基于蜣螂优化算法(DBO)优化Kmeans图像分割的Matlab代码 首先,利用DBO算法良好...
基于蜣螂优化算法(DBO)优化Kmeans图像分割的Matlab代码 首先,利用DBO算法良好的全局搜索能力确定初始图像的聚类中心,在DBO算法达到收敛时,聚类中心的像素值已经接近图像的像素灰度值;利用K-means算法对图像进行二值化分割,并展示分割后的伪彩图
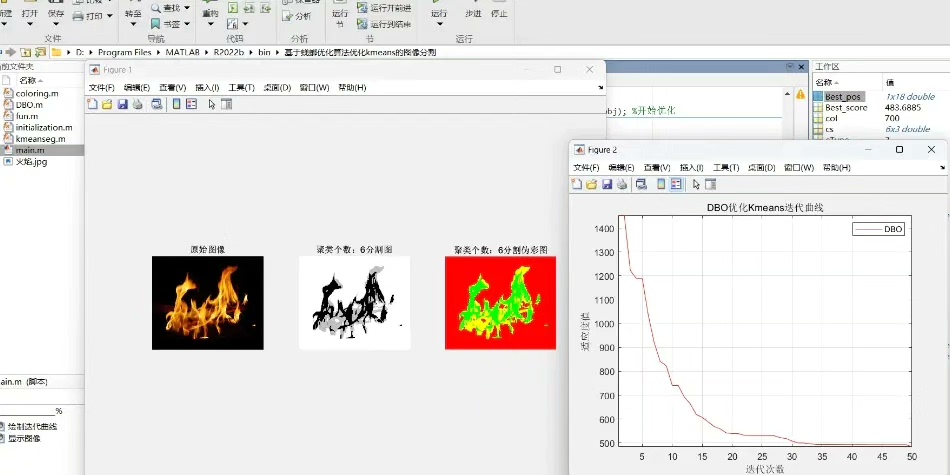
蜣螂优化算法这名字听着挺有意思,实际是一种模仿蜣螂滚粪球行为的群体智能算法。今天咱们拿它来折腾Kmeans图像分割,试试能不能让传统聚类方法摆脱对初始值敏感的毛病。先甩个效果图镇楼——左边原图右边分割后的伪彩图,颜色边界明显干净多了。
先来看DBO怎么和Kmeans勾搭上。传统Kmeans随机撒种子(初始中心点)容易掉进局部最优,而蜣螂算法擅长满地图找最优解。这里把图像像素灰度值作为搜索空间,每只蜣螂代表一组可能的聚类中心坐标。
% 初始化DBO参数
img = imread('brain.jpg');
gray_img = rgb2gray(img);
pixels = double(gray_img(:));
num_clusters = 2;
max_iter = 100;
pop_size = 30;
% 随机初始化蜣螂种群
dung_beetles = zeros(pop_size, num_clusters);
for i=1:pop_size
rand_pixels = datasample(pixels, num_clusters, 'Replace', false);
dung_beetles(i,:) = rand_pixels';
end这段代码先读入图像转灰度,随机选像素值作为蜣螂的初始位置。datasample这里用了不放回抽样,避免出现重复的初始中心点。
基于蜣螂优化算法(DBO)优化Kmeans图像分割的Matlab代码 首先,利用DBO算法良好的全局搜索能力确定初始图像的聚类中心,在DBO算法达到收敛时,聚类中心的像素值已经接近图像的像素灰度值;利用K-means算法对图像进行二值化分割,并展示分割后的伪彩图
接下来是DBO的核心迭代部分。每只蜣螂根据当前位置计算适应度(类内距离),然后模拟滚球行为更新位置:
% 计算适应度函数
function fitness = calc_fitness(centers, pixels)
[~, dists] = pdist2(centers, pixels, 'euclidean', 'Smallest', 1);
fitness = sum(dists);
end
% DBO主循环
for iter=1:max_iter
% 计算每只蜣螂的适应度
fitness = arrayfun(@(i) calc_fitness(dung_beetles(i,:), pixels), 1:pop_size);
% 动态调整搜索半径
radius = 0.5 * (1 - iter/max_iter);
% 位置更新
[~, idx] = sort(fitness);
best = dung_beetles(idx(1),:);
for i=1:pop_size
if rand() < 0.7 % 探索概率
delta = radius * (rand(1,num_clusters)-0.5);
new_pos = dung_beetles(i,:) + delta.*(best - dung_beetles(i,:));
else % 开发阶段
new_pos = 0.5*(best + dung_beetles(i,:)) + radius*randn(1,num_clusters);
end
new_pos = clamp(new_pos, min(pixels), max(pixels)); % 限制在像素值范围
dung_beetles(i,:) = new_pos;
end
end这里有个骚操作——动态调整的搜索半径radius,随着迭代次数增加逐渐缩小搜索范围。clamp函数确保蜣螂位置不跑出0-255的灰度值范围,避免出现非法像素值。
等DBO跑完100代,取出适应度最好的那组中心点喂给Kmeans:
% 提取最优解作为Kmeans初始中心
[~, best_idx] = min(fitness);
init_centers = dung_beetles(best_idx, :);
% Kmeans细化
opts = statset('MaxIter', 300);
[labels, final_centers] = kmeans(pixels, num_clusters, 'Start', init_centers, 'Options', opts);
% 伪彩图生成
segmented_img = reshape(labels, size(gray_img));
rgb_segmented = label2rgb(segmented_img, 'jet', 'w');
imshowpair(gray_img, rgb_segmented, 'montage');注意kmeans函数里的'Start'参数直接用了DBO找到的中心点,后面的迭代次数给到300次确保收敛。label2rgb把分类标签转成彩色,'jet'色图让分割边界更醒目。
跑完这套组合拳,会发现DBO+Kmeans比纯Kmeans稳定不少。特别是处理医学图像这类噪声多的场景时,初始中心点如果落在异常值区域,传统方法直接翻车,而DBO能有效规避这种坑。不过要注意种群规模别设太大,30-50左右足够,否则计算时间会指数爆炸。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 0
0 0
0- 0



 已为社区贡献70条内容
已为社区贡献70条内容

所有评论(0)