python基于Hadoop的电商数据分析系统设计与实现
前言
本文设计并实现了一种基于Hadoop的电商数据分析系统,旨在解决电商领域中海量数据的处理与分析难题。系统针对电商数据的多维度特性(如用户行为、交易记录、商品信息等),结合其数据量大、格式多样、实时性高、价值密度低的特点,构建了包括数据采集、清洗、分析和可视化在内的核心功能模块。系统采用分层架构,通过Flume和Kafka实现高效数据采集,基于HDFS进行分布式存储,利用Mapreduce和Spark完成数据处理,并借助Hive构建数据仓库,最终通过Echarts实现数据的可视化展示。经实际电商数据测试,系统在性能和准确性方面表现优异,能够稳定处理TB级数据,并在秒级内完成复杂分析任务。测试结果表明,系统为企业提供了精准的用户行为分析、商品推荐和销售预测等功能,显著提升了决策效率和市场竞争力。
一、项目介绍
开发语言:Python
python框架:Django
软件版本:python3.7/python3.8
数据库:mysql 5.7或更高版本
数据库工具:Navicat11
开发软件:PyCharm/vs code
二、功能介绍
随着电子商务的快速发展,平台每日产生的用户行为数据、交易记录、商品信息及社交化内容呈现爆发式增长,传统数据处理技术面临存储效率低、实时分析能力弱、多源异构数据融合困难等核心瓶颈。以某头部电商平台为例,其“双十一”单日数据量可突破PB级,涵盖结构化订单数据、半结构化日志流以及非结构化图文评论,现有单机架构难以支撑秒级响应的库存预警、动态定价及个性化推荐等高并发场景需求。