手把手教你基于 MindSpore 实现 SAM 模型通用图像分割
本文详细介绍了如何在 MindSpore 框架下利用 Segment Anything Model (SAM) 实现通用图像分割。通过手把手的步骤演示,涵盖了从实验平台环境配置、依赖库安装,到数据加载、模型推理及结果可视化的全流程。读者将学习如何使用 MindSpore NLP Transformers 库加载预训练的 SAM 模型,并通过 BBox 提示框对特定目标进行零样本分割。教程配备了完整
本文同步发布于MindSpore社区,欢迎加入MindSpore社区,一同探索更多可能!
本文将参考 Hugging Face 的交互式推理流程,带大家基于 MindSpore 与 MindSpore NLP Transformers,一步步实现 Segment Anything Model (SAM) 的 BBox 框提示端到端推理与可视化。
什么是 SAM?
Segment Anything Model(SAM)(Meta AI, 2023)是一种“可提示(promptable)”的通用分割模型。它可以通过 点 / 框 / 已有掩码 等提示,在零样本条件下对任意目标生成分割结果。
第一步:打开实验平台
首先,我们需要登录实验平台,找到对应的实训项目。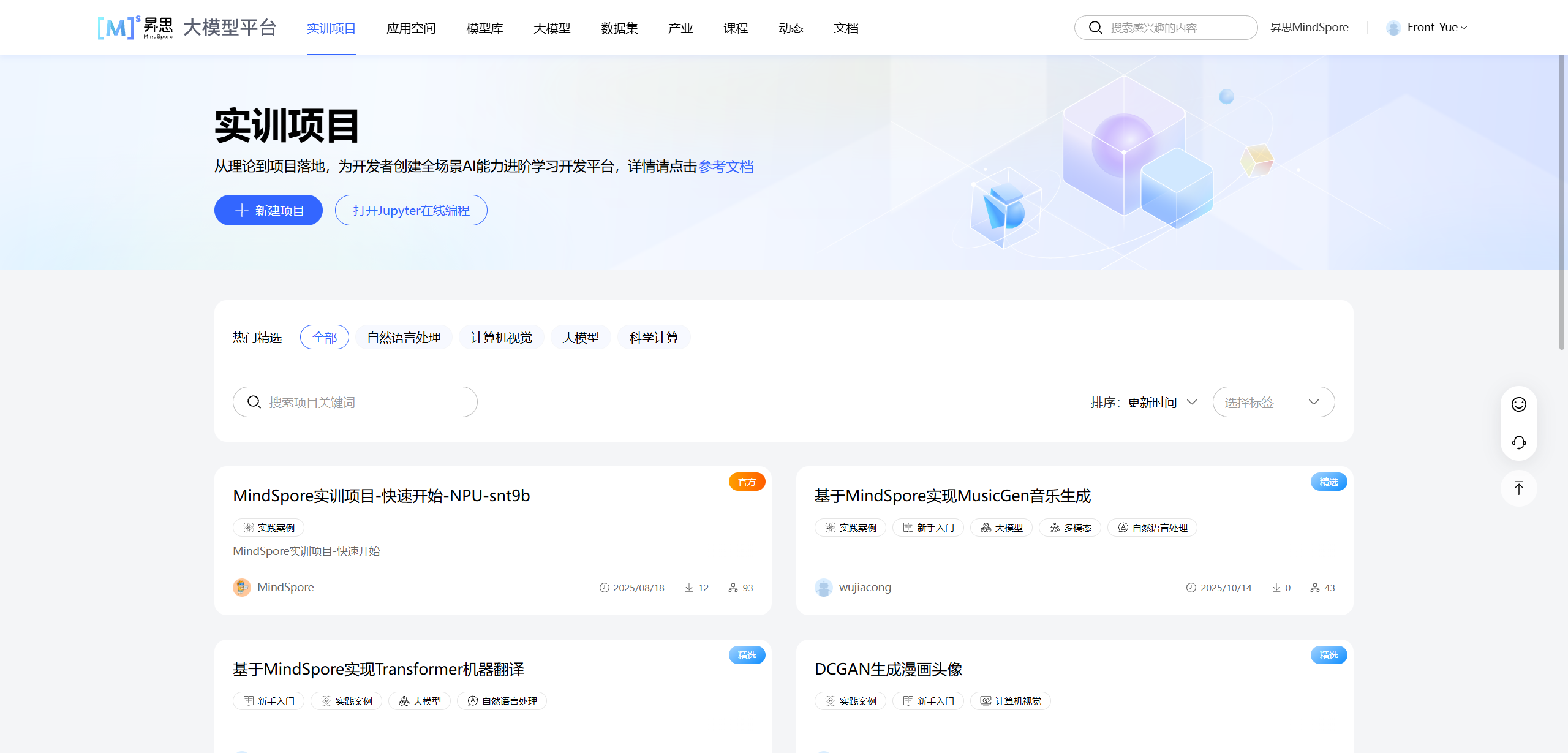
点击“打开 Jupyter 在线编程”后,选择合适的运行环境。本案例推荐使用 Ascend-snt9b 环境,镜像选择包含 mindspore 的版本(如 python3.9-ms2.7.1)。
