大模型在S100系统中的高效转换与量化部署:从GGUF、SafeTensors到ONNX的解决方案
大模型部署面临存储、内存带宽和计算资源三大挑战。GGUF和SafeTensors作为两种高效模型格式,分别针对量化优化和安全存储设计。GGUF统一管理元数据并支持内存映射,而SafeTensors采用零拷贝加载确保安全性。ONNX Runtime GenAI工具链可将这些格式转换为优化的ONNX中间表示,支持多种精度和硬件加速。通过标准化转换流程和量化技术,实现了大模型在资源受限环境下的高效部署,
0. 引言:大模型部署的技术挑战
随着人工智能技术的快速发展,大语言模型和多模态模型在各个领域展现出了强大的能力。然而,在实际的工业部署中,这些模型面临着巨大的技术挑战。一个典型的大模型往往包含数十亿甚至数千亿个参数,仅存储FP16精度的模型权重就需要数十GB的空间,这对存储、内存带宽和计算资源都提出了极高的要求。
存储空间限制:以Llama2-7B模型为例,其FP16格式的模型文件大小约为13GB,而FP32格式则需要26GB。在资源受限的边缘设备上,如此庞大的存储需求往往难以满足。
内存带宽瓶颈:大模型推理过程中,需要频繁地从内存中读取模型参数。内存带宽的限制使得模型推理速度受到严重制约,特别是在序列生成任务中,这种瓶颈更加明显。
计算资源约束:虽然现代AI芯片的算力不断提升,但面对动辄数十亿参数的模型,计算资源仍然是宝贵的。如何在有限的算力下实现高效推理,是每个部署工程师都必须考虑的问题。
1. GGUF与SafeTensors模型格式解析
在现代深度学习生态系统中,模型的存储和分发格式直接影响着部署的便利性和性能。本节将深入分析两种重要的模型格式:GGUF和SafeTensors,并探讨它们各自的技术特点和应用场景。
1.1 GGUF格式:面向量化优化的统一格式
GGUF(GPT-Generated Unified Format)是llama.cpp社区开发的新一代模型文件格式,专门针对量化模型的高效存储和加载而设计。它是对早期GGML格式的重大改进,解决了版本兼容性和扩展性等关键问题。
1.1.1 GGUF格式的核心优势
统一的元数据管理:GGUF文件将模型权重、架构配置、分词器信息、量化参数等所有运行时需要的信息打包在一个文件中。这种设计极大地简化了模型的分发和部署流程,用户只需下载一个GGUF文件就能获得完整的模型资源。
高效的内存映射支持:GGUF采用了精心设计的文件结构,数据块严格对齐,非常适合使用内存映射(mmap)技术。这意味着即使是几十GB的大模型也能实现近乎瞬时的加载,同时显著降低峰值内存占用。
丰富的量化选项:GGUF支持多种量化方法,包括Q4_0、Q4_1、Q8_0等基础量化格式,以及Q4_K_M、Q5_K_M等K-quants系列高级量化格式。这些量化方法通过对模型不同层使用不同精度,在保持性能的同时实现更高的压缩比。
1.1.2 GGUF的技术实现原理
GGUF文件的结构设计体现了对性能和兼容性的精心平衡。文件头部包含版本号和键值对元数据,确保了格式的前向兼容性。权重数据部分采用分块存储,每个张量都有独立的元信息,包括数据类型、维度和偏移量等,这使得部分加载成为可能。
# GGUF文件结构示意
class GGUFFile:
def __init__(self):
self.header = {
'magic': 'GGUF',
'version': 3,
'tensor_count': 0,
'metadata_kv_count': 0
}
self.metadata = {} # 键值对形式的模型元信息
self.tensor_infos = [] # 张量信息列表
self.tensor_data = b'' # 实际的权重数据
1.2 SafeTensors格式:安全高效的现代选择
SafeTensors是Hugging Face开发的新一代模型存储格式,其设计目标是提供比传统pickle格式更安全、更高效的模型序列化方案。与GGUF不同,SafeTensors主要关注模型权重的安全存储和快速加载。
1.2.1 SafeTensors的设计理念
安全性优先:传统的pickle格式存在严重的安全隐患,恶意构造的模型文件可能在加载时执行任意代码。SafeTensors采用了简单的二进制格式,仅包含张量数据和基本元信息,从根本上杜绝了代码注入的可能性。
零拷贝加载:SafeTensors的文件格式支持零拷贝操作,模型加载时可以直接映射文件内容到内存,避免了数据复制的开销。这对于大模型的快速启动至关重要。
跨框架兼容:SafeTensors提供了统一的API接口,支持PyTorch、TensorFlow、JAX等主流深度学习框架,为模型的跨平台部署提供了便利。
1.2.2 SafeTensors的文件结构
SafeTensors文件由头部信息和张量数据两部分组成。头部使用JSON格式存储张量的元信息,包括名称、数据类型、形状和在文件中的偏移量。这种设计既保证了可读性,又确保了解析的高效性。
# SafeTensors文件结构
{
"header_size": 1024,
"metadata": {
"model.layers.0.weight": {
"dtype": "F16",
"shape": [4096, 4096],
"data_offsets": [1024, 33558528]
},
"model.layers.1.weight": {
"dtype": "F16",
"shape": [4096, 4096],
"data_offsets": [33558528, 67092032]
}
}
}
2. 模型格式转换:从GGUF/SafeTensors到ONNX
ONNX(Open Neural Network Exchange)作为一种开放的神经网络交换格式,为不同深度学习框架之间的模型互操作性提供了标准化解决方案。在S100系统的部署流程中,ONNX格式是必不可少的中间表示形式。本节将详细介绍如何将GGUF和SafeTensors格式的模型转换为ONNX格式。
2.1 ONNX格式的技术优势
ONNX格式在工业部署中具有独特的优势。首先,它提供了与硬件无关的模型表示,使得同一个模型可以在不同的推理引擎上运行。其次,ONNX支持丰富的算子集合,能够表示大多数深度学习模型的计算图。最重要的是,ONNX Runtime等推理引擎针对ONNX格式进行了深度优化,在性能和内存使用方面都有显著优势。
2.2 ONNX Runtime GenAI:统一的模型转换解决方案
ONNX Runtime GenAI是微软推出的专门用于生成式AI模型的转换和部署工具,它提供了统一的接口来将各种格式的模型转换为ONNX格式。本节将详细介绍如何使用ONNX Runtime GenAI进行模型转换。
2.2.1 ONNX Runtime GenAI工具链概述
ONNX Runtime GenAI的核心组件是models.builder工具,它能够将Hugging Face上的PyTorch模型或GGUF模型转换为ONNX格式。该工具支持多种生成式模型,包括LLaMA、Phi、GPT等主流架构。
主要特性:
- 支持多种模型格式:PyTorch、GGUF、SafeTensors
- 内置量化支持:INT4、INT8、FP16、FP32
- 多执行提供程序:CPU、CUDA、DML
- 自动优化:算子融合、内存优化、图优化
2.2.2 工具安装与环境配置
# 安装ONNX Runtime GenAI
pip install onnxruntime-genai
# 验证安装
python -c "import onnxruntime_genai; print('安装成功')"
# 查看工具帮助
python -m onnxruntime_genai.models.builder -h
工具参数详解:
python -m onnxruntime_genai.models.builder -h
输出参数说明:
-m, --model_name: 指定Hugging Face模型ID(如:microsoft/Phi-3-mini-4k-instruct)-i, --input: 指定本地模型路径-o, --output: 指定输出目录-p, --precision: 控制精度和量化(fp32, fp16, int8, int4)-e, --execution_provider: 指定执行提供程序(cpu, cuda, dml)-c, --cache_dir: 控制模型转换过程中的临时文件目录--extra_options: 扩展参数,支持多种高级配置
2.2.3 基本转换流程
步骤1:直接转换Hugging Face模型
# 转换Phi-3-mini-4k-instruct模型
python -m onnxruntime_genai.models.builder \
-m microsoft/Phi-3-mini-4k-instruct \
-o ./Phi-3-mini-4k-instruct-onnx \
-p int4 \
-e cpu \
--extra_options attn_implementation=eager
转换过程监控:
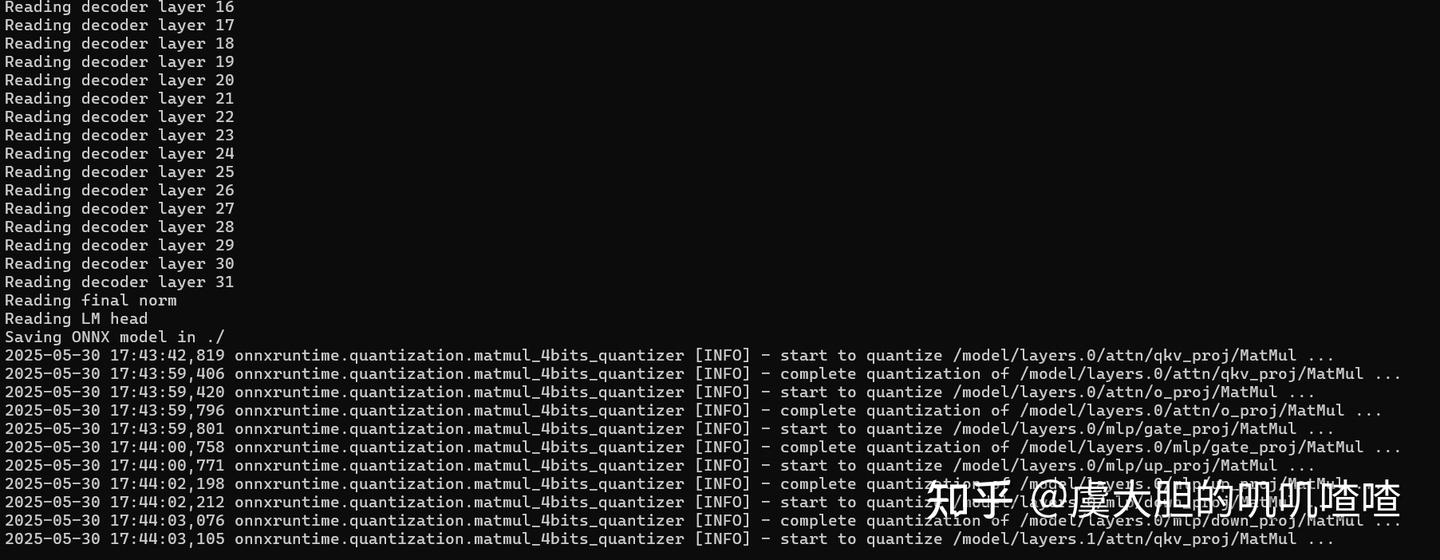
步骤2:本地模型转换
# 先下载模型到本地
huggingface-cli login
huggingface-cli download microsoft/Phi-3-mini-4k-instruct --local-dir
# 使用本地路径转换
python -m onnxruntime_genai.models.builder \
-o ./Phi-3-mini-4k-instruct-onnx \
-i /path/to/local/model \
-p int4 \
-e cpu \
--extra_options attn_implementation=eager
2.2.4 高级配置选项
extra_options参数详解:
# 常用extra_options配置
extra_options_configs = {
# 注意力机制实现
'attn_implementation': 'eager', # 或 'flash_attention_2'
# 模型层数限制(用于快速测试)
'num_hidden_layers': 4,
# 仅生成配置文件
'config_only': True,
# 量化配置
'quantization_config': {
'load_in_4bit': True,
'bnb_4bit_quant_type': 'nf4',
'bnb_4bit_use_double_quant': True
},
# 模型优化配置
'optimization_config': {
'enable_fusion': True,
'enable_memory_optimization': True,
'enable_graph_optimization': True
}
}
实际使用示例:
# 快速测试配置(减少层数)
python -m onnxruntime_genai.models.builder \
-m microsoft/Phi-3-mini-4k-instruct \
-o ./test-model \
-p int4 \
-e cpu \
--extra_options num_hidden_layers=4
# 仅生成配置文件
python -m onnxruntime_genai.models.builder \
-m model_name \
-o ./ \
-p int4 \
-e cpu \
--extra_options config_only=true
# 使用Flash Attention优化
python -m onnxruntime_genai.models.builder \
-m microsoft/Phi-3-mini-4k-instruct \
-o ./optimized-model \
-p fp16 \
-e cuda \
--extra_options attn_implementation=flash_attention_2
2.2.5 输出文件结构分析
转换完成后,会生成以下文件结构:
Phi-3-mini-4k-instruct-onnx/
├── genai_config.json # GenAI配置文件(最重要)
├── model.onnx # ONNX模型文件
├── model.onnx.data # 模型权重数据
├── special_tokens_map.json # 特殊token映射
├── tokenizer.json # 分词器配置
└── tokenizer_config.json # 分词器元数据
genai_config.json核心配置解析:
{
"model": {
"bos_token_id": 1,
"context_length": 4096,
"decoder": {
"session_options": {
"log_id": "onnxruntime-genai",
"provider_options": []
},
"filename": "model.onnx",
"head_size": 96,
"hidden_size": 3072,
"inputs": {
"input_ids": "input_ids",
"attention_mask": "attention_mask",
"past_key_names": "past_key_values.%d.key",
"past_value_names": "past_key_values.%d.value"
},
"outputs": {
"logits": "logits",
"present_key_names": "present.%d.key",
"present_value_names": "present.%d.value"
},
"num_attention_heads": 32,
"num_hidden_layers": 32,
"num_key_value_heads": 32
},