基于Hadoop的电商数据分析系统需构建覆盖数据全生命周期的分布式解决方案:在数据存储层,要求系统兼容HDFS与列式数据库的混合存储模型,实现历史数据冷热分级管理,解决海量小文件存储碎片化问题;在计算层需集成MapReduce离线批处理与Spark Streaming实时流计算框架,满足促销期间流量洪峰下的秒级用户行为捕捉与小时级销售趋势预测;在应用层需搭建可配置化分析引擎,支持多维度交叉分析(如区域购买偏好与商品评价的情感倾向关联挖掘),并通过可视化界面输出可解释的决策建议(如基于协同过滤算法的爆款商品潜力预测)。同时,系统需提供API接口与企业现有CRM、ERP系统无缝对接,确保运营策略能快速迭代落地,最终形成“数据采集-清洗-分析-决策”闭环,为电商生态的精细化运营提供底层技术支撑。
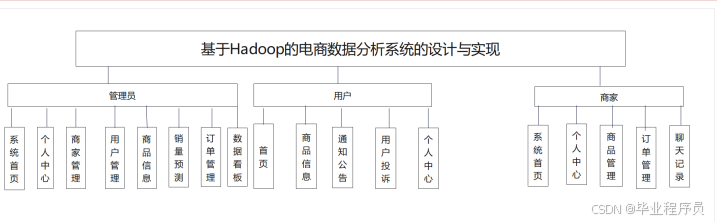
根据对系统需求的深入剖析,绘制一张功能模块图以形象化展示各功能模块间的相互关联。每个 角色对应各自专属的功能模块,这种模块化的架构显著提升了整个系统的结构明晰度与逻辑性。