YOLO深度学习(计算机视觉)—毕设笔记2(项目结构+数据准备)
本文介绍了YOLO目标检测项目的数据准备流程,主要包括: 文件结构搭建:提供标准数据集文件夹结构模板,可根据项目需求调整; 数据获取与处理:推荐多个公开数据集来源(Kaggle、Robflow等),并说明图片批量重命名方法; 数据标注工具:详细对比labelimg、label-studio和makesense三款工具的使用方法,重点推荐label-studio; 数据处理脚本:提供多个实用Pyth
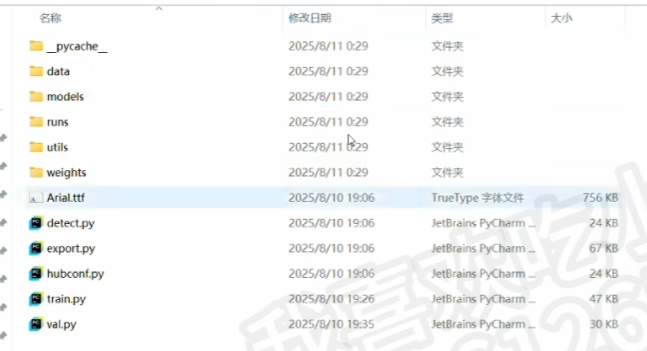
一、大致文件结构
关于YOLO目标检测的项目(上一篇有介绍什么是YOLO目标检测),直接复制这个文件结构就行了
1、DataSet数据集文件夹
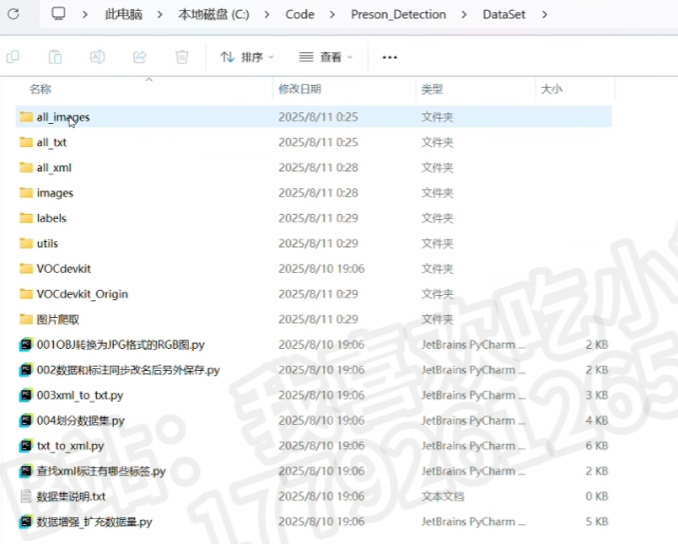
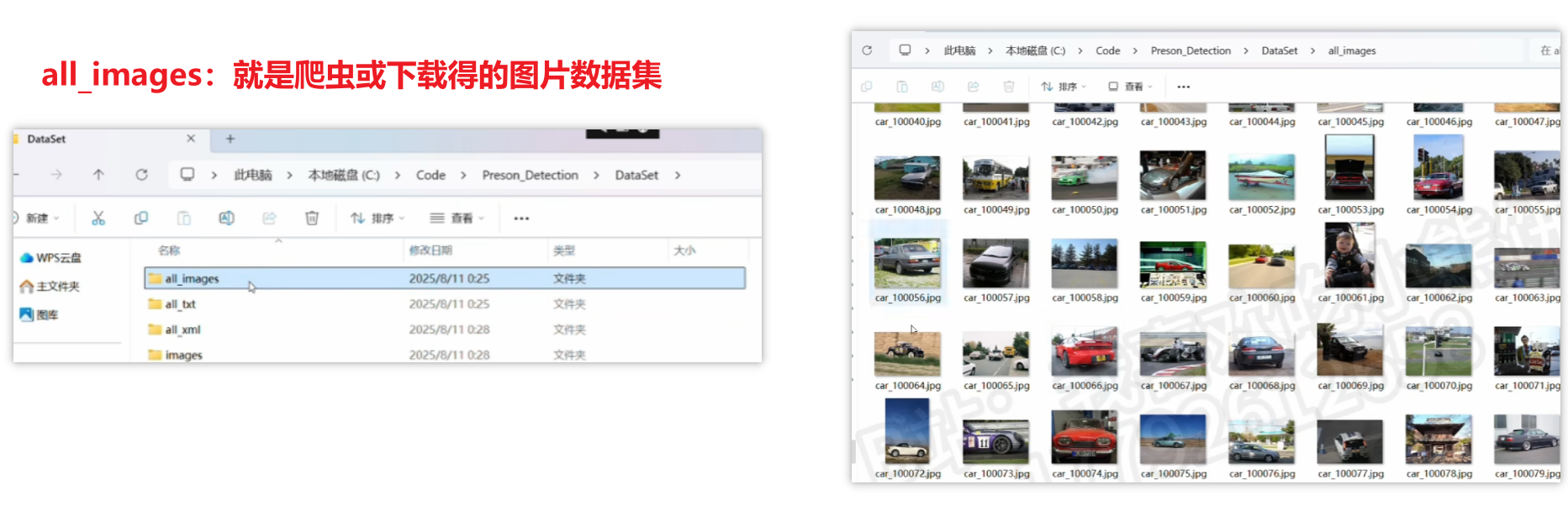
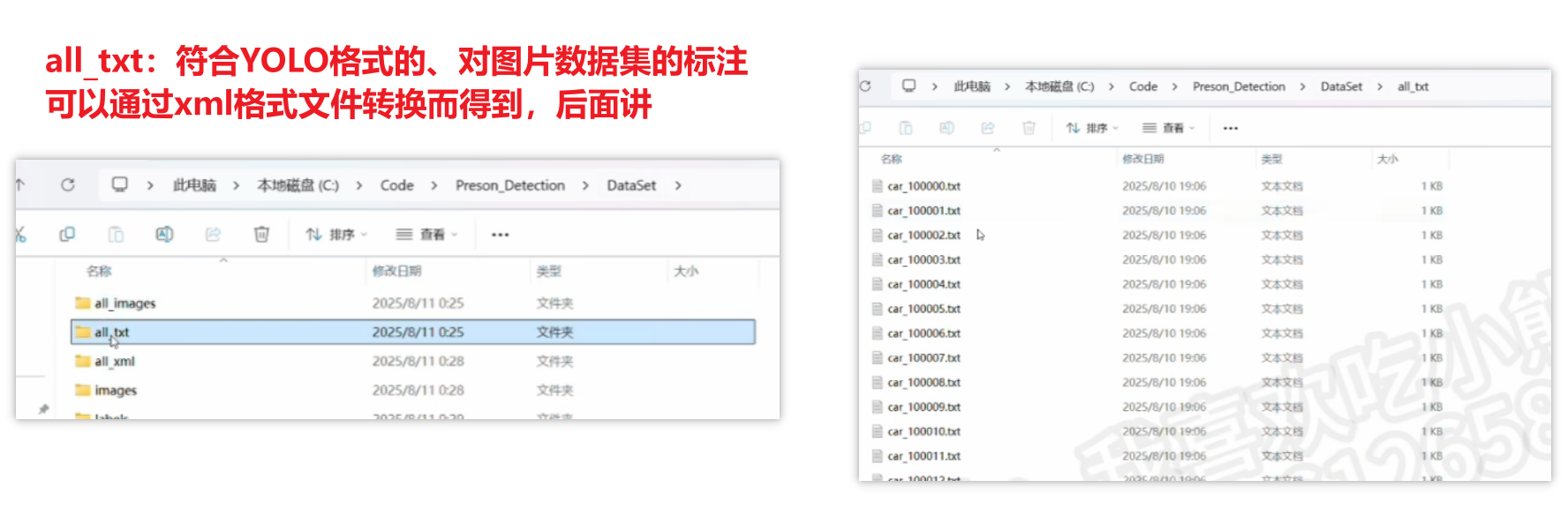
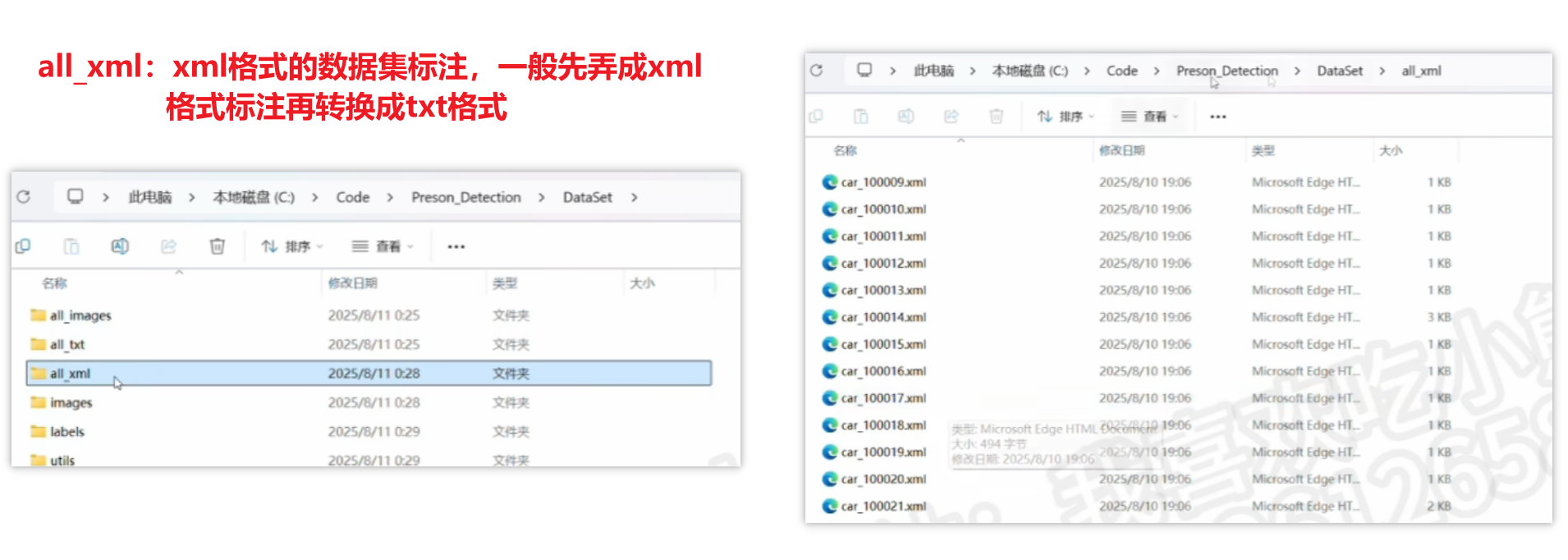
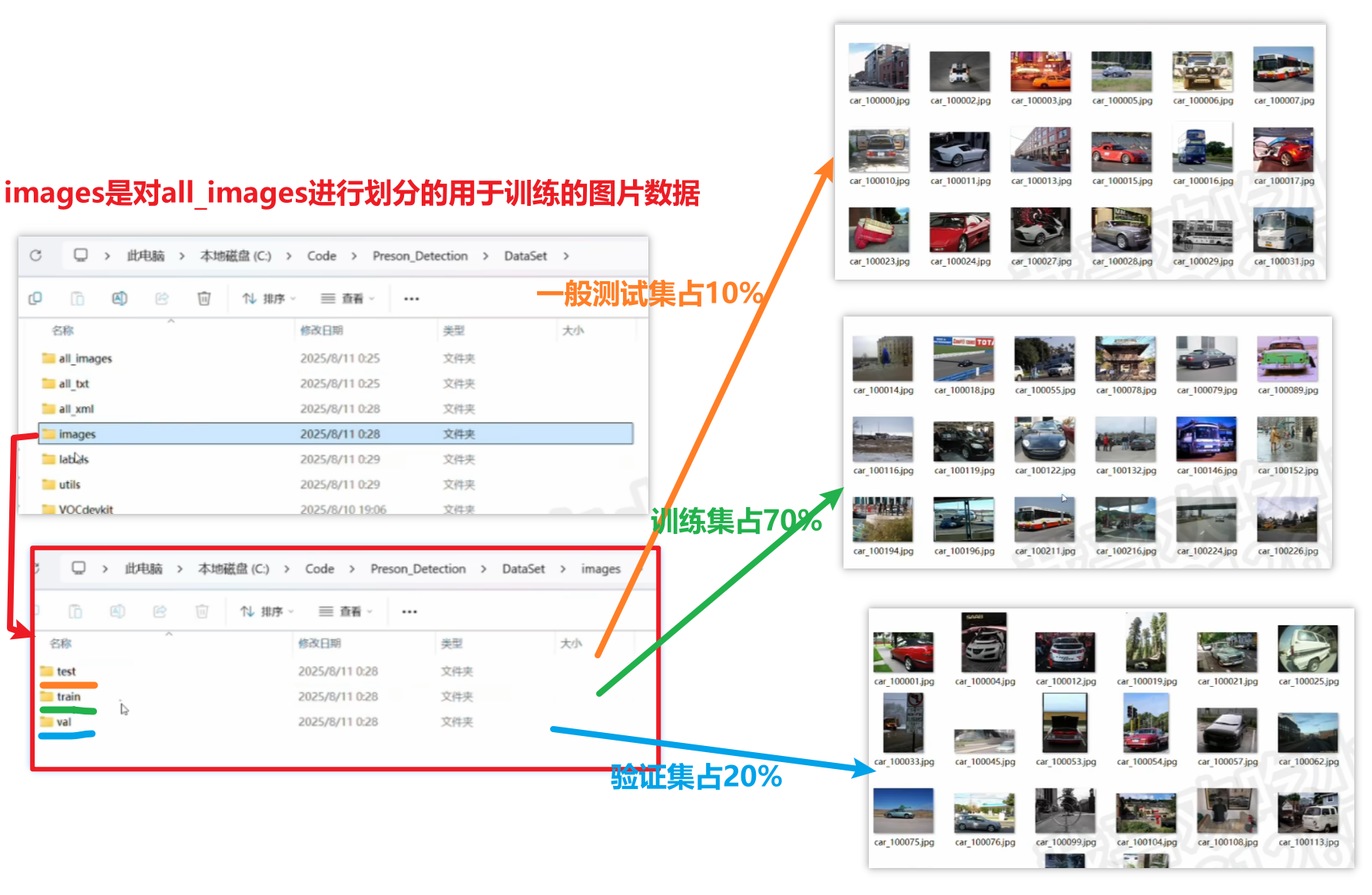
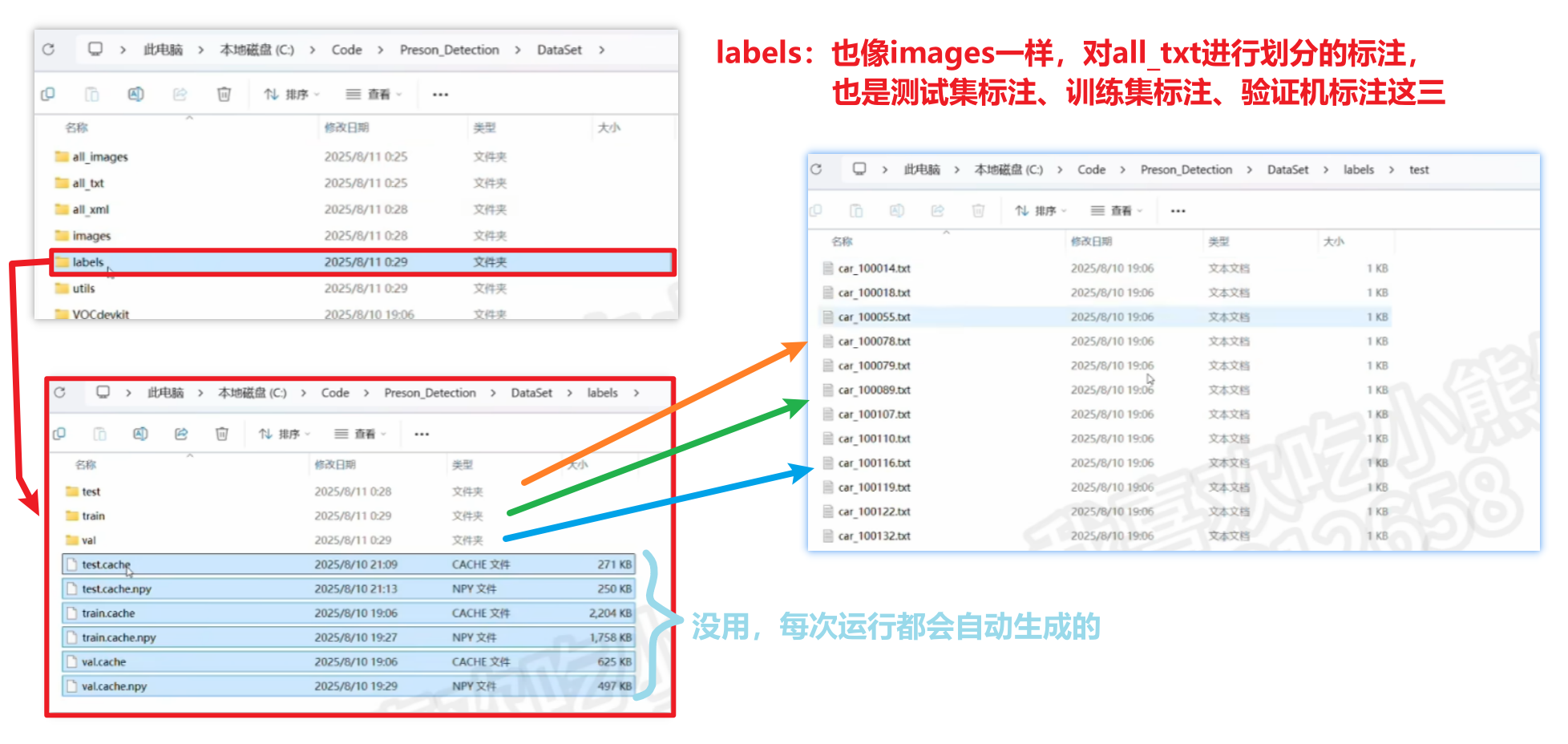
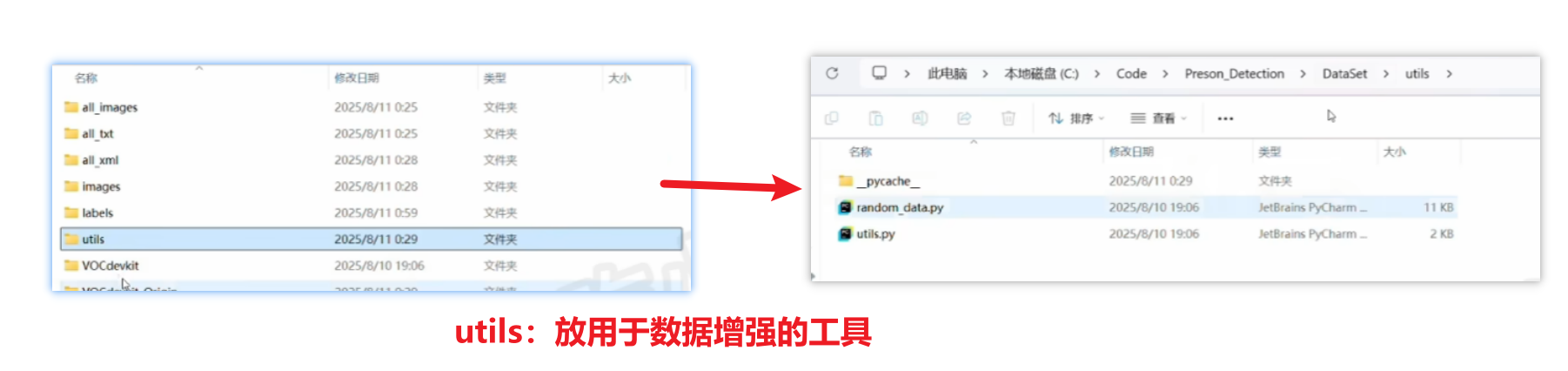
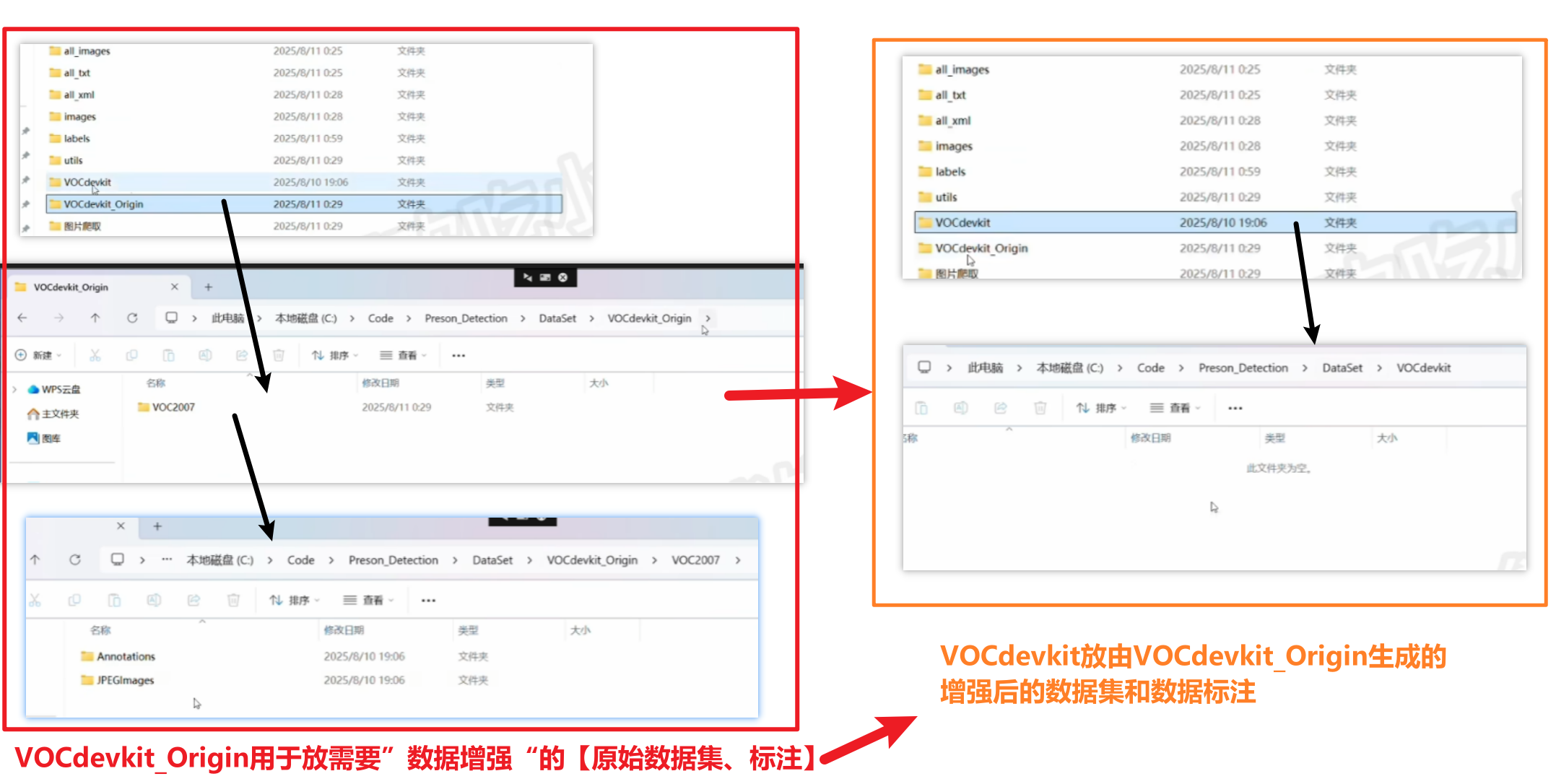

当然这个结构只是标准通用的,并非定死了
比如最基础的这种简单的结构(图片和数据标注都不要验证集、不要xml格式的标注,并直接把all_images分类整理好后删掉all_images),也是一样可以满足训练的基本要求的
(初学者可以先按下面这个格式来也行,注意icon是这个项目的名字,你如果项目是检测花朵,icon就可以自己换成flower就行或者换成fuckyou都行,一个意思)


2、模型文件夹
