FFmpeg 视频压缩内存泄漏的架构级限流解决方案(Flink URL 流场景)
引言
在音视频工业级处理场景中,FFmpeg 是编解码与压缩的核心工具,但其底层原生库特性导致的内存泄漏问题,成为服务稳定性的核心痛点。尤其在 Flink 实时流架构下,消息仅传递视频 URL 而非实际流数据,视频压缩呈现URL 下载 - 编解码处理 - 成品上传的流水线特征,单阶段内存泄漏极易引发全链路资源雪崩。常规全局限流手段仅能粗暴控制并发,既无法适配各阶段差异化资源需求,还会大幅牺牲吞吐量。
基于分段隔离 + 分级治理的实践经验,本文设计了一套适配 Flink URL 流场景的FFmpeg 视频压缩流水线阶段化分级限流方案。该方案将全链路拆分为独立资源管控阶段,定制化设计限流规则、监控指标和兜底策略,实现 “单阶段内存泄漏单点隔离、全链路资源按需调度”,从架构层面兜底内存泄漏引发的稳定性问题,同时兼顾处理效率。
一、场景痛点:Flink URL 流下 FFmpeg 视频压缩的内存失控难题
本场景采用 Flink 作为流处理引擎,消息队列仅传递视频 URL、压缩规格等轻量信息,虽规避了大视频流占用带宽问题,但让内存泄漏的影响更具传导性,结合 FFmpeg 特性形成四大核心痛点:
1.1 各阶段泄漏风险与资源消耗差异化
视频压缩三阶段的泄漏诱因、资源消耗类型完全不同,单一内存监控无法覆盖全链路,核心特征对比如下:
|
处理阶段 |
核心操作 |
主要泄漏点 |
核心消耗资源 |
故障影响范围 |
|
URL 下载 |
HTTP/FTPS 拉取视频流 |
连接池未释放、流缓存堆积 |
堆外内存、网络 IO、线程 |
自身阶段,易阻塞后续处理 |
|
FFmpeg 处理 |
编解码、帧压缩、格式转换 |
编解码器实例、帧缓存、原生库未释放 |
堆内存、CPU、显存、堆外内存 |
全链路核心,泄漏引发整体雪崩 |
|
成品上传 |
推送至对象存储(OSS/S3) |
客户端池泄漏、临时文件缓存未释放 |
磁盘缓存、网络 IO |
自身阶段,易堆积处理完成品 |
1.2 单阶段泄漏引发全链路多米诺效应
流水线处理具有阶段间强依赖、资源串行占用的核心特征,某一阶段因内存泄漏导致资源耗尽,会直接阻塞后续所有阶段。
例如 FFmpeg 处理阶段堆内存占满,会导致下载阶段拉取的流数据无法进入处理环节,堆积的任务持续占用下载连接池和堆外内存,最终引发下载、上传阶段相继资源耗尽,整个 Flink Job 崩溃。
1.3 常规监控与限流无法适配场景特性
- 监控盲区:FFmpeg 底层大量编解码操作基于堆外内存执行,常规 JVM 监控工具(Jconsole、Prometheus+JMX)无法覆盖堆外内存占用,内存泄漏预警和感知存在明显缺失;
- 限流低效:传统全局限流仅依据全局内存水位控制并发,既无法精准管控堆外内存泄漏等阶段化问题,还会因 “一刀切” 规则,因单阶段轻微异常阻塞全链路,大幅降低服务有效吞吐量。
1.4 Flink 算子级故障易扩散
如果将下载、处理、上传封装为连续算子链,未做任何资源隔离措施,单个算子因内存泄漏引发的故障会直接扩散至整个算子链,导致 Flink TaskManager 频繁重启,进而引发消息堆积和数据延迟,严重违背实时处理的业务诉求。
二、常规解决方案的局限:治标不治本
针对 FFmpeg 视频压缩的内存泄漏问题,行业常规解决方案主要分为三类,但在工业级千万级日处理量的实时场景中,均存在明显局限,无法满足高稳定性、高吞吐量的双重需求:
