单 / 多目标模板匹配:相似度度量与阈值优化【计算机视觉】
归一化处理是提升相关性匹配算法鲁棒性的关键核心,它解决了CCORR 认亮不认像的先天缺陷,让算法从「理论可行」走向「实际可用」。模板匹配任务中,应优先选择带归一化的匹配算法(如 NCC),避免使用无归一化的基础算法(如 CCORR),以保证匹配结果的稳定性和可靠性。cv2.matchTemplate() 核心参数3个:目标图、模板图、匹配算法,用于生成相似度数据;cv2.rectangle() 核
单 / 多目标模板匹配:相似度度量与阈值优化【计算机视觉】
模板匹配(Template Matching)
模板匹配(Template Matching)是计算机视觉里最基础、最常用的一种 “在大图里找小图” 的方法。它的核心思想特别简单:拿一个小模板,在大图上从左到右、从上到下滑动,每到一个位置就算一算 “这里像不像模板”,最像的地方就是答案。
注意:本文所有代码均可导入Jupyter Notebook
完整代码仓库地址:🔗 GitHub:https://github.com/KnifeWen007/CV—StudyNotebook
Ⅰ、引言
模板匹配是计算机视觉领域最基础且实用的目标定位方法之一,其核心价值在于无需复杂特征提取,仅依赖像素灰度统计特性即可完成目标定位。在实际场景中,我们常需要从复杂图像中快速找到特定目标(如工业流水线上的零件、监控画面中的特定物体、文档中的标识图案等),而模板匹配凭借原理简单、实现高效、计算成本低的优势,成为这类场景的首选预处理或核心定位手段。
在深入公式之前,我们先明确模板匹配的核心流程,这是理解后续算法的前提:
- 准备输入图像(大图,记为 I I I)和模板图像(小图,记为 T T T),模板尺寸为 w × h w \times h w×h,输入图像尺寸为 W × H W \times H W×H;
- 以模板尺寸为滑动窗口,在输入图像上从左到右、从上到下逐像素滑动;
- 每个窗口位置 ( x , y ) (x,y) (x,y)(窗口左上角坐标),计算窗口内子图像 I ( x , y ) I(x,y) I(x,y) 与模板 T T T 的相似度/差异度;
- 所有位置计算完成后生成“响应图”,通过响应图的极值(最大值/最小值)确定最佳匹配位置。
而我们今天的核心,就是详解步骤3中的4种核心相似度计算方法,分为平方差类和相关性类两大类别,逐一拆解其数学公式、含义和应用。
Ⅱ、平方差类匹配算法
平方差类匹配算法是模板匹配中最基础的一类算法,核心逻辑是通过“计算模板与目标图像窗口的像素差值大小”判断匹配度(差值越小,说明两者越相似,匹配度越高),核心是求解模板与滑动窗口之间的像素差值平方和。
一、平方差匹配(SQDIFF)
平方差匹配(SQDIFF)是模板匹配中最基础、最直观的算法。它的核心思想是:
如果模板和图像中的某个区域越相似,那么它们对应像素的差值就越小。
因此,我们可以用“差值的平方和”来衡量两个区域的差异程度。
1. 数学公式
SSD ( x , y ) = ∑ u = 0 w − 1 ∑ v = 0 h − 1 [ I ( x + u , y + v ) − T ( u , v ) ] 2 \text{SSD}(x, y) = \sum_{u=0}^{w-1} \sum_{v=0}^{h-1} \left[ I(x+u, y+v) - T(u, v) \right]^2 SSD(x,y)=u=0∑w−1v=0∑h−1[I(x+u,y+v)−T(u,v)]2
其中:
- I I I:输入图像(大图)
- T T T:模板图像(小图)
- ( x , y ) (x, y) (x,y):滑动窗口在图像中的左上角坐标
- ( u , v ) (u, v) (u,v):模板内部的相对坐标(横向 0 ∼ w − 1 0 \sim w-1 0∼w−1,纵向 0 ∼ h − 1 0 \sim h-1 0∼h−1)
- w , h w, h w,h:模板的宽度和高度
- SSD ( x , y ) \text{SSD}(x,y) SSD(x,y):该窗口位置的平方差总和(核心结论:值越小,匹配度越高)
(1)第一步:逐像素计算对应差值
I ( x + u , y + v ) − T ( u , v ) I(x+u, y+v) - T(u, v) I(x+u,y+v)−T(u,v)
这一步的核心是完成“单个像素的差异对比”,具体逻辑:
- 确定滑动窗口在输入图像 I I I中的位置 ( x , y ) (x,y) (x,y)(左上角坐标);
- 取模板 T T T中相对坐标 ( u , v ) (u,v) (u,v)对应的像素值 T ( u , v ) T(u, v) T(u,v);
- 取输入图像窗口中对应位置的像素值 I ( x + u , y + v ) I(x+u, y+v) I(x+u,y+v)(即窗口内的相对坐标映射到大图的绝对坐标);
- 计算两个像素值的差值,差值的大小直接反映单个像素的匹配程度。
补充说明:
- 若两个像素值完全一致,差值为 0 0 0,表示单个像素完美匹配;
- 若两个像素值存在差异,差值为正数或负数,差值的绝对值越大,单个像素的不匹配程度越高。
(2)第二步:对单个像素差值进行平方运算
[ I ( x + u , y + v ) − T ( u , v ) ] 2 \left[ I(x+u, y+v) - T(u, v) \right]^2 [I(x+u,y+v)−T(u,v)]2
这是平方差匹配的“关键优化步骤”,之所以要对差值进行平方,核心有两个目的:
- 消除正负差值相互抵消的问题
举例:模板与窗口中有两个对应像素,差值分别为 + 5 +5 +5和 − 5 -5 −5,若直接求和,结果为 0 0 0,会错误地认为这两个像素整体无差异;而经过平方运算后,两个差值都变为 25 25 25,求和后为 50 50 50,能够正确累积真实差异,避免“假匹配”。 - 放大较大差异的权重,突出不匹配区域
平方运算具有“放大差值”的特性,差值越大,平方后的结果增长越快。
举例:像素差值为 1 1 1,平方后为 1 1 1;像素差值为 10 10 10,平方后为 100 100 100。这种放大效应能让明显不匹配的区域(大差值像素较多)的总差异值大幅提升,更容易在后续的求和步骤中被区分出来,减少“模糊匹配”的误判。
(3)第三步:对所有像素的平方差进行求和运算
∑ u = 0 w − 1 ∑ v = 0 h − 1 … \sum_{u=0}^{w-1} \sum_{v=0}^{h-1} \dots u=0∑w−1v=0∑h−1…
这一步的核心是完成“从单个像素到整个窗口的差异汇总”,具体逻辑:
- 双重求和符号 ∑ u = 0 w − 1 ∑ v = 0 h − 1 \sum_{u=0}^{w-1} \sum_{v=0}^{h-1} ∑u=0w−1∑v=0h−1表示遍历模板 T T T的所有像素(横向从 0 0 0到 w − 1 w-1 w−1,纵向从 0 0 0到 h − 1 h-1 h−1);
- 将每个像素平方后的差值进行累加,得到该窗口位置的“总差异值” SSD ( x , y ) \text{SSD}(x,y) SSD(x,y);
- 汇总后的总差异值,反映了整个窗口与模板的整体匹配程度,而非单个像素的局部差异。
核心结论:
- 总差异值 SSD ( x , y ) \text{SSD}(x,y) SSD(x,y)越小,说明窗口与模板的整体差异越小,匹配度越高;
- 总差异值 SSD ( x , y ) \text{SSD}(x,y) SSD(x,y)越大,说明窗口与模板的整体差异越大,匹配度越低;
- 当 SSD ( x , y ) = 0 \text{SSD}(x,y)=0 SSD(x,y)=0时,说明窗口与模板的所有对应像素完全一致,实现“完美匹配”。
2. 核心局限:为什么 SQDIFF 对亮度变化敏感?