模型的大致文件结构是这样的
具体怎么用,文件怎么写,暂时不用管,后面会详细说
二、数据准备
1、图像数据集获取
其中,图片可以自己爬虫,也可以去相关网站获取:
- 飞桨AI:https://aistudio.baidu.com/datasetoverview
- Kaggle:https://www.kaggle.com/
- modelscope:https://www.modelscope.cn/datasets
- hugging face:https://huggingface.co/datasets
- Robflow:https://universe.roboflow.com/
- Obeject Detection:https://public.roboflow.com/object-detection
- 另外我们下载的ultralytics本身就有本地数据集,可以去了解一下在这个路径
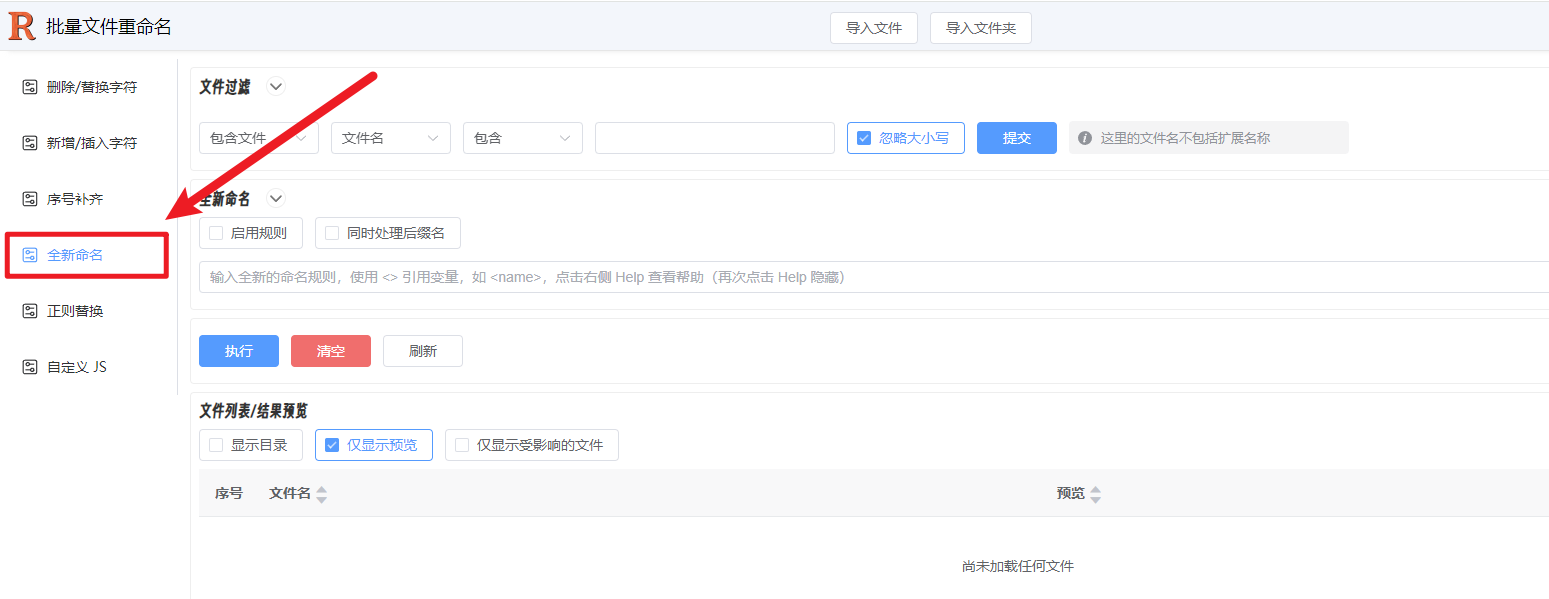
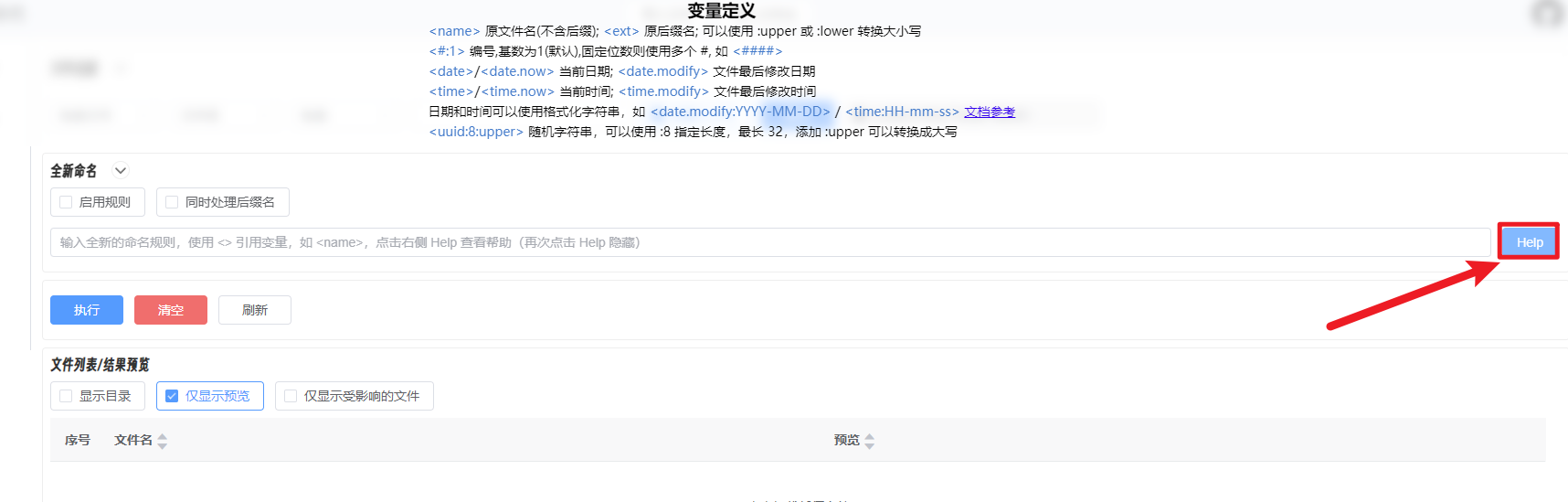
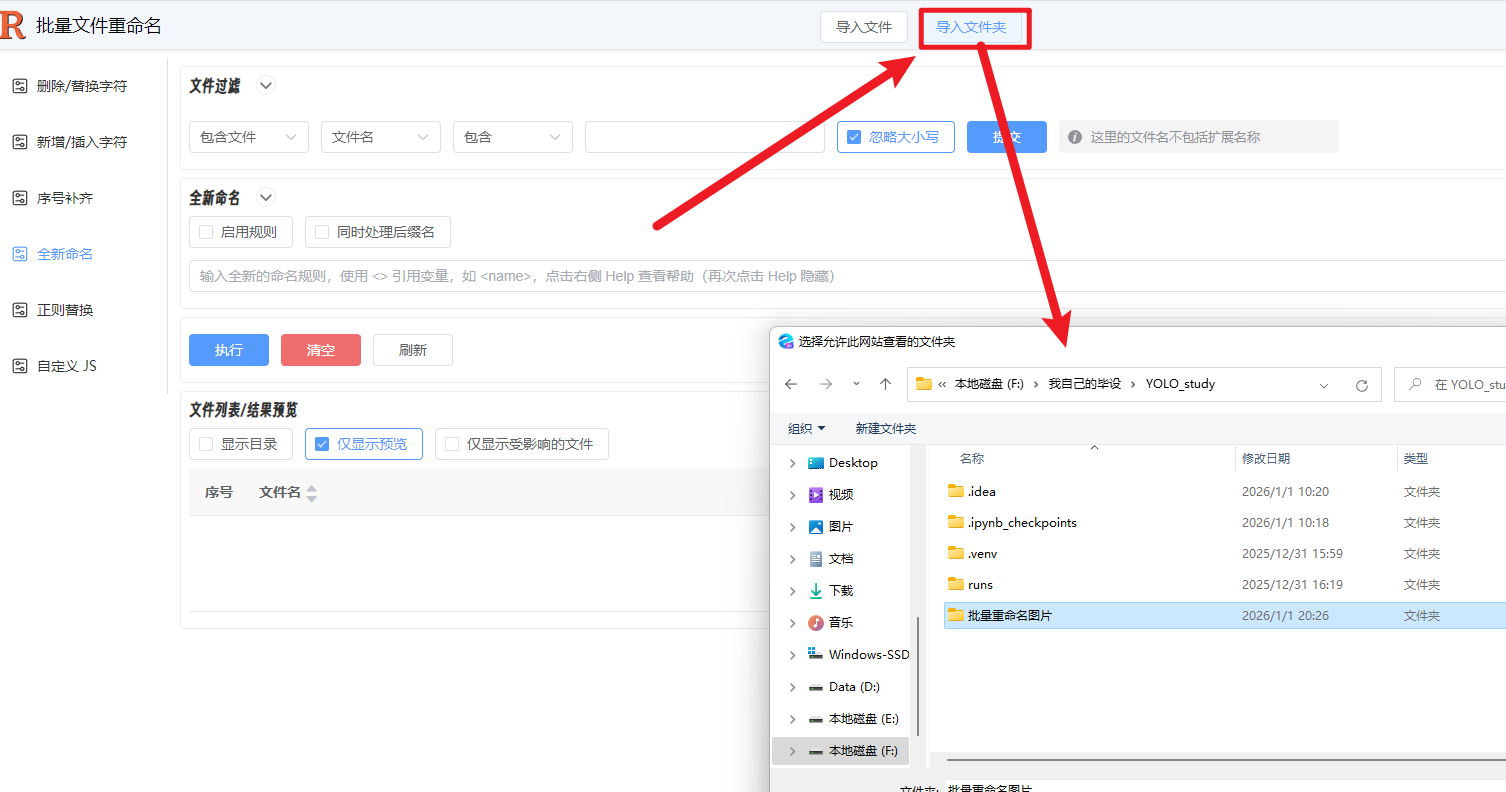
那么获取到的图片我们也不能就不管了,需要批量改他们的文件名好方便yolo模型识别,整理,那就可以到这个网站来批量处理:https://rename.jgrass.xyz/
点一下Help会提示你怎么批量操作
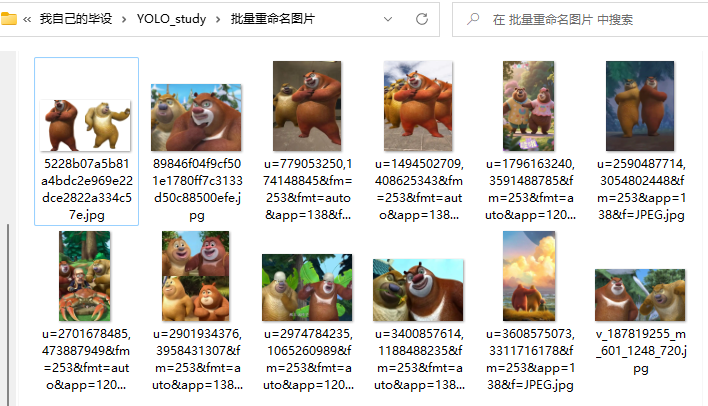
大比分现在我下载了一堆熊大熊二的图片,现在我要该他们的名
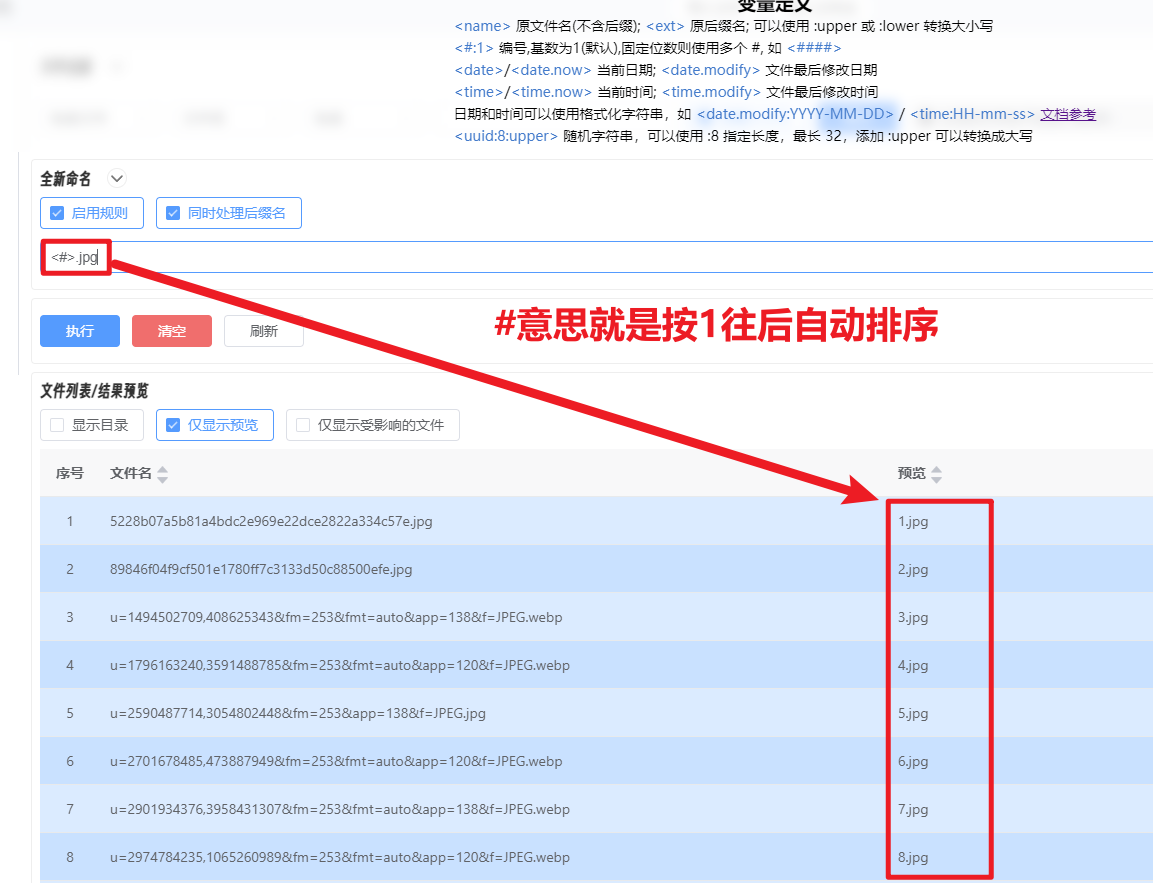
如果图片是jpg、png格式就不用改后缀,如果像我这很多是webp格式的就要连后缀名也改了
搞定,如果要改的名字复杂一点,可以自行AI查一下
2、数据标注
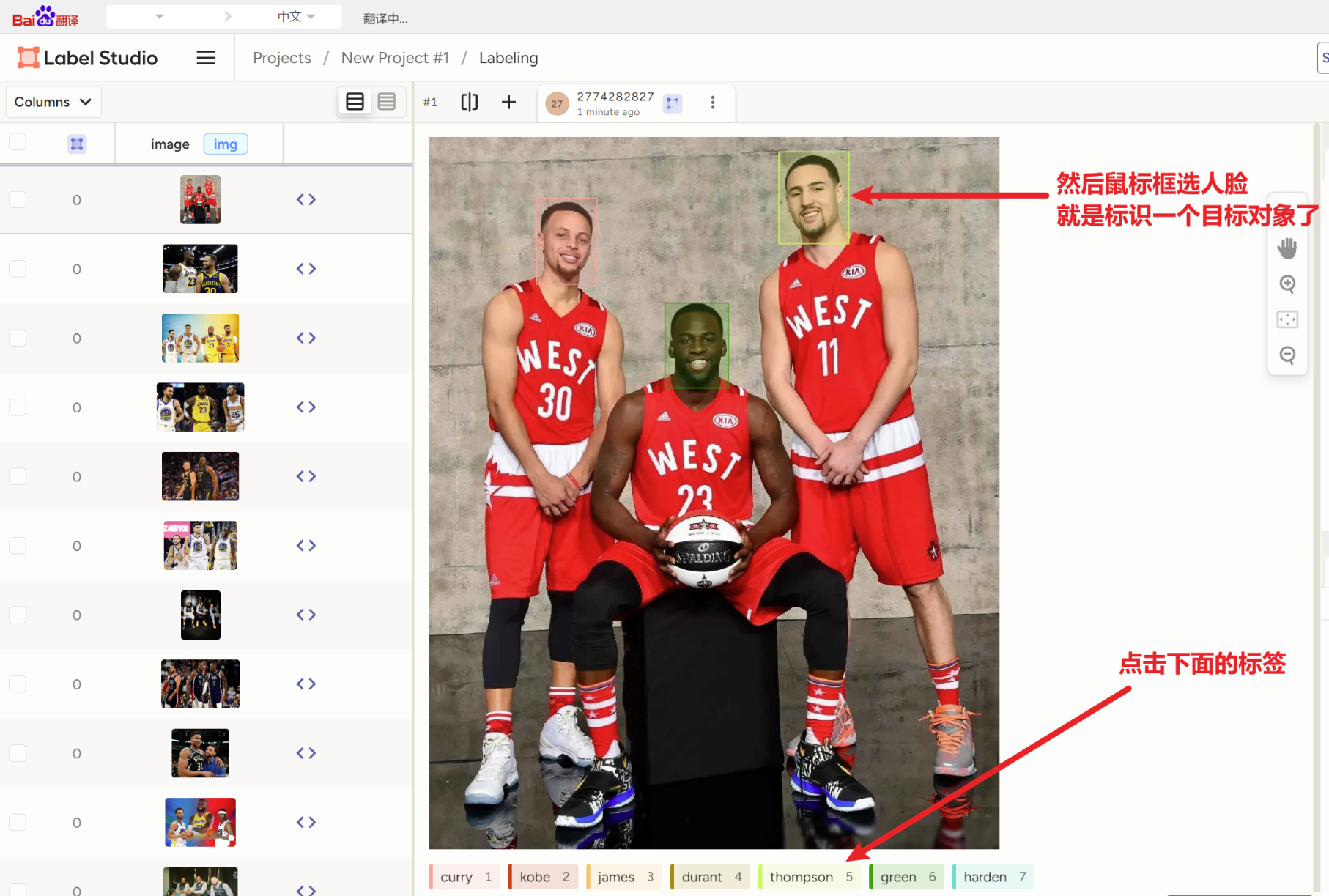
