▲基于深度Qlearning强化学习的室内无线网络资源最优分配算法matlab仿真
本文提出一种基于深度Q学习的室内无线网络功率分配算法,用于解决家庭基站密集部署时的同频干扰和能耗问题。通过构建包含信道增益和干扰水平的状态空间,将连续功率离散化为动作空间,以能效作为奖励函数,采用深度神经网络逼近Q值函数。MATLAB仿真结果表明,该算法在能效、传输速率和功率控制方面均优于传统Q学习和注水算法,实现了动态环境下的资源优化分配。完整程序已上传至CSDN平台。
目录
📶1.引言
随着室内无线通信需求的快速增长,家庭基站(Femtocell Base Station, FBS)因其部署灵活、覆盖精准等优势而广泛应用于室内场景。然而,密集部署的家庭基站之间存在严重的同频干扰问题,且每个基站的发射功率若不加以合理控制,将导致系统整体能耗急剧上升。传统的注水算法(Water-Filling Algorithm)在静态信道条件下具有最优性,但面对动态变化的室内信道环境,其性能显著下降。标准Q学习算法虽可应对动态环境,但受制于离散状态-动作空间的维度爆炸,难以处理连续功率分配问题。
本文提出基于深度Q学习(Deep Q-Learning, DQN)的家庭基站发射功率分配算法。该算法利用深度神经网络(Deep Learning Network, DLN)逼近Q值函数,以解决高维连续状态空间下的功率优化问题,通过将能效指标作为奖励信号,结合经验回放和目标网络机制,实现对室内无线网络发射功率的动态优化分配。
🧠2.室内无线网络系统模型
考虑一个包含N个家庭基站的室内无线网络系统。每个家庭基站i服务Ui个用户终端,所有家庭基站共享K个正交子信道进行下行数据传输。家庭基站i在子信道k上的发射功率记为pi,k,每个家庭基站的总发射功率受最大功率约束:
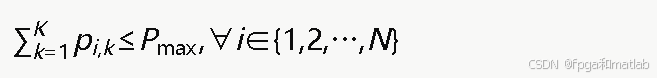
其中,Pmax为单个家庭基站的最大发射功率。
室内无线传播环境具有多径效应显著、阴影衰落复杂等特点。家庭基站i到用户u在子信道k上的信道增益建模为:
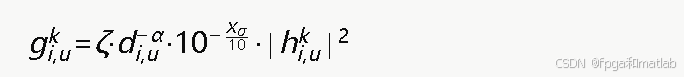
其中ζ为参考距离处的路径损耗常数,di,u为基站i与用户u之间的距离,α为室内路径损耗指数(通常取2至4之间),Xσ为服从均值为零、标准差为σ的对数正态阴影衰落分量,hi,uk为瑞利小尺度衰落系数。
家庭基站i服务的用户u在子信道k上的下行信干噪比(SINR)为:
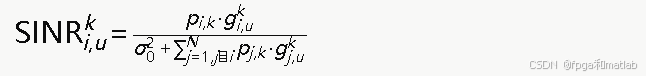
其中σ02为加性高斯白噪声功率,分母中的求和项代表其他所有家庭基站在子信道k上对用户u造成的同频干扰。对应的可达速率为:

其中B为每个子信道的带宽。家庭基站i的总通信速率为:
![]()
系统能效(Energy Efficiency, EE)定义为单位功耗所能传输的比特数,是本文优化的核心目标。家庭基站i的能效表示为:

✅3.深度Q学习算法设计
状态空间:每个家庭基站i在时隙t的状态由当前信道增益信息和干扰水平共同构成:

动作空间:将每个子信道上的连续功率值离散化为L个等级,动作定义为所有子信道上功率等级的组合:
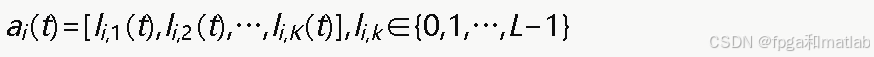
对应的实际发射功率为:

奖励函数:以能效增量作为即时奖励,引导智能体学习节能策略:
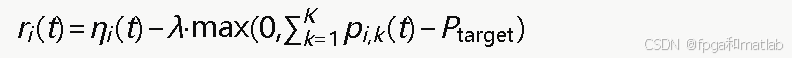
其中λ为功率惩罚系数,Ptarget为目标功率上限,用以鼓励降低不必要的发射功率。
💢4.深度Q网络架构
利用深度神经网络Q(s,a;θ)逼近真实的动作-值函数Q∗(s,a),网络参数为θ。网络结构采用全连接前馈网络,输入层维度等于状态维度∣s∣,输出层维度等于动作空间大小LK。隐藏层使用ReLU激活函数:

📚5.MATLAB程序
%% ======================== 系统参数设置 ========================
N_fbs = 6; % 家庭基站数量
K_ch = 4; % 子信道数量
U_per_fbs = 3; % 每个基站服务用户数
room_size = 20; % 室内区域大小 (m)
B_sub = 180e3; % 子信道带宽 (Hz)
sigma2_noise= 1e-12; % 噪声功率 (W)
P_max = 0.2; % 最大发射功率 (W)
P_circuit = 0.1; % 电路静态功耗 (W)
mu_pa = 2.5; % 功放效率倒数
alpha_pl = 3.0; % 室内路径损耗指数
zeta_ref = 1e-3; % 参考路径损耗
shadow_std = 4; % 阴影衰落标准差 (dB)
% --- DQN参数 ---
L_levels = 5; % 功率离散等级数
gamma_disc = 0.95; % 折扣因子
lr = 0.001; % 学习率
epsilon_init= 1.0; % 初始探索率
epsilon_min = 0.05; % 最小探索率
eps_decay = 0.995; % 探索率衰减
tau_soft = 0.01; % 目标网络软更新系数
buffer_size = 5000; % 经验回放缓冲区大小
batch_size = 64; % 小批量采样大小
target_update_freq = 10; % 目标网络更新频率
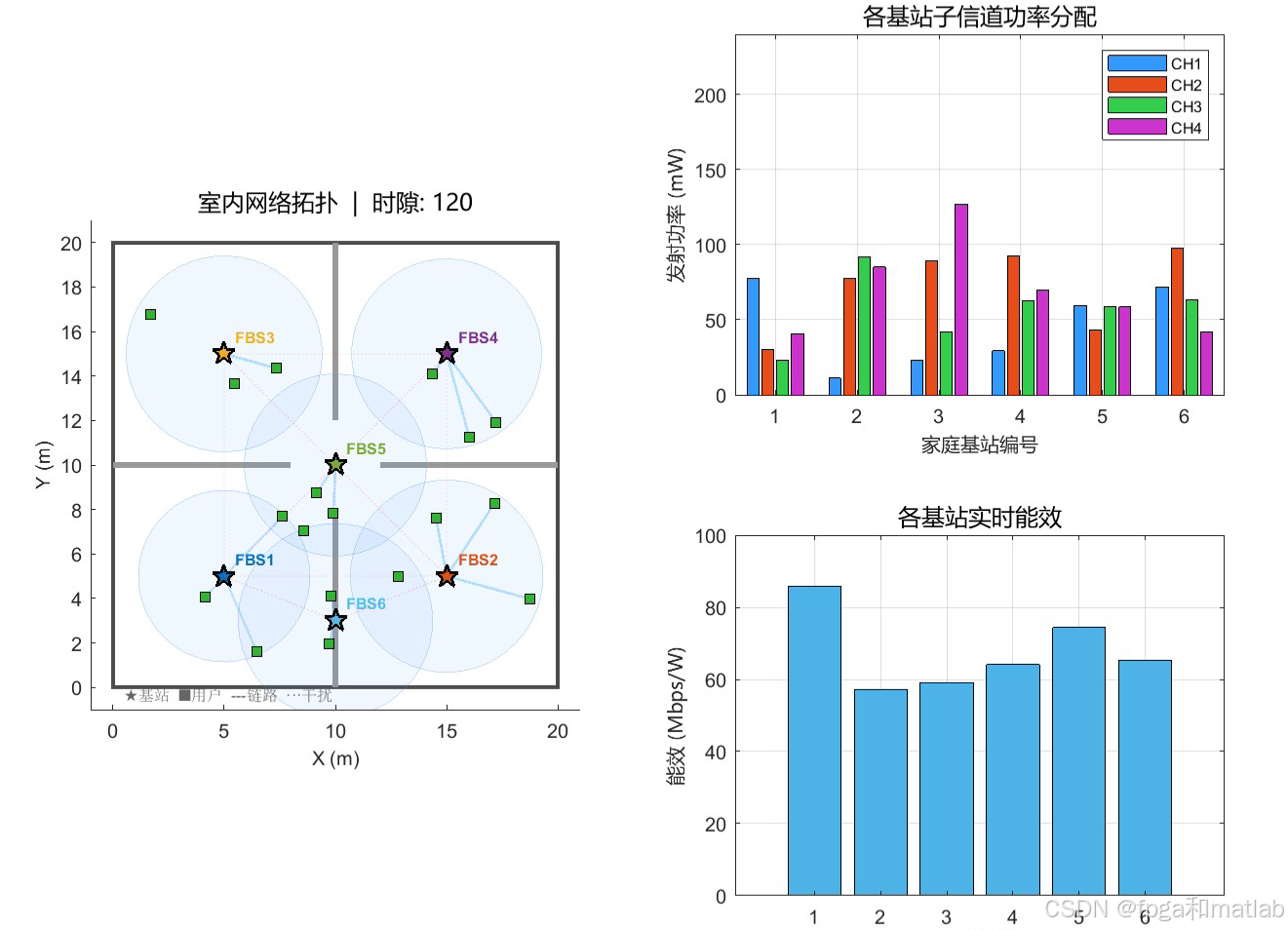
📊6.仿真结果分析
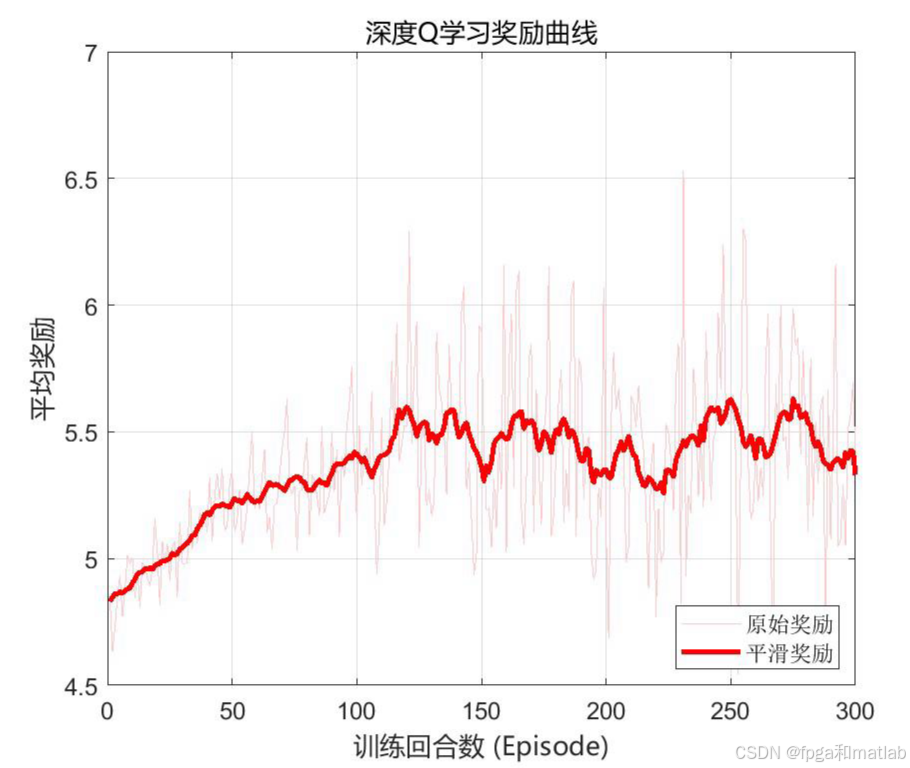
累积奖励曲线,奖励持续上升,反映能效优化策略不断改善。