2.1 内存泄漏根治:技术难度高、落地周期长
根治手段主要为通过 Valgrind 工具排查 FFmpeg 原生库泄漏、规范 JNI 调用释放实例、优化池化对象生命周期等,但存在两大核心问题:
- 技术门槛高:需要深入掌握 FFmpeg 底层 C/C++ 源码,对开发人员能力要求极高;
- 线上无窗口:排查、修复、测试、上线全流程周期长,而线上服务无法停机等待,无法解决即时的稳定性问题。
2.2 通用限流兜底:粒度粗、无场景化设计
常规限流手段为全局并发数控制、全局内存水位阈值限流,核心弊端:
- 指标单一:仅控制全局堆内存、并发数等指标,无法感知堆外内存、连接池等阶段化资源问题;
- 策略粗暴:“一刀切” 限流规则,单阶段轻微异常即阻塞全链路,牺牲大量吞吐量;
- 无隔离性:未结合 Flink 流处理特性做算子级隔离,故障扩散风险依然存在。
2.3 简单堆外内存优化:仅缓解、无兜底
部分方案采用堆外内存池化、临时文件清理等手段做优化,但仅能缓解内存占用问题,无法从根本上解决泄漏;且当泄漏达到一定程度时,仍会引发资源耗尽,缺乏有效的故障兜底和限流能力。
三、核心设计思路:流水线阶段化分级限流
基于上述场景痛点和常规方案的局限,采用分段隔离 + 分级治理的核心设计思路,结合 Flink URL 流的流水线处理特性,提出阶段化分级限流的解决方案,核心遵循五大设计原则,实现 “精准限流、隔离故障、保障核心”:
3.1 链路拆分:独立管控,解耦故障
将 “URL 下载 - FFmpeg 处理 - 成品上传” 全链路拆分为三个独立的资源管控单元,阶段间通过异步任务队列解耦,实现 “阶段内资源自治、阶段间异步调度”,从根源上避免单阶段故障的直接传导。
3.2 指标定制:多维度监控,精准感知
摒弃单一的内存水位指标,为每个阶段定制多维度监控指标体系,覆盖 “资源 + 业务” 双维度,确保限流精准、预警及时:
- 核心资源指标:堆 / 堆外内存、CPU / 显存占用、连接池 / 实例池使用率;
- 核心业务指标:任务执行时长、超时率、失败率、任务队列长度。
3.3 分级阈值:弹性限流,兼顾双效
为各阶段的监控指标设置低水位、危险水位、熔断水位三档阈值,不同水位触发差异化的限流策略,避免过度限流,兼顾服务稳定性和吞吐量:
- 低水位:轻微限流(降速 / 小幅降低并发),不影响核心任务处理;
- 危险水位:深度限流(减半并发 / 关闭非核心任务),控制故障范围;
- 熔断水位:临时暂停新任务,仅处理已堆积任务,快速恢复资源。
3.4 架构适配:算子隔离,优先级调度
- 算子级资源隔离:将三个阶段封装为独立的 Flink 算子,为每个算子分配专属的 CPU、内存、并发度,实现算子级故障隔离;
- 任务优先级调度:在 Flink 源端对视频 URL 做业务优先级打标,限流时优先保障核心任务处理,低优先级任务进入等待队列,最大化利用服务资源。
3.5 经验复用:堆外监控,提前优化
通过自定义堆外内存探针实现 FFmpeg 堆外内存的精准监控(“JNI 封装 FFmpeg 原生内存 API + Java 定时采集 + 指标上报” 的组合方案);同时结合连接池 / 实例池化、临时文件清理等手段,从源头减少内存泄漏的发生,为限流策略提供更精准的指标依据。
核心设计定位:本方案并非 “根治内存泄漏”,而是从架构层面为内存泄漏做兜底—— 通过精细化的阶段化限流,将泄漏的影响控制在单个阶段内,避免全链路雪崩,同时为内存泄漏的根治争取充足的线上时间。
四、落地实现:阶段化分级限流全流程设计
