opencv学习笔记15:RNN→SSM→mamba
摘要:本文系统介绍了循环神经网络(RNN)、状态空间模型(SSM)及其改进架构Mamba的技术原理。重点分析了RNN的循环机制、SSM的离散化方法(零阶保持技术)、循环式与卷积式实现的优缺点对比,以及HiPPO初始化技术。特别深入阐述了Mamba的创新点:通过选择性扫描算法实现动态参数调整,结合硬件感知优化提升效率。文章详细推导了离散SSM的数学公式,对比了循环表示和卷积表示的计算特性,并图解说明
目录
② Timestep 1 & 2(标准步:记忆 + 新输入)
(2)卷积计算示例:用卷积核对三个单词进行卷积——————(可以跳过)
6.S4(ICLR 2022):SSM + 离散化(可循环表示或卷积表示) + HiPPO
2.Mamba = 有选择处理信息 + 硬件感知算法 + 更简单的SSM架构
①原论文公式对应———————————————————————————————
一.RNN
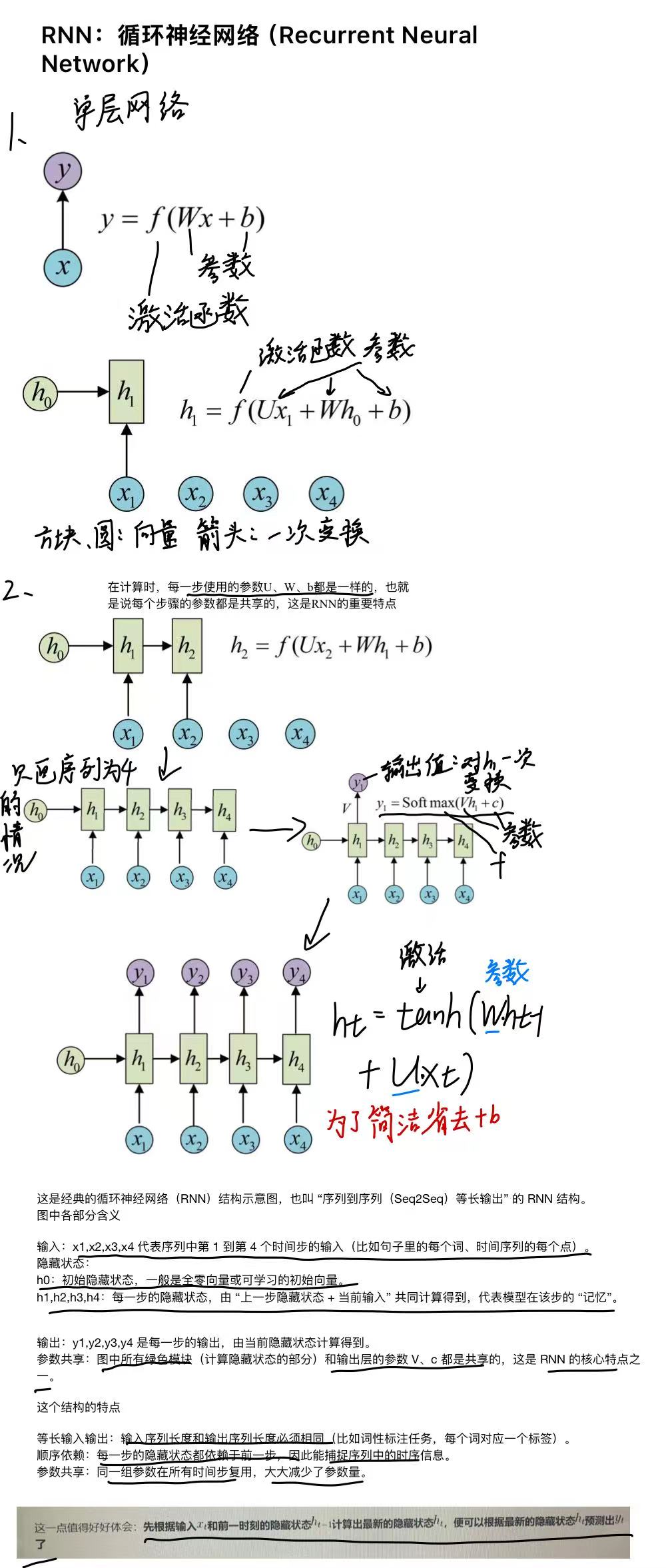
循环神经网络(RNN)是一种基于序列的网络。它在序列的每个时间步都需要两个输入,即时间步t的输入和前一个时间步t-1的隐藏状态,以生成下一个隐藏状态并预测输出。
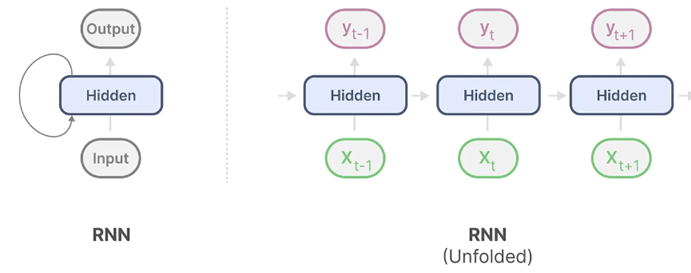
上图左图中画了一个从 Hidden 指向自己的自环箭头,这个箭头就是 RNN 的核心:它表示 “上一时刻的隐藏状态会作为下一时刻的输入”,也就是我们常说的![]()
右图展开了(箭头颜色不明显)
二.SSM

三.
