基于改进YOLOv8 钢材损害目标检测识别系统-【完整代码数据可直接运行】
基于改进YOLOv8 钢材损害目标检测识别系统-【完整代码数据可直接运行】
·
视频讲解:
https://www.bilibili.com/video/BV1nFrxBCEnr/
运行结果:

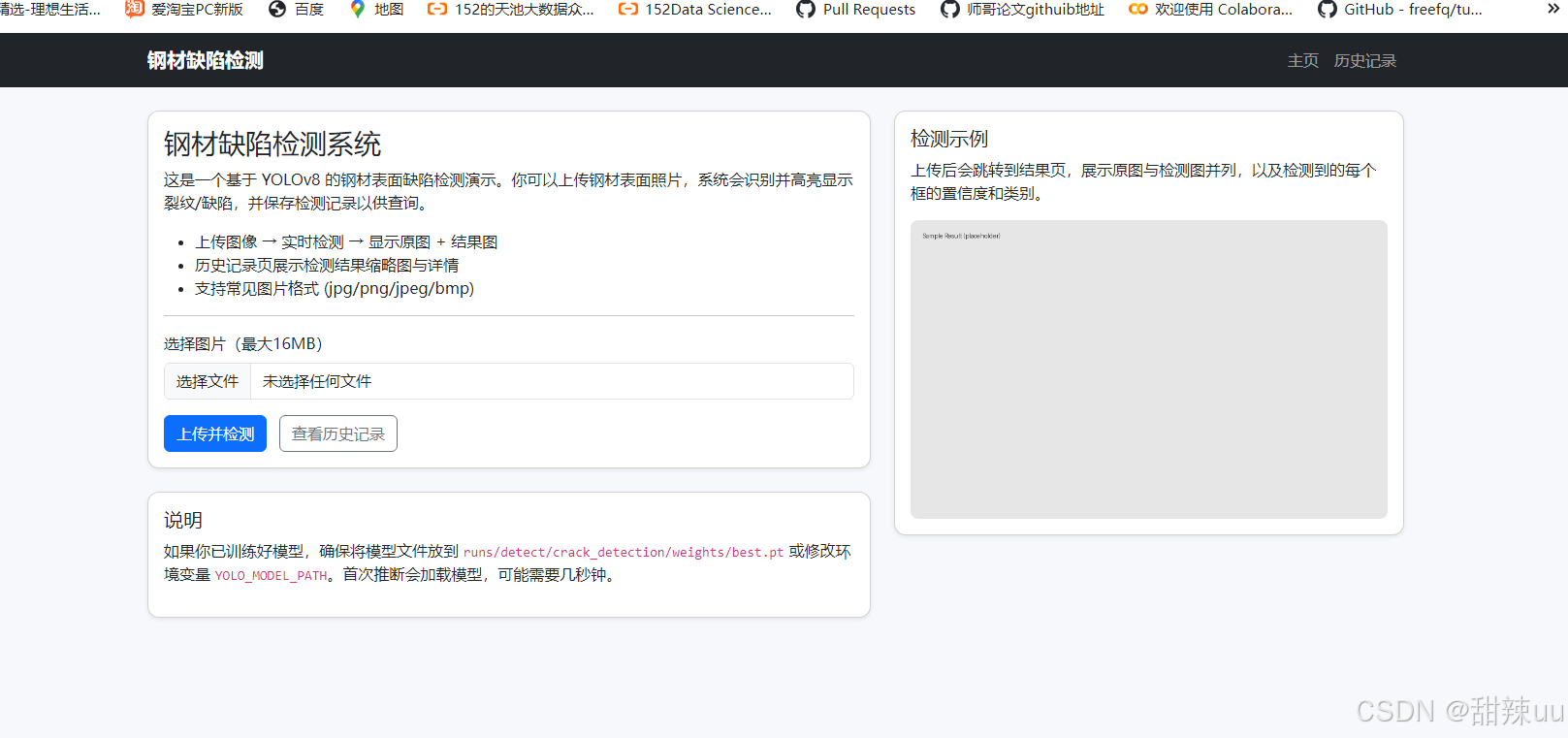
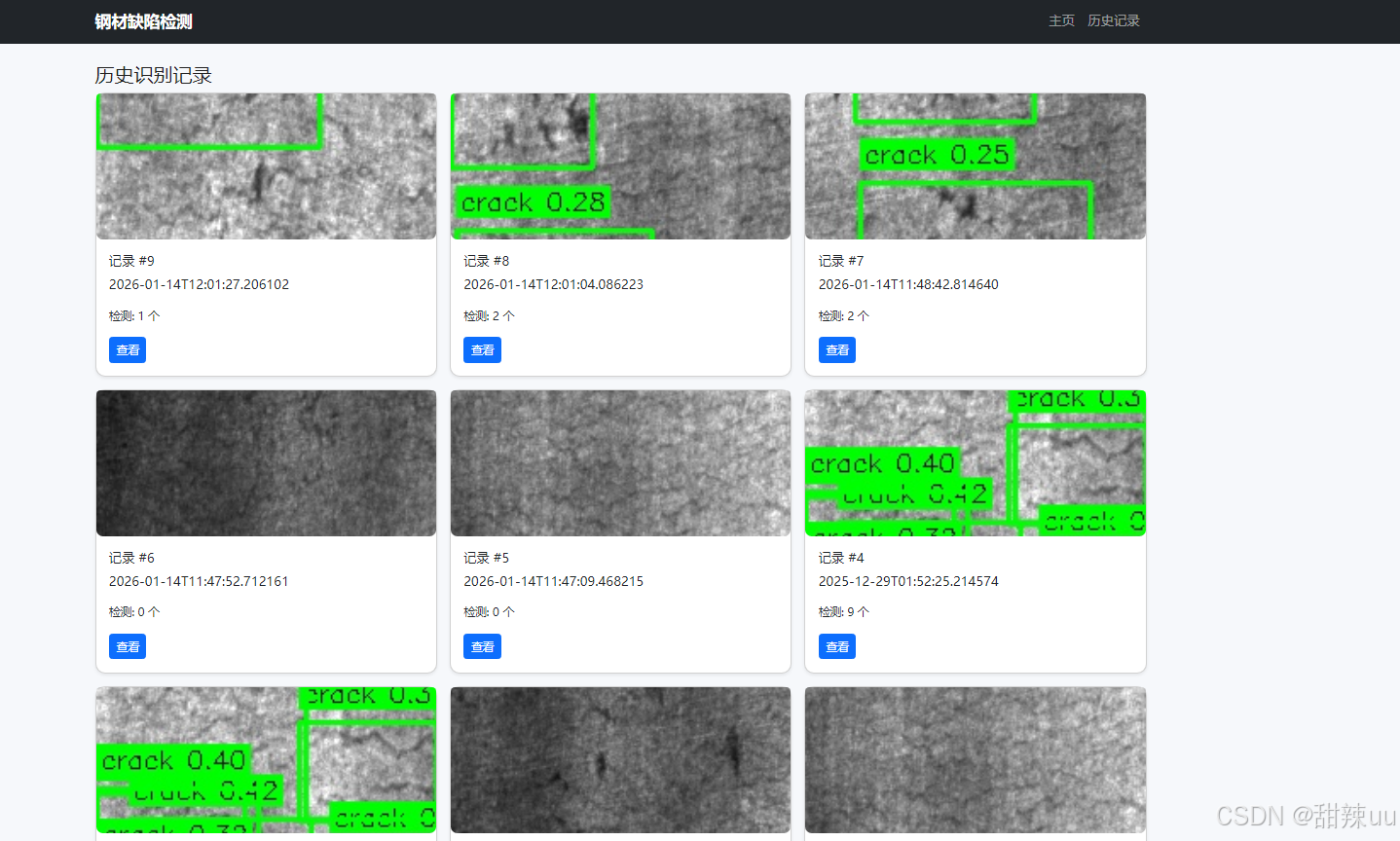
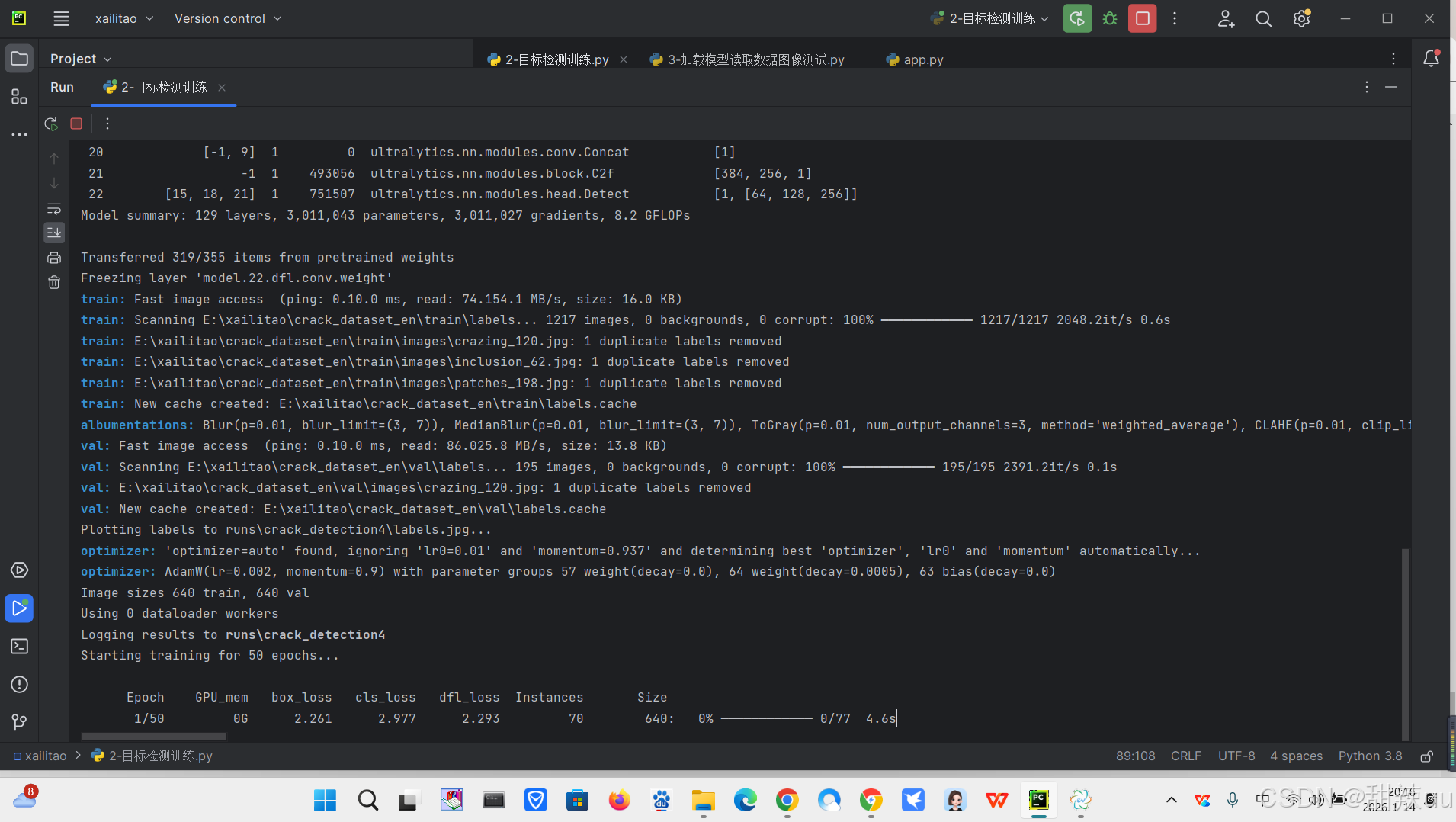
代码:
import os
import shutil
import random
import cv2
import xml.etree.ElementTree as ET
import numpy as np
import torch
from ultralytics import YOLO
# ================== 修复路径问题(添加调试信息) ==================
# 获取当前工作目录
current_dir = os.path.abspath(os.getcwd())
print(f"✅ 当前工作目录: {current_dir}")
# 检查当前目录下的文件和文件夹
print("\n📁 当前目录内容:")
for item in os.listdir(current_dir):
print(f" - {item}")
# ================== 配置区域(请根据实际修改) ==================
# 您的原始数据路径(现在使用绝对路径)
# 修改为您的实际数据集路径,例如:E:\xailitao\data
# 如果数据集在当前目录下,可以保留为"JPEGImages"和"Annotations"
# 如果数据集在其他位置,请提供完整路径
ORIGINAL_IMAGES_DIR = "VOC2007/JPEGImages" # 图像文件夹
ORIGINAL_ANNOTATIONS_DIR = "VOC2007/Annotations" # XML标注文件夹
# 检查文件夹是否存在
if not os.path.exists(os.path.join(current_dir, ORIGINAL_IMAGES_DIR)):
print(f"\n❌ 错误: 找不到图像文件夹: {ORIGINAL_IMAGES_DIR}")
print("请确认以下几点:")
print("1. 数据集文件夹是否在当前目录下?")