将阶段化分级限流方案落地为五层分层架构,各层级独立部署、联动协作,与 Flink 算子深度融合,实现 “指标采集 - 规则决策 - 限流执行 - 故障兜底” 的全链路自动化管控。
4.1 整体分层架构
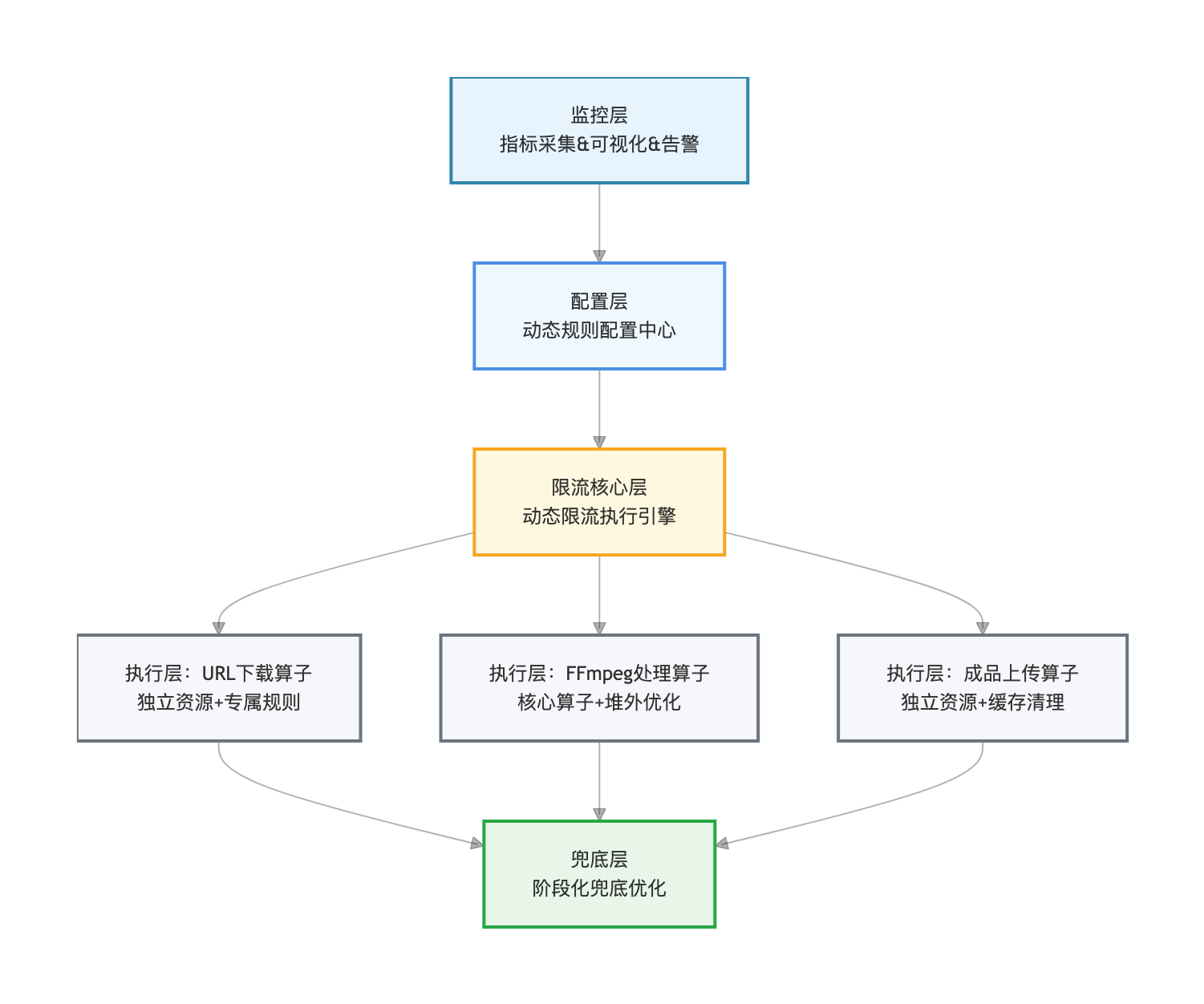
各层级通过轻量 RPC / 消息通信实现联动,所有模块均可独立扩展,灵活适配业务量的动态变化。
4.2 核心阶段:三阶段精细化限流规则设计
针对三个阶段的差异化泄漏风险、资源消耗特性,设计专属的监控指标、分级限流策略和兜底手段,以下为16GB 内存服务器的实测最优规则(可根据硬件配置、业务量灵活调整):
|
处理阶段 |
核心监控指标(核心在前) |
三档限流策略(低 / 危险 / 熔断) |
核心兜底手段 |
|
URL 下载 |
堆外内存占用、连接池占用率、下载超时率 |
降速 50% / 关闭非核心下载 / 暂停新任务拉取 |
连接池池化、流缓存即时释放、超时任务死信队列 |
|
FFmpeg 处理 |
堆内存占用、CPU 占用率、任务执行时长 |
并发降 25% / 并发减半 + 释放空闲实例 / 暂停新任务 + 实例池重置 |
编解码器池化、堆外内存手动释放、大视频分片处理 |
|
成品上传 |
磁盘缓存内存、上传队列长度、失败率 |
降速 30% / 关闭非核心上传 / 暂停新任务 + 清理缓存 |
客户端池化、临时文件定时清理、失败任务指数退避重试 |
4.3 架构适配:Flink 算子级隔离与优先级调度
针对 Flink 流处理的技术特性,做算子解耦、资源分配、优先级调度三大改造,让限流方案与 Flink 深度融合,实现精细化的任务管控。
4.3.1 算子解耦与独立资源分配
拆分原有连续的算子链,为三个阶段分别封装独立的 Flink 算子,通过Disruptor 异步消息队列实现算子间数据传递,彻底规避故障传导;同时为每个算子分配专属资源:
表格
|
Flink 算子 |
核心职责 |
推荐并发度 |
核心隔离手段 |
|
DownloadOperator |
URL 拉取、流缓存管理 |
10 |
独立连接池、堆外内存池隔离 |
|
FFmpegProcessOperator |
视频编解码、压缩 |
20 |
独立实例池、堆内存隔离、显存独占 |
|
UploadOperator |
成品推送、临时缓存管理 |
15 |
独立客户端池、磁盘缓存隔离 |
4.3.2 任务优先级打标与限流集成
1. 优先级分级:在 Flink 源端对视频 URL 做三级业务优先级打标,打标信息随任务同步传递至各算子:
- P0:核心实时任务(如直播视频压缩);
- P1:常规业务任务(如普通用户视频处理);
- P2:非核心离线任务(如历史视频转码)。
2. 限流执行规则:各算子限流时遵循 “高优先级优先处理” 原则,仅对低优先级任务做限流 / 暂停,确保核心业务不受影响:
- 低水位:仅限流 P2 任务;
- 危险水位:暂停 P2 任务,仅处理 P0/P1;
- 熔断水位:仅处理 P0 任务,P1/P2 进入死信队列。
3. 核心代码实现(以 FFmpegProcessOperator 为例):
/**
* FFmpeg核心处理算子:集成分级限流+优先级调度,基于Flink Managed State实现状态持久化
*/
public class FFmpegProcessOperator extends RichMapFunction<VideoTask, ProcessedVideo> {
