滤波操作通过频域处理实现:
- 低通滤波:保留低频,用于图像去噪。
- 高通滤波:保留高频,用于边缘增强。
OpenCV实现关键步骤:
- 输入图像转换为
np.float32格式 - 调用
cv2.dft()进行正变换,结果需用np.fft.fftshift()将零频移至中心 - 逆变换通过
cv2.idft()还原图像
核心公式
离散傅里叶变换(DFT)公式:
F(k) = \sum_{n=0}^{N-1} f(n) e^{-j 2\pi kn/N}
逆变换(IDFT)公式:
f(n) = \frac{1}{N} \sum_{k=0}^{N-1} F(k) e^{j 2\pi kn/N}
易混淆点
- 时域信号强调时间顺序,频域信号强调频率分布。
- 高频分量振幅小但影响快速变化部分,低频分量振幅大但影响整体轮廓。
傅里叶变换的作用
傅里叶变换将图像从空间域转换到频域,便于分析不同频率成分的特性及处理。高频和低频分量分别对应图像的不同特征,通过滤波操作可实现图像增强或降噪。
高频与低频的定义
高频分量
- 对应图像中变化剧烈的灰度分量,如边缘、纹理或噪声。
- 在频域中表现为远离中心的外围区域。
- 示例:物体边界(船与水的交界处)或快速变化的像素值。
低频分量
- 对应图像中变化平缓的灰度分量,如整体背景或平滑区域。
- 在频域中集中在中心区域。
- 示例:均匀的大海或缓慢过渡的阴影。
滤波器的类型与作用
低通滤波器
- 保留低频分量,抑制高频。
- 效果:图像模糊化,边缘细节减弱。
- 实现方式:在频域中屏蔽外围区域(如设置中心区域为1,其余为0)。
高通滤波器
- 保留高频分量,抑制低频。
- 效果:边缘锐化,平滑区域减弱。
- 实现方式:在频域中屏蔽中心区域(如设置外围区域为1,中心为0)。
OpenCV中的傅里叶变换实现
核心函数
cv2.dft():执行傅里叶变换,输入需为np.float32格式。cv2.idft():执行逆傅里叶变换还原图像。
处理流程
- 转换图像格式为浮点型:
img_float32 = np.float32(img) - 执行傅里叶变换并中心化:
dft = cv2.dft(img_float32, flags=cv2.DFT_COMPLEX_OUTPUT) dft_shift = np.fft.fftshift(dft) - 计算幅度谱并可视化:
magnitude_spectrum = 20 * np.log(cv2.magnitude(dft_shift[:,:,0], dft_shift[:,:,1]))
频域分析结果解读
- 中心区域:亮度高,代表低频分量(图像整体结构)。
- 外围区域:亮度低,代表高频分量(细节或噪声)。