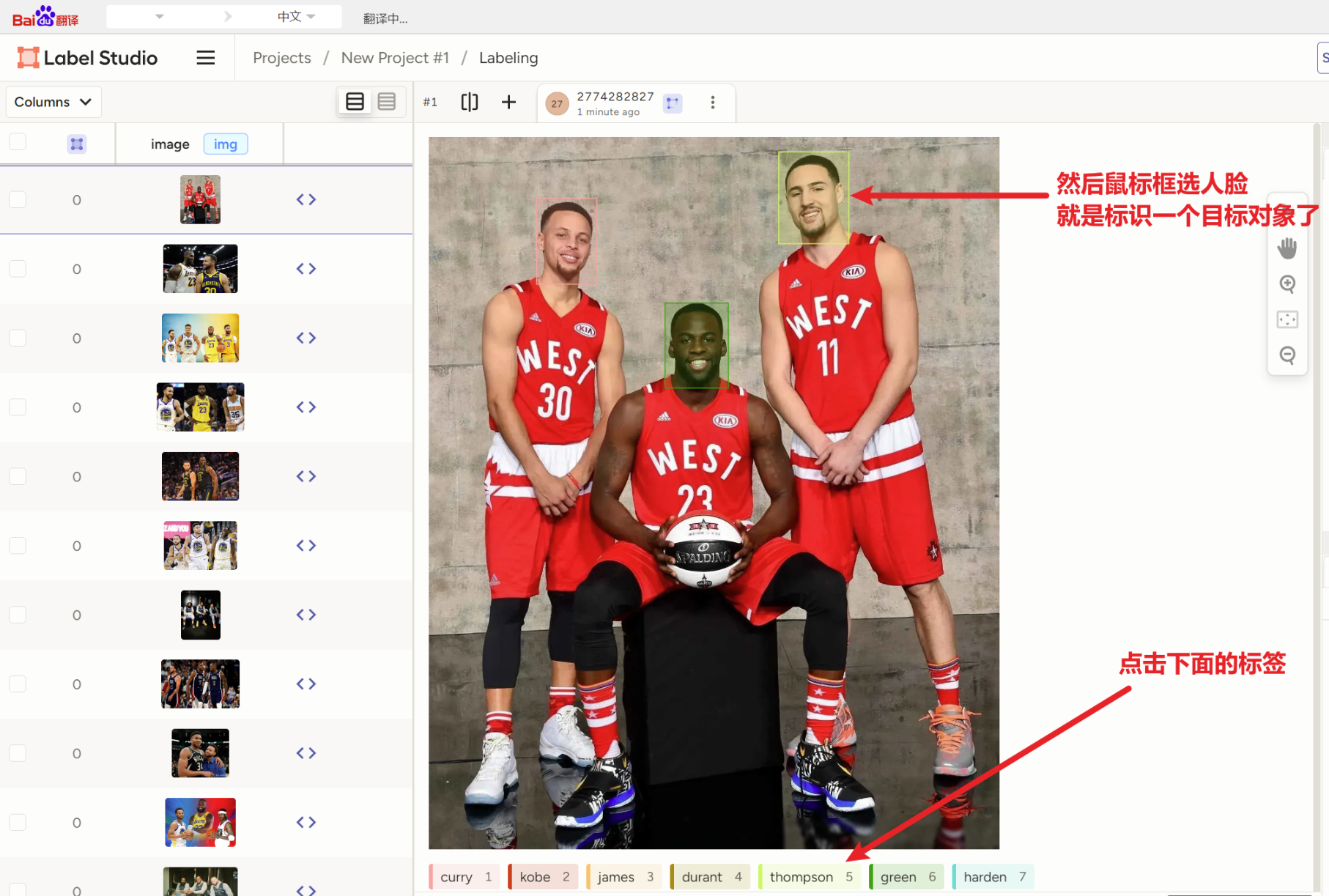
而对数据标注是个大工程,对应每一个图片来一个一个手动敲字不可能,要用到2个工具【labelimg】或【label-studio】
1)【labelimg(不推荐)】
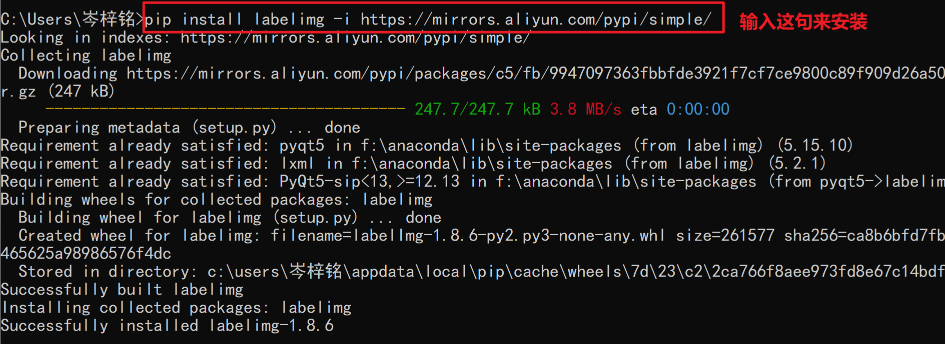
1、cmd或者用编译器,打开“黑窗口”,输入下面命令安装它
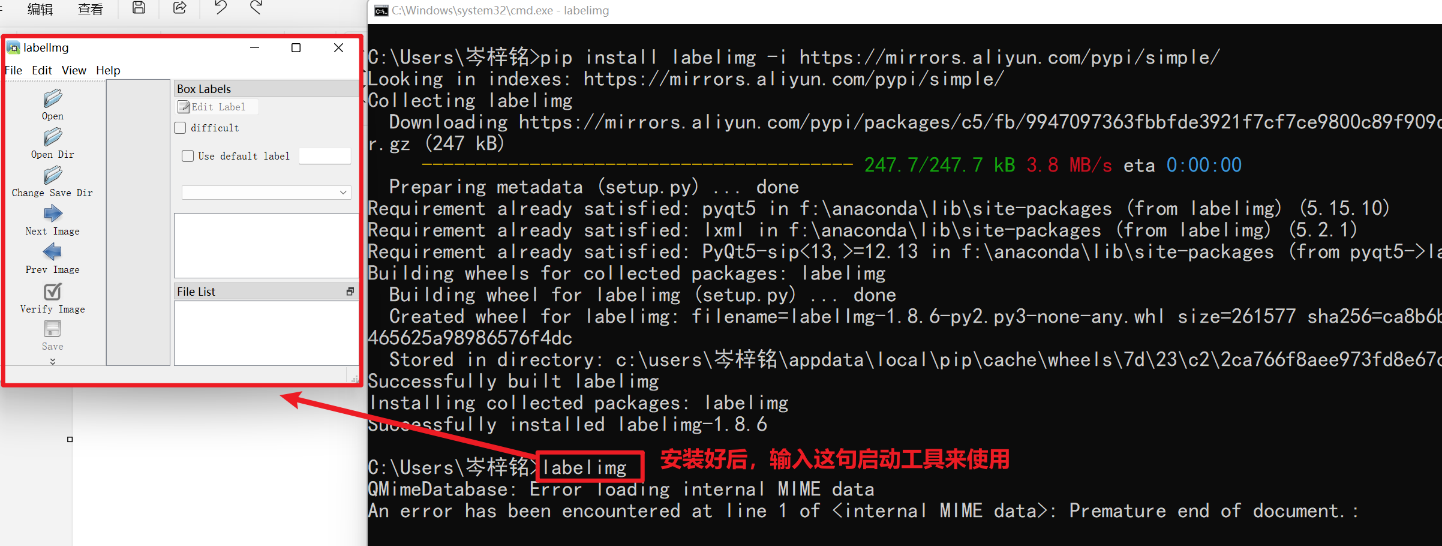
pip install labelimg -i https://mirrors.aliyun.com/pypi/simple/2、安装后输入这个命令来使用
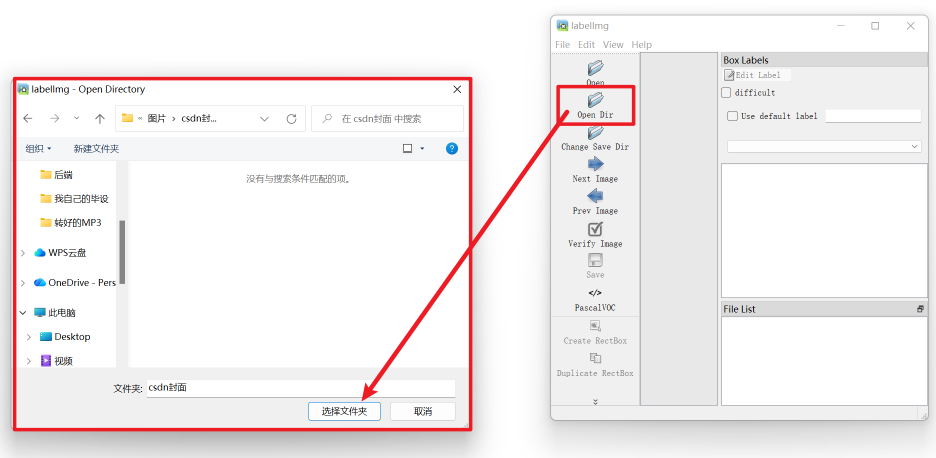
labelimg3、点击你要标注的图片的文件夹
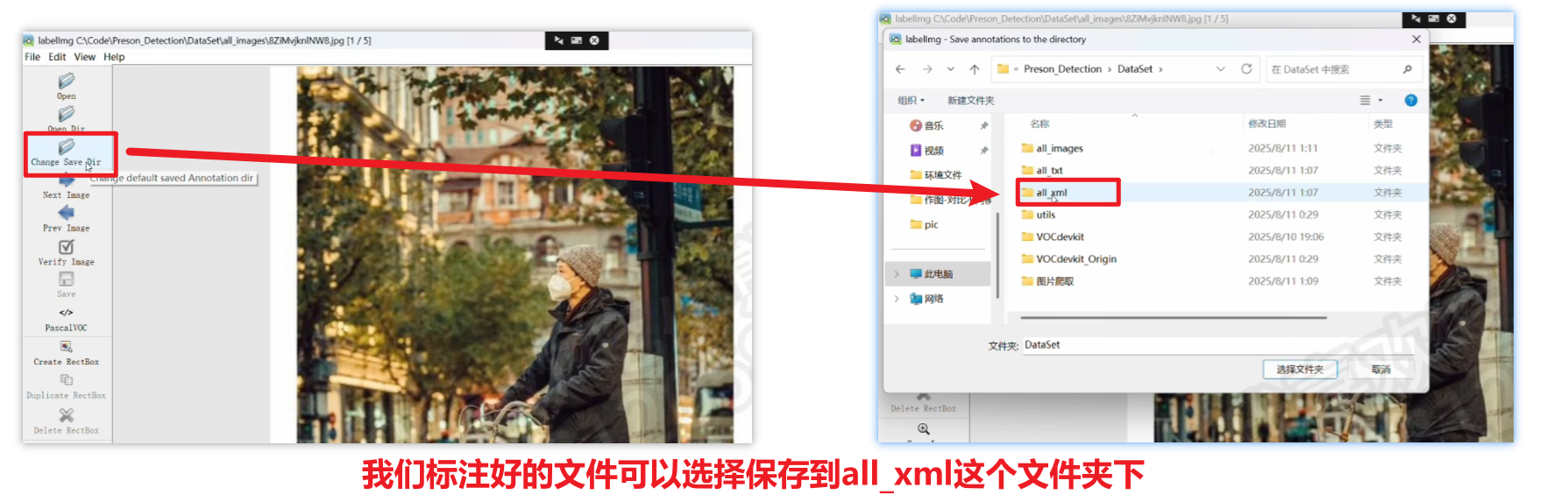
虽然可能点开后会显示没有图片,但是不用管,直接点选择文件夹,图片就会全部导入到工具软件里了
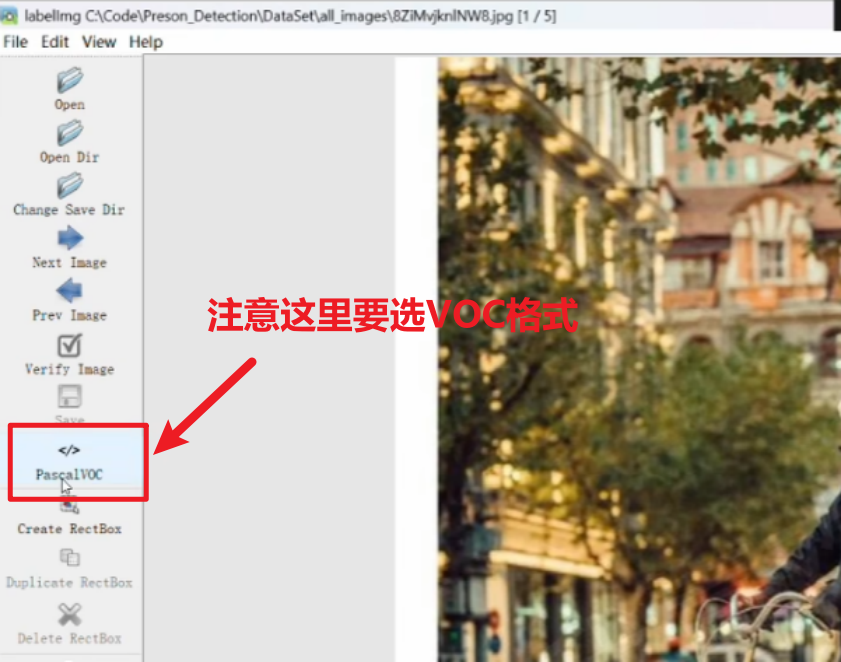
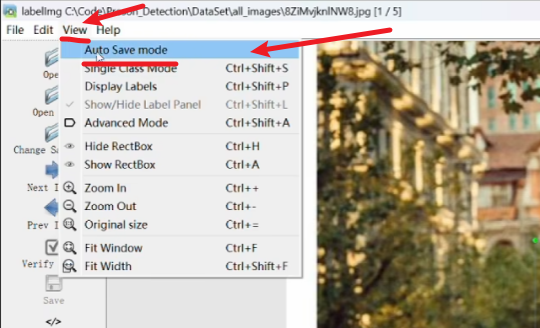
快速自动保存的话就点下图的按钮,这样框选完并打好标签后,点击切换下一张图时就会自动保存上一张图的标注(切换前一张图片是键盘A、切换下一张图片是键盘D)

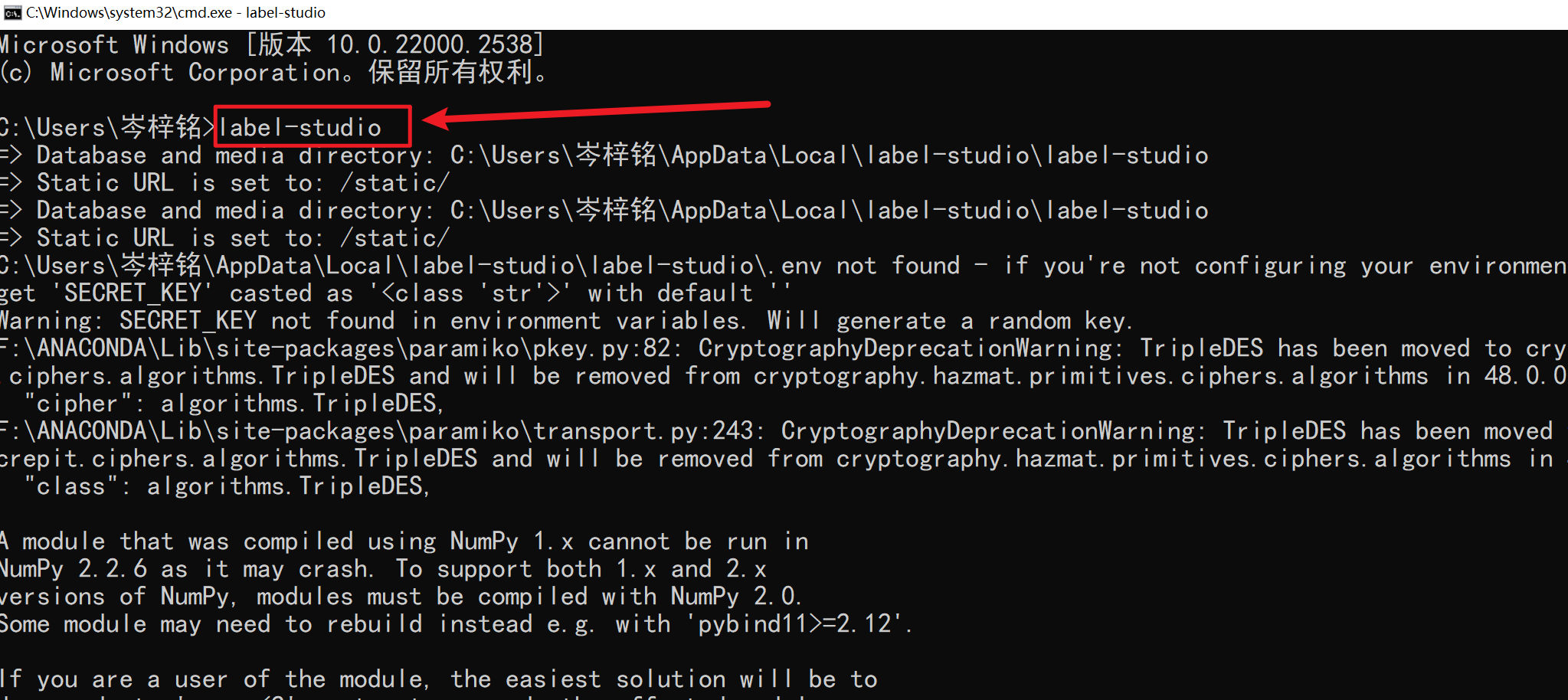
2)【label-studio(推荐,夯爆了)】
当然我还发现有的电脑TMD用pip下载下来的labelimg跟他死了妈一样一堆bug,所以第二种方法是卸载它,然后换成用label-studio,比labelimg好用
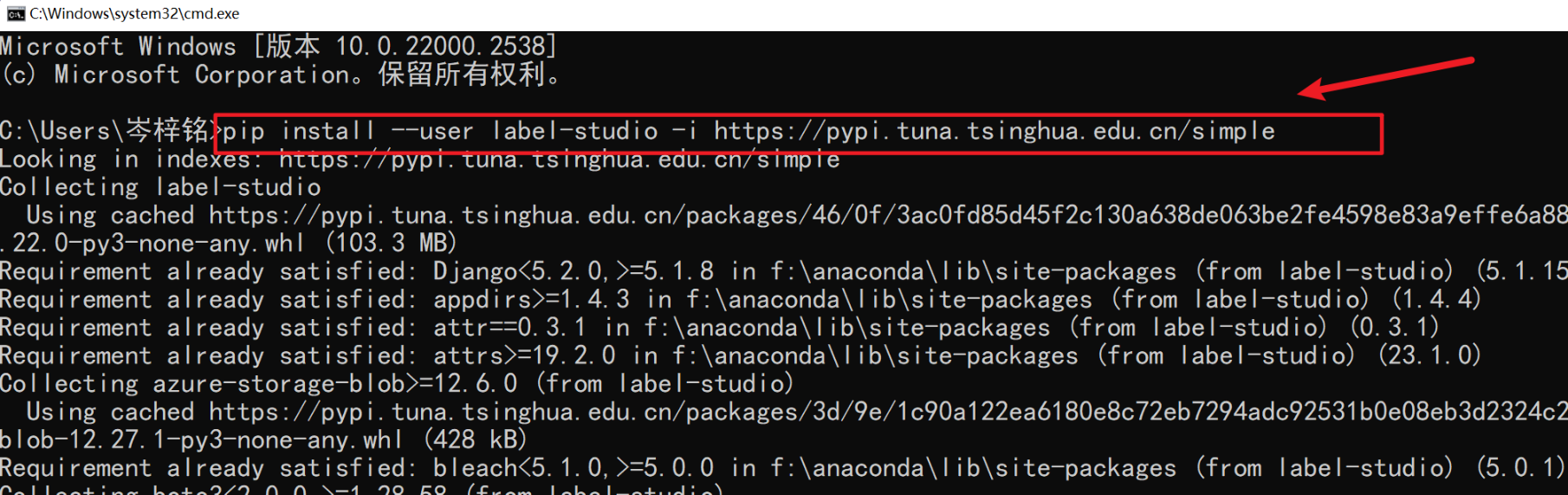
先执行这个代码来全局下载,别漏了 --user
pip install --user label-studio -i https://pypi.tuna.tsinghua.edu.cn/simple