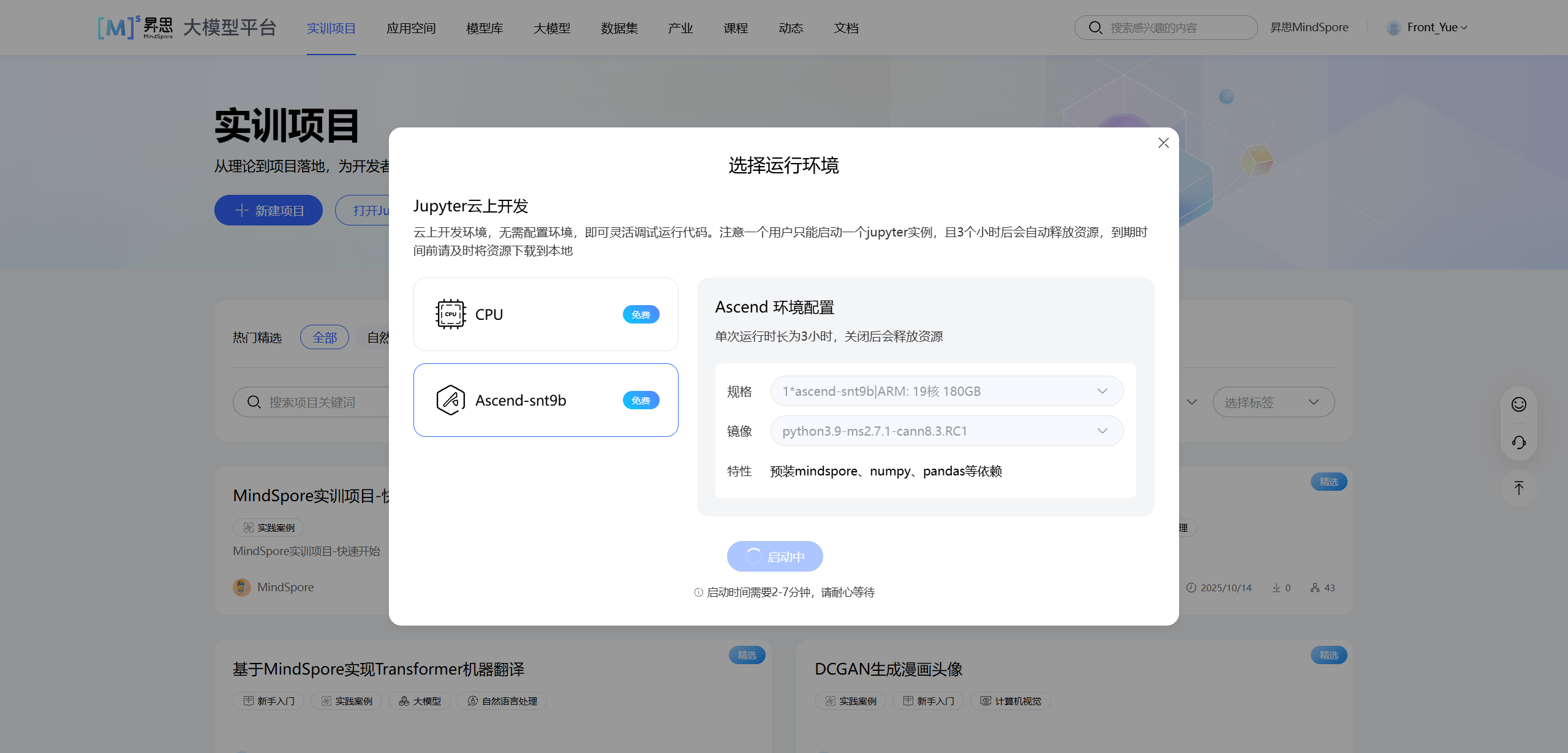
等待环境启动完成后,我们就可以开始编写代码了。
第二步:环境准备
在开始之前,我们需要确认安装了正确版本的 mindspore 和 mindnlp。
本案例的运行环境要求为:
- Python 3.10
- MindSpore 2.7.0
- MindSpore NLP 0.5.1
在 Notebook 的第一个单元格中,我们可以检查或安装依赖:
# 检查当前版本
!pip show mindspore
!pip show mindnlp
# 如果需要安装指定版本,可以运行以下命令(根据实际情况取消注释)
# !pip uninstall mindspore -y
# %env MINDSPORE_VERSION=2.7.0
# !pip install mindspore==2.7.0 -i https://repo.mindspore.cn/pypi/simple --trusted-host repo.mindspore.cn --extra-index-url https://repo.huaweicloud.com/repository/pypi/simple
# 安装 mindnlp
# !pip uninstall mindnlp -y
# !pip install mindnlp==0.5.1
第三步:导入依赖库
环境准备好后,我们需要导入本案例所需的 Python 库,包括 mindspore、mindnlp 以及用于图像处理和可视化的 PIL 和 matplotlib。