private transient LimitDecisionMaker decisionMaker; // 限流决策器
private ValueState<Integer> limitLevel; // 限流档位:0-低/1-危险/2-熔断
private enum TaskPriority { P0, P1, P2 } // 任务优先级枚举
@Override
public void open(Configuration parameters) {
// 初始化限流决策器
decisionMaker = new LimitDecisionMaker();
// 初始化Flink状态,重启后可恢复
ValueStateDescriptor<Integer> desc = new ValueStateDescriptor<>("limitLevel", Integer.class, 0);
limitLevel = getRuntimeContext().getState(desc);
}
@Override
public ProcessedVideo map(VideoTask task) throws Exception {
int currentLevel = limitLevel.value();
TaskPriority priority = TaskPriority.valueOf(task.getPriority());
// 分级限流规则执行
if (currentLevel == 1 && priority == P2) {
TaskWaitQueue.put(task);
throw new LimitException("危险水位,P2非核心任务暂停处理");
}
if (currentLevel == 2 && priority != P0) {
DeadLetterQueue.put(task);
throw new LimitException("熔断水位,仅处理P0核心任务");
}
// 未触发限流,执行FFmpeg压缩核心逻辑
return FFmpegProcessService.compress(task.getVideoUrl(), task.getCompressSpec());
}
@Override
public void close() {
if (decisionMaker != null) decisionMaker.close();
}
}
4.4 关键技术实现:监控、池化与内存优化
为保障限流方案的精准性和有效性,针对堆 / 堆外内存监控、FFmpeg 实例管理、内存泄漏优化三大核心点,做定制化技术实现,从 “监控 + 优化” 双维度减少内存泄漏的影响。
4.4.1 堆 / 堆外内存精准监控
实现自定义堆外内存监控探针,突破常规 JVM 监控的盲区,实现 JVM 直接内存 + FFmpeg 原生库堆外内存的全量、实时采集;堆内存通过 JMX+Flink 原生指标实现精准监控,所有指标超阈值时通企业微信即时告警。
核心代码实现:
/**
* 堆外内存监控探针:每秒采集一次,精准监控FFmpeg原生库+JVM堆外内存
*/
@Component
public class OffHeapMemoryMonitor {
// 定时采集,频率1s,与限流引擎指标采集频率一致
@Scheduled(fixedRate = 1000)
public void collectOffHeapMemory() {