"eos_token_id": [32000, 32001, 32007],
"pad_token_id": 32000,
"type": "phi3",
"vocab_size": 32064
},
"search": {
"diversity_penalty": 0.0,
"do_sample": false,
"early_stopping": true,
"length_penalty": 1.0,
"max_length": 4096,
"min_length": 0,
"no_repeat_ngram_size": 0,
"num_beams": 1,
"num_return_sequences": 1,
"past_present_share_buffer": true,
"repetition_penalty": 1.0,
"temperature": 1.0,
"top_k": 1,
"top_p": 1.0
}
}
关键配置说明:
decoder.inputs/outputs: 定义模型的输入输出接口past_key_names/past_value_names: KV缓存配置,用于加速推理num_attention_heads: 注意力头数,影响模型性能search: 推理搜索参数,控制生成质量
2.2.6 转换质量验证
import onnxruntime as ort
import numpy as np
from transformers import AutoTokenizer, AutoModelForCausalLM
def validate_conversion(original_model_path, onnx_model_path, genai_config_path):
"""验证转换质量"""
# 加载原始模型
tokenizer = AutoTokenizer.from_pretrained(original_model_path)
model = AutoModelForCausalLM.from_pretrained(original_model_path)
# 加载ONNX模型
ort_session = ort.InferenceSession(onnx_model_path)
# 准备测试输入
test_text = "Hello, how are you?"
inputs = tokenizer(test_text, return_tensors="pt")
# 原始模型推理
with torch.no_grad():
original_output = model(**inputs)
original_logits = original_output.logits.numpy()
# ONNX模型推理
onnx_inputs = {
"input_ids": inputs["input_ids"].numpy(),
"attention_mask": inputs["attention_mask"].numpy()
}
onnx_output = ort_session.run(None, onnx_inputs)
onnx_logits = onnx_output[0]
# 计算差异
diff = np.abs(original_logits - onnx_logits)
max_diff = np.max(diff)
mean_diff = np.mean(diff)
print(f"转换验证结果:")
print(f" 最大差异: {max_diff:.6f}")
print(f" 平均差异: {mean_diff:.6f}")
print(f" 验证状态: {'通过' if max_diff < 1e-4 else '失败'}")
return max_diff < 1e-4
# 使用示例
validate_conversion(
"microsoft/Phi-3-mini-4k-instruct",
"./Phi-3-mini-4k-instruct-onnx/model.onnx",
"./Phi-3-mini-4k-instruct-onnx/genai_config.json"
)
2.2.7 性能优化技巧
1. 内存优化:
# 使用内存映射加载大模型
python -m onnxruntime_genai.models.builder \
-m large-model \
-o ./output \
-p int4 \
-e cpu \
--extra_options use_mmap=true
2. 并行处理:
# 启用多线程处理
python -m onnxruntime_genai.models.builder \
-m model-name \
-o ./output \
-p int4 \
-e cpu \
--extra_options num_threads=8
3. 缓存优化:
# 使用缓存目录加速重复转换
python -m onnxruntime_genai.models.builder \
-m model-name \
-o ./output \
-c ./cache \
-p int4 \
-e cpu
4. 减少内存
# 解决方案:使用量化减少内存占用
python -m onnxruntime_genai.models.builder \
-m large-model \
-o ./output \
-p int4 \
-e cpu \
--extra_options num_hidden_layers=8 # 减少层数
5. CUDA加速
# 解决方案:使用GPU加速
python -m onnxruntime_genai.models.builder \
-m model-name \
-o ./output \
-p fp16 \
-e cuda \
--extra_options use_gpu_optimization=true
6. 模型兼容性
# 解决方案:使用兼容模式
python -m onnxruntime_genai.models.builder \
-m model-name \
-o ./output \
-p fp32 \
-e cpu \
--extra_options compatibility_mode=true
2.3 SafeTensors到ONNX的转换方案
2.3.1 使用onnx-safetensors库进行转换
对于SafeTensors格式,我们可以使用专门的onnx-safetensors库来实现高效转换。这个库提供了在ONNX和SafeTensors之间互相转换的能力,支持所有ONNX数据类型,包括float8、float4等新型数据格式。
import onnx
import onnx_safetensors
from transformers import AutoModelForCausalLM
# 1. 加载SafeTensors格式的模型
model_path = "path/to/safetensors/model"
model = AutoModelForCausalLM.from_pretrained(model_path)