原理分析
平方差匹配直接计算像素值的绝对差值,而图像整体亮度变化会导致所有像素值发生“同向偏移”,进而让差值被整体放大,最终影响匹配结果。
具体举例
假设存在一个理想场景:模板像素值为 20 20 20,图像窗口对应像素值也为 20 20 20,此时差值为 0 0 0,平方差为 0 0 0,匹配度极高。
当图像整体亮度增加 10 10 10(光照变亮),此时:
- 模板像素值仍为 20 20 20(无变化);
- 图像窗口对应像素值变为 30 30 30(整体偏移);
- 像素差值从 0 0 0变为 10 10 10,平方差从 0 0 0变为 100 100 100;
- 若模板为 w × h w \times h w×h尺寸,总差异值 SSD ( x , y ) \text{SSD}(x,y) SSD(x,y)会增加 100 × w × h 100 \times w \times h 100×w×h,大幅提升,最终被判定为“不匹配”,但实际上图像内容与模板完全一致,仅亮度发生变化。
最终结论
SQDIFF 对整体亮度变化、局部亮度偏移都非常敏感,无法适应光照不稳定的场景,这也是后续需要引入“归一化平方差匹配(SQDIFF_NORMED)”的核心原因。
二、归一化平方差匹配(SQDIFF_NORMED)
归一化平方差匹配(SQDIFF_NORMED)是对基础平方差匹配(SQDIFF)的优化升级,其核心目标是消除图像亮度变化(整体/局部)对匹配结果的干扰,让算法能够适应光照不稳定的场景。
它的核心思想是:通过对输入图像窗口和模板图像的像素值进行"归一化处理",消除两者之间的绝对亮度偏移,只关注像素值的相对分布规律,再计算平方差总和。
简单来说,SQDIFF 关注"像素值绝对差异",而 SQDIFF_NORMED 关注"像素值相对差异"—— 即使图像和模板存在整体亮度偏移,归一化后也能抵消这种偏移的影响,还原真实的内容匹配度。
在模板匹配里,“归一化” 指的是:
把两个东西(图像窗口和模板)放到同一个 “尺度” 和 “亮度基准” 上,让它们可以公平地比较。
就像把两个人的身高都换成米,或者把两个班级的考试成绩都换算成百分制,这样比较才有意义。
1. 数学公式
归一化平方差的计算分为"归一化处理"和"平方差求和"两个核心步骤,完整公式如下:
NSSD ( x , y ) = ∑ u = 0 w − 1 ∑ v = 0 h − 1 [ I ( x + u , y + v ) − T ( u , v ) ] 2 ∑ u = 0 w − 1 ∑ v = 0 h − 1 I ( x + u , y + v ) 2 ⋅ ∑ u = 0 w − 1 ∑ v = 0 h − 1 T ( u , v ) 2 \text{NSSD}(x, y) = \frac{\sum_{u=0}^{w-1} \sum_{v=0}^{h-1} \left[ I(x+u, y+v) - T(u, v) \right]^2}{\sqrt{\sum_{u=0}^{w-1} \sum_{v=0}^{h-1} I(x+u, y+v)^2 \cdot \sum_{u=0}^{w-1} \sum_{v=0}^{h-1} T(u, v)^2}} NSSD(x,y)=∑u=0w−1∑v=0h−1I(x+u,y+v)2⋅∑u=0w−1∑v=0h−1T(u,v)2∑u=0w−1∑v=0h−1[I(x+u,y+v)−T(u,v)]2
其中:
- 分子部分:与基础 SQDIFF 的平方差总和完全一致,反映窗口与模板的原始绝对差异;
- 分母部分:输入图像窗口所有像素值的平方和 与 模板图像所有像素值的平方和 的乘积的平方根,是归一化因子,用于抵消亮度变化带来的整体偏移;
- NSSD ( x , y ) \text{NSSD}(x,y) NSSD(x,y):归一化后的平方差值(核心结论:取值范围为 [ 0 , 1 ] [0, 1] [0,1],值越小,匹配度越高);
- 其他参数( I 、 T 、 ( x , y ) 、 ( u , v ) 、 w 、 h I、T、(x,y)、(u,v)、w、h I、T、(x,y)、(u,v)、w、h)的定义与基础 SQDIFF 完全一致。
(1)第一步:计算分子——原始平方差总和
分子部分 ∑ u = 0 w − 1 ∑ v = 0 h − 1 [ I ( x + u , y + v ) − T ( u , v ) ] 2 \sum_{u=0}^{w-1} \sum_{v=0}^{h-1} \left[ I(x+u, y+v) - T(u, v) \right]^2 ∑u=0w−1∑v=0h−1[I(x+u,y+v)−T(u,v)]2 与 SQDIFF 的总差异值完全相同,其作用是保留窗口与模板之间的像素差异信息,具体逻辑可参考 SQDIFF 的三步计算法(逐像素差值→平方运算→求和汇总)。
这一步不做任何优化,核心是记录原始的像素差异数据,为后续归一化提供基础。
(2)第二步:计算分母——归一化因子
分母是 SQDIFF_NORMED 与 SQDIFF 的核心区别,也是解决亮度敏感问题的关键,其计算公式为:
∑ u = 0 w − 1 ∑ v = 0 h − 1 I ( x + u , y + v ) 2 ⋅ ∑ u = 0 w − 1 ∑ v = 0 h − 1 T ( u , v ) 2 \sqrt{\sum_{u=0}^{w-1} \sum_{v=0}^{h-1} I(x+u, y+v)^2 \cdot \sum_{u=0}^{w-1} \sum_{v=0}^{h-1} T(u, v)^2} u=0∑w−1v=0∑h−1I(x+u,y+v)2⋅u=0∑w−1v=0∑h−1T(u,v)2
拆解分析:
- 先分别计算两个平方和:
- 输入图像窗口的像素平方和: S I = ∑ u = 0 w − 1 ∑ v = 0 h − 1 I ( x + u , y + v ) 2 S_I = \sum_{u=0}^{w-1} \sum_{v=0}^{h-1} I(x+u, y+v)^2 SI=∑u=0w−1∑v=0h−1I(x+u,y+v)2
- 模板图像的像素平方和: S T = ∑ u = 0 w − 1 ∑ v = 0 h − 1 T ( u , v ) 2 S_T = \sum_{u=0}^{w-1} \sum_{v=0}^{h-1} T(u, v)^2 ST=∑u=0w−1∑v=0h−1T(u,v)2
- 再计算两个平方和的乘积: S I ⋅ S T S_I \cdot S_T SI⋅ST
- 最后对乘积取平方根,得到归一化因子: S I ⋅ S T \sqrt{S_I \cdot S_T} SI⋅ST
归一化因子的核心作用:对图像窗口和模板的整体亮度规模进行"标准化",抵消两者之间的绝对亮度偏移,让后续的差异对比更具公平性。