- 物理意义:距离中心越远,频率越高,对应图像中更细微的变化。
应用场景示例
低通滤波实现模糊效果
- 创建掩膜保留中心低频区域:
mask = np.zeros((rows, cols, 2), np.uint8) mask[crow-30:crow+30, ccol-30:ccol+30] = 1 - 逆变换还原图像:
idft_shift = dft_shift * mask img_back = cv2.idft(np.fft.ifftshift(idft_shift))
高通滤波实现边缘增强
- 创建掩膜保留外围高频区域:
mask = np.ones((rows, cols, 2), np.uint8) mask[crow-30:crow+30, ccol-30:ccol+30] = 0
技术要点
- 频谱中心化:使用
np.fft.fftshift将低频移至中心,逆变换前需ifftshift还原。 - 双通道处理:傅里叶变换结果为复数(实部+虚部),需通过
cv2.magnitude转换为幅值。 - 可视化增强:对数变换(
20*np.log)可提升幅度谱的显示效果。
通过频域处理,可高效实现图像去噪、边缘检测等操作,优于空间域卷积的复杂度。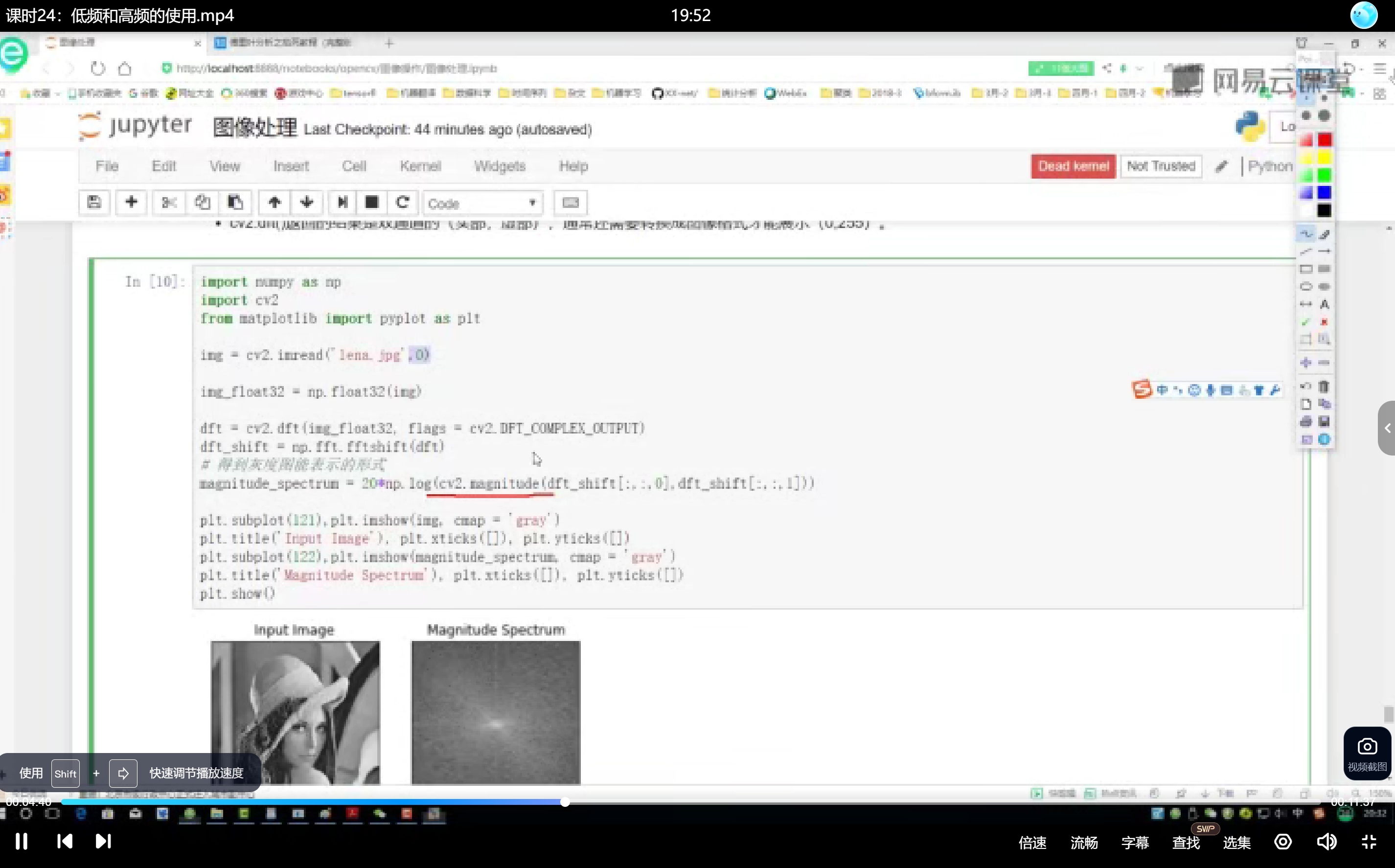
银行卡卡号识别项目实战指南
项目目标与输出要求
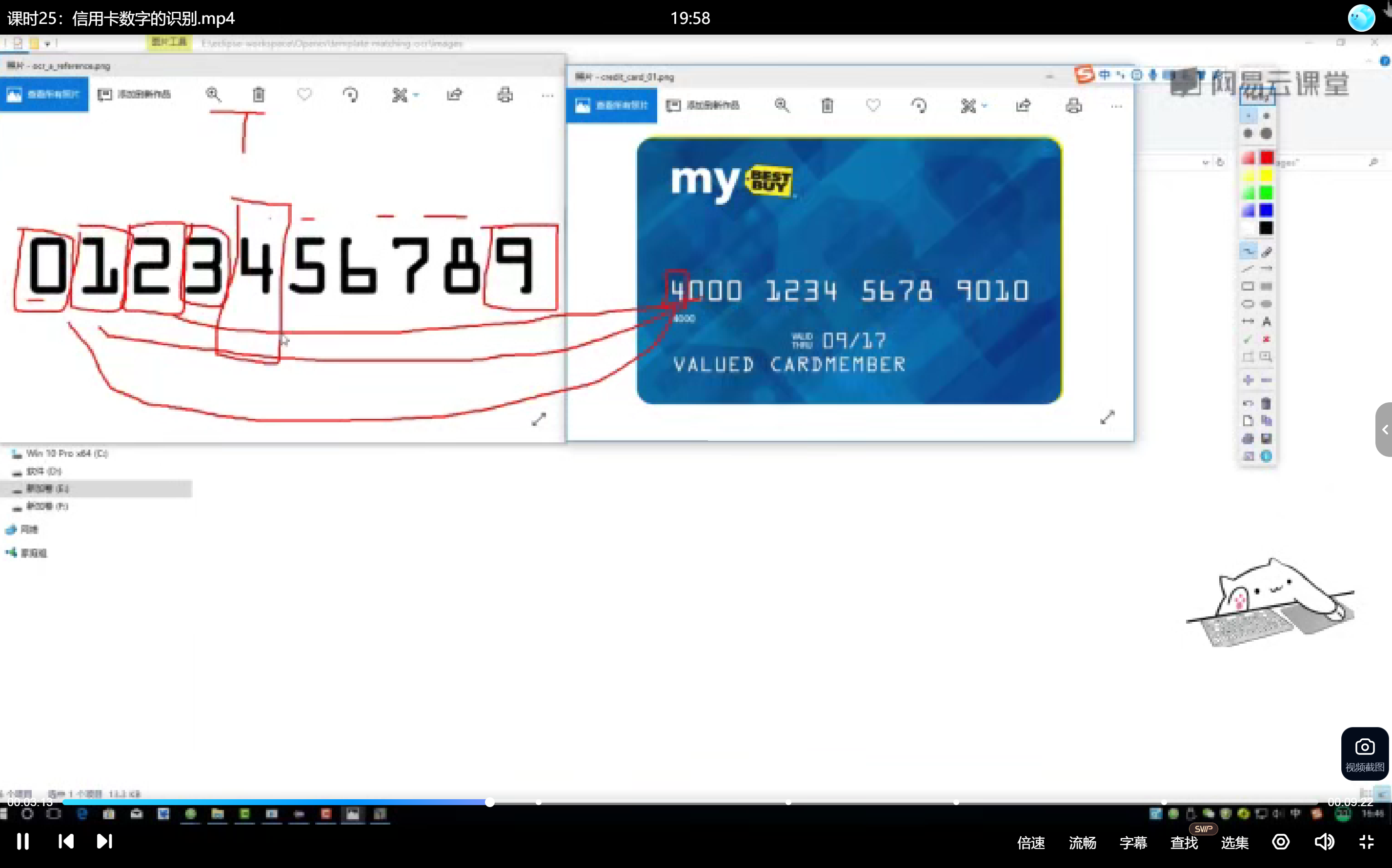
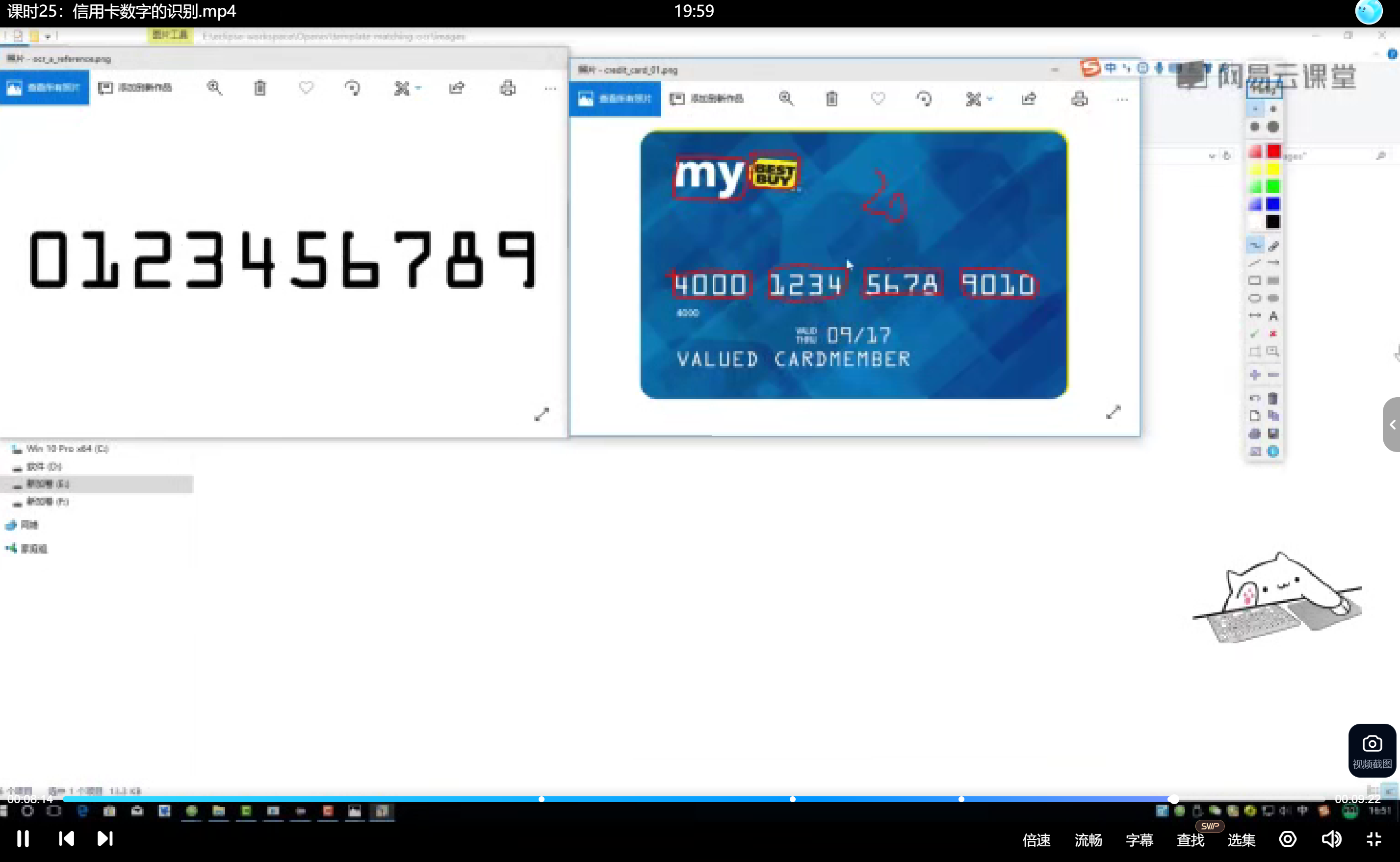
输入银行卡图像后,识别并输出卡号数字序列及其对应位置,类似车牌识别系统。输出要求包括分组输出数字序列(如4000 1234 5678 9010),每组数字需用矩形框标注在原图上。
技术基础要求
掌握OpenCV基本操作、形态学处理技术、模板匹配方法、图像预处理技术。
模板准备与轮廓检测
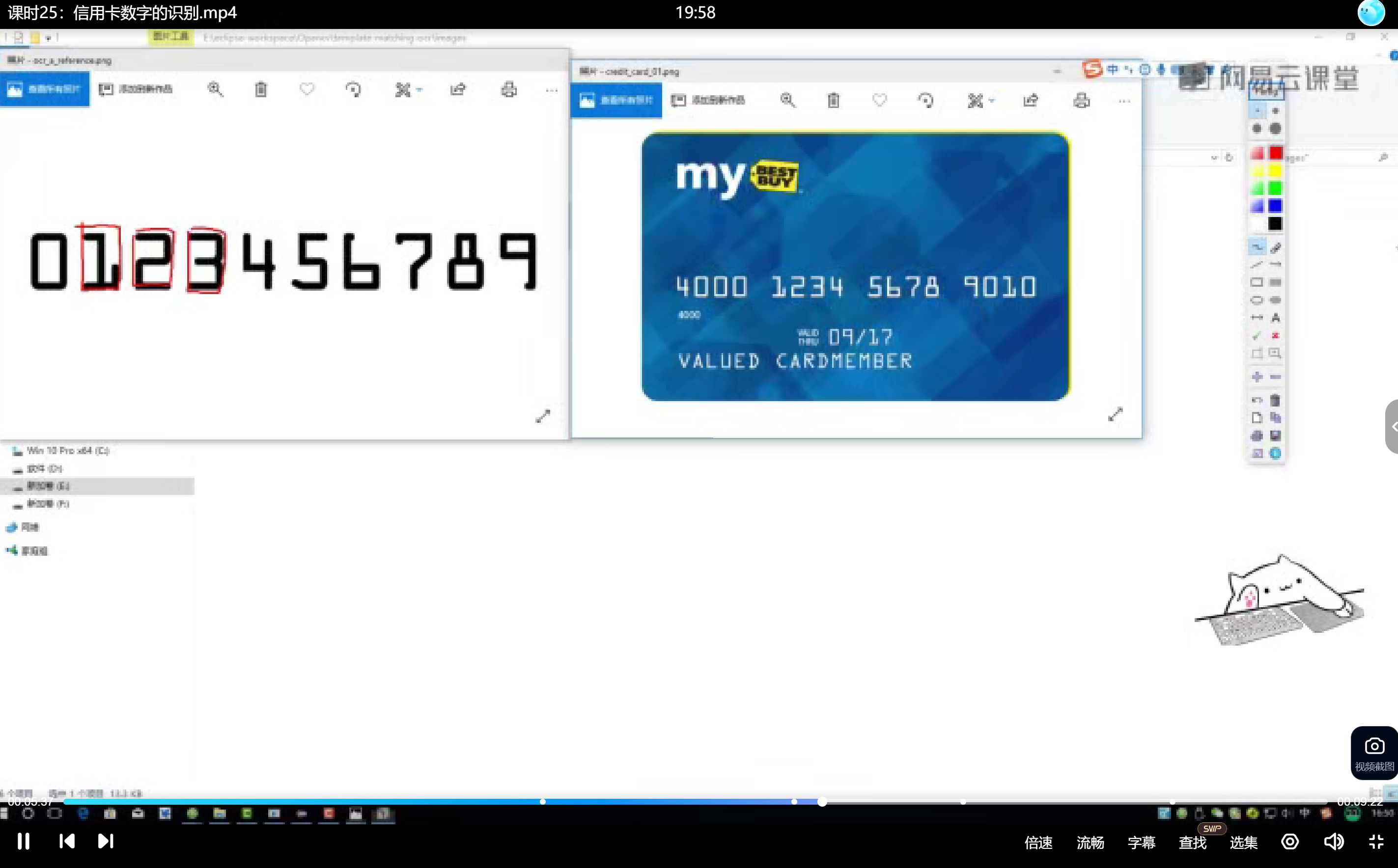
使用与目标字体风格一致的模板(如银行卡专用字体),包含完整数字集0-9,每个数字需单独提取保存。对模板图像进行轮廓检测,优先选择外轮廓(数字的外边界),获取每个数字的外接矩形。
匹配原理
将待识别区域与所有模板数字进行相似度计算,采用平方差等匹配方法,相似度最高的模板数字即为识别结果。
预处理流程
图像灰度化、二值化处理、轮廓检测、外接矩形获取。根据长宽比过滤非数字轮廓(如文字logo),银行卡数字具有特定长宽比例特征,保留符合数字特征的轮廓。将检测区域resize到与模板相同尺寸,保证匹配时的尺度一致性。
核心方法与关键技术点