# 2. 导出为ONNX格式
dummy_input = torch.randn(1, 512, dtype=torch.long) # 示例输入
onnx_path = "model.onnx"
torch.onnx.export(
model,
dummy_input,
onnx_path,
input_names=["input_ids"],
output_names=["logits"],
dynamic_axes={
"input_ids": {0: "batch_size", 1: "sequence_length"},
"logits": {0: "batch_size", 1: "sequence_length"}
},
opset_version=17
)
# 3. 使用onnx-safetensors优化模型存储
base_dir = "path/to/output"
data_path = "model.safetensors"
# 将权重保存为SafeTensors格式,提高加载效率
model_with_external_data = onnx_safetensors.save_file(
onnx.load(onnx_path),
data_path,
base_dir=base_dir,
replace_data=True
)
# 保存优化后的模型
onnx.save(model_with_external_data, "optimized_model.onnx")
2.2.2 转换过程中的关键配置
在转换过程中,需要特别注意以下几个关键配置参数:
Opset版本选择:不同的目标平台对ONNX opset版本有不同要求。S100系统通常支持opset 17,而某些边缘设备可能只支持较低版本。
动态轴配置:对于语言模型,通常需要支持可变的batch size和sequence length,因此需要正确配置动态轴。
数据类型优化:根据目标硬件的特性,可以在转换时就指定合适的数据类型,为后续的量化过程做准备。
2.4 GGUF到ONNX的间接转换方案
由于直接转换GGUF到ONNX存在技术障碍,我们推荐采用间接转换的方式:
2.4.1 方案一:通过Hugging Face格式中转
# 1. 使用llama.cpp工具将GGUF转换为Hugging Face格式
python convert-hf-to-gguf.py --input model.gguf --output ./hf_model --reverse
# 2. 使用onnxruntime-genai转换为ONNX
python -m onnxruntime_genai.models.builder \
-i ./hf_model \
-o ./onnx_model \
-p fp32 \
-e cpu \
--extra_options attn_implementation=eager
2.4.2 方案二:使用原始模型重新导出
如果可以获得原始的模型文件,推荐直接从原始格式进行转换,避免多次格式转换带来的精度损失:
# 直接从原始模型导出ONNX
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "microsoft/Phi-3-mini-4k-instruct"
model = AutoModelForCausalLM.from_pretrained(
model_name,
_attn_implementation="eager"
)
# 配置导出参数
export_config = {
"opset_version": 17,
"input_names": ["input_ids", "attention_mask"],
"output_names": ["logits"],
"dynamic_axes": {
"input_ids": {0: "batch_size", 1: "sequence_length"},
"attention_mask": {0: "batch_size", 1: "sequence_length"},
"logits": {0: "batch_size", 1: "sequence_length"}
}
}
# 准备示例输入
dummy_input_ids = torch.tensor([[1, 2, 3, 4, 5]], dtype=torch.long)
dummy_attention_mask = torch.tensor([[1, 1, 1, 1, 1]], dtype=torch.long)
# 执行转换
torch.onnx.export(
model,
(dummy_input_ids, dummy_attention_mask),
"phi3_model.onnx",
**export_config
)
2.5 转换质量验证
转换完成后,验证模型的正确性是必不可少的步骤。我们需要比较原始模型和ONNX模型的输出,确保转换过程没有引入精度损失:
import onnxruntime as ort
import numpy as np
# 加载原始模型和ONNX模型
original_model = AutoModelForCausalLM.from_pretrained(model_path)
ort_session = ort.InferenceSession("model.onnx")
# 准备测试输入
test_input = torch.tensor([[1, 2, 3, 4, 5]], dtype=torch.long)
# 获取原始模型输出
with torch.no_grad():
original_output = original_model(test_input).logits
# 获取ONNX模型输出
ort_inputs = {"input_ids": test_input.numpy()}
onnx_output = ort_session.run(None, ort_inputs)[0]
# 计算差异
diff = np.abs(original_output.numpy() - onnx_output)
max_diff = np.max(diff)
mean_diff = np.mean(diff)
print(f"最大差异: {max_diff}")
print(f"平均差异: {mean_diff}")
# 通常认为差异小于1e-4是可接受的
if max_diff < 1e-4:
print("转换成功,精度在可接受范围内")
else:
print("转换可能存在问题,需要进一步检查")
3. 量化技术深度解析
量化技术是大模型部署中最关键的优化手段之一,它通过降低数值精度来减少模型大小、提高推理速度并降低内存占用。本节将深入分析量化技术的原理,重点讲解训练后量化(PTQ)和量化感知训练(QAT)的技术细节。
3.1 量化的数学基础
量化本质上是一个数值映射过程,将连续的高精度浮点数映射到离散的低精度数值空间。最常用的是线性量化(仿射量化),其核心公式为:
量化: Q = r o u n d ( R S + Z ) Q = round(\frac{R}{S}+Z) Q=round(SR+Z)
反量化: R = S × ( Q − Z ) R = S × (Q - Z) R=S×(Q−Z)
其中:
- R是原始浮点值
- Q是量化后的整数值
- S是缩放因子(Scale)
- Z是零点偏移(Zero Point)
3.2 精度格式对比分析
不同精度格式在存储效率和计算精度之间存在权衡关系:
FP32(32位浮点):标准的单精度浮点格式,提供最高精度但占用存储空间最大。一个10亿参数的模型需要约4GB存储空间。
FP16(16位半精度浮点):将存储需求减半,同时在大多数现代GPU上得到硬件加速支持。存储空间约为FP32的50%。
INT8(8位整数):将存储空间进一步压缩到FP32的25%,在CPU和专用AI芯片上有良好的硬件支持。
INT4(4位整数):极致压缩方案,存储空间仅为FP32的12.5%,适合极端资源受限的场景。
一句话总结:精度越低(如INT8/INT4),模型越小、带宽越省、吞吐越高;但越低位通常越“脆”,需要更精细的量化策略保精度。
3.2.1 视觉Transformer精度敏感点与掉点成因
- 注意力 Q/K/V 路径(核心):硬件上常走“左 int16 × 右 int8 → int32”的乘加流水线,通常让 K 在左、Q 在右。若 Q/K 的量化刻度(scale)或零点(zero-point)没对齐, Q ⋅ K T Q\cdot K^{T} Q⋅KT 会整体“缩水/偏移”,softmax 前的 logits 被压扁,概率就不准。
- 图像层更易掉点:图像特征分布“长尾”、尖峰多,且各个 head 差异大。若只做 per-tensor 量化、或 Q/K 精度不一致,细节容易被吃掉;建议权重 per-channel,Q/K 尽量用对称量化或保证刻度对齐。
- 前处理必须 100% 对齐:RGB/BGR 顺序、均值/方差、插值、裁剪/缩放任一处不一致,都会把激活分布整体平移或拉伸,量化统计就会跑偏 → 推理掉点。
一句话:先把“量纲”对齐(Q/K 的 scale/zero-point 与前处理分布),再谈量化;量纲不对齐,后面怎么调都费劲。
通俗说明:把Q看成“问题”,K看成“知识库”。两者的刻度(scale)要一致,原点(zero-point)最好是0;不然“单位不一样”,相乘得到的打分会被整体压缩或偏移,softmax做概率归一化时就容易失真。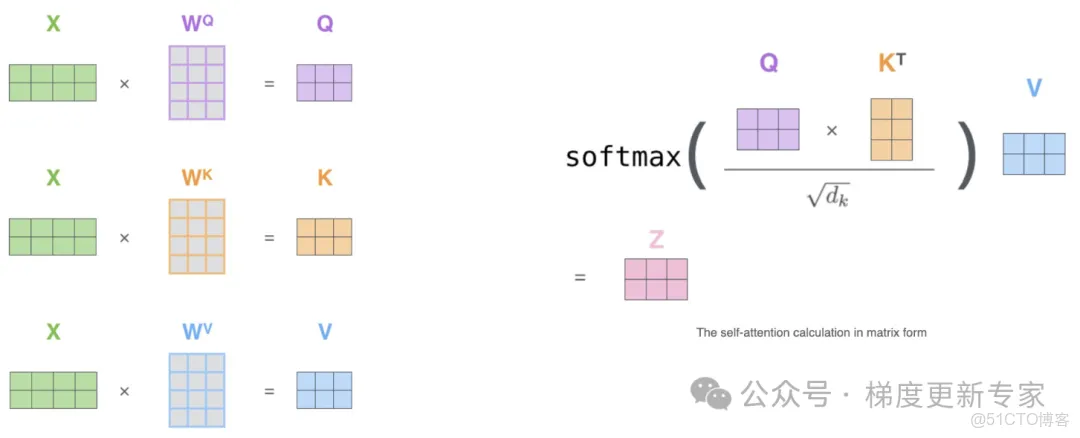
3.2.2 避免精度损失的工程清单
- 量化策略
- 做:权重优先用 per-channel;激活用 per-tensor+非对称。
理由:充分利用每个通道的动态范围,激活适配非对称分布,整体更稳。 - 做:Q/K 走对称量化或保证二者位宽/刻度一致;必要时分别统计 Q/K 的 scale/zero-point 并开 per-channel。
理由:减少 head/通道差异带来的失真,避免 Q ⋅ K T Q\cdot K^{T} Q⋅KT 被整体压缩/偏移。 - 做:把 softmax 前的 1 / d k 1/\sqrt{d_k} 1/dk 合并到 scale。
理由:少一次放大-再缩小的误差来源,数值链路更短更稳。
- 做:权重优先用 per-channel;激活用 per-tensor+非对称。
- 校准与数据
- 做:图像侧校准集中加入高对比、强纹理、强光照变化与多尺度样本,数量 50~200 更稳。
理由:覆盖“难样本”,统计到真实的长尾分布。 - 做:前处理与训练 100% 对齐(通道、均值/方差、插值、裁剪/缩放)。
理由:前处理一偏,量化统计就偏,后面全跟着错。
- 做:图像侧校准集中加入高对比、强纹理、强光照变化与多尺度样本,数量 50~200 更稳。
- 图优化与混合精度
- 做:固定 LN/Softmax/残差 Add 为 FP16/FP32,仅量化 QKV 投影、FFN 两层线性、Conv/MLP。
理由:把最敏感的归一化/残差留在高精度,既稳又省事。 - 做:必要时仅对“softmax 前线性/首层聚合模块”小范围 FP16 回退。
理由:精准回退,避免大面积牺牲吞吐。
- 做:固定 LN/Softmax/残差 Add 为 FP16/FP32,仅量化 QKV 投影、FFN 两层线性、Conv/MLP。
先修“分布”和“刻度”,最后才考虑小范围 FP16 回退;能不回退就不回退。
3.2.3 S100推荐量化模板(片段)
calibration:
calibration_type: default # 或 mix/kl
per_channel: true
quantization:
quantize_method: kld
optimization:
asymmetric: true
bias_correction: true
node_info:
- node_type: Linear
scope:
- ".*attention.q_proj.*"
- ".*attention.k_proj.*"
per_channel: true
keep_dtype: fp16 # 如掉点严重可临时回退
3.2.4 Attention专项实操检查清单
- Q/K前处理与归一化一致:确保训练与部署的颜色空间、均值/方差、插值、裁剪完全对齐。
- 量化配置:
Q/K权重per-channel,激活per-tensor;对Q/K尽量使用对称量化(Z=0)。 - 乘法路径:核实
MatMul左右操作数的位宽绑定关系;避免图优化将左右交换。 - 缩放项处理:将
1/sqrt(d_k)合入scale;softmax/LN保持FP16优先。 - 敏感层回退:必要时仅回退softmax前线性或第一层融合模块为FP16。
- 校准集:图像侧覆盖高对比、纹理密集、光照变化、多尺度;样本50~200更稳。
3.2.5 可视化与统计(辅助定位掉点)
# 统计softmax前logits分布与KL散度(按head)
import torch, numpy as np
def collect_logits(model, dataloader, hook_name="attn_scores_pre_softmax"):
stats = []
handle = None
def hook(module, inp, out):
x = out.detach().float().cpu().numpy()
# x: [B, heads, Lq, Lk]
stats.append(x)
# 注册hook(需按实际模型定位模块)
target = dict(model.named_modules())[hook_name]
handle = target.register_forward_hook(lambda m,i,o: hook(m,i,o))
model.eval()
with torch.no_grad():
for batch in dataloader:
_ = model(**batch)
handle.remove()