(3)第三步:计算归一化平方差——分子除以分母
将原始平方差总和(分子)除以归一化因子(分母),得到最终的归一化平方差值 NSSD ( x , y ) \text{NSSD}(x,y) NSSD(x,y)。
这一步的核心是"缩放":将原本可能无限增大的绝对平方差,压缩到一个固定的取值范围 [ 0 , 1 ] [0, 1] [0,1] 内,同时消除亮度变化带来的整体偏移影响。
2. 核心结论:归一化后的匹配度判断
与 SQDIFF 保持一致的"差值越小,匹配度越高"逻辑,但归一化后有更明确的取值边界和判断标准:
- 取值范围: NSSD ( x , y ) ∈ [ 0 , 1 ] \text{NSSD}(x,y) \in [0, 1] NSSD(x,y)∈[0,1],这是归一化处理的核心优势之一,便于统一判断匹配程度,不受模板尺寸和像素值规模影响;
- 匹配度判断: NSSD ( x , y ) \text{NSSD}(x,y) NSSD(x,y) 越小,窗口与模板的匹配度越高;反之,匹配度越低;
- 完美匹配:当 NSSD ( x , y ) = 0 \text{NSSD}(x,y) = 0 NSSD(x,y)=0 时,说明窗口与模板的所有对应像素完全一致(与 SQDIFF 一致);
- 完全不匹配:当 NSSD ( x , y ) = 1 \text{NSSD}(x,y) = 1 NSSD(x,y)=1 时,说明窗口与模板的像素分布无任何相似性,差异达到最大值。
三、平均差算法的光照鲁棒性对比实验
1. 实验对象
目标:在一张灰度图像中,用 “人脸局部” 作为模板进行匹配。
变量:通过增加整体图像亮度(+50),模拟光照变化的场景。
2. 对比算法
未归一化的平方差(SQDIFF):直接计算像素值的绝对差异,对亮度变化敏感。
归一化平方差(SQDIFF_NORMED):通过归一化处理消除亮度偏移的影响,对亮度变化鲁棒。
鲁棒性(Robustness):指的是算法在面对干扰、噪声或环境变化时,依然能保持稳定、正确输出结果的能力
import cv2
import numpy as np
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 读取图像
img = cv2.imread('target.jpg', 0)
tpl = cv2.imread('template.jpg', 0)
# 校验图像读取
if img is None or tpl is None:
raise ValueError("图像读取失败")
# 获取尺寸并校验
h, w = tpl.shape[:2]
img_h, img_w = img.shape[:2]
if h > img_h or w > img_w:
raise ValueError("模板尺寸过大")
# 生成增亮图像(亮度+50)
img_bright = img.astype(np.float32) + 50
img_bright = np.clip(img_bright, 0, 255).astype(np.uint8)
img.astype(np.float32) + 50:
- 原始图像 img 是 uint8 数据类型(像素值范围 0-255),如果直接加 50,可能出现像素值超过 255 的溢出问题(比如原像素值 240,加 50 后变成 290,uint8 会自动截断为无效值)。
- 先转换为 np.float32 高精度浮点型,再整体加 50,实现安全的亮度提升,模拟光照增强。
res_sqdiff = cv2.matchTemplate(img, tpl, cv2.TM_SQDIFF)
res_nsqdiff = cv2.matchTemplate(img, tpl, cv2.TM_SQDIFF_NORMED)
res_sqdiff_bright = cv2.matchTemplate(img_bright, tpl, cv2.TM_SQDIFF)
res_nsqdiff_bright = cv2.matchTemplate(img_bright, tpl, cv2.TM_SQDIFF_NORMED)
两种匹配方法:
cv2.TM_SQDIFF:基础平方差匹配,差值越小,匹配度越高(完美匹配时差值为 0)。cv2.TM_SQDIFF_NORMED:归一化平方差匹配,差值被归一化到 0-1 区间,同样是值越小,匹配度越高,且不受亮度变化影响。
def get_best(res):
return cv2.minMaxLoc(res)[2], cv2.minMaxLoc(res)[0]
loc_sq, val_sq = get_best(res_sqdiff)
loc_nsq, val_nsq = get_best(res_nsqdiff)
loc_sq_b, val_sq_b = get_best(res_sqdiff_bright)
loc_nsq_b, val_nsq_b = get_best(res_nsqdiff_bright)
cv2.minMaxLoc(res):OpenCV 专门用于提取二维数组中「最小值、最大值、最小值位置、最大值位置」的函数,返回值顺序为 (最小值, 最大值, 最小值坐标, 最大值坐标)。
- 返回值:
cv2.minMaxLoc(res)[2]是最小值坐标(最佳匹配位置,因为平方差类算法 “值越小匹配度越高”);cv2.minMaxLoc(res)[0]是最小值(最小差异值,量化匹配效果)。
def draw_box(gray, loc1, loc2, prefix):
color = cv2.cvtColor(gray, cv2.COLOR_GRAY2BGR)
cv2.rectangle(color, loc1, (loc1[0]+w, loc1[1]+h), (255,0,0), 2)
cv2.putText(color, '平方差', (loc1[0], loc1[1]-10), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (255,0,0), 1)
cv2.rectangle(color, loc2, (loc2[0]+w, loc2[1]+h), (0,0,255), 2)
cv2.putText(color, '归一化平方差', (loc2[0], loc2[1]-25), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0,0,255), 1)
return color, f'{prefix}(含匹配框)'
img_box, title1 = draw_box(img, loc_sq, loc_nsq, '原始图像')
