2025pgconf - 针对现代CPU编写高效C代码(并应用于PostgreSQL)
可以通过硬件或软件实现,基于硬件的预取通常是通过在处理器中具有专用硬件机制来实现的,该机制监视执行程序请求的指令或数据流,根据该流识别程序可能需要的接下来的几个元素,并预取到处理器的缓存中。反向分支是指目标地址低于其自身地址的分支。这种技术可以帮助提高循环的预测精度,循环通常是反向分支,并且更常被采用。可执行的微操作,并放到微操作缓存中,以便后面不必每次都解码。指令解码位置时,问下分支预测器,预测
2025pgconf - 针对现代CPU编写高效C代码(并应用于PostgreSQL)
过去20年间,CPU时钟速度的同比增速已放缓。如今的性能提升主要源自每个时钟周期完成更多运算。特定CPU每个时钟周期能处理的运算量不仅取决于其设计,还受运行代码的影响。本文探讨其为实现代码极速执行所采用的策略,涉及分支预测与缓存预取等主题。针对每个概念,我们将分析代码层面可进行的优化调整,以减轻CPU负担并提升执行效率。
指令和数据的可预测性对性能影响很大
1、CPU中的概念
物理CPU数:计算机上实际配置的CPU数;CPU核数:单个CPU上能处理数据的芯片组数量,也就是我们通常所说的双核、四核等概念;逻辑CPU数:超线程可以使得一个CPU单核像多核一样执行。这样总核数=物理CPU数*每颗CPU物理CPU的核数,总逻辑CPU数=物理CPU数*每颗CPU物理CPU核数*超线程数。
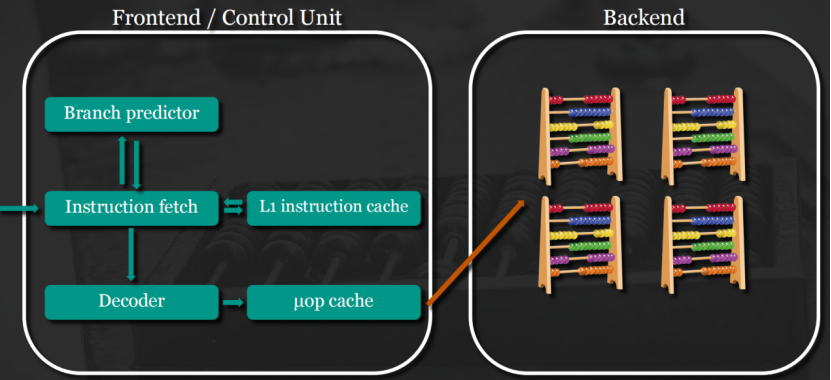
uOps微操作:CPU内部执行的基本指令单元。会将收到的复杂解码成多个微操作。当然为了提升性能,还会将这些微操作放到微操作缓存中,避免重复解码。