// 1. 采集JVM直接内存(堆外内存)
long jvmOffHeap = ManagementFactory.getPlatformMXBeans(BufferPoolMXBean.class)
.stream().mapToLong(BufferPoolMXBean::getUsed).sum();
// 2. 采集FFmpeg原生库堆外内存(基于JNI封装FFmpeg原生API)
long ffmpegOffHeap = FFmpegNativeApi.av_memory_usage();
// 3. 计算总堆外内存占用,转换为GB方便监控展示
double totalOffHeap = (jvmOffHeap + ffmpegOffHeap) / 1024.0 / 1024.0 / 1024.0;
// 4. 上报至Prometheus,对接Grafana可视化
PrometheusMetrics.offHeapMemoryTotal.set(totalOffHeap);
PrometheusMetrics.ffmpegOffHeapMemory.set(ffmpegOffHeap / 1024.0 / 1024.0 / 1024.0);
// 5. 超阈值告警(16GB服务器,90%为危险水位)
if (totalOffHeap >= 14.4) {
AlarmManager.sendAlarm("堆外内存占用超标", "当前总堆外内存:" + totalOffHeap + "GB,已达危险水位");
}
}
}
// FFmpeg JNI API封装,仅保留核心方法
public class FFmpegNativeApi {
static { System.loadLibrary("ffmpeg-jni"); } // 加载FFmpeg JNI动态库
public native static long av_memory_usage(); // 获取FFmpeg原生库内存占用(字节数)
}
4.4.2 FFmpeg 编解码器实例池化管理
FFmpeg 编解码器实例的频繁创建 / 销毁是内存泄漏的核心诱因之一,因此对核心编解码器实例做单例定长池化管理,提前创建实例、复用实例、使用后即时清理缓存,从根源上减少泄漏。
核心代码实现:
/**
* FFmpeg编解码器实例池:单例模式+定长池化,避免频繁创建/销毁导致的内存泄漏
*/
public class FFmpegCodecPool {
// 单例实例,全局唯一
private static final FFmpegCodecPool INSTANCE = new FFmpegCodecPool();
// 编解码器实例池,定长10(可根据业务调整)
private final LinkedBlockingQueue<AVCodecContext> codecPool = new LinkedBlockingQueue<>(10);
// 私有构造方法,初始化池化实例(H264编解码器)
private FFmpegCodecPool() {
for (int i = 0; i < 10; i++) {
codecPool.offer(FFmpegNativeApi.createCodecContext("h264"));
}
}
// 获取编解码器实例,超时10s
public AVCodecContext getCodecContext() throws InterruptedException {