img_bright_box, title2 = draw_box(img_bright, loc_sq_b, loc_nsq_b, '增亮图像')
- 在灰度图像上绘制彩色匹配框和文字标签,将抽象的 “匹配位置” 转化为直观的视觉效果,方便对比两种算法的匹配精度。得到两张带彩色匹配框的图像,蓝色框(平方差)和红色框(归一化平方差)
plt.figure(figsize=(20, 10))
plt.subplot(2,4,1)
plt.imshow(cv2.cvtColor(img_box, cv2.COLOR_BGR2RGB))
plt.title(title1)
plt.axis('off')
plt.subplot(2,4,2)
plt.imshow(res_sqdiff, cmap='gray')
plt.title('原始图像 - 平方差热力图')
plt.axis('off')
plt.subplot(2,4,3)
plt.imshow(res_nsqdiff, cmap='gray')
plt.title('原始图像 - 归一化平方差热力图')
plt.axis('off')
plt.subplot(2,4,4)
plt.imshow(tpl, cmap='gray')
plt.title('模板图像')
plt.axis('off')
plt.subplot(2,4,5)
plt.imshow(cv2.cvtColor(img_bright_box, cv2.COLOR_BGR2RGB))
plt.title(title2)
plt.axis('off')
plt.subplot(2,4,6)
plt.imshow(res_sqdiff_bright, cmap='gray')
plt.title('增亮图像 - 平方差热力图')
plt.axis('off')
plt.subplot(2,4,7)
plt.imshow(res_nsqdiff_bright, cmap='gray')
plt.title('增亮图像 - 归一化平方差热力图')
plt.axis('off')
plt.subplot(2,4,8)
plt.text(0.5,0.5,'亮度+50\n\n平方差:对亮度敏感\n归一化平方差:对亮度鲁棒',ha='center',va='center',fontsize=12)
plt.title('实验说明')
plt.axis('off')
plt.tight_layout()
plt.show()
print("【原始图像匹配结果】")
print(f"平方差 位置:{loc_sq} | 最小差值:{val_sq:.6f}")
print(f"归一化平方差 位置:{loc_nsq} | 最小差值:{val_nsq:.6f}")
print("【增亮图像匹配结果】")
print(f"平方差 位置:{loc_sq_b} | 最小差值:{val_sq_b:.6f}")
print(f"归一化平方差 位置:{loc_nsq_b} | 最小差值:{val_nsq_b:.6f}")


3. 实验结论
- 正常光照下:基础平方差匹配(SQDIFF)与归一化平方差匹配(SQDIFF_NORMED)表现一致,均能精准定位模板,无明显差异。
- 亮度变化下:两者鲁棒性差异显著,基础平方差匹配对亮度敏感,匹配位置偏移、结果失效;归一化平方差匹配对亮度鲁棒,仍能精准锁定目标,结果稳定。
- 工程启示:光照稳定场景可选基础平方差匹配(效率高);光照波动场景优先选归一化平方差匹配(准确性有保障),归一化处理是提升光照鲁棒性的关键。
Ⅲ、相关性类匹配算法
相关性类匹配算法与平方差类算法的核心逻辑不同,平方差类是通过“差值大小”判断匹配度(差值越小,匹配度越高),而相关性类是通过“相似度(相关性)高低”判断匹配度(相关性越高,匹配度越高),核心是计算模板与目标图像窗口之间的像素相关性。
一、相关性匹配(CCORR)
1. 核心原理
相关性匹配的本质是计算模板图像与目标图像滑动窗口的像素点积和(也叫互相关和),数学公式可简化为:
R ( x , y ) = ∑ x ′ , y ′ T ( x ′ , y ′ ) ⋅ I ( x + x ′ , y + y ′ ) R(x,y) = \sum_{x',y'} T(x',y') \cdot I(x+x', y+y') R(x,y)=x′,y′∑T(x′,y′)⋅I(x+x′,y+y′)
其中:
- T ( x ′ , y ′ ) T(x',y') T(x′,y′):模板图像的像素值
- I ( x + x ′ , y + y ′ ) I(x+x', y+y') I(x+x′,y+y′):目标图像中对应滑动窗口的像素值
- R ( x , y ) R(x,y) R(x,y):计算得到的相关性值,值越大表示模板与该窗口的相似度越高,匹配度越好。
简单理解:把模板和滑动窗口的像素看作两个数组,相关性值就是两个数组的“相似度得分”,得分越高,说明两者越像。
2. 关键特点
- 匹配判断:相关性值越大,匹配度越高(与平方差类相反,寻找最佳匹配时需找最大值位置)。
- 优点:计算逻辑简单,运算效率较高,在光照稳定、模板与目标灰度分布高度一致的场景下,匹配精度较好。
- 致命缺陷:对亮度变化和对比度变化极其敏感,鲁棒性差。
原因:相关性值是像素的直接乘积和,若图像整体亮度提升(如所有像素值+50),乘积和会呈几何级增长,无法区分“亮度差异”和“模板本身的相似度差异”,容易出现误匹配。 - 适用场景:仅适用于光照、对比度完全受控的理想场景(如工业检测中固定光源下的产品匹配),实际场景中应用较少。
二、归一化互相关(CCORR_NORMED,简称 NCC)
1. 核心原理
归一化互相关是在普通相关性匹配的基础上,增加了归一化处理,消除了亮度和对比度整体变化带来的干扰,数学公式可简化为:
R ( x , y ) = ∑ x ′ , y ′ T ( x ′ , y ′ ) ⋅ I ( x + x ′ , y + y ′ ) ∑ x ′ , y ′ T ( x ′ , y ′ ) 2 ⋅ ∑ x ′ , y ′ I ( x + x ′ , y + y ′ ) 2 R(x,y) = \frac{\sum_{x',y'} T(x',y') \cdot I(x+x', y+y')}{\sqrt{\sum_{x',y'} T(x',y')^2 \cdot \sum_{x',y'} I(x+x', y+y')^2}} R(x,y)=∑x′,y′T(x′,y′)2⋅∑x′,y′I(x+x′,y+y′)2∑x′,y′T(x′,y′)⋅I(x+x′,y+y′)
