【AI大模型前沿】Mistral 3:欧洲开源力量的AI力作,多模态与高性能的完美融合
Mistral 3是Mistral AI推出的新一代开源AI模型系列,包括小型的Ministral 3(3B、8B、14B参数)和大型的Mistral Large 3(675B总参数,41B激活参数)。该系列模型支持多模态(文本和图像)与多语言功能,具有高性能和高性价比,在多种硬件上可高效运行,适用于边缘计算、企业级部署等多种场景。
系列篇章💥
目录
前言
随着人工智能技术的飞速发展,开源模型领域不断涌现出新的成果。Mistral 3作为Mistral AI推出的最新多模态大模型系列,凭借其卓越的性能、高性价比以及广泛的适用场景,正在成为全球开发者和企业关注的焦点。本文将深入剖析Mistral 3的核心功能、技术架构、性能表现以及应用场景,为读者全面解读这一前沿技术成果。
一、项目概述
Mistral 3是Mistral AI推出的新一代开源AI模型系列,包括小型的Ministral 3(3B、8B、14B参数)和大型的Mistral Large 3(675B总参数,41B激活参数)。该系列模型支持多模态(文本和图像)与多语言功能,具有高性能和高性价比,在多种硬件上可高效运行,适用于边缘计算、企业级部署等多种场景。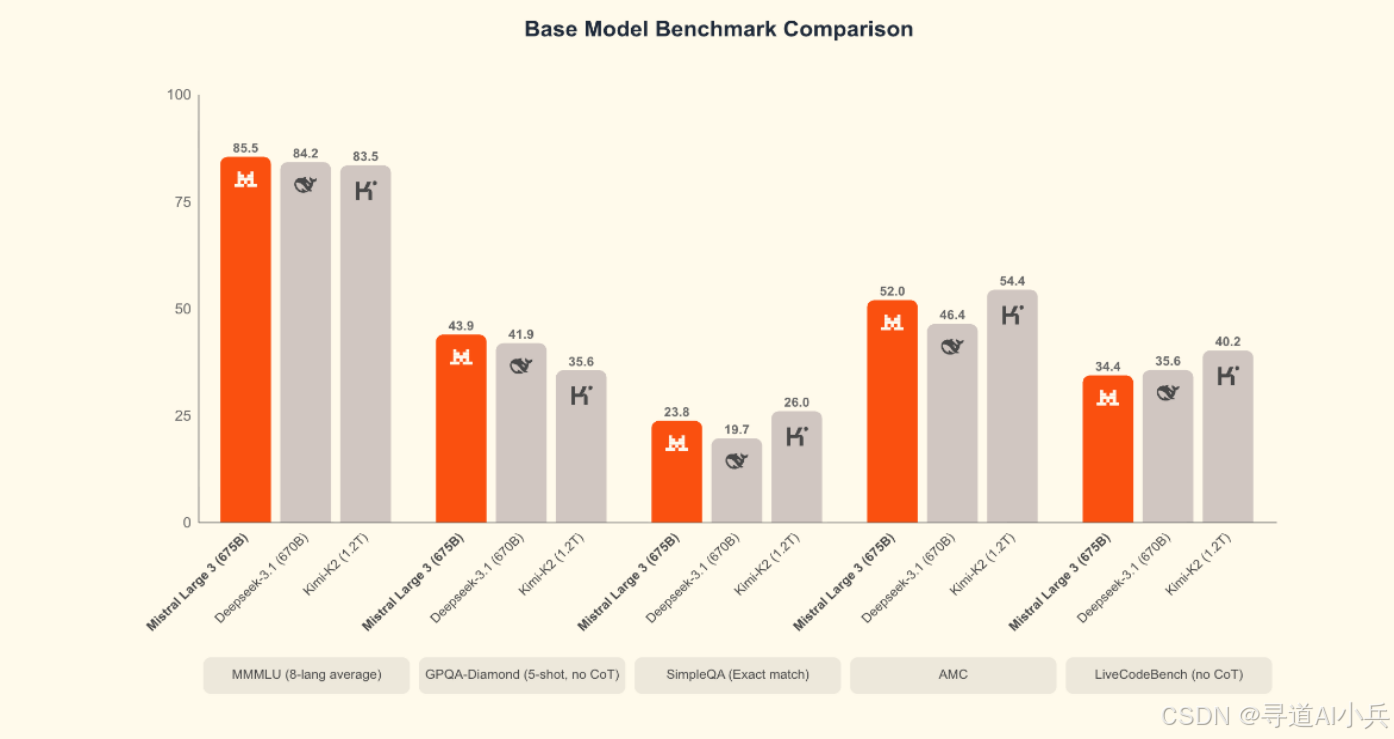
二、核心功能
(一)多模态与多语言能力
Mistral 3支持文本和图像输入,具备强大的多模态处理能力。它能理解和生成超过40种语言的内容,适用于跨语言和跨文化的应用场景。这种能力使模型在处理复杂的多模态任务时表现出色,例如在多语言的图像描述生成和多语言对话系统中。
(二)高效推理与灵活部署