Pipeline slot:流水线槽,是现代CPU微架构的一个关键抽象概念,用于衡量处理器在每个时钟周期内能够处理的微操作数量。
CPU Microcodes:CPU微码,充当硬件与软件之间的翻译层,负责将复杂的机器指令分解成CPU电路可以执行的微操作。
程序计数器:是一个关键寄存器,存储下一个将要执行的指令在内存中的地址,确保CPU能够按照顺序或者跳转方式正确执行
2、CPU Front-End:CPU前端
CPU前端负责指令的获取、解码和预处理,为后续执行阶段准备微操作。
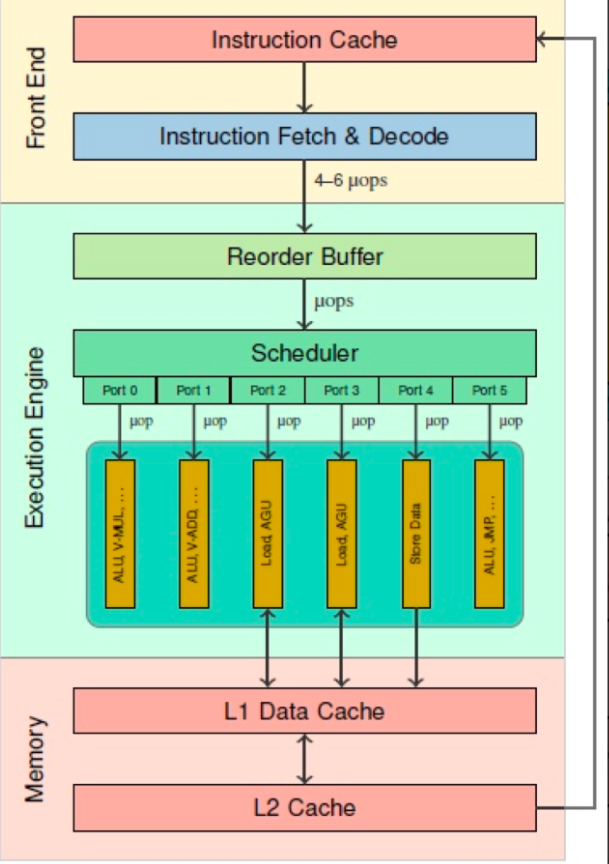
1)前端从指令缓存中读取指令,依据程序计数器提供的地址进行操作。为提升效率,现代CPU采用指令预取技术,预测并提前加载可能执行的指令到缓存。
2)解码Decoder将原始机器指令转换成CPU可执行的微操作,并放到微操作缓存中,以便后面不必每次都解码。分支预测在遇到跳转、循环等分支指令时,前端通过分支预测单元BPU预判执行路径,提前加载目标指令流。
3)后端就从微操作缓存中取微操作进行执行。
3、指令可预测性
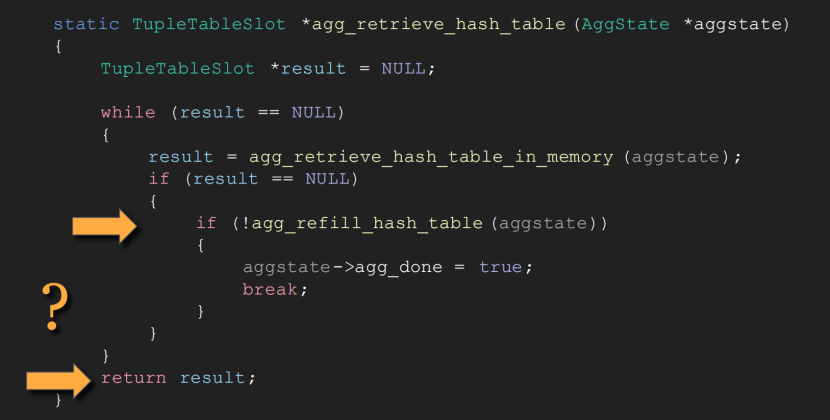
我们看下hash聚合算子中从hash表取分组值的函数流程,首先会从agg_retrieve_hash_table_in_memory取分组值,如果result不为NULL,则返回该分组值;如果result为NULL,表示内存中的hash表已经取完分组值,需要调用agg_refill_hash_table,将溢出磁盘的数据重新加载并构建hash表,如果该函数返回true,则继续while循环,从构建好的hash表中取分组值,否则表示所有数据都已经处理完毕,该函数执行结束:
如下图所示,第一个跳转指令是无条件跳转分支,进入L2,也就是会调用agg_retrieve_hash_table_in_memory函数,然后test指令判断是否为NULL,je指令判断如果为NULL,则跳转L4;
L4调用agg_refill_hash_table,然后test判断if条件是否为true,如果为true则跳到L8。
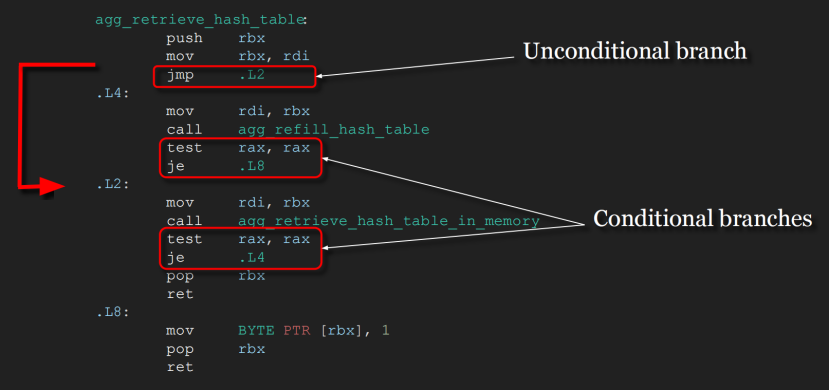
接着分析下指令,当到L2的je指令解码位置时,问下分支预测器,预测下个执行的指令是下面的分支:也就是预测内存hash表取完了,下一个需要进入L4重新构建hash表。实际上大部分场景应该走上面的分支,因为hash表大部分次数都会取出非NULL的result,需要走L8返回,这样就造成了指令预测失败:
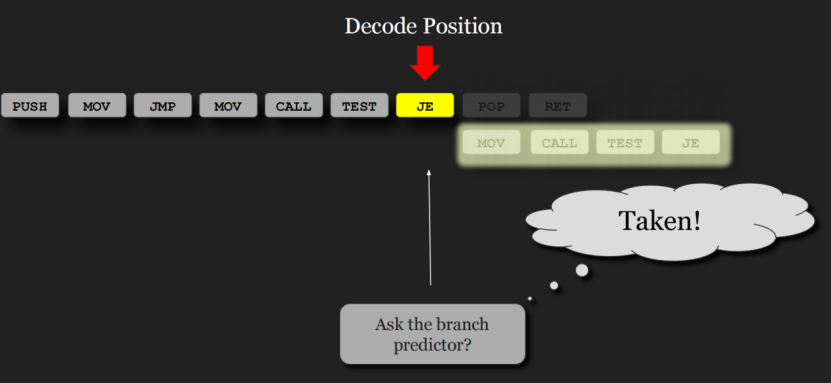
SPARC和MIPS(最早的两种商用RISC架构)的早期实现使用了单向静态分支预测:它们总是预测不会进行条件跳转,因此它们总是获取下一个顺序指令。
一种更高级的静态预测形式假定将采用反向分支,而不会采用正向分支。反向分支是指目标地址低于其自身地址的分支。这种技术可以帮助提高循环的预测精度,循环通常是反向分支,并且更常被采用。比如上面L2的je跳到L4,L4比L2的je自身地址低。
4、测试下分支预测器


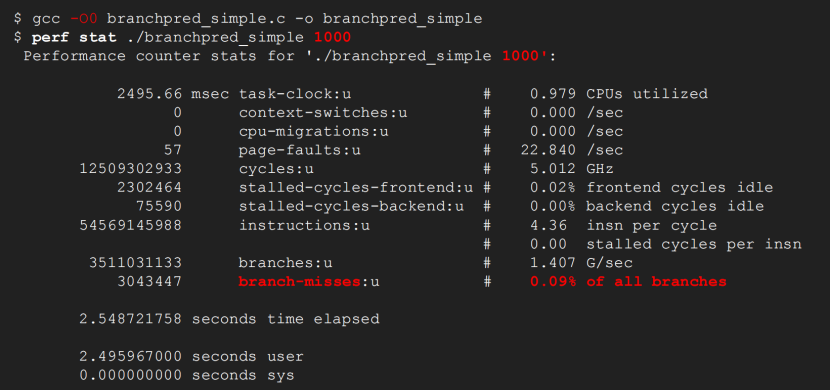
通过perf stat命令执行该程序1000次,采集性能数据:也可以perf stat -p指定进程