import os
import requests
import numpy as np
import mindspore as ms
import matplotlib.pyplot as plt
import matplotlib.patches as patches
from PIL import Image
from pathlib import Path
from mindnlp.transformers import SamModel, SamProcessor
第四步:数据加载与准备
本案例使用 Meta 官方仓库提供的示例图片 dog.jpg。我们定义一个下载函数来获取图片。
1. 下载图片
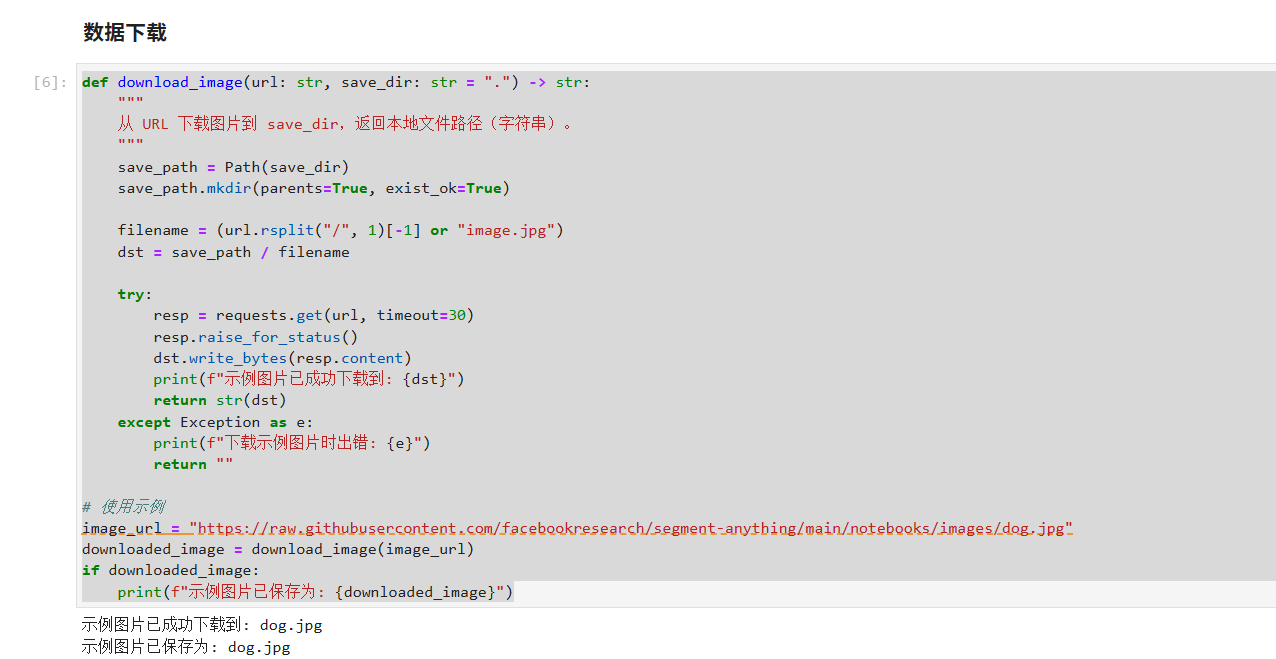
def download_image(url: str, save_dir: str = ".") -> str:
"""
从 URL 下载图片到 save_dir,返回本地文件路径(字符串)。
"""
save_path = Path(save_dir)
save_path.mkdir(parents=True, exist_ok=True)
filename = (url.rsplit("/", 1)[-1] or "image.jpg")
dst = save_path / filename
try:
resp = requests.get(url, timeout=30)
resp.raise_for_status()