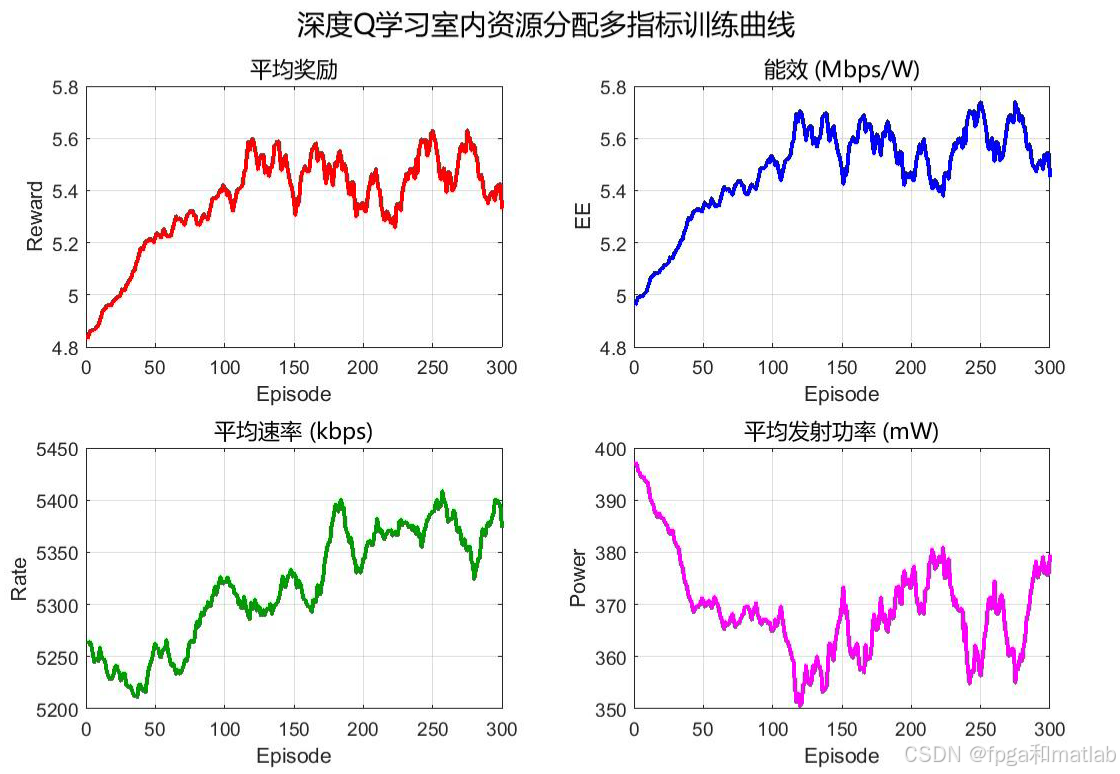
四指标综合面板,奖励↑,能效↑,速率↑,功率↓ 的协同优化趋势。
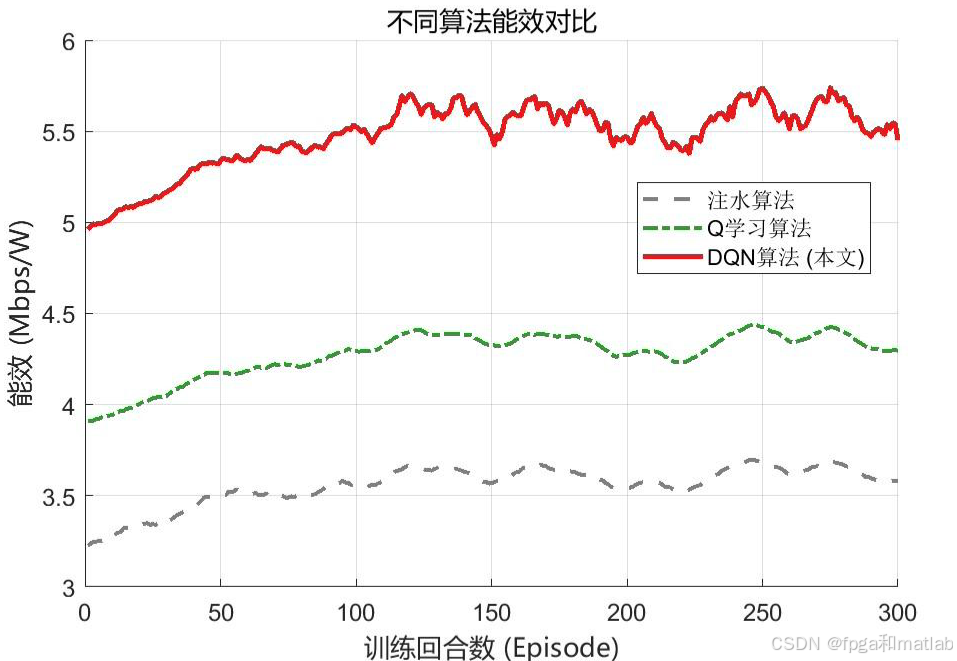
算法对比曲线,DQN在能效和收敛速度上显著优于Q学习和注水算法。
✨7.完整程序下载
完整可运行代码,博主已上传至CSDN,使用版本为MATLAB2024b:
(本程序包含程序操作步骤视频)
基于深度Qlearning强化学习的室内无线网络资源最优分配算法matlab仿真【包括程序,中文注释,程序操作和讲解视频】资源-CSDN下载

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 10
10 0
0- 0



 已为社区贡献48条内容
已为社区贡献48条内容

所有评论(0)