[TMI 2022] 脑部MRI配准新范式:联合“渐进式”与“由粗到细”策略
[TMI 2022] 脑部MRI配准新范式:联合“渐进式”与“由粗到细”策略
论文题目: Joint Progressive and Coarse-to-Fine Registration of Brain MRI via Deformation Field Integration and Non-Rigid Feature Fusion
发表期刊: IEEE Transactions on Medical Imaging (TMI), Vol. 41, No. 10, Oct 2022
作者团队: Jinxin Lv, Qiang Li, et al. (华中科技大学)
关键词: 脑部MRI配准, 深度学习, 渐进式配准, 特征融合, 皮层下核团
1. 🚀 速读 (TL;DR)
针对脑部 MRI 配准中复杂的皮层下核团对齐难题,现有的方法要么采用渐进式(Progressive)(如级联多个网络,参数量大),要么采用由粗到细(Coarse-to-fine)(如金字塔结构,层间交互有限)。本文认为这两种策略并不互斥,并提出了一种统一框架。
该框架基于双编码器 U-Net,通过两个核心模块:形变场积分 (DFI) 和 非刚性特征融合 (NFF),实现了在解码器每一层同时进行渐进式变形和多尺度细化。实验表明,该方法在 IXI、LPBA 和私有数据集上显著优于 VoxelMorph、VTN 和 Dual-PRNet,平均 Dice 系数提升最高达 8%,且参数量远少于级联网络。
2. 🧐 动机与痛点 (Motivation)
现有方法的局限性
- 直接估计法 (Direct Estimation): 如 VoxelMorph,试图一次性预测大变形场,对于复杂的解剖结构(如小的皮层下核团)往往难以处理。
- 渐进式配准 (Progressive): 如 VTN (Volume Tweening Network),通过级联多个 CNN 子网络逐步对齐。
- 缺点: 计算成本高,参数量巨大(每个级联都是一个完整网络)。
- 由粗到细策略 (Coarse-to-Fine): 如 Dual-PRNet,利用多尺度特征。
- 缺点: 分解依赖于相邻的两层,层间信息交互不足,提升空间有限。
本文的洞察
- 结合优势: 渐进式能处理大变形,由粗到细能节省参数。为什么不将两者结合?
- 轻量化级联: 不需要级联笨重的完整 CNN,而是利用 U-Net 解码器的每一层 (Decoding Block) 作为“级联”的步骤。
- 特征交互: 之前的层预测出的粗糙形变场,应该被用来“预对齐”当前层的特征,从而简化当前层的预测任务。
3. 💡 方法论 (Methodology)
3.1 整体架构
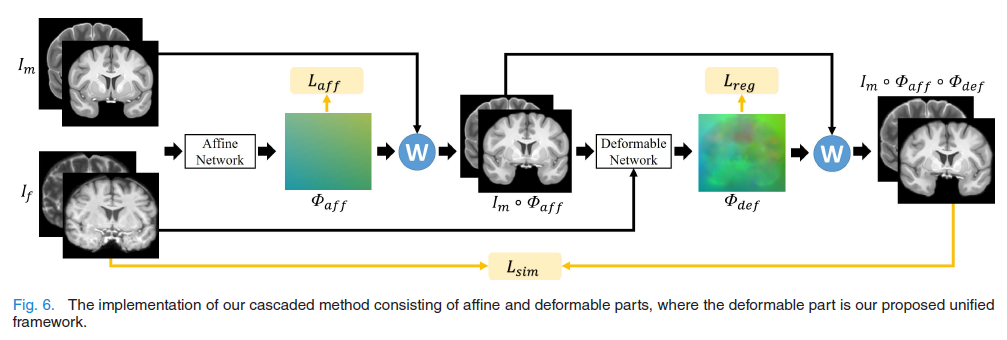
模型包含两部分:
- 仿射配准网络 (Affine Network): 先进行全局粗配准(旋转、平移、缩放)。