功能 模块图具体如图2 所示。
————————————
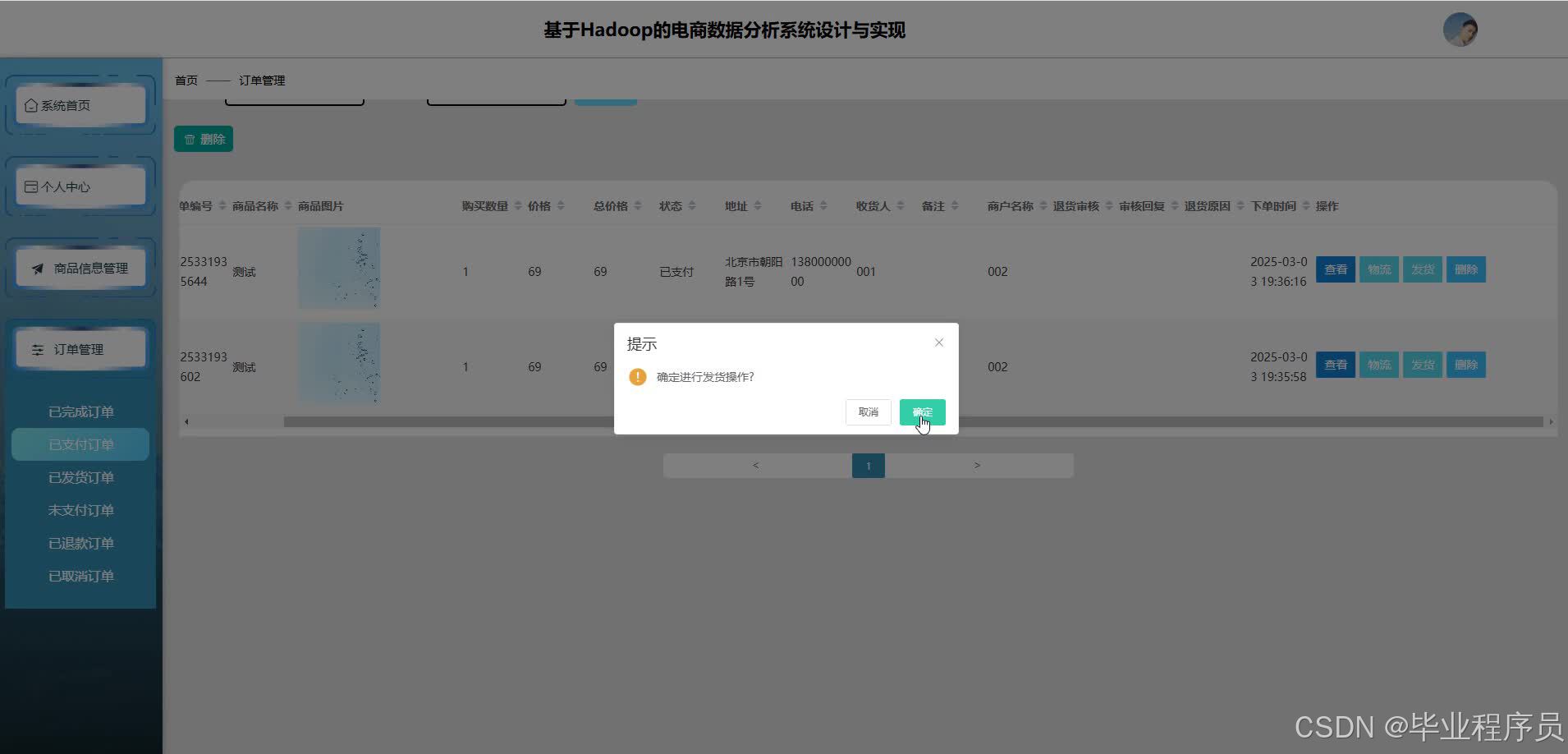
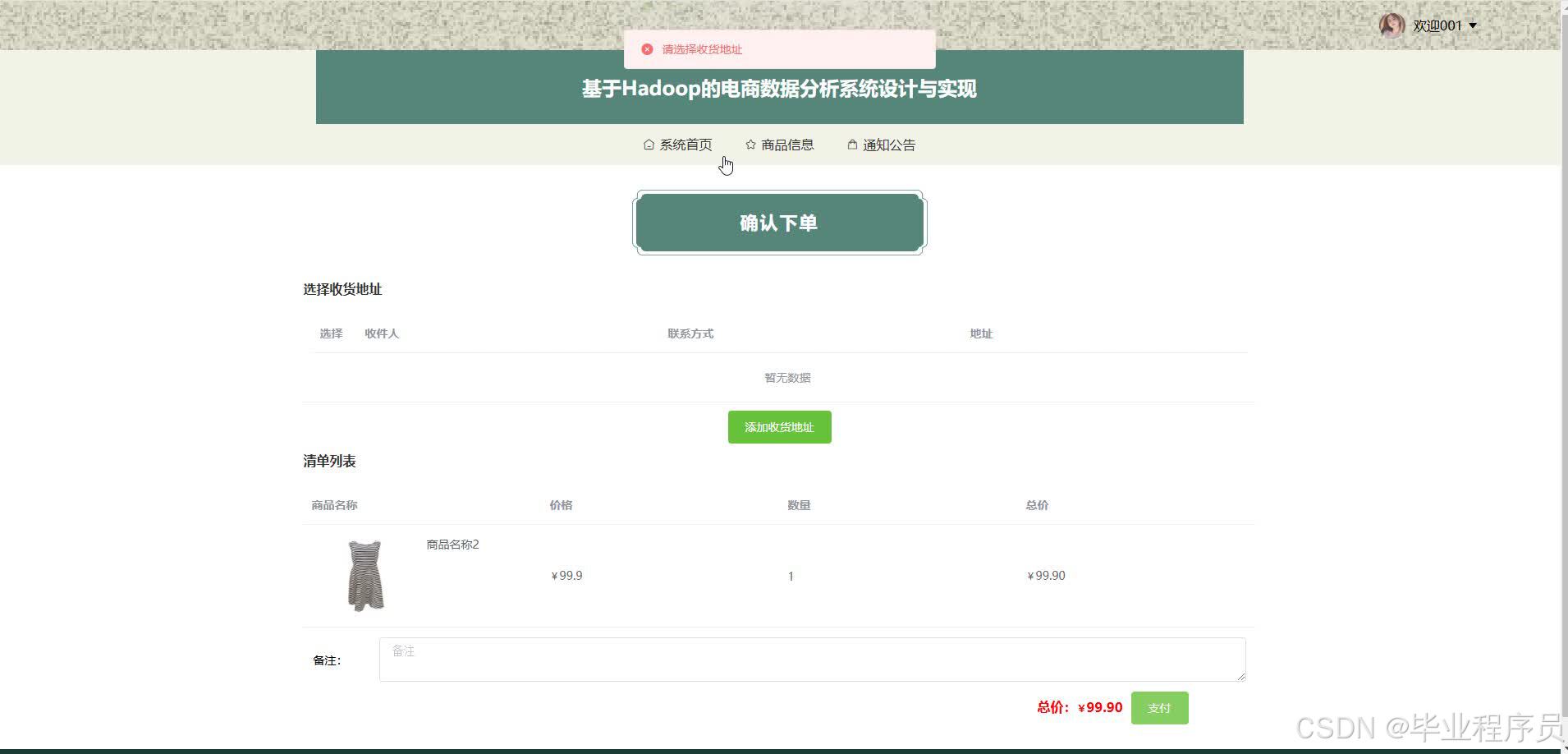
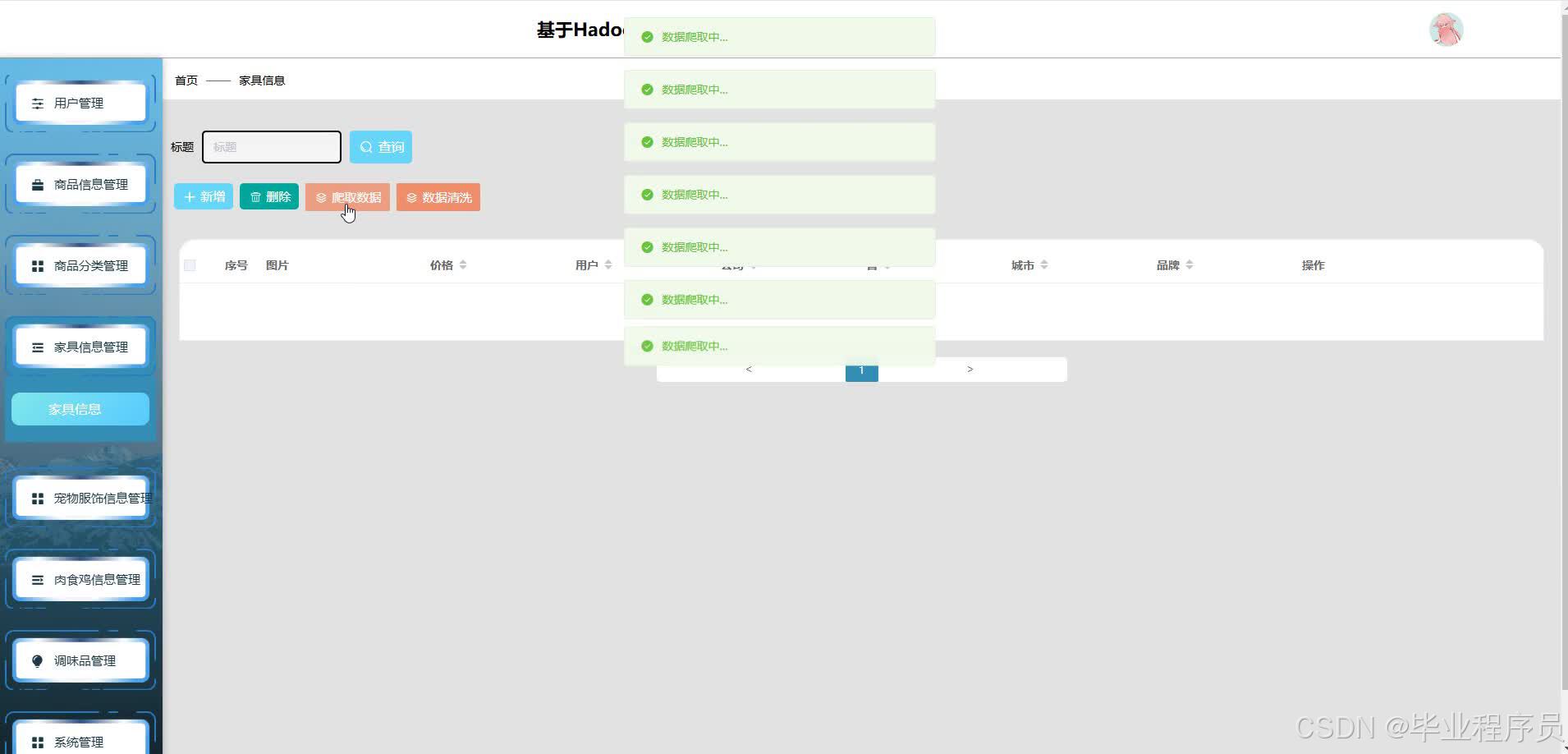
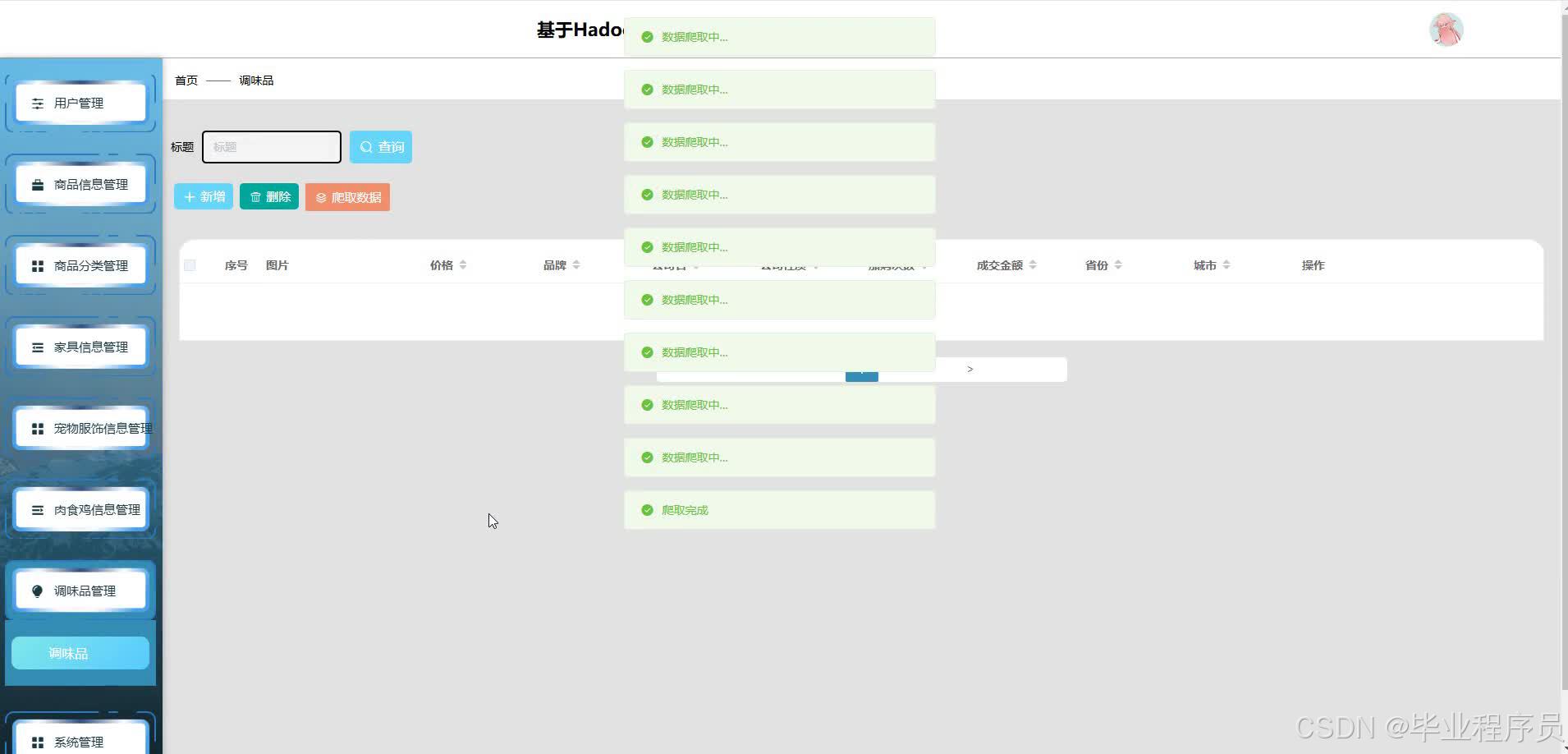