arr = np.concatenate(stats, axis=0)
# 计算每个head的均值/方差/极值与分位数
head_axis = 1
mean = arr.mean(axis=(0,2,3))
std = arr.std(axis=(0,2,3))
p99 = np.quantile(arr, 0.99, axis=(0,2,3))
return dict(mean=mean, std=std, p99=p99)
将浮点与量化模型的上述统计对比,若出现“方差显著减小/均值显著偏移/分位数被截断”,多半是Q/K缩放不匹配或过度裁剪导致的logits压缩。
3.2.6 Attention精度调优决策树与排障清单
决策树(示意):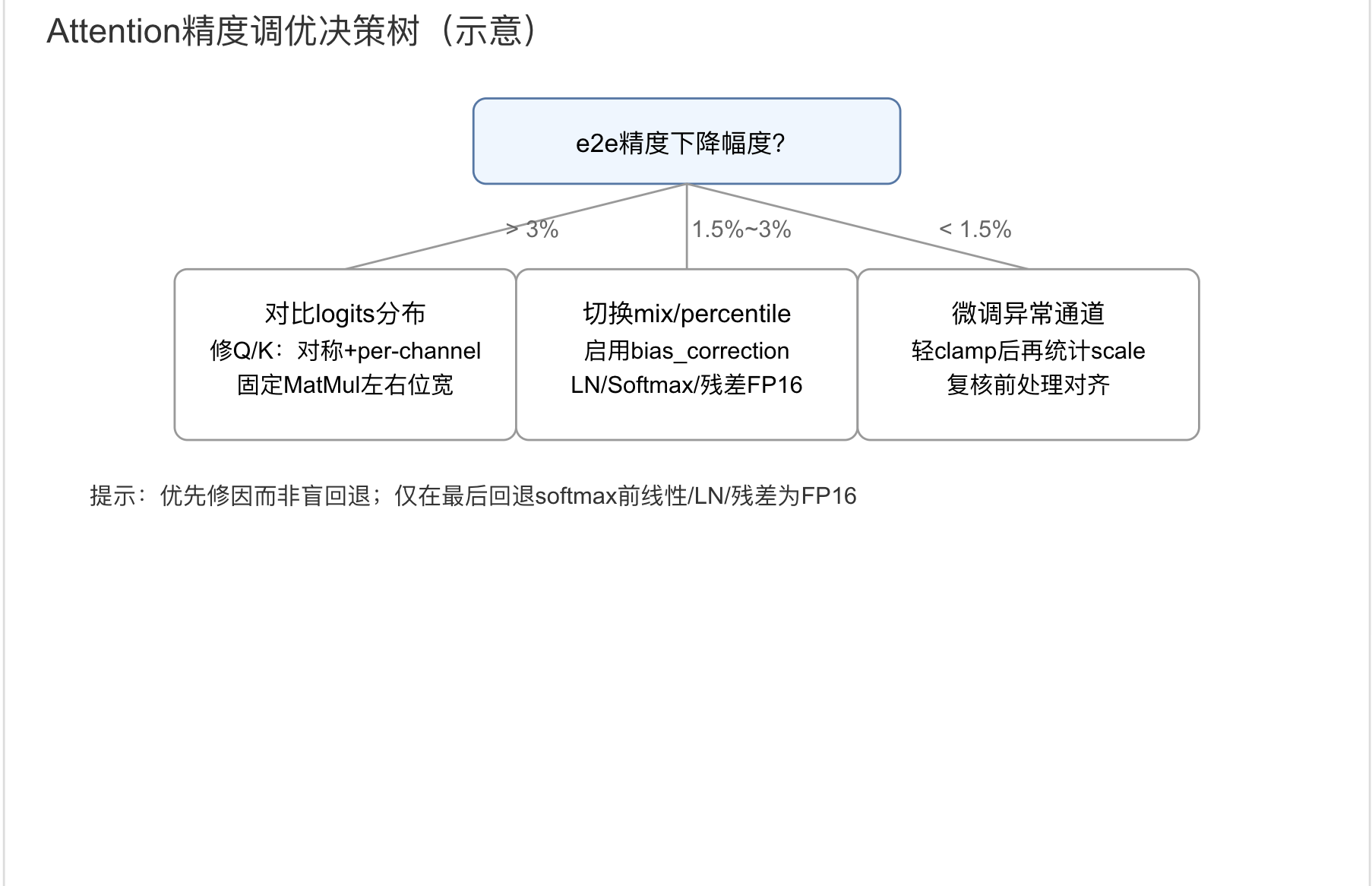
- 若e2e精度下降>3%:
- 对比浮点/量化的softmax前logits分布(均值/方差/分位数);若压缩明显→ 优先处理Q/K路径(对称量化、per-channel、合并
sqrt(d_k))。 - 检查图优化是否交换了
MatMul左右;必要时强制K在左、Q在右。 - 校准集是否覆盖高对比/纹理/光照/多尺度;样本量不足时增至50~200。
- 对比浮点/量化的softmax前logits分布(均值/方差/分位数);若压缩明显→ 优先处理Q/K路径(对称量化、per-channel、合并
- 若下降1.5%~3%:
- 量化方法从
max/kl切换为mix或调percentile(0.99999~0.999)并选择最优。 - 打开
bias_correction与asymmetric,比较节点余弦相似度曲线。 - 将LN/Softmax/残差Add固定为FP16;必要时仅回退softmax前一层线性为FP16。
- 量化方法从
- 若下降<1.5%但仍不达标:
- 对个别异常head/通道做轻微clamp后再统计scale;或提升这些通道的量化位宽(如INT8→INT16,仅限支持的工具链)。
- 复核前处理对齐:通道顺序、均值/方差、插值、裁剪必须与训练一致。
排障清单(最小化回退,优先修因):
- 确认
Q/K均启用per-channel权重量化;激活per-tensor,softmax前尽量Z=0。 - 确认
sqrt(d_k)被吸收入scale,避免重复缩放。 - 确认图优化未打乱
MatMul左右与位宽绑定;必要时以Gemm/Transpose固化。 - 仅在最后一步才回退若干敏感层为FP16,避免过度牺牲性能。
3.3 对称量化与非对称量化
量化方法根据零点的取值可以分为两种主要类型:
3.3.1 对称量化
对称量化强制零点Z=0,将对称的浮点范围[-α, α]映射到整数范围[-2^(n-1)+1, 2^(n-1)-1]。
def symmetric_quantization(tensor, bits=8):
"""对称量化实现"""
# 计算量化范围
q_max = 2**(bits - 1) - 1
q_min = -q_max
# 计算缩放因子
scale = torch.max(torch.abs(tensor)) / q_max
# 执行量化
quantized = torch.round(tensor / scale)
quantized = torch.clamp(quantized, q_min, q_max)
return quantized, scale, 0 # 零点为0
优势:计算简单,硬件实现效率高,无需零点运算。
劣势:对于非对称分布的数据(如ReLU激活后的值),会浪费量化范围。
3.3.2 非对称量化
非对称量化允许零点Z取非零值,可以将任意浮点范围[α, β]映射到完整的整数范围。
def asymmetric_quantization(tensor, bits=8):
"""非对称量化实现"""
# 计算量化范围
q_max = 2**bits - 1
q_min = 0
# 计算实际数值范围
r_min = torch.min(tensor)
r_max = torch.max(tensor)
# 计算缩放因子和零点
scale = (r_max - r_min) / (q_max - q_min)
zero_point = q_min - r_min / scale
zero_point = torch.round(torch.clamp(zero_point, q_min, q_max))
# 执行量化
quantized = torch.round(tensor / scale + zero_point)
quantized = torch.clamp(quantized, q_min, q_max)
return quantized, scale, zero_point
优势:充分利用量化空间,精度更高,特别适合非对称分布。
劣势:计算复杂度略高,需要额外的零点运算。
3.4 量化粒度策略
量化的粒度决定了量化参数的共享范围,直接影响量化精度和计算效率:
3.4.1 张量级量化(Per-Tensor)
整个张量共享一组量化参数,实现简单但可能损失精度。
def per_tensor_quantization(tensor, bits=8):
"""张量级量化"""
# 全局统计信息
tensor_min = tensor.min()
tensor_max = tensor.max()
# 计算全局量化参数
scale = (tensor_max - tensor_min) / (2**bits - 1)
zero_point = -tensor_min / scale
return quantize_with_params(tensor, scale, zero_point, bits)
3.4.2 通道级量化(Per-Channel)
每个输出通道使用独立的量化参数,在保持硬件友好性的同时提高精度。
def per_channel_quantization(tensor, bits=8, axis=0):
"""通道级量化"""
# 沿指定轴计算统计信息
tensor_min = tensor.min(dim=axis, keepdim=True)[0]
tensor_max = tensor.max(dim=axis, keepdim=True)[0]
# 计算每通道量化参数
scale = (tensor_max - tensor_min) / (2**bits - 1)
zero_point = -tensor_min / scale
return quantize_with_params(tensor, scale, zero_point, bits)
3.4.3 分组级量化(Group-wise)
将张量分成若干组,每组使用独立的量化参数,提供精度和效率的平衡。
3.5 训练后量化(PTQ)详解
PTQ是在模型训练完成后直接对预训练模型进行量化的方法,具有实现简单、成本低的优势。
3.5.1 PTQ的基本流程