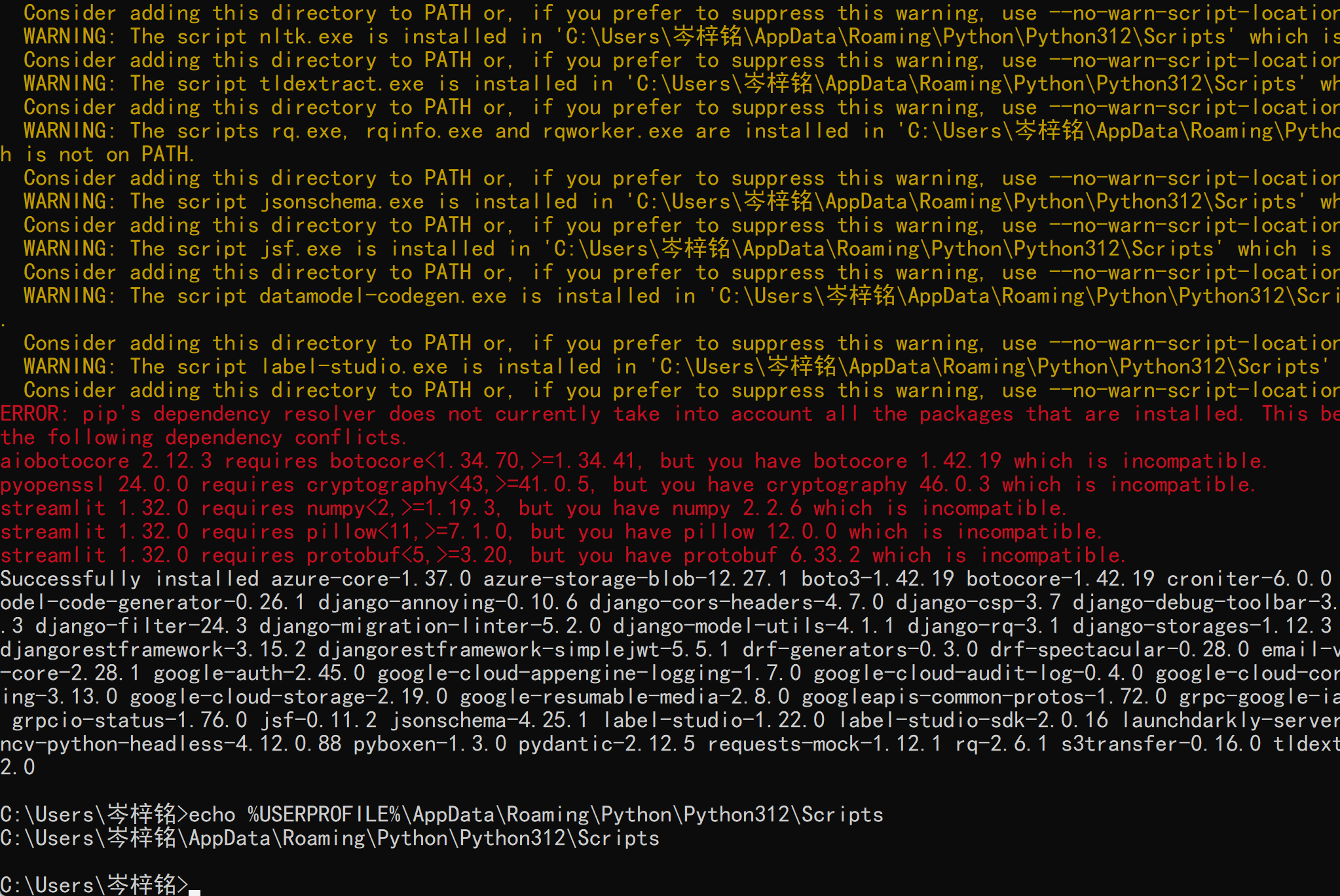
有这些黄色红色的警告报错都不用管,正常的一个提醒而已,现在以及安装完毕
;
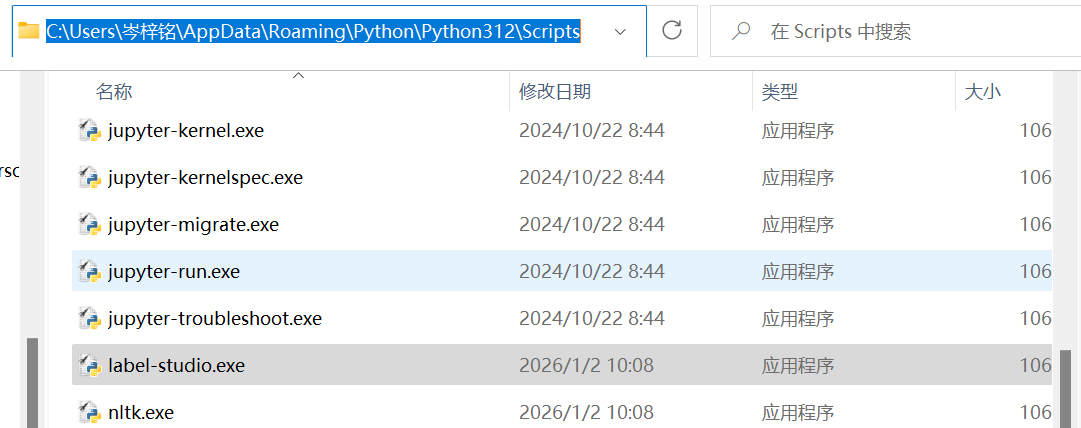
然后再执行这个命令,找到你的label-studio是安装在哪了:
echo %USERPROFILE%\AppData\Roaming\Python\Python312\Scripts
可以去这个路径检查一下有没有label-studio.exe,有的话就对了,把这个文件夹路径复制下来,注意是当前文件夹而不是包括这个label-studio.exe
添加到path环境变量,搞定

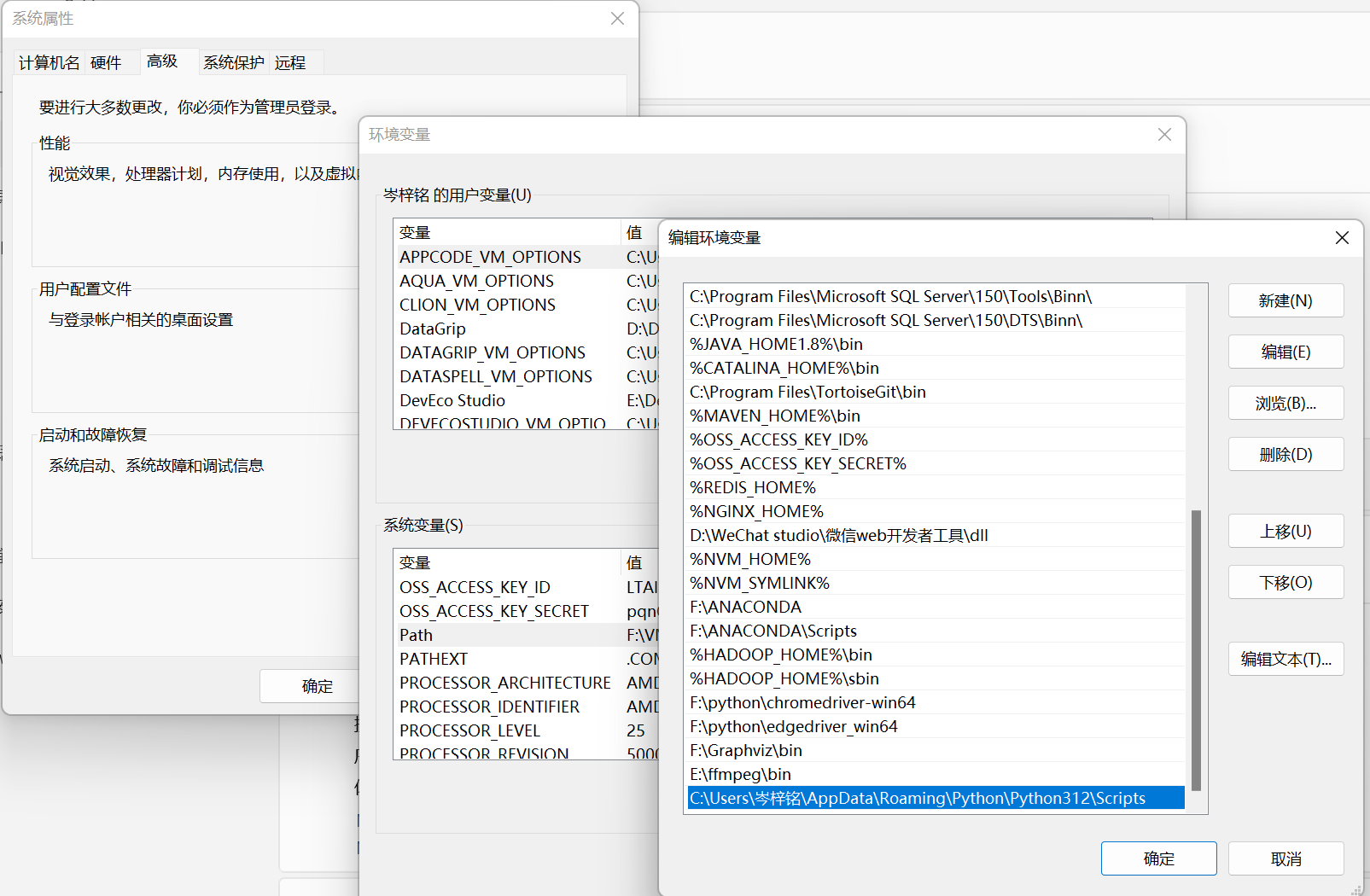
以后用的时候只用敲【label-studio】就可以启动
首次启动还要注册登陆一下
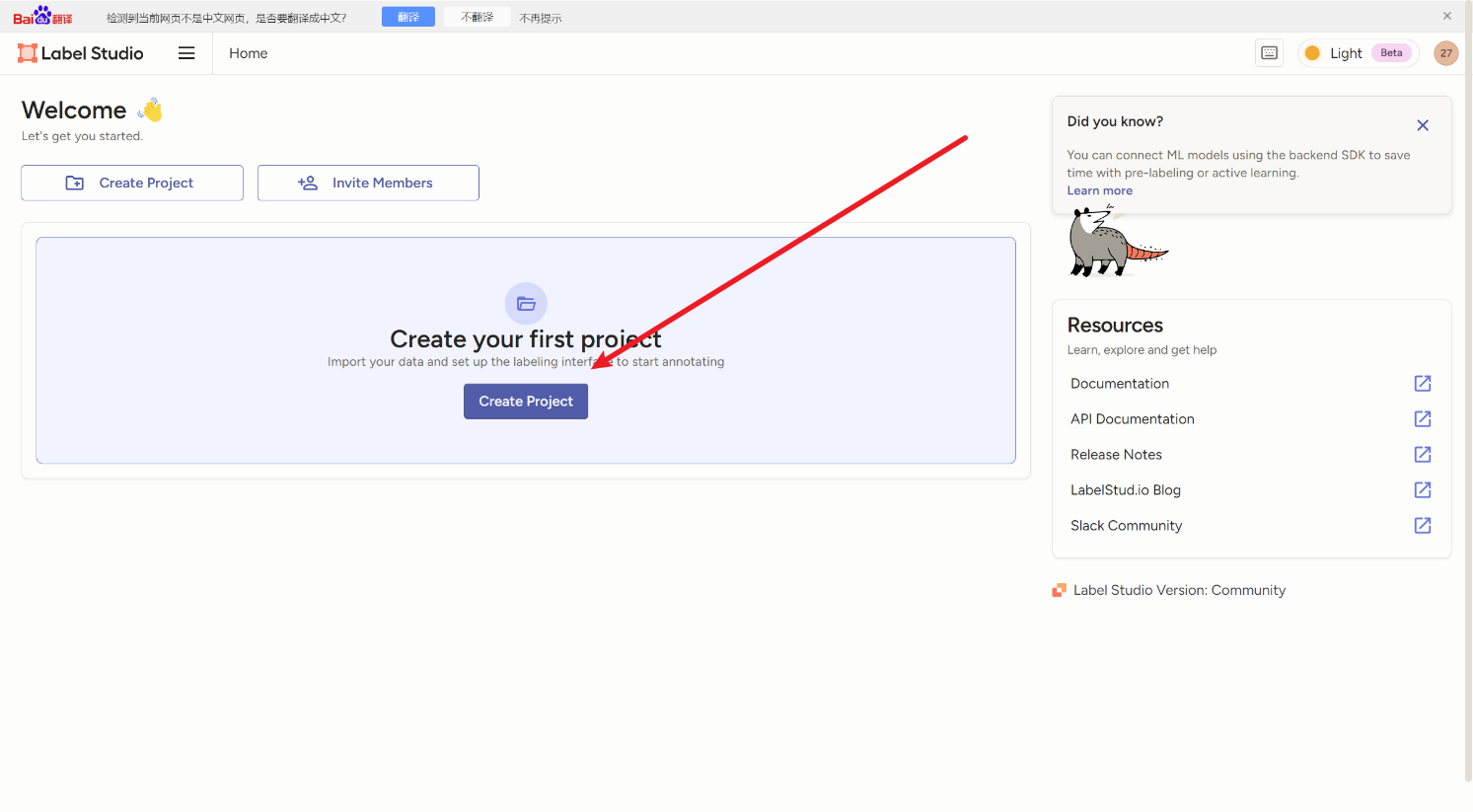
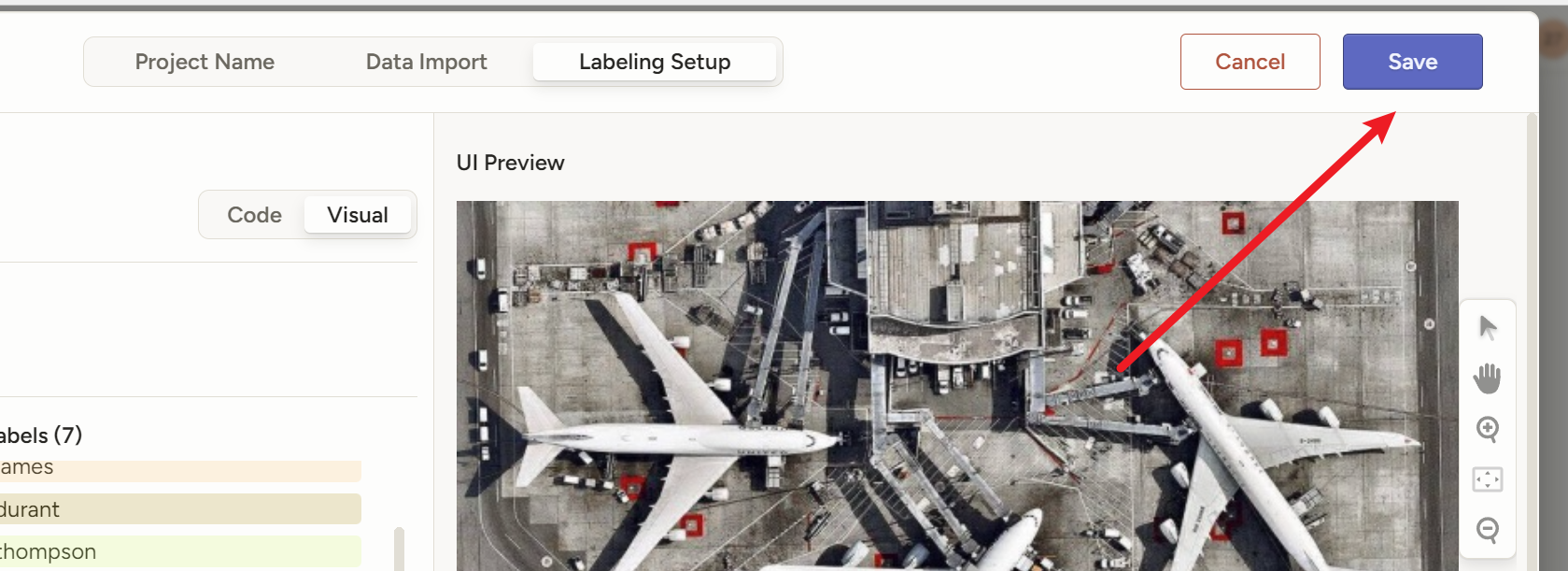
然后要创建一个自己的项目
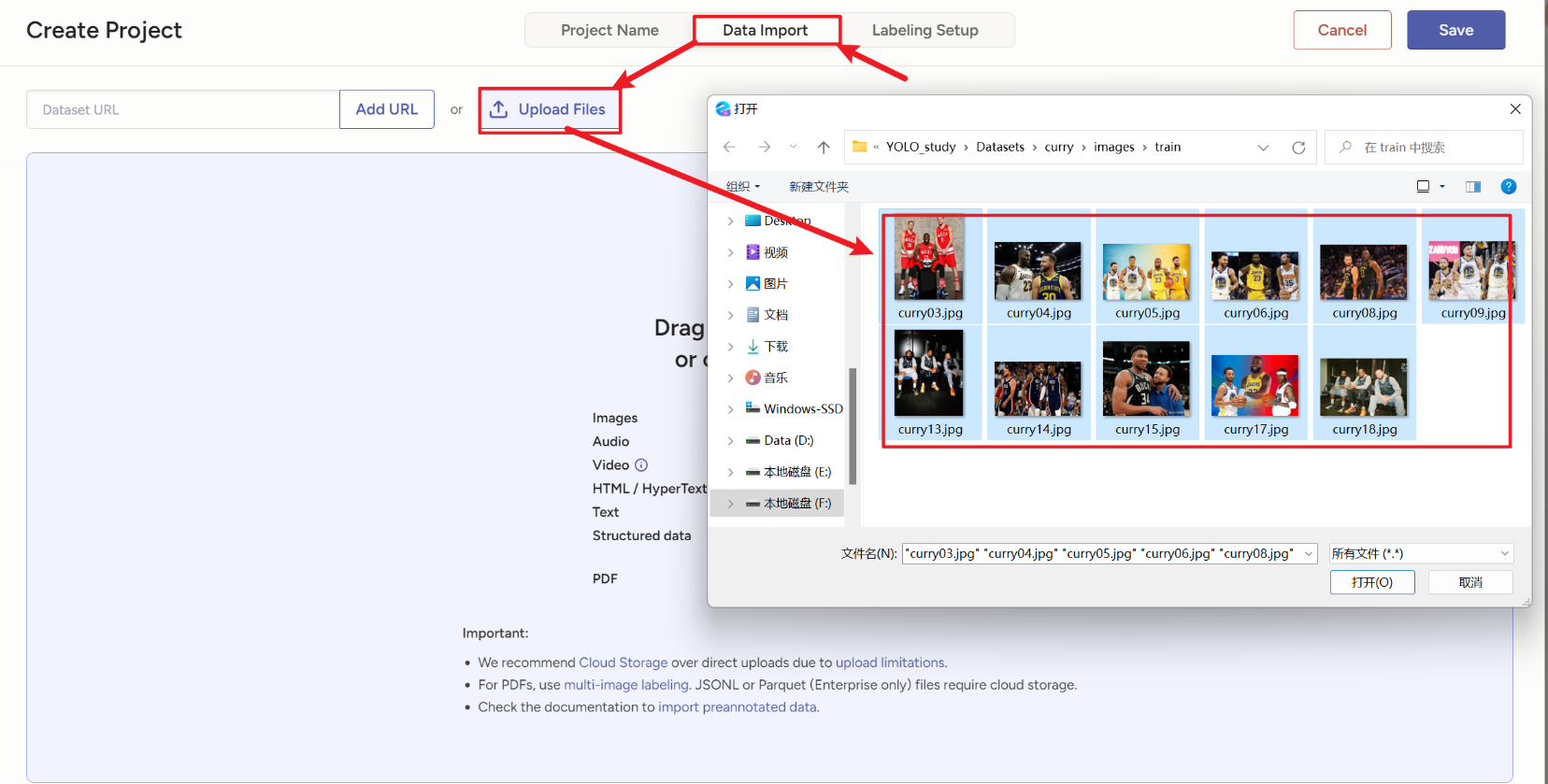
先别点save,然后下一步上传图片
然后点右边选择一个模板,这个网站提供了很多模板
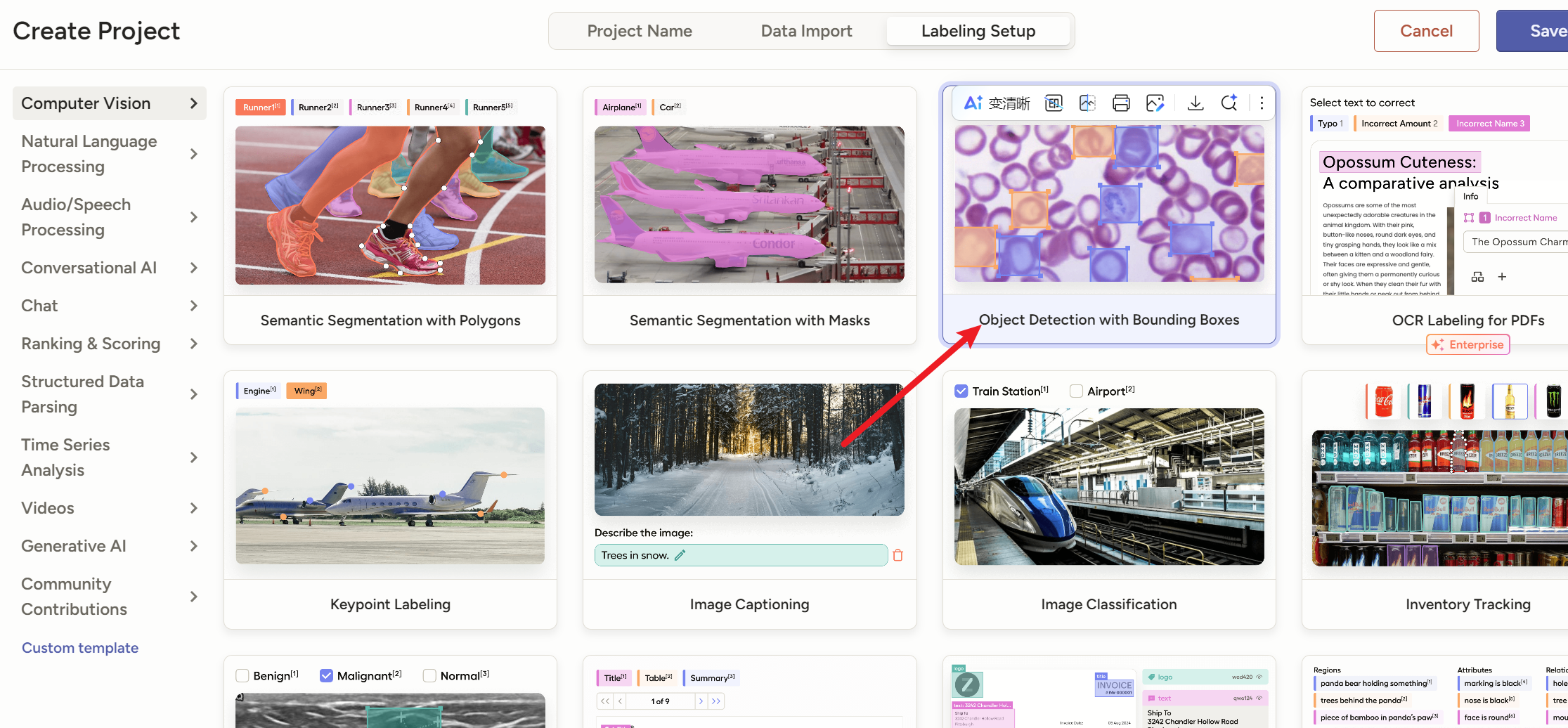
我们随便选一个,比如这个【
Object Detection with Bounding Boxes】就是【目标检测(用矩形框标注特定对象)】
注意这里我翻了个致命错误,就是先把图片数据集分类成train和val了,然后在label-studio的一个项目里给train和val两个文件夹图片打标签,然后分别到导出,结果就是标注文件里出现了很多上一格文件夹里重复打过的标注文件
一定要先在整个数据文件夹先打完标签导出,然后再批量修改文件名,然后再分类!!!