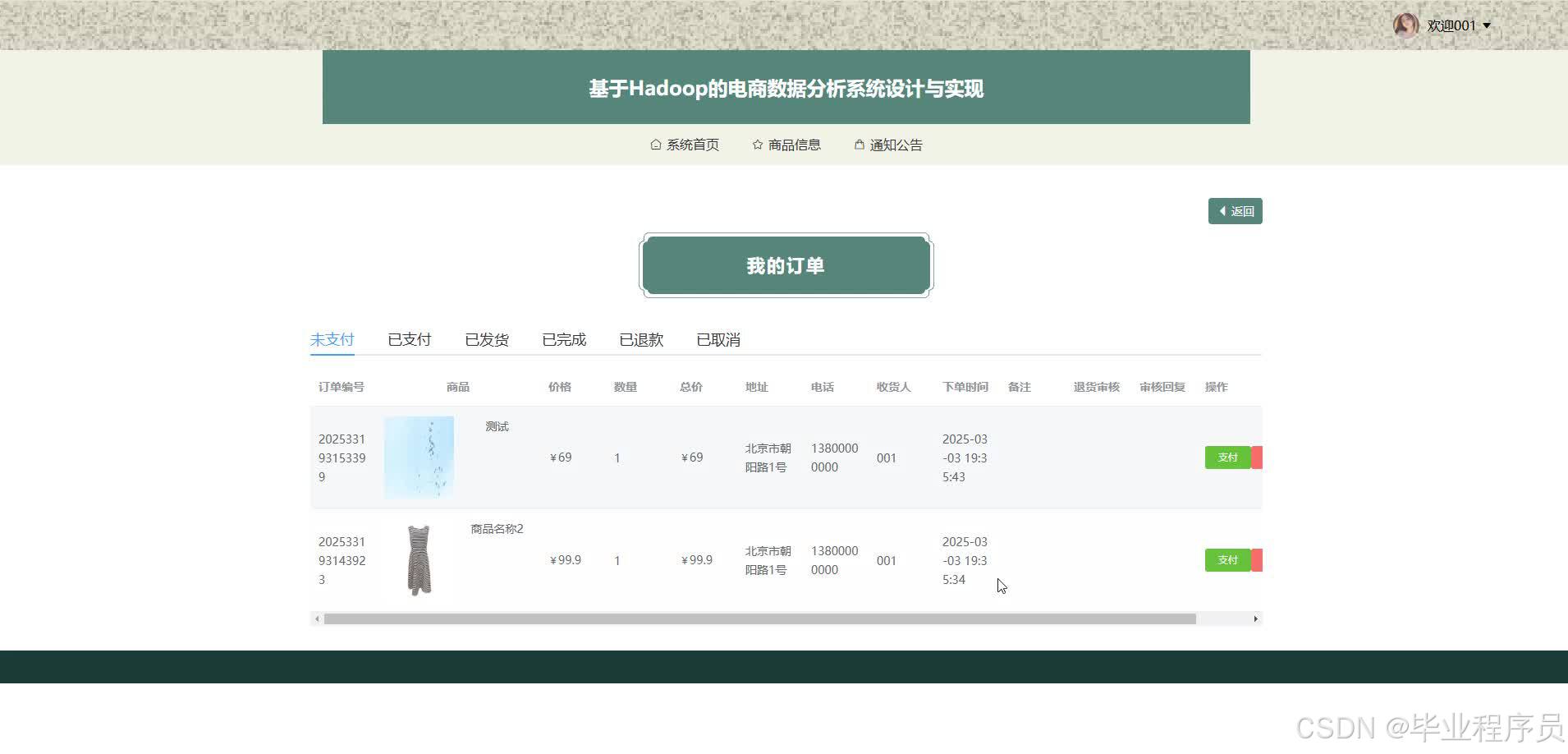
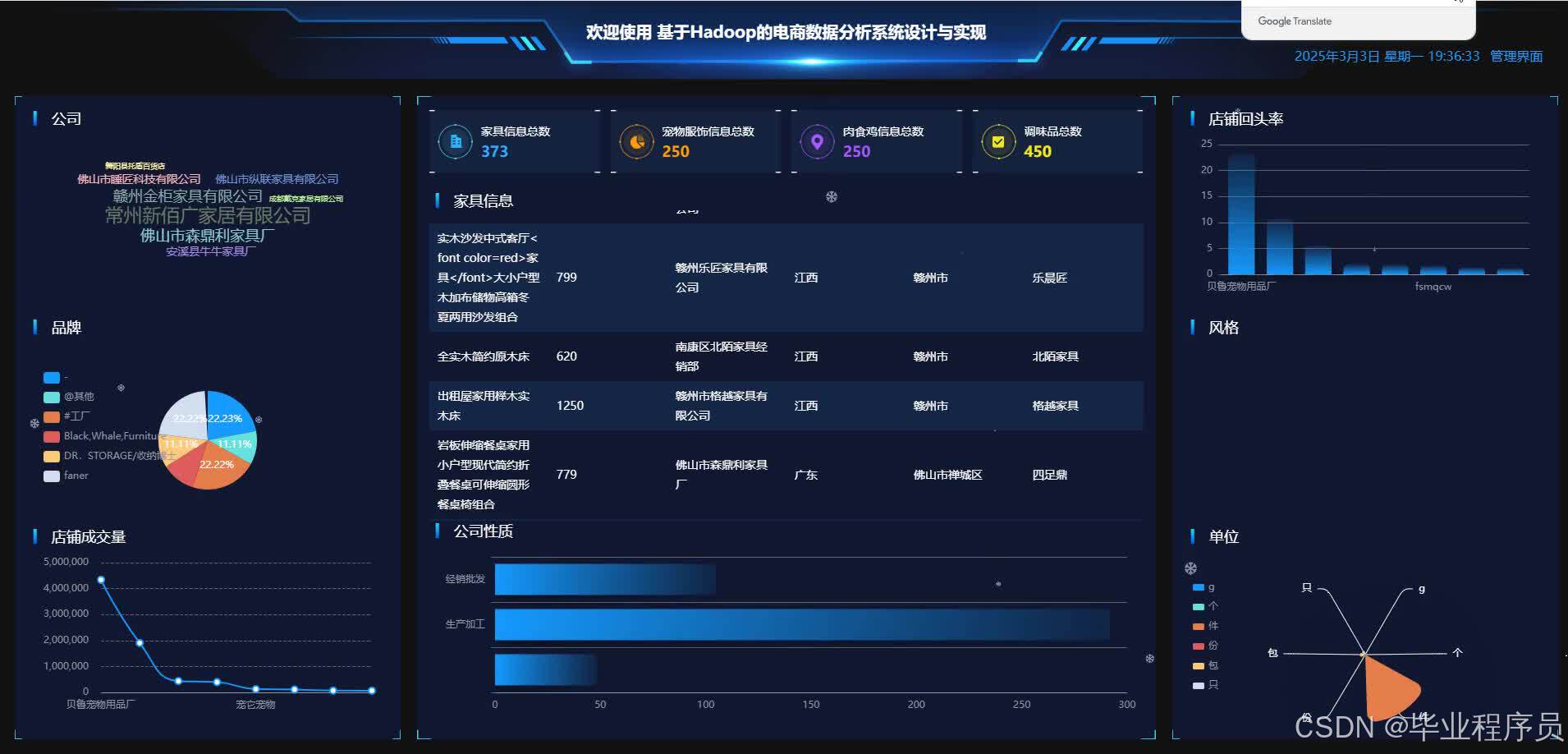
四、效果图
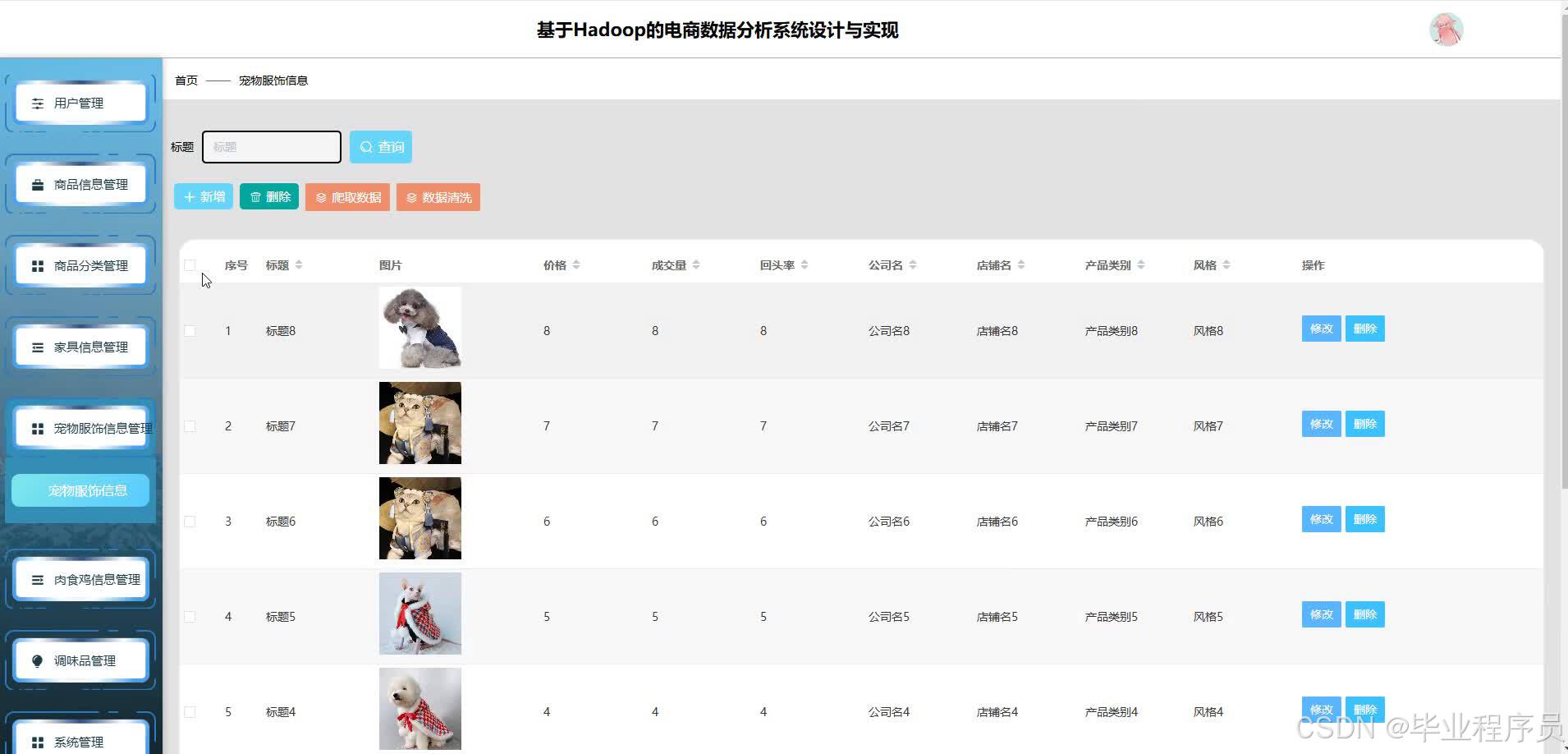
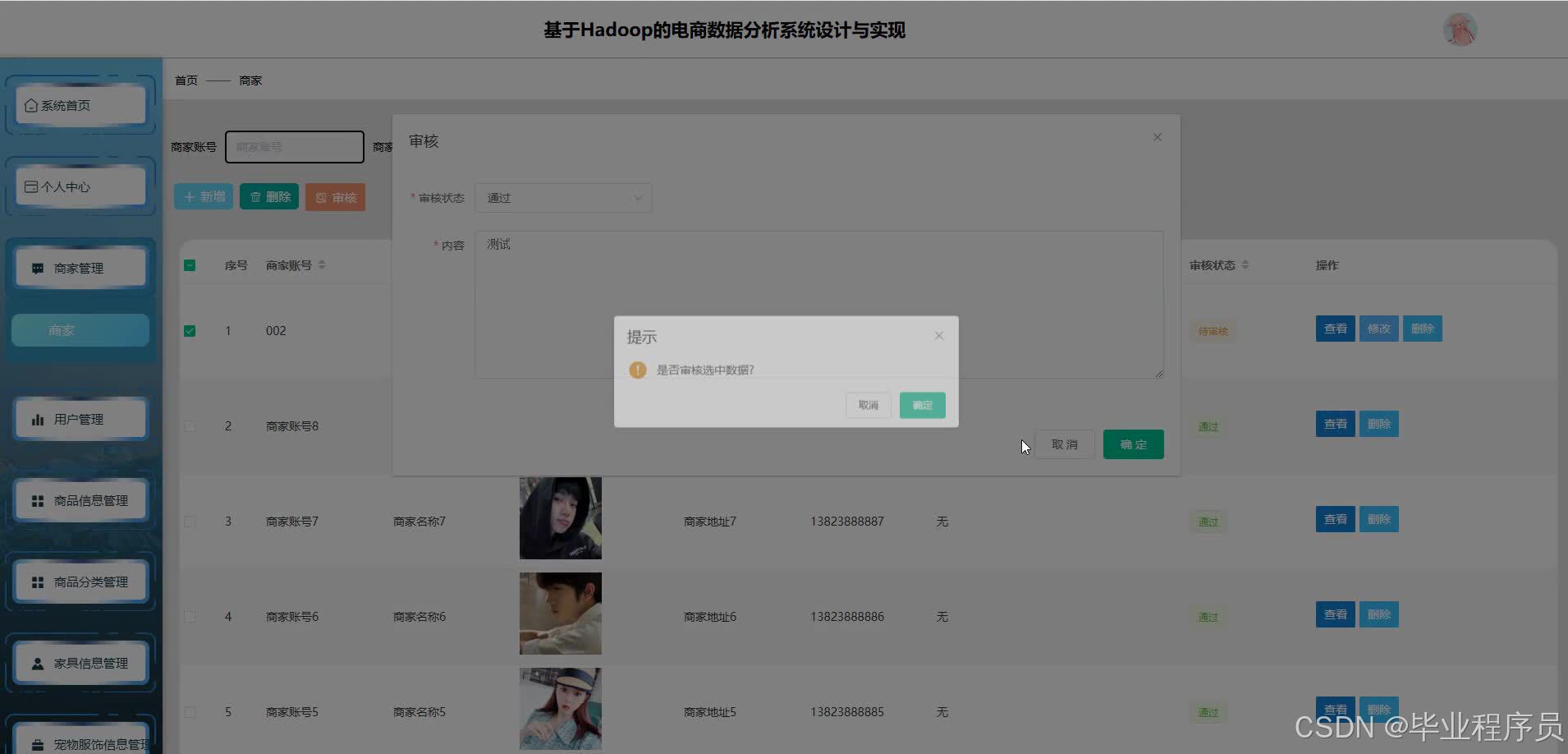
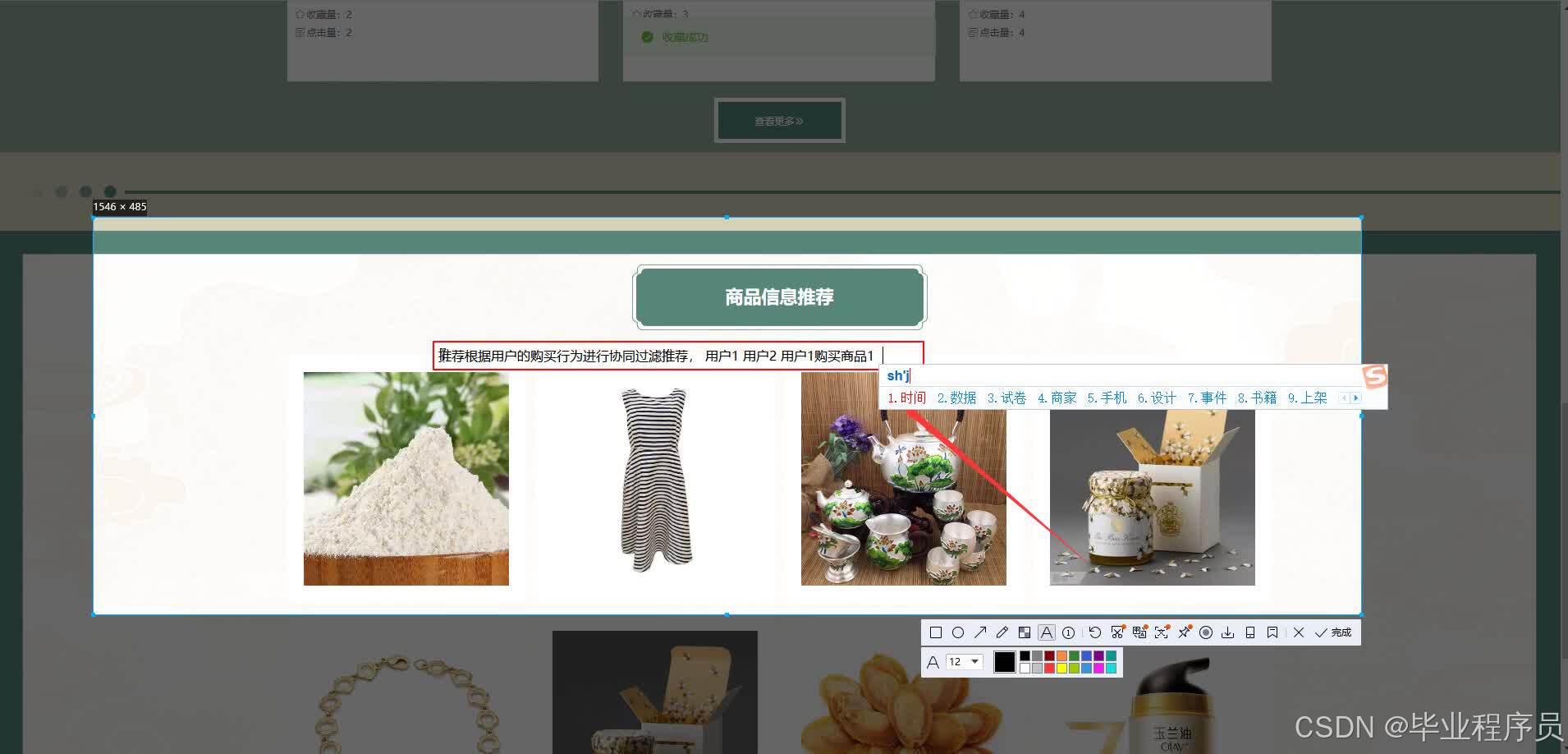
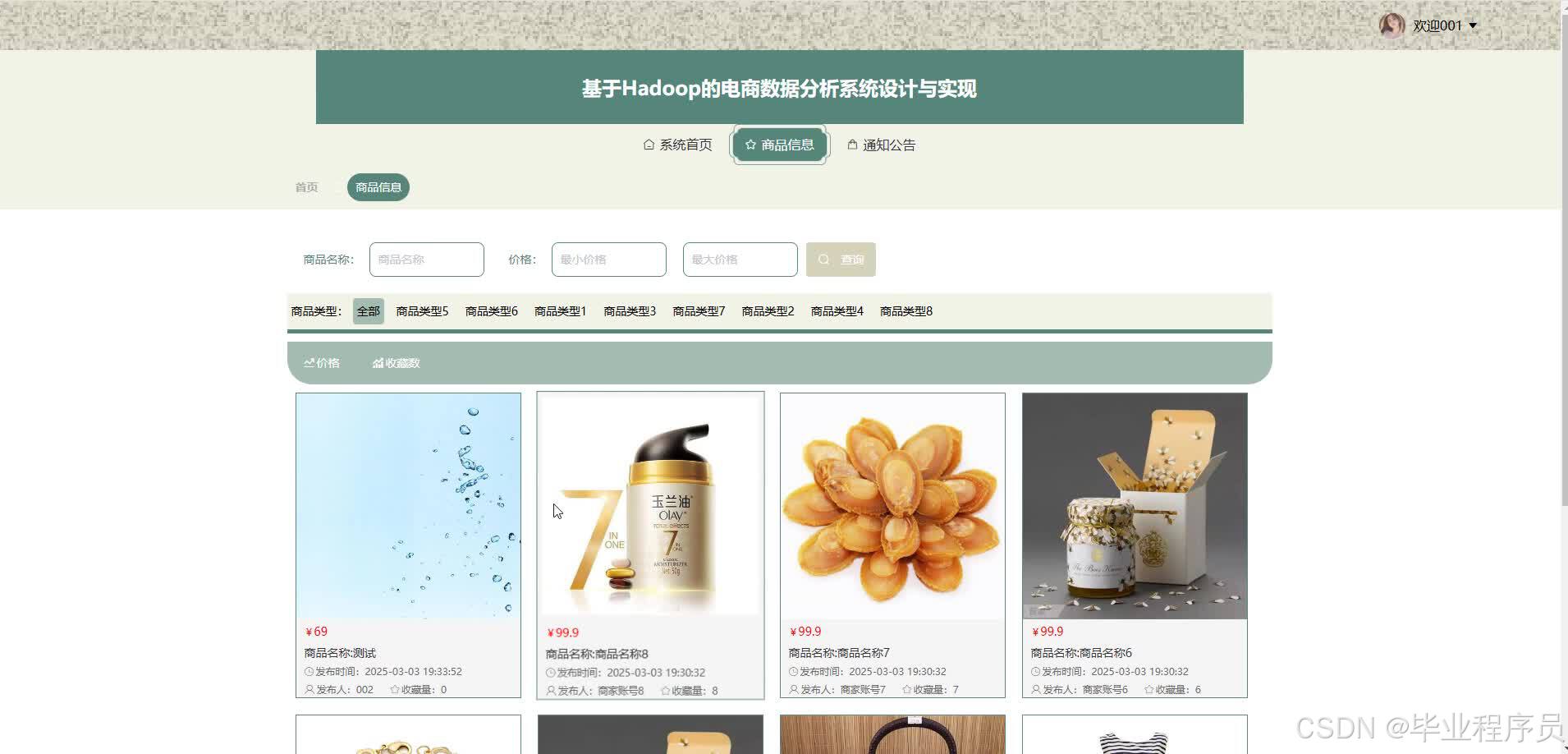