Mistral 3优化了推理性能,支持在边缘设备(如RTX PC、Jetson设备)和数据中心(如NVIDIA H100、A100)上高效运行。它提供了从边缘到云端的灵活部署选项,能够根据不同的硬件环境和应用场景进行优化部署。这种灵活性使得模型能够在各种资源受限或高性能需求的环境中高效运行。
(三)多种模型变体
Mistral 3提供了基础版(Base)、指令微调版(Instruct)和推理版(Reasoning)。每种变体针对不同的任务需求进行了优化。例如,指令微调版适合处理指令跟随任务,推理版则在复杂推理任务中表现出色。这种多样化的模型变体设计,满足了从文档分析到创意协作、多语言对话等多种应用场景。
(四)高性价比
Ministral 3系列(3B、8B、14B参数)在性能和成本之间取得了最佳平衡。这些模型生成更少的token数量,同时保持高性能。这种高性价比的设计使得Mistral 3成为在资源受限环境中部署的理想选择,能够在不牺牲性能的前提下,显著降低计算成本。
(五)定制化服务
Mistral AI提供定制模型训练服务,支持企业根据特定需求对模型进行微调或优化。这种定制化服务使企业能够根据自身的业务需求和数据特点,对模型进行针对性的优化。无论是优化特定领域任务的性能,还是在专有数据集上提升表现,Mistral 3都能为企业提供个性化的解决方案。
三、技术揭秘
(一)混合专家架构(MoE)
Mistral Large 3 采用稀疏混合专家架构,总参数量达 675B,激活参数为 41B。这种架构通过动态分配计算资源,提高模型效率和扩展性。它允许模型在大规模训练中高效利用计算资源,同时保持高性能。
(二)预训练与微调
模型在大规模数据上进行预训练,学习通用语言和图像模式。预训练后,通过指令微调(Instruct)和推理优化(Reasoning),提升模型在特定任务上的表现。这种组合方法使模型在多种任务中都能达到优异的性能。