基于模板匹配的数字识别,结合轮廓检测的精确定位。关键技术点包括模板的准确性和适配性、轮廓检测的准确性、预处理的质量控制。
实现步骤
准备专用数字模板库、输入图像预处理、粗定位数字区域、精确定位单个数字、模板匹配识别、结果输出与可视化。
知识点小结
- 模板匹配原理:通过对比目标区域与预存模板的相似度(如平方差计算)识别数字,需区分模板匹配与特征匹配的适用场景。
- 轮廓检测应用:提取数字外轮廓后生成外接矩形,用于标准化匹配区域,注意过滤非数字轮廓(如文字/logo)的长宽比筛选。
- 预处理流程:灰度转换→二值化→形态学操作(开运算/闭运算)优化轮廓质量,形态学操作顺序对结果影响显著。
- 银行卡数字识别步骤:模板数字分离、输入图像区域检测、轮廓匹配与Resize、分组输出,四分组逻辑需与卡号标准格式对齐。
- 项目实战难点:字体特异性(如银行卡专用字体需定制模板),模板字体一致性决定匹配准确率。
参数设置与代码实现
-
核心参数
使用命令行参数传递输入图像(-i)和模板图像(-t)路径,例如:python script.py -i images/credit_card_03.png -t images/ocr_a_reference.png -
参数作用
-i:指定信用卡等输入图像的路径。-t:指定包含数字0-9的模板图像路径。
-
信用卡类型映射
通过字典映射卡号首数字识别类型,例如:card_type = { "3": "American Express", "4": "Visa", "5": "MasterCard" }
环境配置与工具选择
-
开发工具推荐
- Eclipse:支持多语言(Python/Java/C),适合大型项目调试。
- PyCharm:专为Python设计,集成调试工具。
- Jupyter Notebook:适合分步验证代码片段。
-
运行环境配置
- 在IDE中配置运行参数:
- 右键点击
.py文件选择 Run As → Run Configurations。 - 在 Program arguments 输入参数,例如
-i images/credit_card_03.png -t images/ocr_a_reference.png。
- 右键点击
- 路径规范:使用相对路径,确保项目结构一致。
- 在IDE中配置运行参数:
图像处理流程
灰度与二值化处理
- 灰度转换
使用cv2.cvtColor()将模板图像转为灰度图:gray = cv2.cvtColor(template, cv2.COLOR_BGR2GRAY) - 二值化
反二值化处理(背景黑/数字白),便于轮廓检测:_, binary = cv2.threshold(gray, 10, 255, cv2.THRESH_BINARY_INV)