# 目标:展示一个线性层为主的小模型如何完成PTQ(采样校准 → 统计量 → 量化 → 验证)
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import DataLoader, TensorDataset
import numpy as np
class TinyMLP(nn.Module):
def __init__(self, in_dim: int = 128, hidden: int = 64, out_dim: int = 10):
super().__init__()
self.fc1 = nn.Linear(in_dim, hidden)
self.fc2 = nn.Linear(hidden, out_dim)
def forward(self, x: torch.Tensor) -> torch.Tensor:
x = self.fc1(x)
x = F.relu(x)
x = self.fc2(x)
return x
def percentile_min_max(x: torch.Tensor, p: float = 0.9995):
# 用分位数抑制极端异常值,适合实战
x = x.detach().float().flatten()
lo = torch.quantile(x, 1 - p)
hi = torch.quantile(x, p)
return lo.item(), hi.item()
def compute_affine_params(x: torch.Tensor, bits: int = 8, p: float = 0.9995):
qmin, qmax = 0, 2 ** bits - 1
rmin, rmax = percentile_min_max(x, p)
# 保障数值稳定
if rmax <= rmin:
rmax = rmin + 1e-6
scale = (rmax - rmin) / (qmax - qmin)
zero_point = round(qmin - rmin / scale)
zero_point = int(min(max(zero_point, qmin), qmax))
return float(scale), int(zero_point)
def quantize_dequantize(x: torch.Tensor, scale: float, zp: int, bits: int = 8) -> torch.Tensor:
qmin, qmax = 0, 2 ** bits - 1
q = torch.round(x / scale + zp).clamp(qmin, qmax)
dq = (q - zp) * scale
return dq
def per_channel_weight_quantize(w: torch.Tensor, bits: int = 8, dim: int = 0):
# 每个输出通道独立量化(更稳)
scales, zps = [], []
w_q = torch.zeros_like(w)
for c in range(w.size(dim)):
idx = [slice(None)] * w.dim()
idx[dim] = c
w_c = w[tuple(idx)]
scale, zp = compute_affine_params(w_c, bits)
w_q[tuple(idx)] = quantize_dequantize(w_c, scale, zp, bits)
scales.append(scale)
zps.append(zp)
return w_q, np.array(scales), np.array(zps)
@torch.no_grad()
def ptq_minimal_demo():
torch.manual_seed(0)
# 1) 构造“校准/评测”数据(真实项目换成你的样本)
cali_x = torch.randn(256, 128)
test_x = torch.randn(256, 128)
test_y = torch.randint(0, 10, (256,))
model = TinyMLP()
model.eval()
# 2) 收集激活统计(只需前向)
activations_fc1 = []
def hook_fc1(m, i, o):
activations_fc1.append(o.detach())
h = model.fc1.register_forward_hook(hook_fc1)
_ = model(cali_x)
h.remove()
# 3) 计算激活量化参数(per-tensor + 非对称)
act_cat = torch.cat(activations_fc1, dim=0)
act_scale, act_zp = compute_affine_params(act_cat, bits=8, p=0.9995)
# 4) 权重量化(per-channel)
w1_q, w1_scales, w1_zps = per_channel_weight_quantize(model.fc1.weight, bits=8, dim=0)
b1 = model.fc1.bias
w2_q, w2_scales, w2_zps = per_channel_weight_quantize(model.fc2.weight, bits=8, dim=0)
b2 = model.fc2.bias
# 5) 构造“量化后”的前向(简化版:权重/激活都做量化-反量化)
def forward_quantized(x: torch.Tensor) -> torch.Tensor:
# fc1
x_q = quantize_dequantize(x, act_scale, act_zp, 8)
x1 = F.linear(x_q, w1_q, b1)
x1 = F.relu(x1)
# fc2(演示起见,复用同样的激活参数;实战建议分别统计)
x2 = F.linear(x1, w2_q, b2)
return x2
# 6) 简单对比精度(分类top1)与数值误差
with torch.no_grad():
logits_fp = model(test_x)
logits_q = forward_quantized(test_x)
top1_fp = (logits_fp.argmax(dim=1) == test_y).float().mean().item()
top1_q = (logits_q.argmax(dim=1) == test_y).float().mean().item()
mse = F.mse_loss(logits_q, logits_fp).item()
print(f"Top1 FP32={top1_fp:.3f}, PTQ={top1_q:.3f}, MSE={mse:.6f}")
ptq_minimal_demo()
要点回顾:
- 激活:per-tensor + 非对称(适配偏移分布);权重:per-channel(适配通道差异)。
- 统计分位数(percentile)抑制极端值;图像/注意力侧更稳。