(三)硬件优化
与 NVIDIA 合作,使用 HBM3e 高带宽内存和 Hopper 架构的 GPU 进行训练和推理优化。通过 TensorRT-LLM 和 SGLang 等技术,实现高效的低精度执行。这些优化确保了模型在不同硬件环境中的高效运行。
(四)多模态融合
集成先进的多模态技术,使模型能同时处理文本和图像输入。这种融合能力让模型能够实现更丰富的语义理解和生成能力,例如在图像描述和多模态对话任务中表现出色。
(五)分布式智能
通过优化的压缩格式(如 NVFP4)和高效的推理框架(如 vLLM),支持在分布式系统中高效运行。这种设计降低了部署成本,同时提高了模型的可扩展性,使其能够在多种硬件配置下高效运行。
(六)推理优化
针对长上下文和高吞吐量任务,采用预填充/解码分离服务和推测性解码技术。这些技术显著提升了推理效率和响应速度,使模型在处理复杂任务时更加高效。
四、性能表现
(一)推理能力测试
在推理能力方面,Ministral 3 在多个基准测试中取得了显著成绩。例如,在 Arena Hard 和 WildBench 等测试中,它分别达到了 0.509 和 66.8 的高分。这表明该模型在处理复杂指令和多语言对话任务时具有很强的适应性和准确性。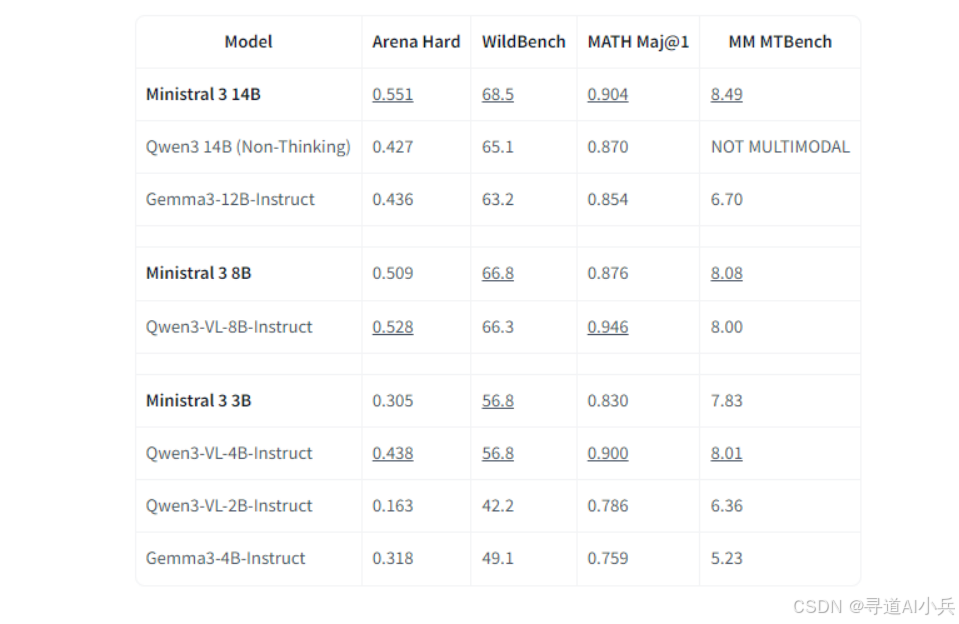
(二)多语言能力测试
Ministral 3在多语言处理方面表现出色。在 Multilingual MMLU 和 TriviaQA 等多语言基准测试中,它分别达到了 0.706 和 0.681 的高分。这表明该模型能够理解和生成多种语言的内容,支持跨语言的应用场景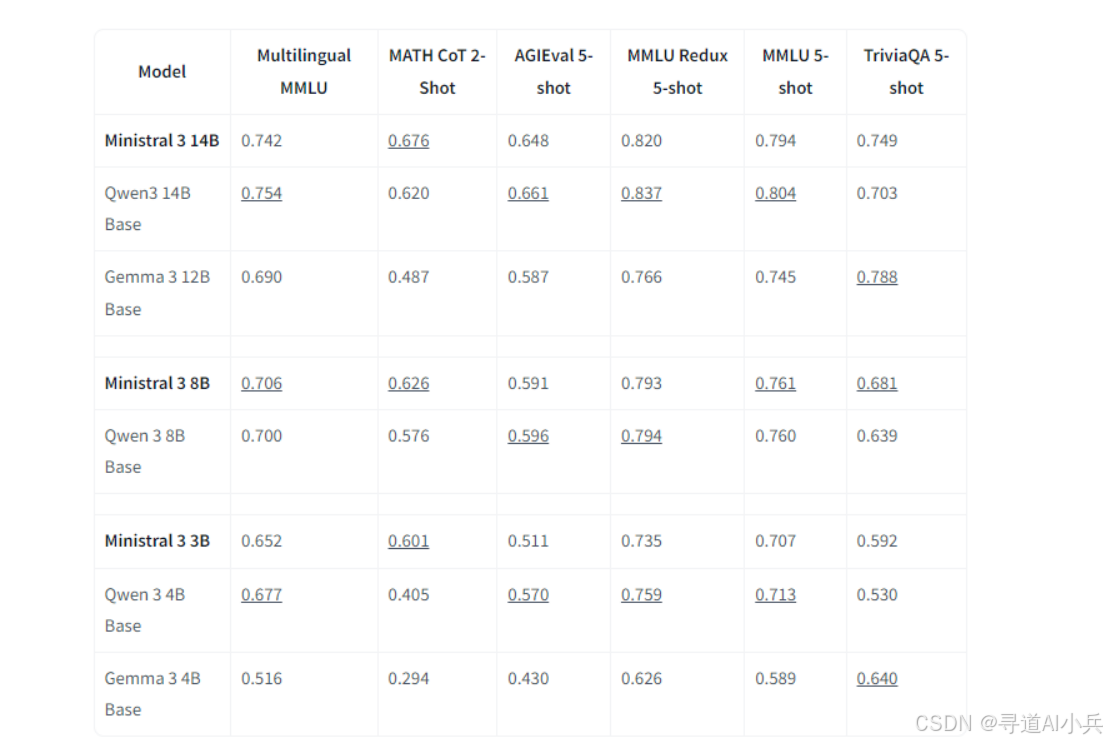