1.零阶保持技术
那模型如何处理离散化数据呢?答案是可以利用零阶保持技术(Zero-order hold technique)
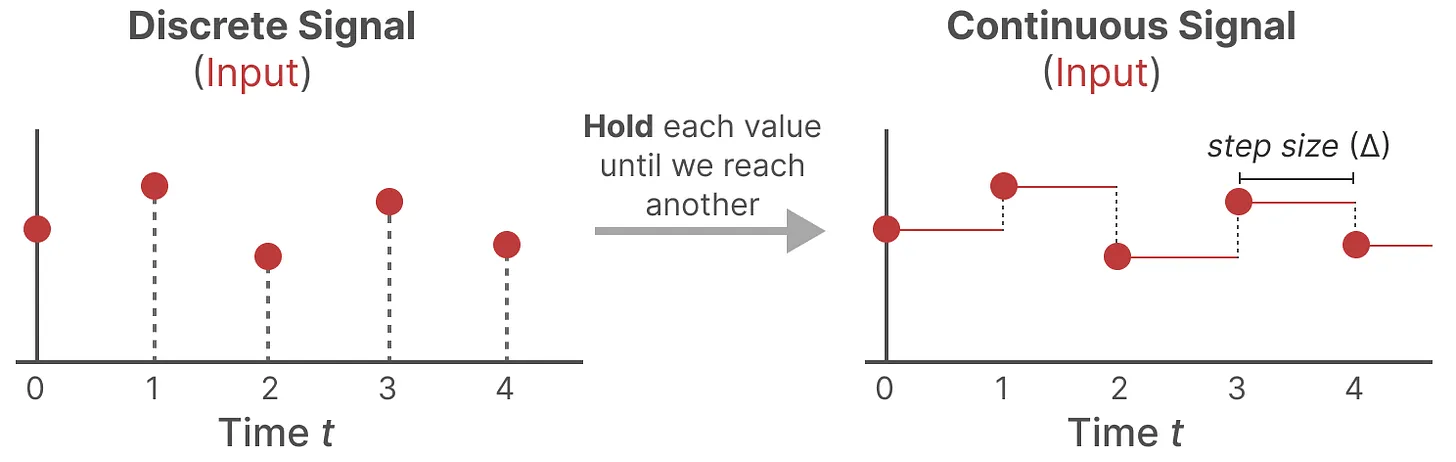
零阶保持技术:
- 每次收到离散信号时,在后面一段时间内收不到信号时 我们都会持续保留这个值,直到收到新的离散信号(如上面右图所示),如此操作导致的结果就是创建了 SSM 可以使用的连续信号
- 保持该值的时间由一个新的可学习参数表示,称为步长(size)——
,步长 Δ 就是两次离散采样之间的时间间隔。
- 有了连续的输入信号后,便可以通过SSM生成连续的输出,并且仅根据输入的时间步长对值进行采样
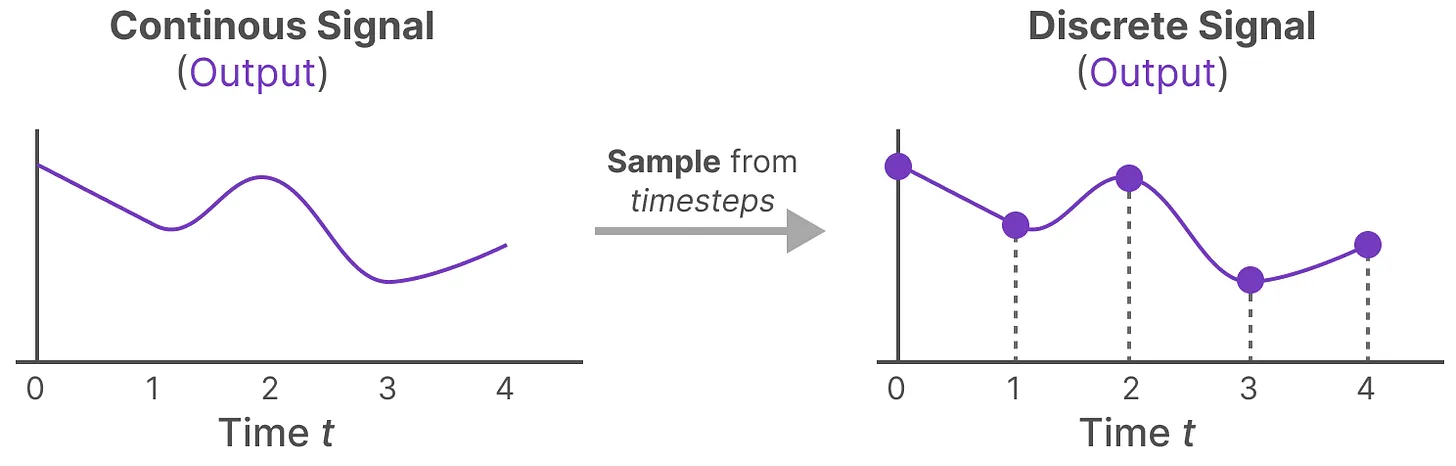
这些采样值就是我们的离散输出,
现在直接对参数A、B改造,然后直接输入离散数据给SSM,则可以直接输出离散数据了。即针对A、B按如下方式做零阶保持(做了零阶保持的在对应变量上面加了个横杠)
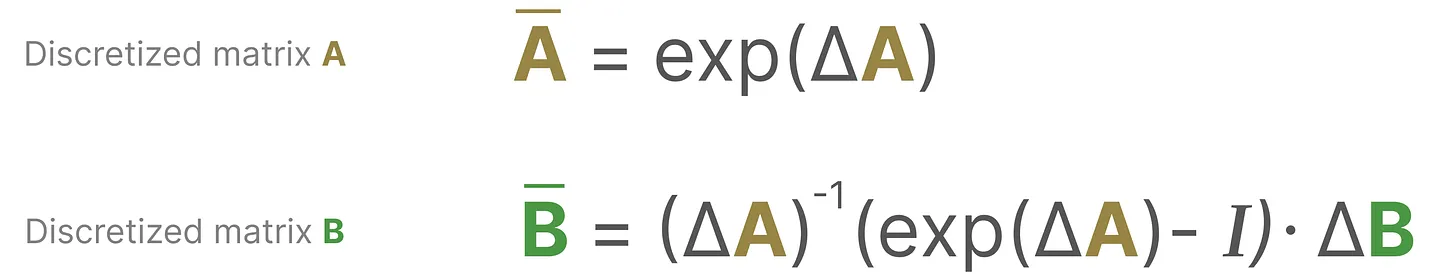
最终连续 SSM 转变为离散SSM,使得不再是函数到函数![]() ,而是序列到序列
,而是序列到序列![]()
所以矩阵![]() 和
和![]() 现在表示模型的离散参数,且这里使用k(k 代表第 k 个时间步),而不是t来表示离散的时间步长
现在表示模型的离散参数,且这里使用k(k 代表第 k 个时间步),而不是t来表示离散的时间步长