print("2. 文件夹名称是否正确?(注意大小写)")
print("3. 如果数据集在其他位置,请修改代码中的路径")
print(f" 例如: ORIGINAL_IMAGES_DIR = 'E:/xailitao/JPEGImages'")
print("4. 当前目录下实际文件夹列表:")
for item in os.listdir(current_dir):
print(f" - {item}")
exit(1)
if not os.path.exists(os.path.join(current_dir, ORIGINAL_ANNOTATIONS_DIR)):
print(f"\n❌ 错误: 找不到标注文件夹: {ORIGINAL_ANNOTATIONS_DIR}")
print("请确认以下几点:")
print("1. 数据集文件夹是否在当前目录下?")
print("2. 文件夹名称是否正确?(注意大小写)")
print("3. 如果标注文件夹在其他位置,请修改代码中的路径")
print("4. 当前目录下实际文件夹列表:")
for item in os.listdir(current_dir):
print(f" - {item}")
exit(1)
# ===========================================================
# ================== 确保使用纯英文路径(终极修复) ==================
# 创建英文路径的临时数据集目录(在当前工作目录下创建英文文件夹)
ENGLISH_DATASET_DIR = "crack_dataset_en" # 纯英文目录名
DATASET_DIR = os.path.join(current_dir, ENGLISH_DATASET_DIR)
# 确保临时目录存在
os.makedirs(DATASET_DIR, exist_ok=True)
# 创建数据集子目录
for sub_dir in ["train/images", "train/labels", "val/images", "val/labels", "labels_txt"]:
os.makedirs(os.path.join(DATASET_DIR, sub_dir), exist_ok=True)
# =================================================================
# ================== 数据集转换函数 ==================
def convert_voc_to_yolo(xml_path, img_path, output_dir):
"""
将Pascal VOC XML标注转换为YOLO格式的txt文件
参数:
xml_path (str): XML文件路径
img_path (str): 对应的图像文件路径
output_dir (str): 输出目录(labels_txt)
"""
# 解析XML
tree = ET.parse(xml_path)
root = tree.getroot()
# 获取图像尺寸
size = root.find('size')
width = int(size.find('width').text)
height = int(size.find('height').text)
# 提取边界框信息
bboxes = []
for obj in root.findall('object'):
name = obj.find('name').text
bbox = obj.find('bndbox')
xmin = int(bbox.find('xmin').text)
ymin = int(bbox.find('ymin').text)
xmax = int(bbox.find('xmax').text)
ymax = int(bbox.find('ymax').text)
# 计算YOLO格式坐标(归一化)
x_center = (xmin + xmax) / 2.0 / width
y_center = (ymin + ymax) / 2.0 / height
bbox_width = (xmax - xmin) / width
bbox_height = (ymax - ymin) / height
# 由于我们只有一个类别(crack),类别ID为0
class_id = 0
bboxes.append([class_id, x_center, y_center, bbox_width, bbox_height])
# 保存为YOLO格式txt
output_file = os.path.join(output_dir, os.path.splitext(os.path.basename(img_path))[0] + '.txt')
with open(output_file, 'w') as f:
for bbox in bboxes:
f.write(f"{bbox[0]} {bbox[1]:.6f} {bbox[2]:.6f} {bbox[3]:.6f} {bbox[4]:.6f}\n")
# ================== 转换所有XML标注为YOLO格式 ==================
print("\n🔄 正在转换标注文件...")