轮廓检测与排序
- 轮廓检测
使用cv2.findContours()检测外轮廓并简化坐标:contours, _ = cv2.findContours(binary, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE) - 轮廓排序
按从左到右排序轮廓(自定义函数sort_contours):contours_sorted = sort_contours(contours, method="left-to-right")
模板匹配
- 匹配过程
对信用卡图像中的数字区域与模板逐一匹配,计算相似度(如相关系数)。 - 结果验证
输出卡类型(如MasterCard)和卡号(如5412751234567890)。
关键步骤详解
- 读取模板图像
template = cv2.imread(args["t"]) - 灰度转换
减少计算量,保留明暗关系:gray_template = cv2.cvtColor(template, cv2.COLOR_BGR2GRAY) - 二值化处理
确保轮廓检测输入为二值图像:_, binary_template = cv2.threshold(gray_template, 10, 255, cv2.THRESH_BINARY_INV)
常见问题与调试建议
- 路径错误:检查相对路径是否与项目结构一致。
- 轮廓检测失败:确认二值化参数(如阈值)是否适配图像。
- 匹配精度低:调整模板与输入图像的缩放比例或使用多尺度匹配。
应用场景扩展
- 车牌识别:类似流程可用于车牌字符分割与识别。
- 文档OCR:调整预处理步骤(如去噪、倾斜校正)适配不同场景。
代码块严格遵循Markdown格式,无步骤词汇,内容模块化分点呈现。
信用卡数字识别流程详解
轮廓检测
图像预处理后调用cv2.findContours()函数,传入图像副本.copy()而非原始图像。选择cv2.RETR_EXTERNAL轮廓检测模式仅获取外轮廓,忽略内轮廓干扰。轮廓近似方法采用cv2.CHAIN_APPROX_SIMPLE压缩冗余坐标点。
轮廓绘制使用cv2.drawContours(),参数-1表示绘制全部轮廓,设定颜色为(0,0,255)的红色线条,线宽3像素。验证阶段通过np.array(refCnts).shape检查轮廓数量,信用卡数字区域应精确检测到10个独立轮廓。
轮廓排序
轮廓检测结果无序,需按数字实际排列顺序排序。计算每个轮廓的外接矩形cv2.boundingRect(),获取矩形左上角坐标(x,y)作为排序依据。自定义排序函数myutils.sort_contours()按x坐标升序排列,确保轮廓索引与数字值对应(索引0对应数字0)。