核心逻辑:将相关性值归一化到 [0, 1] 区间,分子是普通相关性的点积和,分母是模板与滑动窗口的像素平方和乘积的平方根(归一化因子),最终结果只反映两者的“相对灰度分布相似度”,与整体亮度、对比度无关。
2. 关键特点
- 匹配判断:归一化相关性值越接近 1,匹配度越高(最佳匹配位置为最大值位置,值范围锁定在 [0,1],便于量化判断)。
- 核心优势:对整体亮度变化、整体对比度变化具有极强的鲁棒性,是实际场景中应用最广泛的模板匹配算法之一。
原因:归一化因子消除了亮度、对比度整体偏移的影响,即使图像变亮、变暗或对比度拉伸,仍能准确识别模板的相对灰度分布,保持匹配稳定。 - 优点补充:匹配精度高,抗干扰能力强,适用场景广。
- 轻微不足:计算量略大于普通相关性匹配(多了归一化因子的计算),但在现代计算机硬件下,这种效率差异可忽略不计。
- 适用场景:户外自然光场景、光照波动场景、对比度变化场景(如监控画面、产品外观检测、医学图像匹配等),是模板匹配的“首选算法”之一。
三、相关性算法的光照 & 对比度鲁棒性对比实验
1. 实验目的
- 验证 普通相关性匹配(CCORR)对亮度、对比度变化的敏感性。
- 验证 归一化互相关(CCORR_NORMED,NCC)对亮度、对比度变化的强鲁棒性。
- 直观对比两类相关性算法的匹配效果差异,理解归一化处理的核心价值。
2. 实验核心思路
- 基于原始图像,分别生成「增亮图像」和「提高对比度图像」,模拟两种常见环境干扰。
- 对3张图像(原图、增亮图、高对比度图)分别执行 CCORR 和 CCORR_NORMED 匹配。
- 可视化匹配结果(匹配框、热力图),量化输出匹配数据,对比分析算法表现。
3. 对比算法
img_bright = img.astype(np.float32) + 50
img_bright = np.clip(img_bright, 0, 255).astype(np.uint8)
img_contrast = cv2.convertScaleAbs(img, alpha=1.5, beta=0)
- 为相关性算法(CCORR/NCC)提供不同干扰场景的测试素材,模拟真实环境中的亮度波动和对比度变化,最终目的是验证两种算法的抗干扰能力(鲁棒性),形成对比实验。
- 生成img(原图)、img_bright(增亮图)、img_contrast(高对比度图)三组图像,形成「无干扰 + 两种干扰」的对比场景,后续算法在三组场景下的表现差异,正是验证算法优劣的核心依据
res_ccorr = cv2.matchTemplate(img, tpl, cv2.TM_CCORR)
res_ncc = cv2.matchTemplate(img, tpl, cv2.TM_CCORR_NORMED)
res_ccorr_bright = cv2.matchTemplate(img_bright, tpl, cv2.TM_CCORR)
res_ncc_bright = cv2.matchTemplate(img_bright, tpl, cv2.TM_CCORR_NORMED)
res_ccorr_contrast = cv2.matchTemplate(img_contrast, tpl, cv2.TM_CCORR)
res_ncc_contrast = cv2.matchTemplate(img_contrast, tpl, cv2.TM_CCORR_NORMED)
- 直接调用 OpenCV 封装的相关性算法核心接口,对三组测试图像分别执行两种相关性匹配,得到 6 个算法原始输出结果(匹配结果矩阵 / 热力图数据),这是相关性算法落地的核心步骤。
cv2.matchTemplate(src, templ, method)
src:待匹配的目标图像(此处为img/img_bright/img_contrast)。templ:模板图像(此处为tpl)。method:匹配算法类型(此处为两种相关性算法)。- 返回值:
res_xxx(二维数组/匹配结果矩阵),数组中每个元素对应「模板在目标图像中对应位置」的匹配得分,数组尺寸=(目标图像高-模板高+1, 目标图像宽-模板宽+1)。
两种算法参数详解
cv2.TM_CCORR:普通相关性匹配(CCORR),无归一化处理,匹配得分是「模板与目标窗口的像素点积和」,得分越大,匹配度(表面上)越高。cv2.TM_CCORR_NORMED:归一化互相关(NCC),有归一化处理,匹配得分被限制在[0,1]区间,得分越接近1,真实匹配度越高,抗干扰能力强。
# 5. 绘制匹配框
def draw_corr_box(gray, loc1, loc2, prefix):
gray_copy = gray.copy()
color = cv2.cvtColor(gray_copy, cv2.COLOR_GRAY2BGR)
# 普通相关性(CCORR,蓝色框)- 文字放在框内底部,偏移5像素避免贴边
cv2.rectangle(color, loc1, (loc1[0]+w, loc1[1]+h), (255,0,0), 2)
cv2.putText(color, 'CCORR', (loc1[0]+5, loc1[1]+h-5), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (255,0,0), 1)
# 归一化互相关(NCC,红色框)- 文字放在框内底部,偏移5像素避免贴边
cv2.rectangle(color, loc2, (loc2[0]+w, loc2[1]+h), (0,0,255), 2)
cv2.putText(color, 'NCC', (loc2[0]+5, loc2[1]+h-5), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0,0,255), 1)
return color, f'{prefix}(含匹配框)'
# 生成3张带框图像
img_box, title1 = draw_corr_box(img, loc_ccorr, loc_ncc, '原始图像')
img_bright_box, title2 = draw_corr_box(img_bright, loc_ccorr_bright, loc_ncc_bright, '增亮图像')
img_contrast_box, title3 = draw_corr_box(img_contrast, loc_ccorr_contrast, loc_ncc_contrast, '高对比度图像')
| 图像类型 | 普通相关性(CCORR) | 归一化互相关(NCC) |
|---|---|---|
| 原始图像 | res_ccorr |
res_ncc |