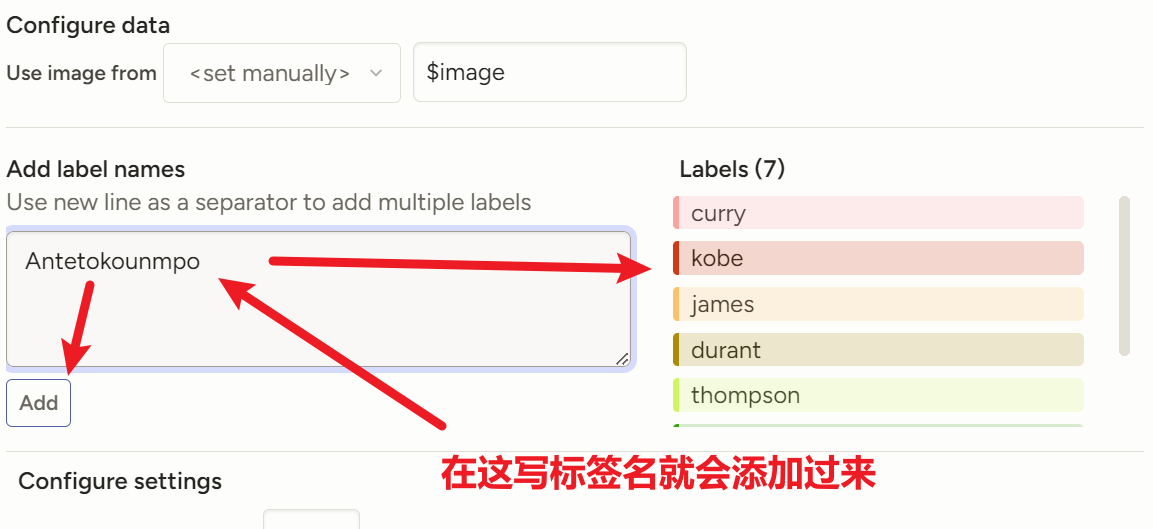
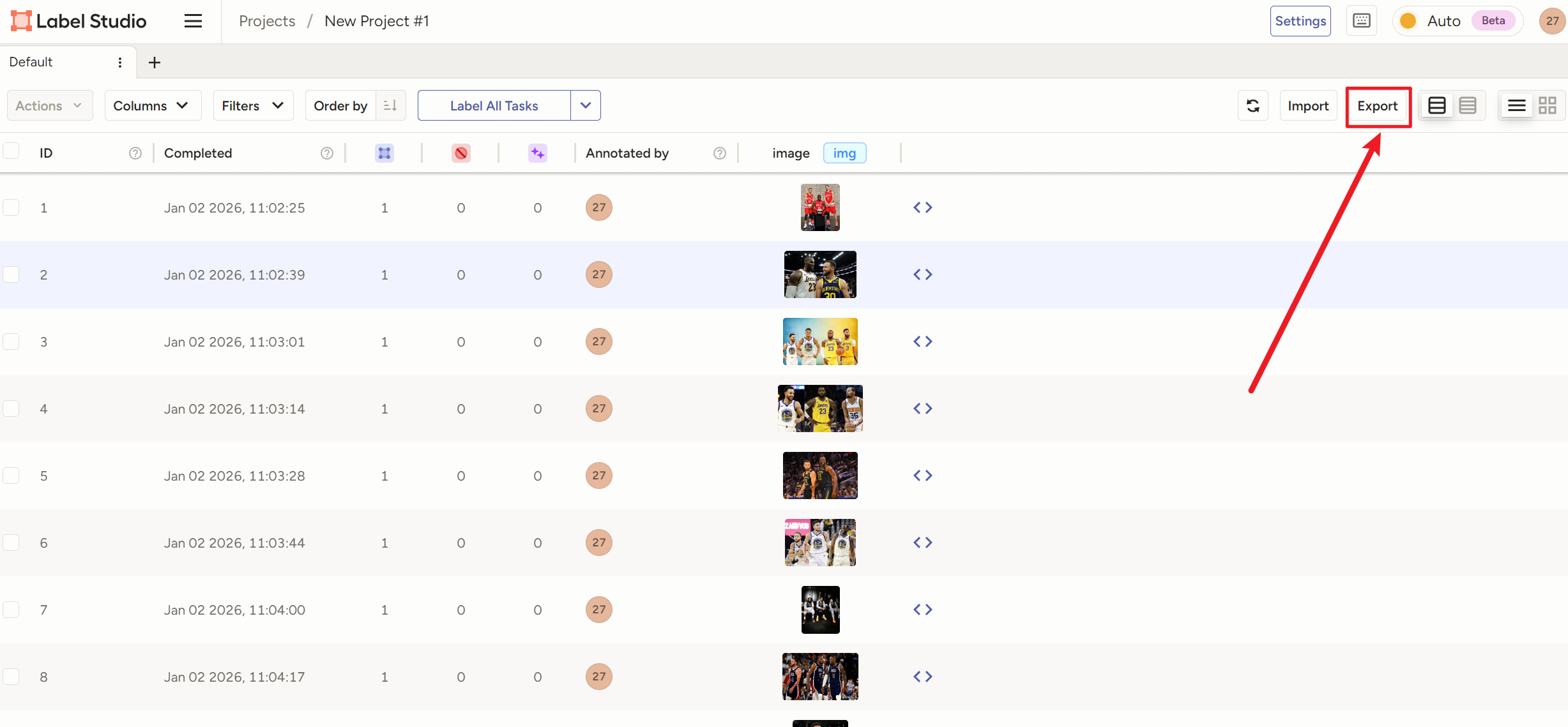
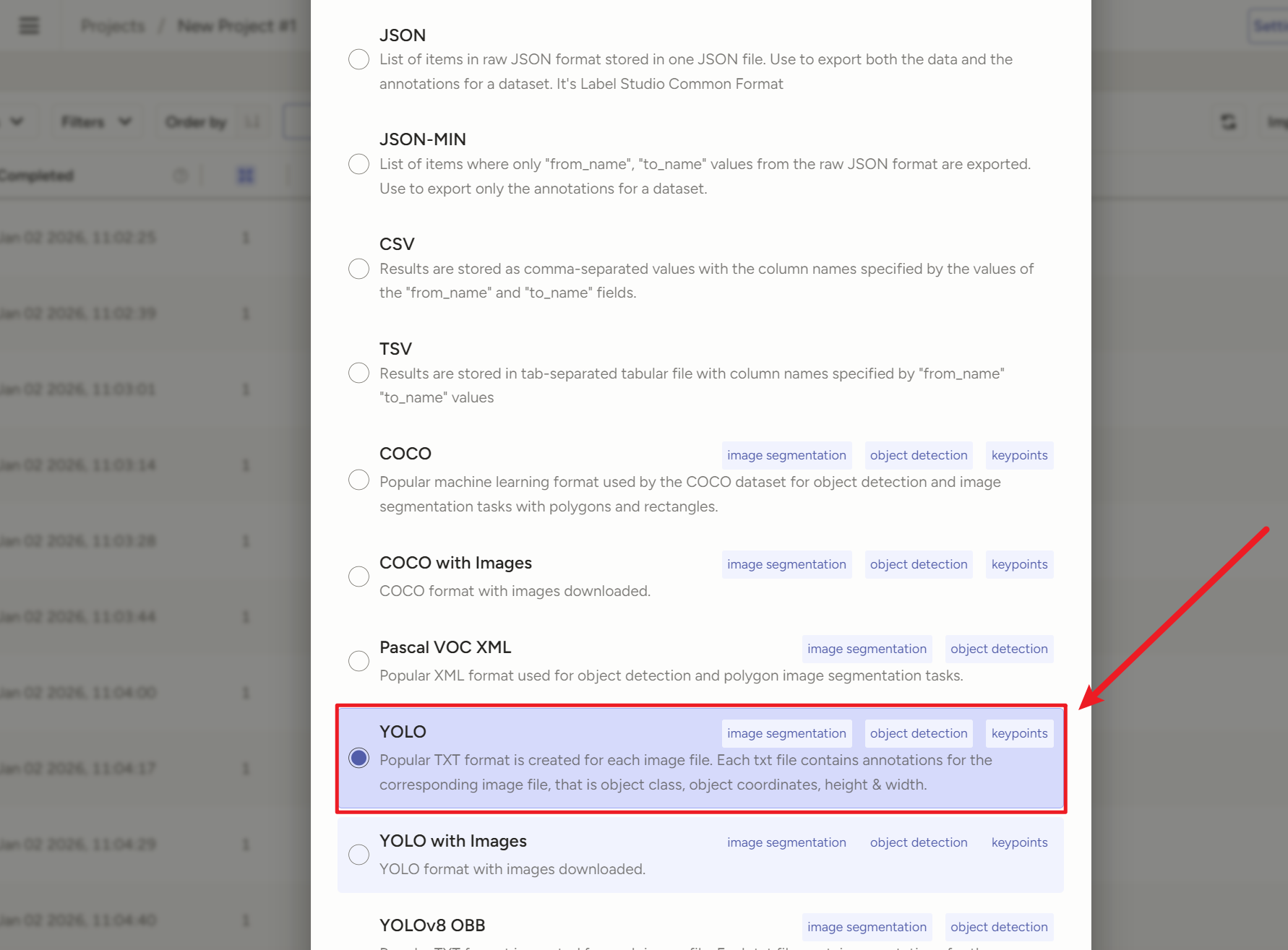
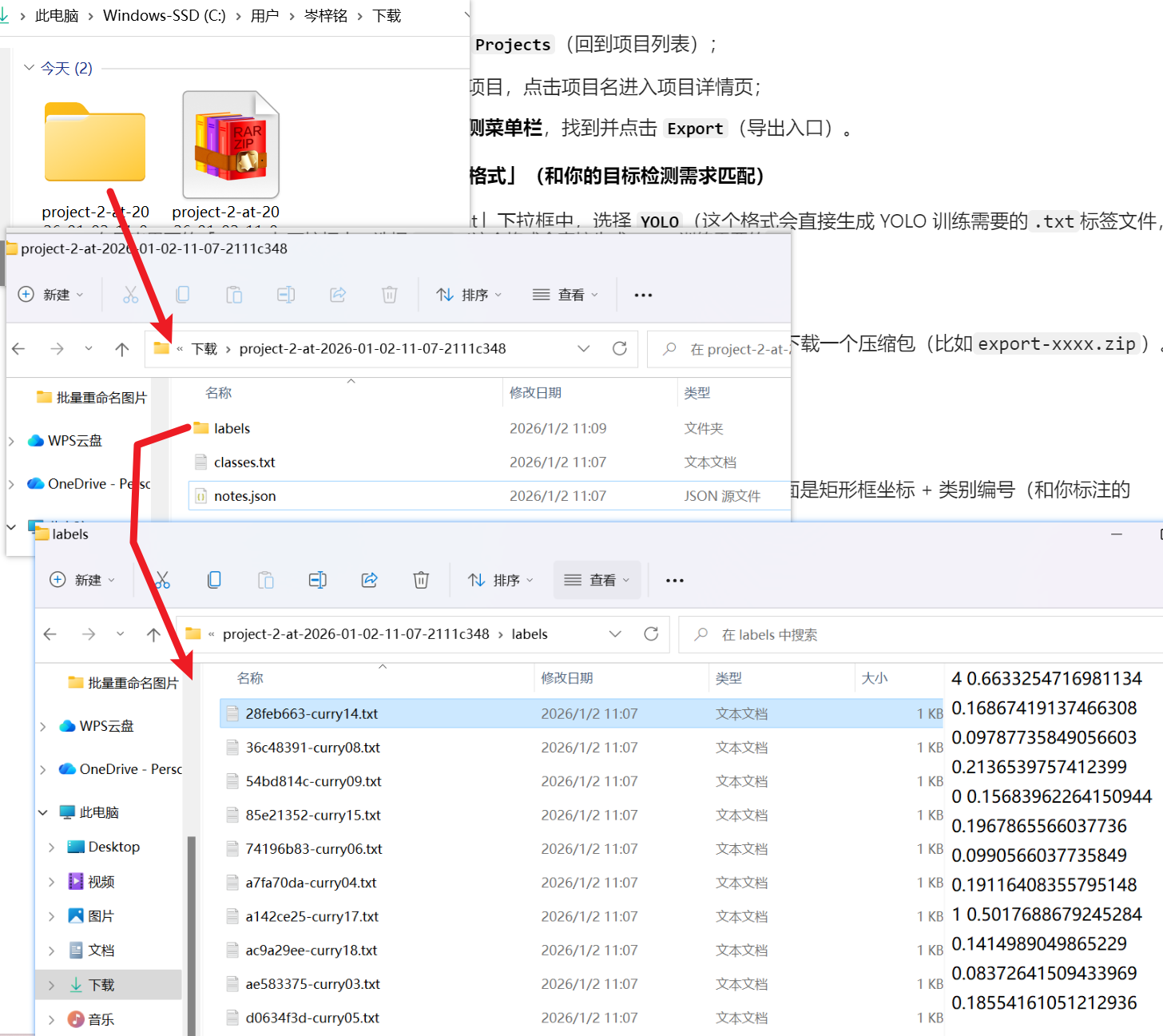
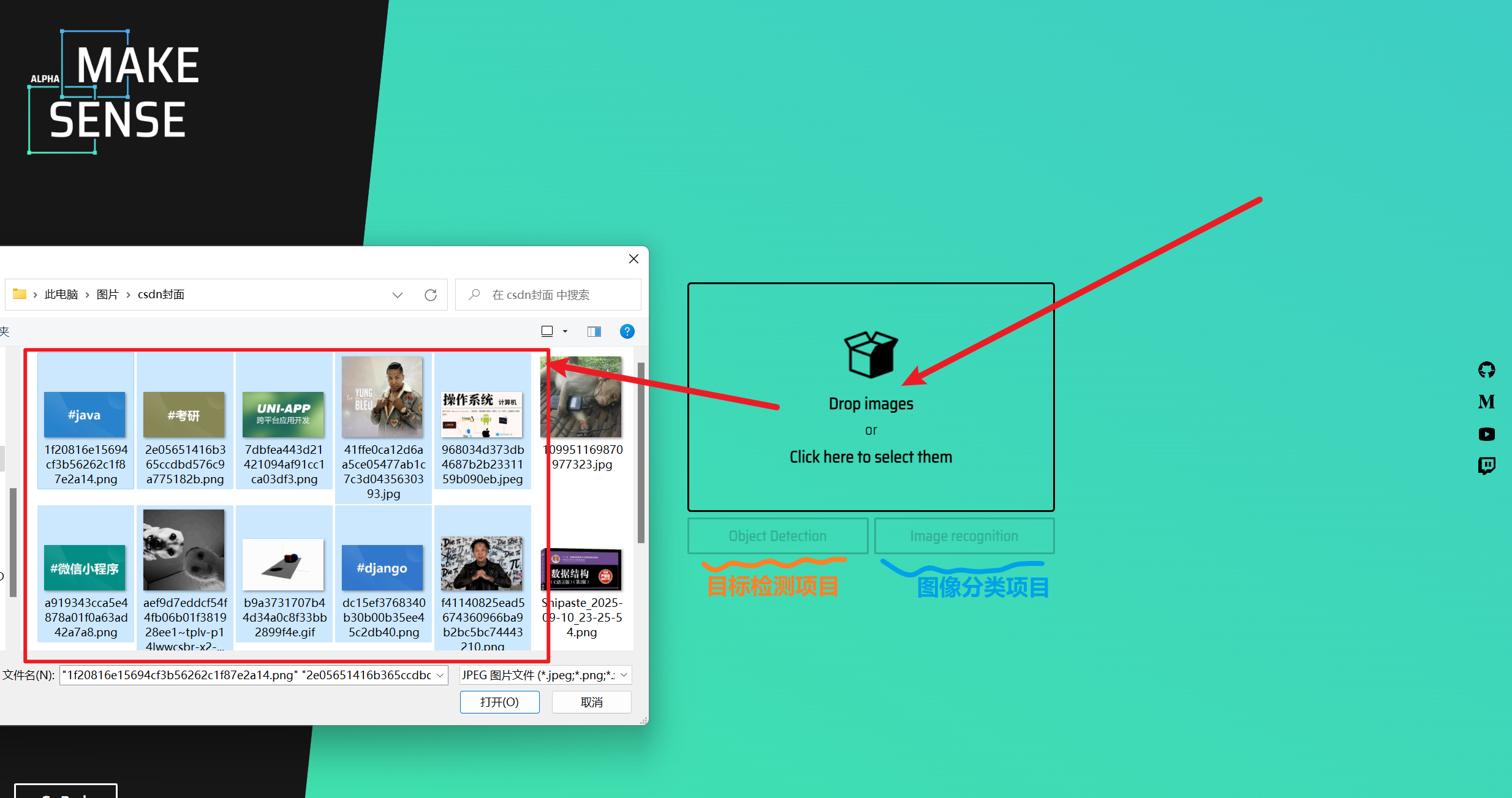
3)【make sence(半推荐,人上人)】
操作很简单也是很像label-studio,但是他没有那么多模板,只有简单的矩形框选这些功能,所以我还是更推荐label-studio,夯爆了
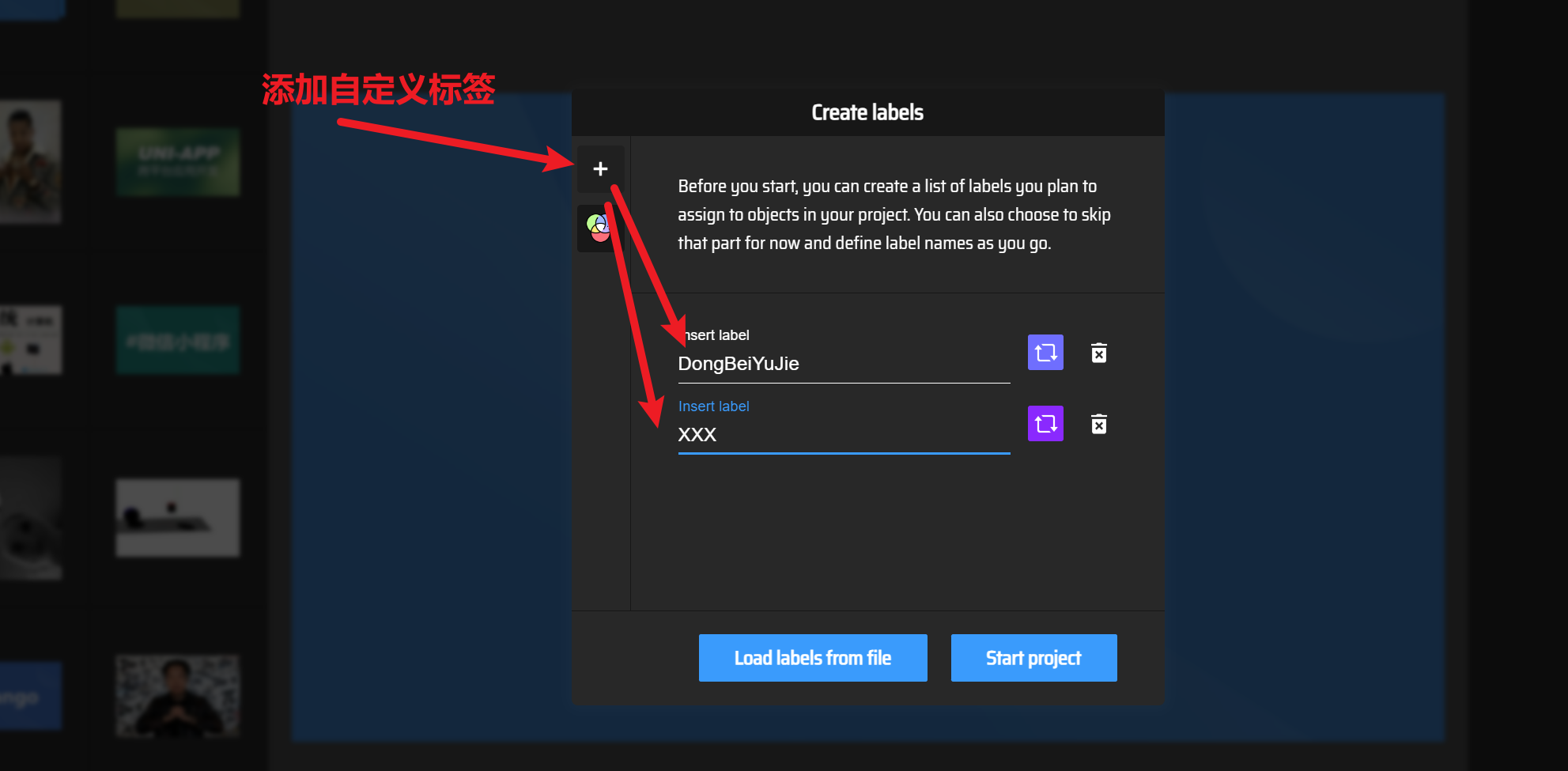
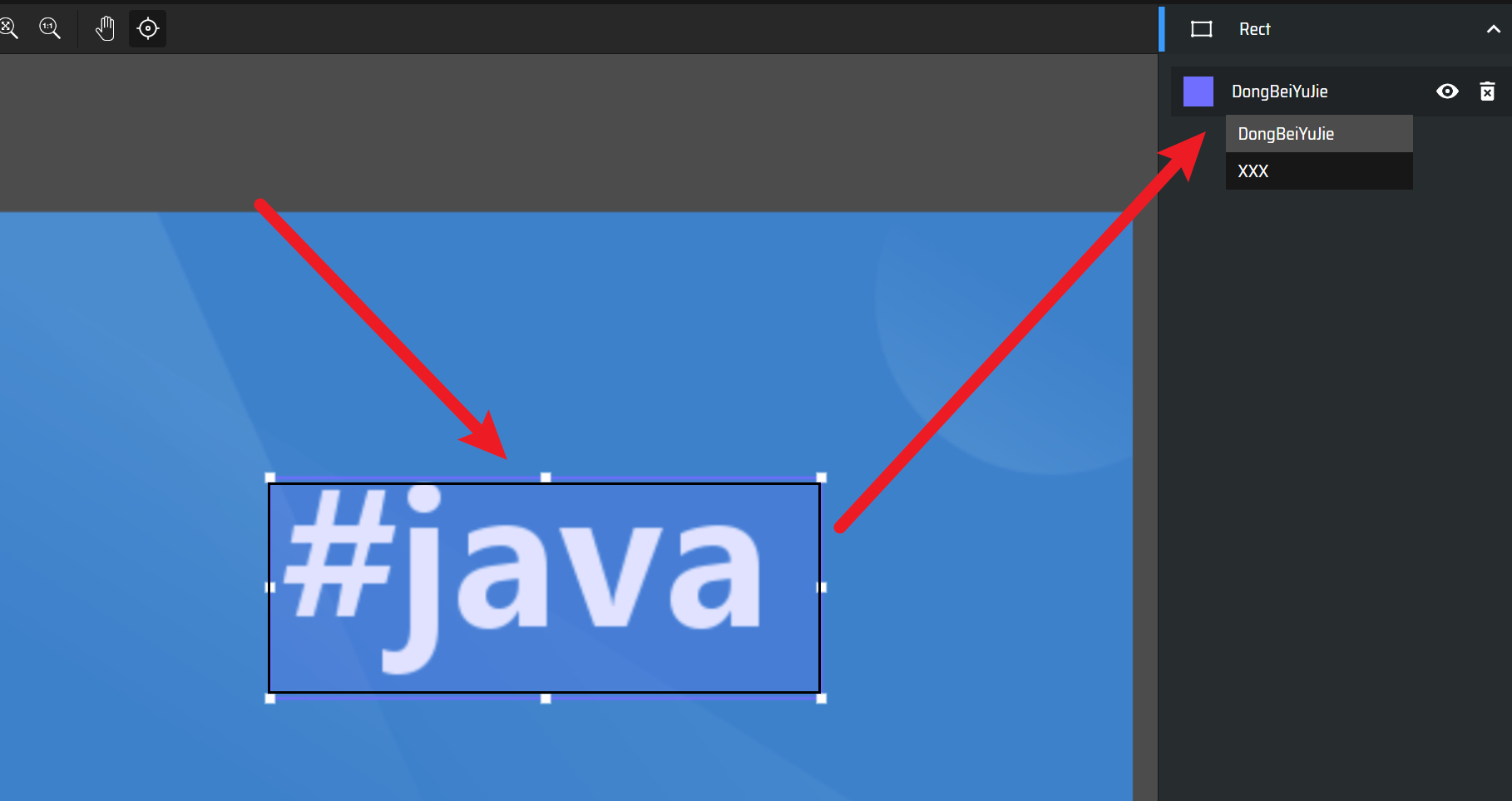
4)X-anylabeling自动化标注(推荐)
这个工具可以自动化标注,但是前提是可能需要提前训练一个AI模型,再导入然后才能自动化标注,就是先干小活、再干大活
【安装配置】
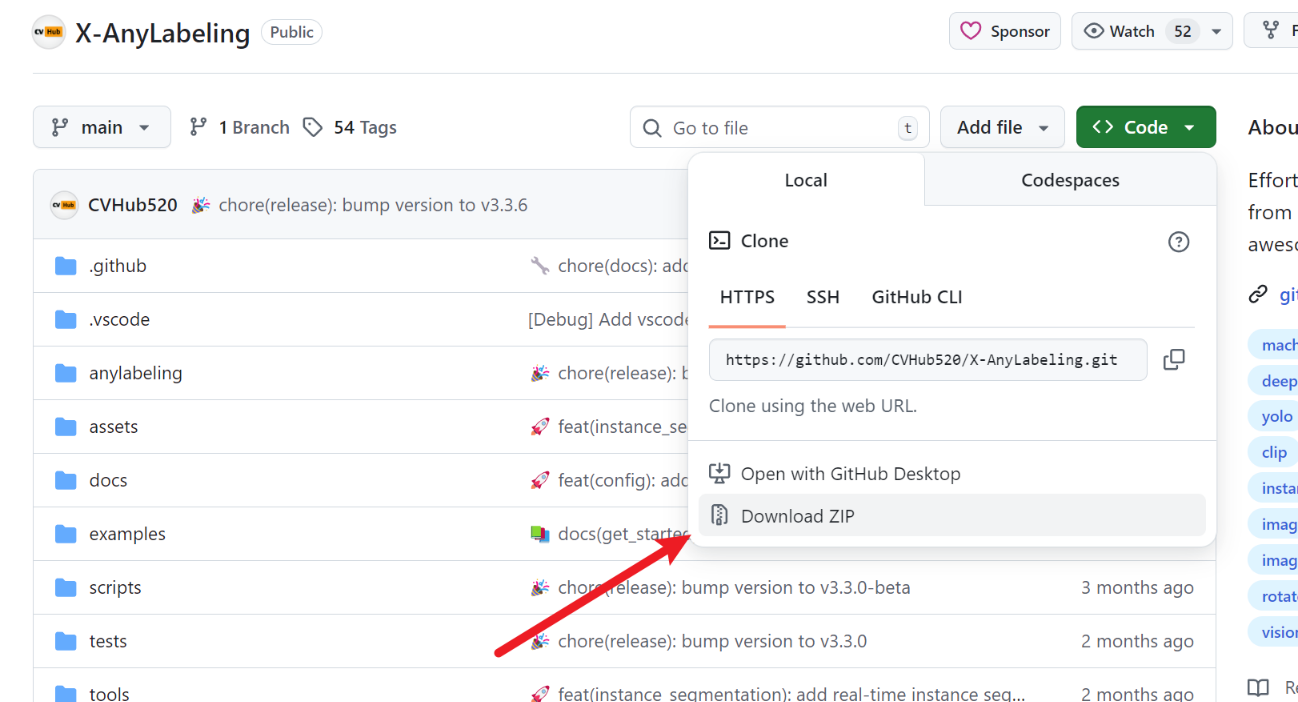
自动化标注工具安装链接:【X-AnyLabeling】点击这个链接
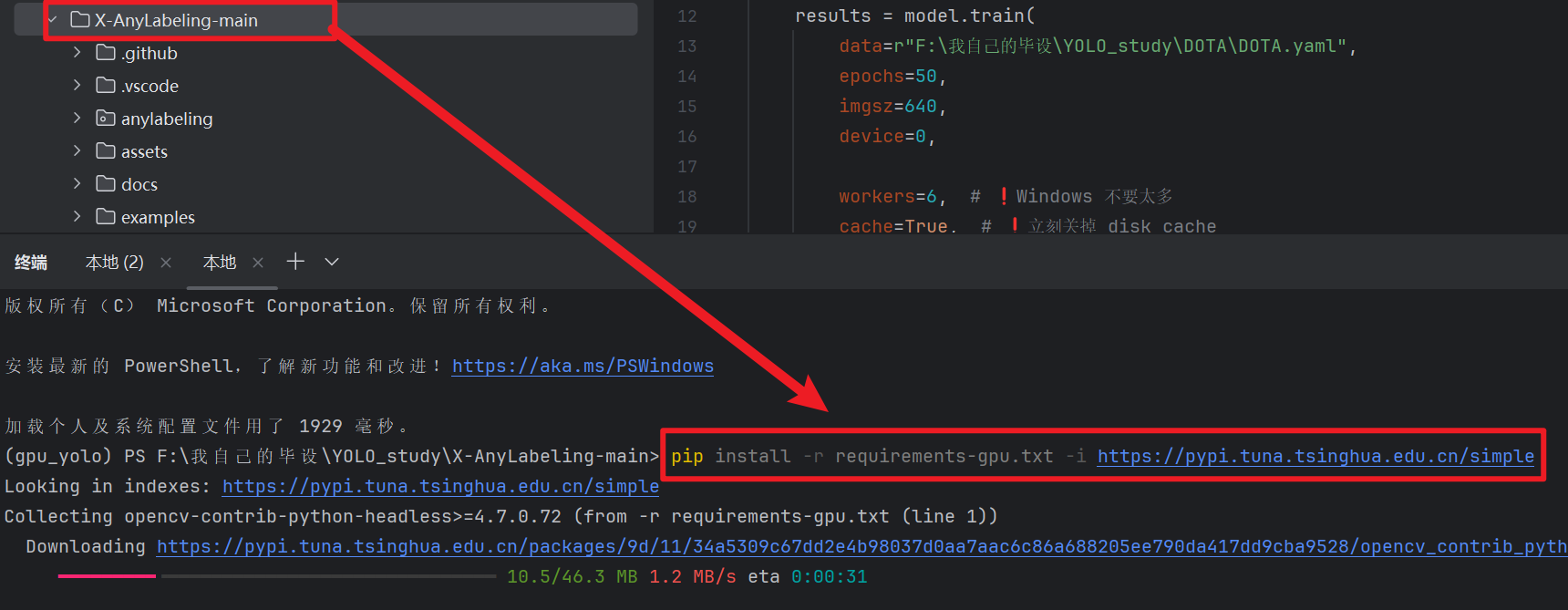
下载好后,解压到我们跑模型的python环境下(因为这个工具依赖ultralytics、pytorch,我们跑模型的python环境有这些依赖,就不用重新下载了)
打开这个工具的目录终端,输入下面命令安装 “GPU版依赖”(没GPU的自己搜一下CPU版,再说没GPU你就别跑这么大的遥感数据集了)
pip install -r requirements-gpu.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
;
然后以后就执行【python anylabeling/app.py】这个命令来打开这个软件
;
然后先导入文件夹
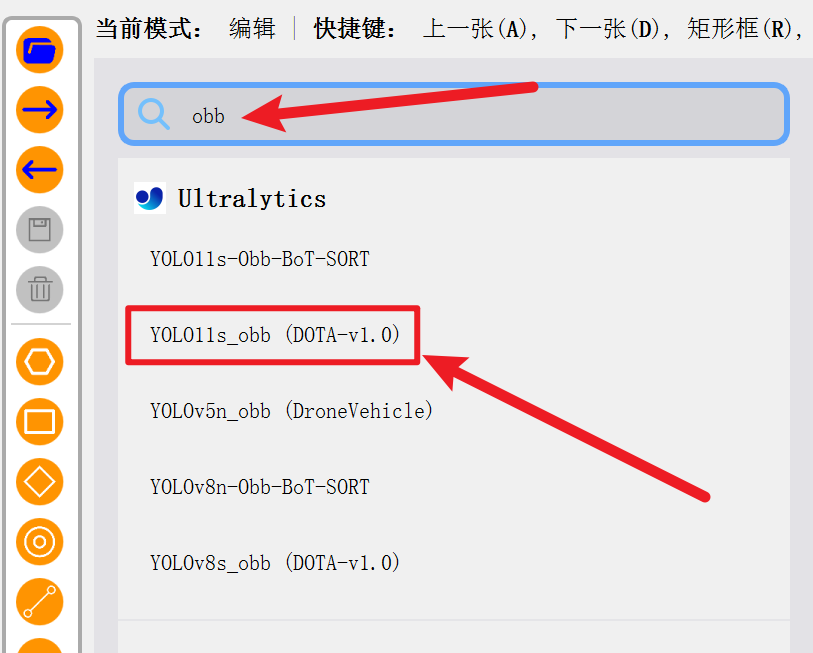
摁【Ctrl+A】启动AI模型,点击它进去选择我们要的OBB旋转框模型
然后我们要什么模型,就输入关键词搜一下,比如我们要旋转框obb格式的AI模型就这样
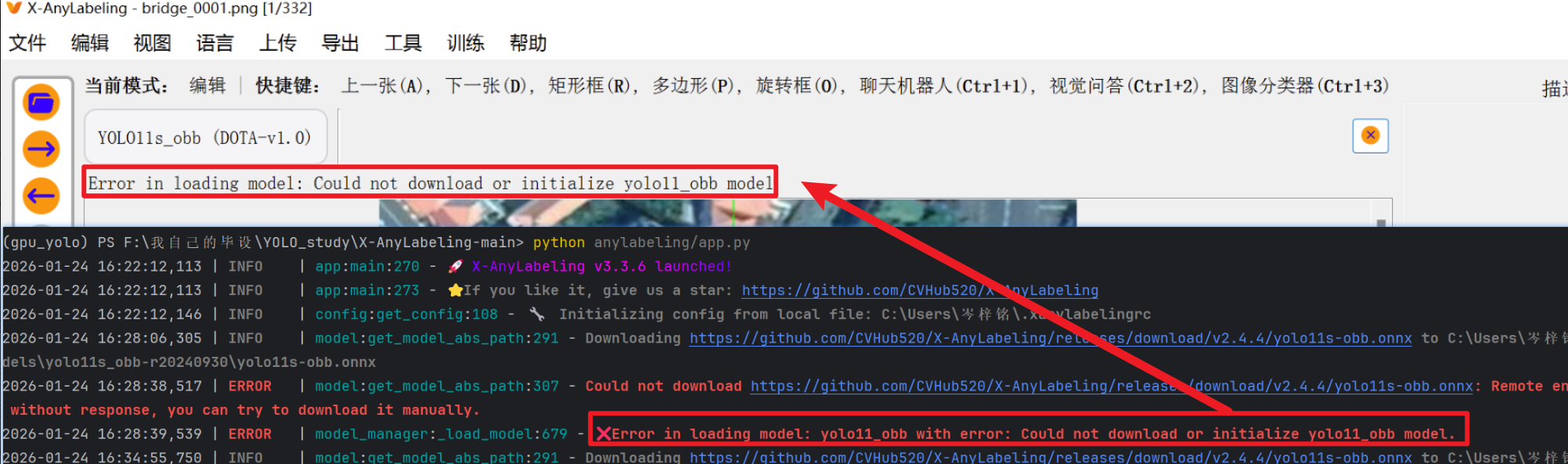
点击一下,首次使用时工具就会在后台先把这个模型下载到本地,等下载好了就可以用了