五、应用场景
(一)智能客服与多语言对话系统
利用 Mistral 3 的多语言对话能力,企业可构建智能客服系统,支持多语言咨询。它能够自动理解用户问题并提供准确回答,显著提升客户体验。这种系统不仅降低了人力成本,还能实现24小时不间断服务,特别适用于国际化企业。
(二)内容创作与文案生成
Mistral 3 能快速生成高质量文案,帮助创作者提高效率。它适用于广告、媒体和社交媒体等领域,能够根据用户需求生成创意文案、新闻报道或社交媒体内容。这种能力不仅节省时间,还能激发创作者的灵感。
(三)智能教育工具
基于 Mistral 3 开发的多语言智能辅导系统,为学生提供个性化学习支持。它能够根据学生的学习进度和需求,生成针对性的学习材料和练习题。这种系统支持多种语言,适应不同语言背景的学生,提升学习效果。
(四)智能边缘设备应用
将 Mistral 3 部署到边缘设备,如 RTX PC 和 Jetson 设备,可实现低延迟的语音助手和图像识别功能。这种部署方式优化了智能家居和工业自动化场景,使设备能够实时响应用户指令,提高系统的智能化水平。
(五)企业级文档分析与知识管理
Mistral 3 能高效分析企业文档,实现自动摘要、翻译和问答。它支持多语言处理,特别适用于国际化企业。通过这种能力,企业可以快速提取文档中的关键信息,提升知识管理效率,优化内部信息流通。
六、快速使用
(一)安装依赖
确保安装 vllm >= 0.12.0:
pip install vllm --upgrade
这样应该会自动安装 mistral_common >= 1.8.6 。检查:
python -c "import mistral_common; print(mistral_common.__version__)"