dst.write_bytes(resp.content)
print(f"示例图片已成功下载到: {dst}")
return str(dst)
except Exception as e:
print(f"下载示例图片时出错: {e}")
return ""
# 使用示例
image_url = "https://raw.githubusercontent.com/facebookresearch/segment-anything/main/notebooks/images/dog.jpg"
downloaded_image = download_image(image_url)
if downloaded_image:
print(f"示例图片已保存为: {downloaded_image}")
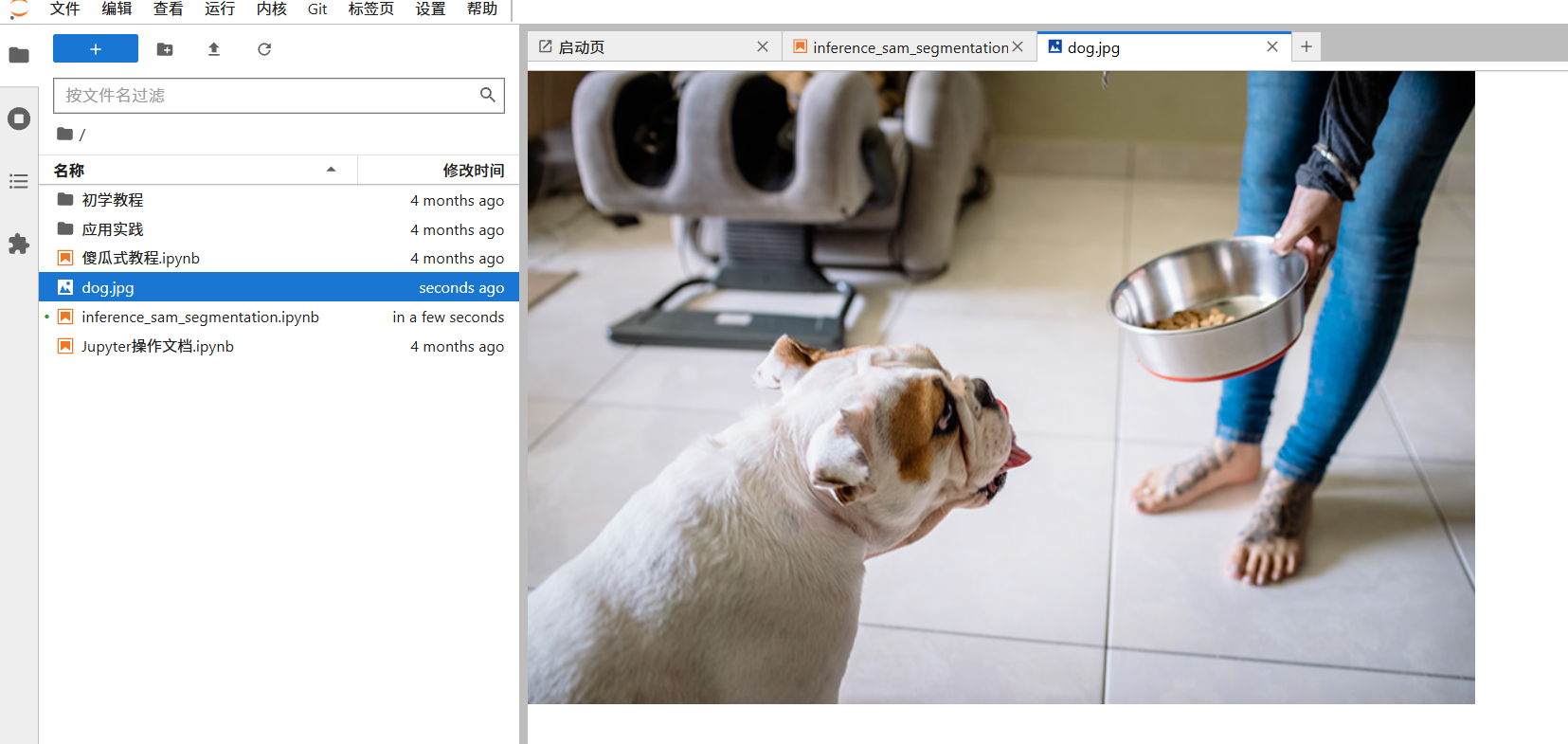
2. 读取图片并设置提示框 (BBox)
SAM 模型支持通过 BBox(边界框)来提示需要分割的区域。我们设置一个坐标为 [0, 217, 450, 800] 的框,并将其画在原图上进行确认。
img_path = "dog.jpg"
assert os.path.exists(img_path), f"Image not found: {img_path}"
# 自定义 BBox,坐标格式为 [x1, y1, x2, y2]
bbox = [0, 217, 450, 800]
bbox = [int(x) for x in bbox]
image = Image.open(img_path).convert("RGB")