| 增亮图像 | res_ccorr_bright |
res_ncc_bright |
| 高对比度图像 | res_ccorr_contrast |
res_ncc_contrast |
plt.figure(figsize=(24, 18))
# 第一行:原始图像结果
plt.subplot(3, 4, 1)
plt.imshow(cv2.cvtColor(img_box, cv2.COLOR_BGR2RGB))
plt.title(title1)
plt.axis('off')
plt.subplot(3, 4, 2)
plt.imshow(res_ccorr, cmap='gray')
plt.title('原始图像 - CCORR热力图')
plt.axis('off')
plt.subplot(3, 4, 3)
plt.imshow(res_ncc, cmap='gray')
plt.title('原始图像 - NCC热力图')
plt.axis('off')
plt.subplot(3, 4, 4)
plt.imshow(tpl, cmap='gray')
plt.title('模板图像(原始)')
plt.axis('off')
# 第二行:增亮图像结果
plt.subplot(3, 4, 5)
plt.imshow(cv2.cvtColor(img_bright_box, cv2.COLOR_BGR2RGB))
plt.title(title2)
plt.axis('off')
plt.subplot(3, 4, 6)
plt.imshow(res_ccorr_bright, cmap='gray')
plt.title('增亮图像 - CCORR热力图')
plt.axis('off')
plt.subplot(3, 4, 7)
plt.imshow(res_ncc_bright, cmap='gray')
plt.title('增亮图像 - NCC热力图')
plt.axis('off')
plt.subplot(3, 4, 8)
plt.text(0.5, 0.5, '亮度+50\n\nCCORR:敏感\nNCC:鲁棒', ha='center', va='center', fontsize=10)
plt.title('实验说明')
plt.axis('off')
# 第三行:高对比度图像结果
plt.subplot(3, 4, 9)
plt.imshow(cv2.cvtColor(img_contrast_box, cv2.COLOR_BGR2RGB))
plt.title(title3)
plt.axis('off')
plt.subplot(3, 4, 10)
plt.imshow(res_ccorr_contrast, cmap='gray')
plt.title('高对比度图像 - CCORR热力图')
plt.axis('off')
plt.subplot(3, 4, 11)
plt.imshow(res_ncc_contrast, cmap='gray')
plt.title('高对比度图像 - NCC热力图')
plt.axis('off')
plt.subplot(3, 4, 12)
plt.text(0.5, 0.5, '对比度×1.5\n\nCCORR:敏感\nNCC:鲁棒', ha='center', va='center', fontsize=10)
plt.title('实验说明')
plt.axis('off')
plt.tight_layout()
plt.show()
print("【原始图像匹配结果】")
print(f"CCORR(普通相关性) 最佳位置:{loc_ccorr} | 最大相关值:{val_ccorr:.6f}")
print(f"NCC(归一化互相关) 最佳位置:{loc_ncc} | 最大相关值([0,1]):{val_ncc:.6f}")
print("【增亮图像匹配结果(亮度+50)】")
print(f"CCORR(普通相关性) 最佳位置:{loc_ccorr_bright} | 最大相关值:{val_ccorr_bright:.6f}")
print(f"NCC(归一化互相关) 最佳位置:{loc_ncc_bright} | 最大相关值([0,1]):{val_ncc_bright:.6f}")
print("【高对比度图像匹配结果(对比度×1.5)】")
print(f"CCORR(普通相关性) 最佳位置:{loc_ccorr_contrast} | 最大相关值:{val_ccorr_contrast:.6f}")
print(f"NCC(归一化互相关) 最佳位置:{loc_ncc_contrast} | 最大相关值([0,1]):{val_ncc_contrast:.6f}")


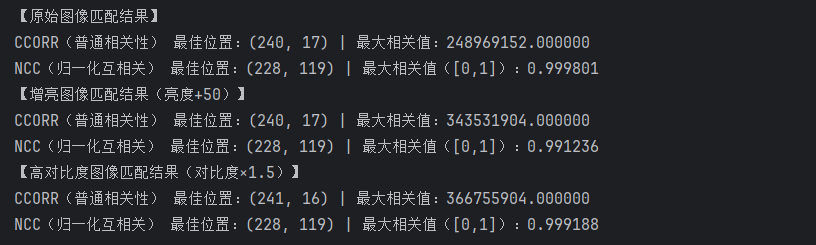
4. 实验结论
(1)普通相关性(CCORR)算法结论
CCORR 作为无归一化的基础相关性算法,存在显著先天缺陷,实用性极低,不适合任何实际场景的模板匹配任务:
- 匹配逻辑局限:仅以「像素点积和最大值」作为匹配依据,只关注像素「绝对亮度高低」,不关注灰度「相对分布相似度」,容易将图像中高亮度区域误判为最佳匹配区域,即使是「原版模板对原版图像」,也会出现严重错位。
- 抗干扰能力极差:对亮度变化、对比度变化高度敏感,仅轻微的光照增强或对比度拉伸,就会导致匹配结果完全失真,匹配框偏移严重,无法锁定真实目标区域。
- 量化结果无参考性:匹配得分无固定取值范围,仅能在同一图像的同一算法内做相对对比,无法跨场景、跨图像评估匹配效果,缺乏实用价值。
- 适用场景:仅存在于理论教学中,用于对比凸显归一化算法的优势,无任何实际工程落地场景。
(2)归一化互相关(NCC/CCORR_NORMED)算法结论
NCC 作为 CCORR 的改进版(增加归一化处理),是模板匹配任务中的核心实用算法,具备强鲁棒性,可广泛应用于实际场景:
- 匹配逻辑精准:通过归一化处理消除了亮度均值、对比度方差的影响,仅关注「模板与目标窗口的灰度相对分布相似度」,能够精准锁定与模板灰度分布一致的区域,即使存在局部亮度不均,也能实现精准匹配。
- 抗干扰能力优异:对图像亮度变化、对比度变化具有极强的鲁棒性,在增亮、高对比度等干扰场景下,依然能保持稳定的匹配效果,匹配框精准对齐真实目标,量化得分波动极小(趋近于1)。
- 量化结果直观可靠:匹配得分被严格限制在 [0,1] 区间,得分越接近1,说明匹配度越高,可跨场景、跨图像评估匹配效果,具备明确的参考价值和工程落地性。
- 适用场景:广泛应用于工业检测、人脸识别、图像拼接、目标追踪等实际计算机视觉任务,是模板匹配的首选算法之一。