这里注意:一定一定一定一定一定一定要 “开魔法”,不然这些模型都没办法下载到本地,这个工具就一点卵用也没有
即使开了也可能下载失败,多点几次或者换一下别的模型就行了
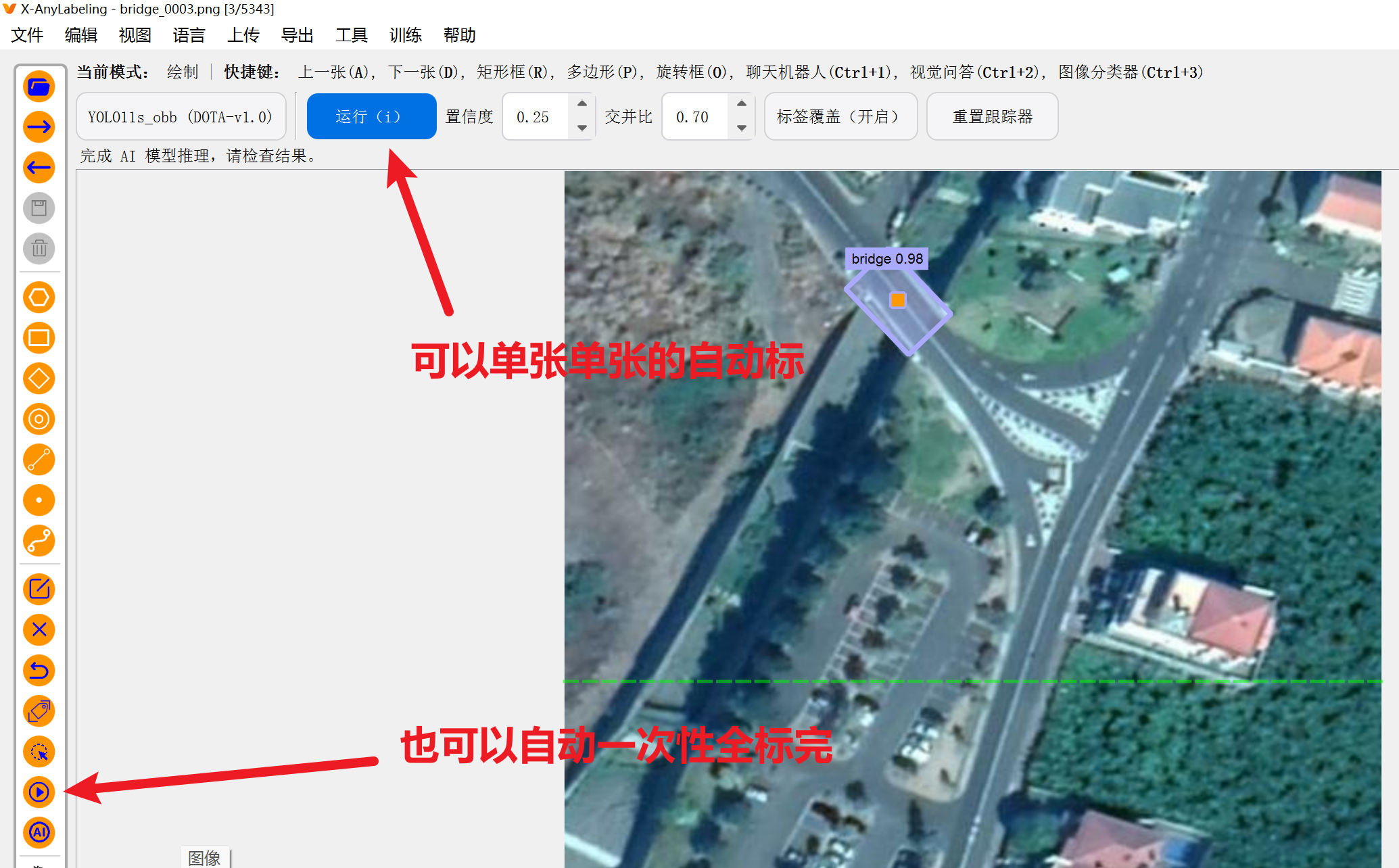
这里不推荐用它来拉 obb旋转框,因为很麻烦,这里只是演示一下它是怎么拉旋转框的
(还是推荐手动拉框用label-studio,这个工具知识和AI自动化拉框)


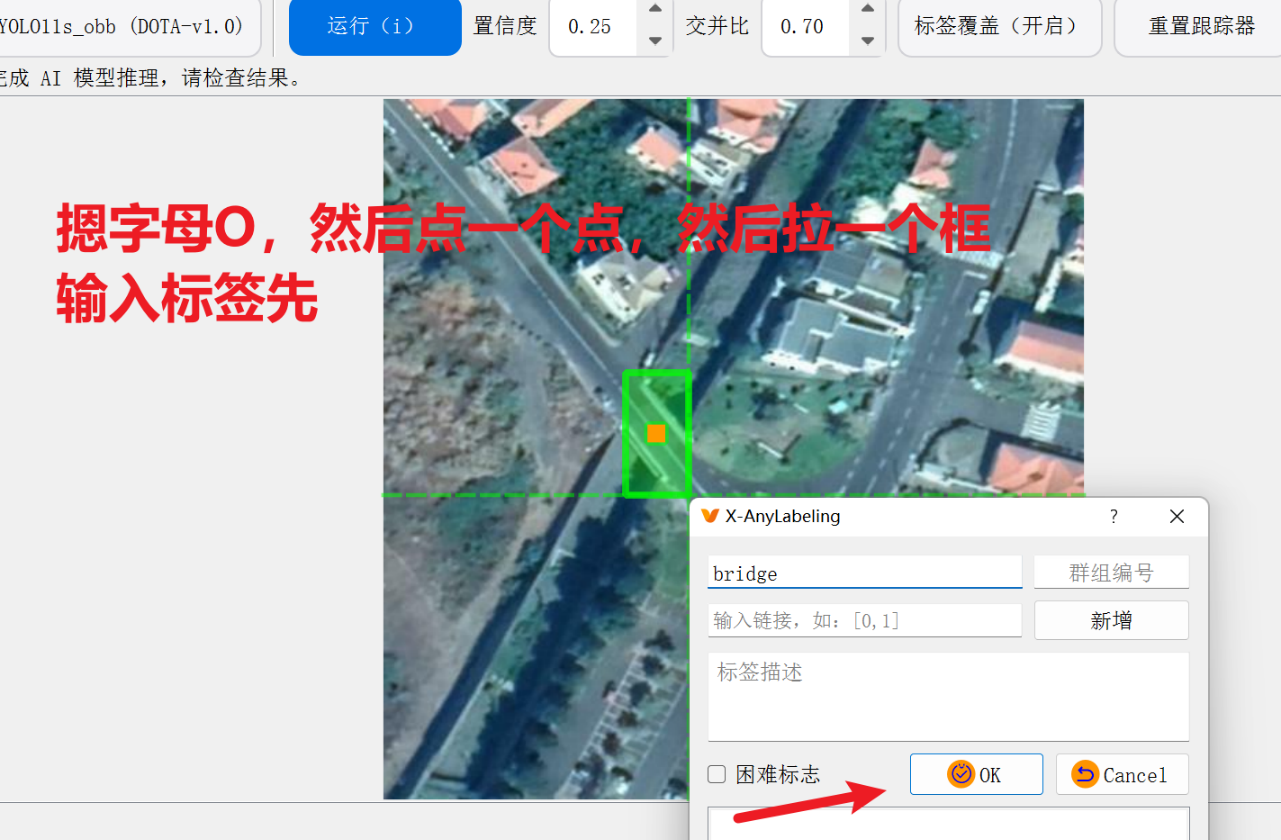

【自动化给旋转框obb打标签】
那么如果前面我们已经手动标注了一堆图片了,现在我们就要用这一小部分数据集先训练一个模型先
还得注意,把文件images和labels里的文件分成【train】和【val】好应对yolo训练的文件个格式:
【然后就是训练我们手动标注的小预训练模型】
import torch from ultralytics import YOLO if __name__ == '__main__': # 这是为了Windows下开启workers>0 的硬性条件,workers>0就加快速度 torch.multiprocessing.freeze_support() # 解决多进程报错问题 # 直接加载官方YOLO11n预训练模型 # model = YOLO(r"F:\我自己的毕设\YOLO_study\DOTA\my_yaml\11\my_yolo11-obb.yaml").load("yolo11n-obb.pt") model = YOLO("yolo11n-obb.pt") results = model.train( data=r"F:\我自己的毕设\YOLO_study\DOTA\Datasets\DOTA_split\all_images\自动化标签预训练\X-AnyLabeling.yaml", epochs=100, # 训练100轮 patience=60, # 防过拟合,60轮验证集mAP还不提升就停止 imgsz=1280, # 遥感图像目标还是太小,调大尺寸 # 加快速度 device=0, workers=3, # ❗Windows 不要太多 #cache=True, # ❗立刻关掉 disk cache batch=-1, #val=False, # ❗打开验证(反而更稳定) #plots=False, # ❗关闭训练曲线 # 小目标增强 augment=True, # 