别让你的私有大模型死在“实验室”:从散装实验到标准化工程闭环
本文揭示了私有化大模型落地失败的核心原因——缺乏工程闭环,而非技术问题。作者提出标准化实践路径:1) 定义结构化数据契约;2) 通过manifest实现数据版本化;3) 使用Axolotl确保训练可复现;4) 构建回归集作为上线门禁;5) 建立失败样本反馈机制。文章强调模型交付应从"实验室玄学"转为包含数据治理、训练编排、评测验证的工程体系,并提供7天实施清单和验收标准,帮助开
别让你的私有大模型死在“实验室”:从散装实验到标准化工程闭环
引入:为什么 90% 的模型微调项目无法真正交付?
在很多开发者的预期中,微调私有模型的核心挑战在于挑选模型、调整参数或跑通 LoRA。然而,现实的工业落地往往令人沮丧:你可能通过 LoRA 训出了一个效果不错的模型,但当你准备将其部署到生产环境,或者需要针对新的业务数据进行迭代时,混乱随之而来——无法稳定复现效果、上线后发现异常却无法安全回滚、模型表现下滑却找不到是哪一版数据或哪组超参导致的。
你陷入了“散装实验”的泥潭。作为架构师,我必须直言:你缺的不是训练技巧,而是工程闭环。 如果模型训练不能从“实验室玄学”转化为一套标准化的生产流水线,那么你的私有化落地注定只能靠运气。
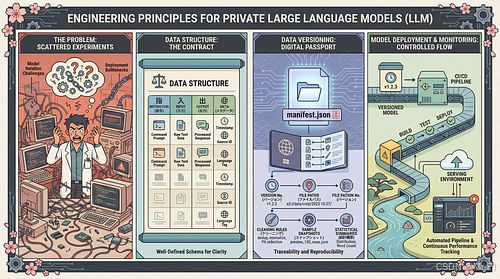
1:模型训练不是“语料收集”,而是构建“可训练的契约”
在工程化视角下,你训练的并不是杂乱无章的“语料”,而是具体的“任务行为”。
很多项目失败的第一步就是直接将乱序文本塞进模型。真正的工程化实践要求在采集阶段就定义好数据 Schema。一个标准化的数据结构(契约)至少应包含以下字段:
- instruction:明确用户要求模型执行的任务指令。
- input:提供任务所需的上下文或背景材料。
- output:期望模型给出的标准回答(包含格式要求)。
- meta:记录来源、时间戳、权限域、语言、质量评分等元数据。
工程铁律:数据不结构化,模型就不稳定;模型不稳定,上线就只能靠运气。
只有先确立数据契约,确保任务行为受控,才能谈后续的稳定性。
2:没有 manifest 的数据,就是一次性耗材
训练失败并不可怕,可怕的是你无法定位失败的原因。在工程闭环中,数据版本化是不可逾越的基石。
每一批次进入训练流程的数据都必须携带一个 manifest.json 文件。这个文件是数据的“身份证”,也是实现“模型可追溯”和“稳定复现”的唯一路径。它必须包含:
- 版本号:采用语义化版本(如 v1.2.0)。
- 来源:记录原始文件路径、URL 或数据库索引。
- 清洗规则:对应的数据清洗脚本 commit ID。
- 抽样快照:固定抽取的(如 200 条)用于快速回归验证的样本。
- 统计摘要:样本总数、语言占比、平均 Token 长度、重复率等特征。
有了这个清单,数据就不再是随用随丢的耗材,而是具备审计价值的工程资产。
3:追求“最强配方”是误区,先拿到“可复现配方”
在实验阶段,开发者往往执着于寻找能让 loss 降到最低的“神仙参数”。但在生产环境下,一致性远比上限重要。
我们推荐使用 Axolotl 作为训练编排层。它的核心价值在于将数据加载、训练策略(SFT、QLoRA、DPO/ORPO)统一在配置体系内。为了通过架构评审,每次训练任务必须产出最小可复现三件套(Artifacts):
- config.yaml:完整的训练配置原文。
- data_manifest.json:对应的训练数据版本与统计快照。
- run_report.md:包含 loss 曲线、关键指标变化及实验结论。
没有这三件套,任何一次训练都只是不可复制的偶然事件,无法进入交付环节。
4:没有回归集,模型上线本质上是在“赌博”
模型训好了就能上线吗?如果没有回归集(Regression Set),你的上线决策就是一场豪赌。