(3)整体核心总结
- 归一化处理是提升相关性匹配算法鲁棒性的关键核心,它解决了 CCORR 认亮不认像的先天缺陷,让算法从「理论可行」走向「实际可用」。
- 模板匹配任务中,应优先选择带归一化的匹配算法(如 NCC),避免使用无归一化的基础算法(如 CCORR),以保证匹配结果的稳定性和可靠性。
Ⅳ、多目标模板匹配
一、Python 代码实现
import numpy as np
import cv2
import matplotlib.pyplot as plt
# 利用快速排序算法找到数列中第k大的值
def findKth(s, k):
return findKth_c(s, 0, len(s) - 1, k)
def findKth_c(s, low, high, k):
m = partition(s, low, high)
if m == len(s) - k:
return s[m]
elif m < len(s) - k:
return findKth_c(s, m + 1, high, k)
else:
return findKth_c(s, low, m - 1, k)
def partition(s, low, high):
pivot, j = s[low], low
for i in range(low + 1, high + 1):
if s[i] <= pivot:
j += 1
s[i], s[j] = s[j], s[i]
s[j], s[low] = s[low], s[j]
return j
这段代码实现了快速选择算法,核心功能是在无需对整个数组完整排序的前提下,高效定位并返回数组中第k大的元素,三个函数分工协作、层层调用,聚焦于目标元素查找,不关心数组整体有序性。
findKth(s, k) - 算法入口函数
- 核心作用:提供简洁易用的调用接口,屏蔽底层递归所需的区间边界参数(
low/high),降低使用者操作门槛,无需手动初始化递归区间。 - 核心逻辑:直接调用递归核心函数
findKth_c(),传入数组完整区间(起始索引0、结束索引len(s) - 1)和查找参数k,最终转发并返回递归函数的查找结果,完成接口封装。
findKth_c(s, low, high, k) - 递归核心函数
- 核心作用:通过「单向递归+分区定位」,精准找到第k大元素的位置,找到后直接返回,舍弃无关区间,避免冗余计算。
- 核心逻辑:
- 调用
partition()函数对当前区间[low, high]进行分区处理,得到基准值的最终有序索引m; - 计算第k大元素对应的目标索引:
len(s) - k(基于数组升序分区的特性,升序排列后第k大元素的索引为数组长度减去k); - 单向递归判断(区别于快速排序的双向递归):
- 若
m == len(s) - k:基准值即为第k大元素,直接返回s[m]; - 若
m < len(s) - k:第k大元素在基准值右侧区间,仅递归处理[m+1, high]区间; - 若
m > len(s) - k:第k大元素在基准值左侧区间,仅递归处理[low, m-1]区间。
- 若
- 调用
partition(s, low, high) - 分区函数
- 核心作用:将当前区间
[low, high]按基准值分区,把基准值放到其最终的有序位置,返回该位置索引,为递归提供定位依据。 - 核心逻辑:
- 选择区间起始元素
s[low]作为基准值(pivot),初始化左侧区域尾指针j = low; - 遍历区间
[low+1, high],将所有「小于等于基准值」的元素移动到区间左侧,每找到一个符合条件的元素,j指针右移一位并交换元素; - 遍历结束后,交换基准值
s[low]和左侧区域尾指针对应元素s[j],将基准值放置到其最终有序位置; - 返回基准值索引
j,此时基准值左侧所有元素均≤它,右侧所有元素均≥它。
- 选择区间起始元素
class temp_match_multi():
def __init__(self, img, temp, k=50):
if img is None or temp is None:
raise ValueError("图像读取失败,请检查文件路径是否正确或文件是否损坏")
self.img_bgr = img
self.temp_bgr = temp
self.img_rgb = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
self.temp_rgb = cv2.cvtColor(temp, cv2.COLOR_BGR2RGB)
self.k = k
def match(self):
temp_gray = cv2.cvtColor(self.temp_bgr, cv2.COLOR_BGR2GRAY)
img_gray = cv2.cvtColor(self.img_bgr, cv2.COLOR_BGR2GRAY)
w, h = temp_gray.shape[::-1]
match_method = cv2.TM_CCORR_NORMED
res = cv2.matchTemplate(img_gray, temp_gray, match_method)
match_result_flat = list(np.array(res).flatten())
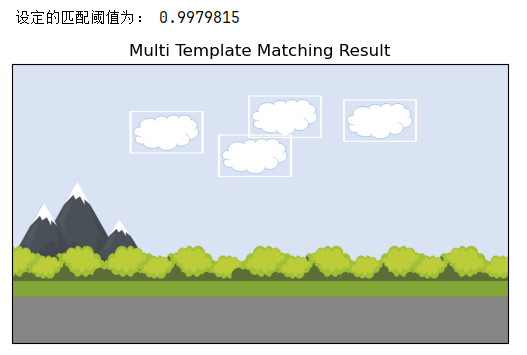
threshold = findKth(match_result_flat, self.k + 1)
print('设定的匹配阈值为:', threshold)
loc = np.where(res >= threshold)
img_draw_bgr = self.img_bgr.copy()
for pt in zip(*loc[::-1]):
cv2.rectangle(img_draw_bgr, pt, (pt[0] + w, pt[1] + h), (255, 255, 255), 1)
img_draw_rgb = cv2.cvtColor(img_draw_bgr, cv2.COLOR_BGR2RGB)
plt.figure()
plt.title('Multi Template Matching Result')
plt.imshow(img_draw_rgb)
plt.xticks([])
plt.yticks([])
plt.show()
- 代码明确定义
match_method = cv2.TM_CCORR_NORMED,并传入cv2.matchTemplate()执行模板匹配,NCC(Normalized Cross-Correlation,归一化互相关)就是该方法的对应名称(cv2.TM_CCORR_NORMED是 OpenCV 中 NCC 算法的具体实现); - 它是归一化版本的互相关匹配,输出相似度值在 [0,1] 区间,抗亮度干扰能力强,便于后续多目标匹配的阈值筛选;