xml_files = [f for f in os.listdir(os.path.join(current_dir, ORIGINAL_ANNOTATIONS_DIR)) if f.endswith('.xml')]
for xml_file in xml_files:
xml_path = os.path.join(current_dir, ORIGINAL_ANNOTATIONS_DIR, xml_file)
img_file = os.path.splitext(xml_file)[0] + '.jpg' # 假设图像为.jpg
img_path = os.path.join(current_dir, ORIGINAL_IMAGES_DIR, img_file)
if os.path.exists(img_path):
convert_voc_to_yolo(xml_path, img_path, os.path.join(DATASET_DIR, "labels_txt"))
else:
print(f"⚠️ 警告: 图像文件 {img_file} 不存在,跳过 {xml_file}")
print(f"✅ 已转换 {len(xml_files)} 个标注文件到 YOLO 格式")
# 获取所有有效图像文件
image_files = [
f for f in os.listdir(os.path.join(current_dir, ORIGINAL_IMAGES_DIR))
if f.lower().endswith(('.jpg', '.jpeg', '.png'))
]
# 筛选有对应标签的图像
valid_files = []
for img_file in image_files:
base_name = os.path.splitext(img_file)[0]
label_file = f"{base_name}.txt"
if os.path.exists(os.path.join(DATASET_DIR, "labels_txt", label_file)):
valid_files.append((img_file, label_file))
# 检查有效样本数
if len(valid_files) < 10: # 最小样本数设为10
print(f"\n⚠️ 警告:仅找到 {len(valid_files)} 个有效样本,将使用全部样本")
NUM_SAMPLES = len(valid_files)
else:
NUM_SAMPLES = 500 # 总样本数
# 随机选择样本
if len(valid_files) > 0:
selected_files = random.sample(valid_files, min(NUM_SAMPLES, len(valid_files)))
train_files = selected_files[:int(len(selected_files) * 0.9)]
val_files = selected_files[int(len(selected_files) * 0.9):]
else:
print("\n❌ 错误: 没有找到有效的样本文件,无法继续训练")
exit(1)
# 复制到英文路径数据集
print("\n📁 正在组织数据集...")
for img_file, label_file in train_files:
shutil.copy(os.path.join(current_dir, ORIGINAL_IMAGES_DIR, img_file),
os.path.join(DATASET_DIR, "train/images", img_file))
shutil.copy(os.path.join(DATASET_DIR, "labels_txt", label_file),
os.path.join(DATASET_DIR, "train/labels", label_file))
for img_file, label_file in val_files:
shutil.copy(os.path.join(current_dir, ORIGINAL_IMAGES_DIR, img_file),
os.path.join(DATASET_DIR, "val/images", img_file))
shutil.copy(os.path.join(DATASET_DIR, "labels_txt", label_file),
os.path.join(DATASET_DIR, "val/labels", label_file))
# 生成数据集配置文件 (dataset.yaml)
yaml_content = f"""
path: {DATASET_DIR}
train: train/images
val: val/images
nc: 1 # 裂缝通常为1类
names: ['crack'] # 类别名称
"""
with open(os.path.join(DATASET_DIR, "dataset.yaml"), "w") as f:
f.write(yaml_content)
print(f"\n✅ 数据集准备完成!(使用纯英文路径)\n"
f" - 总样本: {len(valid_files)}\n"
f" - 训练集: {len(train_files)} 个\n"
f" - 验证集: {len(val_files)} 个\n"
f" - 配置文件: {os.path.join(DATASET_DIR, 'dataset.yaml')}\n")
# ================== 开始训练(自动检测GPU/CPU) ==================
print("\n🚀 正在使用YOLOv8n进行训练(自动检测设备)...")
print("⚠️ 注意:首次运行会自动下载预训练模型(约100MB),请保持网络畅通")
# 自动检测设备
device = 'cuda' if torch.cuda.is_available() else 'cpu'
print(f"🔍 检测到设备: {device} {'(GPU)' if device == 'cuda' else '(CPU)'}")
# 重要修复:使用绝对路径并确保路径是纯英文
data_path = os.path.join(DATASET_DIR, "dataset.yaml")
print(f"🔍 正在使用数据路径: {data_path}")
# 确保路径是纯英文,没有中文字符
data_path = os.path.normpath(data_path) # 规范化路径
data_path = data_path.replace("\\", "/") # 确保使用正斜杠
# 加载预训练模型并训练
model = YOLO('yolov8n.pt')
# 训练参数(小数据集优化)
results = model.train(
data=data_path,
epochs=50, # 小数据集建议多训练
imgsz=640, # 图像尺寸
batch=16, # 小数据集建议小batch
name='crack_detection',
project='runs',
device=device # 自动使用CPU/GPU
)
print("\n✅ 训练完成!结果保存在:")
print(f" - 模型: {os.path.abspath('runs/detect/crack_detection/weights/best.pt')}")
print(" - 训练曲线: runs/detect/crack_detection/results.png")
print(" - 预测示例: runs/detect/crack_detection/val_batch0_pred.jpg")
print("\n💡 提示:训练时间约10-30分钟(CPU环境),请耐心等待")
腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 3
3 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)