- 实战中请分层/分点统计激活参数,而不是复用同一组。
3.5.2 校准数据的重要性
校准数据的质量直接影响PTQ的效果。理想的校准数据应该:
代表性强:涵盖模型在实际使用中可能遇到的各种输入模式。
数量适中:通常100-1000个样本就足够,过多可能导致计算开销增大。
分布均衡:避免某些模式的数据占主导地位,影响量化参数的准确性。
3.6 量化感知训练(QAT)详解
QAT在训练过程中模拟量化的影响,让模型主动适应量化带来的精度损失。
3.6.1 QAT的实现原理
QAT的核心是在前向传播中插入伪量化节点:
# 目标:在训练中“带着量化噪声”学,让模型自己适应量化
import torch
import torch.nn as nn
import torch.nn.functional as F
class FakeQuant(nn.Module):
def __init__(self, bits=8, symmetric=True, momentum=0.1):
super().__init__()
self.bits = bits; self.symmetric = symmetric; self.momentum = momentum
self.register_buffer('amin', torch.tensor(0.)); self.register_buffer('amax', torch.tensor(0.))
def forward(self, x):
if self.training and not self.symmetric:
cur_min, cur_max = x.min(), x.max()
self.amin = self.momentum*cur_min + (1-self.momentum)*self.amin
self.amax = self.momentum*cur_max + (1-self.momentum)*self.amax
xmin, xmax = self.amin, self.amax
qmin, qmax = 0, 2**self.bits-1
scale = (xmax-xmin)/(qmax-qmin+1e-12); zp = torch.clamp(torch.round(-xmin/scale), qmin, qmax)
q = torch.clamp(torch.round(x/scale+zp), qmin, qmax)
return scale*(q-zp)
else:
qmax = 2**(self.bits-1)-1
scale = x.abs().max()/(qmax+1e-12)
q = torch.clamp(torch.round(x/scale), -qmax, qmax)
return q*scale
class QATMLP(nn.Module):
def __init__(self, in_dim=128, hidden=64, out_dim=10):
super().__init__()
self.fc1 = nn.Linear(in_dim, hidden)
self.act_q = FakeQuant(bits=8, symmetric=False)
self.fc2 = nn.Linear(hidden, out_dim)
self.wq1 = FakeQuant(bits=8, symmetric=True)
self.wq2 = FakeQuant(bits=8, symmetric=True)
def forward(self, x):
# 权重前做一次“伪量化”模拟
w1 = self.wq1(self.fc1.weight); b1 = self.fc1.bias
x = F.linear(x, w1, b1)
x = self.act_q(F.gelu(x))
w2 = self.wq2(self.fc2.weight); b2 = self.fc2.bias
return F.linear(x, w2, b2)
# 训练:让网络在“量化扰动”下收敛
model = QATMLP(); opt = torch.optim.AdamW(model.parameters(), lr=1e-3)
for step in range(200):
x = torch.randn(32, 128); y = torch.randint(0, 10, (32,))
logits = model(x)
loss = F.cross_entropy(logits, y)
opt.zero_grad(); loss.backward(); opt.step()
print('QAT done, last loss:', loss.item())
3.6.2 QAT的训练策略
def quantization_aware_training(model, train_loader, val_loader, epochs=10):
"""量化感知训练"""
# 1. 为模型添加伪量化节点
quantized_model = prepare_qat_model(model)
# 2. 设置优化器(通常使用较小的学习率)
optimizer = torch.optim.AdamW(quantized_model.parameters(), lr=1e-5)
# 3. 训练循环
for epoch in range(epochs):
quantized_model.train()
for batch_idx, (data, target) in enumerate(train_loader):
optimizer.zero_grad()
output = quantized_model(data)
loss = F.cross_entropy(output, target)
loss.backward()
optimizer.step()
# 验证性能
val_accuracy = validate(quantized_model, val_loader)
print(f'Epoch {epoch}, Validation Accuracy: {val_accuracy:.4f}')
# 4. 转换为真实量化模型
final_model = convert_to_quantized(quantized_model)
return final_model
3.7 PTQ与QAT的选择指南
选择PTQ还是QAT需要考虑多个因素:
计算资源:PTQ只需要几个小时的校准时间,而QAT可能需要数天的重新训练。
精度要求:QAT通常能获得更高的精度,特别是在极低比特量化时。
模型类型:对于某些预训练模型,PTQ已经能够获得足够好的效果。
部署时间:如果需要快速部署,PTQ是更好的选择。
3.8 高级量化技术
…详情请参照古月居

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 3
3 0
0- 0



 已为社区贡献30条内容
已为社区贡献30条内容

所有评论(0)