开启增强 hsv_h=0.015, # 色相、对比度 hsv_s=0.7, # 饱和度 hsv_v=0.4, # 亮度 degrees=8.0, # 旋转角度 mosaic=0.5, # 取50%图片开始mosaic增强 close_mosaic=50, # 最后50轮不做mosaic增强,专注于原始图像学习 copy_paste=0.8, # 复制粘贴增强 mixup=0.0, # 小目标很多很乱,别整混合了 perspective=0.0, # 透视变换关了吧,本来就是俯瞰视图没什么角度倾斜 # 防止过拟合的优化器 lr0=0.01, # 学习率 lrf=0.1, # 学习率衰减 )
【最后最重要的步骤!!千万别搞错!!!】
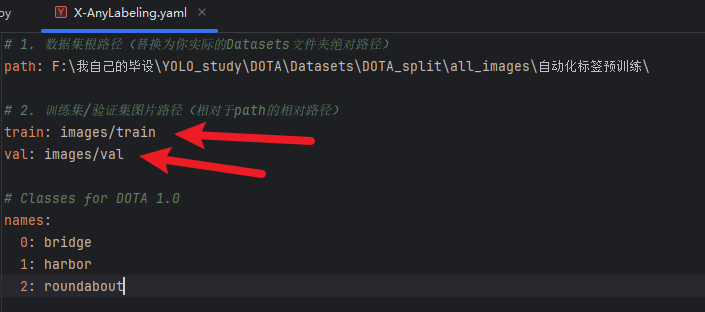
要导入我们的自定义,我们需要官方要求的两个文件
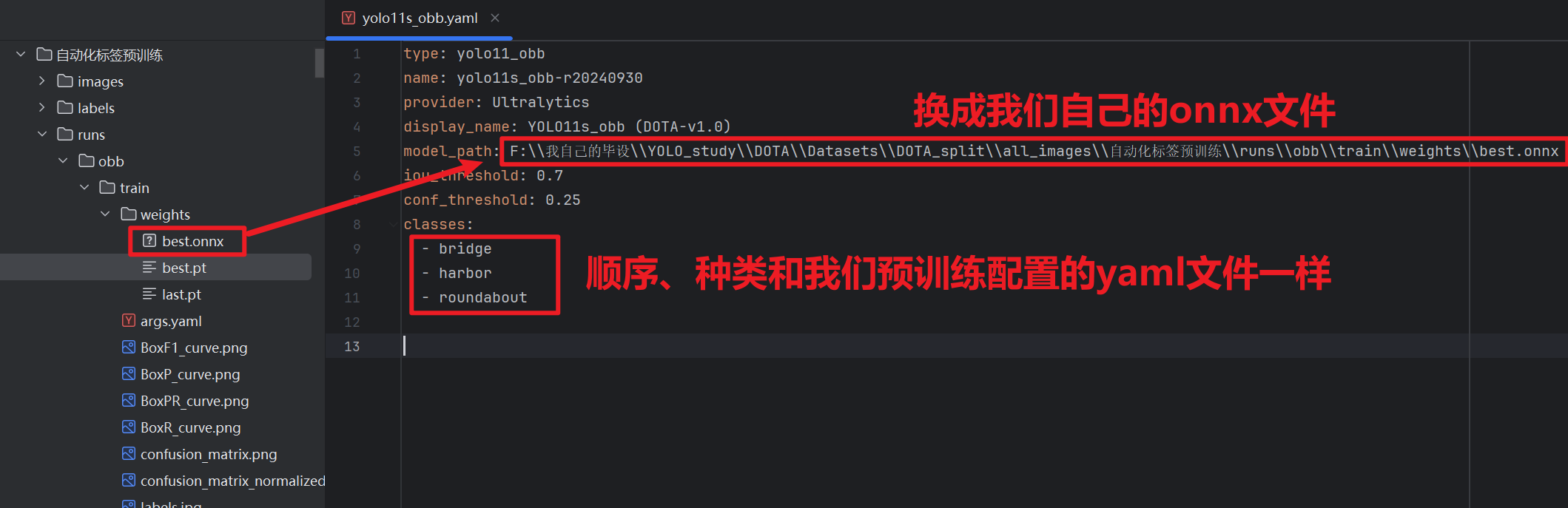
- 第一个是【yaml】配置文件
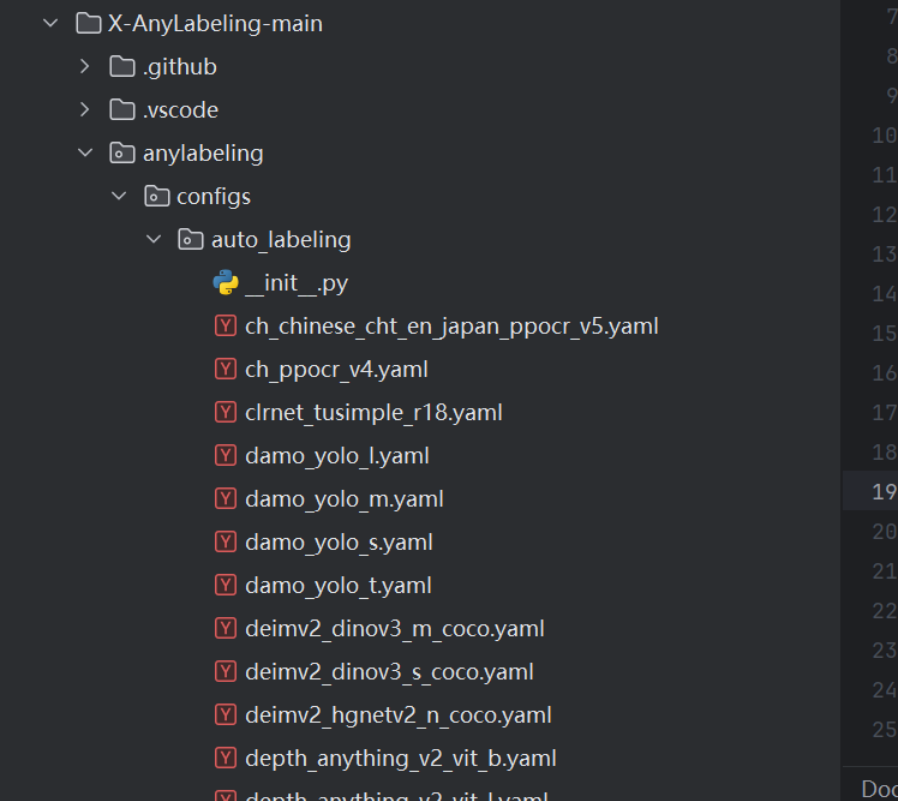
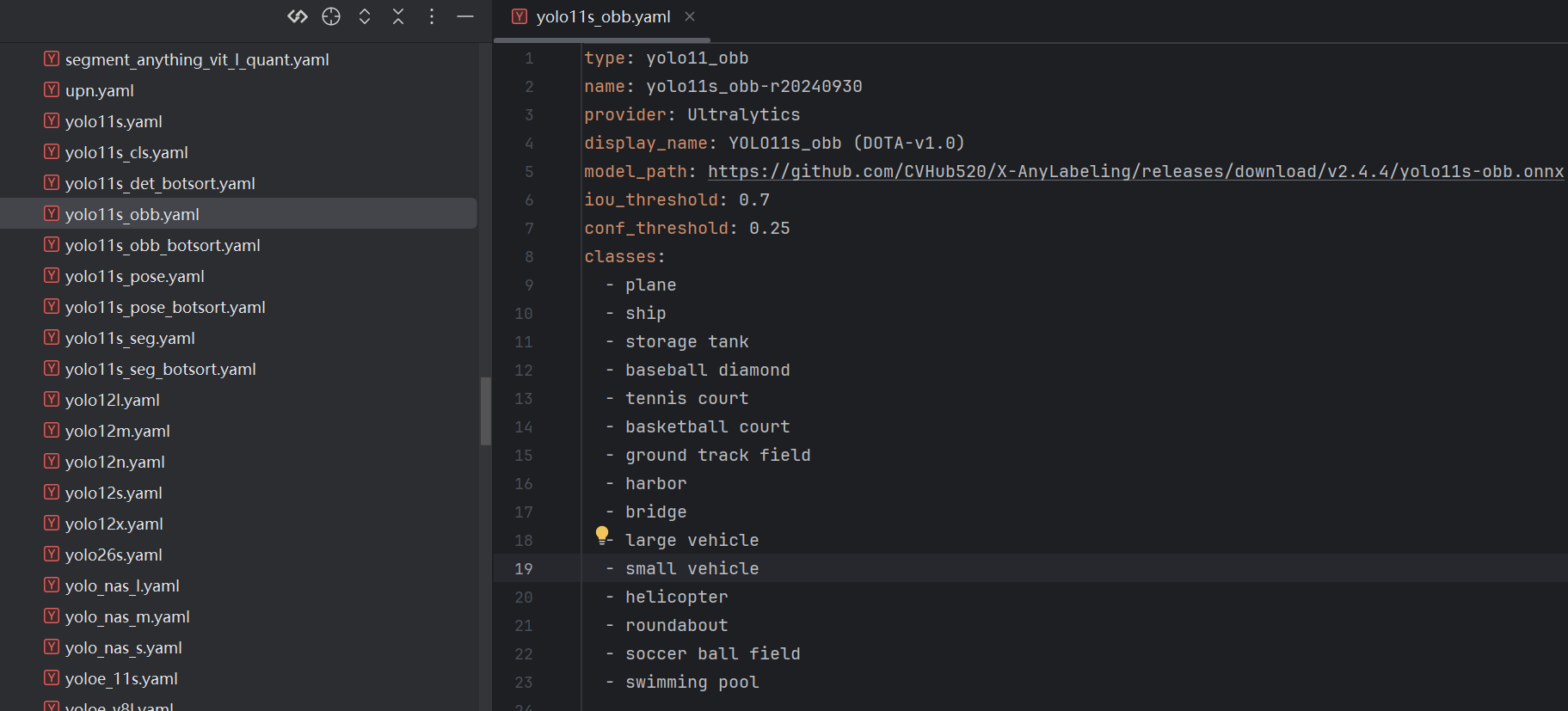
- 跟我们训练的那个yaml文件不一样,这个是告知X-Anylabeling我们的模型在哪?我们要标注的几个标签是啥?
- 我们要到X-Anylabeling安装路径下图的位置找到自己需要的yaml文件,比如我yolo-obb的就选obb的yaml文件
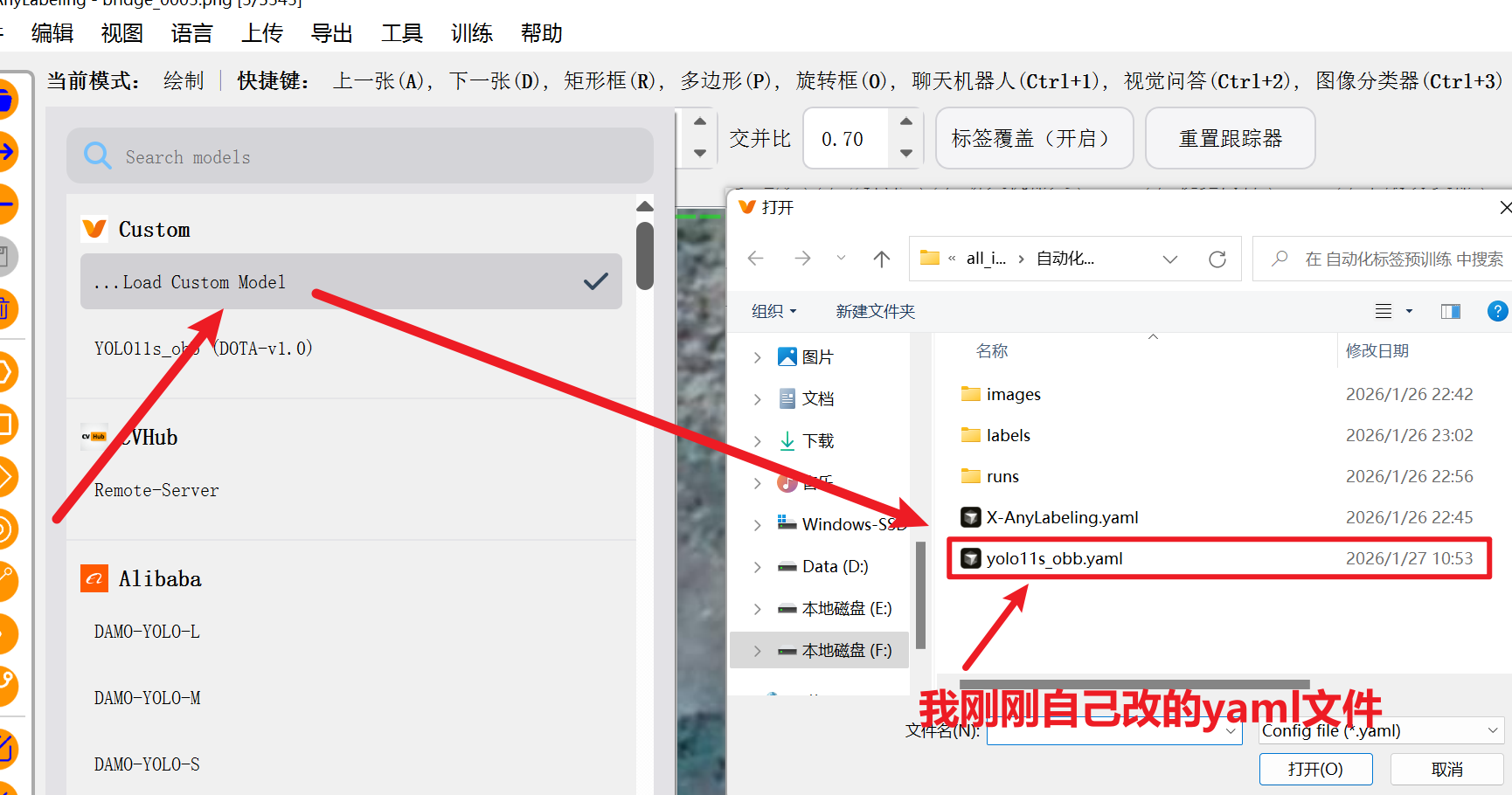
- 然后复制到我们自己的目录,后需要改一下里面的内容
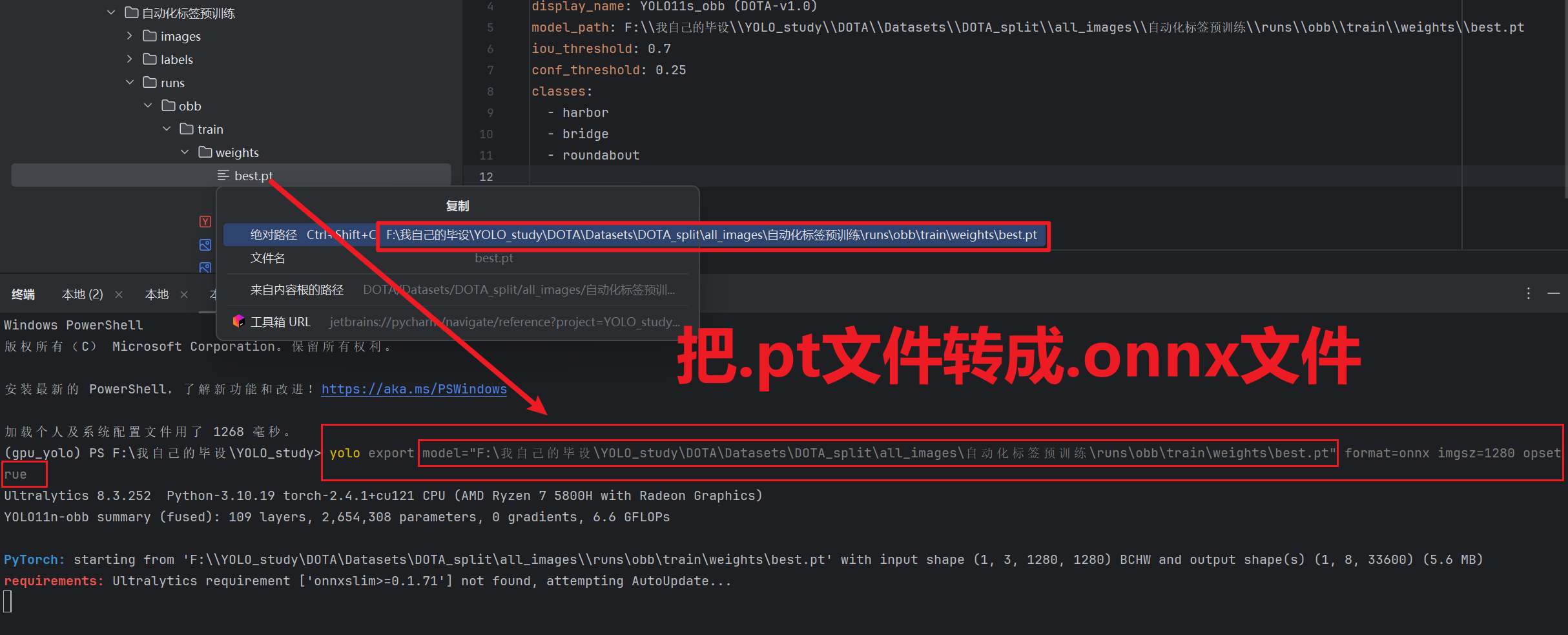
- 第二个文件就是【.onnx】文件
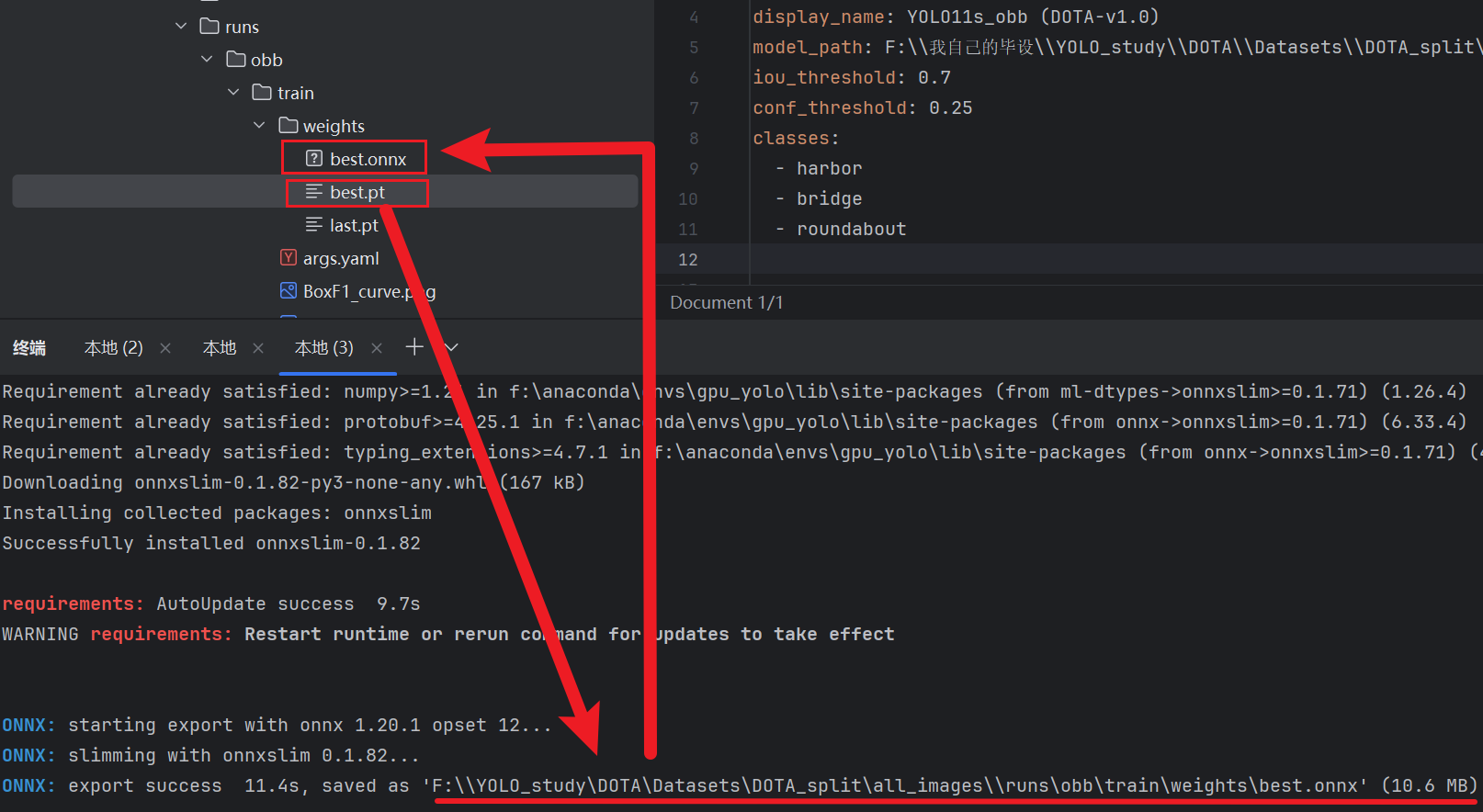
- 这个死人软件不支持【.pt】文件模型,所以我们必须先把【.pt】模型转成【.onnx】格式,到终端输入下面指令
yolo export model="我们刚刚预训练的模型.pt文件路径" format=onnx imgsz=和训练的时候的尺寸一致 opsetrue- 现在就可以修改刚刚的yaml文件了
然后大功告成,回到工具导入模型
3、还可以【脚本】进行数据前置准备
记住这些脚本要适配你们的项目是需要改动的,自己复制到豆包问一下怎么改
1)如果不确定数据集要怎么划分【训练集】、【验证集】....