W, H = image.size
print("图片尺寸:", (W, H), "| BBox:", bbox)
# 可视化原图和 BBox
plt.figure(figsize=(6,4))
plt.imshow(image)
ax = plt.gca()
rect = patches.Rectangle((bbox[0], bbox[1]), bbox[2]-bbox[0], bbox[3]-bbox[1],
linewidth=2, edgecolor='yellow', facecolor='none')
ax.add_patch(rect)
plt.title("Original image with input box")
plt.axis("off")
plt.show()

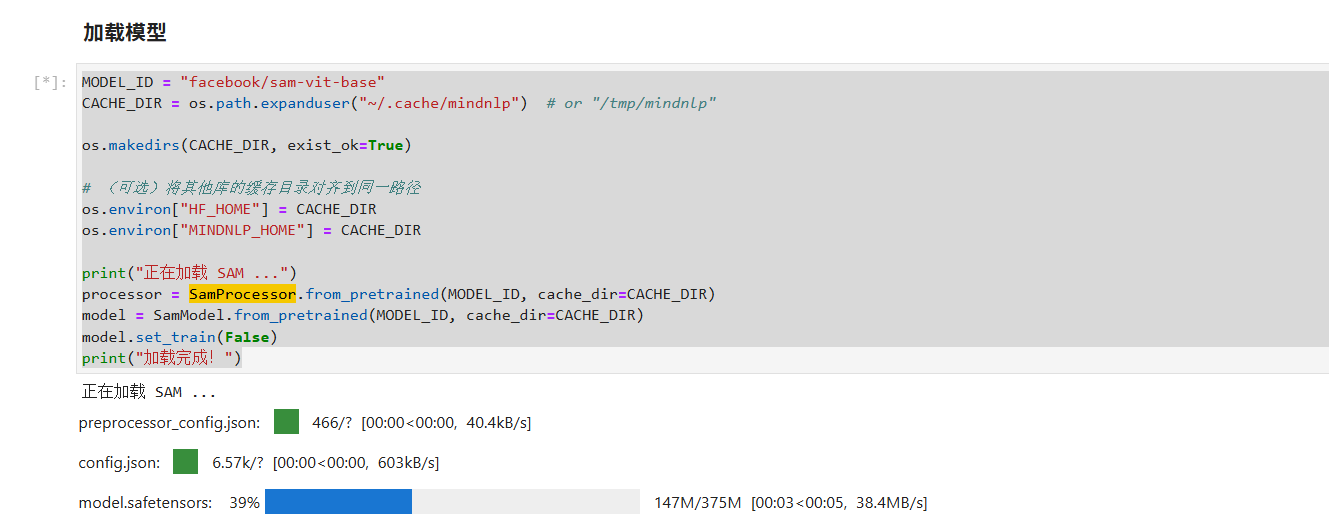
第五步:加载 SAM 模型
接下来,我们从 Hugging Face Hub 加载预训练的 facebook/sam-vit-base 模型和处理器。
MODEL_ID = "facebook/sam-vit-base"
CACHE_DIR = os.path.expanduser("~/.cache/mindnlp")
os.makedirs(CACHE_DIR, exist_ok=True)
os.environ["HF_HOME"] = CACHE_DIR
os.environ["MINDNLP_HOME"] = CACHE_DIR
print("正在加载 SAM ...")