外接矩形返回值为(x,y,w,h)四元组,排序后需验证轮廓顺序与数字显示顺序完全一致。典型错误包括未处理坐标相同的轮廓或排序方向错误。
模板匹配
从排序后的轮廓中提取ROI区域,使用外接矩形坐标截取ref[y:y+h, x:x+w]图像块。所有数字模板统一resize至(57,88)标准尺寸,消除尺寸差异影响。构建digits字典存储模板,键为数字0-9,值为对应ROI图像。
关键注意事项包括必须使用.copy()保留原始图像数据,每个模板尺寸严格一致。建议每步处理后通过cv2.imshow()显示中间结果,例如:
for (i, (x, y, w, h)) in enumerate(refCnts):
roi = ref[y:y+h, x:x+w]
roi = cv2.resize(roi, (57, 88))
digits[i] = roi
调试验证
实时显示轮廓检测结果,打印len(contours)验证轮廓数量。外接矩形计算阶段检查坐标值是否在合理范围内。模板匹配阶段核对字典键值对应关系,确保数字0的模板存储在digits[0]中。常见错误包括ROI截取越界或resize比例失调。
数学公式验证示例:
轮廓面积计算
[ S = \sum_{i=1}^{n} (x_i y_{i+1} - x_{i+1} y_i) ]
其中(x_{n+1}=x_1, y_{n+1}=y_1)
图像预处理流程
形态学操作
核大小根据任务需求设定,用于去除背景干扰。预处理步骤包含读取图像、调整尺寸、转换为灰度图,为后续操作奠定基础。
顶帽操作
通过指定与字体区域匹配的核大小,突出图像中的明亮区域(如文字)。该操作有效分离前景与背景,增强目标区域的对比度。
边缘检测与二值化
索贝尔算子
仅采用x方向梯度计算边缘,实验表明比xy双向结合效果更优。通过梯度幅度强化数字边缘特征。
膨胀与腐蚀(B操作)
膨胀操作连接断裂轮廓,腐蚀操作消除细小噪声。两者结合形成连续块状区域,便于后续轮廓提取。
自适应阈值
针对双峰分布的灰度直方图,自动选择最佳阈值完成二值化。避免手动调参,适应光照不均的场景。
轮廓处理与匹配
轮廓筛选
基于边界矩形长宽比等几何特征过滤无效轮廓,保留潜在数字区域。剔除过小或比例不符的干扰项。
模板匹配
对筛选后的大轮廓内部进行逐数字匹配。通过外接矩形定位目标,调整尺寸后与模板库比对,确定具体数值。
关键参数调整建议
- 形态学核大小需匹配字体物理尺寸。
- 索贝尔算子方向选择依赖数字排列方向。
- 自适应阈值方法适用于光照变化场景。
- 长宽比过滤阈值应根据实际数字比例设定。