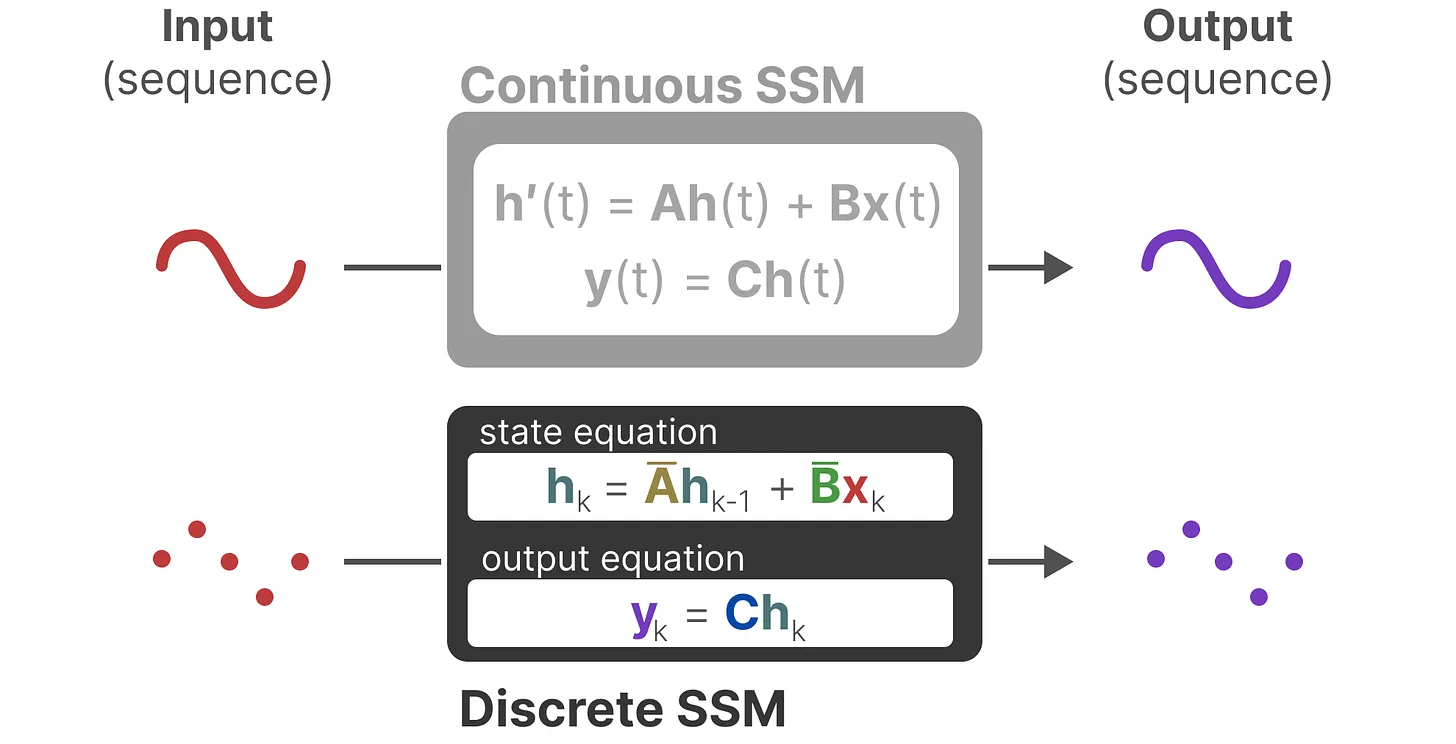
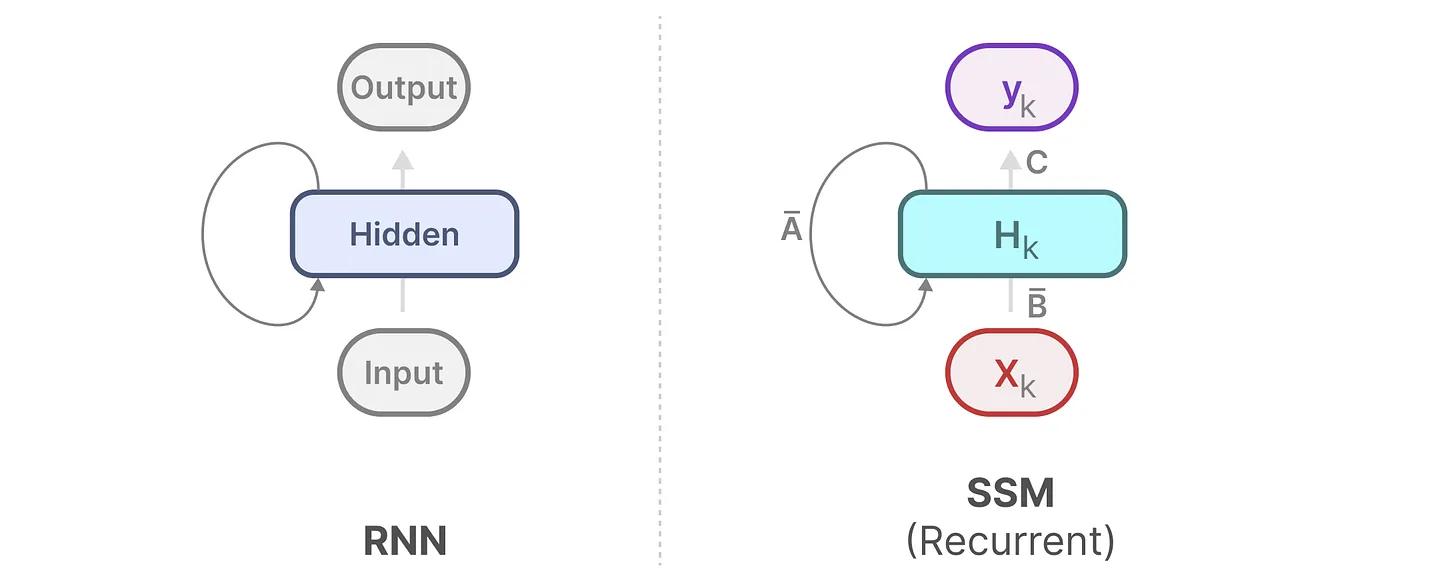
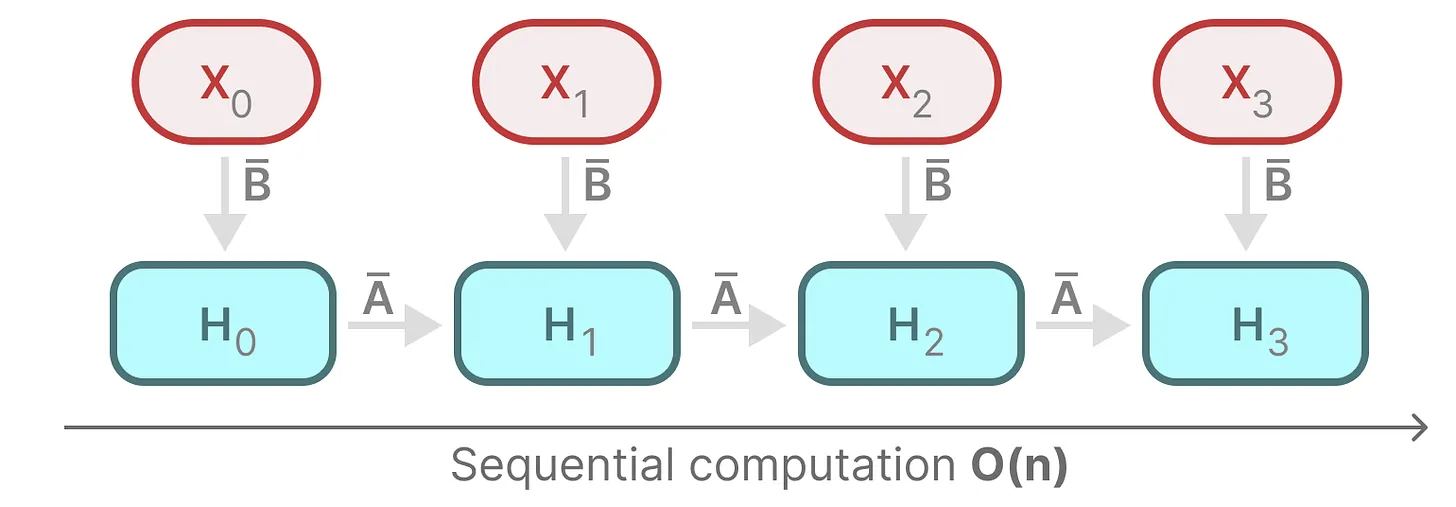
2.循环式的离散 SSM(便于快速推理)
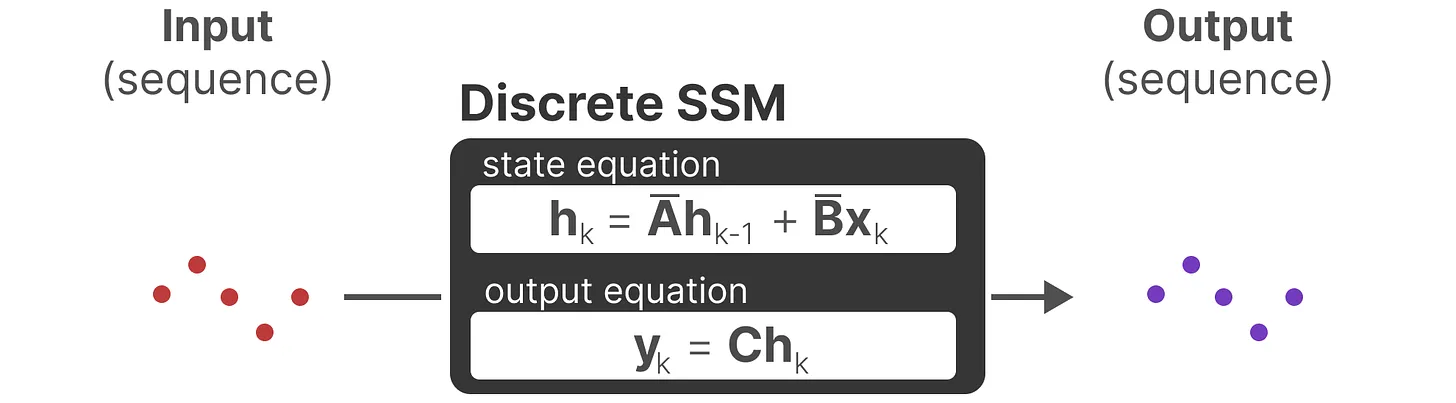
上图为离散SSM,拆开让时间步k=0、1、2如下图
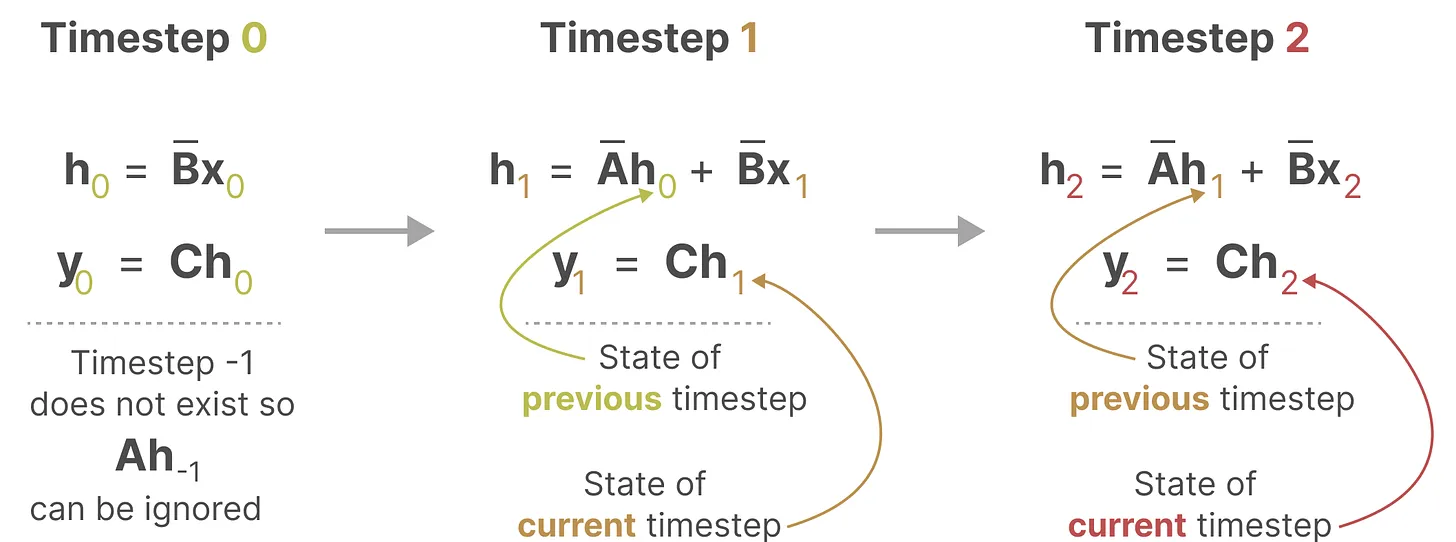
① Timestep 0(初始步:无历史记忆)
- 因为是第 0 步,不存在 “上一时刻状态
”,所以省略了
- 初始状态 h0 完全由第一个输入 x0 经过矩阵
变换得到。
- 这对应 RNN 中 “初始隐藏状态 h0 设为全零或由输入初始化” 的逻辑。
② Timestep 1 & 2(标准步:记忆 + 新输入)
- 公式的两个组成部分(图中箭头已标注):
(历史记忆):上一步状态
变换,
(当前输入):当前输入
- 输出计算:yk=C hk,即当前状态经过矩阵 C 变换得到输出。
为方便大家理解其中的细节,我再展开一下的计算,展开h2、h1、h0再乘开
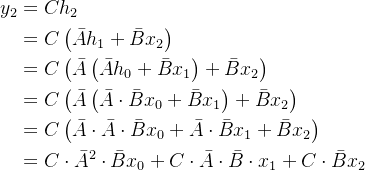
离散SSM 可以用 RNN 结构处理:
再按照SSM那样展开(可以看到,始终是
和
的共同作用之下更新的)
3.卷积式的离散SSM(便于并行训练)