processor = SamProcessor.from_pretrained(MODEL_ID, cache_dir=CACHE_DIR)
model = SamModel.from_pretrained(MODEL_ID, cache_dir=CACHE_DIR)
model.set_train(False)
print("加载完成!")
第六步:模型推理
使用 SamProcessor 处理图像和提示框,然后输入到模型中进行推理。模型会返回预测的掩码(masks)和对应的 IoU 分数。
inputs = processor(images=image, input_boxes=[[bbox]], return_tensors="pt")
outputs = model(**inputs)
pred_masks = outputs.pred_masks # (B, boxes, M, 256, 256)
iou_scores = outputs.iou_scores # (B, boxes, M)
print("pred_masks 形状:", tuple(pred_masks.shape))
print("iou_scores 形状:", tuple(iou_scores.shape))
第七步:结果可视化展示
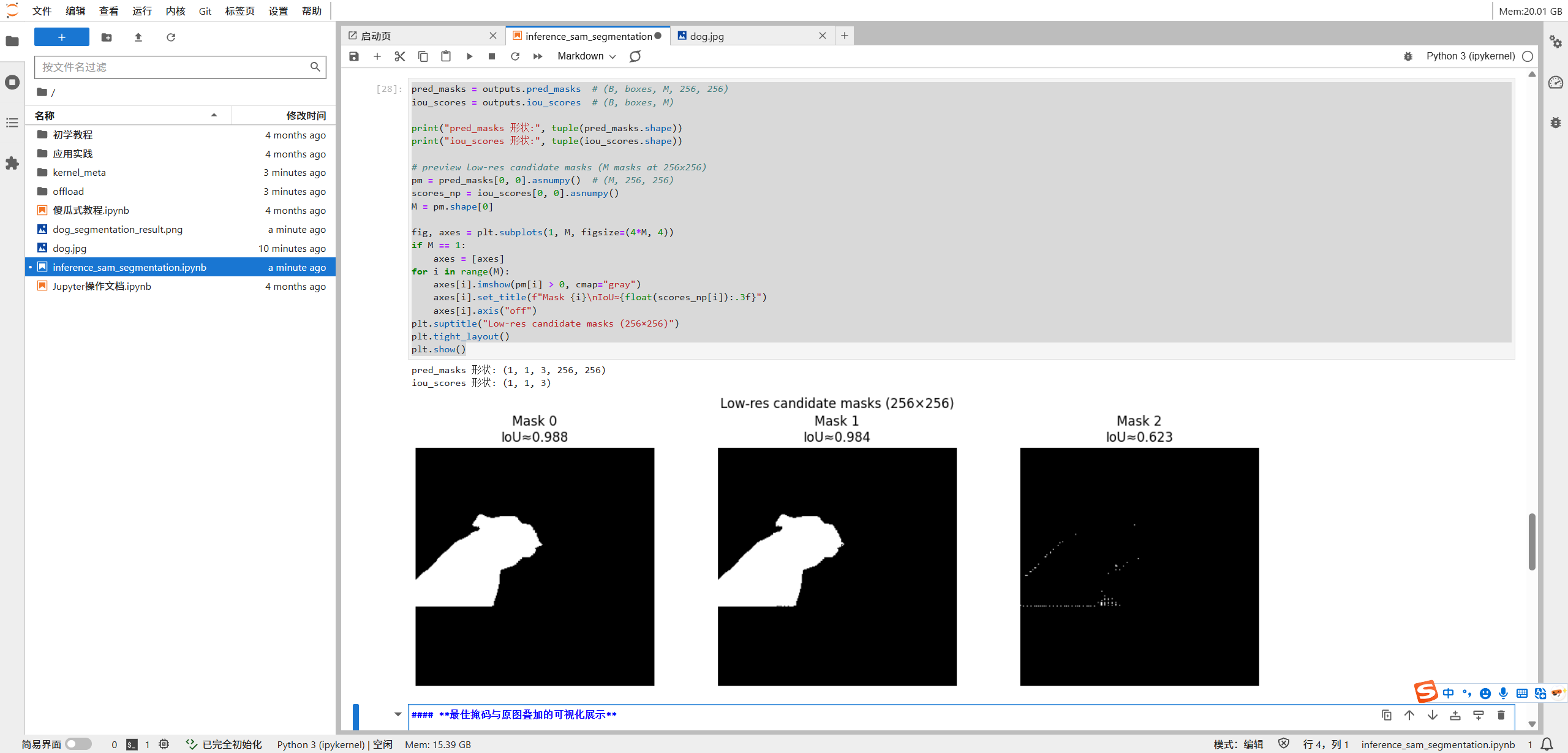
1. 候选掩码可视化
模型通常会输出多个候选掩码(通常是 3 个),我们可以先查看这几个低分辨率的候选掩码。
pm = pred_masks[0, 0].asnumpy()