通过流程化组合这些操作,可有效提升复杂背景下数字识别的鲁棒性。各步骤参数需通过测试集迭代优化。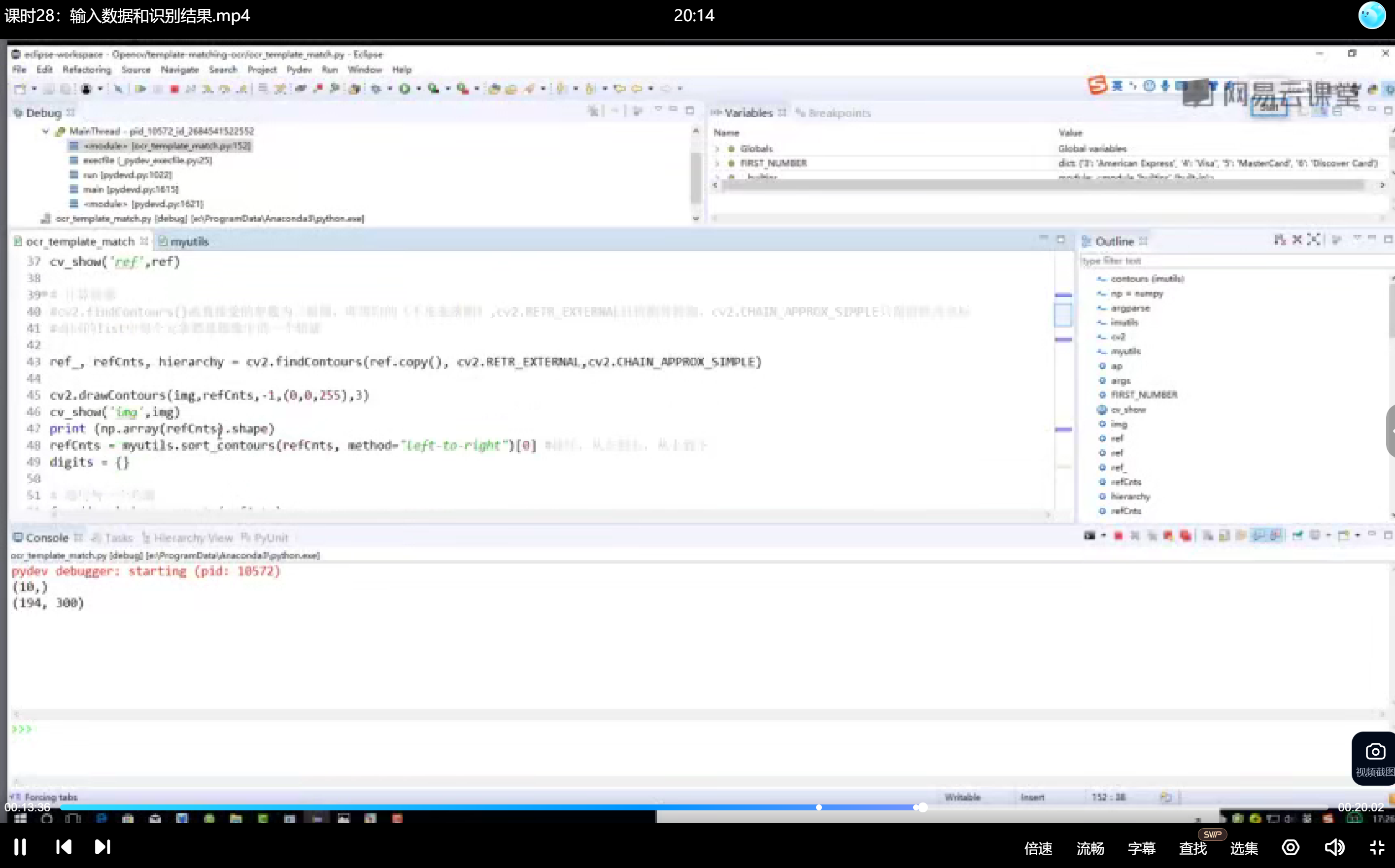
文档轮廓提取与扫描的实现方法
图像预处理
将输入图像转换为灰度图,减少计算复杂度。应用高斯滤波消除噪声,避免后续边缘检测受到干扰。高斯滤波核大小通常为奇数,如(5,5),标准差根据图像噪声程度调整。
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
blurred = cv2.GaussianBlur(gray, (5, 5), 0)
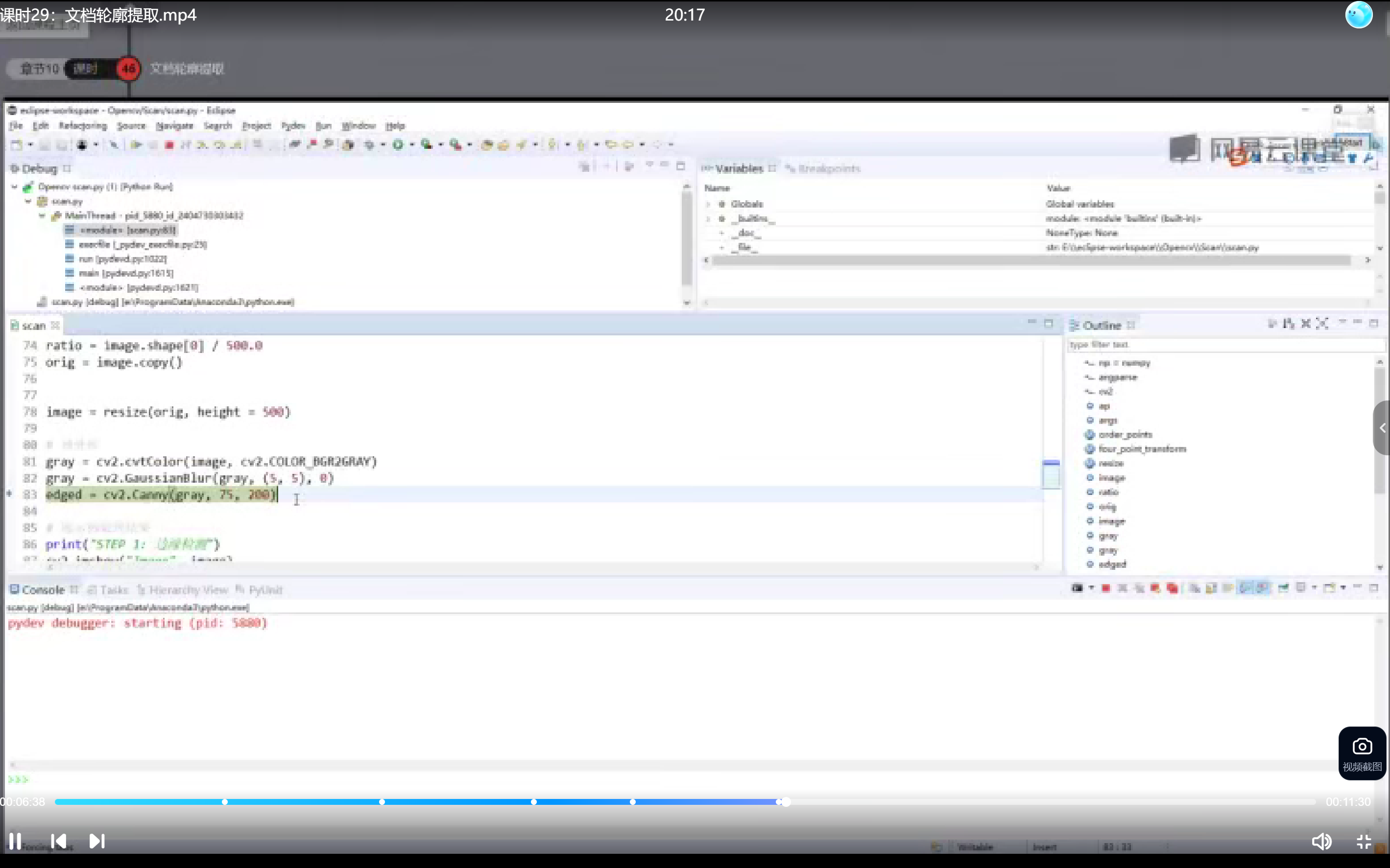
边缘检测
使用Canny算法进行边缘检测,阈值设置影响边缘提取效果。低阈值和高阈值的比例建议为1:2或1:3,例如50和150。
edged = cv2.Canny(blurred, 50, 150)
轮廓检测与筛选
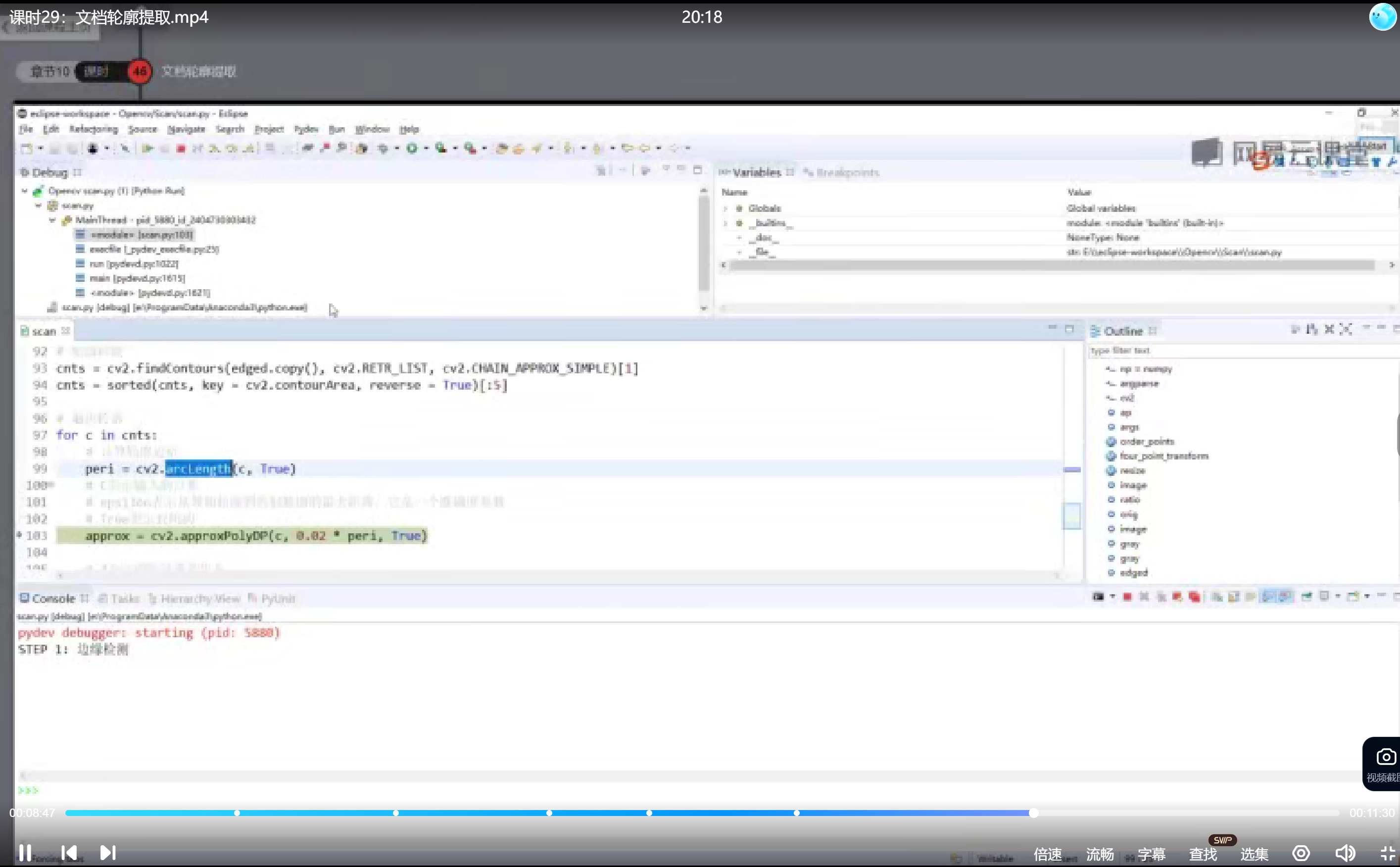
查找所有轮廓并保留最外层轮廓。按面积或周长排序,选择最大的轮廓作为文档边界。轮廓近似使用Douglas-Peucker算法,epsilon参数控制近似精度。
contours, _ = cv2.findContours(edged.copy(), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
contours = sorted(contours, key=cv2.contourArea, reverse=True)[:5]
peri = cv2.arcLength(contours[0], True)
approx = cv2.approxPolyDP(contours[0], 0.02 * peri, True)
透视变换
获取轮廓四个角点后,计算目标矩形尺寸。使用透视变换矩阵将倾斜文档校正为正面视图。目标点顺序需与原始点顺序一致,避免图像旋转。
def order_points(pts):
rect = np.zeros((4, 2), dtype="float32")
s = pts.sum(axis=1)
rect[0] = pts[np.argmin(s)]
rect[2] = pts[np.argmax(s)]
diff = np.diff(pts, axis=1)
rect[1] = pts[np.argmin(diff)]
rect[3] = pts[np.argmax(diff)]
return rect