图像识别任务中,我们用卷积核聚合特征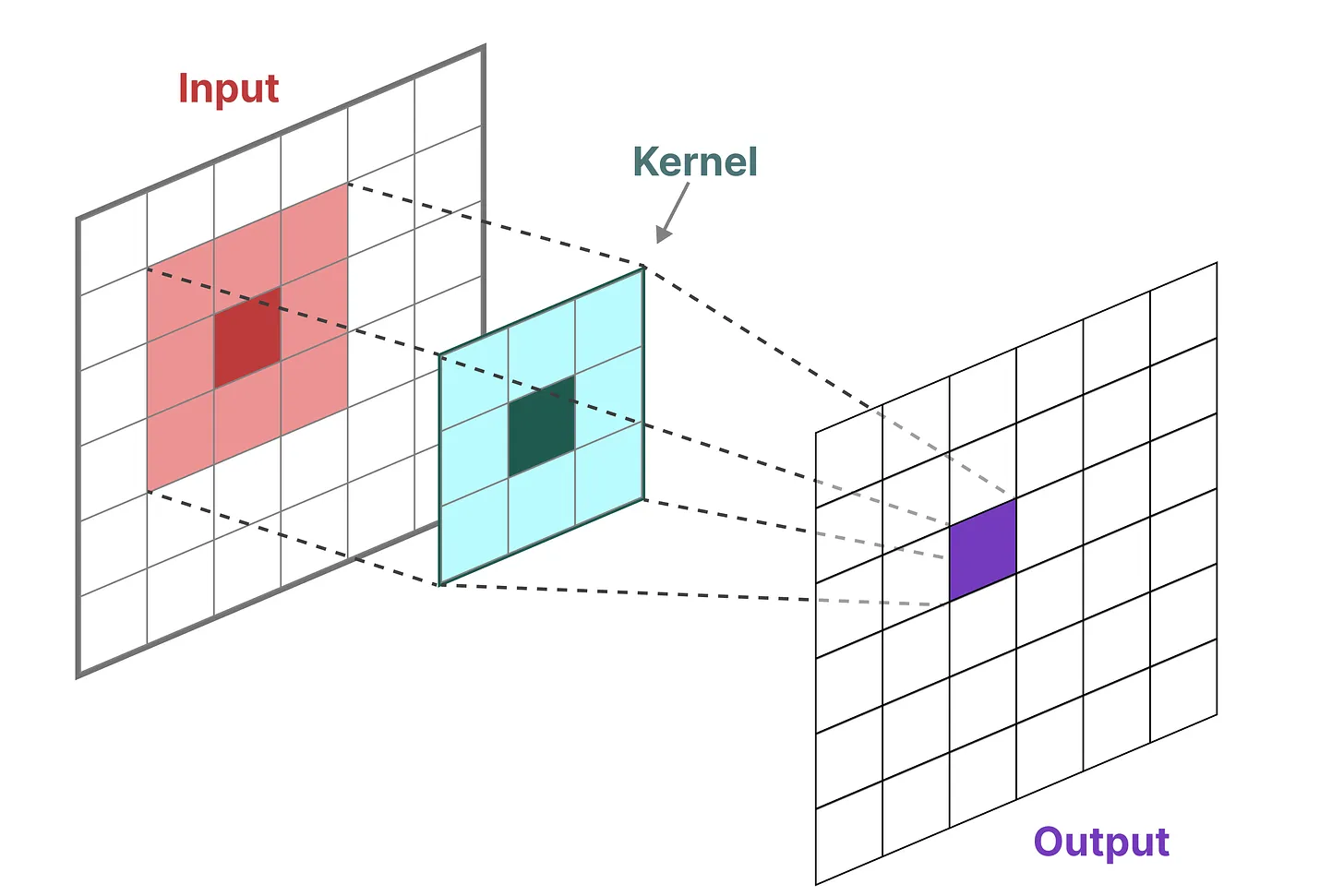
由于我们处理的是文本而不是图像,因此我们需要一维视角:三格输入数据分别和三格的卷积核相乘得到输出
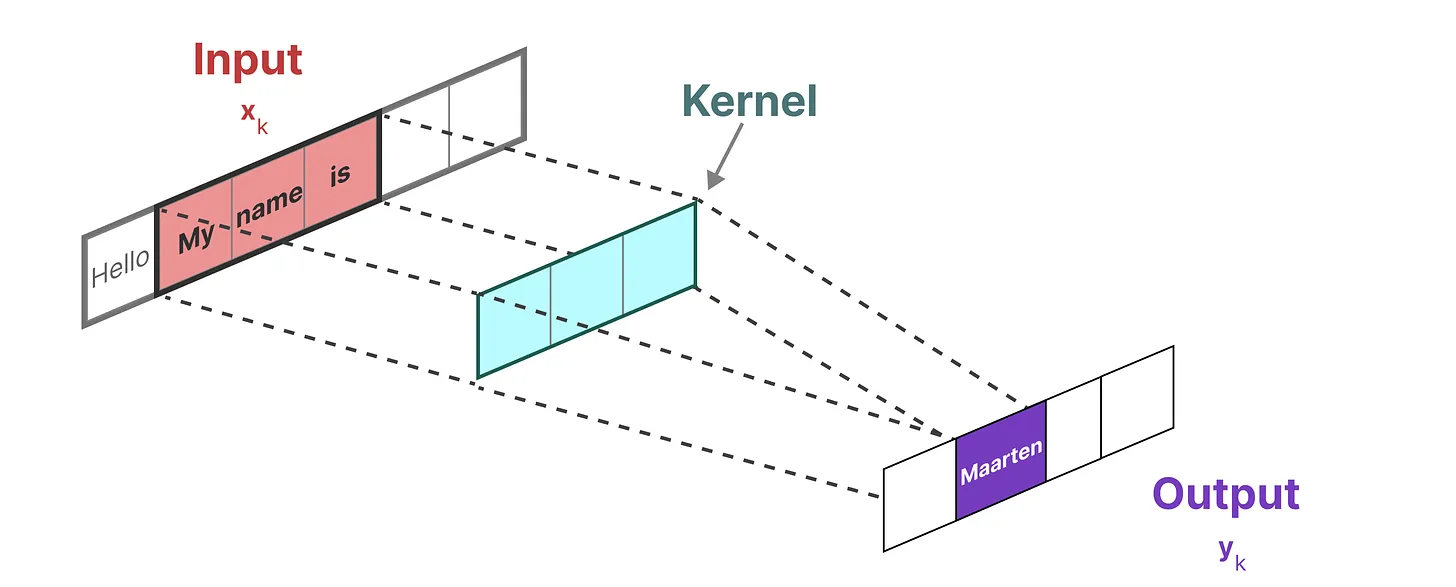
根据之前推出的y2的式子
我们可以推出y3,:![]()
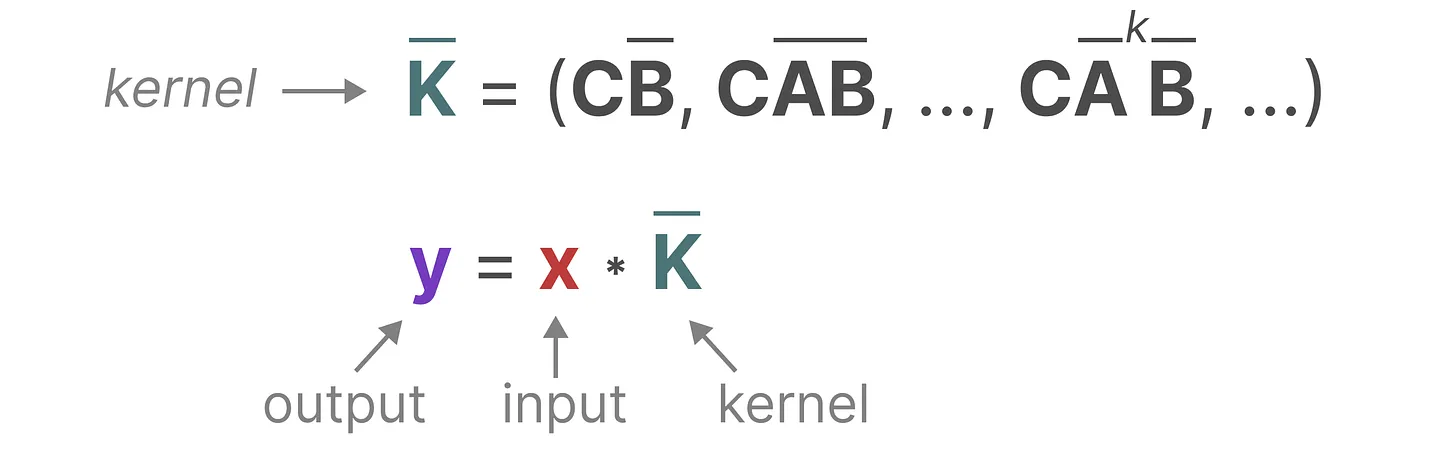
再推得到yk的公式,进而得到SSM的卷积核
(1)卷积核如下:(3)有解释
(2)卷积计算示例:用卷积核对三个单词进行卷积——————(可以跳过)
- 对第一个词进行进行卷积计算,前面进行零填充padding

- 内核将移动一次以执行下一步的计算

- 最后一步,我们可以看到内核的完整效果:

图中的就是我们之前推导出的公式
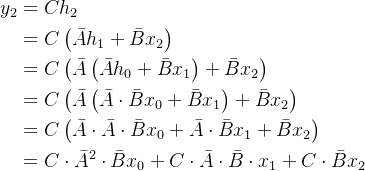
————————————————————————————————————————
(3)卷积公式
此外,换个形式看,是不意味着实际上可以计算为点积,其中右侧向量是我们的输入
其中三个离散参数A、B、C都是常数,因此我们可以预先计算左侧向量并将其保存为卷积核,则卷积计算公式为:
4.循环式VS卷积式
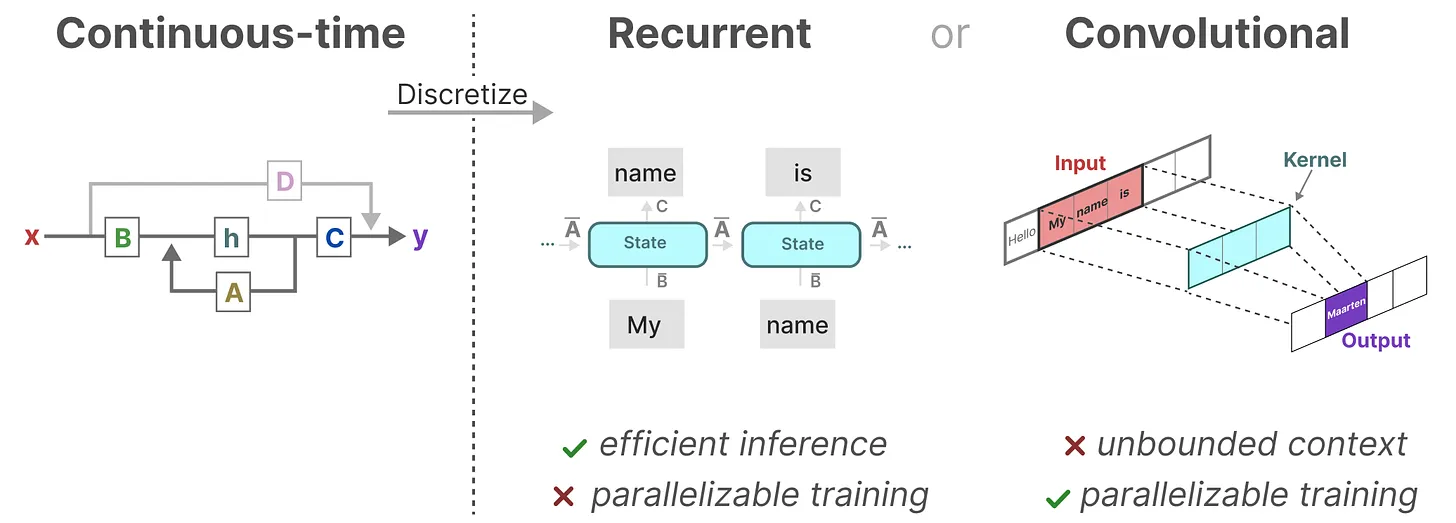
循环式:高效推理 快✅️、并行训练 慢❌️
高效推理快:
- 场景:比如你用 Mamba 写文章,写完第 100 个字,要写第 101 个字。
- 计算方式:只需要上一个状态 h100 和 当前输入 x101,就能算出 h101。
- 优势:不需要把前面 100 个字全部重新算一遍,O (1) 时间就能出结果。这对长文本生成、实时语音识别非常重要。
并行训练慢:
- 场景:你在 GPU 上训练模型,输入是一批句子。
- 计算方式:因为 h2 依赖 h1,h3 依赖 h2,必须按时间步串行计算。
- 劣势:GPU 擅长同时算很多东西(并行),但在这里只能排队算,训练速度慢。
卷积式:并行训练 快✅️、高效推理 慢❌️
并行训练 快:
卷积核是固定的,我们可以把整个输入序列和卷积核做矩阵乘法。GPU 可以一次性算出所有时间步的输出,训练速度极快(这就是 CNN 的优势)。
高效推理 慢:
处理非常长的序列(比如 1 万个 token)。问题:卷积核的大小是固定的(比如只能看前 100 个 token)。如果要看到第 1 个 token 对第 10000 个 token 的影响,卷积核需要做 100 层,或者核大小设为 10000(这会导致参数爆炸)。劣势:很难捕捉超长距离的依赖关系,而且推理时需要把整个序列都加载进来,不能像循环那样 “流式计算”。
5.HIPPO初始化矩阵A
如果还像2②循环结构,矩阵捕获先前状态的信息来构建新状态,公式是
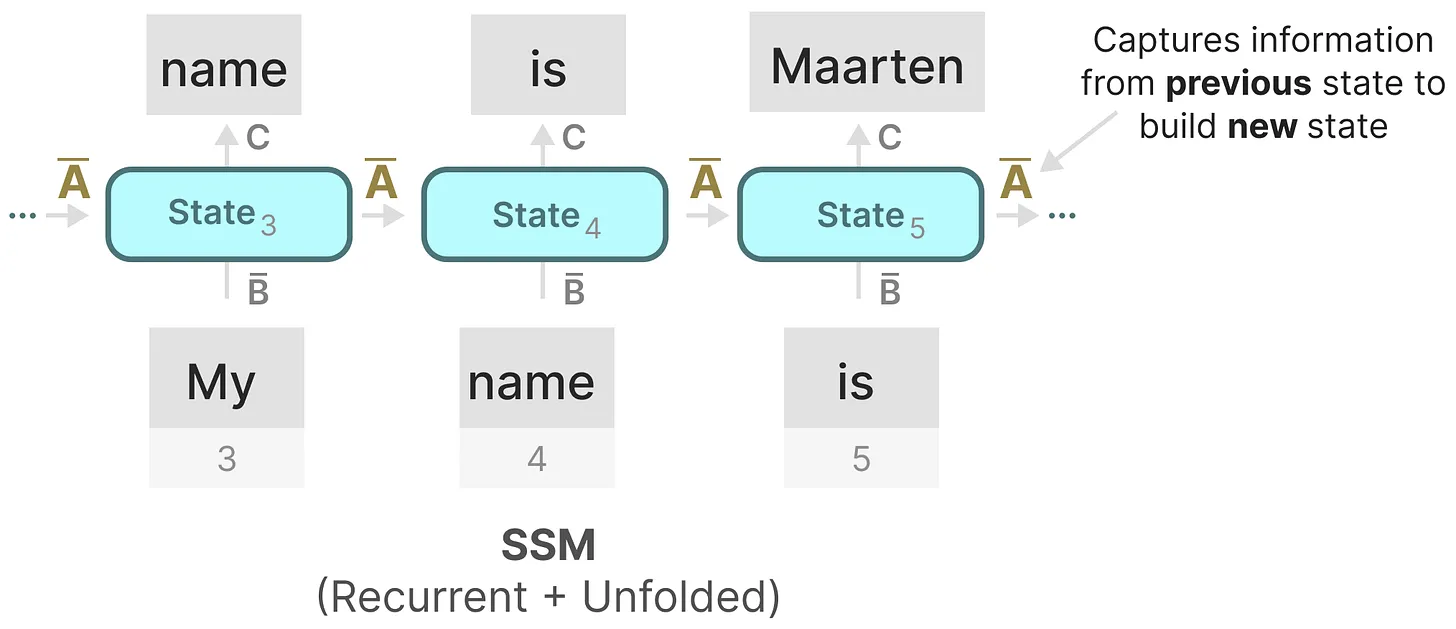
