有关PaddleSeg训练时出现:ValueError: all input arrays must have the same shape
本文记录了在使用百度飞桨平台进行图像分割训练时遇到的问题及解决方法。作者在自定义数据预处理时发现,虽然手动生成的标签图与官方样本在颜色和像素值上一致,却出现形状错误。通过排查发现,问题根源在于图像位深度不同(官方标签图为8位,自建图为24位),导致处理异常。最终采用官方代码中的图像保存方法(使用PIL库的'P'模式并设置调色板),使训练得以正常进行。文章提醒开发者注意图像位深度对模型训练的影响,并
前言
这篇文章纯粹是记录一下问题的所在和解决方法,比较这个一度让我折腾了挺久却找不到原因。
问题
起因是最近看了下百度飞桨的平台,看到了里面的分割训练,就尝试着用了一下,一开始是用官方提供的数据以及官方提供的自定义数据预处理的方法,训练没什么问题。
为了增加自定义的样本数量,我自己手动用传统的图像方法做了一些样本,并且已经确保了生成的分割标签图跟官方生成的标签图的背景和前景颜色一致了。见下图官方代码下的tools/data/labelme2seg.py生成的:
在看看自己代码写生成的标签图:

前景背景颜色以及像素值都是一样的(验证过),但是却出现了下面的错误:
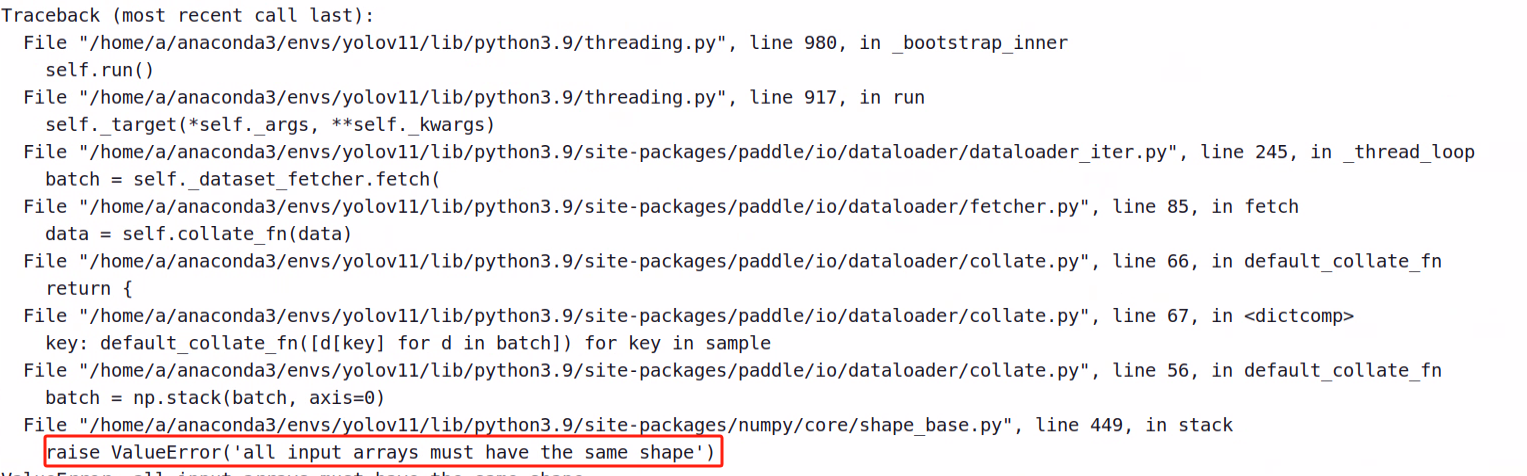
很明显是形状不对,不过也重新验证了图像的宽高是一致的,就很好奇,到底是哪里有问题,也打印了源码中,确实在读取的时候出现了这个错误,最后确定了验证的时候只是验证了宽高,深度没有验证,因为肉眼看了图片都是彩图,深度不是3还能是什么!!!!!!!
原因
继续找原因,在源码中读取数据的时候打印了图像的形状,发现不一样:
标签数据中,data[‘label’].shape: (512, 512)是通过tools/data/labelme2seg.py生成的生成的,而data[‘img’].shape: (3, 512, 512)是自己用opencv方法保存的,看来根源就在这了!!!!我赶紧用图像查看器查看这两张图的属性:

一个8,一个24,MD,印象中彩色图不是都是24的吗?但是却忽略了伪彩图,而且还跟保存的方法有关。至于为什么位深度有8,24这种,这里就不说明了,自己可以去看资料。
解决
不得与用回了tools/data/labelme2seg.py中的保存标签图的方法:
if lbl.min() >= 0 and lbl.max() <= 255:
lbl_pil = PIL.Image.fromarray(lbl.astype(np.uint8), mode='P')
lbl_pil.putpalette(color_map)
lbl_pil.save(annotated_img_path)
详细的可以自己去查看,顺便说一下,color_map也要同步一致才能确保你的数据跟官方生成的是一样的。
结束
通过修改了保存方式,训练正常进行了,仅此操作进行记录,如果有其他更好方法请告知。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 8
8 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)