评测体系应分为两个维度:
- 质量指标:格式合格率、事实一致性、禁词命中率。
- 工程指标:延迟 P95、吞吐量 (tokens/s)、显存占用。
为了确保模型不退化,必须构建一个包含 50 条用例的“门禁回归集”:
- 20 条常见需求:覆盖 80% 以上的主路径场景。
- 20 条难例:包含长上下文、存在逻辑冲突的材料等极端情况。
- 10 条对抗例:专门用于诱导越权、编造事实的陷阱题。
上线门禁(验收阈值): 结构合格率 ≥ 0.95,敏感禁词命中 = 0。回归集关键用例应为 0 失败(可容忍极少数 minor leaks,但在下个迭代必须修复)。
5:上线后的“失败样本库”才是最值钱的资产
闭环的终点不是上线,而是反馈的回流。
私有模型最大的护城河不是算法,而是线上产生的真实错误。你应该构建一个“线上 -> 反馈 -> 再训练 -> 再上线”的持续进化体系:
- 失败样本库:收集用户纠正的表达、幻觉场景,用于下一次 SFT 修复格式与事实错误。
- 偏好对(Chosen/Rejected):利用用户反馈构建偏好数据,通过 DPO 或 ORPO(比 DPO 更高效的偏好对齐技术)压制 AI 的啰嗦或不合规风格。
真正的私有模型,是被失败样本“喂”出来的。
6:7 天跑通闭环骨架的实战路径
要把上述理念转化为生产力,可以参考以下 7 天落地清单:
- Day 1:定义交付标准。定义数据 Schema,编写 manifest.json 模板。
- Day 2:数据结构化。准备首批 500 条高质量指令数据,优先训练模型“讲规矩”。
- Day 3:基准训练。使用 Axolotl 跑通 QLoRA SFT,产出第一个模型资产。
- Day 4:评测体系构建。编写 50 条回归集用例及自动化评测脚本。
- Day 5:服务工程化。使用 vLLM 搭建 OpenAI 兼容的推理接口,实现应用侧零代码切换。
- Day 6:统一入口集成。通过 RunPod Serverless 调通 /runsync 同步推理入口,作为鉴权、限流与日志的统一网关。
- Day 7:版本治理。在 Weights & Biases (W&B) 这个“版本中枢”上,关联 Run 指标、Report 和 Artifact 产物版本。
闭环验收清单(建议贴到项目 README)
作为一名合格的 AI 架构师,在模型上线前,请对照此清单进行最终核验:
- manifest.json 存在:含数据来源、清洗规则 commit ID 及统计快照。
- config.yaml 存在:训练配方可一键复现。
- eval_regression.jsonl 存在:固定回归集用例 ≥ 50 条。
- eval_report.md 存在:包含新老版本指标对比及上线结论。
- vLLM 兼容性验证:OpenAI 兼容接口健康检查通过。
- RunPod /runsync 调通:具备稳定的同步推理调用能力。
- W&B 治理完备:可随时回滚到任意一个 Run、Artifact 或 Report 版本。
结尾:从玄学走向工程
私有大模型的落地不再是比拼谁的 GPU 更多,而是比拼谁的工程化程度更高。当你的模型能够基于 manifest.json 溯源,通过回归集验证,并依靠线上失败样本自动回流迭代时,你才真正拥有一套可持续进化的智能系统。
从“实验心态”转向“工程心态”是每个 AI 开发者的必修课。你的下一个模型训练任务,是准备继续在 Notebook 里“碰运气”,还是开始构建一套能自动迭代的闭环系统?

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 5
5 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)