由于A只能记住上一时刻的隐藏状态 hk−1,并在此基础上叠加当前输入 xk 来更新状态,更早之前的信息(比如 hk−2,hk−3 对应的输入)会被不断 “稀释” 和 “遗忘”。1111矩阵A怎么训练的?
怎样才能以保留比较长的memory的方式创建矩阵A呢?
可以使用HiPPO「HiPPO的全称是High-order Polynomial Projection Operator
HiPPO尝试将当前看到的所有输入信号压缩为一个系数向量
HIPPO可以通过函数逼近产生状态矩阵 A 的最优解,其公式可以表示如下:
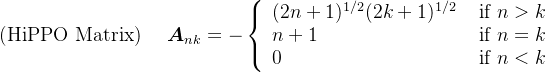
为方便大家更好的理解,基于上面带有负号的定义,我也给大家举一个具体的例子
- 对于
而言,假设
(代表行)和
(代表列) 的范围是 0 到 2:
- 根据带有负号的HiPPO定义可得(比如,对角线上的元素,有
)
- 对角线上方的元素为 0(注意,是对角线上方,不是对角线上,而对角线上方的元素有:n < k)
- 因此,矩阵 A 为
HiPPO 矩阵可以产生一个隐藏状态来记住其历史,使得在被应用于循环表示和卷积表示中时,可以处理远程依赖性
6.S4(ICLR 2022):SSM + 离散化(可循环表示或卷积表示) + HiPPO
S4定义:序列的结构化状态空间——Structured State Space for Sequences,一类可以有效处理长序列的 SSM
S4就是综合了上面所讲的:SSM + 离散化(可循环表示或卷积表示) + HiPPO

111S4D?