(二)启动服务
vllm serve mistralai/Ministral-3-8B-Instruct-2512 \
--tokenizer_mode mistral --config_format mistral --load_format mistral \
--enable-auto-tool-choice --tool-call-parser mistral
可以设置 --max-model-len 来保留内存。默认情况下设置为 262144 ,这个值比较大,但对于大多数场景并不必要。
可以设置 --max-num-batched-tokens 来平衡吞吐量和延迟,数值越高表示吞吐量越高,但延迟也越高。
(三)模型推理
1、视觉推理
from datetime import datetime, timedelta
from openai import OpenAI
from huggingface_hub import hf_hub_download
# Modify OpenAI's API key and API base to use vLLM's API server.
openai_api_key = "EMPTY"
openai_api_base = "http://localhost:8000/v1"
TEMP = 0.15
MAX_TOK = 262144
client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base,
)
models = client.models.list()
model = models.data[0].id
def load_system_prompt(repo_id: str, filename: str) -> str:
file_path = hf_hub_download(repo_id=repo_id, filename=filename)
with open(file_path, "r") as file:
system_prompt = file.read()
today = datetime.today().strftime("%Y-%m-%d")
yesterday = (datetime.today() - timedelta(days=1)).strftime("%Y-%m-%d")
model_name = repo_id.split("/")[-1]
return system_prompt.format(name=model_name, today=today, yesterday=yesterday)
SYSTEM_PROMPT = load_system_prompt(model, "SYSTEM_PROMPT.txt")
image_url = "https://static.wikia.nocookie.net/essentialsdocs/images/7/70/Battle.png/revision/latest?cb=20220523172438"
messages = [
{"role": "system", "content": SYSTEM_PROMPT},
{
"role": "user",
"content": [
{
"type": "text",
"text": "What action do you think I should take in this situation? List all the possible actions and explain why you think they are good or bad.",
},
{"type": "image_url", "image_url": {"url": image_url}},
],
},
]
response = client.chat.completions.create(
model=model,
messages=messages,
temperature=TEMP,
max_tokens=MAX_TOK,
)
print(response.choices[0].message.content)
2、纯文本示例
from openai import OpenAI
from huggingface_hub import hf_hub_download
# Modify OpenAI's API key and API base to use vLLM's API server.
openai_api_key = "EMPTY"
openai_api_base = "http://localhost:8000/v1"
TEMP = 0.15
MAX_TOK = 262144
client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base,
)
models = client.models.list()
model = models.data[0].id
def load_system_prompt(repo_id: str, filename: str) -> str:
file_path = hf_hub_download(repo_id=repo_id, filename=filename)
with open(file_path, "r") as file:
system_prompt = file.read()
return system_prompt
SYSTEM_PROMPT = load_system_prompt(model, "SYSTEM_PROMPT.txt")
messages = [
{"role": "system", "content": SYSTEM_PROMPT},
{
"role": "user",
"content": "Write me a sentence where every word starts with the next letter in the alphabet - start with 'a' and end with 'z'.",
},
]
response = client.chat.completions.create(
model=model,
messages=messages,
temperature=TEMP,
max_tokens=MAX_TOK,
)
assistant_message = response.choices[0].message.content
print(assistant_message)
七、结语
Mistral 3作为Mistral AI的最新力作,以其卓越的性能、多模态能力、高性价比以及灵活的部署选项,为全球开发者和企业提供了强大的AI工具。无论是在边缘设备上的轻量级应用,还是在企业级场景中的复杂任务处理,Mistral 3都能展现出色的表现。随着技术的不断发展和优化,Mistral 3有望在更多领域发挥重要作用,推动人工智能技术的广泛应用。
八、项目地址
- Mistral 3项目官网:https://mistral.ai/news/mistral-3
- Hugging Face模型库:https://huggingface.co/collections/mistralai/ministral-3

🎯🔖更多专栏系列文章:AI大模型提示工程完全指南、AI大模型探索之路(零基础入门)、AI大模型预训练微调进阶、AI大模型开源精选实践、AI大模型RAG应用探索实践🔥🔥🔥 其他专栏可以查看博客主页📑
😎 作者介绍:资深程序老猿,从业10年+、互联网系统架构师,目前专注于AIGC的探索(CSDN博客之星|AIGC领域优质创作者)
📖专属社群:欢迎关注【小兵的AI视界】公众号或扫描下方👇二维码,回复‘入群’ 即刻上车,获取邀请链接。
💘领取三大专属福利:1️⃣免费赠送AI+编程📚500本,2️⃣AI技术教程副业资料1套,3️⃣DeepSeek资料教程1套🔥(限前500人)
如果文章内容对您有所触动,别忘了点赞、⭐关注,收藏!加入我们,一起携手同行AI的探索之旅,开启智能时代的大门!

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 25
25 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)