- 核心作用是完成模板与目标图像的灰度相似度计算,为后续标注高相似度目标提供数据支撑。
def plot_image(img_rgb, title):
plt.figure()
plt.title(title)
plt.imshow(img_rgb)
plt.xticks([])
plt.yticks([])
plt.show()
if __name__ == "__main__":
target_img = cv2.imread('img.png')
template_img = cv2.imread('temp.png')
try:
test_multi = temp_match_multi(target_img, template_img, k=50)
plot_image(test_multi.img_rgb, 'Target Image (Original)')
plot_image(test_multi.temp_rgb, 'Template Image (Original)')
test_multi.match()
except ValueError as e:
print("程序运行出错:", e)
二、多模板匹配核心 OpenCV 方法 - 参数及作用详解
1. cv2.matchTemplate() - 计算方法
cv2.matchTemplate(image, templ, method)
| 参数名 | 核心作用 | 代码中的具体取值 |
|---|---|---|
| image | 待查找匹配区域的目标图像,作为匹配的“大图”,要求为单通道(灰度图)或3通道(彩色图),代码中使用灰度图以提升效率 | img_gray(目标图像转换后的灰度图) |
| templ | 用于匹配的模板图像,作为匹配的“小图”,尺寸必须小于等于 image,通道数需与 image 一致,代码中为灰度图 | temp_gray(模板图像转换后的灰度图) |
| method | 指定匹配算法的类型,决定相似度的计算方式,直接影响匹配结果的稳定性和筛选效率 | cv2.TM_CCORR_NORMED(归一化互相关算法) |
- 这三个参数均为必传参数,缺少任何一个都无法完成匹配;
- 代码中选用 cv2.TM_CCORR_NORMED 作为 method,是为了得到 [0,1] 区间的标准化相似度值,方便后续多目标阈值筛选。
2. cv2.rectangle() - 标注方法
cv2.rectangle(img, pt1, pt2, color, thickness)
| 参数名 | 核心作用 | 代码中的具体取值 |
|---|---|---|
| img | 待绘制矩形框的目标图像,是匹配结果标注的载体,代码中使用原始图像的复制件,避免修改原始数据 | img_draw_bgr(self.img_bgr 的复制图) |
| pt1 | 矩形框的左上角坐标,对应模板匹配得到的有效窗口起始位置,决定矩形框的摆放起点 | pt(筛选出的高相似度匹配坐标) |
| pt2 | 矩形框的右下角坐标,由 pt1 加上模板的宽高(w/h)计算得出,保证矩形框刚好框住匹配区域 | (pt[0] + w, pt[1] + h)(模板宽高补全坐标) |
| color | 矩形框的颜色,采用 OpenCV 标准的 BGR 通道格式,代码中选用高对比度颜色保证标注清晰 | (255, 255, 255)(白色,BGR 格式) |
| thickness | 矩形框的线宽,单位为像素,代码中选用细线避免遮挡匹配目标本身,适合多目标密集场景 | 1(1像素细线) |
- img 是传入的图像数组,该函数会直接在该图像上进行绘制(原地修改),因此代码中先复制原始图像再绘制,保护原始数据;
- 若 thickness 传入负数(如 -1),会填充整个矩形框,覆盖匹配目标,不适合多目标标注场景。
3. 总结
- cv2.matchTemplate() 核心参数3个:目标图、模板图、匹配算法,用于生成相似度数据;
- cv2.rectangle() 核心参数5个:绘制图像、左上角坐标、右下角坐标、颜色、线宽,用于批量标注匹配结果;
- 所有参数均围绕“多目标匹配”设计,保证了匹配的高效性和标注的清晰性。
Ⅴ、总结
模板匹配的核心是通过计算 目标图像窗口 与 模板图像 的像素差异/相关性,得到相似度值
4种方法对比
| 方法类型 | 相似度判断 | 抗干扰能力 | 结果区间 | 工程实用性 |
|---|---|---|---|---|
平方差(TM_SQDIFF) |
越小越好 | 弱(敏感亮度/对比度) | 无固定区间 | 低(仅用于简单场景) |
归一化平方差(TM_SQDIFF_NORMED) |
越小越好 | 强 | [ 0 , 1 ] [0,1] [0,1] | 中(平方差类首选) |
相关性(TM_CCORR) |
越大越好 | 弱(敏感亮度/对比度) | 无固定区间 | 低(仅用于简单场景) |
归一化相关性(TM_CCORR_NORMED) |
越大越好 | 极强 | [ 0 , 1 ] [0,1] [0,1] | 高(实际工程首选,多目标匹配核心) |
单/多模板匹配
| 对比维度 | 单模板匹配 | 多模板匹配 |
|---|---|---|
| 核心目标 | 寻找唯一最高匹配度区域 | 寻找前k个高匹配度区域 |
| 阈值依赖 | 无需阈值,直接取极值 | 必须依赖阈值,筛选有效目标 |
| 匹配方法选择 | 4种均可,优先归一化 | 仅支持归一化类(核心) |
| 额外算法依赖 | 无 | 需快速选择等算法确定阈值 |
| 适用场景 | 目标图像中仅有一个模板目标 | 目标图像中有多个模板目标 |
| 典型案例 | 证件照人脸定位、单地标查找 | 文档文字标注、多元件定位 |
- 归一化相关性(
cv2.TM_CCORR_NORMED)综合性能最优,抗干扰强、结果标准化,是多模板匹配的核心方法; - 单模板匹配聚焦“唯一目标”,无需阈值;多模板匹配聚焦“多个目标”,依赖归一化结果和阈值筛选;
- 多模板匹配是单模板匹配的延伸,核心解决“批量筛选高相似度目标”的需求,更贴近实际复杂场景。
本章多目标模板匹配参考书:《动手学计算机视觉》
上一章
下一章

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 15
15 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)