三.mamba
Mamba是一种状态空间模型(SSM)架构,它改进了S4架构。它有时也被称为S6或者selective SSM,它对S4进行了两项重要修改:
选择性扫描算法(selective scan algorithm),允许模型过滤相关或者不相关的信息
硬件感知的算法(hardware-aware algorithm),允许通过并行扫描(parallel scan)、核融合(kernel fusion)和重计算(recomputation)有效地存储(中间)结果。
1.动机
痛点:传统 SSM(LTI 线性时不变)是 “死板” 的:参数 A,B,C,Δ 固定,对所有输入一视同仁。长序列中,它会无差别保留有用信息(如名词)和无用信息(如虚词),导致记忆过载、关键信息被淹没。所以要有选择性
传统 LTI 模型做不到 “有选择地压缩”,而选择性机制就是解决这个问题的钥匙。
举例说明痛点:
Selective Copying Task
在选择性复制任务中,SSM的目标是复制输入的一部分并按顺序输出。即只提取出满足特定条件的 token(输入的单词),例如只取出名词。
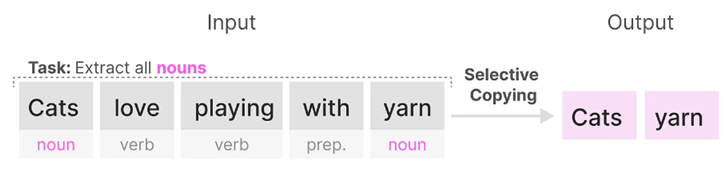
(循环/卷积)SSM在这项任务中表现不佳,因为它是线性时间不变(Linear Time Invariant)的。矩阵A、B、C、D对于SSM生成的每个token(单词)都是相同的。
2.Mamba = 有选择处理信息 + 硬件感知算法 + 更简单的SSM架构

首先使用linear全连接层和Broadcast升维操作让 (Δ, A, B, C) 变成动态(Δ是步长,输入关键信息时Δ 会变大放大输入权重;反之变小,通过门控函数体现),目的就是为了搭配门控机制实现选择性,接下来引入门控机制:
(1)有选择处理信息
选择性处理信息门控简化公式:![]()
- ht:第 t 步的隐藏状态(hidden state),代表模型到当前为止 “记住” 的信息。
- xt:第 t 步的新输入数据(input),比如序列中的一个词向量或特征向量。
- ht+1:更新后的新隐藏状态。
- A,B:可学习的权重矩阵(weight matrices),用于线性变换:
- Aht:对前一时刻的隐藏状态做线性变换。
- Bxt:对当前输入做线性变换。
- f(xt),g(xt):由输入 xt 控制的门控函数(gating functions),f(xt),g(xt)这两个函数通常是神经网络层,比如线性层 + Sigmoid 或 SiLU 激活函数,输出 0~1 之间的数值,代表 “信息门” 的开合程度,比如:
- 输出 1:门全开(完全保留 )。
- 输出 0:门全关(完全抛弃)。
- 输出 0.5:门半开(保留一半)。
- ⊙:逐元素相乘(element-wise product,也叫 Hadamard 乘积),表示用门控值对信息进行 “筛选”。
总结:f和g就像两个阀门,控制新旧信息进入的多少,ht是旧信息,f控制旧信息进入的多少,或者直接全部忽略;xt是新信息,g控制新信息进入的多少
![]()
①原论文公式对应———————————————————————————————
①离散化后的SSM: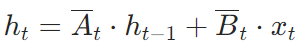
②通过零阶保持(ZOH)离散化公式:linear全连接层,σ是Sigmoid 激活函数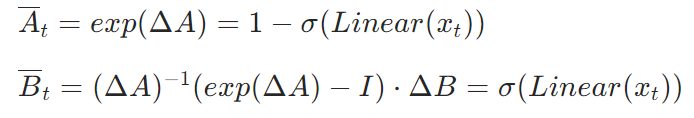