- 可变形配准网络 (Deformable Network): 本文的核心,基于 Dual-Encoder U-Net。
- 双编码器 (Dual-Encoder): 分别提取移动图像 (ImI_mIm) 和固定图像 (IfI_fIf) 的特征。这避免了在浅层直接拼接图像导致的风格/强度干扰,使特征更纯粹。
- 单解码器 (Single-Decoder): 在解码阶段融合特征并预测形变场。
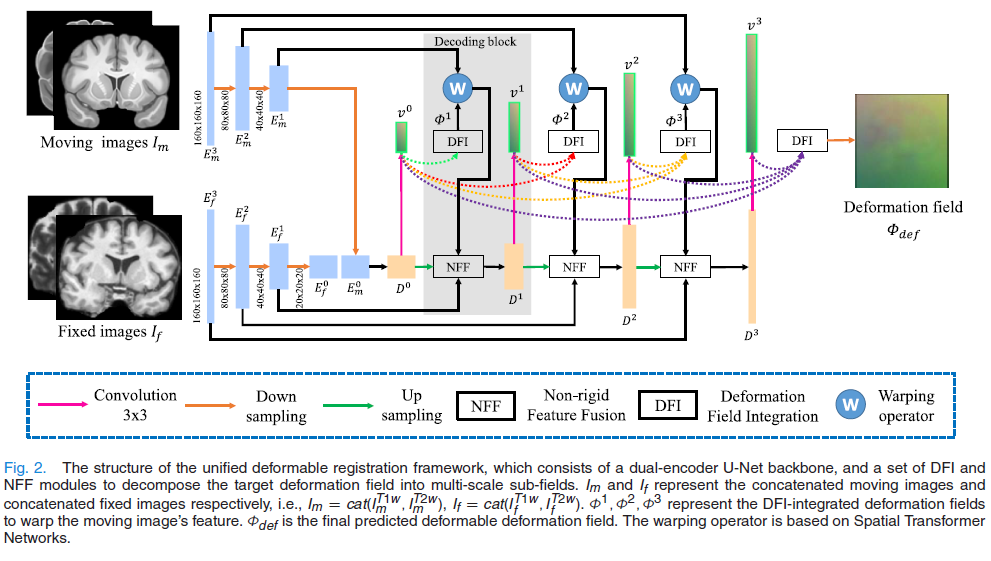
3.2 核心模块:DFI 与 NFF
在解码器的每一层 lll,都包含以下两个模块:
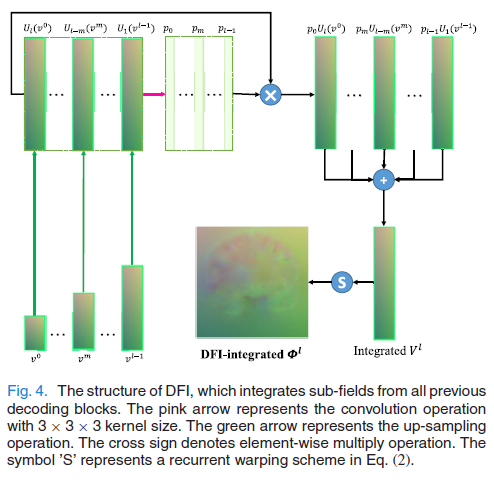
A. 形变场积分模块 (Deformation Field Integration, DFI)
- 作用: 将之前所有层预测出的粗糙速度场(Velocity Sub-fields)整合成一个当前的综合形变场。
- 机制:
- 收集所有前序层的速度场 {v0,...,vl−1}\{v_0, ..., v_{l-1}\}{v0,...,vl−1} 并上采样。
- 通过卷积生成权重图,对这些场进行加权融合,得到 VlV_lVl。
- 通过循环扭曲 (Recurrent Warping) 方案(类似 VoxelMorph-diff 的积分),将速度场 VlV_lVl 转换为微分同胚的形变场 Φl\Phi_lΦl。
- 意义: Φl\Phi_lΦl 代表了“到目前为止”累积的所有形变,用它来扭曲图像相当于完成了前几步的渐进式配准。
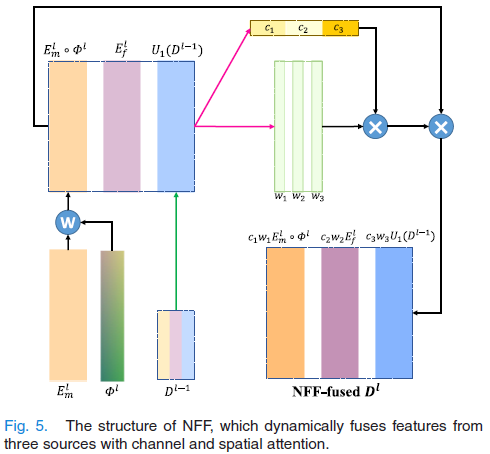
B. 非刚性特征融合模块 (Non-rigid Feature Fusion, NFF)
- 作用: 利用 DFI 生成的形变场,动态融合来自三个源头的特征。
- 三个输入源:
- 移动图像特征 (EmlE_m^lEml): 关键点——先用 DFI 的形变场 Φl\Phi_lΦl 对其进行扭曲(Warp),使其在空间上接近固定图像。
- 固定图像特征 (EflE_f^lEfl): 保持不变。
- 上一层解码特征 (Dl−1D_{l-1}Dl−1): 包含高层语义信息。
- 融合方式: 使用通道注意力 (Channel Attention) 和 空间注意力 (Spatial Attention) 机制,自适应地加权融合这三个特征,生成当前层的解码特征 DlD_lDl。
- 意义: 当前层不再需要解决所有偏差,只需要解决被 Φl\Phi_lΦl 扭曲后剩余的残差,大大降低了预测难度。
3.3 损失函数
采用无监督/弱监督混合损失:
Ltotal=α1Laff+α2Lreg+α3Lsim+α4Lseg \mathcal{L}_{total} = \alpha_1 \mathcal{L}_{aff} + \alpha_2 \mathcal{L}_{reg} + \alpha_3 \mathcal{L}_{sim} + \alpha_4 \mathcal{L}_{seg} Ltotal=α1Laff+α2Lreg+α3Lsim+α4Lseg