-
task-clock:任务所用的 CPU 时间(毫秒)
-
context-switches:上下文切换次数
-
cpu-migrations:CPU迁移次数
-
page-faults:页fault次数
-
cycles:cpu周期数
-
Instructions:执行的指令数
-
branches:分支指令数
-
branch-misses:分支预测错误次数,下面例子预测错误的占比0.09%
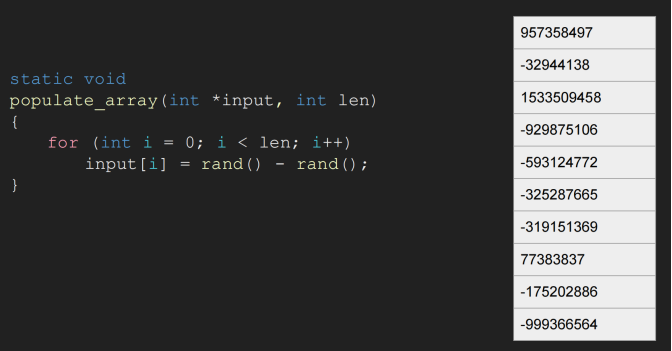
接着再看下下面的循环例子:
分支预测失败率:0.03%
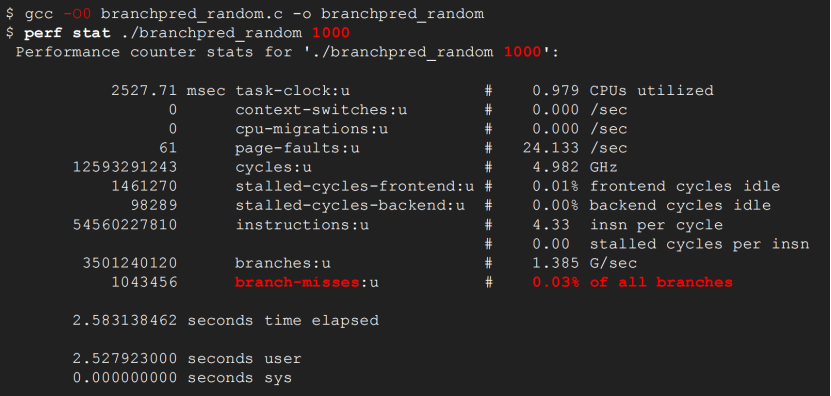
下面是随着数组变大分支预测失败率的趋势图:
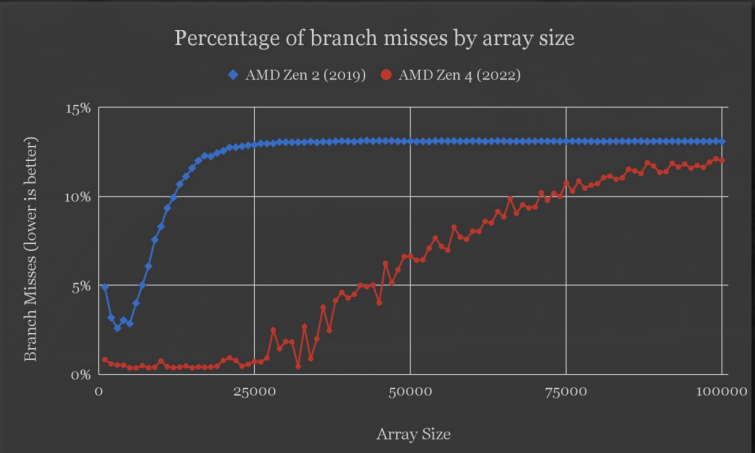
分支预测失败的影响:分支预测失败越多,执行时间越长
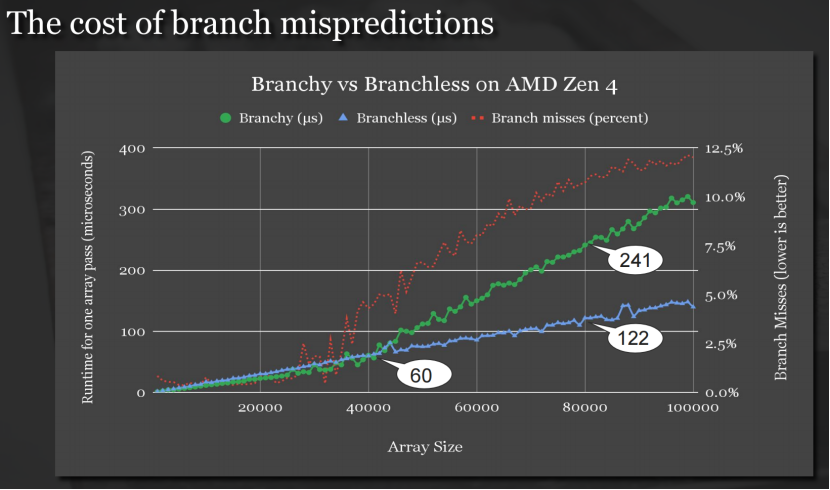
5、如何避免分支预测失败
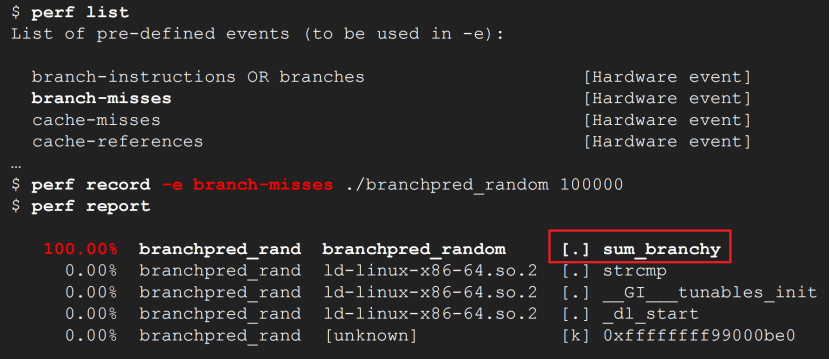
首先需要找到分支预测失败的函数是什么:通过perf record -e指定采集分支预测失败事件:
分支预测失败消除的方法:
1)现代编译器尽最大努力消除代码中的分支
2)x86_64指令集通过提供条件移动指令(CMOV*)来提供帮助
3)CMOV仅在一小部分情况下有帮助
6、数据的可预测性
指令和数据的可预测性会限制性能。
Cache预取可以通过硬件或软件实现,基于硬件的预取通常是通过在处理器中具有专用硬件机制来实现的,该机制监视执行程序请求的指令或数据流,根据该流识别程序可能需要的接下来的几个元素,并预取到处理器的缓存中。