可以用下面这个脚本,把里面的细节改成你自己的要求的,具体含义自己问AI
import os, shutil, random
from tqdm import tqdm
"""
标注文件是yolo格式(txt文件)
训练集:验证集:测试集 (7:2:1)
"""
def split_img(img_path, label_path, split_list):
try:
Data = '.'
# Data是你要将要创建的文件夹路径(路径一定是相对于你当前的这个脚本而言的)
# os.mkdir(Data)
train_img_dir = Data + '/images/train'
val_img_dir = Data + '/images/val'
test_img_dir = Data + '/images/test'
train_label_dir = Data + '/labels/train'
val_label_dir = Data + '/labels/val'
test_label_dir = Data + '/labels/test'
# 创建文件夹
os.makedirs(train_img_dir)
os.makedirs(train_label_dir)
os.makedirs(val_img_dir)
os.makedirs(val_label_dir)
os.makedirs(test_img_dir)
os.makedirs(test_label_dir)
except:
print('文件目录已存在')
train, val, test = split_list
all_img = os.listdir(img_path)
all_img_path = [os.path.join(img_path, img) for img in all_img]
# all_label = os.listdir(label_path)
# all_label_path = [os.path.join(label_path, label) for label in all_label]
train_img = random.sample(all_img_path, int(train * len(all_img_path)))
train_img_copy = [os.path.join(train_img_dir, img.split('\\')[-1]) for img in train_img]
train_label = [toLabelPath(img, label_path) for img in train_img]
train_label_copy = [os.path.join(train_label_dir, label.split('\\')[-1]) for label in train_label]
for i in tqdm(range(len(train_img)), desc='train ', ncols=80, unit='img'):
_copy(train_img[i], train_img_dir)
_copy(train_label[i], train_label_dir)
all_img_path.remove(train_img[i])
val_img = random.sample(all_img_path, int(val / (val + test) * len(all_img_path)))
val_label = [toLabelPath(img, label_path) for img in val_img]
for i in tqdm(range(len(val_img)), desc='val ', ncols=80, unit='img'):
_copy(val_img[i], val_img_dir)
_copy(val_label[i], val_label_dir)
all_img_path.remove(val_img[i])
test_img = all_img_path
test_label = [toLabelPath(img, label_path) for img in test_img]
for i in tqdm(range(len(test_img)), desc='test ', ncols=80, unit='img'):
_copy(test_img[i], test_img_dir)
_copy(test_label[i], test_label_dir)
def _copy(from_path, to_path):
shutil.copy(from_path, to_path)
def toLabelPath(img_path, label_path):
img = img_path.split('\\')[-1]
label = img.split('.jpg')[0] + '.txt'
return os.path.join(label_path, label)
if __name__ == '__main__':
img_path = './all_images' # 你的图片存放的路径(路径一定是相对于你当前的这个脚本文件而言的)
label_path = './all_txt' # 你的txt文件存放的路径(路径一定是相对于你当前的这个脚本文件而言的)
split_list = [0.7, 0.2, 0.1] # 数据集划分比例[train:val:test]
split_img(img_path, label_path, split_list)
2)XML、jpg文件同步批量重命名并保存
你可以用我前面提供的【rename】那个批量处理网站,那如果你刚好电脑没网要离线处理,那就可以用这个脚本
import shutil
import os
def copy_and_rename_xml(source_folder, destination_folder, xml_name, new_name):
source_path = os.path.join(source_folder, xml_name)
destination_path = os.path.join(destination_folder, new_name)
# 复制并重命名XML文件
shutil.copy(source_path, destination_path)
def copy_and_rename_jpg(source_folder, destination_folder, jpg_name, new_name):
source_path = os.path.join(source_folder, jpg_name)
destination_path = os.path.join(destination_folder, new_name)
# 复制并重命名 JPG 文件
shutil.copy(source_path, destination_path)
def create_folder_if_not_exists(folder_name):
# 检查文件夹是否存在
if not os.path.exists(folder_name):
# 如果不存在,则创建文件夹
os.makedirs(folder_name)
print(f"文件夹 '{folder_name}' 创建成功.")
else:
print(f"文件夹 '{folder_name}' 已经存在.")
if __name__ == '__main__':
base_image_path = 'all_images'
base_xml_path = 'all_xml'
save_image_path = 'all_images2'
save_xml_path = 'all_xml2'
prefix = 'obj'
create_folder_if_not_exists(save_image_path)
create_folder_if_not_exists(save_xml_path)
items = os.listdir(base_image_path)
i = 100000
for item in items:
image_name = item
xml_name = item[:-4] + '.xml'
new_image_name = prefix + '_' + str(i) + '.jpg'
new_xml_name = prefix + '_' + str(i) + '.xml'
copy_and_rename_jpg(base_image_path, save_image_path, image_name, new_image_name)
copy_and_rename_xml(base_xml_path,save_xml_path, xml_name, new_xml_name)
i = i + 1
3)xml文件和txt文件互转
xml转txt
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import copy
from lxml.etree import Element, SubElement, tostring, ElementTree
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
from PIL import Image
import numpy as np
classes = ['crazing', 'inclusion', 'patches', 'pitted_surface', 'rolled-in_scale', 'scratches'] # 类别
CURRENT_DIR = os.path.dirname(os.path.abspath(__file__))
def convert(size, box):
dw = 1. / size[0]
dh = 1. / size[1]
x = (box[0] + box[1]) / 2.0
y = (box[2] + box[3]) / 2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
x = np.clip(x, 0, 1)
y = np.clip(y, 0, 1)
w = np.clip(w, 0, 1)
h = np.clip(h, 0, 1)
return (x, y, w, h)
def convert_annotation(image_id, xml_path, txt_path):
in_file = open(xml_path + '/%s.xml' % (image_id), encoding='UTF-8')
out_file = open(txt_path + '/%s.txt' % (image_id), 'w') # 生成txt格式文件
tree = ET.parse(in_file)
root = tree.getroot()
# size = root.find('size')
#
# w = int(size.find('width').text)
# h = int(size.find('height').text)
img_path = './all_images/' + str(image_id) + ".jpg"
img = Image.open(img_path)
w = img.width # 图片的宽
h = img.height # 图片的高
for obj in root.iter('object'):
cls = obj.find('name').text
# print(cls)
if cls not in classes:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
if __name__ == '__main__':
my_xml_path = './all_xml'
my_txt_path = './all_txt'
if not os.path.exists(my_txt_path):
os.mkdir(my_txt_path)
xml_path = os.path.join(CURRENT_DIR, './all_xml/')
# xml list
img_xmls = os.listdir(xml_path)
for img_xml in img_xmls:
label_name = img_xml.split('.')[0]
print(label_name)
convert_annotation(label_name,my_xml_path,my_txt_path)
txt转xml
# .txt-->.xml
# ! /usr/bin/python
# -*- coding:UTF-8 -*-
import os
import cv2
def txt_to_xml(txt_path, img_path, xml_path):
# 1.字典对标签中的类别进行转换
dict = {}
classes = ['pl40', 'p26', 'pne', 'i5', 'po', 'p5'] # 类别
for i in range(0, len(classes)):
dict.update({str(i): classes[i]})
print(dict)
# 2.找到txt标签文件夹
files = os.listdir(txt_path)
# 用于存储 "老图"
pre_img_name = ''
# 3.遍历文件夹
for i, name in enumerate(files):
# 许多人文件夹里有该文件,默认的也删不掉,那就直接pass
if name == "desktop.ini":
continue
# print(name)
# 4.打开txt
txtFile = open(txt_path + name, encoding='utf-8')
# 读取所有内容
txtList = txtFile.readlines()
# 读取图片名称
img_name = name.split(".")[0]
pic = cv2.imread(img_path + img_name + ".jpg")
# 获取图像大小信息
Pheight, Pwidth, Pdepth = pic.shape
# 5.遍历txt文件中每行内容
if len(txtList)==0:
txtFile.close()
os.remove(txt_path + name)
os.remove(img_path + img_name + ".jpg")
for row in txtList:
# 按' '分割txt的一行的内容
oneline = row.strip().split(" ")
# 遇到的是一张新图片
if img_name != pre_img_name:
# 6.新建xml文件
xml_file = open((xml_path + img_name + '.xml'), 'w', encoding='utf-8')
xml_file.write('<annotation>\n')
xml_file.write(' <folder>VOC2007</folder>\n')
xml_file.write(' <filename>' + img_name + '.jpg' + '</filename>\n')
xml_file.write('<source>\n')
xml_file.write('<database>orgaquant</database>\n')
xml_file.write('<annotation>organoids</annotation>\n')
xml_file.write('</source>\n')
xml_file.write(' <size>\n')
xml_file.write(' <width>' + str(Pwidth) + '</width>\n')
xml_file.write(' <height>' + str(Pheight) + '</height>\n')
xml_file.write(' <depth>' + str(Pdepth) + '</depth>\n')
xml_file.write(' </size>\n')
xml_file.write(' <object>\n')
xml_file.write('<name>' + dict[oneline[0]] + '</name>\n')
xml_file.write(' <bndbox>\n')
xml_file.write(' <xmin>' + str(
int(((float(oneline[1])) * Pwidth + 1) - (float(oneline[3])) * 0.5 * Pwidth)) + '</xmin>\n')
xml_file.write(' <ymin>' + str(
int(((float(oneline[2])) * Pheight + 1) - (float(oneline[4])) * 0.5 * Pheight)) + '</ymin>\n')
xml_file.write(' <xmax>' + str(
int(((float(oneline[1])) * Pwidth + 1) + (float(oneline[3])) * 0.5 * Pwidth)) + '</xmax>\n')
xml_file.write(' <ymax>' + str(
int(((float(oneline[2])) * Pheight + 1) + (float(oneline[4])) * 0.5 * Pheight)) + '</ymax>\n')
xml_file.write(' </bndbox>\n')
xml_file.write(' </object>\n')
xml_file.close()
pre_img_name = img_name # 将其设为"老"图
else: # 不是新图而是"老图"
# 7.同一张图片,只需要追加写入object
xml_file = open((xml_path + img_name + '.xml'), 'a', encoding='utf-8')
xml_file.write(' <object>\n')
xml_file.write('<name>' + dict[oneline[0]] + '</name>\n')
''' 按需添加这里和上面
xml_file.write(' <pose>Unspecified</pose>\n')
xml_file.write(' <truncated>0</truncated>\n')
xml_file.write(' <difficult>0</difficult>\n')
'''
xml_file.write(' <bndbox>\n')
xml_file.write(' <xmin>' + str(
int(((float(oneline[1])) * Pwidth + 1) - (float(oneline[3])) * 0.5 * Pwidth)) + '</xmin>\n')
xml_file.write(' <ymin>' + str(
int(((float(oneline[2])) * Pheight + 1) - (float(oneline[4])) * 0.5 * Pheight)) + '</ymin>\n')
xml_file.write(' <xmax>' + str(
int(((float(oneline[1])) * Pwidth + 1) + (float(oneline[3])) * 0.5 * Pwidth)) + '</xmax>\n')
xml_file.write(' <ymax>' + str(
int(((float(oneline[2])) * Pheight + 1) + (float(oneline[4])) * 0.5 * Pheight)) + '</ymax>\n')
xml_file.write(' </bndbox>\n')
xml_file.write(' </object>\n')
xml_file.close()
# 8.读完txt文件最后写入</annotation>
xml_file1 = open((xml_path + pre_img_name + '.xml'), 'a', encoding='utf-8')
xml_file1.write('</annotation>')
xml_file1.close()
print("Done !")
if __name__ == '__main__':
txt_path = "./all_txt/"
image_path = "./all_images/"
xml_path = "./all_xml/"
if not os.path.exists(xml_path):
os.mkdir(xml_path)
# 修改成自己的文件夹 注意文件夹最后要加上/
txt_to_xml(txt_path, image_path, xml_path)
txt_to_xml(txt_path, image_path, xml_path)
4)OBJ转换为JPG格式的RGB图
from PIL import Image
import os
def trans_one_dir(input_folder, output_folder):
# 设置原始图片文件夹和新文件夹的路径
# input_folder = './cutton'
# output_folder = 'new'
# 如果新文件夹不存在,创建它
if not os.path.exists(output_folder):
os.makedirs(output_folder)
# 获取原始图片文件夹中的所有文件
image_files = os.listdir(input_folder)
# 遍历每个图片文件
for image_file in image_files:
# 构建原始图片文件的完整路径
input_path = os.path.join(input_folder, image_file)
# 读取原始图片
original_image = Image.open(input_path)
# 构建新图片文件的完整路径,将文件格式改为JPG
output_path = os.path.join(output_folder, os.path.splitext(image_file)[0] + '.jpg')
# 保存新图片为JPG格式
original_image.convert('RGB').save(output_path, 'JPEG')
print('图片转换完成,保存在' + output_folder + '文件夹中')
def trans_mu_dir(input_folder, output_folder):
# 如果新文件夹不存在,创建它
if not os.path.exists(output_folder):
os.makedirs(output_folder)
# 获取原始图片文件夹中的所有文件
dir_lists = os.listdir(input_folder)
for dir_one in dir_lists:
dir_path = input_folder + '/' + dir_one
out_path = output_folder + '/' + dir_one
# print(dir_path)
# print(out_path)
trans_one_dir(dir_path, out_path)
if __name__ == '__main__':
input_folder = 'all_images'
output_folder = 'all_images2'
trans_one_dir(input_folder,output_folder)5)数据增强_扩充数据量
import os
from random import sample
import numpy as np
from PIL import Image, ImageDraw
from utils.random_data import get_random_data, get_random_data_with_MixUp
from utils.utils import convert_annotation, get_classes
#-----------------------------------------------------------------------------------#
# Origin_VOCdevkit_path 原始数据集所在的路径
# Out_VOCdevkit_path 输出数据集所在的路径
#-----------------------------------------------------------------------------------#
Origin_VOCdevkit_path = "VOCdevkit_Origin"
Out_VOCdevkit_path = "VOCdevkit"
#-----------------------------------------------------------------------------------#
# Out_Num 生成多少组图片
# input_shape 生成的图片大小
#-----------------------------------------------------------------------------------#
Out_Num = 1800
input_shape = [640, 640]
#-----------------------------------------------------------------------------------#
# 下面定义了xml里面的组成模块,无需改动。
#-----------------------------------------------------------------------------------#
headstr = """\
<annotation>
<folder>VOC</folder>
<filename>%s</filename>
<source>
<database>My Database</database>
<annotation>COCO</annotation>
<image>flickr</image>
<flickrid>NULL</flickrid>
</source>
<owner>
<flickrid>NULL</flickrid>
<name>company</name>
</owner>
<size>
<width>%d</width>
<height>%d</height>
<depth>%d</depth>
</size>
<segmented>0</segmented>
"""
objstr = """\
<object>
<name>%s</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>%d</xmin>
<ymin>%d</ymin>
<xmax>%d</xmax>
<ymax>%d</ymax>
</bndbox>
</object>
"""
tailstr = '''\
</annotation>
'''
if __name__ == "__main__":
Origin_JPEGImages_path = os.path.join(Origin_VOCdevkit_path, "VOC2007/JPEGImages")
Origin_Annotations_path = os.path.join(Origin_VOCdevkit_path, "VOC2007/Annotations")
Out_JPEGImages_path = os.path.join(Out_VOCdevkit_path, "VOC2007/JPEGImages")
Out_Annotations_path = os.path.join(Out_VOCdevkit_path, "VOC2007/Annotations")
if not os.path.exists(Out_JPEGImages_path):
os.makedirs(Out_JPEGImages_path)
if not os.path.exists(Out_Annotations_path):
os.makedirs(Out_Annotations_path)
#---------------------------#
# 遍历标签并赋值
#---------------------------#
xml_names = os.listdir(Origin_Annotations_path)
def write_xml(anno_path, jpg_pth, head, input_shape, boxes, unique_labels, tail):
f = open(anno_path, "w")
f.write(head%(jpg_pth, input_shape[0], input_shape[1], 3))
for i, box in enumerate(boxes):
f.write(objstr%(str(unique_labels[int(box[4])]), box[0], box[1], box[2], box[3]))
f.write(tail)
#------------------------------#
# 循环生成xml和jpg
#------------------------------#
for index in range(Out_Num):
#------------------------------#
# 获取一个图像与标签
#------------------------------#
sample_xmls = sample(xml_names, 1)
unique_labels = get_classes(sample_xmls, Origin_Annotations_path)
jpg_name = os.path.join(Origin_JPEGImages_path, os.path.splitext(sample_xmls[0])[0] + '.jpg')
xml_name = os.path.join(Origin_Annotations_path, sample_xmls[0])
line = convert_annotation(jpg_name, xml_name, unique_labels)
#------------------------------#
# 各自数据增强
#------------------------------#
image_data, box_data = get_random_data(line, input_shape)
img = Image.fromarray(image_data.astype(np.uint8))
img.save(os.path.join(Out_JPEGImages_path, "ZZ_random_" + str(index) + '.jpg'))
write_xml(os.path.join(Out_Annotations_path, "ZZ_random_" + str(index) + '.xml'), os.path.join(Out_JPEGImages_path, str(index) + '.jpg'), \
headstr, input_shape, box_data, unique_labels, tailstr)

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 21
21 0
0- 0



 已为社区贡献25条内容
已为社区贡献25条内容

所有评论(0)