③使![]() ,将该式和②代入①,使①变成门控形式
,将该式和②代入①,使①变成门控形式![]() ,该公式即为原论文p8,3.5.1公式,
,该公式即为原论文p8,3.5.1公式,
②对比门控公式和原论文公式
![]()
![]()
ht对应ht-1;f(xt)函数对应1-gt;Aht对应ht-1,第二个式子线性变换让A变成单位矩阵更简化;g(xt)对应gt;Bxt对应xt,依旧把B写成单位矩阵。
————————————————————————————————————————
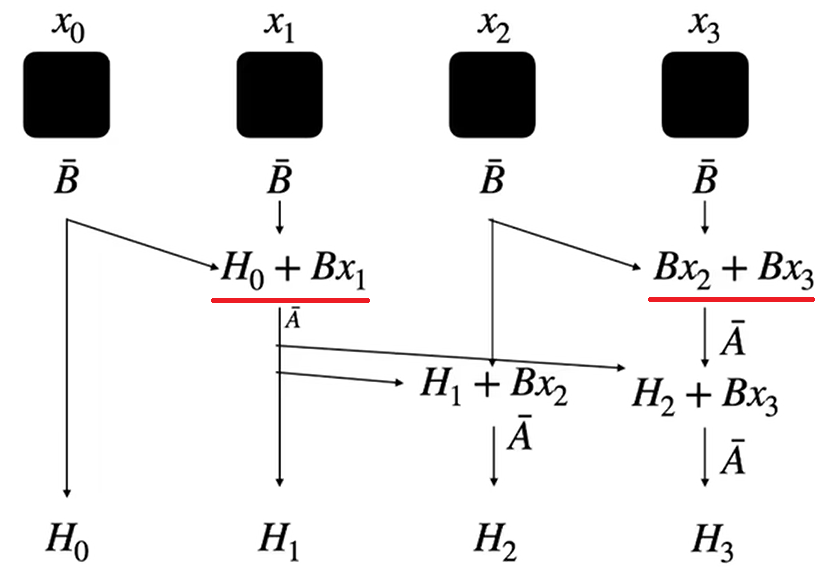
(2)并行扫描(parallel scan)
每个状态比如都是前一个状态比如
乘以
,加上当前输入
乘以
的总和,这就叫扫描操作(scan operation),也就是每次算Ht,根据公式Ht=
Ht-1 +
Xt都要把前面的Ht-1算出来代入才能计算Ht,这是串行的。
而并行扫描没什么意思,就是把所有状态分成两两一块计算,X0和X1分成一块一起算H1=H0+X1,X2和X3分一组一起算H3=H2+
X3,最后整体再回溯反向传播中间缺哪个状态H就补哪个,比如要算H1=H0+
X1没有H0,那就再算H0=
X0代入就行了;若要算H3=H2+
X3没有H2,那就再算H2=H1+
X2,而H1是上一个块已经算过的,这样顺利代入算出H2进而算出H3。
其实就是分治思想,只不过把n个递归变成了n/2次递归代入。
(3)选择性 SSM ——mamba核心模块
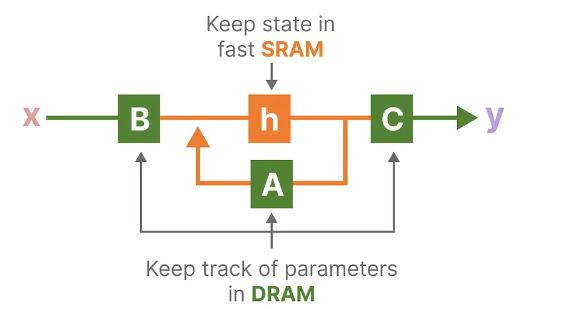
①HBM、SRAM和DRAM 介绍
- SRAM(Static Random Access Memory,静态随机存取存储器),高速缓存,容量小、存取快。
- DRAM(Dynamic Random Access Memory,动态随机存取存储器),就是主存 / 显存,容量大、存取慢。
- HBM 是 DRAM 的 3D 堆叠高端版,下图功能视为等价于DRAM
②选择性 SSM ——mamba核心模块
原论文中原图,是 Selective SSM(选择性状态空间模型) 的前向计算流程,是Mamba 核心模块。Mamba 之所以能在长序列上比 Transformer 更快、更好,是因为它用这个 Selective SSM 替代了 Transformer 的注意力机制。
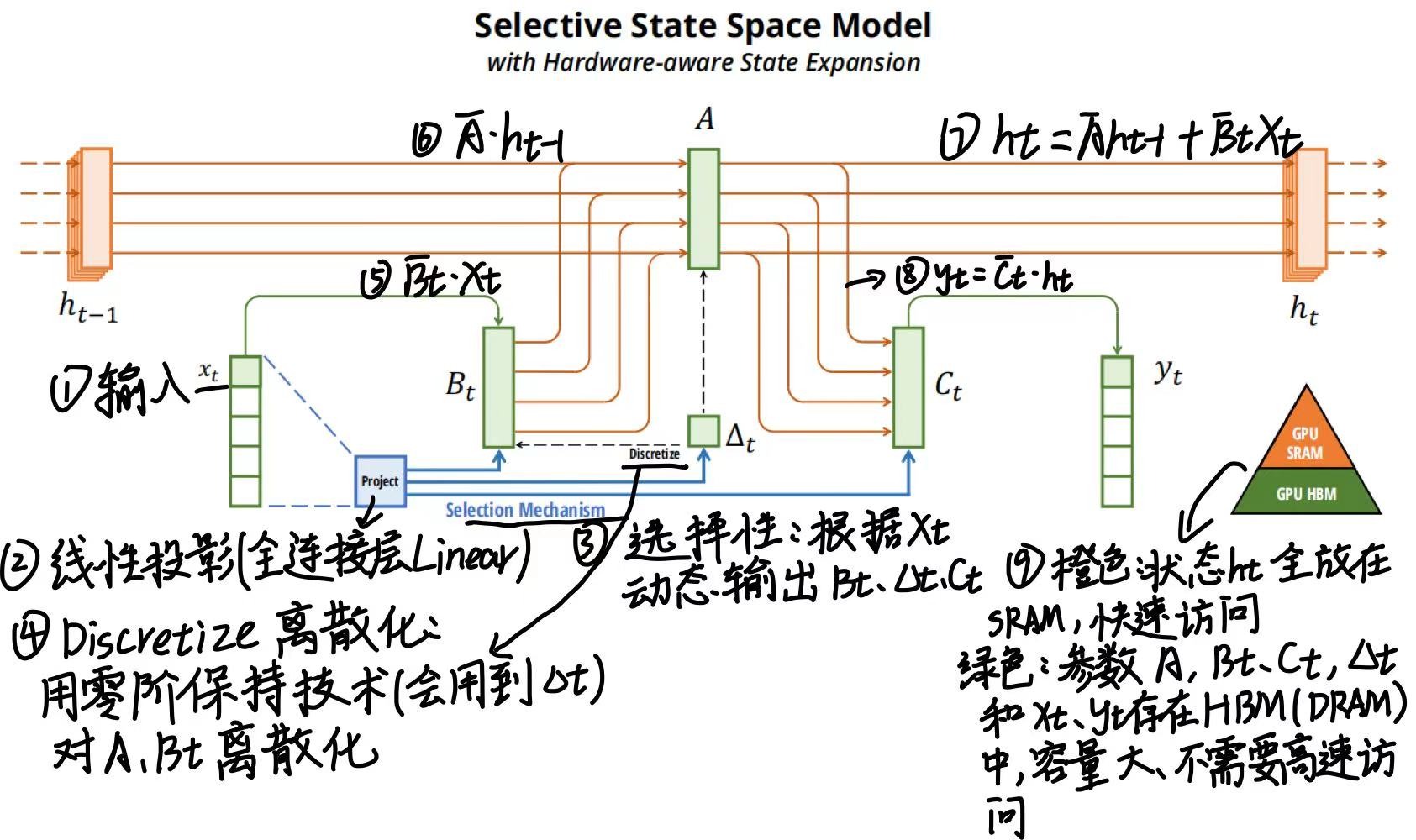
下图是上图选择性SSM的简化版,就将橙色的部分写成了一个橙色的h里面:
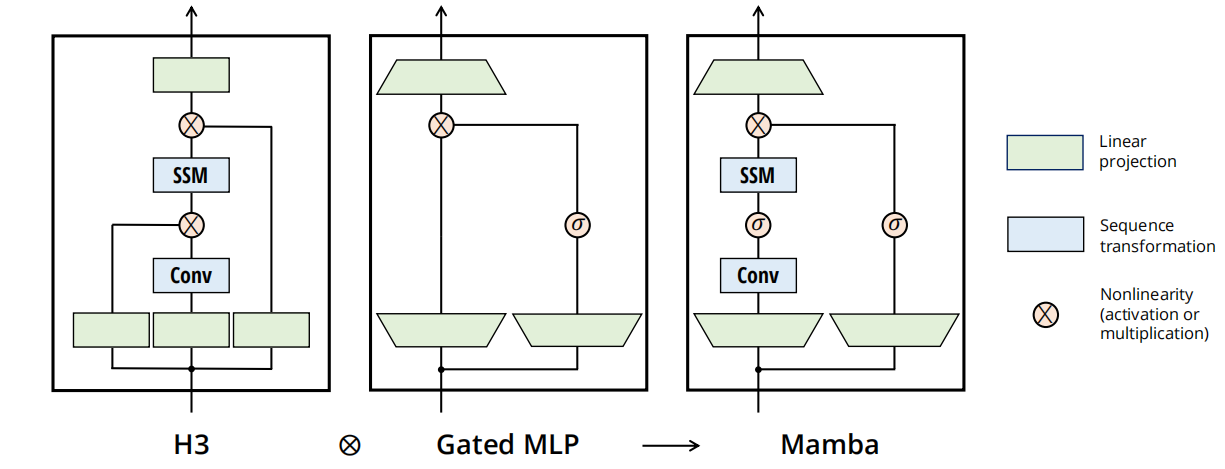
(4)更简单的SSM架构
H3:把输入分别分成三路:从左到右依次对同一个输入做SSM处理、Conv卷积处理,第三路看似仅仅与前两路逐元素相乘,但实际上就是门控机制的雏形:控制信息流,放大有用特征,抑制无用特征
Gated MLP:单一个sigmoid门控
mamba框架:将输入分两路,第一路先线性投影Linear → 卷积操作Conv → 激活函数σ门控机制 为SSM提供精确的输入→ SSM
第二路Linear → σ
最后两路逐元素相乘、最终再进行一次Linear

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 5
5 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)