- 仿射损失: 约束仿射矩阵的正交性和行列式,防止过度剪切。
- 平滑损失: 约束形变场的梯度。
- 相似性损失: 使用 NLCC (归一化局部互相关)。
- 分割损失 (弱监督): Dice Loss。仅在训练时使用解剖标签(如核团掩膜)辅助训练,测试时不需要。
4. 📊 实验与结果
数据集
- IXI: 576 对脑部 MRI,包含 16 个皮层下核团标签。
- LPBA: 40 张 T1w 图像,56 个解剖结构标签。
- Private Dataset: 100 对临床数据。
对比方法
Elastix, ANTs (传统方法); VoxelMorph, VTN, Dual-PRNet (深度学习方法)。
核心结论
- 精度提升: 在 IXI 数据集上,该方法在 Dice、Hausdorff 距离等指标上全面优于 SOTA。相比于仅使用渐进式的 VTN 和仅使用由粗到细的 Dual-PRNet,平均 Dice 提升明显。
- 皮层下核团: 在难以配准的小体积核团(Subcortical Nuclei)上表现尤为出色(见 Boxplots 分析)。
- 效率: 相比于 10 级级联的 VTN (2x10-cascade),本文方法的参数量减少了约 20倍,但精度相当甚至更好。
- 平滑性: 雅可比行列式(Jacobian Determinant)分析显示,该方法在保持高精度的同时,产生了极少的折叠体素(Folding voxels),保证了形变的拓扑合理性。
- 泛化性: 在跨扫描协议(不同机器)和跨固定图像(不同目标)的测试中,该方法的性能下降幅度最小,证明了 Dual-Encoder + Single-Decoder 结构的鲁棒性。
5. 🧠 总结与思考
优点 (Pros)
- 架构创新: 巧妙地将“渐进式”思想融入到了 U-Net 的解码器内部,而不是外部级联,极大地节省了计算资源。
- 特征对齐: NFF 模块在特征空间进行非刚性配准(Feature Warping),这比单纯在图像空间操作更有效。
- 双编码器优势: 实验证实,双编码器比单编码器更能适应不同模态或风格的图像对,提高了泛化能力。
局限性 (Limitations)
- 训练复杂性: 引入了 DFI 和 NFF 模块,使得网络内部的数据流比标准 U-Net 复杂,实现难度稍高。
- 依赖标签: 虽然是弱监督,但为了达到最佳性能(特别是针对核团),训练阶段仍推荐使用分割标签(Dice Loss)。在完全无监督模式下(LPBA实验),虽然仍优于 VoxelMorph,但优势有所收窄。
启示
这篇论文为医学图像配准提供了一个新的设计思路:不要把网络层仅仅看作特征提取器,也可以把它们看作配准的“迭代步骤”。通过在网络内部进行显式的特征扭曲和对齐,可以显著降低深层网络的学习难度。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 14
14 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)