def four_point_transform(image, pts):
rect = order_points(pts)
(tl, tr, br, bl) = rect
widthA = np.sqrt(((br[0] - bl[0]) ** 2) + ((br[1] - bl[1]) ** 2))
widthB = np.sqrt(((tr[0] - tl[0]) ** 2) + ((tr[1] - tl[1]) ** 2))
maxWidth = max(int(widthA), int(widthB))
heightA = np.sqrt(((tr[0] - br[0]) ** 2) + ((tr[1] - br[1]) ** 2))
heightB = np.sqrt(((tl[0] - bl[0]) ** 2) + ((tl[1] - bl[1]) ** 2))
maxHeight = max(int(heightA), int(heightB))
dst = np.array([
[0, 0],
[maxWidth - 1, 0],
[maxWidth - 1, maxHeight - 1],
[0, maxHeight - 1]], dtype="float32")
M = cv2.getPerspectiveTransform(rect, dst)
warped = cv2.warpPerspective(image, M, (maxWidth, maxHeight))
return warped
OCR预处理
对校正后的图像进行二值化处理,增强文字对比度。自适应阈值或大津法适用于不同光照条件下的文档。
warped_gray = cv2.cvtColor(warped, cv2.COLOR_BGR2GRAY)
_, thresh = cv2.threshold(warped_gray, 0, 255, cv2.THRESH_BINARY_INV | cv2.THRESH_OTSU)
关键参数调整建议
- Canny阈值:噪声较多时提高低阈值
- 轮廓近似精度:0.01-0.05倍周长平衡精度与效率
- 透视变换尺寸:根据原始文档长宽比保持比例
- 二值化方法:光照不均时采用自适应阈值
常见问题处理
- 轮廓检测失败:检查边缘检测结果是否闭合
- 透视扭曲:确保角点顺序正确对应
- 文字模糊:透视变换后使用锐化滤波器增强细节
透视变换的核心原理
透视变换通过3×3变换矩阵将二维图像坐标映射到三维齐次坐标系,最终投影回二维平面。关键步骤包括:
- 坐标点匹配:需提供四组对应的原始点与目标点(每组含x、y值),构成8个方程以求解矩阵的8个自由度。