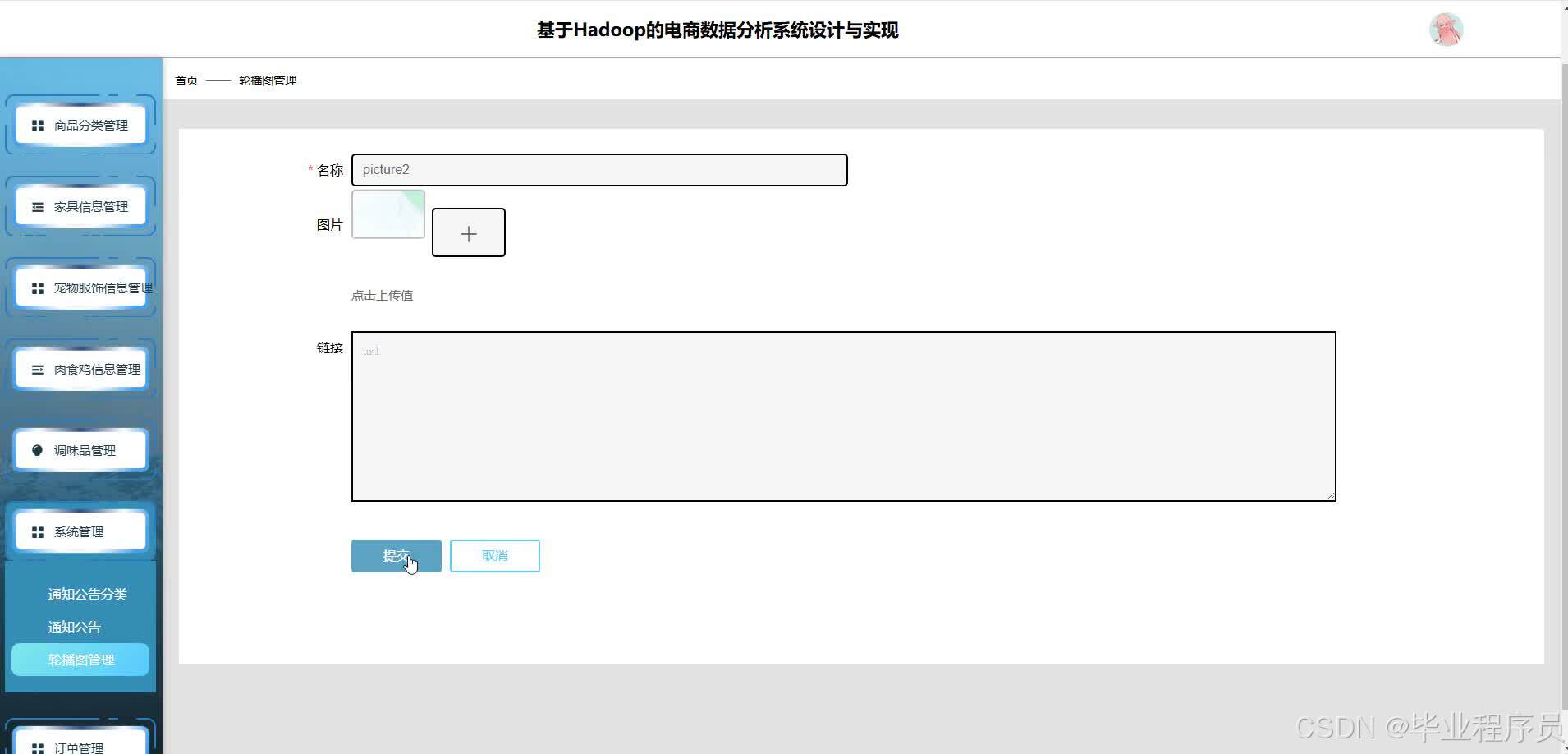
五、文章目录
源码获取
下方名片联系我即可!!
大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式👇🏻

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 9
9 0
0- 0



 已为社区贡献35条内容
已为社区贡献35条内容

所有评论(0)