scores_np = iou_scores[0, 0].asnumpy()
M = pm.shape[0]
fig, axes = plt.subplots(1, M, figsize=(4*M, 4))
if M == 1:
axes = [axes]
for i in range(M):
axes[i].imshow(pm[i] > 0, cmap="gray")
axes[i].set_title(f"Mask {i}\nIoU≈{float(scores_np[i]):.3f}")
axes[i].axis("off")
plt.suptitle("Low-res candidate masks (256×256)")
plt.tight_layout()
plt.show()
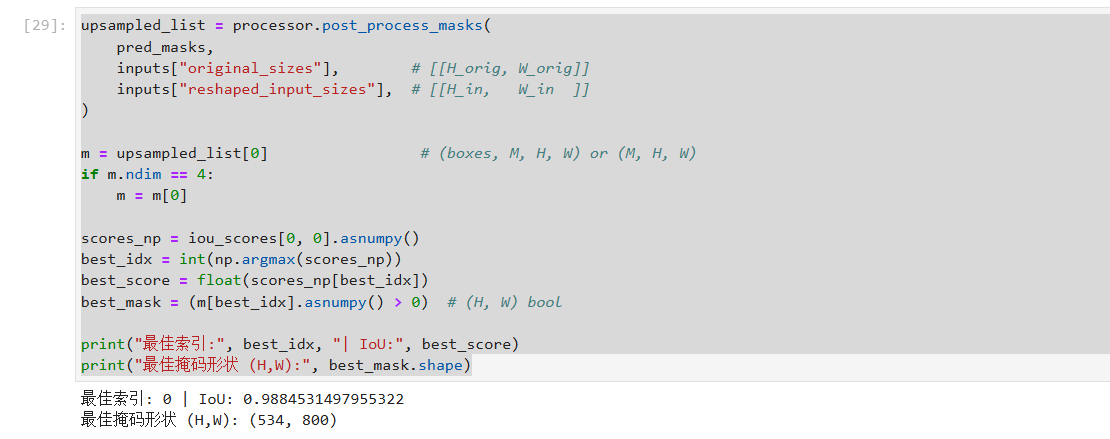
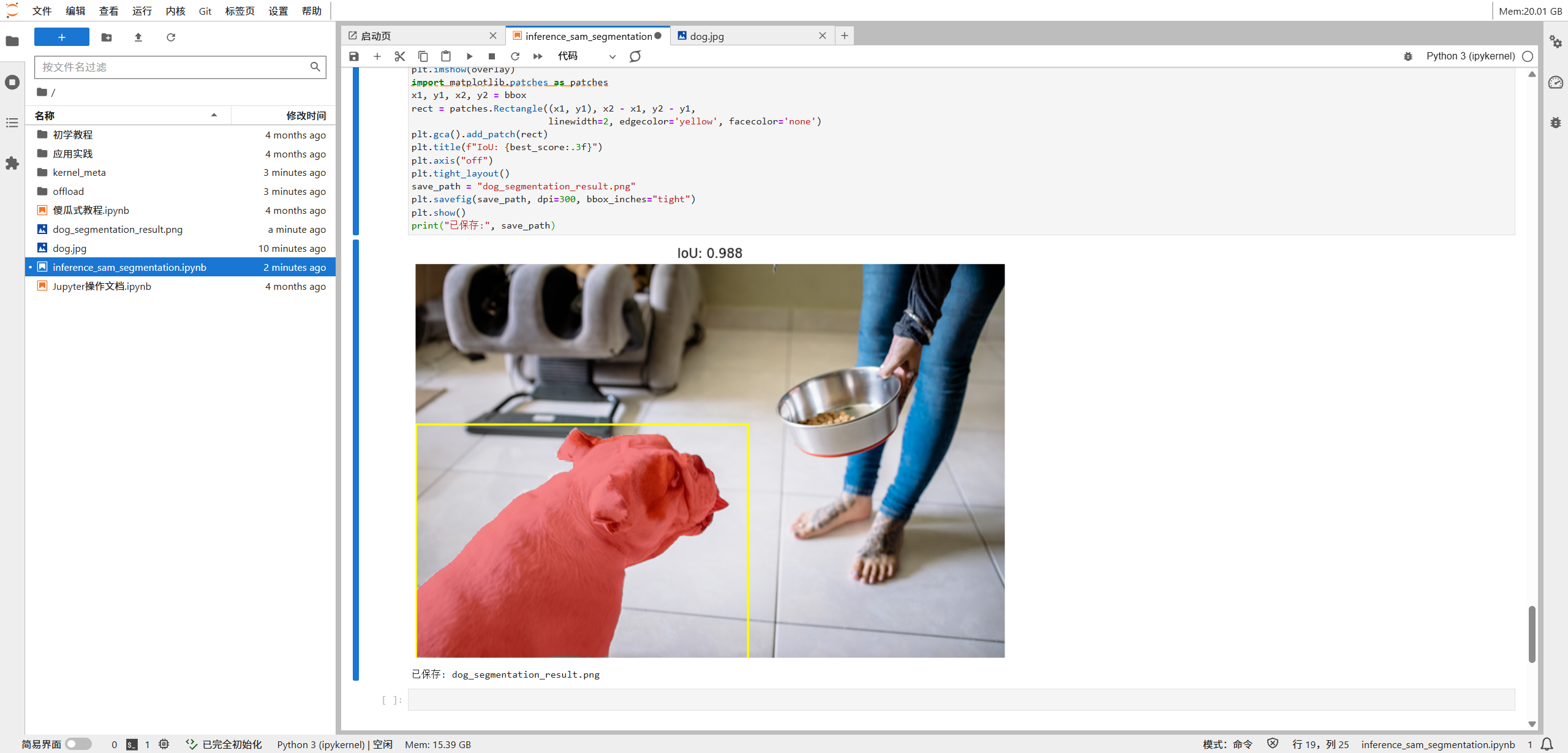
2. 最佳掩码与原图叠加
最后,我们需要将预测的掩码恢复到原图尺寸,并叠加显示效果最好的那个掩码。
# 后处理,将掩码映射回原图尺寸
upsampled_list = processor.post_process_masks(
pred_masks,
inputs["original_sizes"],
inputs["reshaped_input_sizes"],
)
m = upsampled_list[0]
if m.ndim == 4:
m = m[0]
# 选择 IoU 分数最高的掩码
scores_np = iou_scores[0, 0].asnumpy()
best_idx = int(np.argmax(scores_np))
best_score = float(scores_np[best_idx])
best_mask = (m[best_idx].asnumpy() > 0)
print("最佳索引:", best_idx, "| IoU:", best_score)
# 绘制叠加图
H, W = best_mask.shape
overlay = np.zeros((H, W, 4), dtype=np.uint8)
overlay[best_mask] = np.array([255, 0, 0, 115], dtype=np.uint8) # 红色半透明掩码
plt.figure(figsize=(8, 6))
plt.imshow(image)
plt.imshow(overlay)
x1, y1, x2, y2 = bbox
rect = patches.Rectangle((x1, y1), x2 - x1, y2 - y1,
linewidth=2, edgecolor='yellow', facecolor='none')
plt.gca().add_patch(rect)
plt.title(f"IoU: {best_score:.3f}")
plt.axis("off")
plt.tight_layout()
plt.show()

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 8
8 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)