- 齐次坐标转换:将二维点(x,y)(x,y)(x,y)扩展为齐次坐标(x,y,1)(x,y,1)(x,y,1),通过矩阵乘法实现平移、旋转等变换。
- 矩阵求解:OpenCV的
getPerspectiveTransform()函数自动计算变换矩阵MMM,形式如下:
M=[m11m12m13m21m22m23m31m32m33] M = \begin{bmatrix} m_{11} & m_{12} & m_{13} \\ m_{21} & m_{22} & m_{23} \\ m_{31} & m_{32} & m_{33} \end{bmatrix} M= m11m21m31m12m22m32m13m23m33
实现步骤与代码示例
1. 坐标点提取与排序
使用轮廓检测(如cv2.findContours)获取图像边缘,筛选出四个顶点并按固定顺序排列(如左上、右上、右下、左下)。
2. 计算目标尺寸
根据原始区域宽度www和高度hhh定义目标矩形坐标:
max_width = max(int(np.sqrt((tr[0] - tl[0])**2 + (tr[1] - tl[1])**2)),
int(np.sqrt((br[0] - bl[0])**2 + (br[1] - bl[1])**2)))
max_height = max(int(np.sqrt((bl[0] - tl[0])**2 + (bl[1] - tl[1])**2)),
int(np.sqrt((br[0] - tr[0])**2 + (br[1] - tr[1])**2)))
dst_points = np.array([[0, 0], [max_width-1, 0],
[max_width-1, max_height-1], [0, max_height-1]], dtype="float32")
3. 执行变换
调用OpenCV函数计算并应用变换矩阵:
M = cv2.getPerspectiveTransform(src_points, dst_points)
warped = cv2.warpPerspective(image, M, (max_width, max_height))
应用场景与注意事项
- 文档校正:将倾斜的文档图像转换为正视图,便于OCR处理。
- 视角修正:在自动驾驶中校正车载摄像头视角。
- 精度依赖:输入点坐标需精确,否则会导致形变失真。建议结合边缘检测与人工校验。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 8
8 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)