AVCodecContext ctx = codecPool.poll(10, TimeUnit.SECONDS);
if (ctx == null) throw new PoolException("编解码器实例池无空闲,获取超时");
return ctx;
}
// 归还实例,使用后即时清理缓存,避免泄漏
public void returnCodecContext(AVCodecContext ctx) {
if (ctx != null) {
FFmpegNativeApi.clearCodecCache(ctx);
codecPool.offer(ctx);
}
}
// 单例获取方法
public static FFmpegCodecPool getInstance() { return INSTANCE; }
// 服务关闭时,手动释放所有实例
public void destroy() {
codecPool.forEach(FFmpegNativeApi::freeCodecContext);
codecPool.clear();
}
}
// 业务层使用示例,finally块确保实例必归还
public class FFmpegProcessService {
public static ProcessedVideo compress(String videoUrl, CompressSpec spec) {
AVCodecContext codec = null;
try {
codec = FFmpegCodecPool.getInstance().getCodecContext();
return doCompress(videoUrl, spec, codec);
} finally {
if (codec != null) {
FFmpegCodecPool.getInstance().returnCodecContext(codec);
}
}
}
}
4.4.3 额外内存优化手段
在池化管理的基础上,结合三大手段进一步优化 FFmpeg 内存使用,减少限流触发频率:
- 手动内存释放:JNI 调用 FFmpeg 原生方法后,通过av_free、av_unref等 API 手动释放帧缓存、编码上下文等对象;
- 大视频分片处理:对超过 2GB 的大视频,按 100MB 为单位分片压缩,处理完成后再合并,避免单任务占用过多内存;
- 开启 FFmpeg 全局内存池:通过av_pool_init开启 FFmpeg 原生内存池,让原生库的内存申请从内存池中获取,减少内存碎片和泄漏。
4.5 全流程执行时序
视频任务从进入 Flink 流到处理完成的全流程中,各模块联动执行分级限流规则,清晰体现 “指标实时采集 - 规则动态匹配 - 限流精准执行 - 单点故障隔离” 的设计目标:
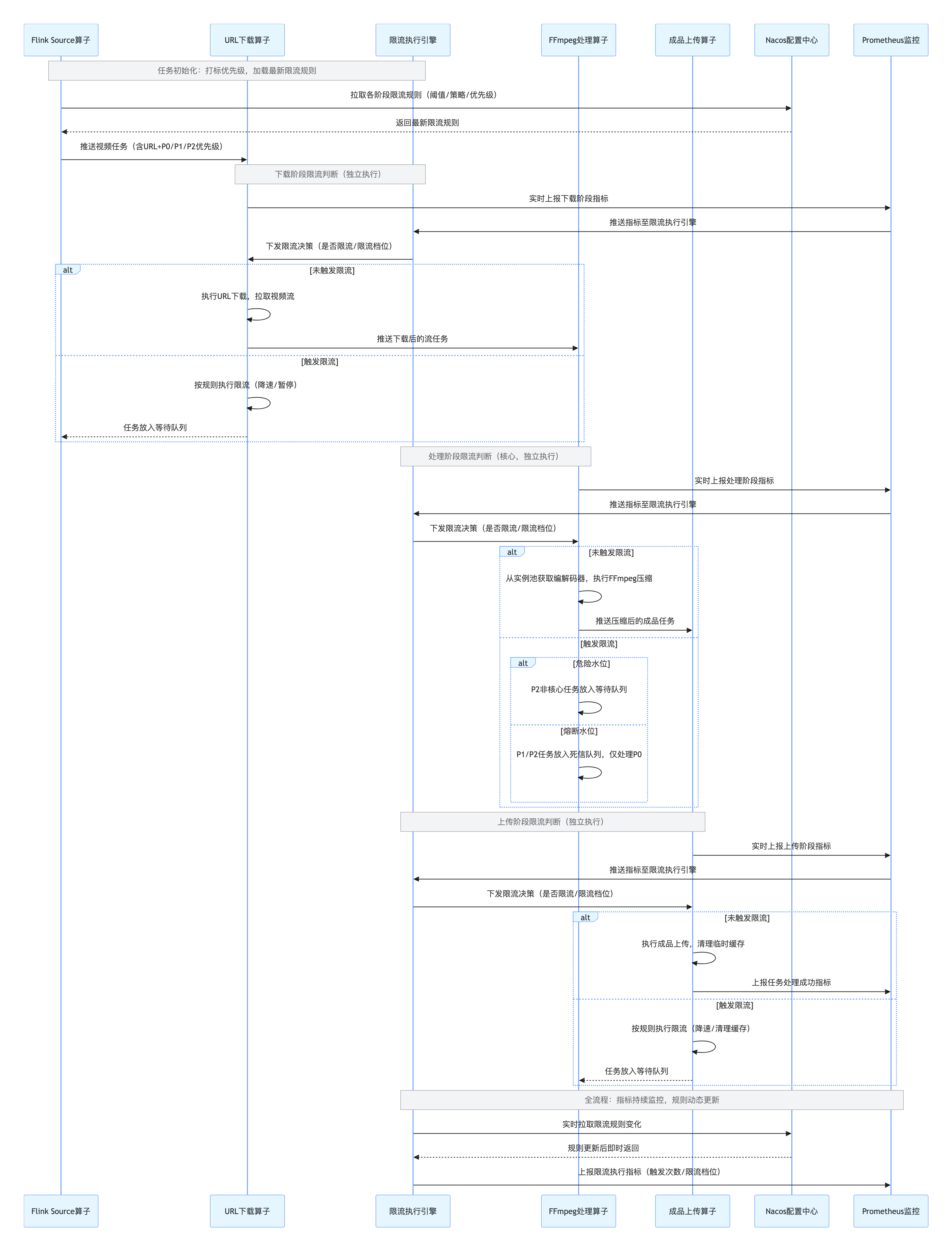
五、方案延伸:限流体系的全域联动与实践复用
本文所设计的 Flink 流处理场景下阶段化分级限流方案,并非独立的技术实现,而是与微服务架构下的限流体系一脉相承,可与过往《Sentinel + Spring Cloud Gateway 联动限流实战》中落地的网关层限流方案形成全域限流防护体系,实现从微服务入口到流式处理节点的全链路流量治理。
5.1 限流设计的核心逻辑复用