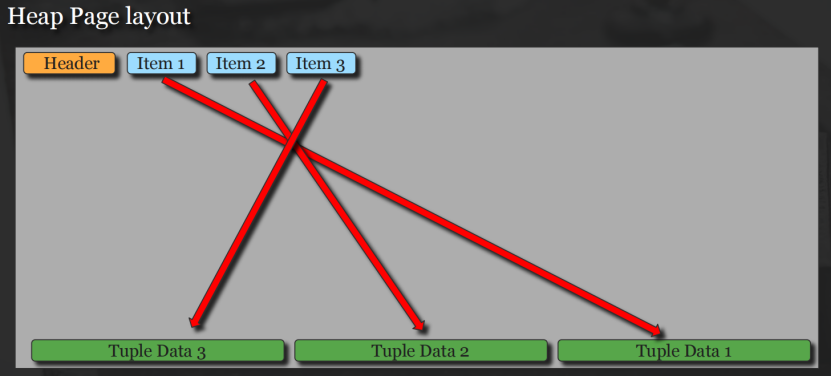
PgSQL中改进数据预取的方式:

PgSQL中lp指针reversed时预取效果会更好:
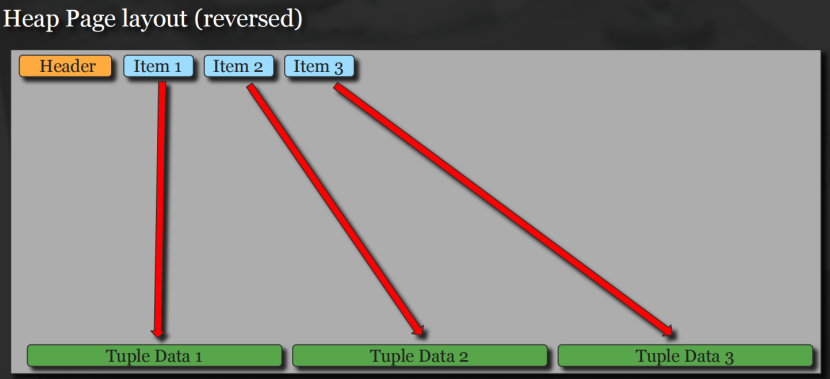
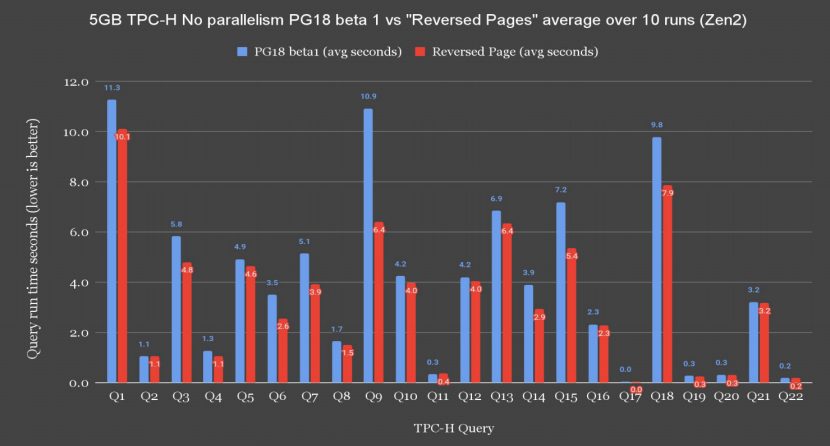
7、资源
1)perf list列出CPU支持的硬件事件
2)perf record -e branch-misses找问题
3)使用https://godbolt.org/网址看下编译的代码:
(1)也可以使用gcc -s
(2)https://cs.brown.edu/courses/cs033/docs/guides/x64_cheatsheet.pdf帮助阅读x86-64 assembly
(3)https://en.wikipedia.org/wiki/X86_calling_conventions
4)使得编代码更优的资源:
(1)https://lemire.me/blog/?s=branchless
(2)https://branchfree.org/
(3)搜branchless programming
(4)Many branchfree algorithms will use SIMD (Single Instruction Multiple Data)
5)Today’s branch predictors: https://www.cs.utexas.edu/~lin/papers/hpca01.pdf
6)CPU testing scripts for this talk https://github.com/david-rowley/cpustudy/
7)A book: “The Art of Writing Efficient Programs” by Fedor G. Pikus
8)Agner Fog’s free PDF https://www.agner.org/optimize/microarchitecture.pdf
9)CPU related articles:
https://chipsandcheese.com/
https://www.realworldtech.com/cpu/
10)https://github.com/david-rowley/postgres/tree/reverse_page_order
8、参考
https://2025.pgconf.dev/schedule.html
https://blog.csdn.net/zhangwenxinzck/article/details/130865209
https://zhuanlan.zhihu.com/p/509264784
https://perf.bcmeng.com/1%20computer-principle/CPU.html#proc-%E6%96%87%E4%BB%B6%E7%B3%BB%E7%BB%9F

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 5
5 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)