无论是 Spring Cloud Gateway 网关层的入口限流,还是本次 Flink 场景下的算子级阶段限流,均遵循 「分层拦截、精准管控、弹性适配」 的核心设计逻辑:
- 分层拦截:网关层做全局流量入口粗粒度管控,流式处理层做节点级细粒度限流,各层各司其职,避免单一环节限流失效导致的全链路雪崩;
- 精准管控:网关层支持路由、API 分组、自定义参数(Header / 请求参数)维度限流,本次方案实现算子、任务优先级、资源类型维度限流,均摒弃「一刀切」的全局限流模式;
- 弹性适配:均设计多档位限流阈值(低 / 危险 / 熔断),并支持规则动态热更新,可应对突发流量、业务峰值等场景,与《Sentinel + Spring Cloud Gateway 联动限流实战》中 Nacos 实现规则持久化、热更新的方案思路完全一致。
5.2 全链路限流的体系化联动
微服务网关作为流量统一入口,负责拦截外部超限、恶意流量,而 Flink 流式处理作为后端核心数据处理环节,负责内部业务流程的流量管控,二者可通过配置中心联动、监控指标互通实现全链路限流:
- 配置中心统一管理:基于 Nacos 实现网关层限流规则与 Flink 算子限流规则的统一存储、持久化与热更新,形成全系统限流规则「一盘棋」,降低维护成本;
- 监控指标全域互通:通过 Prometheus + Grafana 实现网关层 QPS、阻塞数、降级数与 Flink 算子各阶段内存占用、任务处理速率、限流触发次数的指标统一采集与可视化,可从全局视角感知流量变化与限流效果;
- 状态联动适配:网关层可感知 Flink 流式处理层的资源负载状态(如编解码算子内存占用、处理延迟),当流式处理层负载过高时,网关层自动降低对应业务的限流阈值,减少流量输入;当流式处理层恢复正常后,网关层自动恢复阈值,实现流量的动态适配。
5.3 不同场景下的限流方案落地思路
从网关层的 HTTP 流量限流到 Flink 的流式任务限流,不同技术场景的限流方案虽具体实现不同,但落地思路可高度复用,核心遵循 「先定场景、再拆节点、后做管控」的步骤:
- 先定场景:明确业务流量的特征(HTTP 请求 / 流式任务)、核心瓶颈点(网关连接数 / 算子内存)、防护目标(防穿透 / 防雪崩);
- 再拆节点:将流量链路拆分为独立的管控节点(网关路由 / Flink 算子),实现节点级资源隔离,避免单节点故障扩散;
- 后做管控:为每个节点定制专属限流指标、阈值与策略,配套实现监控、告警、规则动态更新,形成「监控 - 限流 - 兜底」的闭环。
六、核心复习要点
- 针对 Flink URL 流场景 FFmpeg 堆外内存泄漏问题,设计流水线阶段化分级限流方案,拆分三个独立算子实现节点级故障隔离与精准限流;
- 核心技术围绕精准监控、彻底隔离、前置优化,通过 JNI 实现堆外内存监控,算子独立资源隔离,实例池化等手段减少泄漏;
- 基于五层分层架构 + P0/P1/P2 优先级调度,弹性管控流量,解决单阶段泄漏引发的全链路雪崩问题;
- 与 Sentinel+Spring Cloud Gateway 网关限流核心逻辑复用,可联动实现全链路全域流量治理;
- 本方案是架构级故障兜底,将泄漏影响控制在局部,为原生层问题根治争取时间,兼顾吞吐量与实时性。
📚 我的技术博客导航:[点击进入一站式查看所有干货]

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 15
15 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)